一种数据处理方法及处理装置与流程
本发明涉及数据处理领域,尤指一种数据处理方法及处理装置。
背景技术:
在图形图像处理、数字信号滤波计算、数值天气预报、网络路由选择、智能交通系统的路径选择、线性规划、傅里叶变换等众多数值问题中,最常用的基本算法就是矩阵与向量的乘法,因此一个快速高效的矩阵乘以向量的计算方法对于解决众多数值问题是非常重要的。
相关技术中,在计算待处理矩阵乘以待处理向量时,会将待处理矩阵按行划分成多个矩阵块,以使每个节点承担一个矩阵块乘以向量的计算任务,最终将每个节点的计算结果组合起来得到矩阵乘以向量的计算结果。
但是,这种方法中每个节点在进行一个矩阵块乘以待处理向量的计算时,会依次计算矩阵块的每一行向量乘以待处理向量,也就是说首先计算矩阵块的第一行向量乘以待处理向量,待计算完成并得到计算结果后才计算矩阵块的第二行向量乘以待处理向量,以此类推,直到计算完矩阵的最后一行向量乘以待处理向量,因此整个计算过程所耗费的时间过长。
技术实现要素:
为了解决上述技术问题,本发明提供了一种数据处理方法及处理装置,能够使每个节点采用多线程并行计算第i个待处理矩阵乘以待处理n维列向量,从而充分利用每个节点的计算能力,大幅度减少每个节点在计算待处理矩阵乘以待处理n维列向量时所耗费的时间。
为了达到本发明目的,本发明提供了一种数据处理方法,包括:
主节点根据从节点的个数p将待处理矩阵m*n按行划分成p个待处理矩阵;
向第i个从节点发送待处理n维列向量和所述p个待处理矩阵中的第i个待处理矩阵,以使所述第i个节点采用多线程并行计算所述第i个待处理矩阵乘以所述待处理n维列向量,得到第i个计算结果;其中,i=1、2…p;
接收所述p个从节点发送的p个计算结果;
根据所述p个计算结果得到所述待处理矩阵m*n与所述待处理n维列向量相乘的计算结果。
所述主节点根据从节点个数p将待处理矩阵m*n按行划分成p个待处理矩阵,包括:
所述主节点根据所述节点的个数p将所述待处理矩阵m*n按行依次划分成包含
其中,所述m%p表示对
所述向p个从节点中第i个从节点发送待处理n维列向量和p个待处理矩阵中第i个待处理矩阵,包括:
当i≤m%p时,向所述p个从节点中第i个从节点发送所述待处理n维列向量和所述p个待处理矩阵中包含
当i>m%p时,向所述p个从节点中第i个从节点发送所述待处理n维列向量和所述p个待处理矩阵中包含
本发明还提供了一种数据处理方法,包括:
从节点接收主节点发送的待处理n维列向量和待处理矩阵;其中,所述待处理矩阵是所述主节点根据所述从节点的个数p将待处理矩阵m*n按行划分成p个待处理矩阵中的一个;
采用多线程并行计算所述待处理矩阵乘以所述待处理n维列向量,并得到计算结果;
向所述主节点发送所述计算结果。
当所述待处理矩阵包含
将所述待处理矩阵采用内存对齐的方式存储于自身节点的预设存储空间中;其中,所述预设存储空间为自身节点中所有线程都能够访问的存储空间;
将所述待处理n维列向量存储于所述预设存储空间中;
开启
并行控制所述
并行控制所述
获取所述计算结果中
当所述待处理矩阵包含
将所述待处理矩阵采用内存对齐的方式存储于自身节点的预设存储空间中;其中,所述预设存储空间为自身节点中所有线程都能够访问的存储空间;
将所述待处理n维列向量存储于所述预设存储空间中;
开启
并行控制所述
并行控制所述
获取所述计算结果中
所述并行控制
在所述
并行控制所述第m个线程块中n个线程的第p个线程从所述预设存储空间中获取所述待处理矩阵的第m行向量的第p个元素和所述待处理n维列向量的第p个元素;其中,p=1、2…n;
所述并行控制
并行控制所述第m个线程块中n个线程的第p个线程计算所述待处理矩阵的第m行向量的第p个元素乘以所述待处理n维列向量的第p个元素,得到所述第m个子计算结果中第p个基本计算结果;
获取所述第m个子计算结果中n个基本计算结果并相加,得到所述第m个子计算结果。
所述并行控制
在所述
并行控制所述第k个线程块中n个线程的第q个线程从所述预设存储空间中获取所述待处理矩阵的第k行向量的第q个元素和所述待处理n维列向量的第q个元素;其中,q=1、2…n;
所述并行控制
并行控制所述第k个线程块中n个线程的第q个线程计算所述待处理矩阵的第k行向量的第q个元素乘以所述待处理n维列向量的第q个元素,得到所述第k个子计算结果中第q个基本计算结果;
获取所述第k个子计算结果中n个基本计算结果并相加,得到所述第k个子计算结果。
本发明还提供了一种主节点,包括:
划分模块,用于根据从节点的个数p将待处理矩阵m*n按行划分成p个待处理矩阵;
第一发送模块,用于向p个从节点的第i个从节点发送待处理n维列向量和所述p个待处理矩阵中第i个待处理矩阵,以使所述第i个节点采用多线程并行计算所述第i个待处理矩阵乘以所述待处理n维列向量,得到第i个计算结果;其中,i=1、2…p;
第一接收模块,用于接收所述p个从节点发送的p个计算结果;
处理模块,用于根据所述p个计算结果得到所述待处理矩阵m*n所述待处理n维列向量相乘的计算结果。
本发明还提供了一种从节点,包括:
第二接收模块,用于从节点接收主节点发送的待处理n维列向量和p个待处理矩阵中第j个待处理矩阵;其中,j=1或2…或p;所述p个待处理矩阵是所述主节点根据所述从节点的个数p将待处理矩阵m*n按行划分成的;
计算模块,用于采用多线程并行计算所述第j个待处理矩阵乘以所述待处理n维列向量,并得到第j个计算结果;
第二发送模块,用于向所述主节点发送所述第j个计算结果。
与现有技术相比,本发明至少包括主节点根据从节点的个数p将待处理矩阵m*n划分成p个待处理矩阵;向p个从节点的第i个节点发送待处理n维列向量和p个待处理矩阵中第i个待处理矩阵,以使所述第i个节点采用多线程并行计算所述第i个待处理矩阵乘以所述待处理n维列向量,得到第i个计算结果;接收p个从节点发送的p个计算结果,得到待处理矩阵m*n和待处理n维列向量相乘的计算结果。从本发明提供的技术方案可见,由于各个从节点采用多线程对主节点发送给自身节点的待处理矩阵和待处理n维列向量进行相乘计算,从而实现了待处理矩阵的每一行向量与待处理n维列向量相乘的并行计算,因此充分地利用了每个节点的计算能力,大幅度地减少了每个节点在计算待处理矩阵乘以待处理n维向量时所耗费的时间。
本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在说明书、权利要求书以及附图中所特别指出的结构来实现和获得。
附图说明
附图用来提供对本发明技术方案的进一步理解,并且构成说明书的一部分,与本申请的实施例一起用于解释本发明的技术方案,并不构成对本发明技术方案的限制。
图1为本发明实施例提供的一种数据处理方法的流程示意图;
图2为本发明实施例提供的另一种数据处理方法的流程示意图;
图3为本发明实施例提供的又一种数据处理方法的流程示意图;
图4为本发明实施例提供的矩阵划分的结构示意图;
图5为本发明实施例提供的线程块中包含线程的结构示意图;
图6为本发明实施例提供的mpi+cuda多粒度混合并行编程算法流程示意图;
图7为本发明实施例提供的一种主节点的结构示意图;
图8为本发明实施例提供的一种从节点的结构示意图;
图9为本发明实施例提供的另一种从节点的结构示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明白,下文中将结合附图对本发明的实施例进行详细说明。需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互任意组合。
本发明实施例提供一种数据处理方法,如图1所示,该方法包括:
步骤101、主节点根据从节点的个数p将待处理矩阵m*n按行划分成p个待处理矩阵。
具体的,从节点有多少个,就将待处理矩阵m*n按行划分成多少个待处理矩阵。
步骤102、向p个从节点的第i个从节点发送待处理n维列向量和p个待处理矩阵中第i个待处理矩阵,以使第i个节点采用多线程并行计算第i个待处理矩阵乘以待处理n维列向量,得到第i个计算结果。
其中,i=1、2…p。
需要说明的是,p个从节点之间并不存在顺序之分,第i个从节点的表述方式只是为了区分p个节点中的一个节点与p个节点中的其他节点。
具体的,向p个从节点中第i个从节点发送待处理n维列向量和p个待处理矩阵中第i个待处理矩阵指的是:向p个从节点中第1个从节点发送待处理n维列向量和p个待处理矩阵中第1个待处理矩阵,向p个从节点中第2个从节点发送待处理n维列向量和p个待处理矩阵中第2个待处理矩阵…向p个从节点中第p个从节点发送待处理n维列向量和p个待处理矩阵中第p个待处理矩阵。
具体的,可以通过信息传递接口(messagepassinginterface,mpi)实现待处理向量和待处理矩阵的发送。mpi提供一个实际可用的、可移植的、高效的和灵活的消息传递接口标准,并且包括协议说明和和语义说明,协议说明和语义说明指明mpi如何在各种实现中发挥其特性。mpi具有以下特性:提供应用程序编程接口;提高通信效率,其中提高通信效率的措施包括避免存储器到存储器的多次重复拷贝允许计算和通信的重叠等;提供的接口方便c语言和fortran77的调用;提供可靠的通信接口,即用户不必处理通信失败;定义的接口能在基本的通信和系统软件无重大改变时,在许多并行计算机生产商的平台上实现;接口的语义是独立于语言的;接口设计是线程安全的。mpi适用于粗粒度的并行,即通过mpi提供的接口同时向p个节点中第i个节点发送待处理n维列向量和p个待处理矩阵中第i个待处理矩阵,即向p个节点中每个节点发送待处理n维列向量和p个待处理矩阵中一个待处理矩阵,其中,向每个节点所发送的待处理矩阵均不重复。
步骤103、接收p个从节点发送的p个计算结果。
具体的,接收p个从节点发送的p个计算结果指的是接收p个从节点中第1个从节点发送的第1个计算结果,p个从节点中第2个从节点发送的第2个计算结果…p个从节点中第p个从节点发送的第p个计算结果。
步骤104、根据p个计算结果得到待处理矩阵m*n和待处理n维列向量相乘的计算结果。
具体的,由于第1个计算结果、第2个计算结果…第p个计算结果是待处理矩阵m*n的不同部分与待处理n维列向量相乘的计算结果,因此获取了第1个计算结果、第2个计算结果…第p个计算结果,这p个计算结果就组成了m维列向量,这个m维列向量就是待处理矩阵m*n和待处理n维列向量相乘的计算结果。
本发明实施例所提供的数据处理方法,主节点根据从节点的个数p将待处理矩阵m*n划分成p个待处理矩阵;向p个从节点的第i个从节点发送待处理n维列向量和p个待处理矩阵中第i个待处理矩阵,以使第i个节点采用多线程并行计算第i个待处理矩阵乘以待处理n维列向量,得到第i个计算结果;接收p个从节点发送的p个计算结果,得到待处理矩阵m*n和待处理n维列向量相乘的计算结果。从本发明提供的技术方案可见,由于各个从节点并不是依次计算待处理矩阵中每一行向量与待处理n维列向量的乘积,而是采用多线程对主节点发送给自身节点的待处理矩阵和待处理n维列向量进行乘积计算,从而实现了待处理矩阵的每一行向量与待处理n维列向量相乘的并行计算,因此充分地利用了每个节点的计算能力,大幅度地减少了每个节点在计算待处理矩阵乘以待处理n维向量时所耗费的时间。
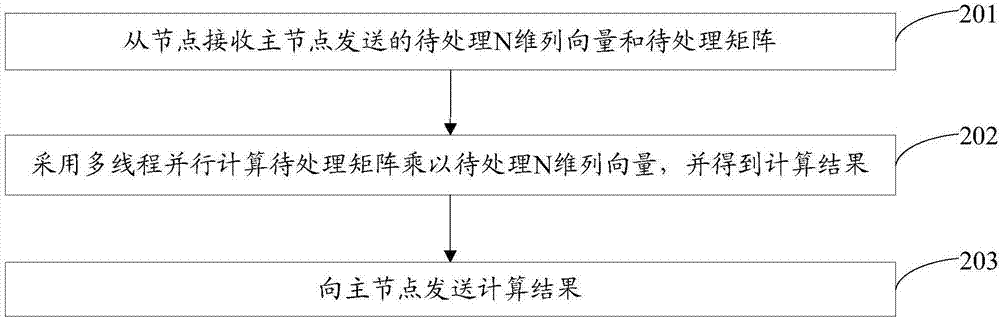
本发明实施例提供另一种数据处理方法,如图2所示,该方法包括:
步骤201、从节点接收主节点发送的待处理n维列向量和待处理矩阵。
其中,待处理矩阵是主节点根据从节点的个数p将待处理矩阵m*n按行划分成p个待处理矩阵中的一个。
步骤202、采用多线程并行计算待处理矩阵乘以待处理n维列向量,并得到计算结果。
具体的,从节点得到的计算结果对于主节点来说具体就是第i个计算结果。
具体的,可以通过统一计算设备架构(computeunifieddevicearchitecture,cuda)中提供的多线程并行计算待处理矩阵乘以待处理n维列向量,cuda适用于细粒度的并行,即在节点中提供很多个线程并行处理计算任务。
步骤203、向主节点发送计算结果。
需要说明的是,本实施例提供的数据处理方法是以p个从节点中任意一个从节点为主体进行描述的,p个从节点中所有从节点的数据处理过程一致。
本发明实施例所提供的数据处理方法,从节点接收主节点发送的待处理n维列向量和p个待处理矩阵中待处理矩阵;采用多线程并行计算待处理矩阵乘以待处理n维列向量,并得到计算结果;向主节点发送计算结果。从本发明提供的技术方案可见,由于各个从节点并不是依次计算待处理矩阵中每一行向量与待处理n维列向量的乘积,而是采用多线程对主节点发送给自身节点的待处理矩阵和待处理n维列向量进行乘积计算,从而实现了待处理矩阵的每一行向量与待处理n维列向量相乘的并行计算,因此充分地利用了每个节点的计算能力,大幅度地减少了每个节点在计算待处理矩阵乘以待处理n维向量时所耗费的时间。
下面提供一个完成的实施例来说明本发明提供的数据处理方法,因一个主节点和p个从节点的交互过程太过繁杂,无法一一在图中示出,因此以一个主节点和两个从节点(一个接收到主节点发送的包含
步骤301、主节点根据从节点的个数将待处理矩阵m*n按行依次划分成包含
其中,
步骤302、当i≤m%p时,主节点向p个节点中第i个节点发送待处理n维列向量和p个待处理矩阵中包含
具体的,向p个节点中第i个节点发送待处理n维列向量和p个待处理矩阵中第i个待处理矩阵可以是由主进程控制p个从进程来完成的,如果是由这种方式完成的,主进程采用mpi_scatterv函数与各个从进程通信。
需要说明的是,当从节点为前m%p个节点时,从节点会接收到主节点发送的包含
步骤303、从节点接收主节点发送的待处理n维列向量和包含
需要说明的是,由于待处理矩阵是按行划分m*n矩阵得到的,因此包含包含
步骤304、从节点将待处理矩阵采用内存对齐的方式存储于自身节点的预设存储空间中。
其中,预设存储空间为自身节点中所有线程都能够访问的存储空间。
具体的,待处理矩阵的
步骤305、从节点将待处理n维列向量存储于预设存储空间中。
具体的,由于待处理n维列向量是后续步骤中
步骤306、从节点开启
具体的,gpu接收到cpu发送的待处理矩阵的
步骤307、从节点并行控制
其中,
具体的,从节点并行控制
具体的,步骤307可以通过步骤307a、步骤307b实现:
步骤307a、从节点在
具体的,从节点在
需要说明的是,线程块也被称为block,一个block处理待处理矩阵第m行向量与待处理n维列向量相乘。
步骤307b、从节点并行控制第m个线程块中n个线程的第p个线程从预设存储空间中获取待处理矩阵的第m行向量的第p个元素和待处理n维列向量的第p个元素。
其中,p=1、2…n。
具体的,从节点并行控制第m个线程块中n个线程的第p个线程从预设存储空间中获取待处理矩阵的第m行向量的第p个元素和待处理n维列向量的第p个元素指的是:从节点并行控制第m个线程块中n个线程的第1个线程从预设存储空间中获取待处理矩阵的第m行向量的第1个元素和待处理n维列向量的第1个元素、第m个线程块中n个线程的第2个线程从预设存储空间中获取待处理矩阵的第m行向量的第2个元素和待处理n维列向量的第2个元素…第m个线程块中n个线程的第n个线程从预设存储空间中获取待处理矩阵的第m行向量的第n个元素和待处理n维列向量的第n个元素。
步骤308、从节点并行控制
具体的,从节点并行控制
具体的,步骤308可以通过步骤308a、步骤308b实现:
步骤308a、从节点并行控制第m个线程块中n个线程的第p个线程计算待处理矩阵的第m行向量的第p个元素乘以待处理n维列向量的第p个元素,得到第m个子计算结果中第p个基本计算结果。
具体的,从节点并行控制第m个线程块中n个线程的第p个线程计算待处理矩阵的第m行向量的第p个元素乘以待处理n维列向量的第p个元素,得到第m个子计算结果中第p个基本计算结果指的是:从节点并行控制第m个线程块中n个线程的第1个线程计算待处理矩阵的第m行向量的第1个元素乘以待处理n维列向量的第1个元素并得到第m个子计算结果中第1个基本计算结果、第m个线程块中n个线程的第2个线程计算待处理矩阵的第m行向量的第2个元素乘以待处理n维列向量的第2个元素并得到第m个子计算结果中第2个基本计算结果…第m个线程块中n个线程的第n个线程中计算待处理矩阵的第m行向量的第n个元素乘以待处理n维列向量的第n个元素并得到第m个子计算结果中第n个基本计算结果。
步骤308b、从节点获取第m个子计算结果中n个基本计算结果并相加,得到第m个子计算结果。
具体的,由于第m个线程块中n个线程并行地计算的待处理矩阵中一行向量与待处理n维向量的乘积,因此将n个线程中的n个基本计算结果相加,就能够得到待处理矩阵中第m个线程块计算的一行向量与待处理n维向量的乘积。
具体的,使用如上所述的线程组织形式可以更加提高计算速度,从而更好地发挥节点的计算能力,线程块中再开启线程的示意图可以如图5所示。
步骤309、从节点获取计算结果中
具体的,从节点获取计算结果中
与步骤303~309的并列执行方法包括步骤310~316:
步骤310、从节点接收主节点发送的待处理n维列向量和包含
需要说明的是,由于待处理矩阵是按行划分m*n矩阵得到的,因此包含包含
步骤311、从节点将待处理矩阵采用内存对齐的方式存储于自身节点的预设存储空间中。
其中,预设存储空间为自身节点中所有线程都能够访问的存储空间。
步骤312、从节点将待处理n维列向量存储于预设存储空间中。
步骤313、从节点开启
具体的,gpu接收到cpu发送的待处理矩阵的
步骤314、从节点并行控制
其中,
具体的,从节点并行控制
具体的,步骤14可以通过步骤314a、步骤314b实现:
步骤314a、从节点在
步骤314b、从节点并行控制第k个线程块中n个线程的第q个线程从预设存储空间中获取待处理矩阵的第k行向量的第q个元素和待处理n维列向量的第q个元素。
其中,q=1、2…n。
具体的,从节点并行控制第k个线程块中n个线程的第q个线程从预设存储空间中获取待处理矩阵的第k行向量的第q个元素和待处理n维列向量的第q个元素指的是:从节点并行控制第k个线程块中n个线程的第1个线程从预设存储空间中获取待处理矩阵的第k行向量的第1个元素和待处理n维列向量的第1个元素、第k个线程块中n个线程的第2个线程从预设存储空间中获取待处理矩阵的第k行向量的第2个元素和待处理n维列向量的第2个元素…第k个线程块中n个线程的第n个线程从预设存储空间中获取待处理矩阵的第k行向量的第n个元素和待处理n维列向量的第n个元素。
步骤315、从节点并行控制
具体的,从节点并行控制
具体的,步骤315可以通过步骤315a、步骤315b实现:
步骤315a、从节点并行控制第k个线程块中n个线程的第q个线程计算待处理矩阵的第k行向量的第q个元素乘以待处理n维列向量的第q个元素,得到第k个子计算结果中第q个基本计算结果。
具体的,从节点并行控制第k个线程块中n个线程的第q个线程计算待处理矩阵的第k行向量的第q个元素乘以待处理n维列向量的第q个元素,得到第k个子计算结果中第q个基本计算结果指的是:从节点并行控制第k个线程块中n个线程的第1个线程计算待处理矩阵的第k行向量的第1个元素乘以待处理n维列向量的第1个元素并得到第k个子计算结果中第1个基本计算结果、第k个线程块中n个线程的第2个线程计算待处理矩阵的第k行向量的第2个元素乘以待处理n维列向量的第2个元素并得到第k个子计算结果中第2个基本计算结果…第k个线程块中n个线程的第n个线程中计算待处理矩阵的第k行向量的第n个元素乘以待处理n维列向量的第n个元素并得到第k个子计算结果中第n个基本计算结果。
步骤315b、从节点获取第k个子计算结果中n个基本计算结果并相加,得到第k个子计算结果。
具体的,由于第k个线程块中n个线程并行地计算的待处理矩阵中一行向量与待处理n维向量的乘积,因此将n个线程中的n个基本计算结果相加,就能够得到待处理矩阵中第k个线程块计算的一行向量与待处理n维向量的乘积。
步骤316、从节点获取计算结果中
需要说明的是,步骤303~309与步骤310~316并不存在执行的先后顺序,而是每个节点根据自身接收到的待处理矩阵包含的行向量数不同,选择步骤303~309或步骤310~316执行。
步骤317、从节点向主节点发送计算结果。
步骤318、主节点接收p个从节点发送的p个计算结果。
步骤319、主节点根据p个计算结果得到待处理矩阵m*n和待处理n维列向量相乘的计算结果。
本发明实施例所提供的数据处理方法,主节点根据从节点的个数p将待处理矩阵m*n划分成p个待处理矩阵,向p个从节点的第i个从节点发送待处理n维列向量和p个待处理矩阵中第i个待处理矩阵;从节点接收主节点发送的待处理n维列向量和p个待处理矩阵中待处理矩阵,采用多线程并行计算待处理矩阵乘以待处理n维列向量,并得到计算结果,然后向主节点发送计算结果;主节点接收p个从节点发送的p个计算结果,并根据p个计算结果得到待处理矩阵m*n和待处理n维列向量相乘的计算结果。从本发明提供的技术方案可见,由于各个从节点并不是依次计算待处理矩阵中每一行向量与待处理n维列向量的乘积,而是采用多线程对主节点发送给自身节点的待处理矩阵和待处理n维列向量进行乘积计算,从而实现了待处理矩阵的每一行向量与待处理n维列向量相乘的并行计算,因此充分地利用了每个节点的计算能力,大幅度地减少了每个节点在计算待处理矩阵乘以待处理n维向量时所耗费的时间。
本发明实施例还提供一种mpi+cuda多粒度混合并行编程算法流程示意图,如图6所示,在mpi下首先进行任务划分,主进程通过mpi_scatterv函数将任务发送给从进程并自身也处理一部分任务,主进程和从进程处理任务的过程是一致的,因此以主进程的处理过程进行说明:
主进程将所要处理的任务存储在cpu上;
cpu通过cudamallocpitch函数和cudamemcpy2d函数发送到gpu上;
在cuda架构中gpu采用多线程计算所要处理的任务,并将处理结果发送到cpu上,然后释放掉自己的内存;
待主进程通过mpi_gatherv函数收集处理结果时,cpu再将处理结果通过从进程发送。
其中mpi框架部分主要程序如下所示:
cuda的主要程序如下:
本发明实施例提供一种主节点,如图7所示,该主节点4包括:
划分模块41,用于将根据从节点的个数p待处理矩阵m*n划分成p个待处理矩阵。
第一发送模块42,用于向p个从节点的第i个从节点发送待处理n维列向量和p个待处理矩阵中第i个待处理矩阵,以使第i个节点采用多线程并行计算第i个待处理矩阵乘以待处理n维列向量,得到第i个计算结果;其中,i=1、2…p。。
第一接收模块43,用于接收p个从节点发送的p个计算结果。
处理模块44,用于根据p个计算结果得到待处理矩阵m*n和待处理n维列向量相乘的计算结果。
进一步,划分模块41,具体用于根据节点的个数p将待处理矩阵m*n按行依次划分成包含
第一发送模块42,具体用于当i≤m%p时,向p个从节点中第i个从节点发送待处理n维列向量和p个待处理矩阵中包含
本发明实施例所提供的主节点,根据从节点的个数p将待处理矩阵m*n划分成p个待处理矩阵;向p个从节点的第i个从节点发送待处理n维列向量和p个待处理矩阵中第i个待处理矩阵,以使第i个节点采用多线程并行计算第i个待处理矩阵乘以待处理n维列向量,得到第i个计算结果;接收p个从节点发送的p个计算结果,得到待处理矩阵m*n和待处理n维列向量相乘的计算结果。从本发明提供的技术方案可见,由于各个从节点并不是依次计算待处理矩阵中每一行向量与待处理n维列向量的乘积,而是采用多线程对主节点发送给自身节点的待处理矩阵和待处理n维列向量进行乘积计算,从而实现了待处理矩阵的每一行向量与待处理n维列向量相乘的并行计算,因此充分地利用了每个节点的计算能力,大幅度地减少了每个节点在计算待处理矩阵乘以待处理n维向量时所耗费的时间。
在实际应用中,所述划分模块41、第一发送模块42、第一接收模块43、处理模块44均可由主节点中的cpu、微处理器(microprocessorunit,mpu)、数字信号处理器(digitalsignalprocessor,dsp)或现场可编程门阵列(fieldprogrammablegatearray,fpga)等实现。
本发明实施例提供一种从节点,如图8所示,该从节点5包括:
第二接收模块51,用于从节点接收主节点发送的待处理n维列向量和p个待处理矩阵中第j个待处理矩阵。其中,j=1或2…或p;p个待处理矩阵是主节点根据从节点的个数p将待处理矩阵m*n按行划分成的。
计算模块52,用于采用多线程并行计算第j个待处理矩阵乘以待处理n维列向量,并得到第j个计算结果。
第二发送模块53,用于向主节点发送第j个计算结果。
进一步,在图8对应的实施例的基础上,本发明实施例提供另一种从节点,如图9所示,当待处理矩阵包含
第一存储单元521,用于将待处理矩阵采用内存对齐的方式存储于自身节点的预设存储空间中;其中,预设存储空间为自身节点中所有线程都能够访问的存储空间。
第二存储单元522,用于将待处理n维列向量存储于预设存储空间中。
预处理单元523,用于开启
第一控制单元524,用于并行控制
第二控制单元525,用于并行控制
处理单元526,用于获取计算结果中
进一步,当待处理矩阵包含
第一控制单元524,还用于并行控制
第二控制单元525,还用于并行控制
处理单元526,还用于获取计算结果中
进一步,第一控制单元524,具体用于:
在
并行控制第m个线程块中n个线程的第p个线程从预设存储空间中获取待处理矩阵的第m行向量的第p个元素和待处理n维列向量的第p个元素;其中,p=1、2…n。
第二控制单元525,具体用于:
并行控制第m个线程块中n个线程的第p个线程计算待处理矩阵的第m行向量的第p个元素乘以待处理n维列向量的第p个元素,得到第m个子计算结果中第p个基本计算结果。
获取第m个子计算结果中n个基本计算结果并相加,得到第m个子计算结果。
进一步,第一控制单元524,具体还用于:
在
并行控制第k个线程块中n个线程的第q个线程从预设存储空间中获取待处理矩阵的第k行向量的第q个元素和待处理n维列向量的第q个元素;其中,q=1、2…n。
第二控制单元525,具体还用于:
并行控制第k个线程块中n个线程的第q个线程计算待处理矩阵的第k行向量的第q个元素乘以待处理n维列向量的第q个元素,得到第k个子计算结果中第q个基本计算结果。
获取第k个子计算结果中n个基本计算结果并相加,得到第k个子计算结果。
本发明实施例所提供的从节点,接收主节点发送的待处理n维列向量和p个待处理矩阵中待处理矩阵;采用多线程并行计算待处理矩阵乘以待处理n维列向量,并得到计算结果;向主节点发送计算结果。从本发明提供的技术方案可见,由于各个从节点并不是依次计算待处理矩阵中每一行向量与待处理n维列向量的乘积,而是采用多线程对主节点发送给自身节点的待处理矩阵和待处理n维列向量进行乘积计算,从而实现了待处理矩阵的每一行向量与待处理n维列向量相乘的并行计算,因此充分地利用了每个节点的计算能力,大幅度地减少了每个节点在计算待处理矩阵乘以待处理n维向量时所耗费的时间。
在实际应用中,所述第二接收模块51、计算模块52、第一存储单元521、第二存储单元522、预处理单元523、第一控制单元524、第二控制单元525、处理单元526、第二发送模块53均可由位于从节点中的cpu、mpu、dsp或fpga等实现。
本发明实施例还提供一种主节点,该主节点包括第一存储器、第一处理器以及存储在第一存储器上并可在第一处理器上运行的计算机程序,第一处理器执行计算机程序时实现的步骤包括:
根据从节点的个数p将待处理矩阵m*n按行划分成p个待处理矩阵;
向p个从节点的第i个从节点发送待处理n维列向量和p个待处理矩阵中第i个待处理矩阵,以使第i个节点采用多线程并行计算第i个待处理矩阵乘以待处理n维列向量,得到第i个计算结果;其中,i=1、2…p。
接收p个从节点发送的p个计算结果。
根据p个计算结果得到待处理矩阵m*n待处理n维列向量相乘的计算结果。
进一步,上述第一处理器执行计算机程序时实现的步骤具体包括:
根据节点的个数p将待处理矩阵m*n按行依次划分成包含
进一步,上述第一处理器执行计算机程序时实现的步骤具体包括:
当i≤m%p时,向p个从节点中第i个从节点发送待处理n维列向量和p个待处理矩阵中包含
当i>m%p时,向p个从节点中第i个从节点发送待处理n维列向量和p个待处理矩阵中包含
本发明实施例还提供一种从节点,该从节点包括第二存储器、第二处理器以及存储在第二存储器上并可在第二处理器上运行的计算机程序,第二处理器执行计算机程序时实现的步骤包括:
从节点接收主节点发送的待处理n维列向量和待处理矩阵;其中,待处理矩阵是主节点根据从节点的个数p将待处理矩阵m*n按行划分成p个待处理矩阵中的一个。
采用多线程并行计算待处理矩阵乘以待处理n维列向量,并得到计算结果。
向主节点发送计算结果。
进一步,当待处理矩阵包含
将待处理矩阵采用内存对齐的方式存储于自身节点的预设存储空间中;其中,预设存储空间为自身节点中所有线程都能够访问的存储空间;
将待处理n维列向量存储于预设存储空间中。
开启
并行控制
并行控制
获取计算结果中
上述第二处理器执行计算机程序时实现的步骤具体包括:
在
并行控制第k个线程块中n个线程的第p个线程从预设存储空间中获取待处理矩阵的第m行向量的第p个元素和待处理n维列向量的第p个元素;其中,p=1、2…n。
并行控制第k个线程块中n个线程的第p个线程计算待处理矩阵的第m行向量的第p个元素乘以待处理n维列向量的第p个元素,得到第m个子计算结果中第p个基本计算结果。
获取第m个子计算结果中n个基本计算结果并相加,得到第m个子计算结果。
进一步,当待处理矩阵包含
将待处理矩阵采用内存对齐的方式存储于自身节点的预设存储空间中;其中,预设存储空间为自身节点中所有线程都能够访问的存储空间。
将待处理n维列向量存储于预设存储空间中。
开启
并行控制
并行控制
获取计算结果中
进一步,上述第二处理器执行计算机程序时实现的步骤具体还包括:
在
并行控制第k个线程块中n个线程的第q个线程从预设存储空间中获取待处理矩阵的第k行向量的第q个元素和待处理n维列向量的第q个元素;其中,q=1、2…n。
并行控制第k个线程块中n个线程的第q个线程计算待处理矩阵的第k行向量的第q个元素乘以待处理n维列向量的第q个元素,得到第k个子计算结果中第q个基本计算结果。
获取第k个子计算结果中n个基本计算结果并相加,得到第k个子计算结果。
虽然本发明所揭露的实施方式如上,但所述的内容仅为便于理解本发明而采用的实施方式,并非用以限定本发明。任何本发明所属领域内的技术人员,在不脱离本发明所揭露的精神和范围的前提下,可以在实施的形式及细节上进行任何的修改与变化,但本发明的专利保护范围,仍须以所附的权利要求书所界定的范围为准。
- 还没有人留言评论。精彩留言会获得点赞!