一种面向分布式存储结构的处理方法与流程
本发明属于多核嵌入式存储结构设计技术领域,具体涉及一种面向分布式存储结构的处理方法。
背景技术:
随着数字信号处理技术已经广泛应用于通信、图像识别、雷达、电子、医学成像等领域,各领域对数字信号处理器(dsp,digitalsignalprocessor)的性能需求也激增。而传统的单核dsp计算性能在现有工艺条件下已接近瓶颈,故多核dsp将成为未来的一个重要发展方向。但多核dsp编程环境复杂,软件人员需要考虑各核任务、资源、数据的分配以及核间的协同工作等,导致编程周期长,负担重。同时,不恰当的多核协同工作方案会导致无法充分利用多核的硬件加速优势,甚至出现多核的性能还不如单核的情况。所以急需一套适用于多核dsp的应用编译框架,解放软件编程人员,自动将串行的单核代码翻译成并行的多核代码。
多核处理器c语言自动化是一个非常经典的研究课题,传统的自动化并行编译器,希望通过从传统单指令流的串行程序中提取粗粒度的并行来实现在多核处理器的并行执行,经过几十年的研究,目前也无法获得大的突破。
工作在系统应用层的openmp和mpi编程模型近年来在任务多核化方面已取得重要进展,是当前比较流行的两种并行编程模型。openmp通过对现有的串行c语言增加一组编译制导语句和库函数,由程序员指明线程间数据的私有和共享属性,采用fork-join的模式并行执行;国内清华大学对在开源编译器orc上,对openmp指导语句进行了全局静态分析;中国科技大学实现了针对集群系统的扩展openmp。mpi则是通过一组消息库函数来支持不同处理器之间的消息通信,以单程序多数据(singleprogrammultipledata,spmd)方式在多个处理器核间并行执行程序,由编程人员对程序进行任务划分和通信交互。
除了openmp和mpi之外,还有其他诸多编程模型,总的来看这些并行编程模型都主要基于共享存储模型,共享存储模型因存在多核访存冲突和数据局部性难以利用的不足,导致多核处理器可扩展性差、多核加速比难以提升;此外,现有的编程模型都是面向并行系统的编程模型,要求程序员必须熟悉并行系统结构,所设计的并行算法需要对程序进行精心的任务划分、数据通信和同步设计。因此,程序的性能受制于程序员并行算法的设计和对并行系统的理解,这不仅极大地增加了编程人员、尤其是各个应用领域编程人员的编程负担,而且降低了程序的运行效率,很大程度上影响了并行系统性能的发挥。
此外,涉及诸多矩阵、数组和图像处理的混合运算,在分布式存储模型下,计算核必须将参与计算的数据显性地传递到本地存储区后才能开展运算。计算表达式越复杂,需要传递的数据流种类就越多,这导致数据流传输的控制逻辑非常复杂,自动化调度困难。
技术实现要素:
本发明所要解决的技术问题在于针对上述现有技术中的不足,提供一种面向分布式存储结构的处理方法,通过充分利用分布式存储结构的数据局部性原理,本发明提高了多核加速比,同时也解决了分布式存储模型下复杂计算表达式引发的数据流传输控制逻辑异常繁琐、自动化调度困难等问题。
本发明采用以下技术方案:
一种面向分布式存储结构的处理方法,采用面向密集计算的5层并行编译框架,包括:用于生成剔除冗余的多原子应用并行区域的密集计算应用编译层、以数据并行模型为基础的原子应用层、用于将所述原子应用层的应用指令集翻译成基于多核运行时系统的spmd并行代码的数据并行编译层、用于完成任务调度和数据流调度的并行运行时层以及用于支撑所述并行运行时层的操作系统层和本地编译层。
优选的,所述密集计算应用编译层的步骤如下:
s101、对复杂表达式进行词法分析,成功则转到步骤s102,否则退出;
s102、对复杂表达式进行语法分析,成功则转到步骤s103,否则退出;
s103、生成有向无环图中间表达式,成功则转到步骤s104,否则退出;
s104、生成多原子并行区域代码,成功则转到步骤s105,否则退出;
s105、生成由多原子并行区域组成的中间文件。
优选的,步骤s101中,所述词法分析处理的输入信息是带有并行制导语句的c语言源代码,将源代码文件中的一个个字符串,逐个识别为有意义的词素或单词符号,并转变为便于内部处理的格式来保存。
优选的,步骤s102中,所述语法分析将词法分析输出的内部编码格式表示的单词序列构建出一个符合语法规则的完整语法树。
优选的,所述语法树对于语言的部分采用递归下降分析法进行生成,对于并行区域内的矩阵表达子式则采用算符优先分析法,生成并行区域对应的语法树。
优选的,步骤s103中,中间表达式根据有向无环图生成,采用三地址码表示,一条三地址码对应一个或一类原子应用层。
优选的,步骤s104中,综合复杂表达式词法分析所得特征信息和语法分析三地址码序列生成所述多原子并行区域代码,并识别三地址码代表的确切含义及相关的特征参数,生成一系列按序执行的原子应用并行区域。
优选的,所述数据并行编译层的工作步骤如下:
s201、对由多原子并行区域组成的中间文件进行词法分析,成功则转到步骤s202,否则退出;
s202、进行语法及语义分析,成功则转到步骤s203,否则退出;
s203、生成ast抽象语法树,成功则转到步骤s204,否则退出;
s204、ast变换,成功则转到步骤s203,否则退出;
s205、生成可由c编译器编译的c代码。
优选的,步骤s204具体为:
首先将原源代码生成ast抽象语法树,然后再扫描这个语法树,发现编译制导指令进行变换,将该节点对应的子树摘下来,保留原代码,做整形,生成单独函数,调用计算核本地编译器编译成可重定位文件,放入到内存文件系统,插入新增的运行库函数的调用,然后将该变换后的子树再插入到原来的地方,最后,本层的编译器遍历这整个ast,并还原输出成c语言源代码文件,完成代码转换。
与现有技术相比,本发明至少具有以下有益效果:
本发明提供的面向分布式存储结构的应用编译框架处理方法,采用面向密集计算的密集计算应用编译层、原子应用层、数据并行编译层、并行运行时层以及操作系统层和本地编译层5层并行编译框架,突破了复杂存储模型管理和高效并行编程模型等难题,缩小了用户与处理器的距离,大幅度提升了用户编写密集计算应用程序的编程效率,为分布式多核存储模型下,开展高加速并行计算提供了新的理论和方法。
进一步的,密集计算应用编译层直接分析应用矩阵、数组和图像类计算表达式,完成计算表达式的解耦、识别公共子式并优化,最终自动生成剔除冗余的多原子应用并行区域,为数据并行编译层完成多核代码的自动生成奠定基础。
进一步的,分析并行编译制导区域中的代码,能预先发现表达式中的公共子式,进而消除这些冗余的公共子式,导致生成自动剔除冗余的多原子应用并行区域,带来整个计算表达式中计算量的线性下降,最终缩短了相应的计算时间。
进一步的,递归下降法根据语言中各语法范畴有文法递归定义的特点,用一组相互递归的子程序来完成语法分析。生成语法树(ast)的过程对于语言的部分采用递归下降分析法,简单易于实现;算符优先法则利用各个算符间的优先关系和结合规则来指导语法分析,不仅简单易于实现还特别适合于分析各种表达式,因此对于并行区域内的矩阵表达子式采用算符优先分析法,生成并行区域对应的语法树。
进一步的,数据并行编译层首先进行ast分析以识别原子应用层的原子指令类别,再根据原子指令类别搜集该类应用所需的参数,进而完成该类应用的数据的自动划分并生成调用spmd运行库函数的c语言代码节点,最终进行ast变换将原子指令翻译成基于多核运行时系统的spmd并行代码。
进一步的,对ast进行分析,识别带有编译制导指令的c语言节点,并将该类节点变换成不带编译制导指令、插入了调用运行时库函数的c语言代码节点,从而完成源代码到源代码的变换,实现了多核代码的自动生成,大幅度提升了用户编写密集计算应用程序的编写效率。
综上所述,基于本发明处理方法的模型,可以研发嵌入式多核版matlab,实现可见即可得的编程效果,为新一代巡航导弹、防空导弹、智能无人机等智能武器快速研发和部署矩阵运算、模式识别、机器学习等复杂算法,提供简单而高效的多核编程平台。
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
图1为本发明的并行编译框架示意图;
图2为本发明的密集计算应用编译层工作流程图;
图3为本发明的含有并行制导语句的c语言代码;
图4为本发明的并行区域对应的dag示意图;
图5为本发明的多原子并行区域自动生成过程示意图;
图6为本发明的数据并行编译器工作流程图。
具体实施方式
请参阅图1,本发明提供了一种面向分布式存储结构的处理方法,采用面向密集计算的5层并行编译框架,包括:密集计算应用编译层、原子应用层、数据并行编译层、并行运行时层、操作系统层和本地编译层。
密集计算应用编译层用于分析应用层矩阵、数组和图像计算表达式,完成了计算表达式的解耦和公共子式优化,最终自动生成剔除冗余的多原子应用并行区域,解决了分布式存储模型下运算逻辑的合理解耦问题。
原子应用层以数据并行模型为基础定义了一系列“应用指令集”,主要包括海量矩阵、海量数组的基本运算和图像类的基本算子。该层拉近了用户与处理器的距离,降低了面向密集计算编译器的设计难度。
数据并行编译层根据实际应用需求(主要是数据大小、起始地址和数据流调度模型)将原子应用层的“应用指令集”翻译成基于多核运行时系统的spmd并行代码。
并行运行时层按照原子应用运算的计算逻辑完成任务调度和数据流调度,解决了分布式存储模型下的数据流调度问题。同时该层能够检测多核系统运行故障,及时完成任务重构和任务迁移,提升了系统的可靠性。
操作系统层和本地编译层主要为实现高效的运行时层提供良好的支撑平台,为实现公共子式优化、图像数据存储、任务重构和任务迁移提供强大支撑。
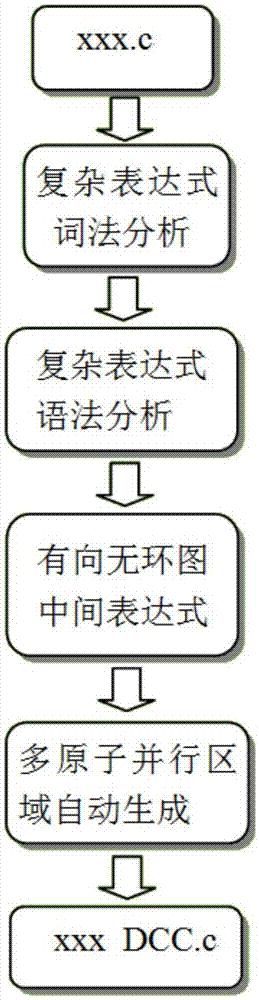
请参阅图2,所述密集计算应用编译层的步骤如下:
s101、对复杂表达式进行词法分析,成功则转到步骤s102,否则退出;
s102、对复杂表达式进行语法分析,成功则转到步骤s103,否则退出;
s103、生成有向无环图中间表达式,成功则转到步骤s104,否则退出;
s104、生成多原子并行区域代码,成功则转到步骤s105,否则退出;
s105、生成由多原子并行区域组成的中间文件。
请参阅图,3,词法分析处理的输入信息是带有并行制导语句的c语言源代码,它将源代码文件中的一个个字符串,逐个识别为有意义的词素或单词符号,并转变为便于内部处理的格式来保存。它和普通c语言的词法分析大体相同,不同之处关键在于分析并行编译制导区域中的代码。
请参阅图4,语法分析将词法分析输出的内部编码格式表示的单词序列尝试构建出一个符合语法规则的完整语法树。生成语法树的过程对于语言的部分采用递归下降分析法,而对于并行区域内的矩阵表达子式则采用算符优先分析法,生成并行区域对应的语法树。
中间表达式根据有向无环图生成,采用三地址码表示。不过此编译器中的一条三地址码对应的是一个或者一类原子应用层而不是本地编译器中一条或者一类机器指令。
请参阅图5,生成多原子并行区域代码需要综合复杂表达式词法分析所得特征信息和语法分析三地址码序列,并准确识别三地址码代表的确切含义及相关的特征参数,进而生成一系列按序执行的原子应用并行区域。
请参阅图6,本发明数据并行编译层工作步骤如下:
s201、对由多原子并行区域组成的中间文件进行词法分析。成功则转到步骤s202,否则退出;
s202、进行语法及语义分析。成功则转到步骤s203,否则退出;
s203、生成ast抽象语法树。成功则转到步骤s204,否则退出;
s204、ast变换。成功则转到步骤s203,否则退出;
s205、生成可由c编译器编译的c代码。
所述数据并行编译层的编译工作最关键的就是对所生成的ast进行分析变换,将带有编译制导指令的c语言源代码转换成不带编译制导指令、插入了调用运行库函数的c语言代码。
首先需要将原来的源代码生成ast抽象语法树,然后再扫描这个语法树,发现编译制导指令就进行变换:
将该节点对应的子树摘下来,基本保留原来的代码不做太大变化,做一定的整形,生成单独函数,调用计算核本地编译器编译成可重定位文件,放入到内存文件系统;
在合适的地方插入新增的运行库函数的调用,然后将该变换后的子树再插入到原来的地方。
最后,本层的编译器遍历这整个ast,并还原输出成c语言源代码文件。
至此,代码转换工作就完成了。
综上所述,本发明提出的面向分布式存储结构的应用编译框架,针对分布式存储模型,突破了复杂存储模型管理、多级编译器设计和大规模数据调度难题,实现了简单、高效的多核并行编程方式。
- 还没有人留言评论。精彩留言会获得点赞!