基于Spark和SIMD的弹性分布式序列比对系统及方法与流程
本发明涉及一种序列比对系统及方法,具体地涉及一种基于spark和simd的弹性分布式序列比对系统及方法。
背景技术:
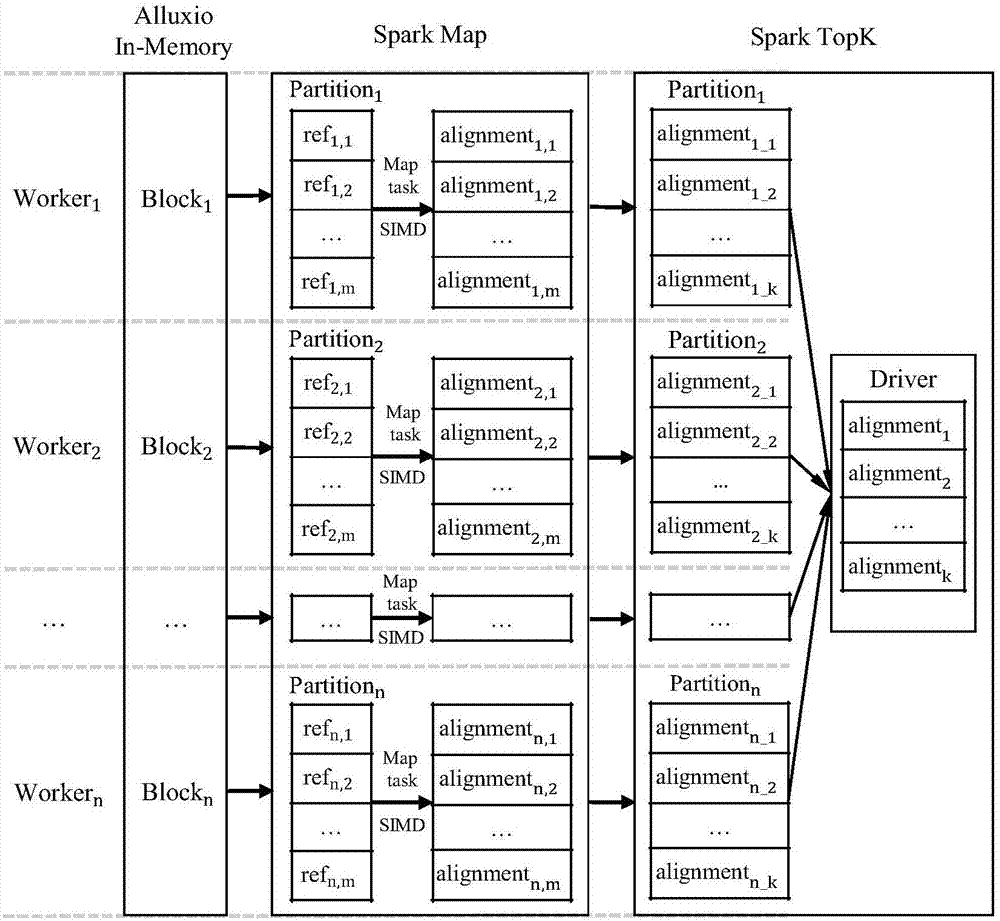
:序列比对是用来识别双序列之间高度相似的区域,一般用比对得分来评价双序列之间的相似度,为了方便后续分析,会计算最佳比对路径。序列比对算法是生物信息学领域基本而又至关重要的算法,被广泛应用于基因串匹配、本地重新比对等校准操作、变异分析、蛋白质数据库搜索等领域。序列比对包括本地序列比对、全局序列比对和半全局序列比对等。目前最常用的本地序列比对算法是smith-waterman(sw)算法,该算法也是目前最常用的序列比对算法之一。sw算法是基于动态规划的算法,可以找出两序列之间的最优本地比对。但是sw算法具有很高的时间复杂度,所以也是最慢的比对算法之一。尽管像blast(basiclocalalignmentsearchtool)等采用启发式方法的算法速度更快,但是无法保证找到最优解。由于sw算法至关重要,所以从提出到现在,已经有大量的科学家提出了加速sw运行的算法。包括基于simd(singleinstructionmultipledata,单指令多数据流)指令集的加速算法、基于gpu的算法、基于fpga的算法。相对于基于gpu、fpga的加速方法,基于simd的加速方法更加通用,使用的也更频繁。farrar提出了将simd寄存器并行查询序列但以条纹模式(stripedpattern)访问的算法,相对于其他已经被优化的但没有用simd的实现来说有超过6倍的加速比。farrar的算法已经被嵌入到几个流行的基因序列匹配工具中,比如bwa-mem和bowtie2。zhao实现了一个基于simd的sw算法c/c++库来方便将sw算法整合到其他基因组的应用中,其库名被称作ssw(stripedsmith-waterman),同时扩展了farrar的算法,除了最优的比对得分之外还返回比对信息。ssw使用的是英特尔处理器支持的sse2(streamingsimdextensions2)指令集。2016年daily提出了sw算法c语言库parasail,该库包含了不同的序列比对算法,包括sw算法、nw(needleman-wunsch)算法和sg(semi-global)算法。parasail主要意图是方便将序列比对算法整合到其他应用,而不是替换目前高性能的蛋白质搜索工具。parasail提供了超过一千个函数,并且支持sse2、sse4.1、avx2(advancedvectorextensions2)和knc(knight'scorner)等simd指令集。以上这些算法主要运行在单机环境,可扩展性受限,难以满足数据快速增长带来的计算需求。由于sw算法随着序列长度的增加,其时间复杂度和空间复杂度都呈平方增加,所以sw算法也是最慢的序列比对算法之一。而传统基于simd、gpu或fpga等技术实现的sw算法可扩展性受限,难以满足基因数据指数增长带来的计算需求。尽管sparksw实现了基于spark的分布式sw算法,但使用纯scala代码编写,没有使用其他加速技术,所以性能较差。作者实验结果显示,sparksw最高性能只有0.346gcups(gigacellupdatespersecond)。我们通过实验发现,当查询序列长度为4096字符,参考序列数据集为大小4g的1000万条左右序列时,sparksw在8个物理节点的集群运行需要38.53个小时。虽然sparksw具有很好的可扩展性,但是性能并不理想。技术实现要素:针对传统序列比对算法可扩展性的问题和单纯只使用spark进行计算的低性能问题,本发明目的是:提供了一种基于spark和simd的弹性分布式序列比对系统及方法,将spark的分布式计算和simd技术的高性能进行结合来实现序列比对,采用alluxio和hdfs来分布式存储数据,采用计算框架spark进行分布式计算,在每个节点采用simd技术进行序列比对,提高了性能。本发明的技术方案是:一种基于spark和simd的弹性分布式序列比对系统,包括一个主节点和与主节点连接的多个工作节点,所述主节点用于管理元数据和集群,包括基于分布式计算框架spark的主节点、基于分布式内存文件系统alluxio的主节点和hadoop分布式文件系统的主节点;所述工作节点用于数据的存储和计算,包括存储层和计算层,所述存储层包括alluxio和hdfs,所述计算层包括基于分布式计算框架spark和simd指令集,基于分布式计算框架spark通过中介模块调用基于simd的序列比对算法进行序列比对。优选的,所述中介模块的执行包括以下步骤:通过spark的scala类调用java类,并进行对象和数据转换;通过java类调用基于simd的序列比对算法,将计算结果返回给java类;java类将计算结果返回给scala类,并将java对象转换成scala对象。优选的,所述基于simd的序列比对算法包括分布式本地序列比对算法dsw、分布式全局序列比对算法dnw和分布式半全局序列比对算法dsg。本发明还公开了一种基于spark和simd的弹性分布式序列比对方法,包括预处理阶段、map阶段和topk阶段;预处理阶段,对查询序列、参考序列数据集和评分矩阵进行抽取、清洗和转换;map阶段,将查询序列与参考序列数据集中的每一条参考序列进行序列比对,通过中介模块调用基于simd的序列比对算法进行序列比对,获得序列比对结果;topk阶段,获取查询序列与所有参考序列比对得分最高的k个结果。优选的,所述序列比对结果包括参考序列名称、最佳序列比对得分和路径,路径用开始位置、结束位置和cigar表示。优选的,所述基于simd的序列比对算法包括分布式本地序列比对算法dsw、分布式全局序列比对算法dnw和分布式半全局序列比对算法dsg。优选的,所述中介模块的执行包括以下步骤:通过spark的scala类调用java类,并进行对象和数据转换;通过java类调用基于simd的序列比对算法,将计算结果返回给java类;java类将计算结果返回给scala类,并将java对象转换成scala对象。与现有技术相比,本发明的优点是:1、本发明的弹性分布式序列比对系统dsa将spark的分布式计算和simd技术的高性能进行结合,既有效解决了传统单机算法可扩展性受限的问题,又解决了单纯只使用spark进行计算的低性能问题。另外,dsa采用了alluxio和hdfs来分布式存储数据,将常用数据提前缓存在内存中,可以提高i/o性能和减少节点间的网络开销,并实现了相关的转换方法,使得fasta、fastq等传统的基因数据格式经过转换后也可以分布式存储。2、本发明设计和实现了分布式本地序列比对算法dsw、分布式全局序列比对算法dnw和分布式半全局序列比对算法dsg。经实验发现,dsw、dnw和dsg都具有很好的可扩展,dsw相对于现有的分布式序列比对算法sparksw最高取得了200.77倍的加速比。附图说明下面结合附图及实施例对本发明作进一步描述:图1是基于spark和simd技术的弹性分布式序列比对系统dsa的架构图;图2是基于spark和simd技术的弹性分布式序列比对系统dsa的流程示意图;图3是dsw跟sparksw使用不同参考序列数据集的比较图;图4是dsw跟sparksw使用不同查询序列数据集的比较图;图5是dsw、dnw和dsg的可扩展性评估图。具体实施方式以下结合具体实施例对上述方案做进一步说明。应理解,这些实施例是用于说明本发明而不限于限制本发明的范围。实施例中采用的实施条件可以根据具体厂家的条件做进一步调整,未注明的实施条件通常为常规实验中的条件。实施例:基于spark和simd技术的弹性分布式序列比对系统dsa的架构图,如图1所示,dsa采用了标准的master-slave的架构,主要包括一个master和若干个slave。master主要负责管理元数据和集群,每个master节点主要包括spark的master、alluxio的master和hdfs的namenode。worker也就是slave,主要负责数据的存储和计算,一般worker节点有若干个。每个worker节点主要包括两层,存储层和计算层。在存储层中,为了加速数据的读写,采用了基于内存的分布式文件系统alluxio作为主要存储组件,代替了传统的基于磁盘的分布式文件系统。在dsa中,hdfs仅被用作数据的持久化。第二层为计算层,主要是基于内存分布式计算框架apachespark。dsa采用了基于simd指令集的数据并行策略来在worker节点的每个核内并行化序列比对算法,通过simd指令集并行的操作寄存器且在多个数据点同时执行相同的操作。apachespark的原生语言是scala,并只提供了java、python和r语言的api,并没有提供c/c++的api。而基于simd技术的序列比对算法一般是用c/c++实现的。所以apachespark无法直接调用基于simd技术的序列比对算法。为了将基于simd技术的序列比对算法整合到spark中,本发明设计了一个中介模块(mediator)。具体来说就是先通过使用java本地方法(jni,javanativeinterface)来设计和实现多个java类去调用基于simd的序列比对算法,由于jni可以连接java和c/c++,所以jni充当了一个连接者的作用,使得通过java代码可以调用c/c++语言的代码,并获得返回的结果。然后再设计和实现多个scala类去调用实现好的java类,并且将java对象转换成scala对象。因此,基于scala语言的spark应用就可以通过dsa中的中介模块mediator间接地调用基于simd的序列比对算法。由于apachespark的调度器应用了延迟调度策略去调度任务,所以当任务的执行时间很长的时候,spark从hdfs读取文件的时候会有较差的数据本地性和高的网络带宽。所以在dsa的设计中,采用了基于内存的文件系统alluxio作为主要的存储组件,这不仅可以通过从本地节点的内存而不是磁盘提供数据来加速i/o的性能,而且还可以将热点数据缓存在内存中来减少节点间的网络开销。使用alluxio作为主要存储可以有效地提高数据读写的性能。为了方便数据分布式存储,本发明设计和实现了相关的转换方法,使得fasta、fastq等传统的数据在转换后可以分布式存储在集群中。在序列比对的过程中经常需要去获取最相似的k个比对结果,比如在蛋白质数据库搜索和基因串匹配的种子扩增阶段,就需要获取多个比对中最相似的若干个比对结果。因此,在dsa中,分布式序列比对算法也被设计成获取最相似的k个比对结果的形式。基于spark和simd技术的弹性分布式序列比对系统dsa的处理流程,如图2所示,系统流程主要包括预处理阶段、map阶段和topk阶段,具体步骤如下:(1)预处理阶段主要是对查询序列、参考序列数据集和评分矩阵进行抽取、清洗和转换等预处理,抽取出查询序列和参考序列数据集中的序列名称和序列等信息,并进行切割,将其转换为数组形式,方便后续计算。对于评分矩阵,需要进行转换,默认的评分矩阵是易于理解的,但是不方便计算,所以需要转换成128128的二维矩阵,便于后续计算;(2)map阶段将查询序列与参考序列数据集进行map,对每一对查询序列和参考序列通过中介模块mediator调用simd应用进行序列比对,获得序列比对结果,包括参考序列名称、最佳序列比对得分和路径,路径用开始位置、结束位置和cigar表示;(3)topk阶段会在maprdd的每个partition中通过使用传统的快速选择算法来获取topk个无序的序列比对结果。选择的顺序是基于序列比对对象的最高比对得分,实现时是通过一个隐式方法来实现。然后再运行一个reduce任务,主要是对rdd中每个partition的topk个比对结果进行进一步筛选,计算出全局的topk个无序的比对结果。最后对这全局的k个比对结果进行排序,得到最终结果并进行返回。为了方便使用,dsa中实现了分布式的本地序列比对算法dsw、分布式的全局序列比对算法dnw和分布式的半全局序列比对算法dsg,这些算法可以应用于不同的场景。分布式的本地序列比对算法dsw,通过中介模块mediator调用基于simd的ssw应用进行序列比对。分布式的全局序列比对算法dnw,通过中介模块mediator调用基于simd的parasail应用的nw方法进行序列比对。分布式的半全局序列比对算法dsg,通过中介模块mediator调用基于simd的parasail应用的sg方法进行序列比对。为了更好地与sparksw进行性能比较,dsw实验数据集与sparksw保持一致,采用公开数据集uniref100。详细的实验数据如表1所示。r是参考序列数据集的名称。sr是参考序列数据集的大小,单位是mb。nr是参考序列数据集中序列的数量。q是查询序列的编号。nq是查询序列在uniref100中的名称。lq是查询序列的长度,单位是字符。表dsw评估使用的序列比对数据集rsrnrqnqlqr13278295q1p186918r264156590q2p8314016r3128313180q3p2073832r4256626360q4o5574664r55121252720q5q6gzw8128r610242505440q6q6gzx4256r720485019006q7q19li2512r8409610038012q8q7tqi71024r9819220076024q9q8iyd82048r101638440152048q10r0inu34096固定查询序列长度,对不同大小的参考序列数据集进行分析,查询序列的固定长度是512个字符,采用表1中的q7。参考序列数据集采用表1中的r1至r10,参考序列数据集大小从32m到16g递增。dsw和sparksw均使用了8个节点,每个节点使用8gb的内存来运行spark应用,每个spark使用8个executors,每个节点使用12gb的内存用于alluxio的存储。每个节点的操作系统为ubuntu14.04.1,cpu的类型为intelxeonw3505,每个节点2个核,每个节点物理内存大小为22g,spark的版本为1.5.2,scala的版本为2.10.5,hdfs的版本为2.6.0,alluxio的版本为1.3.0,ssw的版本为1.2.1,parasail的版本为1.1.0,gcc的版本为4.8.4。实验结果如图3所示,图中展示了dsw跟sparksw使用不同参考序列数据集的比较。横坐标是不同的参考序列数据集,纵坐标是dsw相对于sparksw的加速比。实验结果显示在不同的参考序列数据集的情况下,dsw相对于sparksw都有显著的性能提升。随着参考序列数据集大小的增加,dsw相对于sparksw的加速比是先上升后下降。dsw相对于sparksw最小的加速比为9.47倍,最高的加速比达到122.27倍。在参考序列数据集为r10时,sparksw的平均运行时间为15.53个小时,即931.62分钟,而dsw只需要8.37分钟。将dsw跟sparksw使用不同查询序列数据集的比较。该组实验是固定参考序列数据集的大小,对不同的查询序列长度进行性能分析。参考序列数据集固定大小是4gb,采用表1中的r8。查询序列数据集采用表1中的q1至q10,每个数据集均为一条查询序列,长度从8个字符到4096个字符递增。dsw和sparksw都使用了8个节点,每个节点使用8gb的内存来运行spark应用,每个spark使用8个executors,每个节点使用12gb的内存用于alluxio的存储。其他详细的配置跟图3所示的实验一样。实验结果如图4所示,图中展示了dsw跟sparksw使用不同查询序列数据集的性能比较。横坐标是查询序列数据集,纵坐标是dsw相对于sparksw的加速比。实验结果显示在不同的查询序列数据集的情况下,dsw相对于sparksw都有显著的性能提升。加速比随着序列数据集中序列长度的增加而上升。最高的加速比达到200.77倍。当查询序列为q10时,sparksw的平均运行时间为38.53个小时,即2312.03分钟,而dsw只需要11.52分钟。两组实验分别从不同参考序列数据集和不同查询序列数据集对dsw和spark进行了比较,实验结果表明dsw性能都明显优于sparksw。其主要原因为:1)dsw使用了simd技术来加速sw算法,simd寄存器可以并行地查询序列,并且通过条纹模式进行访问,最后数据可以在指令集层面并行执行。2)dsw使用alluxio代替了hdfs作为主要的存储组件,这样可以加速i/o的性能,并且减少节点间的网络开销。3)dsw采用了更高效的topk算法,dsw不仅减少了topk算法的时间复杂度,而且还避免了类似于sparksw中的shuffle开销。除了取得更高的性能之外,dsw的精度也要高于sparksw。因为sparksw的开源代码中加入了过滤机制,将比对得分低于查询序列长度的比对结果过滤掉,这会过滤掉一些正确的结果。这对某些情况可以减少后续的计算,节省时间,但会降低sparksw序列比对的准确度。而dsw并没有采用这种机制,从而准确度会等于或者高于sparksw。为了更好地评估dsw,本发明将dsw运行在不同的计算节点上。节点数量从1到8。在对dsw的可扩展性评估的同时,也评估了dnw和dsg的可扩展性。在可扩展性评估的实验中,采用了表1中的q7作为查询序列数据集,q7中只有一条名为q19li2的查询序列,长度为512个字符。另外采用了r8作为参考序列数据集,大小为4gb。每个节点只运行一个核。实验结果如图5所示,图中展示了dsw、dnw和dsg的可扩展性评估。横坐标是节点的数量,纵坐标是各个算法相对于自身单机的加速比,当节点数量为1的时候,加速比都为1。黑色横条纹的柱状为理论加速比,即加速比等于节点的数量。通过实验评估和分析,dsw、dnw和dsg随着节点数的增加,取得了接近线性的加速比,说明dsw、dnw和dsg具有良好的可扩展性。综上所述,基于spark和simd的弹性分布式序列比对系统及方法具有良好的可扩展性,而且取得了明显的性能提升。上述实例只为说明本发明的技术构思及特点,其目的在于让熟悉此项技术的人是能够了解本发明的内容并据以实施,并不能以此限制本发明的保护范围。凡根据本发明精神实质所做的等效变换或修饰,都应涵盖在本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1