一种基于Spark平台Web服务个性化推荐方法及系统与流程
本发明涉及大数据处理技术领域,尤其涉及一种基于spark平台web服务个性化推荐方法及系统。
背景技术:
随着大数据时代的到来,网络中的web服务呈指数式增长,随之带来了信息过载的问题。推荐系统是解决新信息过载的最有效方法之一。大数据推荐系统已逐渐成为研究热点。推荐系统帮助用户从庞大的web服务中找到自己满意的web服务是非常困难且耗时的。利用个性化推荐技术从大规模数据中提取用户满意的信息十分必要。然而在当今大数据的实际生活中,由于数据量和规模过于庞大,导致计算过程异常耗时和困难,很难达到满足用户渴望的高效率和满意的推荐结果。而云计算技术的出现为我们提供了很好的方法,基于spark平台web服务个性化推荐系统能够高效地用户提供优质的服务。
技术实现要素:
本发明所要解决的技术问题在于提供了一种能够达到满足用户渴望的高效率和满意的推荐结果的基于spark平台web服务个性化推荐方法及系统。
本发明是通过以下技术方案解决上述技术问题的:一种基于spark平台web服务个性化推荐方法,包括下述步骤:s1、提取用户在电商应用或信息平台的行为数据,对收集的用户对web服务的历史行为信息进行评估分析;
s2、用基于商空间粒度分析的覆盖聚类算法对收集的用户对web服务的历史行为信息进行聚类处理得出聚类结果;
s3、根据上述步骤s2中的聚类结果构建用户关联矩阵mu和web服务关联矩阵ms;
s4、通过对上述步骤s3中构建的关联矩阵进行目标用户和目标web服务的相似邻居分析,得出目标用户和目标web服务的相似邻居结果;
s5、根据上述步骤s4中目标用户和目标web服务的相似邻居结果的聚类信息分别对用户的评价值qos进行预测;
s6、混合处理步骤s5中的预测结果得出推荐方案,完成整个推荐算法;
s7、在spark平台下对该推荐算法进行并行化计算,并对计算结果进行存储,提高推荐系统的性能。
作为优化的技术方案,所述步骤s2中,采用基于用户(user)和web服务(service)二重混合的混合推荐算法对收集的用户对web服务的历史行为信息进行聚类,上述进行聚类的过程采用基于商空间粒度分析的覆盖聚类算法,所述基于商空间粒度分析的覆盖聚类算法具体包括如下步骤:
s01、计算出所有未学习过的样本点的重心,并以离该重心最近的样本点作为覆盖的圆心;
s02、计算出所有还未聚类的样本点与圆心的距离;
s03、计算出步骤s02中所有距离的平均距离,以上述平均距离为半径;
s04、并根据上述半径计算出球形覆盖;
s05、计算当前球形覆盖的重心;当样本点的个数大于预设值是,执行步骤s06,当样本点的个数不大于预设值是,执行步骤s07;
s06、将离步骤s05中球形覆盖的圆心最远的点作为新的圆心,并根据上述新的圆心重复步骤s02、s03、s04、s05,直到所有的样本全部覆盖结束;
s07、将离步骤s05中球形覆盖的圆心最近的点最为新的圆心,计算出步骤s05中球形覆盖的圆心与新的圆心的距离,将离的最近的两个球形覆盖合并为一个新的球形覆盖,并更新其他覆盖与新覆盖的最短距离,如此重复,确定最后的聚类数;
s08、计算出所有覆盖聚类结果中球形覆盖与球形覆盖两两之间的相似度;
s09、比较s08步骤中计算得出的所有相似度值,得到最大相似度阈值;
s10、如果最大相似度阈值大于经过实验获得的相似度阈值,则覆盖聚类结束,确定最后的聚类数,否则,将相似度最大的两个球形覆盖合并,重复步骤s08、s09,更新其他球形覆盖与获得的新的球形覆盖之间的相似度值,直到覆盖聚类结束。
作为优化的技术方案,步骤s3,具体包括:
在对用户进行聚类后,根据每一个web服务下用户的聚类情况,计算出两两用户被分为一类的次数,用cluster-numu1,u2表示用户u1和用户u2被分为一类的次数;在对web服务进行聚类后,根据每一个用户下web服务的聚类情况,计算出两两web服务被分为一类的次数,用cluster-nums1,s2表示web服务s1和web服务s2被分为一类的次数;所有用户和web服务的分为一类的次数cluster-num构成了分别构成了用户关联矩阵mu和web服务关联矩阵ms。
作为优化的技术方案,步骤s4,具体包括:
根据关联矩阵得出目标用户相似邻居similar-neighbors(user)的过程具体包括:对目标用户与邻居用户的被分为一类的次数cluster-num进行降序操作,取前ku个cluster-num值最大的邻居用户作为目标用户的相似邻居similar-neighbors(user);得出目标web服务相似邻居similar-neighbors(service)的过程具体包括:对目标web服务与邻居web服务的被分为一类的次数cluster-num进行降序操作,取前ks个cluster-num值最大的邻居web服务作为目标web服务的相似邻居similar-neighbors(service);其中,ku和ks均为预设值。
作为优化的技术方案,步骤s5,具体包括:
根据得出的相似邻居结果的覆盖信息进行用户对未调用过的web服务的评价值qos预测,过程具体包括为:
根据得出的目标用户相似邻居similar-neighbors(user)的覆盖信息,以及下述公式预测用户u对web服务s的评价值qos;
其中,ku表示目标用户的相似邻居的数目,au(t)表示用户u的相似邻居中第au(t)个用户,
根据得出的目标web服务相似邻居similar-neighbors(service)的覆盖信息,以及下述公式预测用户u对web服务s的评价值qos;
其中,ks表示目标web服务的相似邻居的数目,as(t)表示web服务s的相似邻居中第as(t)个用户,
作为优化的技术方案,步骤s6,具体包括:
依据qu,s(u)以及qu,s(s)得出的基于用户与基于web服务聚类的评价值qos预测,利用混合因子λ将基于用户聚类的推荐算法的评价值qos预测和基于web服务聚类的推荐算法的评价值qos预测相混合,得出下述公式:
qu,s=λqus(u)+(1-λ)qus(s);
将得出的qu,s进行降序排列,取出前n位的web服务作为推荐方案;其中,所述n为预设值。
作为优化的技术方案,步骤s7,具体包括:
在spark平台下对推荐算法进行并行化计算时,对用户聚类具体采用基于商空间粒度分析的覆盖聚类算法,上述基于商空间粒度分析的覆盖聚类算法具体包括getcenter、getradius、getcovering;getcenter用于计算每个web服务中用户对上述web服务的评价值qos的重心,并以离该重心最近的数据点作为球形覆盖的圆心;getradius用于计算每一个web服务中尚未聚类的数据点与圆心之间的距离,且计算出上述所有距离的平均距离,并将上述的平均距离作为球形覆盖的半径;getcovering用于计算所有每一个web服务中属于由上述圆心和半径所构成的球形覆盖内的所有数据点。
在spark平台下对推荐算法进行并行化计算时,对web服务聚类具体采用基于商空间粒度分析的覆盖聚类算法,上述基于商空间粒度分析的覆盖聚类算法具体包括getcenter、getradius、getcovering;getcenter用于计算每个用户对调用过的web服务的评价值qos的重心,并以离该重心最近的数据点作为球形覆盖的圆心;getradius用于计算每一个用户中尚未聚类的数据点与圆心之间的距离,且计算出上述所有距离的平均距离,并将上述的平均距离作为球形覆盖的半径;getcovering用于计算每一个用户中属于由上述圆心和半径所构成的球形覆盖内的所有数据点。
本发明还公开一种基于spark平台web服务个性化推荐系统,包括:
用户历史行为信息收集模块,提取用户在电商应用或信息平台的行为数据,对收集的行为数据进行评估分析;
聚类模块,利用基于商空间粒度分析的覆盖聚类算法对收集的用户对web服务的历史行为信息进行聚类处理得出聚类结果;
构建关联矩阵模块,根据上述聚类结果构建用户关联矩阵mu和web服务关联矩阵ms;
相似邻居结果计算模块,通过对上述构建的关联矩阵进行目标用户和目标web服务的相似邻居分析,得出目标用户和目标web服务的相似邻居结果;
评价值qos预测模块,根据上述相似用户和相似web服务的相似邻居结果的聚类信息分别对用户的评价值qos进行预测;
混合处理和推荐模块,对用户的评价值qos的预测值进行混合处理得出推荐方案,完成整个推荐算法;
spark平台推荐算法并行化处理模块,在spark平台下对推荐算法进行并行化计算,并对上述计算结果进行存储。
优化的,聚类模块采用基于用户和web服务的二重聚类混合的混合推荐算法对收集的用户对web服务的历史行为信息进行聚类,上述进行聚类的过程采用基于商空间粒度分析的覆盖聚类算法,所述基于商空间粒度分析的覆盖聚类算法具体包括如下步骤:
s01、计算出所有未学习过的样本点的重心,并以离该重心最近的样本点作为覆盖的圆心;
s02、计算出所有还未聚类的样本点与圆心的距离;
s03、计算出步骤s02中所有距离的平均距离,以上述平均距离为半径;
s04、并根据上述半径计算出球形覆盖;
s05、计算当前球形覆盖的重心;当样本点的个数大于预设值是,执行步骤s06,当样本点的个数不大于预设值是,执行步骤s07;
s06、将离步骤s05中球形覆盖的圆心最远的点作为新的圆心,并根据上述新的圆心重复步骤s02、s03、s04、s05,直到所有的样本全部覆盖结束;
s07、将离步骤s05中球形覆盖的圆心最近的点最为新的圆心,计算出步骤s05中球形覆盖的圆心与新的圆心的距离,将离的最近的两个球形覆盖合并为一个新的球形覆盖,并更新其他覆盖与新覆盖的最短距离,如此重复,确定最后的聚类数;
s08、计算出所有覆盖聚类结果中球形覆盖与球形覆盖两两之间的相似度;
s09、比较s08步骤中计算得出的所有相似度值,得到最大相似度阈值;
s10、如果最大相似度阈值大于经过实验获得的相似度阈值,则覆盖聚类结束,确定最后的聚类数,否则,将相似度最大的两个球形覆盖合并,重复步骤s08、s09,更新其他球形覆盖与获得的新的球形覆盖之间的相似度值,直到覆盖聚类结束。
优化的,构建关联矩阵模块中,在对用户进行聚类后,根据每一个web服务下用户的聚类情况,计算出两两用户被分为一类的次数,用cluster-numu1,u2表示用户u1和用户u2被分为一类的次数;在对web服务进行聚类后,根据每一个用户下web服务的聚类情况,计算出两两web服务被分为一类的次数,用cluster-nums1,s2表示web服务s1和web服务s2被分为一类的次数;
相似邻居结果计算模块得出目标用户相似邻居similar-neighbors(user)的过程具体包括:对目标用户与邻居用户的被分为一类的次数cluster-num进行降序操作,取前ku个cluster-num值最大的邻居用户作为目标用户的相似邻居similar-neighbors(user);得出目标web服务相似邻居similar-neighbors(service)的过程具体包括:对目标web服务与邻居web服务的被分为一类的次数cluster-num进行降序操作,取前ks个cluster-num值最大的邻居web服务作为目标web服务的相似邻居similar-neighbors(service);其中,ku和ks均为预设值;
评价值qos预测模块用于根据关联矩阵计算模块得出的相似邻居结果对用户对未调用过的web服务的评价值qos进行预测,对用户的评价值qos预测具体包括:
根据得出的目标用户相似邻居similar-neighbors(user)的覆盖信息,以及下述公式预测用户u对web服务s的评价值qos;
其中,ku表示目标用户的相似邻居的数目,au(t)表示用户u的相似邻居中第au(t)个用户,
根据得出的目标web服务相似邻居similar-neighbors(service)的覆盖信息,以及下述公式预测用户u对web服务s的评价值qos;
其中,ks表示目标web服务的相似邻居的数目,as(t)表示web服务s的相似邻居中第as(t)个用户,
混合处理和推荐模块,依据qu,s(u)以及qu,s(s)得出的基于用户与基于web服务二重聚类的评价值qos预测,利用混合因子λ将基于用户聚类的推荐算法的评价值qos预测和基于web服务聚类的推荐算法的评价值qos预测相混合,得出下述公式:
qu,s=λqus(u)+(1-λ)qus(s);
将预测和混合模块得出的qu,s进行降序排列,取出前n位的web服务作为推荐方案;其中,所述n为预设值;
所述spark平台推荐算法并行化处理模块在spark平台下对推荐算法进行并行化计算时,对用户聚类具体采用基于商空间粒度分析的覆盖聚类算法,上述基于商空间粒度分析的覆盖聚类算法具体包括getcenter、getradius、getcovering;getcenter用于计算每个web服务中用户对上述web服务的评价值qos的重心,并以离该重心最近的数据点作为球形覆盖的圆心;getradius用于计算每一个web服务中尚未聚类的数据点与圆心之间的距离,且计算出上述所有距离的平均距离,并将上述的平均距离作为球形覆盖的半径;getcovering用于计算每一个web服务中属于由上述圆心和半径所构成的球形覆盖内的所有样本点;
所述spark平台推荐算法并行化处理模块在spark平台下对推荐算法进行并行化计算时,对web服务聚类具体采用基于商空间粒度分析的覆盖聚类算法,上述基于商空间粒度分析的覆盖聚类算法具体包括getcenter、getradius、getcovering;getcenter用于计算每个用户对调用过的web服务的评价值qos的重心,并以离该重心最近的数据点作为球形覆盖的圆心;getradius用于计算每一个用户中尚未聚类的数据点与圆心之间的距离,且计算出上述所有距离的平均距离,并将上述的平均距离作为球形覆盖的半径;getcovering用于计算每一个用户中属于由上述圆心和半径所构成的球形覆盖内的所有样本点。
本发明相比现有技术具有以下优点:本发明提取用户在电商应用或信息平台的行为数据,对收集的行为数据进行评估分析;该推荐方法对用户的偏好进行分析,具体为基于用户和基于web服务的二重聚类混合的混合推荐算法,分别对用户和web服务进行聚类,找到目标用户和目标web服务的相似邻居,改善了预测的精度,提高了推荐的结果的准确性,且该推荐算法采用基于商空间粒度分析的覆盖聚类算法,将相似的数据聚合在一起,在覆盖后不断更新重心、不断调整已完成的覆盖,解决了初始值选择和聚类速度的问题,避免了对海量数据进行复杂的迭代操作;而且该推荐方法在spark平台下实现地,解决了大数据情况下的计算耗时和困难的问题,通过对大数据进行并行化计算和处理,并将计算结果进行存储,在用户登录是直接将上述结果推荐给目标用户,不仅节约了计算的耗时和困难的问题,而且保证了对数据计算和处理的有效性,高效地为用户提供优质的推荐算法。
附图说明
图1为本发明提出的一种基于spark平台web服务个性化推荐方法中基于用户和web服务的二重聚类混合的混合推荐算法的流程图;
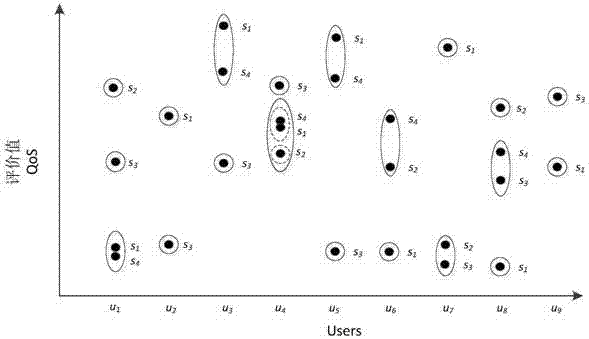
图2为本发明提出的一种基于spark平台web服务个性化推荐方法中基于用户聚类的示例图;
图3为本发明提出的一种基于spark平台web服务个性化推荐方法中基于web用户聚类的示例图;
图4为本发明提出的一种基于spark平台web服务个性化推荐方法中构建用户关联矩阵的示例图;
图5为本发明提出的一种基于spark平台web服务个性化推荐方法中构建web服务关联矩阵的示例图;
图6为本发明提出的一种基于spark平台web服务个性化推荐方法中聚类算法并行实现的示例图;
图7为本发明提出的一种基于spark平台web服务个性化推荐方法的步骤示意图;
图8为本发明提出的一种基于spark平台web服务个性化推荐系统的模块图。
具体实施方式
下面对本发明的实施例作详细说明,本实施例在以本发明技术方案为前提下进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
参照图1-图7,本发明提出的一种基于spark平台web服务个性化推荐方法,包括下述步骤:
s1、提取用户在电商应用或信息平台的行为数据,对收集的用户对web服务的历史行为信息进行评估分析;
s2、用基于商空间粒度分析的覆盖聚类算法对收集的用户对web服务的历史行为信息进行聚类处理得出聚类结果;
s3、根据上述步骤s2中的聚类结果构建用户关联矩阵mu和web服务关联矩阵ms;
s4、通过对上述步骤s3中构建的关联矩阵进行目标用户和目标web服务的相似邻居分析,得出目标用户和目标web服务的相似邻居结果;
s5、根据上述步骤s4中目标用户和目标web服务的相似邻居结果的聚类信息分别对用户的评价值qos进行预测;
s6、混合处理步骤s5中的预测结果得出推荐方案,完成整个推荐算法;
s7、在spark平台下对该推荐算法进行并行化计算,并对计算结果进行存储,提高推荐系统的性能。
所述步骤s2中,采用基于用户(user)和web服务(service)二重混合的混合推荐算法对收集的用户对web服务的历史行为信息信息进行聚类,上述进行聚类的过程采用基于商空间粒度分析的覆盖聚类算法,所述基于商空间粒度分析的覆盖聚类算法具体包括如下步骤:
s01、计算出所有未学习过的样本点的重心,并以离该重心最近的样本点作为覆盖的圆心;
s02、计算出所有还未聚类的样本点与圆心的距离;
s03、计算出步骤s02中所有距离的平均距离,以上述平均距离为半径;
s04、并根据上述半径计算出球形覆盖;
s05、计算当前球形覆盖的重心;当样本点的个数大于预设值是,执行步骤s06,当样本点的个数不大于预设值是,执行步骤s07;
s06、将离步骤s05中球形覆盖的圆心最远的点作为新的圆心,并根据上述新的圆心重复步骤s02、s03、s04、s05,直到所有的样本全部覆盖结束;
s07、将离步骤s05中球形覆盖的圆心最近的点最为新的圆心,计算出步骤s05中球形覆盖的圆心与新的圆心的距离,将离的最近的两个球形覆盖合并为一个新的球形覆盖,并更新其他覆盖与新覆盖的最短距离,如此重复,确定最后的聚类数;
s08、计算出所有覆盖聚类结果中球形覆盖与球形覆盖两两之间的相似度;
s09、比较s08步骤中计算得出的所有相似度值,得到最大相似度阈值;
s10、如果最大相似度阈值大于经过实验获得的相似度阈值,则覆盖聚类结束,确定最后的聚类数,否则,将相似度最大的两个球形覆盖合并,重复步骤s08、s09,更新其他球形覆盖与获得的新的球形覆盖之间的相似度值,直到覆盖聚类结束。
所述推荐算法采用基于用户和web服务的二重聚类混合的混合推荐算法;
基于用户的聚类。对于每一个web服务,根据用户user对该service的评价值qos进行聚类,将每一个service中用户给出的评价值qos相似的user聚为一类。如图2所示,共有4个service,例如在s1中,根据所有user对s1的评价值qos,对这些user进行基于商空间粒度分析的覆盖聚类操作,将评价值qos相似user聚为一类,得到{u1,u6,u8,u9},{u2,u4}和{u3,u5,u7}。
基于web服务的聚类。对于每一个user,根据用户user对已经调用过且有过评价值qos的service进行聚类,将这些user给出评价值qos相似的service聚为一类。如图3所示,共有9个user,例如在u4中,根据当前用户对service的评价值qos,对这些service进行基于商空间粒度分析的覆盖聚类操作,将user给出评价值qos相似的service聚为一类,得到{s1,s2,s4}和{s3}。
基于用户和web服务的二重聚类混合的混合推荐算法的流程结构具有以下优点:
(1)这种结构设计的算法同时考虑了用户和web服务两方面的信息,而且该推荐算法还加入用户和web服务的聚类信息进行评价值qos预测,可以有效地缓解推荐系统中常见的数据稀疏性问题。
(2)分别对用户和web服务进行基于商空间粒度分析的覆盖聚类,构建了用户关联矩阵mu和服务关联矩阵ms,可以更深层次地挖掘用户和服务之间的关系,能够更好的找到目标用户和目标web服务的相似邻居,改善预测的精度,提高推荐结果的准确性。
(3)对用户和web服务进行聚类的算法是基于商空间粒度分析的覆盖聚类算法,该算法采用覆盖的理念将比较集中的数据点聚合在一起,在覆盖后不断更新中心,不断调整完成的覆盖,不需要对大量数据进行复杂的迭代操作,解决了初始值选择和聚类速度等问题。该算法还引入了粒度的概念,选择不同的粒度计算时,可以直观的从不同角度理解样本类内和类间的物理意义,对问题有实际的指导意义。
(4)基于用户聚类的推荐算法更侧重用户个人偏好,单个用户的多样性比较好;基于web服务聚类的推荐算法考虑了其他用户的偏好,系统的多样性较好。因此两者结合进行推荐,考虑的范围更广,推荐结果更加准确。
(5)该推荐算法是基于spark实现,解决了大数据环境中数据的可扩展性问题。
优选地,所述步骤s3中,在对用户进行聚类后,根据每一个web服务下用户的聚类情况,计算出两两用户被分为一类的次数,用cluster-numu1,u2表示用户u1和用户u2被分为一类的次数,如图4所示;在对web服务进行聚类后,根据每一个用户下web服务的聚类情况,计算出两两web服务被分为一类的次数,用cluster-nums1,s2表示web服务s1和web服务s2被分为一类的次数,如图5所示。
优选地,所述步骤s4中,根据关联矩阵得出目标用户相似邻居similar-neighbors(user)的过程具体包括:对目标用户与邻居用户的被分为一类的次数cluster-num进行降序操作,取前ku个cluster-num值最大的邻居用户作为目标用户的相似邻居similar-neighbors(user);得出目标web服务相似邻居similar-neighbors(service)的过程具体包括:对目标web服务与邻居web服务的被分为一类的次数cluster-num进行降序操作,取前ks个cluster-num值最大的邻居web服务作为目标web服务的相似邻居similar-neighbors(service);其中,ku和ks均为预设值。ku和ks是通过实验取值的,进行一系类不同ku和ks值的实验,通过实验结果,即预测精度来取值,选择预测精度最高的ku和ks值。
优选地,步骤s5中,根据得出的相似邻居结果对用户的评价值qos预测具体包括:
根据得出的目标用户相似邻居similar-neighbors(user)的覆盖信息,以及下述公式预测用户u对web服务s的评价值qos;
其中,ku表示目标用户的相似邻居的数目,au(t)表示用户u的相似邻居中第au(t)个用户,
根据得出的目标web服务相似邻居similar-neighbors(service)的覆盖信息,以及下述公式预测用户u对web服务s的评价值qos;
其中,ks表示目标web服务的相似邻居的数目,as(t)表示web服务s的相似邻居中第as(t)个用户,
步骤s6,具体包括:依据qu,s(u)以及qu,s(s)得出的基于用户与基于web服务二重聚类的评价值qos预测,利用混合因子λ将基于用户聚类的推荐算法的评价值qos预测和基于web服务聚类的推荐算法的评价值qos预测相混合,得出下述公式:
qu,s=λqus(u)+(1-λ)qus(s);
将得出的qu,s进行降序排列,取出前n位的web服务作为推荐方案;其中,所述n为预设值。n值根据用户需求取值,用户想要获得n个服务,就取n,如果用户没有说明,就是根据经验取值。
步骤s7,具体包括:
在spark平台下对推荐算法进行并行化计算时,对用户聚类具体采用基于商空间粒度分析的覆盖聚类算法,上述基于商空间粒度分析的覆盖聚类算法具体包括getcenter、getradius、getcovering;getcenter用于计算每个web服务中用户对上述web服务的评价值qos的重心,并以离该重心最近的数据点作为球形覆盖的圆心;getradius用于计算每一个web服务中尚未聚类的数据点与圆心之间的距离,且计算出上述所有距离的平均距离,并将上述的平均距离作为球形覆盖的半径;getcovering用于计算所有每一个web服务中属于由上述圆心和半径所构成的球形覆盖内的所有样本点。
在spark平台下对推荐算法进行并行化计算时,对web服务聚类具体采用基于商空间粒度分析的覆盖聚类算法,上述基于商空间粒度分析的覆盖聚类算法具体包括getcenter、getradius、getcovering;getcenter用于计算每个用户对调用过的web服务的评价值qos的重心,并以离该重心最近的数据点作为球形覆盖的圆心;getradius用于计算每一个用户中尚未聚类的数据点与圆心之间的距离,且计算出上述所有距离的平均距离,并将上述的平均距离作为球形覆盖的半径;getcovering用于计算每一个用户中属于由上述圆心和半径所构成的球形覆盖内的所有样本点。
本实施方式的个性化推荐算法的实现过程中,spark需要一个分布式文件系统做数据源,因此需要将数据存储在hdfs中,然后将数据转换为rdd(弹性分布式数据集)形式进行并行操作。rdd是spark的一个主要的抽象,rdd提供了一种高度受限的共享内存模型,因此工程师可以将rdd缓存在多个机器的内存中,实现高效率的并行计算。
基于用户聚类的并行实现,对用户user聚类使用的是基于商空间粒度分析的覆盖聚类算法,如图6所示,主要包括多个phase,每个phase都是获得一个球形覆盖的阶段,每个phase主要包括3个并行操作:getcenter、getradius和getcovering。
getcenter:计算每一个service中user评价值qos的重心,并以离该重心最近的数据点作为覆盖的圆心。getcenter的并行化主要是从hdfs中读入数据,数据格式为<user,service,qos>,然后转化为相应的rdd结构,通过reduce操作获得重心,然后通过map操作将rdd转换为与重心计算过距离的新的rdd,最后再通过reduce操作得到距离重心最近的点最为覆盖的圆心center。
getradius:计算每一个service中尚未聚类的点与圆心center的距离,然后得出所有距离的平均距离avg-d,并以该avg-d作为覆盖半径r。getradius并行化主要是通过map操作并行计算所有未聚类点到圆心center的距离,获得一个新的rdd,然后在对这个新的rdd进行reduce操作即并行计算上述所有距离的平均距离avg-d,即获得覆盖的半径r。
getcovering:计算每一个service中属于圆心center和半径r覆盖内的所有数据点。getcovering并行化主要是通过filter操作并行计算出距离圆心center小于半径r的rdd数据,即距离圆心center小于半径r的数据属于这个球形覆盖,获得这个球形覆盖。
基于web服务聚类的并行实现类似于基于用户聚类的并行实现。
参照图8,本发明提出一种基于spark平台web服务个性化推荐系统,包括:
用户历史行为信息收集模块,提取用户在电商应用或信息平台的行为数据,对收集的行为数据进行评估分析;
聚类模块,利用基于商空间粒度分析的覆盖聚类算法对收集的用户对web服务的历史行为信息进行聚类处理得出聚类结果;
构建关联矩阵模块,根据上述聚类结果构建用户关联矩阵mu和web服务关联矩阵ms;
相似邻居结果计算模块,通过对上述构建的关联矩阵进行目标用户和目标web服务的相似邻居分析,得出目标用户和目标web服务的相似邻居结果;
评价值qos预测模块,根据上述相似用户和相似web服务相似邻居结果的聚类信息对用户的评价值qos进行预测;
混合处理和推荐模块,对用户的评价值qos的预测值进行混合处理得出推荐方案,完成整个推荐算法;
spark平台推荐算法并行化处理模块,在spark平台下对推荐算法进行并行化计算,并对上述计算结果进行存储。
优选地,聚类模块采用基于用户和web服务的二重聚类混合的混合推荐算法对收集的用户对web服务的历史行为信息进行聚类,上述进行聚类的过程采用基于商空间粒度分析的覆盖聚类算法,所述基于商空间粒度分析的覆盖聚类算法具体包括如下步骤:
s01、计算出所有未学习过的样本点的重心,并以离该重心最近的样本点作为覆盖的圆心;
s02、计算出所有还未聚类的样本点与圆心的距离;
s03、计算出步骤s02中所有距离的平均距离,以上述平均距离为半径;
s04、并根据上述半径计算出球形覆盖;
s05、计算当前球形覆盖的重心;当样本点的个数大于预设值是,执行步骤s06,当样本点的个数不大于预设值是,执行步骤s07;
s06、将离步骤s05中球形覆盖的圆心最远的点作为新的圆心,并根据上述新的圆心重复步骤s02、s03、s04、s05,直到所有的样本全部覆盖结束;
s07、将离步骤s05中球形覆盖的圆心最近的点最为新的圆心,计算出步骤s05中球形覆盖的圆心与新的圆心的距离,将离的最近的两个球形覆盖合并为一个新的球形覆盖,并更新其他覆盖与新覆盖的最短距离,如此重复,确定最后的聚类数;
s08、计算出所有覆盖聚类结果中球形覆盖与球形覆盖两两之间的相似度;
s09、比较s08步骤中计算得出的所有相似度值,得到最大相似度阈值;
s10、如果最大相似度阈值大于经过实验获得的相似度阈值,则覆盖聚类结束,确定最后的聚类数,否则,将相似度最大的两个球形覆盖合并,重复步骤s08、s09,更新其他球形覆盖与获得的新的球形覆盖之间的相似度值,直到覆盖聚类结束。
构建关联矩阵模块中,在对用户进行聚类后,根据每一个web服务下用户的聚类情况,计算出两两用户被分为一类的次数,用cluster-numu1,u2表示用户u1和用户u2被分为一类的次数;在对web服务进行聚类后,根据每一个用户下web服务的聚类情况,计算出两两web服务被分为一类的次数,用cluster-nums1,s2表示web服务s1和web服务s2被分为一类的次数;
相似邻居结果计算模块用于对关联矩阵构建模块的关联矩阵进行目标web服务相似邻居分析得出目标用户相似邻居similar-neighbors(user)、目标web服务的相似邻居similar-neighbors(service);
相似邻居结果计算模块得出目标用户相似邻居similar-neighbors(user)的过程具体包括:对目标用户与邻居用户的被分为一类的次数cluster-num进行降序操作,取前ku个cluster-num值最大的邻居用户作为目标用户的相似邻居similar-neighbors(user);得出目标web服务相似邻居similar-neighbors(service)的过程具体包括:对目标web服务与邻居web服务的被分为一类的次数cluster-num进行降序操作,取前ks个cluster-num值最大的邻居web服务作为目标web服务的相似邻居similar-neighbors(service);其中,ku和ks均为预设值;
评价值qos预测模块用于根据关联矩阵计算模块得出的相似邻居结果对用户对未调用过的web服务的评价值qos进行预测,对用户的评价值qos预测具体包括:
根据得出的目标用户相似邻居similar-neighbors(user)的覆盖信息,以及下述公式预测用户u对web服务s的评价值qos;
其中,ku表示目标用户的相似邻居的数目,au(t)表示用户u的相似邻居中第au(t)个用户,
根据得出的目标web服务相似邻居similar-neighbors(service)的覆盖信息,以及下述公式预测用户u对web服务s的评价值qos;
其中,ks表示目标web服务的相似邻居的数目,as(t)表示web服务s的相似邻居中第as(t)个用户,
混合处理和推荐模块,依据qu,s(u)以及qu,s(s)得出的基于用户与基于web服务二重聚类的评价值qos预测,利用混合因子λ将基于用户聚类的推荐算法的评价值qos预测和基于web服务聚类的推荐算法的评价值qos预测相混合,得出下述公式:
qu,s=λqus(u)+(1-λ)qus(s);
将预测和混合模块得出的qu,s进行降序排列,取出前n位的web服务作为推荐方案;其中,所述n为预设值。
所述spark平台推荐算法并行化处理模块在spark平台下对推荐算法进行并行化计算时,对用户聚类具体采用基于商空间粒度分析的覆盖聚类算法,上述基于商空间粒度分析的覆盖聚类算法具体包括getcenter、getradius、getcovering;getcenter用于计算每个web服务中用户对上述web服务的评价值qos的重心,并以离该重心最近的数据点作为球形覆盖的圆心;getradius用于计算每一个web服务中尚未聚类的数据点与圆心之间的距离,且计算出上述所有距离的平均距离,并将上述的平均距离作为球形覆盖的半径;getcovering用于计算每一个web服务中属于由上述圆心和半径所构成的球形覆盖内的所有样本点;
所述spark平台推荐算法并行化处理模块在spark平台下对推荐算法进行并行化计算时,对web服务聚类具体采用基于商空间粒度分析的覆盖聚类算法,上述基于商空间粒度分析的覆盖聚类算法具体包括getcenter、getradius、getcovering;getcenter用于计算每个用户对调用过的web服务的评价值qos的重心,并以离该重心最近的数据点作为球形覆盖的圆心;getradius用于计算每一个用户中尚未聚类的数据点与圆心之间的距离,且计算出上述所有距离的平均距离,并将上述的平均距离作为球形覆盖的半径;getcovering用于计算每一个用户中属于由上述圆心和半径所构成的球形覆盖内的所有样本点。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!