一种建立明挖基坑工程勘察与模拟参数关系的方法与流程
本发明属于土木工程技术领域,尤其涉及一种建立明挖基坑工程勘察与模拟参数关系的方法,用于明挖基坑工程开挖过程中由勘察参数得到贴近实际工况的模拟参数,进而对实际工程进行较为精准的数值计算。
背景技术:
随着现代科学技术的发展,计算机数值模拟在各行各业正在发挥着越来越大的作用。在岩土工程领域,随着大型土工构造物、超高层建筑以及地下采矿、跨海隧道、城市轨道交通等地下工程等的大量兴建,使得数值模拟技术在岩土工程中的应用得到不断发展,岩土工程数值模拟在工程勘察、设计、施工过程中发挥越来越大的作用,而基坑工程数值模拟是其重要的组成部分。
数值模拟计算结果的可信程度以及工程设计、施工方案的安全性主要取决于数值计算和模拟过程中岩土体参数的可靠程度。由于岩土体在形成过程中,矿物成分、土层深度、应力历史、含水量和密度等因素千变万化,各点处岩土体的性质可能有较大差别。目前在岩土工程设计中所需的岩土力学参数,通常是从试验数据以统计分析并参考经验数据而定,带有一定的任意性。作为抽样的试验数据具有随机的不确定性特征,变化范围较大。当勘察作业不能提供正确、合理的岩土体参数时,就会给工程设计、施工安全带来不确定性,容易导致工程事故的发生。
在第10届全国岩土力学数值与解析方法讨论会上,浙江大学龚晓南教授发起的一项关于岩土工程数值分析的调查,调查对象为分布在全国各地的从事岩土工程研究和工程应用的各类人员,具有一定的权威性。龚晓南教授对调查结果进行了分类统计。由调查结果可以看出,参与调查的岩土工程的研究和工程技术人员普遍认为数值模拟技术在岩土工程中占有越来越重要的地位,比例超过90%。与此同时,数值分析用于岩土工程问题时,参数测定与本构模型获得了极高的重视,是影响数值分析结果可靠性的重要因素,数值分析方法包含数值算法、本构关系研究和选择、参数测定、初始和边界条件的确定以及分析技巧等多方面内容,在参与调查的研究和工程技术人员中,参数测定为114人次,占据了43.02%最高比例。鉴于当前数值分析的精度还有欠缺,针对如何进一步提高岩土数值分析能力需要解决的关键问题的调查显示,有112人次认为本构模型参数测定是最关键的问题,占据49.56%,远高于其他因素,由此可见参数确定在岩土工程数值模拟分析中的重要性。
由于岩土介质性质的复杂性,直接由勘察和试验获得的参数往往包含很多人为和其他误差因素,使得直接用于计算分析难以得到与实际符合较好的结果。在这种背景下,反分析方法应运而生。反分析即以现场监测的数据如位移、应变、应力或荷载等信息,通过建立反演模型,反算得到该系统的一些初始参数,如地层初始应力、本构模型参数等的方法。反分析的目的是建立一个更接近现场实测结果的理论预测模型,以便能较正确地反映或预测岩土结构的某些力学行为。
目前,随着科技手段的不断进步,勘察和试验技术以及反分析算法均得到一定程度的发展,勘察获取参数的精度不断提高,反分析数值算法也被相继提出和改进。然而,通过以上两种手段获取勘察与模拟参数之间关系的研究却常常被疏忽,而这两种参数之间关系的建立可以提高基坑工程岩土工程问题数值模拟参数的取值能力;降低岩土工程建模分析参数选取复杂度,缩短调参时间,提高数值模拟计算精度和可靠性,更有效地为基坑设计提供评估、校核;模拟施工过程,事先对施工可能产生的岩土问题进行预测、评估和预警,提前采取有效措施,有效降低(地铁)事故发生的概率等。
技术实现要素:
本发明目的在于提供一种利用数值计算、遗传算法优化的bp神经网络,由实际监测结果数据反演得到贴近实际工况的数值模型的计算参数,然后再次利用遗传算法优化的bp神经网络建立勘察参数与模拟参数之间关系的方法,由工程的勘察参数可得到贴近实际工况的模拟参数,进而得到与实际相符的数值计算结果。
为实现上述目的,本发明采用如下的技术方案:
一种建立明挖基坑工程勘察与模拟参数关系的方法包括以下步骤:
步骤1、采集基坑工程的监测数据,根据其变化规律对其进行拟合,作为反演计算的基础数据;
步骤2、建立标准的数值计算模型,选取合适的土体本构模型;提取土层的原始勘察参数,以此转换为数值计算的初始土体计算参数;以初始土体计算参数为基础,扩展为数值计算的样本参数和测试样本参数;将样本参数和测试样本参数分别进行数值计算;
步骤3、将样本参数和数值计算结果代入遗传算法优化的bp神经网络进行训练,建立土体参数和数值计算结果之间的映射关系,并用测试样本参数来测试神经网络模型;将实际监测数据代入土体参数和计算结果的关系求得实测位移对应的土体参数;对多个基坑工程案例分别进行计算,将多个基坑工程案例的勘察参数与反演得到的实测位移对应的模拟的土体参数代入遗传算法优化的bp神经网络,建立明挖基坑工程勘察与模拟参数的关系。
作为优选,步骤1中的监测数据包括:桩顶沉降、地表沉降、桩顶水平位移、桩体水平位移。
作为优选,步骤1中的原始勘察参数包括:粘聚力、内摩擦角、压缩模量、泊松比、天然密度、天然含水量、比重、孔隙比、液限、塑性指数、压缩指数、回弹指数。
作为优选,步骤3具体包括以下步骤:
步骤3.1:将步骤2得到的计算结果代入神经网络模型,将土体样本参数(nai…nfi)作为输入层,其对应的模拟计算结果(sai…sfi)作为输出层,隐含层节点数可取
步骤3.2:将测试样本参数(nai…nfi)代入步骤3.1建立的土体样本参数和模拟计算结果之间的映射关系,运行步骤3.1保存的神经网络模型进行计算,得出测试样本对应的神经网络计算结果(lai…lfi),对比分析测试样本参数(nai…nfi)对应的数值模拟计算结果(sai…sfi)和神经网络计算结果(lai…lfi)的误差,满足要求,则进行下一步骤;
步骤3.3:将实际监测数据(sa1…sf1)代入步骤3.1建立神经网络模型,运行并进行计算,进而得出由实测数据对应的模拟的土体参数(ma1…mf1),每个明挖基坑工程均按照上述流程分别进行计算。所有基坑工程案例的勘察参数为(ai…fi),由实测数据按照上述步骤反演计算得到的模拟的土体参数(mai…mfi);
步骤3.4:将勘察参数(ai…fi)作为神经网络的输入层,由实测数据反演计算得到的模拟的土体参数(mai…mfi)作为神经网络的输出层,按照步骤3.1设置神经网络和遗传算法的相关计算参数,运行神经网络模型进行计算,进而得出明挖基坑工程勘察与模拟参数之间的映射的关系。
有益效果
本发明有效的利用数值计算、遗传算法优化的bp神经网络及实际监测、勘察数据,建立勘察与模拟参数之间的关系,以此提高基坑工程岩土工程问题数值模拟参数的取值能力;降低岩土工程建模分析参数选取复杂度,缩短调参时间,提高数值模拟计算精度和可靠性,更有效地为基坑设计提供评估、校核;模拟施工过程,事先对施工可能产生的岩土问题进行预测、评估和预警,提前采取有效措施,有效降低(地铁)事故发生的概率等。
附图说明:
图1各种本构模型在基坑数值开挖分析中适用性的示意图;
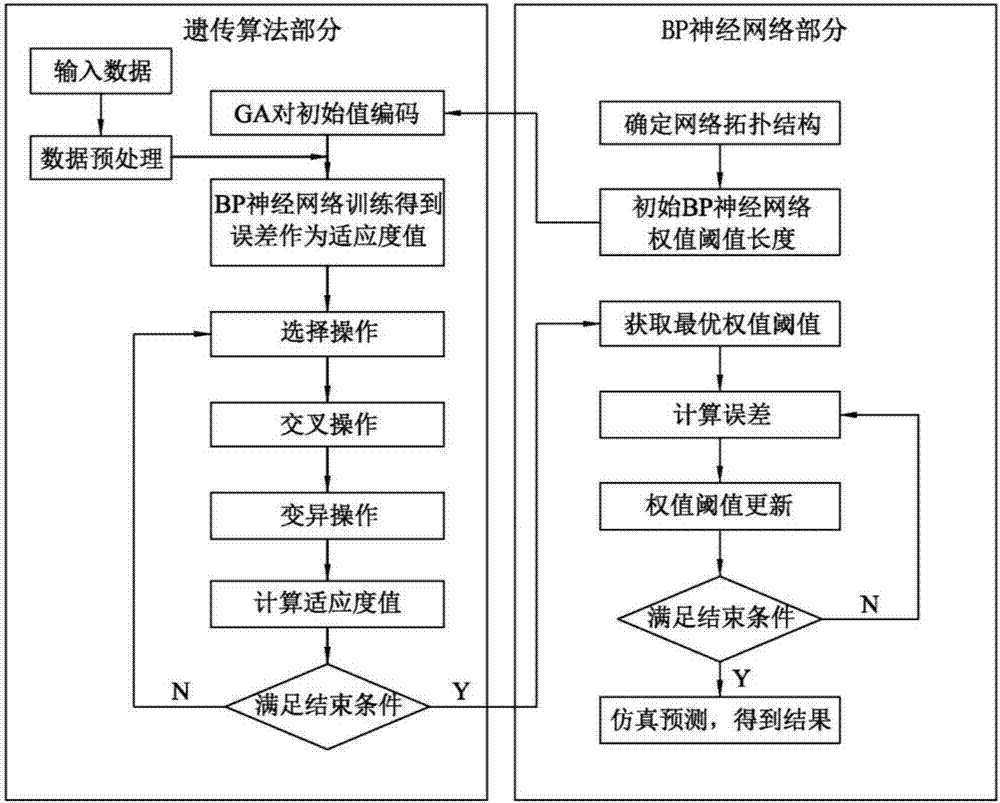
图2遗传算法优化bp神经网络流程图;
图3本发明方法流程图。
具体实施方法:
如图3所示,本发明提供一种建立明挖基坑工程勘察与模拟参数关系的方法,包括以下步骤:
1)工程案例的选取,其控制条件包括:
1.1)所需工程案例须包含勘察、设计、第三方监测等资料且资料数据完整
数值计算模型的建立需要勘察报告中土层资料,因此勘察参数作为所有资料的数据基础之一是必须完整齐全的;数值计算模型的建立除需要知道勘察报告中的土层参数外,还需要知道基坑的设计资料,如基坑平面设计图、剖面图、开挖流程及支护结构参数等,以便建立的模型更加精确,开挖工况更加符合现场实际工况,计算的结果更加逼近监测的数据;第三方监测资料必须完整,主要是因为参数反演主要依靠实际监测的数据来反演得到更加逼近实际状况的土体参数,除此之外,依据第三方监测点平面布置图,在数值计算中设置相对应的监测点,使数值计算的位移量与实际监测的位移量具有相对应的空间位置坐标,使整个流程具有可反演性。
1.2)工程项目均须包含同类别的岩土体
不同土体的模型参数差异性较大,因此需建立同类土体的勘察与模拟参数之间的关系,这就要求所需工程案例必须同时含有同类别的岩土体。
1.3)工程项目所在地点须为同一地区区域
不同地区的同种类的土体物理力学性质也存在一定的差异性,因此要求所需的工程案例须为同一地区。
2)基坑监测数据的处理,包括:
2.1)误差分析
在诸如基坑开挖等岩土工程的施工过程中,位移等监测数据通常包含多种因素的影响,得到的位移量测值存在着误差,在利用位移数据进行反分析之前需对其进行数据处理。
根据如位移等测量要素产生的原因和性质,可以讲误差分为系统误差、随机误差和过失误差三类:系统误差、随机误差及过失误差。
a)系统误差
系统误差是由于某些固定的原因造成的,其特点是在整个测量过程中始终有规律的存在着,其绝对值和符号保持不变或者有规律的变化着,主要来源于以下几个方面:方法误差、工具误差、环境误差、操作误差及主观误差。
系统误差可以通过查找相关原因,总结变化规律,在测量中采取相应措施以减小误差,或在数据处理时对测量结果进行修正。
b)随机误差
随机误差由一些随机的偶然因素造成。如果进行大量的测量,会符合一定的统计规律,一般认为服从正太分布。产生随机误差的原因有测量仪器、测量方法和环境条件等方面,如电源电压的波动、环境温度、湿度和气压的微小波动,磁场干扰、仪器的微小变化、操作人员操作上的微小差别等。随机误差在测量中是无法避免的。在实际试验中,往往很难区分随机误差和系统误差,因此许多误差都是这两类误差的组合。
c)过失误差
过失误差是由于试验人员粗心大意,不按操作规程办事等原因造成的误差,如读错仪表刻度、记录和计算错误。过失误差一般数值较大,并且常与实事明显不符。
除此之外,当使用监测数据与基坑工程数值模拟相结合进行参数反演时,如果选取的本构关系不能完全体现岩土介质变形的本质特征,也将导致计算结果与基坑工程实际变形值存在差异,我们暂且将其称之为“本质误差”;另外数值模型也会对实际工程做诸多简化,同样会使数值模拟结果与实际变形值存在差异。
2.2)监测数据分析
由于监测周报没有记录详细的基坑开挖进度,即没有明确体现基坑开挖深度与监测数据的对应关系,因此需要对原始的监测数据进行细致的分析,综合考虑多种因素,整理出可用于数值模拟参数反演的、对应不同开挖深度的监测数据信息。
监测数据处理:由于基坑面积大,施工期限长,跨越秋冬春夏,中间经历了停工、天气变化等诸多因素的影响(经历冻胀以及数次暴雨),都会对基坑变形产生显著的影响。此外,由于检测仪器本身以及人为原因对监测数据带来的影响也不可忽视。与此同时,对基坑工程进行数值模拟仅考虑了影响基坑变形的本质原因,包括基坑工程所处的工程地质条件、水文地质条件、基坑形态、支护结构设计、开挖过程等;根据数值计算过程中选择的本构关系模型,通常还会忽略蠕变、温度变化等对基坑变形产生的影响。因此,基坑监测数据需要进行预处理,不能直接用于数值模拟反演分析。如何合理的处理监测数据,摒除外部影响因素,获取反映基坑施工过程本质变形规律的数据信息,是需要认真分析的问题。
2.3)监测数据处理
实测数据受到现场施工环境、施工工序、仪器精度、天气变化、人为干扰等众多因素的影响,而模拟却是在理想的环境下进行,两者结算的结果难免会产生误差,为尽量控制误差,需要对监测数据进行对比和筛选,剔除一些奇异点,条件满足的,可对实测数据进行拟合,得到较为合理的实测数据。
3)建立标准的数值计算模型,要满足以下标准化要求:
3.1)数值模型的建立
建立的模型为工程实体的局部部位,在建立数值模型之间,需对监测的数据进行归纳总结,选择监测类型较多、较全、较完成的部位,同时选择建模部位的周边环境较为简单、实体形状简单、规则,便于建模,条件满足的话,最好建立完整的数值计算模型。
模型的尺寸取基坑深度的3~5倍,模型底部为固定边界,分别约束其x、y、z方向位移;模型顶部为自由面,不设置约束;模型在两个水平方向上分别约束该水平方向的位移。
建立的模型网格划分也有一定要求,疏密需划分妥当,建模的过程中采用了结构单元,结构单元处的网格需划分较密集一些,因为一个单元体当中至多有一个结构单元节点。同时建模时在开挖步和基坑底等关键部位,应设置界面,防止开挖不到位对计算结果产生一定的影响。
基坑案例的支护结构中均包含钻孔灌注桩,而钻孔灌注桩的受力形式与地下连续墙相近,通过抗弯刚度相等的原则,将钻孔灌注桩围护结构这算成一定厚度的地下连续墙,等效的公式如式1。
式中:h为等效地连墙厚度,d为钻孔灌注桩直径,t为桩的净距。
地连墙采用实体单元,地连墙与土体之间设置接触面。
3.2)本构模型的类别
常用的本构模型分为3大类,弹性类模型、弹-理想塑性类模型和应变硬化类的弹塑性模型。弹性模型由于不能反映土体的塑性性质、不能较好地模拟主动土压力和被动土压力因而不适合于基坑开挖的分析。弹-理想塑性的mc模型和dp模型由于采用单一刚度往往导致很大的坑底回弹,难以同时给出合理的墙体变形和墙后土体变形。能考虑软粘土应变硬化特征、能区分加荷和卸荷的区别且其刚度依赖于应力历史和应力路径的硬化类模型如mcc模型和hs模型,能同时给出较为合理的墙体变形及墙后土体变形情况。敏感环境下的基坑工程设计需重点关心墙后土体的变形情况,从满足工程需要和方便实用的角度出发,建议采用mcc和hs模型进行敏感环境下的基坑开挖数值分析。根据模型本身的特点,可以大致判断各种本构模型在基坑数值开挖分析中的适用性,详见图1。
3.3)本构模型的选取及其参数初值的确定
依据步骤2.2),主要采用修正剑桥模型(mcc模型),砂卵石采用摩尔库伦模型(mc模型)。修正剑桥模型需4个模型参数,即v-lnp'平面中正常固结线的斜率λ,v-lnp'平面中回弹线的斜率κ、p'-q'面上csl线的斜率m、泊松比v(或剪切模量g)。其中λ和κ可根据固结实验分别由式2和式3求得。
式中cc和cs分别为土的压缩指数和回弹指数。m可根据三轴压缩试验由式4得到。
式中
此外修正剑桥模型尚需2个状态参数,即初始孔隙比e0和前期固结压力p0。
摩尔库伦模型的主要参数为:天然重度γ、粘聚力c、内摩擦角
3.4)样本参数的生成
得到初始参数以后,进行初始的数值计算,并与实测结果对比。确定需要反演的土层以及反演的土体参数,然后在计算参数的基础上,以一定的倍数扩充参数(扩充的参数的计算结果应能包含实际监测的结果),再将反演土层的扩充参数进行排列组合,形成样本参数,最后将样本的参数代入计算模型,分别进行计算,计算完成后将样本参数的计算结果进行整理。除此之外还需随机选取几组位于样本参数之间的测试参数(用于测试神经网络模型),进行数值计算并整理其结果。
4)建立参数反演模型,进行反演计算,包括:
4.1)参数反演计算的限定条件
参数反演的计算手段采用的是遗传算法优化的bp神经网络(其算法流程详见图2),采用此反演模型对样本有一定的要求:a)实测数据的种类数量须不小于土体反演参数的种类数量;b)样本参数计算的结果须能覆盖实测的数据。因此在样本生成的过程中,反演的参数要选取合理,满足参数反演体系的要求,否则计算结果会产生较大误差。
4.2)参数反演的计算流程主要包括:
a)输入、输出层的设计
将步骤2.4)的数值计算结果代入神经网络模型,将土体参数作为输入层,由土体参数得到的数值计算结果作为输出层。
b)隐含层数的确定
隐层节点数的确定没有明确的解析式表示,需根据实践经验确定。因为不是越大越好,也不是越小越好,因此需要选取一个适中的数目。对于单隐层网络,实际应用中,上界为训练样本数,下界为输出单元数。如果采用金字塔法则,即如果只有一层隐层网络,则隐层节点数可取
c)训练样本的归一化
归一化采用matlab中自带函数mapminmax,此函数归一化的形式是用一组中最大值减去最小值作为分母,把要归一化的数减去最小值作为分子,即可得到该数归一化的值。数据的归一化处理是把所有数据都转化为[0,1]之间的数,其目的是取消各维数据间数量级差别,避免因为输入输出数据数量级差别较大而造成网络预测误差较大。
d)初步建立神经网络
采用matlab中的newff函数工具箱初步建立bp神经网络,具体形式如下:
net=newff(a,b,hiddennum);
a表示数值模拟计算结果归一化后的输入样本;
b表示数值模拟土体参数归一化后的输出样本;
hiddennum表示隐含层节点数。
e)遗传算法参数初始化
对遗传算法中含有的参数进行初始化,参数包括:迭代次数、种群规模(染色体个数)、交叉概率、变异概率。在遗传算法优化神经网络问题中,染色体就是由神经网络的权值和阈值组成的。
f)种群初始化
将种群中各染色体初始化,即将每组权值和阈值赋予初始值,方法采用matlab中的rands函数进行初始化。
g)染色体适应度函数的计算
根据个体得到bp神经网络的初始权值和阈值,用训练数据训练bp神经网络后预测系统输出,把预测输出和期望输出之间的误差绝对值和e作为个体适应度值f,计算公式见式5。
式中:n为网络输出节点数;yi为bp神经网络第i个节点的期望输出;oi为第i个节点的预测输出;k为系数。
把每组初始化的染色体(权值和阈值)赋予初步建立的网络(net),将归一化后的数值模拟计算结果作为输入样本和归一化后的土体参数作为输出样本进行网络的训练,并进行测试,把测试的系统误差作为对应染色体(权值和阈值)的适应度函数值,由于误差越小越好,所以系统误差最小的染色体(权值和阈值)为此代种群中最优个体。记录适应度函数最优的个体及其适应度函数。
h)染色体选择
采用轮盘读法对染色体进行选择,即基于适应度比例的选择策略,每个个体i的选择概率pi见式6。
式中:fi为个体i的适应度值,由于适应度值越小越好,所以在个体选择前对适应度值求倒数;k为系数;n为种群个体数目。
i)染色体交叉
由于个体采用实数编码,所以交叉操作方法采用实数交叉法,第k个染色体ak和第l个染色体al在j位的交叉操作方法见式7。
式中:b是[0,1]间的随机数。
j)染色体变异
选取第i个个体的第j个基因aij进行变异,变异操作方法见式8。
式中:amax为基因aij的上界;amin为基因aij的下界;f(g)=r2(1-g/gmax)2;r2为一个随机数;g为当前迭代次数;gmax为最大进化次数;r为[0,1]间的随机数。
k)更新染色体适应度值
再次计算新一代染色体的适应度函数值,方法与第(g)步一样。把每个新生代的染色体的适应度值与上代中最优的个体进行比较,更新最优个体及其适应度值。然后循环迭代,直至达到设定的迭代次数。
l)将最优染色体赋予神经网络进行神经网络训练
最终把最优染色体(权值、阈值)作为神经网络的初始权值阈值赋予神经网络,并将归一化后的数值模拟的计算结果作为输入样本和归一化后的模拟土体的参数作为输出样本进行网络的训练,进而建立数值模拟计算的数据结果与数值模拟土体参数之间的映射关系。
m)测试神经网络模型
将步骤2.4)中的测试参数代入步骤l)建立的神经网络模型进行网络测试,计算出每个测试样本中每个输出变量的误差值。若训练结果不满足要求,则再次调整遗传算法参数,重新进行网络权值阈值的优化直至满足误差要求。
n)计算参数反演
将实际监测数据进行归一化处理,将归一化后的实测数据代入步骤l)建立的神经网络模型,反演得到实测位移对应的模拟土体参数。
5)建立勘察与模拟参数之间关系:
将多个基坑工程按照上述步骤分别进行计算得到由实测位移对应的模拟土体参数,然后再将不同基坑工程的勘察参数作为输入层,反演得到的模拟土体参数作为输出层,代入神经网络进行训练,进而得到勘察与模拟参数之间的映射关系,并找一工程案例进行验证。
实施例1:
基于本发明的建立明挖基坑工程勘察与模拟参数关系方法的具体实施例包括以下步骤:
步骤1:根据监测平面图,提取各个监测点的监测数据(桩顶沉降、地表沉降、桩顶水平位移等)(sa1…sf1),以及勘察参数(a1…f1),对监测数据进行分析,剔除一些奇异点,然后采用拟合等方法对监测数据进行处理,提取关键点的监测数据(sa2…sf2)。
根据支护形式的不同,桩体水平位移的呈现形式也不一样,如桩体水平位移呈现“杯口”型,可将实测数据拟合为指数函数,然后取其桩顶部位的监测数据;如果实测数据呈现“凸肚”型,可拟合为正太分布函数,取其最大位移部位的监测数据;具体拟合为何种函数,还需根据基坑工程的工程特点及监测数据的变化规律动态调整和取值。
步骤2:根据步骤1的监测平面图和监测数据,选择周边环境相对简单、监测种类相对较多、监测数据相对完整、基坑形状较为简单的部位,根据基坑的实际地层条件,基于flac3d5.0数值软件以基坑深度的3~5倍建立标准的基坑开挖模型,并设置其边界条件。
步骤3:由勘察相关参数或经验得出模拟初始参数(na2…nf2)(包括粘聚力、内摩擦角、压缩模量、泊松比、天然重度、正常固结线的斜率λ,弹性膨胀线斜率κ、摩擦常数m、初始孔隙比e0和前期固结压力p0)并进行计算,根据计算结果,围绕模拟初始参数(na2…nf2)乘以一定的系数得出多组样本参数(nai…nfi),然后将样本参数分别代入数值模型进行计算,得出其计算结果(sai…sfi)。在样本参数之间随机选取几组测试样本参数(nai…nfi),并分别进行数值计算,得出其计算结果(sai…sfi)。
flac3d数值计算,由于需要计算多组样本(重复计算,模型不变,只修改土体参数),因此需编写批处理的命令文件“.txt”,并保存不同样本参数的计算结果“.sav”格式文件(其命名须进行修改,否则将被覆盖),为方便后续处理,将需要的计算结果输出为“.xls”excel表格格式文件,将以上文件放在同一个文件内并进行命名。
本发明参数反演计算采用的是遗传算法优化的bp神经网络,程序代码是基于matlab自带人工神经网络工具箱进行编写的“.m”格式文件,输入和输出变量等数据信息保存为“.mat”格式文件。因此如果要在没有安装matlab软件的计算机上执行命令,首先需要将matlab软件安装在计算机上,运行神经网络的过程中需要在matlab中打开“.m”文件,调用“.mat”文件中的数据,运行计算并保存网络,网络信息保存在“.m”文件中。
步骤4:将步骤3得到的计算结果代入神经网络模型,将土体样本参数(nai…nfi)作为输入层,其对应的模拟计算结果(sai…sfi)作为输出层,隐含层节点数可取
步骤5:将测试样本参数(nai…nfi)代入步骤4建立的土体样本参数和模拟计算结果之间的映射关系,运行步骤4保存的神经网络模型进行计算,得出测试样本对应的神经网络计算结果(lai…lfi),对比分析测试样本参数(nai…nfi)对应的数值模拟计算结果(sai…sfi)和神经网络计算结果(lai…lfi)的误差,满足要求,则进行下一步骤。
步骤6:将实际监测数据(sa1…sf1)代入步骤4建立神经网络模型,运行并进行计算,进而得出由实测数据对应的模拟的土体参数(ma1…mf1),每个明挖基坑工程均按照上述流程分别进行计算。所有基坑工程案例的勘察参数为(ai…fi),由实测数据按照上述步骤反演计算得到的模拟的土体参数(mai…mfi)
步骤7:将勘察参数(ai…fi)作为神经网络的输入层,由实测数据反演计算得到的模拟的土体参数(mai…mfi)作为神经网络的输出层,按照步骤4设置神经网络和遗传算法的相关计算参数,运行神经网络模型进行计算,进而得出明挖基坑工程勘察与模拟参数之间的映射的关系。
步骤8:用一新的明挖基坑工程案例,并提取该基坑工程案例的勘察参数,代入到步骤7所建立的明挖基坑工程勘察与模拟参数关系的神经网络模型中进行计算,得出其对应的模拟的土体参数,然后建立新基坑工程的数值模型,并将得出的模拟的土体参数代入数值模型中进行计算,将其计算结果和实测结果进行对比,分析其误差是否满足要求。如不满要求,则采用修正数值模型、采用更高级的本构模型、修正神经网络参数等的方法,再次按照上述步骤2到步骤7的流程进行计算直至满足要求。
后续如果再有新的基坑工程案例,可按照上述步骤1到步骤8的流程再次进行计算,不断修正所建立的明挖基坑工程勘察与模拟参数之间的关系。
- 还没有人留言评论。精彩留言会获得点赞!