基于长短期记忆网络的医疗文本术语自动识别方法及系统与流程
本发明涉及机器学习领域,具体涉及一种基于长短期记忆网络的医疗文本术语自动识别方法及系统。
背景技术
传统的医学术语识别系统可分为基于词库匹配的术语识别系统和基于机器学习的医学术语自动识别系统。
基于词库匹配的医学术语自动识别系统具有精确率高、识别速度快的优点,但对医学规模和质量有着很高的要求,且对未登录字典的术语无法识别,即召回率往往不足。
基于传统机器学习方法的医学术语自动识别系统,可以从训练数据中学习医学术语的上下文信息,根据上下文信息来识别医学术语,避免了字典匹配对未登录字典术语无法识别的状况,大大地提高了召回率,但精确率往往较低。
鉴于上述,本设计人,积极加以研究创新,以期创设一种基于长短期记忆网络的医疗文本术语自动识别方法及系统,使其更具有产业上的利用价值。
技术实现要素:
为解决上述技术问题,本发明的目的是提供一种高精确率,高召回率的基于长短期记忆网络的医疗文本术语自动识别方法及系统。
本发明基于长短期记忆网络的医疗文本术语自动识别方法,包括,
将医学文本语句中每个文字使用预训练的字向量表示,得到训练数据;
将训练数据输入至双向长短记忆网络中,得到医学文本语句中每个文字概率最大的标签类别;
将每个文字概率最大的标签类别此输出结果输入到条件随机场中,使用维特比算法计算联合概率最大的标注序列。
进一步地,用word2vec的文本向量训练方式得到字向量,生成的字向量矩阵l为n×m维矩阵,其中n代表字典中的字数,m代表每个字向量的维数,通常m在100到300之间取值。
本发明基于长短期记忆网络的医疗文本术语自动识别系统,包括:
字向量模型单元,用于将医学文本语句中每个文字使用预训练的字向量表示;
双向长短时记忆网络单元,用于将训练数据输入至双向长短记忆网络中,得到医学文本语句中每个文字概率最大的标签类别;
条件随机场模型单元,用于将每个文字概率最大的标签类别此输出结果输入到条件随机场中,使用维特比算法计算联合概率最大的标注序列。
进一步地,具体包括:
文本输入层,文本以单个字拆分的形式输入;
字向量嵌入层,通过矩阵l将输入的字符映射至预训练的字向量;
双向长短时记忆网络层,采用向前lstm层、向后lstm层分别提取字向量嵌入层特征;
条件随机场层,对双向lstm的信息整合,并将整合后的信息将作为输入,输出医学文本逐字标注词性。
借由上述方案,本发明基于长短期记忆网络的医疗文本术语自动识别方法及系统,至少具有以下优点:
本发明采用双向的长短时记忆网络,将医学文本中各文字的分布式表示作为网络的输入,输出每个字概率最大的标签类别。双向长短时记忆网络充分考虑文字的上下文信息,着眼于对每个文字标签类别的概率最大化;条件随机场更多地考虑整个句子的局部特征的线性加权组合,计算联合概率,直接优化整个序列。使用双向长短时记忆网络和条件随机场算法共同对字序列进行标注。相比传统算法,融合了双向长短时记忆网络和条件随机场各自的优势,双向长短时记忆网络能更充分地利用上下文信息,能有效提升字标注的准确率,使得序列标注中字分类的准确率大大提高,也即提高了医学术语自动识别系统的精确率和召回率。
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,并可依照说明书的内容予以实施,以下以本发明的较佳实施例并配合附图详细说明如后。
附图说明
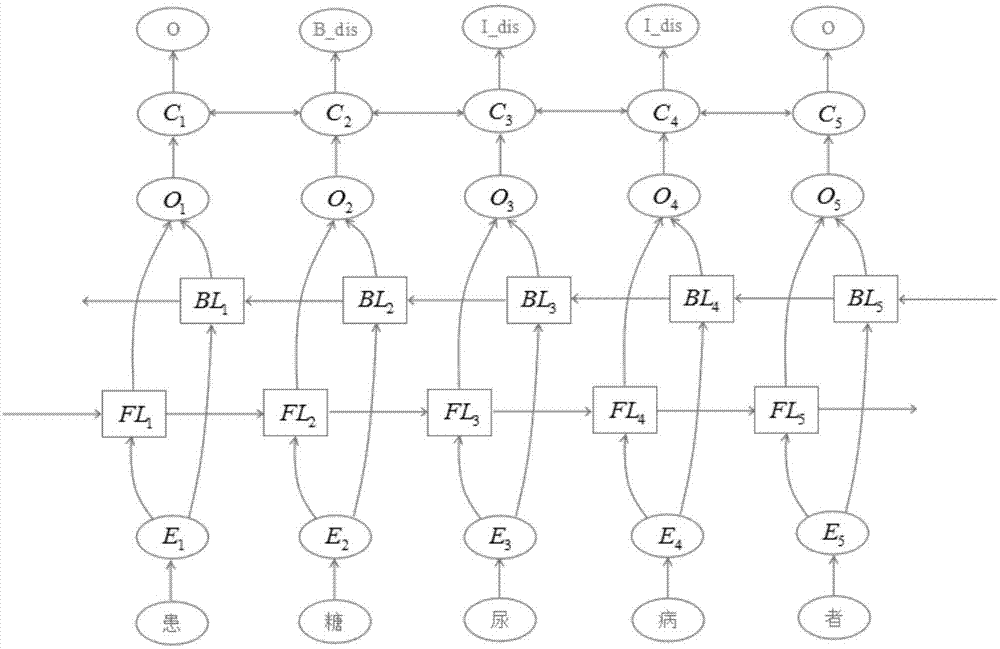
图1为本发明基于长短期记忆网络的医疗文本术语自动识别方法及系统的双向长短时记忆网络的框架图;
图2为本发明基于长短期记忆网络的医疗文本术语自动识别方法及系统的中长短时记忆网络单元fl1-fl5和bl1-bl5详细结构图。
具体实施方式
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
医学类文本中,如教科书、临床指南、电子病历等,都包含大量医学专业术语,这些术语在对文本结构化,知识信息抽取等方面都具有重要作用。我们将医学关键术语分为症状(sym)、疾病(dis)、体征(sgn)、部位词(reg)、器官(org)、体液(bfl)、检查(tes)、药品(dru)、手术(sur)等23个词汇类别。本方案将医学术语的自动识别问题转化为医学文本的字序列标注问题:以字序列作为观测序列,各文字所属术语类别构成的序列作为状态序列。
实施例1
本发明一种基于长短期记忆网络的医疗文本术语自动识别方法的一较佳实施例,包括:
将医学文本语句中每个文字使用预训练的字向量表示,得到训练数据;
将训练数据输入至双向长短记忆网络中,得到医学文本语句中每个文字概率最大的标签类别;
将每个文字概率最大的标签类别此输出结果输入到条件随机场中,使用维特比算法计算联合概率最大的标注序列。
本实施例举例,将采用长短时记忆网络和条件随机场,需要大量的标注训练数据,医学文本的字序列人工标注过程中,将采用字标注常用的bio方案。
举例说明,‘糖尿病的症状有多饮、多食和多尿。’将被标注成如下形式:
糖b_dis
尿i_dis
病i_dis
的o
症o
状o
有o
多b_sym
饮i_sym
、o
多b_sym
食i_sym
和o
多b_sym
尿i_sym
。o
上述标注中,疾病(dis)和症状(sym)类实体均被特殊标注方法如‘b_dis’等标注而出,其他无用词汇和符号则直接被标注成‘o’。
实施例2
本发明一种基于长短期记忆网络的医疗文本术语自动识别系统的一较佳实施例,包括:
字向量模型单元,用于将医学文本语句中每个文字使用预训练的字向量表示;
双向长短时记忆网络单元,用于将训练数据输入至双向长短记忆网络中,得到医学文本语句中每个文字概率最大的标签类别;
条件随机场模型单元,用于将每个文字概率最大的标签类别此输出结果输入到条件随机场中,使用维特比算法计算联合概率最大的标注序列。
如图1至2所示,双向长短时记忆网络+条件随机场模型构建
模型编程框架:pythontensorflow
模型训练数据:步骤1中的大量医学标注文本
模型输入:医学文本逐字输入模型
模型输出:医学文本逐字标注词性
模型架构:文本输入层,字向量嵌入层,双向长短时记忆网络层,条件随机场层,输出层由下至上如下结构图排列所示:
1.模型最底层为汉字输入层,文本以单个字拆分的形式输入模型。
2.e1-e5为字向量嵌入层,通过矩阵l将输入的字符映射至步骤2中预训练的字向量。
3.fl1-fl5为向前lstm层,用于提取e1-e5特征。
4.bl1-bl5为向后lstm层,用于提取e1-e5特征。
5.o1-o5为双向lstm的信息整合输出层,同时将作为后续crf层的输入。
6.c1-c5为crf层。
7.最高层为模型最终的输出层,用于预测输入层字符的标签。
模型中长短时记忆网络单元fl1-fl5和bl1-bl5详细结构介绍:
lstm单元结构图中,xt为t时刻模型输入,ht为t时刻模型输出,由于lstm属于循环神经网络,ht也会成为下一个时间节点t+1的输入,即t+1时刻单元接受输入[ht,xt]。ct为单元状态,用于保存长期状态。σ为sigmoid函数,tanh为双曲正切函数。wf为遗忘门权重矩阵,wi为输入门权重矩阵,wo为输出门权重矩阵,wc为当前单元状态ct新增信息权重矩阵。
上述各实施例中,字向量反映的是字在语义空间中的位置关系,空间中的余弦距离象征着对应字间的语义相似度。本方案采用word2vec的文本向量训练方式,通过引入大量的医学文本(医学教科书,临床指南,电子病历等)进行字向量的训练,生成高维的字向量,以反应字在语义向量空间中的相对位置关系。最终生成的字向量矩阵l为n×m维矩阵,其中n代表字典中的字数,m代表每个字向量的维数,通常m在100到300之间取值。
本发明由于基于长短时记忆网络的字标注任务,输出层为每个字概率最大的标签类别,最后拼接在一起,忽略了句子整体信息,往往会出现不少错误或不合理的标签。为了对其进行修正,本方案进一步采用条件随机场来计算标注序列的联合概率,使用维特比算法寻找联合概率最大的状态序列。条件随机场着眼于整个序列的优化,直指标注任务的最终目标,如此可以修正长短时记忆网络输出的部分错误或不合理的标签,提高术语自动识别的准确率。最终,上述系统在验证数据集上取得了89%的准确率。
以上所述仅是本发明的优选实施方式,并不用于限制本发明,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变型,这些改进和变型也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!