一种基于隐马尔科夫模型的对风电功率预测误差区间进行估计的方法与流程
本发明属于电力系统预测领域,涉及电力系统调度过程中对风电场上报给调度部门的风电功率超短期预测值进行分析和预测的方法,特别能够得到未来一段时间内风电功率超短期预测值的误差范围以及变化的趋势。
背景技术:
随着化石能源的不断枯竭以及环境问题的不断加剧,以风电为代表的可再生能源的利用率不断提高,在各个国家的推动下,风力发电商业化程度不断提高,技术逐渐成熟,得到了迅速发展。目前,我国风电总装机容量已经居于世界第一位,风电并网规模的不断加大,一定程度上缓解了我国能源紧张问题。然而,由于风力发电机组运行时,存在较为明显的随机性和波动性,当风电并网容量提高时,其频繁波动和变化将影响电网的安全稳定及电能质量。因此,准确估计风电功率预测误差的范围,能够为含风电电力系统的运行调度提供重要信息。
传统的电力系统风电功率预测多为确定性的点预测,预测的结果以曲线的形式给出,在预测过程中存在各种不确定因素干扰,得到的结果一般都带有不同程度的误差。针对确定性的点预测的不足,为量化风电功率预测结果的不确定性,可针对日内风电功率预测误差区间进行估计,使调度人员能够提前根据风电功率误差范围和变化趋势及时调整调度计划,保证电能质量,减少系统的备用容量,降低电力系统运行成本以及因风电大规模并网给系统带来的风险。
对于风电功率预测误差区间的估计方法主要有两类,分为统计方法和启发式学习算法。统计方法主要基于风电功率的概率分布,计算在满足一定置信水平下,风电功率误差可能落入到区间中的上下限。应用统计方法,可以用某种分布对风电预测误差进行近似描述,正态分布是最为普遍的假设应用;如果风电预测误差的具体分布未知,可以直接依据风电预测误差的统计分布来描述。因此,这类方法需要获取风电预测误差的分布特征。启发式学习算法主要是通过学习历史数据的规律,预测风电功率误差的上限和下限。应用启发式学习算法是在历史统计数据与风电预测误差之间建立一种映射关系。该方法一般不依赖于风电功率预测误差的分布特征,同时可以以一定的概率涵盖风电预测误差的范围。
当评估复杂系统异常事件(如极端气象事件)构成的不确定性时,由随机变量序列表述的事件通常是相关的。现有方法得到的结果均未考虑风电功率预测误差相邻时段之间的时序相关性,以及没有用概率矩阵的形式描述风电功率预测误差的变化趋势。
技术实现要素:
本发明的目的是提供一种合理有效的方法,对风电场上报给调度部门的风电功率超短期预测值进行预测误差区间估计。本发明通过引入隐马尔科夫模型(hiddenmarkovmodel,hmm)对风电功率超短期预测误差进行建模,并利用局部加权回归散点平滑法对误差区间进行处理,提高结果的准确性以及降低结果的保守性,为调度运行提供参考。
为了达到上述目的,本发明的技术方案为:
一种基于隐马尔科夫模型的对风电功率预测误差区间进行估计的方法,包括以下步骤:
第一步,根据风电功率超短期预测误差,建立风电功率预测误差模型
所述的风电功率预测误差模型为隐马尔科夫模型hmm,其基本形式为λ=(s,o,a,b,π),该模型参数如下:
1)隐式状态有限集合s。
s={s1,s2,…,sm},si∈q,q={q1,q2,…,qn}(1)
式中,si表示第i个时间节点的数据属于哪一种高斯分布;q为m个输入样本可能处于的总的高斯分布集合;n为高斯分布总的种类个数;q代表n种高斯分布中的一种;m为输入样本个数,i∈1~m。
2)可观察序列集合o={o1,o2,…,om}。
根据公式(3)计算中间变量,代入公式(2)中,计算标准化参数ot,代入隐马尔科夫模型中的可观察序列集合o={o1,o2,…,ot,…,om}中。
ot=z-score(λt)(2)
λt=|ηm,t-ηreal,t|/ηm,t(3)
式中,z-score为zero-meannormalization标准化过程;ηm,t为t时刻提前m小时的风电功率预测值,即t-m时刻对于t时刻进行预测的预测值;ηreal,t为t时刻风电功率实际出力值,λt为中间变量;ot表示t时刻风电功率提前m小时预测误差的标准化参数,由式(2)计算得到。
3)隐式状态转移概率矩阵a。
式中,p代表条件概率。
4)观测值概率转移矩阵b。
式中,vk表示可观察序列o在k时刻的观测值。
5)初始状态概率矩阵π。
在实际过程中,风电功率预测误差的概率规律一般难以统计,只能够获得风电功率预测误差的历史数据,无法确定事件所处的状态以及状态的参数。风电功率预测误差模型中隐式状态有限集合s中元素s1,s2,…,sm分别代表每一时刻的标准化数据,属于n种高斯分布中的其中一种高斯分布,而具体属于哪一种状态以及该状态对应的高斯分布的具体参数是未知的,都不能够通过观察得到,所以s称为隐式状态有限集合。
用有限个高斯分布q{q1,q2,…,qn}描述风电功率预测误差标准化数据的波动状态;隐式状态集合s中的元素si表示风电功率预测误差标准化数据在时刻t属于哪一种高斯分布,满足si∈q。
在风电功率预测误差模型中,隐式状态有限集合s是一个马尔科夫链,状态的转移具有马尔科夫性,并且无法被观测到。
第二步,日内风电功率预测误差模型隐式参数估计
由于日内风电功率超短期预测误差的波动状态为隐式变量,无法被观测得到,因此日内风电功率预测误差模型参数估计的不完整。
采用最大期望值em(expectationmaximization)算法对日内风电功率预测误差模型中的s、q参数进行估计。em算法以s(0)、q(0)作为参数s、q的任意初始值,迭代估计最优模型参数s(*)、q(*),em算法分为以下两步,以θ代表s、q的集合:
em算法的e步骤:计算θ对数似然函数的期望
l(θ,θk)=e(lg(p((s,o)|θ))θk,o)(7)
em算法的m步骤:求解使得θ对数似然函数最大的新的模型参数
反复迭代直至θk+1和θk之间的差值达到精度要求,即为最优的模型参数。
通过em算法估计得到隐式状态集合s中各元素所对应的波动状态以及s中各元素所对应的高斯分布的方差
第三步,估计得到最新的风电功率预测误差区间
从物理学角度出发,风速主要受到大气运动作用的影响,所以不论何种预测方式,预测的周期越长,大气运动变化越剧烈,风速波动就越大,预测结果的准确度也就越低。本方法采用滚动预测的方式可以适当降低由于预测周期带来的误差。
根据可观察序列集合o以及第二步得到的隐式状态有限集合s,使用hmm模型中的评估功能,得到隐式状态转移概率矩阵a以及观测值概率转移矩阵b;再使用hmm模型的解码功能以及学习功能,预测未来一段时间的隐式状态集合sfuture。
通过sfuture得到未来n个时间节点预测误差所对应的高斯分布,计算得到n个时间节点的风电预测误差最大波动范围;根据未来一段时间每个时间节点风电功率预测误差属于何种高斯分布,在满足一定的置信水平α的条件下,得到最新的风电功率预测误差区间[-ε,ε],其中ε为满足置信水平α的极大误差。
第四步,基于局部加权回归散点平滑法对第三部得到的风电功率预测误差区间[-ε,ε]进行处理,步骤如下:
4.1)第三步会得到未来n个时间节点的风电功率预测误差区间上下边界[-ε1,ε1]、[-ε2,ε2]、……、[-εn,εn],首先计算各个数据点[ε1、ε2、……、εn]的初始权重;
4.2)利用初始权重进行回归估计,利用估计式的残差定义稳健的权重函数,计算新的权重。所述的权重函数一般表达为数值之间欧氏距离比值的立方函数。
4.3)利用新的权重重复步骤4.2),修正权重函数,收敛后可根据多项式和权重得到任意点的光滑值。
局部加权回归散点平滑法lowess(locallyweightedscatter-plotsmoothing)具有以下特点:1)趋势性:经过lowess方法处理过的数列是个派生数列,它将沿袭原始数据的走势。2)稳定性:派生数列已对原始数列进行了修正,即在相当程度上消除了受某些偶然因素影响所出现的非常波动,从而使派生数列的趋势稳定,体现在数据上则是稳定的延伸。这种走势的变化受某个别时间节点变化的影响较少。
本发明的效果和益处是:针对风电并网容量受限的问题,提供了一种能够提高风电并网容量的方法。利用p2g技术将电网与天然气网耦合,从而实现电网对风电接纳水平的提高。同时,引入试验风速,将风电概率性模型转化为确定性模型,求解风电最大并网容量,为解决风电并网容量受限问题提供了新思路。
附图说明
图1是hmm模型日内风电功率波动区间估计流程图;
图2是用于验证模型正确性的数据曲线图;
图3是具体实施方式的结果图。
具体实施方式
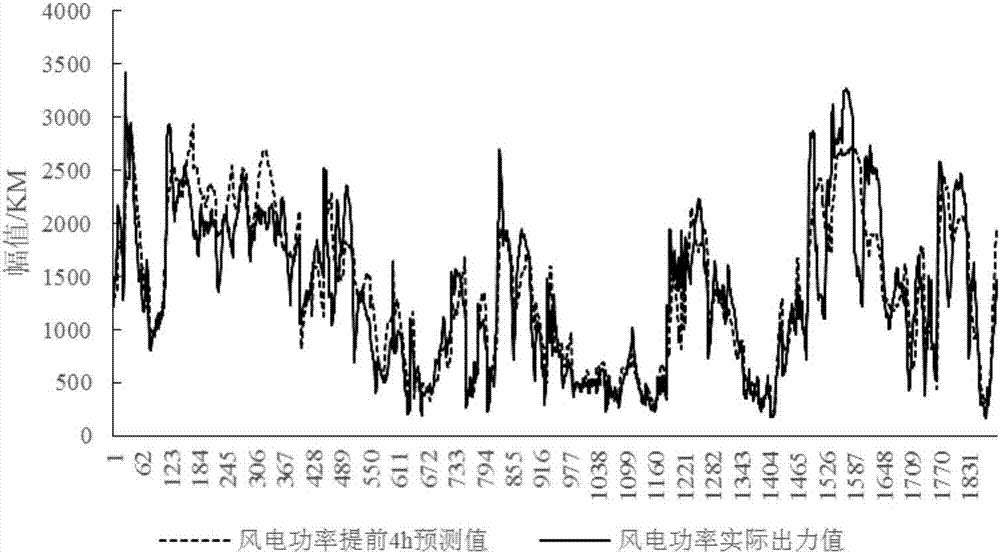
以下以图2所示数据为例,结合技术方案叙述本发明的具体实施方式。本图2使用我国某省风电实际数据进行分析,该数据取样间隔为15min,其中虚线部分为提前四小时风电功率预测值,实线部分为风电功率实际出力值。以n=4、m=4、n=16为参数,文中从数据时间节点1001开始,连续滚动估计8天共768个时间节点的误差区间。
图1为风电功率误差区间估计流程图,具体步骤如下:
第一步,对风电功率期预测误差进行建模。
首先根据公式(5)和(6)将当前时刻之前m个时间节点的风电功率提前m小时预测误差数据进行标准化。将得到的标准化数据作为可观察序列集合o带入到hmm模型中。
第二步,设置好参数s、q的初始值,初始值可以是任意值,将第一步得到的可观察序列集合o以及s(0)、q(0)带入em算法,根据公式(7)和(8)进行反复迭代,可以最大似然估计得到s、q。
第三步,以第一步和第二步为基础,使用hmm模型估计出未来一段时间内,每个时间节点得到的预测值的误差属于哪一种高斯分布,根据该种高斯分布的参数,在满足置信水平95%的条件下,得到最新的风电功率预测误差区间[-ε,ε],具体为:
估计模型每整小时启动运行,估计当前时间节点t到其后16个时间窗口的风功率预测误差范围,在实际的调度过程中,每个时间窗口通常取15min。每次启动后得到的风电功率预测误差波动范围自动覆盖上一个小时得到的结果。
将最新得到的风电超短期功率预测序列y{y1,y2,…,y16}输入到已建立的hmm模型中,即可得到未来16个时间节点的预测误差波动状态的概率以及每种状态之间的转移矩阵。
以未来16个时间节点最大概率预测误差状态所对应的高斯分布,计算得到16个时间节点的风电预测误差最大范围,同理,如果以不同的概率选择方法选择概率,则会得到不同的结果。最终得到最新的风电功率预测误差区间[-ε,ε]。
第四步,将得到最新的风电功率预测误差区间[-ε,ε],使用lowess进行处理,就能够将风电场上报给调度部门的风电超短期预测曲线转化为带状分布,风电功率预测误差区间结果如图3。
- 还没有人留言评论。精彩留言会获得点赞!