一种弱监督的深度台标检测方法与流程
本发明涉及深度学习领域,尤其涉及一种弱监督的深度台标检测方法。
背景技术:
随着互联网的发展和多媒体技术的兴起,网络视频承载着越来越多的内容,成为大数据时代的一个主要内容载体。不同的视频来源倾向于呈现不同的视频内容信息,通过检测视频台标,能更有效地管理网络视频数据,预先掌握视频来源和内容信息,监管包含不良信息的视频。因此,视频台标检测有着较强的实用意义和研究价值。
台标数据广泛地存在于网络视频中,台标检测是对从网络视频中提取出的若干个关键帧进行检测。台标检测相较于一般物体检测具有特殊性,其检测目标出现在较为固定的位置,且在每一帧中占据着较小的比例。目前大部分用于物体检测的数据集并没有这样的特征,台标检测的数据特殊性需要在检测之前进行大量数据的收集和预处理工作。针对这样具有特殊性的数据对象,如何快速、有效、精准地进行检测是完成台标检测任务的重点。
目前实现台标检测的方法主要有以下几种:
(1)基于模板匹配法
模板匹配是一种直观的方法,它根据一定的相似度准则来判断图像帧局部区域与台标模板之间的相似度,从而判断该区域是否含有台标。模板与需要匹配的区域逐个计算匹配度,所以模板匹配法带来了较大运算量。
(2)基于特征匹配法
提取图像特征以衡量相似度是主流方法之一。矩特征又称为不变矩,具有普通特征不具有的旋转、尺度、平移不变性,故被广泛应用于图像分析领域。sift特征和surf特征也被广泛应用。然而这种人工提取特征的方式并不能带来很好的检测结果。
(3)基于神经网络的方法
基于神经网络的台标识别方法是当今的热门和主流。在检测任务中,利用神经网络提取特征比起手工提取特征有着更好的检测效果。然而对于大部分经典的基于神经网络的检测模型,往往都需要大量的标注,耗费人力和时间。
综上所述,以上台标检测方法均有着各种各样的弊端。因此,研究弱监督的台标检测方法具有重要的研究价值和应用前景。
技术实现要素:
针对目前台标检测方法的不足,本发明提供一种弱监督的深度台标检测方法。该方法能够有效改变目前台标检测方法效率低、结果差的情况,并且大大地节省了标注所需的时间和人力。
针对上述不足,本发明所采用的技术方案为:
一种弱监督的深度台标检测方法,其步骤包括:
1)对海量网络视频数据文件进行预处理,得到一个仅标记台标类别的大数据集和一个仅标记台标位置(groundtruth)的小数据集;
2)按照弱监督的框架组织台标定位网络和台标分类网络,并将上述小数据集输入台标定位网络进行训练,得到能预测台标区域的台标定位网络;
3)将上述大数据集输入上述已训练好的台标定位网络,得到所述大数据集中每张图片的若干预测台标区域,并将所述每张图片的若干预测台标区域输入台标分类网络进行训练,得到能为台标分类的台标分类网络;
4)对待检测视频进行与步骤1)相同的部分预处理,并将预处理后得到的图片输入步骤2)训练好的台标定位网络中,得到图片的预测台标区域;
5)将上述图片的预测台标区域输入步骤3)训练好的台标分类网络中,得到图片的台标位置及台标类别。
进一步地,步骤1)具体包括:
1-1)将海量网络视频数据文件根据md5(message-digest5)码去重;
1-2)使用关键帧提取方法从上述去重后的网络视频中提取若干关键帧;
1-3)对每一个网络视频关键帧进行m宫格分割,仅保留位于角落的m分之一图片,其中m根据台标的大小和位置进行取值;
1-4)对上述所有图片进行分类,得到带有台标的图片;
1-5)使用传统方法对上述带有台标的图片进行数据增强(dataaugmentation);
1-6)将上述数据增强后的带有台标的图片根据台标类别进行均衡分配,得到一个仅标记台标类别的大数据集和一个仅标记台标位置的小数据集。
更进一步地,步骤1-1)中所述md5码去重是指:通过比较md5值判断网络视频数据文件是否重复,对于多个有相同md5值的网络视频只保留一个,其余剔除。
更进一步地,步骤1-3)中对每一个网络视频关键帧进行九宫格分割,仅保留位于四个角落的九分之一图片。
更进一步地,步骤1-4)中使用基于卷积神经网络(cnn)的分类器进行分类,若有n类台标待检测,则分类器进行n+1分类,其中包含一个背景类;步骤1-5)中所述传统方法为但不仅仅限于几何变换、平滑滤波、jpeg压缩、对比度与亮度调整。
更进一步地,步骤4)中所述部分预处理仅包括步骤1)中的1-2)和1-3)。
进一步地,步骤2)中所述台标定位网络是基于rpn(regionproposalnet)的台标定位网络;且步骤2)中使用k-means聚类方法对anchorboxes的大小和长宽比例进行选择;其中所述anchorboxes为台标定位网络在每个定位中心点生成的初始预测边框。
进一步地,步骤2)中将所述小数据集中每张图片输入台标定位网络训练若干轮后,选择最新生成的台标定位网络,得到每个预测台标区域对应的置信度,计算预测台标区域与台标位置的iou(交叠率),将该iou与所述预测台标区域对应的置信度作比较,得到当前状态下的难例,并在之后的若干轮训练中,使用bootstrap(自举法)的难例挖掘方法优先选取难例进入台标定位网络进行训练,重复以上步骤直到台标定位网络收敛,得到能预测台标区域的台标定位网络。
进一步地,步骤3)中所述台标分类网络是基于fastrcnn的台标分类网络。
进一步的,步骤3)中将所述大数据集中每张图片输入已训练好的台标定位网络,得到每张图片的若干预测台标区域,将所述每张图片的若干预测台标区域输入台标分类网络进行训练,得到每个预测台标区域的置信度,根据每个预测台标区域的置信度将所述预测台标区域分为n类前景区域(即n类台标)和背景区域,得到能为台标分类的台标分类网络;其中所述前景区域的类别根据对应的图片上的台标类别标记。
本发明的优点在于:
1)本发明使用了基于卷积神经网络的物体检测方法,这种方法可以通过一个训练好的模型精准且快速地检测一个帧中是否包含了台标数据。
2)由于基于卷积神经网络的物体检测方法通常在pascalvoc和ilsvrc等公开数据集上进行训练和评估,而这些数据集上的目标物体并不具有台标数据的特点。为了提升在台标数据上的检验效果,本发明收集了大量的台标样本数据(即网络视频数据文件),并在模型训练中根据台标样本数据的特征进行了一系列的数据预处理,提高了数据处理效率和台标检测效果。
3)在训练台标定位网络时,使用了聚类方法和难例挖掘方法,提升了台标定位的精度和召回率。
4)经典的物体检测方法往往需要大量的人工标注。为了解决这个问题,本发明使用了弱监督的框架。该框架只要求标注一小部分的台标位置数据;其余的大量数据只需标注台标类别,且其台标位置可以根据训练好的台标定位网络生成。这大大地减小了数据标注数量,节省了标注所需的时间和人力。
附图说明
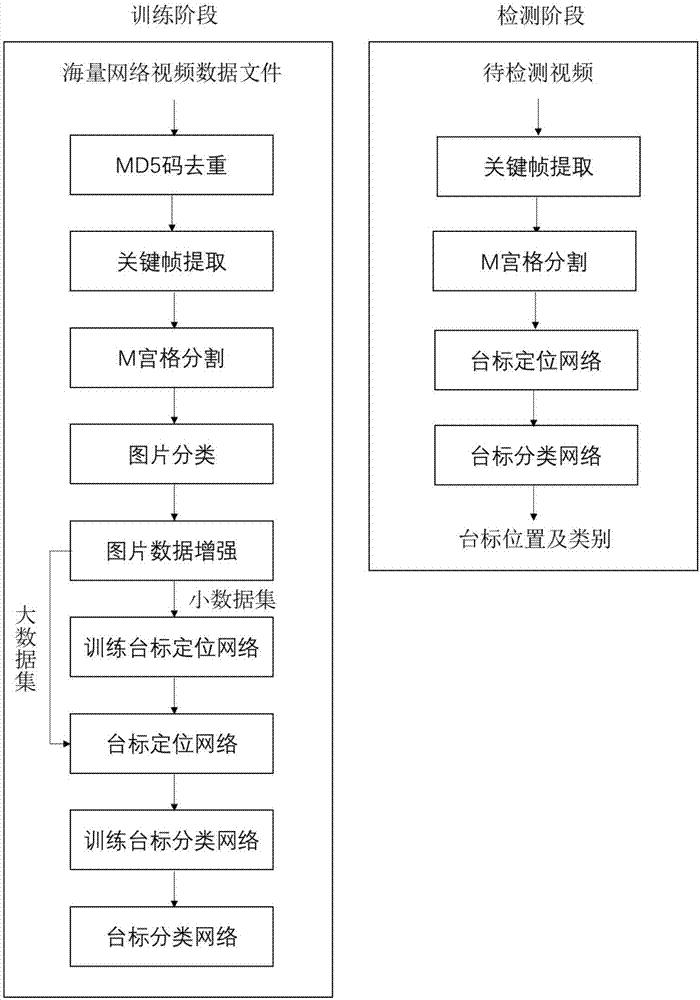
图1为本发明提供的台标检测模型训练流程图;
图2为本发明提供的一种弱监督的深度台标检测方法流程图;
图3为本发明提供的台标定位网络结构图;
图4为台标定位效果对比图;
图5为台标检测效果对比图。
具体实施方式
为使本发明的上述特征和优点能更明显易懂,下文特举实施例,并配合所附图作详细说明如下。
本发明提供一种弱监督的深度台标检测方法,其台标检测模型训练流程如图1所示,该方法流程图如图2所示,且该方法包括训练阶段和检测阶段,其训练阶段主要包括以下步骤:
(1)将海量网络视频数据文件根据md5码去重,保留有效数据以便于后期数据处理和保证有效训练。
(2)使用关键帧提取方法从上述去重的网络视频中提取若干关键帧,并对每一个网络视频关键帧进行m宫格分割,仅保留位于角落的四个m分之一图片块。后续步骤的处理都是围绕关键帧的九分之一图片块展开,以下的“图片”即指代这些图片块。其中m根据台标的大小和位置进行取值。一般地,m为9能得到较为理想的效果。根据具体情况,m一般取值为a2,且a=1、2、3、4、5、6。
(3)对上述所有图片进行分类,得到带有台标的图片。利用一个简单的分类器或网络来为这些图片分类,剔除不包含台标的图片。
(4)对上述带有台标的图片使用传统方法进行数据增强,避免不同种类台标样本的数量差异为训练带来影响。
(5)将上述数据增强后的带有台标的图片根据台标类别均衡地分配到一个大数据集和一个小数据集。其中只标注小数据集的台标位置,并将这个小数据集作为台标定位网络的训练数据。对大数据集仅仅标注台标类别,并将这个大数据集输入已训练好的台标定位网络。
(6)按照弱监督的框架组织台标定位网络和台标分类网络,并将上述小数据集作为台标定位网络的训练数据训练基于rpn的台标定位网络,得到能预测台标区域的台标定位网络。在训练中使用k-means聚类方法和难例挖掘方法来提高训练效果。
(7)将上述大数据集输入上述已训练好的台标定位网络,得到所述大数据集中每张已标记台标类别的图片的若干预测台标区域,并将所述每张已标记台标类别的图片的若干预测台标区域作为训练数据训练基于fastrcnn的台标分类网络,得到能为台标分类的台标分类网络。
在步骤(1)中,md5是一种信息摘要算法。根据这个算法可以为不同的网络视频数据文件生成具有差别的文件摘要信息。在本发明中通过比较md5值来判断网络视频数据文件是否重复。对于多个有相同md5值的网络视频只保留一个,其余剔除。
在步骤(2)中,本发明使用了一种开源的关键帧提取方法,能精准地提取出网络视频关键帧。通常一段网络视频会被提取100张左右的关键帧。在这些关键帧中,台标有明显的特征,即台标出现在较为固定的位置(四个角落),每个角落往往只出现唯一的台标,且占据整张图片较小的比例。所以在该实施例中将这些关键帧图片切分成九份,仅选取位于角落的九分之一图片来输入网络。
在步骤(3)中,本发明使用了基于cnn的一个分类器,利用这个分类器将图片分类。若有n类台标待检测,那么分类器进行n+1分类(其中包含一个背景类)。
在步骤(4)中,本发明通过几何变换、平滑滤波、jpeg压缩、对比度与亮度调整的方式来增强数据,避免了不同种类台标数据在数量级上差异过大。
在步骤(5)中,用于训练台标定位网络的数据比用于训练台标分类网络的数据少许多。本发明中选取了每类20张包含台标的图片训练台标定位网络,选取了每类1000张包含台标的图片训练台标分类网络。数据标注时仅对小数据集标注台标位置,对大数据集仅标注台标类别,因此标注工作量减少了近50倍。
在步骤(6)中,根据台标数据的特点,本发明使用了聚类方法对台标定位网络进行了改进。在台标定位网络训练过程中,滑动窗口会在卷积特征图上滑动以产生若干个anchorboxes。通常这些anchorboxes的大小、比例和数目是需要大量的实验来选出,这耗费了许多的时间。本发明使用训练台标定位网络的小数据集中标记的台标位置的比例和长宽,将它们0-1归一化后输入k-means聚类算法,根据台标数据自动选择anchorboxes的长宽比例和大小,得到预测台标区域。
在步骤(6)中,为了有效地训练难例数据,达到更好的网络泛化能力,本发明使用了难例挖掘方法来改进台标定位网络。将所述小数据集中仅标记台标位置的每张图片输入台标定位网络训练若干轮后,选择最新生成的台标定位网络,得到每个预测台标区域对应的置信度(即预测台标区域是具有台标位置的区域的置信度)。比较这些预测台标区域与台标位置的iou和所述预测台标区域对应的置信度的关系,根据阈值判断难正例、难负例或正常例,并在接下来的几轮训练中优先选择这些难例进行训练。若干轮训练后再次使用最新台标定位网络选择难例,之后再进行训练,重复以上步骤直到台标定位网络收敛,得到能预测台标区域的台标定位网络。其中所述阈值根据置信度和iou的关系选定具体值,其选取范围一般为0.5~1。
在步骤(7)中,使用(6)中训练好的台标定位网络来生成大数据集中每张图片的若干预测台标区域。将仅仅标记了台标类别的大数据集中的每张图片的若干预测台标区域输入到台标分类网络中进行训练,得到定位在这些图片上的预测台标区域的置信度,根据置信度来将这些预测台标区域分为n类前景区域和背景区域,从而得到能为台标分类的台标分类网络。其中前景区域的类别根据对应的图片上的台标类别来标记。
在所述台标检测模型中进行台标检测的流程如下:
1)将待检测视频进行与上述步骤(2)相同的处理;
2)将处理后的图片输入到训练好的台标定位网络中,得到图片的预测台标区域;
3)将上述预测台标区域输入到训练好的台标分类网络中,得到图片的台标位置及台标类别。
本发明台标检测模型主要由三部分构成:数据预处理模块、台标定位网络和台标分类网络。
(1)数据预处理
数据预处理主要包括对网络视频数据文件的去重、关键帧提取、m宫格分割和数据增强。数据预处理模块输入的是海量网络视频数据文件,输出的是若干个m分之一的关键帧图片。数据预处理模块是整个台标检测模型的初始模块。
(2)台标定位网络
台标定位网络是基于rpn的台标定位网络,其结构如图3所示。将经过预处理之后的仅标记台标位置的图片输入到台标定位网络,在卷积层提取特征,计算得到卷积特征图,在最后一层卷积特征图上滑动扫描(滑动窗口的每个中心位置都预测k种不同尺度和比例的anchorboxes)。最后一层卷积共有256个特征图,生成256维长度的全连接特征向量。之后接入回归和分类的两个全连接层,分别得到每张图片上anchorboxes的边框回归坐标以及对应的置信度。将anchorboxes根据边框回归坐标进行回归,得到预测台标区域,根据置信度的大小判断这个预测台标区域是前景区域还是背景区域。训练和测试台标分类网络时,需要使用台标定位网络生成预测台标区域,并将其输入到台标分类网络。
(3)台标分类网络
台标分类网络是基于fastrcnn的台标分类网络,针对n(实验中n=168,如图1中logo1...logo_168)类台标,台标分类网络的输入是台标定位网络产生的预测台标区域,其输出为每个预测台标区域属于n类台标(即n类前景区域)和背景类(背景区域)的置信度,从而确定预测台标区域内的台标分类。
本发明提出的一种弱监督的深度台标检测方法,其测试环境及实验数据为:
(1)测试环境
系统环境:ubuntu14.04lts
处理器:
检测框架;fasterr-cnn
特征提取模型:zf
(2)实验数据
本发明针对网络视频台标检测场景,针对168种台标,收集twitter实网数据并对这些样本进行数据增强,构造台标定位数据集(即仅标记台标位置的小数据集)和台标分类数据集(即仅标记台标类别的大数据集)。台标定位数据集在样本进行数据增强后,包括训练数据每种台标20张图片,测试数据336张图片。台标分类数据集在样本进行数据增强后,包括训练数据每种台标1000张图片,测试数据10000张图片。样本标注时,仅需要为台标定位数据标注台标位置,其余数据仅需标注台标类别,节约大量标注成本。
为说明本发明台标定位的效果,分别采用如下方法训练台标定位网络,并在上述测试集上进行测试:
1)直接采用rpn训练台标定位网络;
2)在1)基础上增加聚类方法;
3)在1)基础上增加难例挖掘方法;
4)使用本发明的台标定位方法。
对上述四种方法训练出的台标定位网络进行测试,并计算其召回率(r)、精度(p)和准确率(a),其台标定位效果对比图如图4所示。由该图可知,采用上述2)中rpn+聚类方法和3)中rpn+难例挖掘方法比1)中直接采用rpn训练台标定位网络在召回率、精度和准确率上都有提升,而本发明的台标定位方法相对于上述2)中rpn+聚类方法在召回率、精度和准确率上又有小幅度提升,且使用难例挖掘方法能增强网络的泛化能力,也能针对难例训练,加快了训练速度。
为说明本发明台标检测的整体效果,分别采用如下方法训练台标检测模型,并在上述测试集上进行测试:
1)直接采用rpn训练台标定位网络和采用fastrcnn(基于fasterr-cnn)训练台标分类网络;
2)使用本发明的台标检测方法。
对上述两种方法训练出的台标检测模型进行测试,并计算其平均精度均值(map)和roc曲线下的平均均值(mapauc),其台标检测效果对比图如图5所示。从图5中可以清晰的看出,采用本发明所述的台标检测方法后,map和mapauc都得到了大幅度提高,证实了本发明的有效性和可用性。
以上实施仅用以说明本发明的技术方案而非对其进行限制,本领域的普通技术人员可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明的精神和范围,本发明的保护范围应以权利要求书所述为准。
- 还没有人留言评论。精彩留言会获得点赞!