内容推荐方法与流程
本申请是申请号为2013100761474、申请日为2013年03月11日、发明创造名称为“内容推荐系统”的专利的分案申请。本发明涉及文字信息检索技术,尤其涉及一种内容推荐方法。
背景技术:
:信息技术的不断发展极大提高了人们获取信息的便利性。无论是通过互联网的各大门户网站、电子商务系统还是通过企业内部的各种资源共享系统的方式,海量的信息开放给用户自由查阅。目前信息量的日益庞大,很大程度上增加了用户获取有效信息的繁重性和复杂度。如何根据用户在网络上查阅文件的行为,分析用户阅读兴趣并检索有效信息提供给用户是信息检索中一个重要的课题。技术实现要素:鉴于以上内容,有必要提供一种内容推荐系统及方法,可以有效利用用户网络上的检索行为,统计并分析用户阅读兴趣,获取有效的文件信息提供给用户。所述的内容推荐系统包括:断词模块,用于对资料库中的文件进行断词;提取模块,用于过滤断词结果,并计算过滤结果中词的重要程度,以重要程度为依据,提取出文件的关键词;统计模块,用于统计用户查阅的历史记录内文件的关键词及重要程度,并计算出关键词的适合度,以适合度为依据,筛选出用户的兴趣关键词;及检索模块,用于根据用户的兴趣关键词从资料库中检索文件,并根据兴趣关键词在文件中的比重来计算文件的关注度,以关注度为依据选取文件返回给用户。所述的内容推荐方法包括:对资料库的文件断词;过滤断词结果,并计算过滤结果中词的重要程度,以重要程度为依据提取文件的关键词;统计用户查阅的历史记录内文件的关键词及重要程度,并计算出关键词的适合度,以适合度为依据筛选出用户的兴趣关键词;及根据用户的兴趣关键词从资料库中检索文件,并根据兴趣关键词在文件中的比重来计算文件的关注度,以关注度为依据选取文件返回给用户。本发明可以提取文字信息的关键词借以分析用户检索行为并统计用户的兴趣关键词,获取符合用户自身特点的信息推送给用户,降低了用户检索和信息过滤的复杂度和繁重性。附图说明图1是本
发明内容推荐系统较佳实施例的应用环境图。图2是本
发明内容推荐系统较佳实施例的功能模块图。图3是本
发明内容推荐方法较佳实施例的方法流程图。图4是本
发明内容推荐系统较佳实施例中文件汇总记录的示意图。图5是本
发明内容推荐系统较佳实施例中文件关键词记录的示意图。图6是本
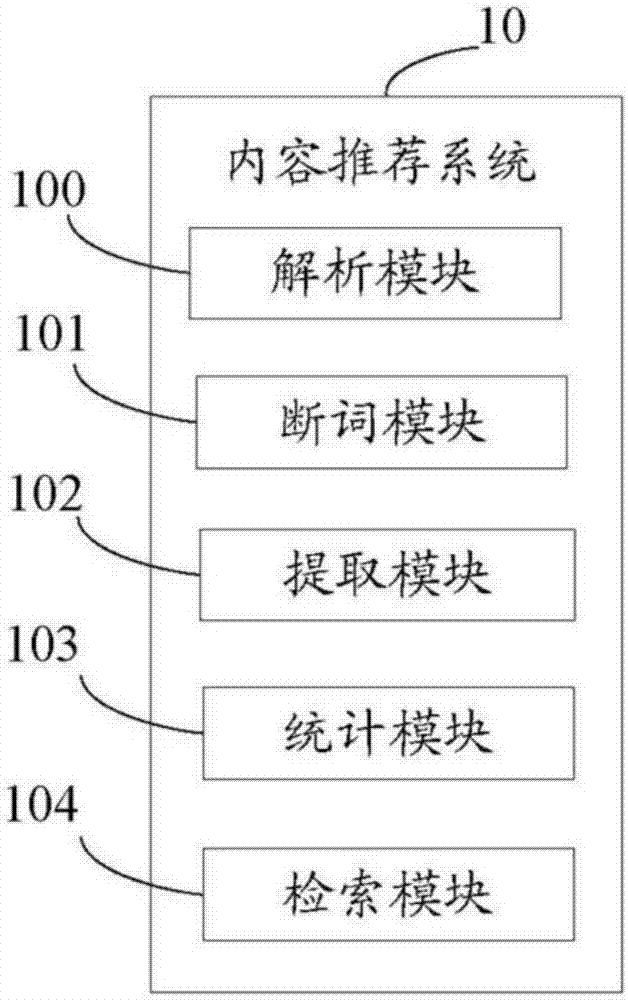
发明内容推荐系统较佳实施例中用户兴趣关键词记录的示意图。主要元件符号说明服务器1用户终端2内容推荐系统10处理器11资料库12解析模块100断词模块101提取模块102统计模块103检索模块104如下具体实施方式将结合上述附图进一步说明本发明。具体实施方式参阅图1所示,是本
发明内容推荐系统的较佳实施例的应用环境图。所述的内容推荐系统10应用于服务器1中。所述服务器1通过国际互联网络或企业内部网络和一个用户终端2进行通讯连接。在本较佳实施例中仅以1个用户终端2进行说明,在本发明其他实施例中服务器1可以与多个用户终端2进行连接。所述用户终端2可以是个人电脑、平板电脑、移动通讯设备(例如手机)等。所述内容推荐系统10的程序代码由处理器11控制执行,并与资料库12进行数据存取传输。所述资料库12存储开放给用户终端2检索的文件、断词词库以及常用词词库、内容推荐系统10处理产生的数据记录等。所述断词词库以及常用词词库提供给内容推荐系统10在断词和提取文件关键词时使用。所述资料库12可以是内置在服务器1的存储器也可以是外接服务器1的存储器。图1仅为示例,在实际应用中,所述的内容推荐系统10的应用并不局限于此。参阅图2所示,是本
发明内容推荐系统的较佳实施例的功能模块图。所述内容推荐系统10包括解析模块100、断词模块101、提取模块102、统计模块103及检索模块104。所述解析模块100用于将文件解析为具有标题及文字正文的结构性的文字信息。所述文件可以是网页内容、含图片的word文件、text文本信息等。本发明其他实施例中可根据文件类型以及文件来源等适当取舍解析模块100。当文件为网页时,解析模块主要是利用网页拆解技术,剔除网页原始码中的html语法(hypertextmarkuplanguage,超文本标记语言)、javascript语法和一些无意义的图片或链接等。当文件为word文件时,解析模块主要是用来剔除文字无关的图片等。当文件为text文本信息,则无需解析模块对文件进行解析。所述断词模块101用于对解析后的文字信息进行断词。所述断词是将文字信息的文句断开成可赋予词类的词。因为中文不似英文有明显的空白符号作为断词的判断,常见的中文断词技术有词库式断词法(wordidentification)、统计式断词法(statisticalwordidentification)及混合式断词法(hybridwordidentification)。词库式断词法对文件断词主要是比对文件中出现的词汇与词库中的词汇进行断词,断词的结果主要受词库大小、品质的影响,一些专有名词或是新生词汇则由于词库的限制而无法正确断出。对于词库式断词加上构词规则的分析即为规则式词库断词法。统计式断词法对文件断词是由一定的统计公式统计临近字元同时出现的频率,以频率的高低作为断词的依据,断词结果不依赖词库品质而是以频率高低决定词汇,可能得到没有意义的词汇。混合式断词法是将词库式断词法和统计式断词法整合,首先利用词库式断词法对文字信息断词,可配合使用构词规则简化断词,再以统计公式列出所有可能结果。混合式断词法结合两种断词法的优点,一定程度上规避了两种断词法的缺点从而优化了断词过程。在本发明的较佳实施例中采取了混合式断词法对中文文字信息进行断词。首先根据资料库12中的断词词库并配合词库小组提出的六条断词规则即采用规则式词库断词法对文字信息进行第一阶段的断词,其中断词词库可以根据本发明不同实施例的适用范围而进行建制;其次利用统计分析法的统计公式对第一阶段断词后的断词结果进行频率统计,列出所有可能的词。本较佳实施例中统计式断词法的主要统计公式如下:f[i]>1………………(公式1-1)tf[i]>1………………(公式1-2)f[i]=tf[i]……………(公式1-3)f[i]表示的某个字、词在文字信息中单独出现的次数;tf[i]表示f[i]记录的该字、词其后的字、词在文字信息中单独出现的次数;f[i]=tf[i]表示某个字、词出现的次数和该字、词其后的字、词出现的次数一致,则表明这两者每次在文字信息中都是一起出现,故认为两者可以合并为一个词。现以一段节选自东方早报网站上的题为《破解“春运购票难”需要系统性方案》的内容为例,对本较佳实施例的断词法进行详细说明。节选内容如下:近年来,铁路春运压力始终居高不下,虽然铁道部努力改善车票购买办法,采取了诸如网络和电话订票、推行实名制、打击“黄牛”等措施,尽量让乘客顺利出行,并取得了一定成效。但今年春运,从艰难的购票到倒票现象依然存在,无不说明诸多乱象的存在。这显示,破解春运购票难,绝对不是单纯票务管理的问题,而是铁路内部涉及利益、理念和技术等各方面的系统工程。以上文字内容经本实施例的第一阶段断词,断词结果为:“近年来铁路春运压力始终居高不下虽然铁道部努力改善车票购买方法采取了诸如网络和电话订票推行实名制打击黄牛等措施尽量让乘客顺利出行并取得了一定成效但今年春运从艰难的倒票现象依然存在这显示破解春运购票难绝对不是单纯票务管理的问题而是铁路内部涉及利益理念技术等各方面的系统工程”。本发明其他实施例中采用不同的断词词库以及断词规则,第一阶段的断词结果则不尽相同。若本实施例的断词词库无“春运”这个词,则第一阶段的断词结果中“春”、“运”是两个独立的字,且“运”字有出现在“春”字之后。对第一阶段断词产生的词、字进行统计分析法断词,第二阶段的统计式断词仅以“春”、“运”这两个进行说明:“春”f[i]=3;“运”tf[i]=3;f[i]=tf[i]即3=3则“春”、“运”可以合并为一个词“春运”。本较佳实施例为降低演算的时间复杂度、提高系统性能而采用以上统计公式进行快速断词,在本发明其他实施例中可以使用不同的统计公式计算临近字元出现的高低频率作为断词的依据。本发明其他实施例中所述断词模块101对中文断词的方法不限定为本较佳实施例所使用的混合式断词法。所述提取模块102用于从文件断词后的断词结果中提取出合适的词作为文件的关键词,并将所述关键词以图5所示的文件关键词记录的格式记录并储存至资料库12中。本较佳实施例中,上述提取过程为:首先,根据资料库12中的常用词词库对断词模块101产生的断词结果进行过滤。断词结果的词不都与文件主题相关,在提取文件关键词之前需对断词结果中的词进行过滤,例如:一些无意义的词“的”、“吗”、“是”或是如“虽然”、“但是”、“并且”等表示句子成分关系的词或是如“一些”、“很多”、“非常”等表示数量及程度的词或是一些“我们”、“大家”等人称代词或是“今天”、“明天”等表示时间的词。其次,加权法计算过滤后的词的重要程度并根据重要程度进行降序排列,取前m个词作为文件的关键词。一篇文件往往针对一个特定主题,那么在文字信息中必定会反复提及一些与主题相关的词,本较佳实施例以此为依据进行计算。本较佳实施例中指定文字正文权重为1,标题权重为3,则一个词的重要程度=该词在文字正文出现次数×正文权重+该词在标题中出现次数×标题权重。例如,一篇文件中“高铁”在文字正文出现了5次,在标题中出现1次,则“高铁”在该文件的重要程度=5×1+1×3=8。本较佳实施例中,服务器1设定每日排程,在每天人均访问量较少的几个时间段上传新的文件至资料库12,同时,为每个新文件分配文件id,并将文件id、路径、标题、大小等内容以图4所示文件汇总记录的格式记录并存储至资料库12。解析模块100、断词模块101和提取模块102按照排程,对资料库12新增的文件进行解析、断词以及提取关键词,提取的关键词以图5所示的文件关键词记录的格式记录并将该文件关键词记录表储存至资料库12,以便后续统计模块103根据历史记录内文件id快速从该文件关键词记录表中取得文件的关键词并从中筛选出用户的兴趣关键词。如图5所示,所述文件关键词记录表的栏位包括:文件id、项次、关键词、重要程度等。本发明其他实施例中提取模块102可以计算断词结果中词的词频,以此作为提取关键词的依据。权重计算可以采用tf-idf(termfrequency-inversedocumentfrequency,词频-逆向文件频率)加权算法或是单独的tf(termfrequency,词频)加权算法计算词在文件中的词频,根据词频进行降序排序,提取前m个词作为关键词。所述统计模块103用于根据用户查阅文件的历史记录和图5所示的文件关键词记录,统计筛选出用户的兴趣关键词,并将所述兴趣关键词以图6所示的用户兴趣关键词记录的格式记录并储存至资料库12中。所述历史记录包含有用户id、日期、文件id等内容,用户终端2在查阅资料库12中的文件时,服务器1会将用户查阅行为储存至资料库12中。本较佳实施例中,上述统计筛选的过程如下:首先,从资料库12中获取用户最近的某个时间范围的历史记录,该历史记录中包含有用户id、检索日期、文件id等内容。其次,根据历史记录内文件id从资料库12中查询图5所示的文件关键词记录表,汇总查询结果的关键词以及每个关键词的重要程度。最后,根据公式2-1计算出每个关键词的适合度,以适合度对关键词降序排序,取前r个关键词作为兴趣关键词。所述兴趣关键词是从用户历史记录内的文件的关键词中获取的,能够反映用户兴趣的关键词。所述适合度用于衡量关键词是否可作为兴趣关键词的标准。历史记录内的文件的关键词汇总后的重要程度越高,则表明该关键词是兴趣关键词的可能性越高;但是若该关键词在历史记录内的每个文件出现,则该关键词能够区别其他关键词作为兴趣关键词的辨识度反而降低,鉴于以上考量,本较佳实施例中设计公式2-1用于计算关键词的适合度。计算关键词能否作为兴趣关键词的适合度的公式见下:feq:汇总后的关键词的重要程度;k:k天内标题出现该关键词的文件篇数;n:n天内的文件总篇数。在本发明的其他实施例中可以创建不同的公式用于合理选取历史记录内文件的关键词作为用户的兴趣关键词。所述统计模块103是基于事后分析的策略,根据用户查阅文件的历史记录,分析出用户的兴趣,以便检索模块104可以根据用户的兴趣关键词,检索出符合用户特点的最新资讯推送给用户。本较佳实施例中,服务器1设定周期性排程,例如在每周一的某个时间段根据用户上一周查阅的文件,从以上文件的关键词中重新筛选出用户的兴趣关键词,将兴趣关键词以图6所示的用户兴趣关键词记录的格式记录并存储在资料库12中。历史记录的周期选择影响到兴趣关键词选取的实时性,在其他实施例中可以根据不同用户层面来制定不同的周期。所述检索模块104用于根据资料库12中图4所示文件汇总记录和图6所示的兴趣关键词检索文件,并计算检索结果中文件的关注度,以关注度为依据选取文件返回给用户终端2,推荐用户查阅。本较佳实施例中,上述检索及计算过程为:首先,根据资料库12中图4所示的文件汇总记录和图6所示的兴趣关键词检索文件,若文件标题与用户的某个兴趣关键词匹配,则检索出该文件。其次,根据图6所示的兴趣关键词及适合度,计算出检索结果中各文件标题中兴趣关键词的比重即文件的关注度,以关注度进行降序排序,获取前s个文件返回给用户。所述文件的关注度是指兴趣关键词在文件标题中的比重,是衡量文件可能被用户关注的程度。本较佳实施例的文件关注度=σ(兴趣关键词在文件标题出现次数×该兴趣关键词的适合度),所述兴趣关键词的适合度即为统计模块103筛选兴趣关键词的依据,由公式2-1计算得到。例如,用户一周内的兴趣关键词为“春运、高铁、西安、深圳、广州”,各兴趣关键词的适合度分别为1、2、5、4、3,若文件1的标题为“2013年春运广州高铁预售期公布”,文件2的标题为“西安到深圳列车时刻及票价查询”,因为文件1标题匹配了兴趣关键词“春运”、“广州”、“高铁”,文件2标题匹配了兴趣关键词“西安”、“深圳”,所以这两个文件会被检索出来,文件1标题和文件2标题中匹配的兴趣关键词出现的次数都为1,文件1的关注度=1×1(“春运”的适合度)+1×3(“广州”的适合度)+1×2(“高铁”的适合度)即文件1的关注度为6,文件2的关注度=1×5(“西安”的适合度)+1×4(“深圳”的适合度)即文件2的关注度为9,则两个文件相比的话优先选择关注度较高的文件2返回给用户。需要指出的是,为提高系统运行速度、降低运算复杂度,所述检索模块104检索文件和计算文件关注度都限定在文件标题范围。本发明其他实施例也可以根据图5所示文件的关键词和重要程度结合图6所示的兴趣关键词和适合度,制定和设计出其他的检索标准和文件关注度计算公式。参阅图3所示,是本
发明内容推荐方法的较佳实施例的流程图。根据不同的需求,该流程图中步骤的顺序可以改变,某些步骤可以省略。步骤s01,解析模块100将文件解析为具有标题及文字正文的结构性的文字信息。所述文件可以是网页内容、含图片的word文件、text文本信息等。其他实施例中可根据文件类型以及文件来源等可以适当取舍解析模块100。当文件为网页时,解析模块主要是利用网页拆解技术,剔除网页原始码中的html语法(hypertextmarkuplanguage,超文本标记语言)、javascript语法和一些无意义的图片或链接等。当文件为word文件时,解析模块主要是用来剔除文字无关的图片等。当文件为text文本信息时,步骤s01可以省略,无需对文件解析。步骤s02,断词模块101根据混合式断词法对解析后的文字信息进行断词。因为中文不似英文以空白将词区分,在本发明的较佳实施例中采取了混合式断词法对中文文字信息进行断词。首先根据资料库12中的断词词库并配合词库小组提出的六条断词规则即规则式词库断词法对文字信息进行第一阶段的断词,其中断词词库可以根据本发明不同实施例的适用范围而进行建制;其次利用统计分析法的统计公式对第一阶段断词后的断词结果进行频率统计。本较佳实施例中统计分析法断词的主要统计公式见前文所述的公式1-1、公式1-2、公式1-3。步骤s03,提取模块102从断词结果中提取合适的词作为文件的关键词。首先,利用资料库12中的常用词词库过滤断词结果,剔除常见的诸如“今天”、“我们”、“并且”等词汇;其次,根据加权法计算过滤后的断词结果中每个词的重要程度并以重要程度降序排列,取前m个词作为文件的关键词。一篇文件内容往往针对一个特定主题,那么在文件内容中必定会反复提及一些与主题相关的词,本较佳实施例以此为依据进行计算词的重要程度。本较佳实施例中指定文字正文权重为1,标题权重为3,则一个词的重要程度=该词在文字正文出现次数×正文权重+该词在标题中出现次数×标题权重。例如一篇文件中“高铁”在文字正文出现了5次,在标题中出现1次,则“高铁”在该文件的重要程度=5×1+1×3=8。本较佳实施例中服务器1设定每日排程,在每天人均访问量较少的时间段上传新的文件至资料库12中,所述步骤s01至s03按照排程对新增的文件进行解析、断词及提取关键词,将提取的关键词存储在图5所示的文件关键词记录表中,以便后续步骤能够根据该表记录的文件id快速取得文件关键词并从中筛选出用户的兴趣关键词。步骤s04,统计模块103根据用户查阅文件的历史记录,统计筛选出用户的兴趣关键词。所述历史记录包含有用户id、日期、文件id等内容,用户终端2在查阅资料库12中的文件时,服务器1会将用户查阅行为储存至资料库12中。首先,从资料库12中获取用户最近的某个时间范围的历史记录。其次,根据历史记录内的文件id从资料库12中查询图5所示的文件关键词记录表,汇总查询结果的关键词以及每个关键词的重要程度。最后,根据公式2-1计算出关键词的适合度,以适合度对关键词降序排序,取前r个关键词作为兴趣关键词,将筛选的兴趣关键词存储在图6所示的用户兴趣关键词记录表中,以便检索步骤可以根据表中的兴趣关键词检索资料库12中的文件。所述步骤s04按照周期性排程,在某个时间段从用户上次查阅文件的关键词中重新筛选出用户的兴趣关键词。步骤s05,检索模块104根据统计得到的兴趣关键词对文件进行检索,计算出检索结果中文件的关注度,以关注度为依据选取文件返回给用户。本较佳实施例中,上述检索及计算过程为:首先,根据资料库12中图4所示文件汇总记录和图6所示的兴趣关键词检索文件,若文件标题与用户的某个兴趣关键词匹配,则检索出该文件。其次,根据图6所示的兴趣关键词及适合度,计算出检索结果中各文件标题中兴趣关键词的比重即文件的关注度,以关注度进行降序排序,获取前s个文件返回给用户。所述文件的关注度是指兴趣兴趣关键词在文件标题中的比重,衡量文件可能被用户关注的程度。本较佳实施例的文件关注度=σ(兴趣关键词在文件标题出现次数×该兴趣关键词的适合度),所述兴趣关键词的适合度即为统计模块103筛选兴趣关键词的依据,由公式2-1计算得到。以上实施例仅用以说明本发明的技术方案而非限制,尽管参照以上较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或等同替换都不应脱离本发明技术方案的精神和范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1