一种基于医生相关属性检索诊断病例的装置及方法与流程
本发明涉及一种基于医生相关属性检索诊断病例的装置及方法。
背景技术
专利文献1(中国专利申请201310603059.5)公开了一种病历查询方法。所述方法包括:在接收到对病历的存储指令时,解析病历以获取多项诊疗信息,以及每项诊疗信息对应的特征数据;根据多项诊疗信息之间的结构关系,对多项诊疗信息进行结构化存储,其中,将每项诊疗信息和相应的特征数据进行关联存储;解析查询指令以确定目标诊疗信息和目标关键字,并在与目标诊疗信息相关联的特征数据中查询与目标关键字相匹配的目标特征数据。
专利文献1还公开了一种病历查询系统,包括:解析单元,用于在接收到对病历的存储指令时,解析所述病历以获取所述病历中的多项诊疗信息,以及所述多项诊疗信息中每项诊疗信息对应的特征数据,以及在接收到对所述病历的查询指令时,解析所述查询指令以确定目标诊疗信息和目标关键字;存储单元,用于根据所述多项诊疗信息之间的结构关系,对所述多项诊疗信息进行结构化存储,其中,将所述每项诊疗信息和相应的特征数据进行关联存储;查询单元,在与所述目标诊疗信息相关联的特征数据中查询与所述目标关键字相匹配的目标特征数据。
通过专利文献1的技术方案,能够将病历中的诊疗信息进行结构化存储,从而在用户查询病历时,可以直接根据查询条件在存储的诊疗信息中进行查询,无需对病历进行全文检索,提高了查询的效率。
然而,用户在检索病历后,有时能够获得很多符合检索条件的病历。在这种情况下,用户只能通过逐一阅读检索出的病历,来判断哪一个病历才是自己所期望的病历。如此一来,用户需要花费大量的时间来筛选病历,给用户造成了极大的困扰。
技术实现要素:
发明要解决的问题
本发明正是为了解决这样的问题而完成的,其目的在于,提供一种能够根据医生相关属性来检索诊断病例的装置及方法,从而能够快速地获得所期望的诊断病例。
解决问题的技术手段
本发明所涉及的基于医生相关属性检索诊断病例的装置,包括:关键字输入部,其用于输入与关键字;诊断病例检索部,其使用所述关键字,对诊断病例共享库进行检索;第一矩阵建立部,其建立第一矩阵,所述第一矩阵为诊断病例-诊断病例共享库属性的二维矩阵,所述第一矩阵建立部通过以下方式建立所述第一矩阵:将所述诊断病例共享库中所有医生诊疗经验描述的属性,即诊断病例共享库属性作为矩阵的列名,将通过所述诊断病例检索部检索出来的诊断病例id以及由用户指定的医生诊疗经验描述的参照属性id作为行名,且将所述参照属性id作为第一行,当所述第一矩阵的某行所表示的所述诊断病例id或所述参照属性id具有所述第一矩阵的某列所表示的所述诊断病例共享库属性时,将所述第一矩阵的该行列的值标记为1,否则标记为0;关系集合建立部,其根据所述第一矩阵,建立关系集合,所述关系集合为诊断病例共享库属性-诊断病例的关系集合,所述关系集合建立部通过以下方式建立所述关系集合:每个诊断病例共享库属性的所述关系集合包含所有在所述第一矩阵中该诊断病例共享库属性所对应的列标记为1的所述诊断病例id或所述参照属性id;第二矩阵建立部,其根据所述关系集合,建立第二矩阵,所述第二矩阵为诊断病例-诊断病例的二维矩阵,所述第二矩阵建立部通过以下方式建立所述第二矩阵:将所述诊断病例id以及所述参照属性id作为行名以及列名,且将所述参照属性id作为第一行以及第一列,将每个诊断病例共享库属性的所述关系集合中的不同所述诊断病例id的两两组合的个数,或是所述诊断病例id与所述参照属性id的组合的个数作为相应的行列的值,并且在所述第二矩阵中将行与列代表相同所述诊断病例id或者均代表所述参照属性id的值标记为0;相似度计算部,其根据所述第二矩阵,计算每个诊断病例id与所述参照属性id的相似度;以及诊断病例推荐部,其根据所述相似度,对所述诊断病例id进行排序,并按照排列顺序推荐所述诊断病例id。
另外,本发明所涉及的基于医生相关属性检索诊断病例的方法,包括:关键字输入步骤,用于输入关键字;诊断病例检索步骤,使用所述关键字,对诊断病例共享库进行检索;第一矩阵建立步骤,建立第一矩阵,所述第一矩阵为诊断病例-诊断病例共享库属性的二维矩阵,在所述第一矩阵建立步骤中,通过以下方式建立所述第一矩阵:将所述诊断病例共享库中所有医生诊疗经验描述的属性,即诊断病例共享库属性作为矩阵的列名,将通过所述诊断病例检索部检索出来的诊断病例id以及由用户指定的医生诊疗经验描述的参照属性id作为行名,且将所述参照属性id作为第一行,当所述第一矩阵的某行所表示的所述诊断病例id或所述参照属性id具有所述第一矩阵的某列所表示的所述诊断病例共享库属性时,将所述第一矩阵的该行列的值标记为1,否则标记为0;关系集合建立步骤,根据所述第一矩阵,建立关系集合,所述关系集合为诊断病例共享库属性-诊断病例的关系集合,在所述关系集合建立步骤中,通过以下方式建立所述关系集合:每个诊断病例共享库属性的所述关系集合包含所有在所述第一矩阵中该诊断病例共享库属性所对应的列标记为1的所述诊断病例id或所述参照属性id;第二矩阵建立步骤,其根据所述关系集合,建立第二矩阵,所述第二矩阵为诊断病例-诊断病例的二维矩阵,所述第二矩阵建立步骤中,通过以下方式建立所述第二矩阵:将所述诊断病例id以及所述参照属性id作为行名以及列名,且将所述参照属性id作为第一行以及第一列,将每个诊断病例共享库属性的所述关系集合中的不同所述诊断病例id的两两组合的个数,或是所述诊断病例id与所述参照属性id的组合的个数作为相应的行列的值,并且在所述第二矩阵中将行与列代表相同所述诊断病例id或者均代表所述参照属性id的值标记为0;相似度计算步骤,根据所述第二矩阵,计算每个诊断病例id与所述参照属性id的相似度;以及诊断病例推荐步骤,根据所述相似度,对所述诊断病例id进行排序,并按照排列顺序推荐所述诊断病例id。
发明的效果
根据本发明的装置及方法,能够根据每个诊断病例的医生相关的属性与用户指定的医生相关的属性的相似度,对检索出的诊断病例进行排序,并按照排列顺序推荐诊断病例,由此,用户能够快速地获得所期望的诊断病例。
附图说明
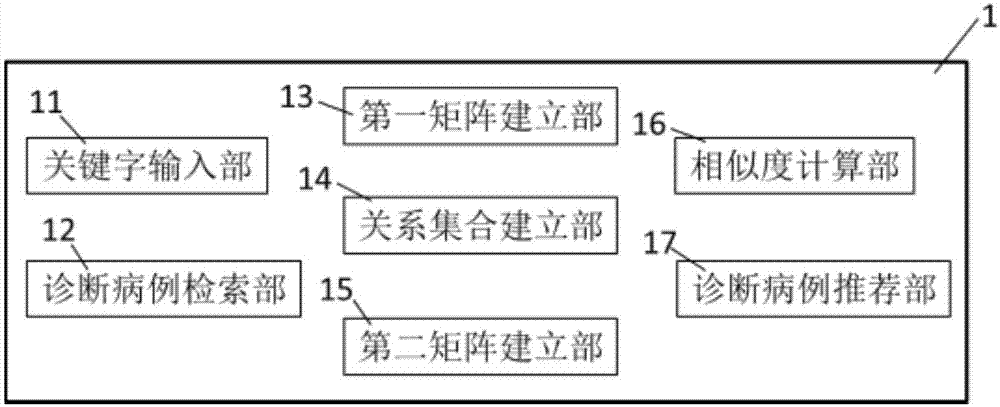
图1为表示本发明实施方式所涉及的装置的构成图。
图2为表示本发明实施方式所涉及的装置执行诊断病例的检索及推荐的流程图。
具体实施方式
以下,参照附图,对本发明的具体实施方式进行说明。
图1为表示本发明实施方式所涉及的装置的构成图,图2为表示本发明实施方式所涉及的装置执行诊断病例的检索及推荐的流程图。
如图1所示,本发明的装置1包括:关键字输入部11、诊断病例检索部12、第一矩阵建立部13、关系集合建立部14、第二矩阵建立部15、相似度计算部16、以及诊断病例推荐部17。
关键字输入部11用于输入关键字(图2中的步骤s1),可以使用键盘等常用的输入设备。
诊断病例检索部12使用所述关键字,对诊断病例共享库进行检索(图2中的步骤s2)。在诊断病例共享库中,每个诊断病例关于医生诊疗经验的描述部分包括:医生所在的科室、医生的职称、医生所在医院的级别等,本领域人员均可以使用该诊断病例共享库进行检索。通常情况下,将诊断病例中关于医生诊疗经验的描述部分经过分词而获得诊断病例的多个属性,再将所有诊断病例的多个属性合并,并剔除重复的属性,就形成了诊断病例共享库的属性。
第一矩阵建立部13建立第一矩阵,所述第一矩阵为诊断病例-诊断病例共享库属性的二维矩阵(图2中的步骤s3)。
具体来说,将所述诊断病例共享库中所有描述医生诊疗经验的属性,即诊断病例共享库属性作为矩阵的列名,记为:
x1,x2,x3...xi(i=n,n为正整数)
将通过所述诊断病例检索部检索出来的诊断病例id以及参照属性id作为行名,且将参照属性id作为第一行,记为:
id,id1,id2,id3...idj(j=n,n为正整数)
在此,参照属性id是由用户根据需要而指定的描述医生诊疗经验的属性。
当所述第一矩阵的某行所表示的所述诊断病例id或所述参照属性id具有所述第一矩阵的某列所表示的所述诊断病例共享库属性时,将所述第一矩阵的该行列的值标记为1,否则标记为0,如此获得了如下所示的第一矩阵:
关系集合建立部14根据所述第一矩阵,建立关系集合,所述关系集合为诊断病例共享库属性-诊断病例的关系集合(图2中的步骤s4)。
具体来说,每个诊断病例共享库属性的所述关系集合包含所有在所述第一矩阵中该诊断病例共享库属性所对应的列标记为1的所述诊断病例id或所述参照属性id,即:
x1:{id,id1,id2…}
x2:{id…idj}
x3:{id1…idj}
x4:{id1,id2…}
…
第二矩阵建立部15根据所述关系集合,建立第二矩阵,所述第二矩阵为诊断病例-诊断病例的二维矩阵(图2中的步骤s5)。
具体来说,将所述诊断病例id以及所述参照属性id作为行名以及列名,且将所述参照属性id作为第一行以及第一列,将每个诊断病例共享库属性的所述关系集合中的不同所述诊断病例id的两两组合的个数,或是所述诊断病例id与所述参照属性id的组合的个数作为相应的行列的值,并且在所述第二矩阵中将行与列代表相同所述诊断病例id或者均为所述参照属性id的值标记为0,如此获得了如下所示的第二矩阵:
在此,需要说明的是,例如,第id2行第id3列的值与第id3行第id2列的值由于都表示在所述关系集合中,id2与id3的组合的个数,因此为相同的值。
相似度计算部16,其根据所述第二矩阵以及所述关系集合,计算每个诊断病例id与所述参照属性id的相似度(图2中的步骤s6)。
在本实施方式中,可以使用下述式一,计算诊断病例idj与所述参照属性id的相似度
j为正整数,j=1,2,3…,并且为了简化公式,令u=idj、v=id,同时,zuv为所述第二矩阵中第u行第v列的值,p为第u行的总的个数,p’为第v列的总的个数,k和k’为正整数,zuk为所述第二矩阵中第u行第k列的值,zk′v为所述第二矩阵中第k'行第v列的值。
诊断病例推荐部17根据所述相似度,对所述诊断病例id进行排序,并按照排列顺序推荐所述诊断病例id(图2中的步骤s7)。
在本实施方式中,所述诊断病例推荐部按照所述相似度从大到小,对所述诊断病例id进行排序,并按照排列顺序推荐所述诊断病例id。
当存在所述相似度为相同的所述诊断病例id时,按照下述式二计算所述相似度为相同的所述诊断病例id的权重值score:
score=(p-1)n(n+1)(式一)
p为所述诊断病例id的点击率;n为在所述第一矩阵中,表示所述参照属性id与所述诊断病例id的行在同一列中的值为相同的列的个数,n为系数,
根据计算出的所述权重值score从大到小,对所述相似度为相同的所述诊断病例id进一步地排序,并结合按照所述相似度的排序与按照所述权重值score的排序,推荐所述诊断病例id。
在此,n用于调整诊断病例id的点击率与属性的权重,可以根据需要设定具体的数字。在本实施方式中,n为1/2。
实施例一
假设:用户输入关键字“高血压”进行检索时,检索结果数不为0,诊断病例共享库的属性为:
{心外科、高级医师、三甲医院、华东沿海地区、从医15年以上}。
输入关键字“高血压”到诊断病例共享库,得到检索结果集。检索结果集中共包括四个诊断病例,诊断病例id依次为id1、id2、id3、id4。
诊断病例关于医生诊疗经验描述的属性依次为:
id1:{心外科、高级医师、华东沿海地区、从医15年以上}
id2:{心外科、高级医师、三甲医院}
id3:{高级医师、三甲医院、华东沿海地区、从医15年以上}
id4:{心外科、三甲医院、从医15年以上}
并且假设用户指定的参照属性id为{高级医师、三甲医院、从医15年以上}。
建立诊断病例-诊断病例共享库属性的二维矩阵,将诊断病例共享库的所有属性作为矩阵的列的名称,即列的名称为:心外科、高级医师、三甲医院、华东沿海地区、从医15年以上。
将所述参照属性id作为矩阵的第一行,将检索结果诊断病例id作为其他行,所述矩阵的行即为id、id1、id2、id3、id4。
当诊断病例或参照属性有列中所列举属性时,将相应行列的值标记为1,否则标为0,即获得如下所述的诊断病例-诊断病例共享库属性的二维矩阵:
随后,建立诊断病例共享库属性-诊断病例的关系集合,即
心外科:{id1,id2,id4}
高级医师:{id,id1,id2,id3}
三甲医院:{id,id2,id3,id4}
华东沿海地区:{id1,id3}
从医15年以上:{id,id1,id3,id4}。
随后,建立诊断病例-诊断病例的二维矩阵,即
随后,利用式一,计算每个诊断病例id与所述与参照属性id的相似度,即,
对以上计算出的相似度进行比较,可知:
c(id3,id)>c(id2,id)=c(id4,id)>c(id1,id)
则按照id3、id2、id4、id1或者id3、id4、id2、id1的顺序推荐诊断病例,并且id3为最推荐的诊断病例。
实施例二
假设:用户输入关键字“糖尿病”进行检索,检索结果数不为0,诊断病例共享库的属性为:
{内分泌科、主任医师、三甲医院、华东沿海地区}
输入关键字“糖尿病”到诊断病例共享库,得到检索结果。检索结果中共包括三个诊断病例,依次为id1,id2,id3。
三个诊断病例中关于医生诊疗经验描述的属性依次为:
id1:{内分泌科、三甲医院}
id2:{华东沿海地区}
id3:{内分泌科、主任医师}
并且假设用户指定的参照属性id为{内分泌科、主任医师、三甲医院、华东沿海地区}。
建立诊断病例-诊断病例共享库属性的二维矩阵,将诊断病例共享库的所有属性作为矩阵的列的名称,即列的名称为:内分泌科、主任医师、三甲医院、华东沿海地区。
将所述参照属性id作为矩阵的第一行,将检索结果诊断病例id作为其他行,所述矩阵的行即为id,id1,id2,id3。
当诊断病例id或所述参照属性id有列中所列举属性时,将相应行列的值标记为1,否则标为0,即获得如下所述的诊断病例-诊断病例共享库属性的二维矩阵:
随后,建立诊断病例共享库属性-诊断病例的关系集合,即
内分泌科:{id,id1,id3}
主任医师:{id,id3}
三甲医院:{id,id1}
华东沿海地区:{id,id2}。
随后,建立诊断病例-诊断病例的二维矩阵,即
随后,利用式一,计算每个诊断病例id与所述与参照属性id的相似度,即,
对以上相似度进行比较,可知:
c(id1,id)=c(id3,id)>c(id2,id)
在此,可以按照id1、id3、id2或者id3、id1、id2的顺序推荐诊断病例,但是也可以根据式二计算诊断病例id1和诊断病例id3各自的权重值,根据权重值对诊断病例id1和诊断病例id3进行进一步地排序。
在本实施例中,假设诊断病例id1的点击率p为500,诊断病例id3的点击率p为901。同时,由上述诊断病例-诊断病例共享库属性的二维矩阵可知,诊断病例id1所在的行与参照属性id所在的行在同一列的值为相同的列的个数n为2,诊断病例id3所在的行与参照属性id所在的行在同一列的值为相同的列的个数n为2。
因此,诊断病例id1的权重值score1为:
诊断病例id3的权重值score3为:
基于权重值score的大小,对相似度相同的诊断病例id1和id3进行再次排序,即推荐顺序为id3、id1。
结合上述基于相似度的排序,则按照id3、id1、id2的顺序推荐诊断病例,并且id3为最推荐的诊断病例。
符号说明
1装置,11关键字输入部,12诊断病例检索部,13第一矩阵建立部,14关系集合建立部,15第二矩阵建立部,16相似度计算部,17诊断病例推荐部。
- 还没有人留言评论。精彩留言会获得点赞!