基于多视图联合嵌入空间的图像‑文本双向检索方法与流程
本发明涉及计算机视觉领域,尤其涉及一种基于多视图联合嵌入空间的图像-文本双向检索方法,通过学习得到多视图联合嵌入空间,实现双向图像-文本检索任务。该方法利用不同视图观察数据,获得数据在不同粒度下的语义关联关系,并通过融合排序方法进行融合,获得更精确的语义关联关系,使得检索结果更加准确。
背景技术:
随着计算机视觉领域研究的不断发展,出现了大批与图像-文本相关的任务,如图片说明(imagecaption),图片描述(densecaption),以及视觉问题回答(visualquestionanswering)等。所有这些任务都要求计算机充分理解图像和文本的语义信息,并通过学习能够将一种模态数据的语义信息翻译到另一个模态,因此,该类任务的核心问题是如何弥合两种不同模态在语义层面上的差距,找到沟通两种模态数据的方法。不同模态的数据存在于异构的空间中,因而想要直接通过计算数据之间的距离来度量它们的语义相似度是不现实的。为了解决这一问题,目前的主流方法是对两种数据进行变形得到同构的特征,从而将数据嵌入到一个共同的空间,这样它们可以直接被比较。针对使用何种特征表示数据和使用何种方法将数据嵌入到共同空间中,研究者们做了大量的工作。
考虑到一些由深度学习得到的特征在许多计算机视觉领域的任务上取得了很好的成绩,大量的研究者使用这些特征来表示图像或文本,并将它们转化成同构形式从而可以将数据映射到共同空间来完成图像-文本检索任务。然而,这些学习得到的特征仅仅提供了数据全局层面的信息而缺少局部信息的描述,因此只用这些特征来表示数据是无法挖掘更细粒度的数据之间的关联性的,比如图像的区域和文本中的短语之间的关联关系。另一类方法是将图像和文本都切分成小的部分,将它们投影到一个共同的空间,以便于从细粒度的数据中捕捉到局部语义关联信息。
尽管上述方法在某些方面已经取得了很好的表现,但仅仅从单一的视角,即局部视角或全局视角,观察语义关联是无法获得两种模态数据之间全面完整的关联关系的。亦即,同时获得上述两种视角观察得到的语义关联并加以合理利用有利于综合理解数据的语义信息并获得精确的检索结果。但目前尚无能同时获得不同视角的异构数据关联关系,并对这些关系加以融合得到数据之间最终的语义相似度的方法。
技术实现要素:
为了克服上述现有技术的不足,本发明提供一种基于多视图联合嵌入空间的图像-文本双向检索方法,通过结合全局层面和局部层面的信息来完成图像-文本检索任务,从画面-句子视图和区域-短语视图下观察数据,获得全局层面和局部层面的语义关联关系,然后通过融合这两种语义关联关系得到一个精准的语义理解。
本发明的原理是:现有的图像和文本语义信息的获取和理解的方法在某些方面已经取得了很好的表现,但是,现有仅仅从单一的视角观察语义关联的方法是无法获得两种模态数据之间全面完整的关联关系的。本发明通过结合全局层面和局部层面的信息来完成图像-文本检索任务,即融合上述两种视角观察得到的语义关联,获得更全面准确的语义关联关系,将有利于综合理解数据的语义信息并获得精确的检索结果。本发明提出基于多视图联合空间学习框架分成三个部分:画面-句子嵌入模块、区域-短语嵌入模块,以及多视图融合模块。在画面-句子视图嵌入模块中,将一帧图片或文本中的一个完整句子视为基本单位,通过已有的预先训练好的模型获得两种模态数据(即图像数据和文本数据)富含语义信息的特征,利用双分支神经网络学习两组特征的同构特征,这些特征向量使得图像和文本数据能够被映射到共同的空间中。与此同时,在对双分支神经网络进行训练的过程中,需要保持数据之间原有的关联关系,即语义相似度,之后尝试将这种关联关系在全局层面的子空间中通过可计算得到的距离保存下来。在区域-短语视图嵌入模块中,将每一幅画面和每一个句子分别切分成区域和短语,然后使用已有的特征提取方法提取这些局部数据包含语义信息的特征,将它们送入到另一个双分支神经网络中,同样获得保持了语义相似度的同构特征和一个嵌入了细粒度数据并可以直接计算距离的局部层面子空间,以便于探索这些细粒度数据之间的关联关系。
在这两个模块中,为了将异构数据嵌入到共同空间中,两个视图中均采用双分支的神经网络,分别用一个分支处理一个模态的数据,使其变成同构的可进行比较的特征。每一分支的神经网络分别由两层全连接层构成。两个视图中的双分支神经网络结构相同,但是针对不同训练数据训练之后,两个神经网络可以分别针对画面-句子数据,和区域-短语数据提取特征并保留不同视图下的语义关联关系。本发明使用数据向量之间的内积来计算距离,并以此表示数据之间的相似度,并且在训练期间,为了保存语义关联信息,使用了一系列的约束条件来保证语义相关的数据在这一共同空间中有着更邻近的位置关系。
在多视图融合模块中,我们通过按比例结合前两个视图中计算得到的距离来计算图像和文本数据之间在多视图联合空间中的距离。这一最终的距离能够更精确的显示出数据之间的语义相似度,并且可以作为检索任务的排序依据。需要注意的是,在执行检索任务的过程中,可以单独利用一个视图的语义关联关系进行检索,也可以使用多视图融合后的语义关联关系进行检索,在后续的实验结果中,可以说明多视图融合后得到的语义相似度更能准确的反应数据之间的语义关联关系。
本发明提供的技术方案是:
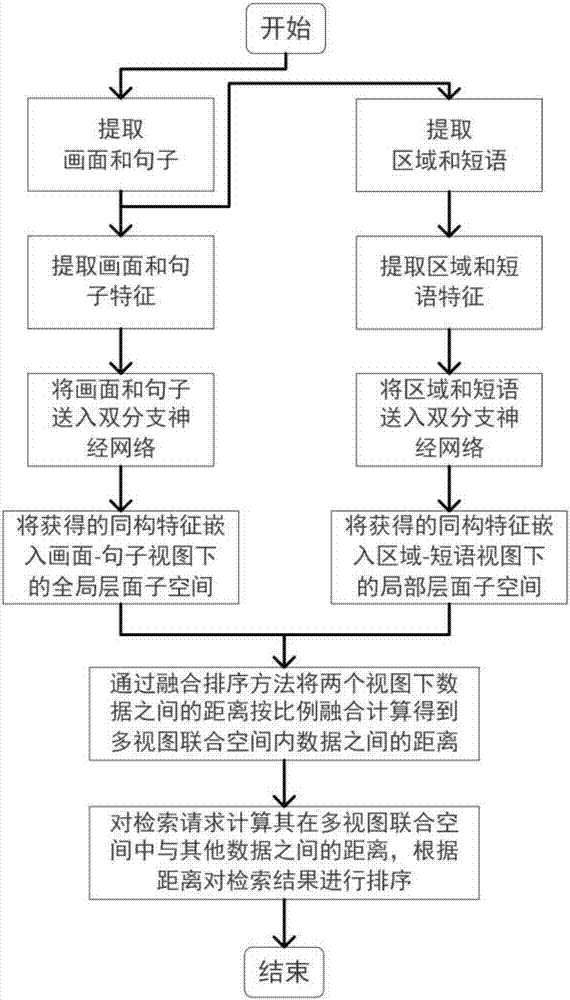
一种基于多视图联合嵌入空间的图像-文本双向检索方法,通过结合全局层面和局部层面的信息进行图像-文本双向检索;针对数据集d={d1,d2,…,d|d|},数据集中每一个文档di包括一张图片ii和一段相关的文本ti,di=(ii,ti),每一段文本由多个句子组成,每一个句子都独立地对相匹配的图片进行描述;在画面-句子视图中,设定fi代表训练图像ii的一幅画面,{si1,si2,…,sik}代表ti中的句子集合,k是文本ti中句子的个数;在区域-短语视图中,设定rim代表画面fi提取出的第m个区域,pin代表文本ti中的句子提取出的第n个短语;本发明方法首先从画面-句子视图和区域-短语视图下观察数据,分别获得全局层面和局部层面的语义关联关系,然后通过融合这两种语义关联关系得到一个精准的语义理解;具体包括如下步骤:
1)分别提取所有的图像的画面和所有文本中的句子,使用已有的19层vgg(visualgeometrygroup提出的神经网络结构)模型提取画面数据的cnn(convolutionalneuralnetwork)特征,使用已有的混合高斯-拉普拉斯混合模型(hglmm)提取句子数据的fv(fishervector)特征;
2)将步骤1)得到的两组特征(cnn特征和fv特征)分别送入双分支神经网络的两个分支中,经过训练得到画面和句子数据的同构特征,此时画面和句子被映射到全局层面子空间,并获得画面-句子视图下图像和文本数据的语义关联信息;
3)使用已有的fasterrcnn模型(fasterregion-basedconvolutionalnetwork)提取所有画面的区域rcnn特征,使用已有的standfordcorenlp语法分析器提取所有句子的短语依赖关系(dependencytriplet),保留含有关键信息的区域和短语特征;
4)将步骤3)得到的两组特征(rcnn特征和短语的依赖关系)分别送入另一个双分支神经网络的两个分支中,经过训练得到区域和短语数据的同构特征,此时区域和短语被映射到局部层面子空间,得到区域-短语视图下图像和文本数据的语义关联信息;
5)使用融合排序方法,将步骤2)和步骤4)得到的不同视图下图像和文本数据的语义关联信息融合起来,计算得到多视图下图像和文本数据在多视图联合空间内的距离,该距离用于度量语义相似度,在检索过程中将其作为排序标准;
6)对检索请求计算得到该检索请求数据在多视图联合空间中与数据集d中另一模态数据(图像或文本)之间的距离(即多视图下图像和文本数据在多视图联合空间内的距离),根据距离对检索结果进行排序;
由此实现基于多视图联合嵌入空间的图像-文本双向检索。
与现有技术相比,本发明的有益效果是:
本发明提供一种基于多视图联合嵌入空间的图像-文本双向检索方法,通过学习得到多视图联合嵌入空间,实现双向图像-文本检索任务。该方法利用不同视图观察数据,获得数据在不同粒度下的语义关联关系,并通过融合排序方法进行融合,获得更精确的语义关联关系,使得检索结果更加准确。具体地,本发明使用双分支神经网络分别将图像和文本数据映射到画面-句子视图的全局层面子空间和区域-短语视图的局部层面子空间,获得全局层面和局部层面的语义关联关系,根据这两组语义关联关系可以单独完成图像-文本双向检索任务,但所得到的检索结果并不全面。本发明提出多视图融合排序方法,将两个视图下的语义关联关系融合在一起,共同计算数据之间在多视图联合空间中的距离,得到的数据之间的距离关系能够更精准的反应数据的语义相似度,使得检索结果的准确度更高。具体地,本发明具有如下技术优势:
(一)本发明从多个视图观察不同模态数据之间的高层语义关联关系,并将这些关联关系融合在一起形成多视图下的语义关联关系,而现有图像-文本检索方法没有此考虑;采用本发明方法可以学习到数据在不同粒度下存在的语义信息,从而能有效的提取更精确的语义信息,获得准确度更高的检索结果;
(二)本发明使用融合排序方法能够将不同视图的语义关联关系融合在一起,使得数据在多视图联合空间中的相对距离能够很好地综合不同视图下的语义关系,最终获得更精确的语义相似度;
(三)本发明采用双分支神经网络,其作用在于不同模态的数据其特征是异构的,无法直接进行比较或计算距离,通过双分支神经网络,每一分支处理一个模态的数据,将不同模态的数据变形成为同构特征,使异构数据同时存在于一个共同空间,可以直接计算距离;
(四)本发明采用一系列约束条件,为了获得同构特征,利用双分支神经网络对数据进行转换,但是在转换过程中,数据原有的语义关系需要得到保留;利用基于间隔的随机损失函数将语义相关数据之间的距离与语义无关数据之间的距离范围拉开间隔,确保在共同空间中数据之间的语义相似度信息得到保留。
附图说明
图1是本发明中基于多视图联合嵌入空间进行图像-文本双向检索的流程框图。
图2是本发明实施例中多视图联合嵌入空间学习过程的示意图;
其中,vgg是19层vgg模型,提取画面的cnn特征,hglmm是混合高斯-拉普拉斯混合模型(hybridgaussian-laplacianmixturemodel)提取句子的fishervector特征,rcnn是fasterrcnn模型提取区域的rcnn特征,parser是standfordcorenlp语法分析器提取短语的依赖三元组。神经网络均由两层全连接层组成,每个视图下的两个神经网络组成双分支神经网络。
图3模态间一致性与模态内一致性示意图;
其中,(a)为模态间一致性表示,(b)为模态内一致性表示。
图4是本发明实施例提供的采用本发明方法在pascal1k数据集下得到的图像-文本检索结果。
具体实施方式
下面结合附图,通过实施例进一步描述本发明,但不以任何方式限制本发明的范围。
本发明提供一种基于多视图联合嵌入空间的图像-文本双向检索方法,通过结合全局层面和局部层面的语义关联关系进行检索;先从画面-句子视图和区域-短语视图下分别获得全局和局部层面的语义关联关系,在画面-句子视图中,将画面和句子嵌入到全局层面的子空间中获取画面和句子的语义关联信息;在区域-短语视图中,提取画面的每一个区域和句子的每一个短语,嵌入到局部层面的子空间中获取区域和短语的语义关联信息;两个视图中均通过双分支的神经网络处理数据得到同构特征嵌入共同空间,在训练中使用约束条件保留数据原有的语义关系;再通过多视图融合排序方法融合两种语义关联关系得到数据之间更精准的语义相似度。
我们利用数据集d={d1,d2,…,d|d|}对图像-文本检索问题加以描述,在这一数据集中,每一个文档包括一张图片和一段相关的文本,如di=(ii,ti),每一个文本由若干个句子组成,每一个句子都独立地对相匹配的图片进行描述。在画面-句子视图中,我们用fi代表训练图像ii的一幅画面,用{si1,si2,…,sik}代表ti中的句子集合(k是文本ti中句子的个数)。在区域-短语视图中,我们用rim代表画面fi提取出的第m个区域,用pin代表文本ti中的句子提取出的第n个短语。接下来我们将详细描述两个视图中使用的约束条件,以及最后多视图融合模块的融合排序方法。
1、画面-句子视图
我们将画面和句子分别送入双分支神经网络中,并且获得在全局层面子空间的同构特征。在训练神经网络的过程中,为了保留模态间一致性和模态内一致性,我们提出了基于间隔的随机损失函数。为了将数据放入画面-句子视图中进行处理,我们做了如下特征提取:
对于图像,我们使用19层vgg模型提取得到的4096维cnn特征(向量)作为画面的原始特征;对于文本,我们使用混合高斯-拉普拉斯混合模型(hybridgaussian-laplacianmixturemodel,hglmm)提取得到的fishervector(fv)特征(向量)作为句子的原始特征,为了计算方便,我们用pca(principalcomponentsanalysis,主成分分析)将最初的18000维fv特征向量降维至4999维。
1)模态间一致性
对于训练画面fi,所有的句子可以分成两个集合,一个集合包含了所有与训练画面匹配的句子,一个集合包含了所有与训练画面不匹配的句子。我们可以推测出一个合理的一致性要求,即在画面-句子视图中,画面fi和在匹配集合中的句子之间的距离必须比画面fi和在不匹配集合中的句子之间的距离小,且距离的差距需要大于间隔m。具体数学表示如式(1):
d(fi,six)+m<d(fi,sjy)ifi≠j(1)
式(1)中,d(fi,six)表示画面fi与在其匹配集合中的句子six之间的距离;d(fi,sjy)表示画面fi与在其不匹配集合中的句子sjy之间的距离。
类似的约束可以应用在训练句子six上:
d(fi,six)+m<d(fj,six)ifi≠j(2)
式(2)中,d(fi,six)表示句子six与在其匹配集合中的画面fi之间的距离;d(fj,six)表示句子six与在其不匹配集合中的画面fj之间的距离。
2)模态内一致性
在训练过程中,除了考虑到数据的模态间一致性,我们还需要针对数据集中同一画面伴随的若干个句子做一些约束,我们称之为模态内一致性。具体来说,对于共享相同含义即描述相同画面的句子而言,他们需要紧密的联系在一起,并且能够与其他的句子区分开来。
为了实现模态内一致性,我们使用了如下约束:
d(six,siy)+m<d(six,sjz)ifi≠j(3)
式(3)中,d(six,siy)表示描述同一个画面fi的句子six与siy之间的距离;d(six,sjz)表示描述画面fi的句子six与描述画面fj的句子sjz之间的距离。
尽管我们应该对画面作出类似公式(3)的约束,即描述同一个句子的画面之间的距离应该更近,但目前我们使用的数据集中,还难以确定若干画面是否描述了相同的句子,因此我们不采用这一项约束,而只对描述同一个画面的句子之间的距离进行公式(3)的约束。
结合上述的约束条件,我们最终总结出了在画面-句子视图上的损失函数:
这里,间隔m可以根据所采用的距离作出调整,为了便于优化,在这里我们将其固定为m=0.1并将它应用在所有的训练样本中,与此同时,通过实验我们发现当λ1=2且λ2=0.2时我们能够获得最好的实验结果。
2、区域-短语视图
在这一视图中,我们希望能够挖掘存在于区域和短语之间的细粒度语义关联关系。我们通过已有的模型提取得到区域和短语特征,对于区域,我们提取画面中得分最高的19个区域的4096维rcnn特征;对于短语,我们利用语法分析器得到依赖树结构,并选择包含关键语义信息的短语。我们用1-of-k编码向量w来代表每一个单词,并将pjy用依赖关系三元组(r,w1,w2)表示的短语映射到嵌入空间中,如式(5):
式(5)中,we是一个400000×d的矩阵,用于将1-of-k向量编码成一个d维的单词向量,其中400000是字典的单词数目,这里我们设定d=200。注意每一个关系r都有单独的权重wr和偏移量br,并且每一个句子提取的短语数是不一样的。
在这个视图中,我们利用双分支神经网络将图像和文本数据射到区域-短语视图的局部子空间中。在训练网络的过程中,我们要求在匹配的图像文本对中的区域和短语之间的距离要比在不匹配对中的区域和短语之间的距离小。在计算这一视图下的数据映射到局部层面子空间的损失函数表示如下:
ψregion-phrase=∑i,j,x,yκijmax[0,1-ηij×d(rix,pjy)](6)
式(6)中,d(rix,pjy)表示区域rix和短语pjy之间的距离,我们定义ηij在i=j的时候等于+1,在i≠j时等于-1,常量κij用于根据ηij的正负个数进行归一化。
3、多视图融合模块
在画面-句子嵌入模块和区域-短语嵌入模块分别通过学习得到各自的嵌入空间之后,我们可以借助这两个空间中的信息来获得多视图下的数据间距离。为了获得图像ii和文本tj之间更精确的语义相似度,我们按比例结合前两个视图下计算得到的距离作为多视图联合空间中两个数据之间的最后距离:
dmulti-view(ii,tj)=dframe-sentence(ii,tj)+λdregion-phrase(ii,tj)(7)
式(7)中,dframe-sentence(ii,tj)表示图像ii和文本tj之间在画面-句子视图中的距离,dregion-phrase(ii,tj)表示图像ii和文本tj之间在区域-短语视图中的距离,dmulti-view(ii,tj)表示图像ii和文本tj之间在多视图融合后的距离。权重λ用于平衡画面-句子视图和区域-短语视图距离的比例,经过实验,我们发现λ=0.6能够产生很好的效果。
图1为多视图联合嵌入空间学习框架流程图。
图2展示了本发明提出的学习框架示意图。该框架分三个部分,画面-句子视图中,我们将画面和句子嵌入到全局层面的子空间中。在区域-短语视图中,我们提取画面和句子中小的成分,将这些成分嵌入到局部层面的子空间中。每一个视图中,我们都用双分支的神经网络处理数据以使它们变成同构特征嵌入共同空间。在多视图融合模块,提出了多视图融合排序方法来融合两个视图分析得到的语义关联信息得到数据之间最终的距离关系。
图3展示了在画面-句子视图下模态间一致性(左)和模态内一致性(右)的示意图。正方形代表画面,圆形代表句子,相同颜色的图像表示的是同一个语义信息。模态间一致性含义为在画面-句子视图中,一个画面(黑色正方形)和与其匹配的句子(黑色圆形)之间的距离必须比该画面(黑色正方形)和与其不匹配的句子(灰色圆形)之间的距离小,此约束对句子同样适用。模态内一致性含义为在画面-句子视图中,一个句子(黑色正方形)和与其语义相近的句子(其他黑色正方形)之间的距离必须比该句子(黑色正方形)和与其语义无关的句子(灰色正方形)之间的距离小。
图4展示了一个图像-文本检索的实际案例,分别给出了画面-句子视图,区域-短语视图和多视图在针对左上角图像返回的前五个句子的检索结果,正确的检索结果用加粗表示。在这个例子中,我们可以看出,画面-句子视图仅仅能检索到全局层面理解后的句子,但是由于它不能辨别区域中的内容,所以会把正确匹配的句子和一些有相似含义但并包括不正确个体的句子混淆。对于区域-短语视图,它返回了一些包含有正确的个体但个体之间关系不准确的句子。比如这一视图下的第三个句子,它可以辨认出‘ayounggirl’,但是却误解了女孩和自行车之间的关系是‘riding’,最终返回了一个错误的句子。但是在融合后的多视图中,它可以同时捕捉到全局层面的语义关联关系和局部层面的语义关联关系,因而多视图的检索效果是准确度最高的。
表1实施例中图像-文本双向检索结果
表1给出了本发明在在pascal1k和flickr8k上通过图像-文本检索和文本-图像检索进行实验验证的结果。为了评价检索效果,我们遵循了标准的排序度量标准,使用recall@k,即正确匹配的数据排在前k(k=1,5,10)个检索结果中的概率,来对检索准确性进行度量。图中列出了本发明与其他现有先进算法的效果比较,包括sdt-rnn(semanticdependencytrees-recurrentneuralnetworks,语义依赖树-循环神经网络),kcca(kernelcanonicalcorrelationanalysis,核典型相关分析),devise(deepvisual-semanticembedding,深度视觉语义嵌入),dcca(deepcanonicalcorrelationanalysis,深度典型相关分析),vqa-a(visualquestionanswering-agnostic,视觉问题回答不可知论),dfe(deepfragmentembedding,深度片段嵌入)。
从表1我们可以看出,本发明方法和其他对比方法相比较而言效果更好。此外,我们还分别展示了两种单独视图的检索效果和多视图融合后的检索效果,从数据中可以看出,结合两个视图之后的多视图融合方法检索效果更好。这一结果证明了单独的两个视图之间彼此是互补的关系,所以将二者结合起来之后可以获得更精准全面的语义关联,检索效果会更好。
需要注意的是,公布实施例的目的在于帮助进一步理解本发明,但是本领域的技术人员可以理解:在不脱离本发明及所附权利要求的精神和范围内,各种替换和修改都是可能的。因此,本发明不应局限于实施例所公开的内容,本发明要求保护的范围以权利要求书界定的范围为准。
- 还没有人留言评论。精彩留言会获得点赞!