基于最大化接受者操作特征曲线下方面积的推荐方法与流程
本发明涉及地点推荐,特别是一种基于最大化接受者操作特征曲线下方面积的推荐方法。
背景技术:
当用户去访问一个喜欢的地点时,基于地点的社交网络允许用户在当前地点签到并分享他们的在当前地点的经历。随着这种社交网络的流行和不同平台的兴起,例如brightkite、foursquare和gowalla,用户的签到数据规模正以前所未有的速度增长。例如2016年一年,foursquare有超过5千万的活跃用户创造了超过80亿的签到数据。
大量的签到数据可以让很多推荐系统的研究能够更好地提高用户体验,例如位置推荐、好友推荐以及活动推荐。在这些应用当中,兴趣地点推荐在过去几年中获得了大量的研究关注,很多算法被开发出来。
兴趣地点推荐的目标是通过对用户签到历史和其他因素的学习,从而推荐给用户可能感兴趣但没有访问过的地点列表。有很多因素导致兴趣地点推荐很困难,其中最重要的因素是签到数据特别稀疏,即被每一个用户访问过的兴趣地点只占了所有地点的极其少的一部分。例如在实验中的一个数据集,一个用户平均只访问了15.9个兴趣地点,而在那个城市当中一共有46617个兴趣地点。这让兴趣地点推荐比其他推荐任务遭受更严重的数据稀疏问题。举例来说,用来电影推荐的netflix的数据库的数据密度为1.2%,这远远比兴趣推荐的签到数据的密度高。同时,签到数据是一种隐反馈数据,即签到数据只提供了正样本和没有标签的样本,这些没有标签的样本可能是负样本也可能是没有被发现的正样本。
现存的很多研究,他们的目标方程的主要部分是关于签到矩阵和模型推荐的差的弗罗贝尼乌斯范数。然而,弗罗贝尼乌斯范数并不是设计来处理稀疏问题的,而且当不设计特别复杂的模型时,很难在稀疏数据集上得到比较好的结果。
技术实现要素:
本发明的主要目的在于克服现有技术中的上述缺陷,提出一种利用地理上下文信息和用户的签到频率,基于最大化接受者操作特征曲线下方面积的推荐方法。
本发明采用如下技术方案:
基于最大化接受者操作特征曲线下方面积的推荐方法,其特征在于:包括如下步骤:
1)通过用户签到数据构建用户的兴趣地点对集合和签到矩阵,该集合中包括该用户所有访问过和未访问的兴趣地点对;
2)根据集合构建最大化接受者操作特征曲线下方面积的目标方程;
3)对目标方程进行优化,再采用随机梯度下降的方法进行求解,迭代结束后,得到最终的用户隐矩阵和兴趣地点隐矩阵;
4)计算集合中的所有兴趣点对的距离,根据该距离计算邻接矩阵n;
5)对于每个用户的每个兴趣地点,根据步骤3)得到的用户隐矩阵p和兴趣地点隐矩阵q,并结合邻接矩阵和签到矩阵计算地理上下文的排序矩阵;
6)根据用户隐矩阵和兴趣地点隐矩阵得到预测的排序矩阵,将其与地理上下文排序矩阵分别进行加权后相加得到最后的推荐结果。
优选的,预先定义:u代表用户集合,l来代表兴趣地点的集合;对于一个目标用户u,定义
其中:|x|表示的是集合x的基数,πui表示访问过的兴趣地点i在目标用户u的推荐列表里的排列位置,πuj表示未访问的兴趣地点j在目标用户u的推荐列表里的排列位置,
优选的,在步骤3)中,所述的对目标方程进行优化包括采用非平滑函数排序,再定义所述目标方程对于参数的导数:
其中qi,qj为兴趣地点隐向量,pu为用户隐向量,
优选的,在步骤3)中,增加一个弗罗贝尼乌斯范数来作为正则项p和q,即为用户隐矩阵p和兴趣地点隐矩阵q,则得到新的损失函数:
α是平衡正则项的权重,对于任意的(u,i)∈d和
优选的,在步骤3)中,对于任意的(u,i)∈d和
优选的,在步骤3)中,对于每一个访问过的兴趣地点,随机选取一个未访问过的兴趣地点组成兴趣地点对,以减少计算时间。
优选的,对于m个用户和n个兴趣地点,定义稀疏矩阵
其中k=10,n(li)是兴趣地点i的k个最近邻的集合;
优选的,定义签到矩阵为
优选的,在步骤6)中所述预测的排序矩阵rpre=pqt。
优选的,在步骤6)中所述最后的推荐结果:
其中:μ∈[0,1]是控制地理影响的系数。
由上述对本发明的描述可知,与现有技术相比,本发明具有如下有益效果:
本发明的方法,为了优化auc,将推荐问题转换成为一个分类问题,其中被访问过的地点作为正样本,反之作为负样本。因此签到数据的稀疏问题便变成了数据分布的不平衡问题,从而能够被优化auc来解决。然而,auc是一个非平滑函数,如何优化auc本身便是一个比较难的问题。过去的工作有将auc替换为例如岭损失函数的,但这种方法不能够容易地推广到其他非平滑函数上。因此,本发明利用了lambdamf的框架,这个框架将基于lambda的方法和在协同过滤中广泛使用的矩阵分解算法结合起来。特别的是,使用auc作为目标方程并定义了一个新的lambda,从而更够更好的在本发明方法的框架auc-mf中利用auc的特性。本发明的实验结果表明auc-mf可以达到最高水准的准确率。
除了二元的签到数据,各种各样的上下文信息都可以提高兴趣地点推荐的准确率,例如兴趣地点的地理坐标,签到数据的时间戳,以及用户之间的关系等等。作为兴趣地点推荐系统,auc-mf也具有一定的拓展性,从而有效利用这些上下文信息。
为了利用地理上下文信息和用户的签到频率,本发明提出了一种可泛化的优化auc-mf结果的方法。假设用户会访问曾经访问过的地点的附近的地点,那对于任何一个兴趣地点,本发明将所有附近访问过的兴趣地点的结果的和加权加在这个兴趣地垫上。权重是通过计算兴趣地点之间的地理距离得到的。实验结果表面这种整合上下文信息的方法进一步提高了算法的准确率。其他类型的上下文信息也可以通过相似的方法整合到实验结果中。值得注意的是,大多数的算法是在训练过程中利用上下文信息,这会导致训练过程特别耗时。因为auc-mf可以作为优化结果的方式来利用上下文信息,因此会方便很多。
本发明还具有如下优势:
1、本发明提出了一种叫做auc-mf的新的用来做兴趣地点推荐的框架,这个框架可以很好的应对数据稀疏问题。
2、本发明提出了一种泛化的利用上下文信息优化推荐结果的方法。因为作为结果优化过程,上下文信息整合到推荐系统里不会有过多的计算。
3、在gowalla上两个数据集的实验可以表明auc-mf在兴趣地点推荐上显著超过其他最高水准的方法。
附图说明
图1为本发明的流程图;
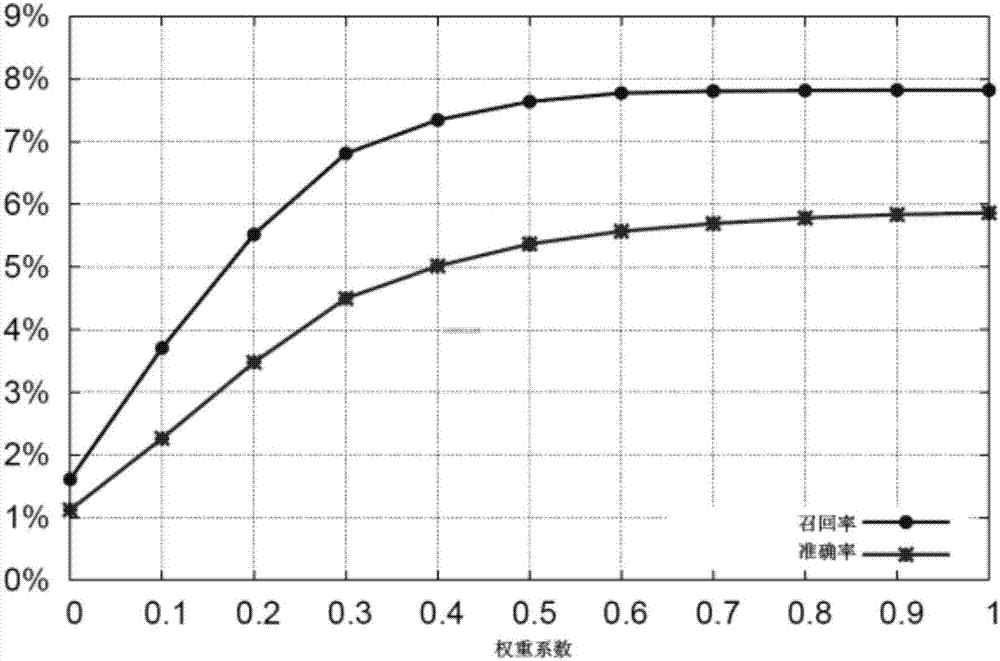
图2为不同设定的μ对最终结果的影响(柏林);
图3为不同设定的μ对最终结果的影响(纽约);
图4为本发明auc-mf的收敛速率(柏林);
图5为本发明auc-mf的收敛速率(纽约)。
具体实施方式
以下通过具体实施方式对本发明作进一步的描述。
基于最大化接受者操作特征曲线下方面积的推荐方法,最大化接受者操作特征曲线下方面积(areaundertheroccurve,auc),简称为auc,是一种广泛用来评价不平衡数据分布的分类准确率的评价指标。参见图1,其主要包括如下步骤:
1)通过用户签到数据构建用户的兴趣地点对集合和签到矩阵,该集合中包括该用户所有访问过和未访问的兴趣地点对。
2)根据集合构建最大化接受者操作特征曲线下方面积的目标方程,目的是让所有的兴趣地点对中,用户访问过的兴趣地点的分值要大于未访问过的兴趣地点分值。
3)对目标方程进行如下优化,为了解决计算溢出问题,添加了弗罗贝尼乌斯范数作为正则项来限制参数;定义每一个兴趣地点对的lambda,从而来解决目标方程为非平滑方程而无法求导的问题。再采用随机梯度下降的方法进行求解,迭代结束后,得到最终的用户隐矩阵和兴趣地点隐矩阵。为了降低计算时间,对于每一个访问过的兴趣地点,随机选取一个未访问的兴趣地点组成兴趣地点对。
4)计算集合中的所有兴趣点对的距离,根据该距离计算邻接矩阵n;
5)对于每个用户的每个兴趣地点,根据步骤3)得到的用户隐矩阵p和兴趣地点隐矩阵q,并结合邻接矩阵和签到矩阵计算地理上下文的排序矩阵。
6)根据用户隐矩阵和兴趣地点隐矩阵得到预测的排序矩阵,将其与地理上下文排序矩阵分别进行加权后相加得到最后的推荐结果。
本发明的方法,各个步骤中的具体细节如下:
给予m个用户和n个兴趣地点的历史交互数据,兴趣地点推荐的目的是推荐给目标用户u一个兴趣地点的列表,同时兴趣地点推荐列表里的兴趣地点是目标用户u之前没有访问过的。在很多现实场景中,兴趣地点推荐是基于用户的隐倾向反馈,即一个用户是否访问过某个兴趣地点。这种反馈通常被一组二元变量yui∈{0,1}的集合表示。如果一个用户u访问过兴趣地点i,则yui被设置成为1,反之设置成为0。值得注意的是,yui=0并不是显示地表示u对i并不感兴趣,也可能是u并不知道i的存在。本发明使用u来代表用户集合,用l来代表兴趣地点的集合。对于一个用户u,用
1.auc评价指标
auc是一个阈值决定评价指标,从而使随机选取的正样本的概率要比要比随机选取的负样本有更高的决定值。根据为二分类定义的auc,定义兴趣地点推荐的auc即最大化接受者操作特征曲线下方面积的目标方程为:
在上式中,|x|表示的是集合x的基数,πui表示的是已访问的兴趣地点i在u的推荐列表里的排列位置,πuj表示的是未访问的兴趣地点j在u的推荐列表里的排列位置,这个排列是根据预测得分
对于任意的(u,i)∈d和
因此
然而,指示函数
2.使用非平滑函数排序
lambdarank提出了一种可以扩展到任意非平滑多变量的损失函数的方法。这是基于ranknet的思想,将成对排序问题转变成梯队下降问题。lambdarank公式化了成对排序的梯度,并命名为λ。拿兴趣地点推荐作为例子,对于用户u,一个隐损失函数
在这里,
其次,雅可比矩阵在每一处都是半正定的。值得注意的是,对于任意的常数λ,上面两个条件都可以被满足。
下面将给出对于兴趣地点推荐的λ的可泛化形式。对于任意的(u,i)∈d和
当
得到导数后,就可以将他们应用于基于矩阵分解的模型来解决兴趣地点推荐的任务。
3.矩阵分解中的λ
基于矩阵分解的算法是推荐系统中最流行和重要的算法。给予m个用户和n个兴趣地点,本发明方法使用稀疏矩阵
lambdamf提出了一种利用随机梯度下降的方法来学习模型参数,本发明利用它的理论并重新定义了优化p和q的梯度。首先,在兴趣地点推荐任务里,对于任意的(u,i)∈d和
因此梯度可以被计算为:
λ的定义是本发明方法的关键。为了让本发明方法能够有效且快速,本发明定义了一种简单且可泛化的λ,在介绍λ之前,首先要解决隐变量的溢出问题。
4.正则项
当使用基于λ的方法时,被访问比较多的兴趣地点会导致严重的溢出问题。假设有一个特别受欢迎的兴趣地点
为了解决这个问题,一种经常使用的方法是增加一个正则项。在本发明中,使用弗罗贝尼乌斯范数来作为正则项,从而能够很容易地在本发明的框架中被优化。通过添加正则项p和q,可以得到新的损失函数
这里α是平衡正则项的权重。然后对于任意的(u,i)∈d和
接着,将介绍λ的表达式。
5.aucλ
在前文中,给出了λ的一般形式的定义,现在来讨论如何去选择λ。为了保证隐损失函数存在且为凸,有两个条件需要被满足。首先,隐损失函数相对于评分的雅可比矩阵必须是对称的。这代表着存在一个损失函数使λ是它的导数。一旦满足了存在条件,应该保证隐损失函数是凸的。这就意味着,雅可比矩阵必须是处处半正定的。正如之前讨论的,常数λ满足上面两个条件。考虑到要最小化损失函数,λ必须为正。因此,对于任意的(u,i)∈d和
在这里,
本发明的auc-mf的程序实现过程中的步骤1)-步骤3)在表格1中给出。
表格1
6.子取样
对于地点推荐,训练过程并不需要无标签的数据。和这个不同,使用auc的兴趣地点推荐需要将所有的兴趣地点对放在优化过程中。这样会让优化过程非常耗时。为了解决这个问题,对于每一对(u,i)∈d,在
这里e(f(x))代表的是f(x)的期望。
7.使用地理上下文扩展auc-mf
auc-mf可以很容易的将上下文因子通过优化推荐结果的方式融合进来。本发明使用地理上下文和签到频率来展示如何扩展auc-mf,即为步骤4)-5)。其他的上下文信息也可以相似地融入到auc-mf里面。
地理上下文已经被证实在兴趣地点推荐里可以起作用。然而,大多数的工作是在训练过程中使用地理上下文信息,这让优化和调参都变得既耗时又困难。本发明提出了一种优化结果的方式来利用上下文信息。这种方法可以通过利用不同的上下文因子来优化auc-mf的推荐结果。
为了整合地理上下文,假设用户会更加愿意光顾之前光顾过的兴趣地点周围的地点。本发明使用高斯距离来测量两个兴趣地点的距离:
在这里xi是兴趣地点i的坐标,即经度和纬度,σ是一个常数,根据经验设为0.1。本发明定义了k近邻矩阵
在这里n(li)是兴趣地点i的k个最近邻的集合。
然后,本发明定义了一个签到矩阵
其中
为了适应地理上下文在不同数据集上的重要性,将rpre和rgeo线性组合起来得到最后的推荐结果:
在这里,μ∈[0,1]是控制地理影响的系数。利用地理上下文的过程在表格2中给出。
表格2
实验部分
接下来将对比auc-mf和相同设定的其他先进的算法。本发明也研究了不同参数对auc-mf的影响。
表格3数据统计
1.实验设定
1.1数据集
本发明使用了gowalla从2010年11月份到2011年7月份的签到数据。这里面一共有36001959次签到,319063个用户和2844076个兴趣地点。每一个签到包含用户id,地点id和时间戳。每个地点的经度和纬度都可以获得。为了检验本发明框架的准确率,使用reverse-geocoder在数据集中提取出了两个城市的数据。关于这两个城市的数据统计在表格3中给出。
在实验中,所有的数据集被分成三个部分,对于每一个用户,将他的签到按照时间戳排序然后取前70%作为训练集,中间10%作为调试集,最后20%作为测试集。
1.2测试标准
使用准确率(pr)和召回率(re)两个度量指标来检验本发明推荐方法的性能。给定一个用户u,
其中ut是测试集中用户的集合,并且设置k=10。
1.3对比方法
本发明和三个基于矩阵分解的算法进行比较。其中两个利用了地理上下文信息并且在最新的评测中获得了头两名的成绩。
irenmf:这个模型使用了从位置角度的地理上的特性,从而将相邻地点建模成两个层次。
wrmf:这个是不使用地理特征的irenmf的特殊版本。
rankgeofm:这是一个基于排序的矩阵分解模型,首先学习了用户的排名倾向,然后包含了相近地点的地理上的影响。
auc-mf:本发明提出的方法。添加地理影响的标记为auc-mf+geo。
表格4实验结果
2.实验结果
首先给出了和其他基准算法的比较,本本发明还给出了地理上下文对算法的影响以及收敛速率。
2.1兴趣地点推荐结果
表格4给出了兴趣地点推荐的比较结果。可以观察到auc-mf要比其他的在准确率和召回率上要高。当融合了地理上下文auc-mf+geo在柏林数据集上提高了准确率。特别的,在柏林数据集上,本发明的方法要超过wsmf、irenmf、rankgeofm和lrt分别有31%、21%、29%和48%。然而,地理上下文信息在纽约数据集上并不是特别有效,。接下来,分析地理上下文的影响。
2.2地理上下文的影响
在auc-mf+geo中,地理上下午的影响被权重μ控制。图2、图3,给出了不同设定的μ对最终结果的影响。值得注意的是,在柏林数据集上,当μ=0.8左右时达到最好结果。在纽约数据集上,不使用上下文信息得到最好结果。
2.3收敛速率
auc-mf的收敛速率在图4、图5,中给出。在柏林数据集上,auc最大化大约需要50回合收敛,但在纽约数据集上只需要不到10回合。这是因为纽约数据集里的数据比柏林数据集多,从而每回合被更新的次数多。
总结
本发明提出了一种基于最大化接受者操作特征曲线下方面积的推荐方法来进行兴趣地点推荐。为了优化auc,使用了基于兰姆达(lambda)的方法来产生一个隐损失函数。为了满足这种方法的两个条件,本发明定义了一个新的常数兰姆达,从而确保隐损失函数的存在和为凸函数。接着将兰姆达方法和矩阵分解方法结合。本发明使用了随机梯度下降来最优化损失函数。本发明的方法具有很好的扩展性从而利用各种上下文信息。实验结果表明,本发明的方法能达到最高水平的结果。
上述仅为本发明的具体实施方式,但本发明的设计构思并不局限于此,凡利用此构思对本发明进行非实质性的改动,均应属于侵犯本发明保护范围的行为。
- 还没有人留言评论。精彩留言会获得点赞!