词典更新装置及词典更新方法与流程
本申请享受2016年9月6日在先提出的日本国专利申请号2016-173918的优先权的利益,并且包括在先申请的全部内容。
本发明的实施方式涉及词典更新装置及词典更新方法。
背景技术:
以往,关于使用单词词典进行声音识别处理的声音识别系统,根据用户对识别结果的修正操作来追加登记未登记于单词词典的单词的技术为人们所知。该现有技术,在用户进行的修正后的单词未被登记于单词词典的情况下,将修正后的单词自动地向单词词典中追加登记。为此,存在登记到单词词典中反而对声音识别处理造成不良影响的单词也被追加登记的情况,要求改善。
技术实现要素:
本发明要解决的课题在于,提供能够有效地抑制将不应该登记的单词追加登记到单词词典中的不良情况的词典更新装置。
实施方式的词典更新装置具备候补提取部、选择控制部及单词登记部。候补提取部基于识别结果文本和修正结果文本,提取对单词词典追加登记的单词的候补,该识别结果文本通过声音识别引擎使用所述单词词典进行声音识别处理而获得,该修正结果文本表示对该识别结果文本的至少一部分进行了修正后的结果。选择控制部生成选择画面,并受理对显示于该选择画面的候补进行选择的操作,所述选择画面上以能够选择的方式显示提取到的候补,并且至少一并显示表示在将该候补追加登记到所述单词词典中的情况下对声音识别处理带来的影响的信息。单词登记部将在所述选择画面上所选择的候补追加登记到所述单词词典中。
根据上述构成的词典更新装置,能够有效地抑制将不应该登记的单词追加登记到单词词典中的不良情况。
附图说明
图1是表示实施方式的服务器装置的功能上的构成例的框图。
图2是表示用户数据的一例的图。
图3是表示声音数据的一例的图。
图4是表示单词词典的一例的图。
图5是表示识别结果数据的一例的图。
图6是表示修正结果数据的一例的图。
图7是表示候补数据的一例的图。
图8是表示关联文件数据的一例的图。
图9是表示评价用数据的一例的图。
图10是表示选择画面的一例的图。
图11是表示服务器装置的动作例的流程图。
图12是表示服务器装置的硬件构成例的框图。
具体实施方式
以下,参照附图详细地说明实施方式的词典更新装置及词典更新方法。以下,举出将实施方式的词典更新装置作为进行使用了单词词典的声音识别处理的声音识别系统的扩张功能来实现的例子进行说明。作为一个例子,声音识别系统能够作为利用了网络的服务器·客户端系统的服务器装置而实现。该服务器装置,根据对于通过使用了单词词典的声音识别处理而获得的识别结果文本的修正操作,提取对单词词典追加登记的单词的候补。并且,生成将提取到的候补以能够选择的方式显示的后述的单词选择画面,并将在该单词选择画面上所选择的候补登记到单词词典中。
图1是表示本实施方式的服务器装置10的功能上的构成例的框图。本实施方式的服务器装置10,例如从声音识别利用应用程序30、浏览器40经由网络而访问。声音识别利用应用程序30是利用基于服务器装置10的声音识别处理的任意的应用程序,在任意的注册用户使用的客户端装置上动作。该客户端装置至少具备:作为声音识别利用应用程序30的执行环境的计算机资源、用于输入用户的声音的领夹麦克风(pinmac)、耳机等的声音输入装置、用于显示识别结果文本的显示装置、用于输入对识别结果文本的修正操作的鼠标、键盘、指示器、触摸屏等操作输入装置、及用于经由网络与服务器装置10连接的通信装置。
另外,浏览器40是用于阅览服务器装置10提供的后述的选择画面的软件,例如在系统的管理者、或者声音识别利用应用程序30的管理者等使用的客户端装置上动作。该客户端装置至少具备作为浏览器40的执行环境的计算机资源、用于显示后述的选择画面的显示装置、用于输入对选择画面的操作的鼠标、键盘、指示器、触摸屏等操作输入装置、用于经由网络与服务器装置10连接的通信装置。另外,也可以是声音识别利用应用程序30和浏览器40在共用的客户端装置上动作的构成。也就是说,可以是使用浏览器40进行用于登记单词的操作的系统的管理者、声音识别利用应用程序30的管理者等使用声音识别利用应用程序30进行对识别结果文本的修正操作,也可以是声音识别利用应用程序30的终端用户使用浏览器40进行用于登记单词的操作。
本实施方式的服务器装置10如例如图1所示,具备用户认证部11、声音输入受理部12、声音识别引擎13、修正控制部14、候补提取部15、精度评价部16、选择控制部17及单词登记部18。
用户认证部11进行从声音识别利用应用程序30、浏览器40向系统的登录处理。通过登录处理,服务器装置10确定访问系统的用户,并把握由声音输入受理部12受理了输入的声音是哪个用户的声音、进行对哪个用户的单词登记动作等。用户通过从声音识别利用应用程序30、浏览器40登录到系统中,从而能够利用本实施方式的服务器装置10的服务。设为能够登录系统的用户是在事前注册过的用户。与注册过的用户(注册用户)有关的用户数据,被存储于用户数据保存部21。用户认证部11参照用户数据保存部21,进行登录处理。用户认证部11具备用于进行认证的api(applicationprogramminginterface:应用程序界面)及ui(userinterface:用户界面)。
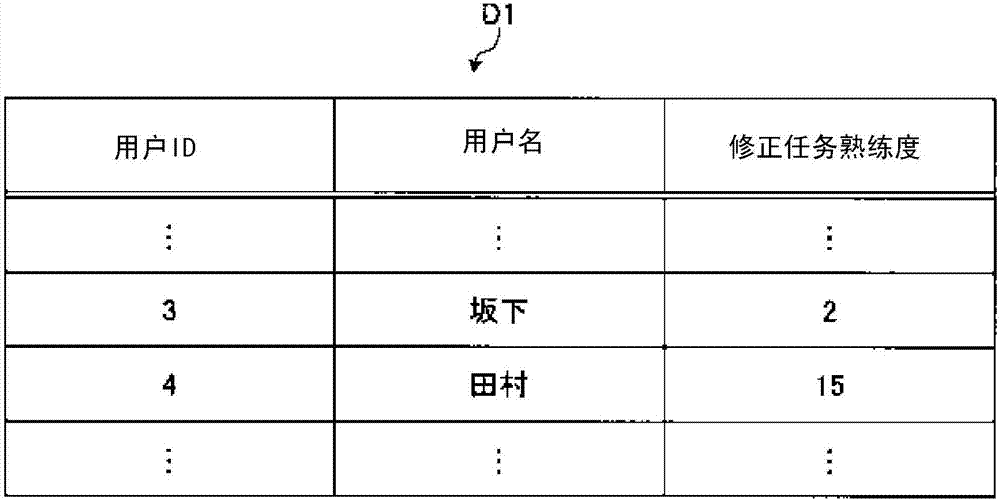
图2是表示存储于用户数据保存部21的用户数据d1的一例的图。用户数据d1如例如图2所示,包括用户id、用户名及修正任务熟练度。用户id是对于各注册用户唯一地分配的识别信息。用户名是用于判别用户的固有名。在登录处理中用户输入或选择用户名。修正任务熟练度被用于计算后述的候补提取部15提取到的候补的得分。关于修正任务熟练度的设定及利用方法,在后面叙述。用户数据d1可以包含用户的邮箱地址、用于认证的密码等其他的信息。
声音输入受理部12受理来自声音识别利用应用程序30的声音输入,并将包含所输入的声音及其附加信息的声音数据保存于声音数据保存部22。从声音识别利用应用程序30,输入例如声音输入按钮的开启关闭等用户的明示的操作、或者根据检测到用户的发声中断一定时间以上的情况等而分割的连续的声音。声音输入受理部12将该连续的声音作为单一的声音而保存在声音数据保存部22中。
图3是表示保存在声音数据保存部22中的声音数据d2的一例的图。声音数据d2如例如图3所示,包括声音id、用户id、声音及发声日期时间。声音id是对各声音唯一地分配的识别信息。用户id表示哪个用户发出了该声音。声音是该声音本身的字节数据。发声日期时间表示进行了该声音的发声的日期时间。
通过声音输入受理部12受理了输入的声音,从声音输入受理部12直接被读出、或者暂时保存于声音数据保存部22后被读出,并被送至声音识别引擎13。
声音识别引擎13使用单词词典保存部23保存的单词词典,对通过声音输入受理部12受理了输入的声音进行声音识别处理。单词词典存在与各用户相对应的单一的单词词典,使用与请求声音识别处理的用户对应的单词词典进行声音识别处理。也可以是存在多个用户共享的单词词典,用户选择共享单词词典并进行声音识别处理、后述的单词登记动作的构成。
图4是表示单词词典保存部23保存的单词词典d3的一例的图。单词词典d3如例如图4所示,包括单词id、标记及读法。单词id是对登记于单词词典d3的各单词唯一地分配的识别信息。标记表示该单词如何显示。读法由建立与该单词的音素的对应所用的平假名、片假名构成。对1个单词可以登记有多个读法。单词词典d3也可以包含各单词的词类信息等其他的信息。
声音识别引擎13进行的声音识别处理的结果,作为识别结果数据被保存在识别结果保存部24中。图5是表示保存在识别结果保存部24中的识别结果数据d4的一例的图。识别结果数据d4如例如图5所示,包括识别结果id、声音id、发声日期时间及识别结果文本。识别结果id是对各识别结果唯一地分配的识别信息。声音id表示该识别结果是对哪个声音的声音识别处理的结果。发声日期时间表示进行与该识别结果对应的声音的发声的日期时间。识别结果文本是作为声音识别处理的结果而获得的文本数据。声音识别引擎13将单一的声音以未进行发声的区间分割而进行声音识别处理,因此对于单一的声音获得多个识别结果的情况存在。
修正控制部14接受来自声音识别利用应用程序30的请求,对识别结果文本进行修正。修正控制部14例如生成显示所指定的范围的识别结果文本的修正画面,并在该修正画面上受理用户的修正操作,从而修正识别结果文本。但是,修正控制部14只要是能够取得与用户对识别结果文本的修正操作对应的修正结果的构成即可,不限于上述的例子。修正控制部14的修正结果,作为修正结果数据被保存于修正结果保存部25。
图6是表示保存于修正结果保存部25的修正结果数据d5的一例的图。修正结果数据d5如例如图6所示那样、包括修正结果id、识别结果id、修正用户id、修正日期时间及修正结果文本。修正结果id是对各修正结果唯一地分配的识别信息。识别结果id表示该修正结果是对哪个识别结果文本进行修正而获得的。修正用户id是进行了修正的用户的用户id。修正日期时间表示进行了修正的日期时间。修正结果文本是通过修正识别结果文本而获得的文本数据。对识别结果文本的修正,不仅能够针对对于该用户的发声进行声音识别处理而获得的识别结果文本进行,还能够针对对于其他的用户的发声进行声音识别处理而获得的识别结果文本进行。也可以是修正控制部14、声音识别利用应用程序30限制能够对某识别结果文本进行修正的用户的构成。
候补提取部15参照识别结果保存部24及修正结果保存部25,基于识别结果数据d4中包含的识别结果文本及修正结果数据d5中包含的修正结果文本,提取对单词词典d3追加登记的单词的候补。候补提取部15例如根据从浏览器40请求后述的选择画面的生成而被调用。候补的提取例如通过检测修正结果文本相对于识别结果文本的差分来进行。即,候补提取部15例如基于图5所例示的识别结果id为65的识别结果文本“理解あは人的動きを把握し認識します”、及图6所例示的修正结果id为32的修正结果文本“リカイアは人的動きを把握し認識します”,检测出识别结果文本中包含的“理解あ”为“リカイア”的情况,作为修正结果文本相对于识别结果文本的差分,并提取修正结果文本中包含的“リカイア”,作为对单词词典d3追加登记的单词的候补。在检测修正结果文本相对于识别结果文本的差分时,也可以进行对修正结果文本进行语态素分析并仅将被认为是差分之中或周边的名词的部分作为提取对象的后处理。
由候补提取部15提取到的候补,作为候补数据被保存在候补保存部26中。图7是表示保存在候补保存部26中的候补数据d6的一例的图。候补数据d6如例如图7所示,包括候补id、标记、读法、修正结果id、精度提高贡献率、得分、得分增加因素信息、得分减少因素信息。
候补id是对于候补提取部15提取到的各候补唯一地分配的识别信息。标记从修正结果文本获得。关于读法,在标记为平假名或片假名的情况下原封不动利用标记,在这以外的情况下参照例如记述有标记与读法的对应关系的外部词典而取得。另外,关于读法未判明的候补,也可以采用使读法为空白栏并在后述的选择画面上由用户追加记载读法的构成。关于用字母示出标记的候补,也可以记录将字母的读法连结后的读法作为该候补的读法。
修正结果id表示该候补是从哪个修正结果文本提取到的。在从多个修正结果文本提取到同一候补的情况下,在该候补的修正结果id中,记录与提取到该候补的多个修正结果文本对应的多个修正结果id。
精度提高贡献率表示,通过对单词词典d3追加登记该候补,声音识别引擎13的识别精度提高何种程度。精度提高贡献率例如通过用精度评价部16评价该候补的登记前及登记后的声音识别引擎13的识别精度而计算。在声音识别引擎13的识别精度在该候补的登记前后提高了例如1.0百分点的情况下,即候补的登记后的识别精度相对于登记前的识别精度的差分为+1.0百分点的情况下,该候补的精度提高贡献率为1.0。另外,关于精度评价部16的识别精度的评价,在后面叙述。
得分表示该候补的优先度,基于几个得分增加因素及得分减少因素而计算。得分增加因素表示该候补的得分的计算中使用的得分增加因素,得分减少因素表示该候补的得分的计算中使用的得分减少因素。
作为得分增加因素,例如列举出该候补是与后述的关联文件内的重要词语一致的单词、该候补从很多的修正结果文本提取而修正频率高、使识别精度提高的效果高、进行了修正的用户的修正任务熟练度高等。另一方面,作为得分减少因素,例如列举出该候补的字符数少等。
对于从修正结果文本提取到的候补,候补提取部15判定上述的得分增加因素及得分减少因素的有无,根据得分增加因素、得分减少因素来增减作为基础的得分,从而计算候补的得分。得分的增减值,既可以是按每个因素为固定的值,也可以是例如关于修正频率超过基准值引起的得分的增加以修正频率越高则越增大得分的增加值等方式加以校正。候补提取部15将这样计算出的各候补的得分,与得分计算中使用的得分增加因素、得分减少因素一起记录。
为了判定是与关联文件内的重要词语一致的单词这一得分增加因素的有无,候补提取部15参照保存了与关联文件有关的关联文件数据的关联文件数据保存部27。关联文件是与利用服务器装置10的服务的声音识别利用应用程序30关联的文件,如果声音识别利用应用程序30是使会议声音文本化的应用程序,则设想为与该会议有关的资料,如果是将呼叫中心中的对话标签文本化的应用程序,则设想为业务的手册等。
图8是表示保存在关联文件数据保存部27中的关联文件数据d7的一例的图。关联文件数据d7如例如图8所示,包括文件id、用户id、文件名、重要词语。文件id是针对所登记的各关联文件唯一地分配的识别信息。用户id表示哪个用户登记了该关联文件。文件名是该关联文件的文件名。重要词语是从该关联文件提取到的重要词语,使用例如tf-idf等的文本处理的指标从关联文件提取。
对于从修正结果文本提取到的候补,候补提取部15从关联文件数据d7检索与该候补的标记一致的重要词语,在找到了与候补的标记一致的重要词语的情况下,使该候补的得分增加,并且记录“关联文件内重要词语”作为得分增加因素。
另外,为了判定修正频率高这一得分增加因素的有无,对于从修正结果文本提取到的候补,候补提取部15例如计数已记录在候补数据d6中的修正结果id的数量,判定修正id的数量是否为基准值(例如3)以上。并且,如果候补数据d6中记录的修正结果id的数量为基准值以上(也就是说修正频率为基准值以上),则使该候补的得分增加,并且记录“修正频率高”作为得分增加因素。
另外,为了判定使识别精度提高的效果高这一得分增加因素的有无,对于从修正结果文本提取到的候补,候补提取部15例如将记录于候补数据d6的精度提高贡献率与规定的阈值(例如1.0百分点)进行比较,并判定精度提高贡献率是否为阈值以上。并且,如果精度提高贡献率为阈值以上,则判断为使识别精度提高的效果高,使该候补的得分增加,并且记录“精度提高效果高”作为得分增加因素。
另外,为了判定进行了修正的用户的修正任务熟练度高这一得分增加因素的有无,对于从修正结果文本提取到的候补,候补提取部15首先将记录于候补数据d6的修正结果id作为关键字检索修正结果数据d5,并取得对应的修正用户id。接着,候补提取部15,将所取得的修正用户id作为关键字检索用户数据d1,取得进行了修正的用户的修正任务熟练度。然后,候补提取部15将所取得的修正任务熟练度与规定值(例如15)进行比较,如果修正任务熟练度为规定值以上,则判断为进行了修正的用户的修正任务熟练度高,使该候补的得分增加,并且记录“熟练用户的修正”作为得分增加因素。
另外,为了判定候补的字符数少这一得分减少因素的有无,对于从修正结果文本提取到的候补,候补提取部15例如将记录于候补数据d6的标记的字符数与规定数(例如3)进行比较,并判定标记的字符数是否为规定数以下。并且,如果标记的字符数为规定数以下,则判定为候补的字符数少,使该候补的得分减少,并且记录“短的单词”作为得分减少因素。
这里,对评价声音识别引擎13的识别精度的精度评价部16进行说明。精度评价部16使用保存于评价用数据保存部28的评价用数据,评价声音识别引擎13的识别精度。图9是表示保存于评价用数据保存部28的评价用数据d8的一例的图。评价用数据d8如例如图9所示,包括评价用数据id、评价用声音、书写文本。评价用数据id是对于保存于评价用数据保存部28的各评价用数据唯一地分配的识别信息。评价用声音是评价中使用的声音的字节数据。书写文本是由评价用数据d8的作成者书写的文本,是与评价用声音对应的正确的文本。
精度评价部16,将评价用数据d8中包含的评价用声音输入至声音识别引擎13,将由声音识别引擎13对该评价用声音进行声音识别处理而获得的识别结果文本,与对应于评价用声音的书写文本进行比较。并且,基于两者的一致度,评价声音识别引擎13的识别精度。作为识别结果文本与书写文本的一致度,使用例如字符正确率等。使用该精度评价部16,评价将候补提取部15提取到的候补作为单词词典d3中包含的单词对待的情况下的声音识别引擎13的识别精度,由此能够计算该候补的精度提高贡献率。
选择控制部17生成选择画面,并受理对显示于该选择画面的候补进行选择的操作,该选择画面上将候补提取部15提取到的候补以能够选择的方式显示,并且至少一并显示表示将该候补追加登记到单词词典d3的情况下对声音识别处理带来的影响的信息。
图10是表示选择控制部17生成的选择画面50的一例的图。选择画面50如例如图10所示,包括候补列表显示区域51、修正履历显示区域52、变化例显示区域53、精度变化显示区域54、得分增减因素显示区域55及“登记”按钮56。
在候补列表显示区域51,显示候补提取部15提取到的候补的列表(候补列表)。候补列表是将候补提取部15提取到的候补按得分从高到低的顺序排列的列表。候补列表中包含的各候补分别用标记57和读法58表示,在各候补的左侧,配置有用于选择该候补作为对单词词典d3追加登记的单词的复选框59。候补列表中包含的各候补的得分、标记57及读法58,从上述的候补数据d6取得。
在修正履历显示区域52,显示与候补列表中包含的各候补对应的修正履历。修正履历例如以用箭头等记号将该候补的提取中使用的识别结果文本与修正结果文本的对建立对应的形式显示。例如,从上述的候补数据d6选择一个各候补的修正结果id,取得与该修正结果id对应的修正结果文本及与同该修正结果id建立关联的识别结果id对应的识别结果文本并进行显示。
在变化例显示区域53,显示与候补列表中包含的各候补对应的识别结果文本的变化例。所谓的与各候补对应的识别结果文本的变化例,是在将该候补对单词词典d3追加登记的前后,声音识别引擎13输出的识别结果文本变化的例子。识别结果文本的变化例,例如检测在将该候补对单词词典d3追加登记的前后、声音识别引擎13输出的识别结果文本发生变化的部分,并以将包括该发生变化的部分的规定长度的识别结果文本的对用箭头等的记号建立对应的形式进行显示。在检测到多个识别结果文本变化的部分的情况下,使登记后的识别结果文本不包括候补的标记的文本优先地显示,由此能够对用户表示出通过将该候补对单词词典d3追加登记而其他的部分变化等、该候补的追加登记带来的副作用。另外,通过将登记前的识别结果文本与修正履历内的识别结果文本不同的文本优先地显示,从而能够对用户表示出将该候补对单词词典d3追加登记对修正过的部位以外有怎样的影响。另外,也可以采用与1个候补对应地显示多个变化例的构成。
在精度变化显示区域54显示出精度变化,该精度变化表示在将候补列表中当前所选择的候补、即复选框59中写入了复选的候补向单词词典d3追加登记的情况下声音识别引擎13的识别精度相比于登记前如何变化。精度变化,例如以用箭头等记号将使用了候补列表中包含的候补任一个都未被登记的当前的单词词典d3的情况下的声音识别引擎13的识别精度(登记前的识别精度)与使用了追加登记了当前所选择的候补的单词词典d3的情况下的声音识别引擎13的识别精度(登记后的识别精度)建立对应的形式来显示。登记后的识别精度,作为估算值,例如通过对登记前的识别精度加上针对当前所选择的候补所计算出的上述的精度提高贡献率而计算。如果当前所选择的候补有多个,则各候补的精度提高贡献率分别被加到登记前的识别精度上。因此,相应于所选择的候补,登记后的识别精度变化,表示登记前后的识别精度的变化的精度变化,以根据所选择的候补而变化的方式显示。
显示于变化例显示区域53的识别结果文本的变化例、与显示于精度变化显示区域54的精度变化,都是表示将候补追加登记到单词词典d3的情况下对声音识别处理带来的影响的信息。用户通过参照显示于选择画面50的这些信息,能够适当地判断是否应该将候补列表中包含的各候补追加登记到单词词典d3。
在得分增减因素显示区域55,显示与候补列表中包含的各候补对应的得分增加因素或得分减少因素。与各候补对应的得分增加因素、得分减少因素,从上述的候补数据d6取得。即,在得分增减因素显示区域55,显示例如“关联文件重要词语”、“修正频率高”、“精度提高效果高”、“熟练用户的修正”等作为得分增加因素。另外,在得分增减因素显示区域55,显示例如“短的单词”等作为得分减少因素。用户通过参照选择画面50上显示的这些信息,能够把握确定候补列表中包含的各候补的优先度的理由,能够更适当地判断是否应该将各候补追加登记到单词词典d3。
“登记”按钮56,是用户为了确定将在候补列表中选择的候补追加登记到单词词典d3中而进行操作的按钮。在选择画面50的“登记”按钮56被操作时,选择控制部17将在该时刻被选择的候补确定为追加登记的对象,并将该候补的标记57与读法58的对通知至单词登记部18。另外,此时,选择控制部17,对于确定为追加登记的对象的候补,取得候补数据d6中包含的修正结果id,并将该修正结果id作为关键字检索修正结果数据d5,从而取得表示进行了成为候补提取的基础的修正操作的用户的修正用户id。并且,在用户数据d1中使同与所取得的修正用户id一致的用户id对应的修正任务熟练度增加一定数量。
单词登记部18将在选择画面50上所选择的候补追加登记到单词词典d3。即单词登记部18相应于选择画面50的“登记”按钮56被操作,将从选择控制部17通知的候补的标记57与读法58的对,登记到单词词典d3。
接着,参照图11对本实施方式的服务器装置10的一系列的动作步骤的概要进行说明。图11是表示本实施方式的服务器装置10的动作例的流程图。
首先,声音识别引擎13,对于从声音识别利用应用程序30输入的声音,进行使用了单词词典d3的声音识别处理,并将识别结果作为识别结果数据d4保存在识别结果保存部24中(步骤s101)。
接着,修正控制部14,相应于用户的修正操作对识别结果数据d4中包含的识别结果文本进行修正,并将修正结果作为修正结果数据d5保存在修正结果保存部25中(步骤s102)。
接着,候补提取部15,基于识别结果数据d4中包含的识别结果文本和修正结果数据d5中包含的修正结果文本,提取对单词词典d3追加登记的单词的候补(步骤s103)。然后,候补提取部15,生成与在步骤s103中提取到的候补有关的候补数据d6,并保存在候补保存部26中(步骤s104)。
接着,选择控制部17,基于候补数据d6生成如图10所示的选择画面50(步骤s105),受理对显示于该选择画面50的候补进行选择的用户的操作(步骤s106)。
最后,单词登记部18,将在选择画面50上由用户所选择的候补追加登记到单词词典d3中(步骤s107),服务器装置10的一系列的动作结束。
以上,如举出具体的例子进行详细地说明那样,本实施方式的服务器装置10,基于通过声音识别引擎13使用单词词典d3进行声音识别处理而获得的识别结果文本及通过修正该识别结果文本的至少一部分而获得的修正结果文本,提取对单词词典d3追加登记的单词的候补。然后,生成选择画面50,并受理对在该选择画面50上所显示的候补进行选择的操作,该选择画面50将提取到的候补以能够选择的方式显示,并且至少一并显示表示在将候补追加登记到单词词典d3的情况下对声音识别处理带来的影响的信息。然后,将在选择画面50上所选择的候补追加登记到单词词典d3。因此,根据本实施方式的服务器装置10,能够使用户识别到在将对单词词典d3追加登记的单词的候补实际追加登记到单词词典d3中的情况下对声音识别处理带来的影响的同时选择对单词词典d3追加登记的单词。由此,能够有效地抑制将不应该登记的单词追加登记到单词词典d3中的不良情况。
本实施方式的服务器装置10,例如能够通过构成一般的计算机的硬件与用计算机执行的程序(软件)的协作来实现。例如,计算机执行规定的程序,由此能够实现上述的用户认证部11、声音输入受理部12、声音识别引擎13、修正控制部14、候补提取部15、精度评价部16、选择控制部17及单词登记部18。另外,能够使用计算机具备的大容量存储装置,实现上述的用户数据保存部21、声音数据保存部22、单词词典保存部23、识别结果保存部24、修正结果保存部25、候补保存部26、关联文件数据保存部27及评价用数据保存部28。另外,候补保存部26也可以使用临时性地保存数据的ram等的存储装置来实现。
图12是表示本实施方式的服务器装置10的硬件构成例的框图。服务器装置10如例如图12所示,具有具备cpu101等的硬件处理器、ram102、rom103等的存储装置、hdd104等的大容量存储装置、经由网络与外部进行通信的通信i/f105及用于连接周边设备的设备i/f106的作为通常的计算机的硬件构成。
此时,上述的程序例如记录在磁盘、光盘、半导体存储器或与之类似的记录介质中提供。记录程序的记录介质只要是计算机系统能够读取的记录介质即可,其存储形式可以是任意的方式。另外,可以构成为将上述程序以预先安装在计算机中,也可以构成为将经由网络发布的上述的程序适当安装在计算机中。
通过上述的计算机执行的程序,成为包括上述的用户认证部11、声音输入受理部12、声音识别引擎13、修正控制部14、候补提取部15、精度评价部16、选择控制部17及单词登记部18等的功能上的各部的模块构成,cpu101等的硬件处理器适当读出并执行该程序,由此上述的各部在ram102等的主存储器上生成。
另外,本实施方式的服务器装置10,也可以是通过asic(applicationspecificintegratedcircuit)、fpga(field-programmablegatearray)等专用的硬件来实现上述的功能上的各部的一部分或全部的构成。
另外,本实施方式的服务器装置10,也可以是构成为将多台计算机以能够通信的方式连接的网络系统,并将上述的各部分散于多台计算机而实现的构成。另外,本实施方式的服务器装置10也可以是在云系统上动作的虚拟机。
另外,在以上说明的实施方式中,例示出了将词典更新装置作实现为声音识别系统的扩张功能的例子,但实施方式的词典更新装置也可以构成为独立于声音识别系统的其他的装置。该情况下,词典更新装置,经由例如网络与声音识别系统连接,从声音识别系统取得识别结果文本、修正结果文本后进行以后的处理。
以上,对本发明的实施方式进行了说明,但该实施方式是作为例子提示的,意图不是限定发明的范围。该新的实施方式,能够以其他各种各样的方式实施,在不脱离发明的主旨的范围内,能够进行各种省略、置换、变更。这些实施方式及其变形,包含在发明的范围及主旨中,并且包含在权利要求书记载的发明及其等同的范围中。
- 还没有人留言评论。精彩留言会获得点赞!