一种基于小波分析和半监督学习的车联网油耗数据质量评估方法与流程
本发明方法涉及车联网数据采集和数据质量控制领域,尤其涉及一种用于车联网背景下车辆油耗数据质量评估的方法。
背景技术:
随着车联网技术的发展和数据挖掘技术的愈发成熟,车联网的海量数据已经在商业,路网的设计规划等领域体现出巨大的潜在价值。这些海量数据的传输和存储方案、知识挖掘,数据质量的控制都是亟待研究和解决的问题。由于油位传感器和现有的车联网数据终端的局限性,相对于误差较为稳定、精准的gps定位数据、车辆速度等数据,车辆的油位数据包含着大量噪声和各种异常变化如加油漏油、传感器故障、网络传输问题等等。因此,对这些油耗数据进行有效准确的分类亦即数据质量评估,对相关业界的车辆状态监测、行车数据统计分析、车辆运营管理等等都具有重要意义。
现有的针对油耗数据的质量控制方法中,一种是根据历史经验人工地给油位的变化量等参数设定阈值,超出阈值的则视为噪声数据。这种方法简单粗暴,只能粗略地过滤一些噪声信息,但难以适用于传感器和网络设备的故障所导致的数据异常,难以更细化、准确地评估数据质量状态。
另一种方法是利用决策树、贝叶斯网络等分类方法对数据进行分类,但是所利用的决策属性仍然限于油位变化值、方差均值等统计参数,分类的准确性有限。并且,由于这些分类算法属于机器学习中的有监督学习,需要大量的带标签训练样本,因此只能利用已有的经过人工分类的数据样本进行训练,在准确性、快速性和数据标签获取成本上都存在不足。
综上,针对车联网背景下的油耗数据质量问题,需要一种准确高效,能适应多种数据异常问题,并且计算和存储的负荷较低的数据质量评估方法。
技术实现要素:
本发明的目的是为了解决上述问题,提出一种基于小波分析和半监督学习的车联网油耗数据质量评估方法,利用小波分析方法得到针对油耗数据的相关属性特征,再利用半监督学习的方法进行分类,得到油耗数据的类别标签,以实现高效、准确且轻量级的数据质量评估方法。
本发明方法所提出基于小波分析和半监督学习的油耗数据质量评估方法,包括以下步骤:
步骤一:对数据进行预处理。
车联网背景下所获得的信息通常至少包括gps坐标、速度、油位、时间等数据,定义:i个油位数据的时间序列为a(a1,a2,...,ai),对应的时间为ti,油位变化值序列q={qi|qi=ai+1-ai},同样有速度s(s1,s2,...,si);
计算速度值的可信度ε、油位变化q的均值
其中:ε为无量纲的系数,si,stri分别为第i个采样点的速度和行程区间速度。
步骤二:小波分析。将油位数据序列a进行k阶dwt计算(discretewavelettransform,离散小波变换),得到k阶近似成分ak和k个不同尺度下的细节成分d1,d2,...,dk。在合适的分解尺度下,ak作为压缩去噪之后的数据序列,近似于原本的序列趋势,dk包含不同频率上的波动和异常信息。阶数k和小波基的类型(haar,db,db2等等)需根据数据的采样频率、噪声类型来确定。之后对分解出的各层信号计算均值、方差、模最大值等统计参量作为特征属性。
步骤三:随机选取一定数量的样本由人工经验初步标注类别标签(label)。这其中:
出于细化分类的需求和实际分类方法的考虑,将数据质量的类别标签定义为l={1,2,3,4},即分为4类:
类别l1:质量好,准确且噪声较小;
类别l2:质量较好,有部分噪声值和异常序列但可以修正过滤;
类别l3:质量较差,有较多噪声和异常序列,难以用数值方法修正;
类别l4:质量很差,数据缺失或者硬件故障导致的大量噪声和异常,没有修复和统计价值。
步骤四:基于支持向量机的多分类器学习。基于支持向量机分类算法(supportvectormachine,svm),构建二叉树svm模型进行多分类任务。将步骤一、二中计算得到的统计参量作为特征属性;以带类别标签l={1,2,3,4}的l个数据样本作为训练样本xl={x1,x2,...,xl}进行初始的svm分类器训练。
设单个训练样本包含i维特征属性,类别属性为y,y∈{l|l={1,2,3,4}},即x=(x1,x2,...,xi,y),wi为第i个特征的权重,权重
步骤五:加入无标签的数据样本xul,利用局部搜索策略进行半监督学习,更新分类器。所得的支持向量机即可对输入的数据样本进行有效的分类数据评估,且随着新样本的增加可以继续更新参数。
本发明的优点在于:
(1)利用了小波分解的信号特点来构建油耗数据的属性特征,具有针对性且能有效地提高分类准确性和结论的可靠性;
(2)多层小波分解得到的近似成分可以作为对数据有效的压缩过滤,细节成分能用于异常状况分析,为数据质量的类别划分提供可信的依据;
(3)使用的分类算法基于支持向量机,使用的特征属性都是统计参量,有效降低了特征维数和运算量,符合车联网下大数据量和移动运算的需求;
(4)考虑速度数据的可信度和相关属性的重要度,在二叉树支持向量机的基础上加入了适用于实施例的权值,能有效地提高分类的准确性和合理性。
附图说明
图1是本发明一个实施例的数据质量评估方法的流程图。
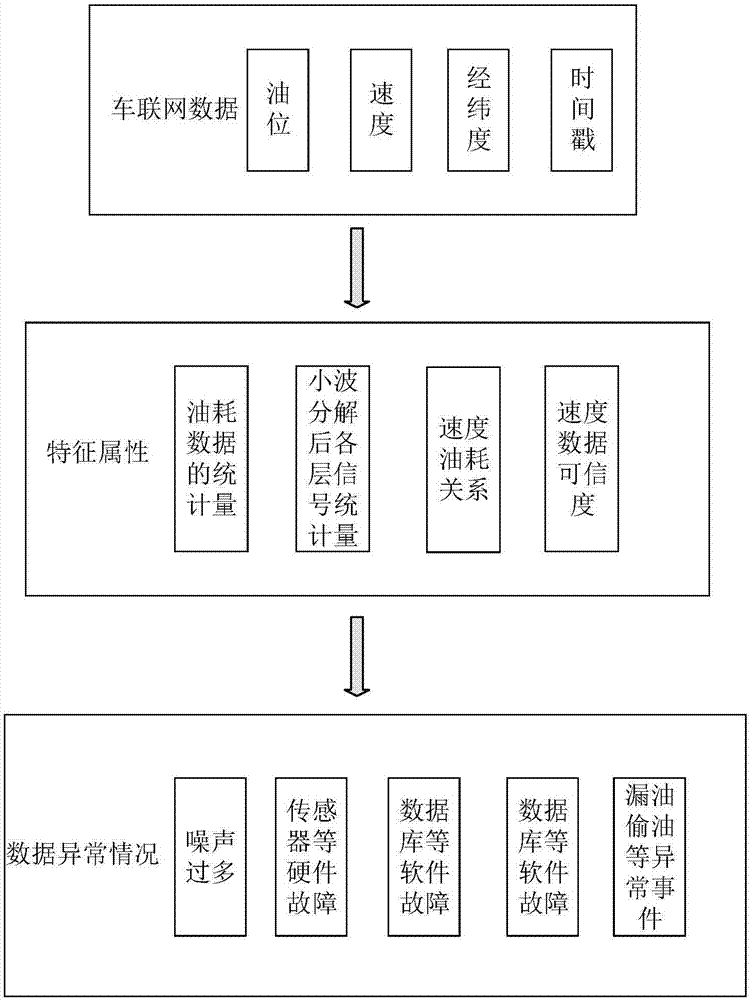
图2是本发明一个实施例中数据特征属性和异常情况的示意图。
图3是本发明一个实施例中小波变换的数据示例图。
具体实施方式
下面将结合附图和实施例对本发明作进一步的详细说明。
附图1,2,3描述本发明方法的车联网油耗数据质量评估方法,其中图1是本实施例的流程图。
由于车联网背景下所获得的信息通常至少包括gps坐标、速度、油位、时间等数据,本发明方法中定义:
i个油位数据的时间序列为a(a1,a2,...,ai),对应的时间为ti,油位变化值序列q={qi|qi=ai+1-ai},同样有速度si,油位变化均值
结合附图2,出于细化分类的需求和实际分类方法的考虑,将数据质量的类别标签定义为l={1,2,3,4},即分为4类:
类别l1:质量好,准确且噪声较小;
类别l2:质量较好,有部分噪声值和异常序列但可以修正过滤;
类别l3:质量较差,有较多噪声和异常序列,难以用数值方法修正;
类别l4:质量很差,数据缺失或者硬件故障导致的大量噪声和异常,没有修复和统计价值。
步骤s01:对数据进行预处理。包括计算速度值的可信度、油位变化均值、油耗离散系数、油耗-速度相关系数等相关统计参数,这其中:
由经纬度可计算得到行程区间速度str,用于计算速度值的可信度,该值用于后面的svm分类模型中的权重计算:
步骤s02:小波分析。结合附图3所示,将油位序列a进行k阶dwt计算(discretewavelettransform,离散小波变换),得到k阶近似成分ak和k个不同尺度下的细节成分d1,d2,...,dk:
a=ak+d1+d2+...+dk
在合适的分解尺度下,ak作为压缩去噪之后的数据序列,近似于原本的序列趋势,dk包含不同频率上的波动和异常信息。阶数k和小波基的类型(haar,db,db2等等)需根据数据的采样频率、噪声类型来确定。本实施例中根据采样频率和实验结果,取k=3,由于haar小波基形式较为简单,运算速度最快,小波变换函数以haar小波为例进行说明,其中x′i为近似信号成分,di为细节成分:
再对分解出的各层信号计算均值、方差、模最大值统计参量作为特征属性,得到
步骤s03:随机选取一定数量的样本由人工经验初步标注类别标签l={1,2,3,4},即下面的训练集xl中得属性y。
步骤s04:基于支持向量机的多分类器学习。基于二叉树支持向量机(bt-svm)进行多分类,。将步骤一、二中计算得到的统计参量作为特征属性;以带类别标签label的数据作为训练样本xl={x1,x2,...,xl}进行有监督的svm分类器训练。
设单个训练样本包含i维特征属性,类别属性为y(y由上面的定义和步骤s102所给出),即x=(wixi,y),wi为第i个特征的权重,其中特征属性xi由步骤s101,s102,s103所给出,权重
由于原始的支持向量机是针对二分类问题的,应用于多分类问题通常采用的策略是将多类问题分解为一系列svm可直接求解的二分类问题,基于这一系列svm求解结果得出最终判别结果。本实施例中根据实际需求采用二叉树支持向量机(bt-svm),所采用的树结构为完全二叉树,即:顶层svm先分为类l1l2与l3l4,第二层再将两类分别划分。完全二叉树分类时所需要的分类器数目最少,因此其速度也是较快的。采用的核函数为rbf:
步骤s05:加入无标签的数据样本xul,利用局部搜索策略进行迭代学习。半监督学习下的svm采用局部搜索策略,给定有标记样本集xl={(x1,y1),...,(xl,yl)}与无标记样本集xul={(xl+1,yl+1),...,(xl+u,yl+u)},其中y∈{-1,+1},l+u=m,其目标函数如下形式:
s.t.yi(ωtxi+b)≥1-ξi,i=1,2,...,m
ξi≥0,i=1,2,...,m
其中(ω,b)代表超平面,ξ为松弛变量,cl,cul是用于平衡有标记与无标记样本重要程度的参数。之后加入无标签的数据样本xul,利用局部搜索策略进行迭代学习。所迭代更新后的分类器即可对输入的数据样本进行有效的数据质量评估,且随着新样本的增加可以继续更新参数,令s04中用xl初步训练得到一个svml,半监督学习的主要步骤如下:
1.用svml对xul中的样本进行分类,得到分类结果集
2.初始化参数,cul<cl
3.基于xl,xul,cl,cul,
4.找出两个被分为不同类且置信概率较低的未标记样本,交换其类别标记,即:对{i,j|(yiyj)<0∧(ξi,ξj>0)∧(ξi+ξj>2)},yi=-yi,yj=-yj。
5.增加cu以提高未标记样本的影响,重复步骤3,4直到cul=cl。
迭代学习完成后即可得到一个svm分类器和对数据样本的分类结果。
综上所述,本发明方法是一种针对车联网油耗数据的质量评估方法,其利用小波分析和多维数据间的关系计算得到有针对性的属性特征;基于多分类支持向量机的方法,采用二叉树svm的结构以适应于数据类别的分布;构建适用于实施例的权重系数;并且基于半监督学习方法,利用未标记的数据集进行分类器训练,构成一个高效、准确、低运算量的数据质量评估方法。
本发明方法具有如下优点和特性:
(1)利用了小波分解的信号特点来构建油耗数据的属性特征,具有针对性且能有效地提高分类准确性和结论的可靠性。
(2)多层小波分解得到的近似成分可以作为对数据有效的压缩过滤,细节成分能用于异常状况分析,为数据质量的类别划分提供可信的依据。
(3)使用的分类算法基于支持向量机,使用的特征属性都是统计参量,有效降低了特征维数和运算量,符合车联网下大数据量和移动运算的需求。
(4)考虑速度数据的可信度和相关属性的重要度,在二叉树支持向量机的基础上加入了适用于实施例的权值,能有效地提高分类的准确性和合理性。
- 还没有人留言评论。精彩留言会获得点赞!