一种基于加密文档基因追踪方法与流程
本发明一种基于加密文档基因追踪方法,针对公司、机关加密文档输出,追踪到具体来源与暗码识别。
背景技术:
随着发展公司产生许多重要的对外和对内的文件,若加密文件一旦流出,我们可以找到流出来源,所以需要通过一种加密文档基因来追踪所泄露出的来源。
国内现有的加密文档基因追踪方法,特别是针对企业级,文档基因追踪方面,只能针对文档的修改来比对或者针对文档进行加密,无法追踪到文档的来源,所以在安全性方面比较低下,比如:
中国专利201110005756.1,给出了一种加密文档唯一标识的生成和更新的方法,所述方法通过将文档进行分段,并计算保存文档每一分段对应的哈希值,在文档修改后再次对文档进行分段,并计算文档每一分段对应的哈希值,通过比较修改前后的各分段的哈希值是否发生变化,获得文档的修改比例,根据该修改比例确定是否生成新的加密文档唯一标识。该方法解决了文件修改后造成的多个文档的标识相同但内容不同的问题。该方法属于文档修改前后进行对比,识别出文档是否被修改过,无法对文档进行加密并追踪到来源。
中国专利200910235692.7,提出的方法包括:提供了一种文档安全控制方法、装置和系统,其中,该方法包括:应用代理获取待加密文档,并根据待加密文档,生成加密文档;应用代理将加密文档的密钥保存至文档安全服务器,并将加密文档传送至应用系统。本发明通过应用代理在获取待加密文档时,自动对文档进行加密,实现了加密过程的自动化、透明化。该方法主要解决在服务器中对文档进行加密和解密获取,无法针对加密后的文档进行追踪来源。
技术实现要素:
发明目的:为解决企业内部加密文档输出,追踪到具体来源与暗码识别。本发明提供的任何形式文档输出方法,在公司内部以及外部归档文件和机密文章具有明显作用。
本发明的技术方案是,一种基于加密文档基因追踪方法,其特征在于:包括如下步骤:
1)通过编码规则将获取加密文档的机器序列号和当前登录用户信息,进行编码,定位四点坐标,由四个坐标点构成矩形;
所述定位四个坐标点,根据页面的左上角为原点计算,x轴和y轴各减去页面长度的四分之一,确定为第一个点,y轴减去四分之三,确定第二个点,x轴减去页面高度的四分之三,确定为第三个点,以第三个点的y轴减去页面长度的四分之三,确定为第四个点。
2)对四个坐标点的数字或/和字符进行编码,例如:01234567转换为二进制是:
012转成0000001100;
345转成0101011001;
67转成1000011。
转换合格式后:000000110001010110011000011
转换时把数字的个数转成二进制:0-8为9个数字,二进制是0000、0001、0010、0011、0100、0101、0110、0111、1000;
设定统一标志位0001代表数字编码,0010为字符编码,
整合后为:00010000001000000000110001010110011000011;
3)对字符进行编码,字符编码,例如:ac-42
转换后的索引(10,12,41,4,2),分组规则:(10,12)(41,4)(2)
把每一组转成11bits的二进制:
(10,12)10*45+12等于462转成00111001110
(41,4)41*45+4等于1849转成11100111001
(2)等于2转成000010
整合后:0011100111011100111001000010
把字符的个数转成二进制:共5个字符,转成000000101
设定统一标志位0010,0010代表字符编码。
整合后为:00100000001010011100111011100111001000010
4)生成补齐码,当没有达到我们最大的bits数的限制,还要加一些补齐码,补齐码设置二进制为1110110000010001,这两个二进制转成十进制是236和17,每一种纠错级别的最大限制,其最大需要104个bits,目前只有80个bits,所以,还需要24个bits,也就是需要3个补齐码,添加三个,于是得到下面的编码:
00100000010110110000101101111000110100010111001011011100010011010100001101000000111011000001000111101100
5)生成加密图片,根据打印文档的尺寸自动缩放比例,初始化图片位置,将四个坐标原点固定在相对位置上,保持正方形状态;
所述定位四个坐标点,根据页面的左上角为原点计算,x轴和y轴各减去页面长度的四分之一,确定为第一个点,y轴减去四分之三,确定第二个点,x轴减去页面高度的四分之三,确定为第三个点,以第三个点的y轴减去页面长度的四分之三,确定为第四个点。
6)对数据码进行分组,进行纠错,分成不同的block,对各个block进行纠错编码,需要4个blocks(2个blocks为一组,共两组),头一组的两个blocks中各15个bits数据+各9个bits的纠错码;
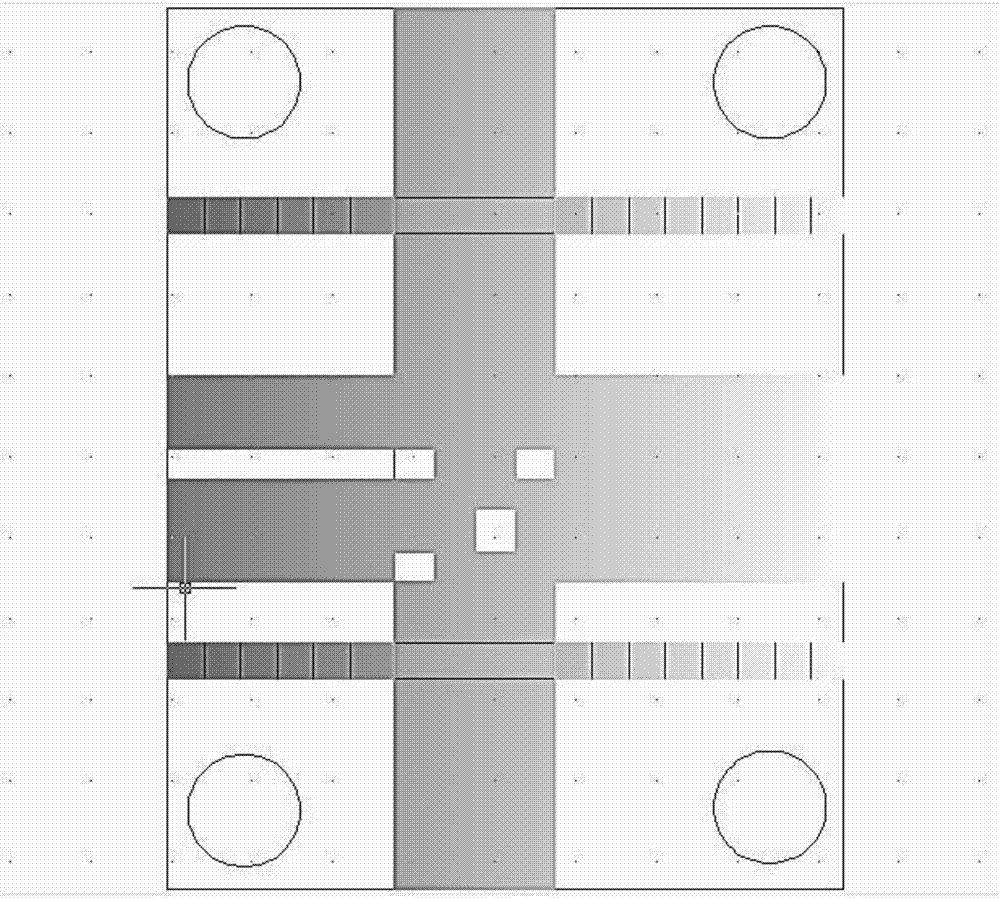
7)结构化数据定位,黑白的区域被指定为固定的位置,称为查询图形和定位图形,寻像图形和定位图形将解码程序确定图形中具体符号的坐标;
蓝色的区域用来保存被编码的数据内容以及纠错信息码;
绿色的区域,用来标识纠错的级别,这个区域为格式化信息。
有益效果:本发明能够解决企业内部加密文档输出,通过加密文档的编码和结构化数据定位,黑白的区域被指定为固定的位置,称为查询图形和定位图形,寻像图形和定位图形将解码程序确定图形中具体符号的坐标。追踪到具体来源与暗码识别。本发明提供的任何形式文档输出方法,在公司内部以及外部归档文件和机密文章具有显著效果。
附图说明
图1为本发明方法的实施流程图。
图2为构化数据定位的颜色表示示意图。
具体实施方式
本发明一种基于加密文档基因追踪方法:包括如下步骤:
(1)通过编码规则将获取机器序列号和当前登录用户信息,进行编码,定位四点坐标,由四个坐标点构成矩形。
(2)通过数字与字符编码器,转换为二进制数,例如:01234567转换为二进制是:
012转成0000001100;
345转成0101011001;
67转成1000011。
整合格式后:000000110001010110011000011
把数字的个数转成二进制:0-7为8个数字,二进制是0000001000
设定统一标志位0001代表数字编码,0010为字符编码,
整合后为:00010000001000000000110001010110011000011。
(3)对字符进行转码,通过字符转码器,例如:ac-42
转换后的索引(10,12,41,4,2),分组规则:(10,12)(41,4)(2)
把每一组转成11bits的二进制:
(10,12)10*45+12等于462转成00111001110
(41,4)41*45+4等于1849转成11100111001
(2)等于2转成000010
整合后:0011100111011100111001000010
把字符的个数转成二进制:共5个字符,转成000000101
设定统一标志位0010,0010代表字符编码。
整合后为:00100000001010011100111011100111001000010
(4)通过补齐码编译器,生成补齐码,当没有达到我们最大的bits数的限制,还要加一些补齐码,设置二进制为1110110000010001,这两个二进制转成十进制是236和17,每一种纠错级别的最大限制,其最大需要104个bits,目前只有80个bits,所以,还需要24个bits,也就是需要3个补齐码,添加三个,于是得到下面的编码:
00100000010110110000101101111000110100010111001011011100010011010100001101000000111011000001000111101100
(4)生成加密图片,根据打印文档的尺寸自动缩放比例,初始化图片位置,将四个坐标原点固定在相对位置上,保持正方形状态;
(5)对数据码进行分组,进行纠错,分成不同的block,对各个block进行纠错编码,需要4个blocks(2个blocks为一组,共两组),头一组的两个blocks中各15个bits数据+各9个bits的纠错码;
(6)生成格式信息,定位10bits格式信息编码,其中包含:
前2个bits用于表示错误异常信息,3个bits表示使用什么样的mask
5个纠错bits。
将10个bits与1000010010做xor操作,增加的扫描器的图像识别。
结合数据量、字符类型和纠错级别,均设有相对应的最多输入字符数。当增加数据量,则需要使用更多的码元来组成,校验码就会变得更大。
根据环境、编码尺寸等因素后设置不同的级别。当纸张内容较多时选择q或h,且数据量较多的时候,也可以选择级别l。一般情况下用户大多选择级别m(15%)。
级别定义如下:
levell:最大7%的错误能够被纠正;
levelm:最大15%的错误能够被纠正;
levelq:最大25%的错误能够被纠正;
levelh:最大30%的错误能够被纠正;
(6)结构化数据定位
黑白的区域被指定为固定的位置,称为查询图形和定位图形,寻像图形和定位图形将解码程序确定图形中具体符号的坐标。(见图2)
蓝色的区域用来保存被编码的数据内容以及纠错信息码。
绿色的区域,用来标识纠错的级别,这个区域为格式化信息。
- 还没有人留言评论。精彩留言会获得点赞!