基于局部聚类比例排序的高光谱波段选择方法与流程
本发明属于图像处理技术领域,主要涉及高光谱图像的波段选择,具体是一种基于局部聚类比例排序的高光谱波段选择方法。用于对高光谱图像的波段选择。
背景技术:
高光谱图像由于其特征(光谱响应值)的高维性,使得在存储、传输、分析等等诸多方面都有很大的限制,人们自然地寻求特征选择或者特征提取等方法来降低高光谱数据带来的hughes现象。高光谱图像的降维可以在原始的光谱空间上进行,也可以通过线性、非线性变化转换到其他空间进行。波段选择属于前者,它选出的是一个物理意义明显的波段子集,其优势在于能够更好地保留特征的物理意义。
在论文“anovelranking-basedclusteringapproachforhyperspectralbandselection”(ieeetransactionsongeoscienceandremotesensing,2016,54(1):88-102)中,jias,tangg,zhuj等人提出了一种基于波段密集度聚类并且分配等级的波段选择算法——增强的快速的基于密度峰值点的聚类算法(e-fpdc)。该方法需要获得每个波段的密度信息以及与具有更高密度的波段之间的最短距离这两个信息,利用两者的结合为波段分配等级,它结合了基于聚类的方法和基于等级排序的方法的优点,在分类正确率上能够达到较好的效果。
但是该方法也存在一些缺点,比如它没有考虑到噪声的影响,将波段每一维度上的差别都计入到相似度的度量中,缺乏噪声鲁棒性;同时它是一种静态的分配等级的方法,在高光谱数据给定之后,每个波段的等级就是确定不变的,选择的波段缺乏多样性。
技术实现要素:
为了克服上述技术的不足,本发明提出了一种提高保留波段分类性能的一种基于局部聚类比例排序的高光谱波段选择方法。其特征在于,包括有如下步骤:
(1)输入数据及参数:高光谱图像原始数据ι∈rm×n×d,其中m,n分别表示图像的长与宽,d表示波段数目,将高光谱图像i展开成一个二维矩阵d={x1,x2,...,xd},其中xi表示一个m×n维的向量,即一个波段,1≤i≤d;输入的参数有:预期选择的波段数k,相似度阈值参数th1,聚类阈值参数th2;
(2)计算波段之间的相似度矩阵:利用相似度阈值参数th1和高光谱数据d来计算阈值向量diff之后,根据波段之间距离和阈值向量来计算波段之间的相似度,再将其呈现为矩阵的形式;
(3)波段聚类:对于第i波段,根据聚类阈值参数th2为其分配最大可聚类距离maxdisi,如果其他波段中与之距离小于maxdisi,则表示两个波段可以聚为一类,否则,两个波段不能聚为一类;
(4)分配等级,动态地加入最终解集:计算聚类后每个波段的局部信息与全局信息的比值,作为波段的等级;降序排序之后动态地选入初始化为空的集合,直到集合大小为k,方法结束;将结束后的解集作为高光谱波段选择的结果,即选出的波段集合。
本发明通过重新计算相似度矩阵来减少噪声对波段相似度的影响,增加了鲁棒性,还调整了聚类准则与选择波段的方式使得波段之间的相关性降低;从分类精度这方面比较现有技术,有所提高。
本发明与现有技术相比有以下优点:
第一,由于本发明在计算相似度矩阵时根据整体的数据分布情况注意到忽略细小的差别而忠实于较大的距离,因此得到的距离衡量更能够真实地体现波段之间的差异,对于噪声有一定的鲁棒性。
第二,本发明为每一个波段独立分配一个最大可聚类的距离,相对于现有方法的整体分配一个阈值距离而言更具有针对性,可以使得聚类的性能得到一定的提高。
第三,本发明将等级分配动态调整,使得选入波段的区间在整体上分布均匀,避免了选入具有冗余信息的波段,使得分类性能,尤其当预期保留数目较少时,相较于现有技术有一定提高。
附图说明
图1:本发明的详细流程图;
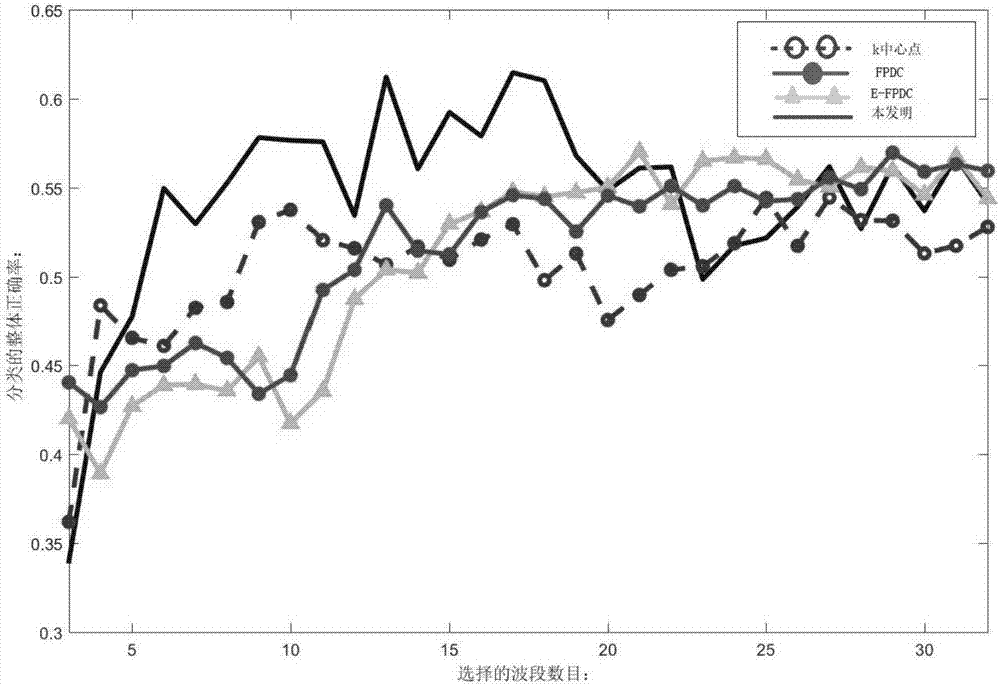
图2:本发明与其他现有技术在indianpines以及paviauniversity数据集上保留不同波段数目后的分类正确率曲线的对比图。其中图2(a)是indianpines上的分类精度与保留波段之间的关系,而图2(b)是paviauniversity上的分类精度与保留波段之间的关系,图2(a)和图2(b)中不同形式的曲线代表不同的方法,而相同的代表同样的方法。
具体实施方式
下面结合附图1对本发明做进一步的描述。
实施例1
现有高光谱图像波段选择方法存在一些缺点,比如它们没有考虑到波段之中因为噪声而造成的误差,过多地依赖聚类方法,没有动态地调整选择策略等。为了解决以上难点,本发明提出一种基于局部聚类比例排序的高光谱波段选择方法,参见图1,包括有如下步骤:
(1)输入数据及参数:输入高光谱图像原始数据ι∈rm×n×d,其中m,n分别表示图像的长与宽,d表示波段数目。将高光谱图像i展开成一个二维矩阵d={x1,x2,...,xd},其中xi表示一个mn维的向量,即一个波段,1≤i≤d;输入的参数有:预期选择的波段数k,相似度阈值参数th1,聚类阈值参数th2。这些参数都是人为设定,可以根据经验以及实验结果的性能,在本例中将相似度阈值参数th1设置为0.01,将聚类阈值参数th2设置为0.17,预期选择的波段数目k设置为在3-32之间变化。
(2)计算波段之间的相似度矩阵:利用相似度阈值参数th1和高光谱数据d来计算阈值向量diff之后,根据阈值向量diff和波段(d中的行向量)之间的欧式距离来计算波段之间的相似度,再将其呈现为矩阵的形式。
本步骤中计算波段之间的相似度矩阵不是同现有方法一样仅根据数据d来计算,现有方法直接使用两个波段向量的欧式距离作为相似度,这样的做法虽然简单直观,但是缺乏针对噪声的处理。而在高光谱图像中,噪声广泛存在且具有随机性,在图像积的空域(图像像素点数目共有mn个)累加起来的误差会使得波段之间的真实关系无法被正确衡量。
(3)波段聚类:对于第i波段,根据聚类阈值参数th2为其分配最大可聚类距离maxdisi,如果其他波段中与之距离小于等于maxdisi,则表示两个波段可以聚为一类;否则,两个波段不能聚为一类。
这样的分配策略更有针对性,而不像现有方法考虑所有的距离对。因为如果有很多分布密集的点,就会使得聚类策略过于严格,有些波段可能无法正确聚类,甚至成为孤立点。
(4)分配等级,动态地加入最终解集:计算聚类后每个波段的局部信息与全局信息的比值,作为波段的等级;降序排序等级之后动态地选入初始化为空的解集ss,即每次选择一个波段之后,要降低该波段的临近波段的等级,本例中将其临近波段的等级降为0,之后再次按照新的波段等级排序选择下一个波段进入解集,直到解集的大小为k,方法结束。将结束后的解集ss作为高光谱波段选择的结果,完成波段选择任务。
本发明是针对高光谱图像(hyperspectralimagery)波段选择问题的一种基于局部聚类比例排序的高光谱波段选择方法。由于高光谱图像波段多,而人工获取标记样本代价大,寻求特征(波段)选择的方法来降低高光谱图像的维度显得尤为重要。本发明提出一种结合聚类算法与等级排序算法的新颖波段选择方法,可以有效解决高光谱数据的存储及分析问题,实验证明在分类精度上与现有方法相比有更好的效果。
实施例2
基于局部聚类比例排序的高光谱波段选择方法同实施例1,具体包括有以下步骤:
2.1.根据展开为二维矩阵d的高光谱图像原始数据,为每个像素点i确定一个判断光谱值是否有变化的阈值diffi,将所有的波段的阈值按照像素点在d中的先后顺序拼接成一个向量diff:
diffi=th1×(max(di)-min(di))
其中,相似度阈值参数th1是第一步中输入的人为设定的参数,在实验中对于两个数据集(indianpines和paviauniversity)都设置为0.01;max(·)和min(·)分别表示对参数向量取最大值以及最小值;di表示展开成二维矩阵d后的高光谱图像中的第i列,意义为第i个像素点所有的光谱响应值组成的向量;diffi表示阈值向量的第i维度处的值。
2.2.确定阈值向量diff之后,再借助波段之间的欧氏距离来计算波段之间的相似度:
其中
本发明通过重新计算相似度矩阵,使得相似度矩阵对于噪声有一定的鲁棒性。由于高光谱图像的长与宽(m×n)较大,即覆盖的像素点较多,且噪声产生具有随机性,因此,如果不将差别较小的欧氏距离去除,在每个像素点上产生的误差会累加成较大的误差,为波段信息的衡量带来很大的影响。为此,本发明提出的解决方案对衡量波段信息较为有效。
实施例3
基于局部聚类比例排序的高光谱波段选择方法同实施例1-2,步骤3所述的波段聚类,具体包括有以下步骤:
3.1.根据聚类阈值参数th2来为每个波段分配一个独立的最大可聚类距离maxdisi,在本例的实验中,对于两个数据集(indianpines和paviauniversity)都将其设置为0.17,也可以根据经验取为0.2左右的值:
maxdisi=sorted(si,:)th2×d
其中sorted(·)index表示对·代表的向量升序排序之后,取索引为index处的值,而si,:表示使用步骤2中计算出的相似度矩阵的第i行的向量,物理意义为第i个波段与其他所有波段之间的距离的集合,将这些距离的集合升序排列之后,取索引为th2×d处的数作为第i波段的最大可聚类距离maxdisi,其中d表示高光谱图像的波段数。如果第i个波段与其他某波段之间的距离小于第i个波段所对应的最大可聚类距离,那么就认为该波段可以和第i个波段聚为一类,否则不能聚为一类。
3.2.得到每个波段的最大可聚类距离maxdis之后,用聚类矩阵l来表示两个波段之间的关系,即
其中maxdisi表示第i波段的最大可聚类距离,而sij表示相似度矩阵的第i行第j列处的值,如果lij=0,说明第i个波段和第j个波段不能聚为一类,而lij=1则说明可以聚成一类。
本发明对于不同的波段设计了不同的最大可聚类距离,可以更加客观地评价波段之间分布的密集程度。而现有方法,因为某一些波段分布十分密集而就会降低判断波段是否属于一类的距离,而使得聚类准则变得过于严格,使得有些波段无法正确聚类,甚至成为孤立点。
实施例4
基于局部聚类比例排序的高光谱波段选择方法同实施例1-3,步骤4中所述的的计算聚类后每个波段的局部信息与全局信息的比值,作为波段的等级;降序排序之后选入集合,作为最终的结果,具体包括有以下步骤:
4.1.首先定义局部信息以及全局信息:局部信息表示在第i波段的临近波段内可与之聚类的数目,全局信息表示在全部波段内可与第i波段聚类的数目。临近波段定义为与某波段的波段号差在d/2k之内的波段,其中d表示高光谱图像的总波段数,而k表示预期选择的波段数。
4.2.计算每个波段的局部信息与全局信息的比值,作为波段的等级;即为所有波段赋值等级为它的局部信息与全局信息的比值,并认为应该优先选择拥有较高比值的波段;如果这个比值较低,一般来说有两种情况:a.局部可聚类的波段(分子)较少,这样的波段本身密度较小,所包含的信息不属于重要信息,难以用较少的这种波段来代表整个数据的分布;b.全局可聚类波段(分母)较多,这样的波段或许包含了很多波段的信息,与很多波段相似性较高,但是它可以看做是位于两个簇之间相连的部分,综合了两个簇的信息,也是不利于区分数据的。
4.3.初始化最终解集ss为空集,得到等级的降序排序之后,可以动态地选择波段进入集合ss,直到最终解集中的波段数目达到k,方法结束,返回解集ss即完成波段选择任务。由于临近的波段之间的比值可能会十分接近,因此,在选择一个波段进入最终解集之后,要降低它临近波段的等级之后,利用新的等级排序进行下一次选择,在本例的实验中的做法是将临近波段的等级降为0。
本发明在这一步骤中选出的波段的整体区间是均匀分布的,而选出的波段在自己的区间上有最高的等级。因此可以在一定程度上保证选取的波段之间的相关性较低,波段代表了尽可能不相似的信息,即没有过多的冗余信息,因此可以提高分类的正确率。
下面给出一个更加详尽完整的例子,对本发明进一步说明:
实施例5
基于局部聚类比例排序的高光谱波段选择方法同实施例1-4,本发明是针对高光谱图像波段选择问题的一种基于局部聚类比例排序的方法。完整流程参见图1,其实现包括有如下步骤:
1.输入数据及参数:首先将一个大小为m×n的高光谱图像三维矩阵ι∈rm×n×d展开成二维矩阵d={x1,x2,...,xd}∈rd×mn,即d矩阵的行数以及列数分别为d和mn,其中d代表波段的数目,m,n表示原数据的长和宽,即原图像包含的像素点个数为m×n。第i波段在原数据i中对应一个大小为m×n的响应值矩阵(每个像素点对应一个响应值),将这个矩阵按列优先展开为维度为mn的向量xi,即将矩阵(共有m行n列)的第2列到第n列依次拼接到第1列的后面,展开后一个波段就对应一个长度为mn的向量xi,并使得该向量在转置后位于d中的第i行。再人为输入相似度阈值参数th1和聚类阈值参数th2,以及预期保留的波段数k,在本例用到的两个数据集上,将th1和th2都分别设置为0.01与0.17。而预期保留的波段数k,是用来判断方法优劣的重要指标,在本例中,将其设置为在3-32之间变化。
2.计算波段之间的相似度:在得到展开为二维的高光谱图像d之后(d中每一行表示一个波段,而每一列表示一个像素点在不同波段下的响应),利用原始的高光谱数据以及输入的相似度阈值参数th1,本例中将其设置为0.01,先计算阈值向量diff,之后再根据波段向量之间的欧式距离来计算sij,即第i个波段与第j个波段的相似度。
计算不同的相似度矩阵的动机在于:高光谱数据的波段响应之间会出现不同程度的噪声的事实。由于空间分辨率较高,每个像素点之间细微的差别(有可能是噪声、成像条件等影响)累计起来也会对最终的两波段距离产生较大的影响。而本发明提出的计算相似度矩阵的方法,由于引入了阈值参数diff,可以抹去细微的差别,而忠实于较大的真实距离。因此,可以得到对于噪声更具有鲁棒性的相似度矩阵。
3.波段聚类:根据聚类阈值参数th2,本例中取为0.17,来判断任意波段的可聚类波段集合。即先用th2来确定每个波段i的最大可聚类距离maxdisi,再根据波段之间的相似度矩阵s,计算聚类矩阵l,聚类矩阵l的意义为:若lij=1,则表示i和j两个波段可以聚为一类;若lij=0,则表示i与j不能聚为一类。
本发明借鉴了现有方法(e-fpdc)的思想,但也有不同之处:即在判断第i个波段可聚类的波段时,并没有考虑其他波段(j、k)之间的距离,仅仅利用第i个波段和其他波段之间的距离集合作为聚类依据。但如果考虑所有距离对,会有一些波段距离很近,如果仅仅根据全部距离对选择一个截断参数dis,对波段的聚类则会造成较大影响,使得有些原本可聚为一类的波段无法聚集,有些波段甚至会成为孤立点。而本发明相当于对不同的波段选择不同的截断参数,可以使聚类准则具有针对性,实验证明只要聚类阈值参数th2能够在合理范围内取值,不至于使聚类矩阵l变成单位矩阵,即可获得更好的效果。
4.分配等级,动态地加入到最终解集:初始化最终解集ss为空,计算聚类后每个波段的局部信息与全局信息的比值,作为波段的等级;其中局部信息表示在第i波段的临近波段内可与之聚类的数目,全局信息表示在全部波段内可与第i波段聚类的数目。临近波段定义为与某波段的波段号差在d/2k之内的波段,其中d表示高光谱图像的总波段数,而k表示预期选择的波段数。
将等级降序排序之后动态地选入集合ss,直到集合中波段数目达到k,作为最终的解集返回。由于获取波段响应值时波长是连续的,因此相邻波段之间的相似度一般会较高。本发明整合某波段的局部信息和全局信息的比值作为其等级,认为其越高越好,因此降序排序后用于最终的选择。如果这个比值较低,一般来说有两种情况:a.局部可聚类的波段(分子)较少,这样的波段本身密度较小,所包含的信息不属于重要信息,难以用较少的这种波段来代表整个数据的分布;b.全局可聚类波段(分母)较多,这样的波段或许包含了很多波段的信息,与很多波段相似性较高,但是它可以看做是位于两个簇之间相连的部分,综合了两个簇的信息,不具有较高的分类能力,所以认为等级越高越好。
而相邻的波段之间的等级也许会较为接近,为了防止波段选择的后的波段相关性较高,本发明在选择一个波段进入集合后,还要动态地为它的临近波段重新分配等级之后,即降低临近波段的等级,使用新的等级排序选择下一个选入的波段。在本例中将临近波段的等级降低为0即可。这样选入的波段的区间是均匀分布的,而选入的波段在各自的区间上都拥有最高的等级,可以保证选入波段之间没有较高的相关性,且能代表更多的分类信息。
实施例6
基于局部聚类比例排序的高光谱波段选择方法同实施例1-5,整体方法的流程也可以如下表所示:
本发明根据不同的准则计算相似度矩阵,可以增加方法的噪声鲁棒性,可以减少由于云层,成像等造成的误差,更加真实地反应波段间的相似性。并且在聚类时利用了某一波段与其他波段的相似度集合来为其分配聚为一类的波段,记录在聚类矩阵l中,将这些聚类信息分为局部信息和全局信息,用以为每个波段分配等级,降序排列等级后动态地选入最终解集,可以有效地避免选入的波段具有较高的相关性。
实施例7
基于局部聚类比例排序的高光谱波段选择方法同实施例1-6,下面结合附图2对本发明的技术效果做进一步的描述。
1.仿真实验条件:
本发明的仿真实验采用的硬件平台为:处理器intercorei5,主频3.20ghz,内存8gb;
软件平台为:windows764位操作系统、matlabr2016b。
2.实验内容:
本发明的仿真实验采用高光谱图像数据集indianpines以及paviauniversity,对两者的波段进行选择,降低特征的维数。其中indianpines数据集于1992年用aviris传感器采集于美国印第安纳松林西北部,场景包含三分之二和三分之一的农业、森林等自然植被。去除水吸收波段后包含200个波段,图像大小为145×145,共包含16种地物。而paviauniversity是于2003年由rosis传感器采集到的意大利paviauniversity地区。总光谱范围为从0.43μm到0.86μm的115个波段,去掉12个含噪波段之后,包含103个波段,图像大小为610×340,共包含9种真实地物类别。实验中,本发明与其他现有波段选择方法在这两个数据集上进行性能对比:分别选择3到32个波段,考察不同方法保留波段的分类性能。即将两个数据集分别用不同的方法保留3到32个波段之后,每类地物随机选择10个作为标记样本,其余作为测试样本,利用十次svm分类得到的正确率取平均值后的变化情况,结果参见图2(a)与图2(b)。
3.实验结果分析:
附图2(a)是对indianpines数据集上使用不同方法进行波段选择之后的分类性能的比较,附图2(b)是对paviauniversity数据集上使用不同方法进行波段选择之后的分类性能的比较。在图2(a)与图2(b)中,加上红色圆圈的虚线均代表使用k中心点聚类算法选出的波段的分类能力,紫色加圆圈线均代表fpdc方法的分类能力,而绿色三角线均代表e-fpdc方法的分类能力,蓝色实线均代表本发明的分类能力。
在附图2(a)中可以看出,本发明与其他现有方法的分类性能进行对比,在保留5-19个波段时,本发明选择的波段用来分类,分类精度可以提高5%左右。而当保留波段增加到20-30之间时,本发明保留的波段的分类性能与现有方法相近。因此在保留波段数较少的时候,本发明优势体现得十分明显。
在附图2(b)中可以看出,本发明与其他现有方法的分类性能进行对比,在保留3-32个波段时,分类性能均有较好的表现,优势还是可以体现在选取波段数目较少的情况下,即选择3-13个波段时,本发明与其他三种现有方法相比,分类精度都有3%左右的提升;而在选取波段数增加时,即选择14-32个波段时,有个别波段数目的情况下分类精度没有较现有方法中最好的相比有所提高,但也与其基本相当。因此,附图2(a),以及附图2(b)能够得到相似的结论,进而证明本发明的有效性。
综上所述,本发明公开的一种基于局部聚类比例排序的高光谱波段选择方法,解决了高光谱波段选择方法中缺乏噪声鲁棒性、选择的波段相关性强的问题。具体步骤有:输入数据,预期选择的波段数以及参数;考虑到噪声的影响,计算更能反映真实波段信息的相似度矩阵;波段聚类;计算每个波段的局部信息与全局信息的比值作为等级,降序排序后将波段动态地加入最终解集。在聚类时更有针对性,为每个波段分配一个最大可聚类距离,可以避免将某些波段错误聚类的情况;在选择波段时,每个波段的等级是通过局部信息与全局信息的比值得到的,考虑到临近波段之间的强相关性,避免选入含有冗余信息的波段。本发明计算的相似度矩阵具有一定鲁棒性,选择出的波段含有较少的冗余信息,分类性能更好。应用在高光谱图像处理领域。
- 还没有人留言评论。精彩留言会获得点赞!