图书评论挖掘系统及方法与流程
本发明一般地涉及计算机技术领域,更具体地,涉及评论挖掘系统及方法。
背景技术:
随着b2c(即,business-to-customer的缩写,而其中文简称为“商对客”。“商对客”是电子商务的一种模式,也就是通常说的直接面向消费者销售产品和服务商业零售模式)、c2c(即,consumertoconsumer实际是电子商务的专业用语,是个人与个人之间的电子商务)网上商城快速发展,商品的在线评论数量迅速增加.在线评论蕴含着丰富的产品意见信息,不仅能够影响消费者购买商品的倾向,更影响了产品的销量。
针对大量的图书评论而言,对其进行数据挖掘,可以帮助消费者在海量信息源中迅速找到真正需要的信息,以最简单直接的手段将评论挖掘结果反馈给商家和消费者。这样既可以帮助商家了解用户最感兴趣的图书产品特征,从而进行改进,又可以帮助用户在购买某种图书之前深入了解该图书的购买者关于购买过程及图书的体验,并可对同类图书进行比对,挑选出适合自己的图书,从而增强消费者的购买行为的科学性。
为了解决上述问题,研究者开始考虑使用自动化的、数据挖掘的方式对网上图书评论进行分析。图书评论挖掘过程主要包含两个方面:一个是产品特征提取,另一个是评论情感分析。目前,评论挖掘技术被越来越多的研究者进行研究探索,但评论挖掘平台的建设还不太成熟,目前还没有专用的图书评论挖掘平台。
评论挖掘技术在英文领域已进行了多年的研究,有了一定的技术基础,但由于中文与英文的差异,英文领域的研究成果无法直接适用于中文领域。现有的评论挖掘系统使用的技术仍然有许多问题等待研究解决。现有技术在提取产品特征时使用了性能较好的fp-growth(frequentpatterntree,又称频繁模式树)算法。fp-tree是一种特殊的前缀树,由频繁项头表和项前缀树构成。fp-growth算法基于以上的结构加快整个挖掘过程。但该方法研究结果有大量的冗余数据,产品特征挖掘结果准确度不高。
而针对情感分析而言,现有技术中通过wordnet的同义词与反义词关系,获得情感词的情感倾向,其中,wordnet是由princeton大学的心理学家,语言学家和计算机工程师联合设计的一种基于认知语言学的英语词典。它不是光把单词以字母顺序排列,而且按照单词的意义组成一个“单词的网络”。然后根据句子中情感倾向占优势的情感词类进行句子极性的判断,但其未考虑评论中会出现大量转义词,以至于准确度较低。
技术实现要素:
现有技术中存在产品特征挖掘准确度不高以及如果评论中出现大量转义词,则会降低情感分析的准确度。为了解决这些问题,本发明提供了一种能够解决上述技术问题的评论挖掘系统。
根据本发明的一方面,提供了一种图书评论挖掘系统,包括:数据获取及清洗模块,用于从大型网站上抓取评论信息的原始数据并对原始数据进行清洗,以形成评论的原始语料库;预处理模块,对原始语料库进行分词和冗余词匹配替换的预处理;特征提取及挖掘模块,用于从原始语料库中提取产品特征并且对产品特征进行挖掘,以获得出现频率高的评论特征词的数据库;以及评论极性分析模块,用于对评论的数据库进行分类以获得具有整体极性分类的结果数据库。
优选地,预处理模块进一步包括冗余词表匹配替换子模块,用于对原始评论与冗余词汇表进行比较并根据比较结果进行冗余词替换。
优选地,冗余词汇表生成子模块,用于结合常见中文频项词非产品特征表和同义词表预先形成冗余词汇表。
优选地,冗余词汇表生成子模块还根据冗余词表匹配替换子模块提供的反馈信息,扩展冗余词汇表。
优选地,预处理模块进一步包括分词子模块,用于对原始语料库中的原始评论进行分词并进行词性标注,其中,词性标注包括标注名词、名词短语、动词、形容词。
优选地,特征提取及挖掘模块利用apriori算法对评论进行产品特征挖掘。
优选地,评论极性分析模块还包括转义处理子模块,用于对评论的数据库中评论进行转义复句处理。
优选地,评论极性分析模块采用svm支持向量机算法对转义复句处理的评论进行整体极性分析以构建svm分类模型。
优选地,评论极性分析模块通过svm分类模型对评论情感极性进行分类并生成结果数据库。
优选地,结果数据库和评论特征词的数据库以图形化或图表化的形式展示给消费者。
优选地,对原始数据进行清洗还包括去除非中文评论和无用评论。
根据本发明的另一方面,提供了一种图书评论挖掘方法,包括:从大型网站上抓取评论信息的原始数据并对原始数据进行清洗,以形成评论的原始语料库;对原始语料库进行分词和冗余词匹配替换的预处理;从原始语料库中提取产品特征并且对产品特征进行挖掘,以获得出现频率高的评论特征词的数据库;以及对评论的数据库进行分类以获得具有整体极性分类的结果数据库。
本发明的实施例所提供的图书评论挖掘系统,通过建立冗余词汇表,并对评论进行冗余词替换处理,提高了产品特征挖掘准确度,并且对转义复句进行整体极性分析,而不是对各个转义词进行分析,因此,即使评论中大量出现转义词,也不会降低情感分析的准确度。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1是根据本发明的实施例的图书评论系统的结构框图;
图2是根据本发明的实施例的预处理模块的结构框图;
图3是根据本发明的实施例的图书评论挖掘系统进行评论挖掘的流程图;
图4是根据本发明的实施例的利用jsoup提取网页信息的流程图;
图5是根据本发明的实施例的情感分析流程图;以及
图6是根据本发明的实施例的图书评论方法的流程图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
图1是根据本发明的实施例的图书评论系统的结构框图。下面将参照图1对图书评论系统进行描述。在本发明的实施例中,图书评论挖掘系统100,包括:数据获取及清洗模块102,用于从大型网站上抓取评论信息的原始数据并对原始数据进行清洗,以形成评论的原始语料库;预处理模块104,对原始语料库进行分词和冗余词匹配替换的预处理;特征提取及挖掘模块106,用于从原始语料库中提取产品特征并且对产品特征进行挖掘,以获得出现频率高的评论特征词的数据库;以及评论极性分析模块108,用于对评论的数据库进行分类以获得具有整体极性分类的结果数据库。
本发明的以上实施例对评论进行冗余词替换处理,提高了产品特征挖掘准确度,并且对转义复句进行整体极性分析,而不是对各个转义词进行分析以获得具有整体极性分类的结果数据库,因此,即使评论中大量出现转义词,也不会降低情感分析的准确度。
下文中,将参照图1-图2对图书评论挖掘系统进行详细描述。图书评论挖掘系统100包括数据获取及清洗模块102,用于从大型网站上抓取评论信息的原始数据并对原始数据进行清洗,以形成评论的原始语料库;对原始数据进行清洗还包括去除非中文评论和无用评论。例如,将评论中的英文和对图书评论无用的评论去除。
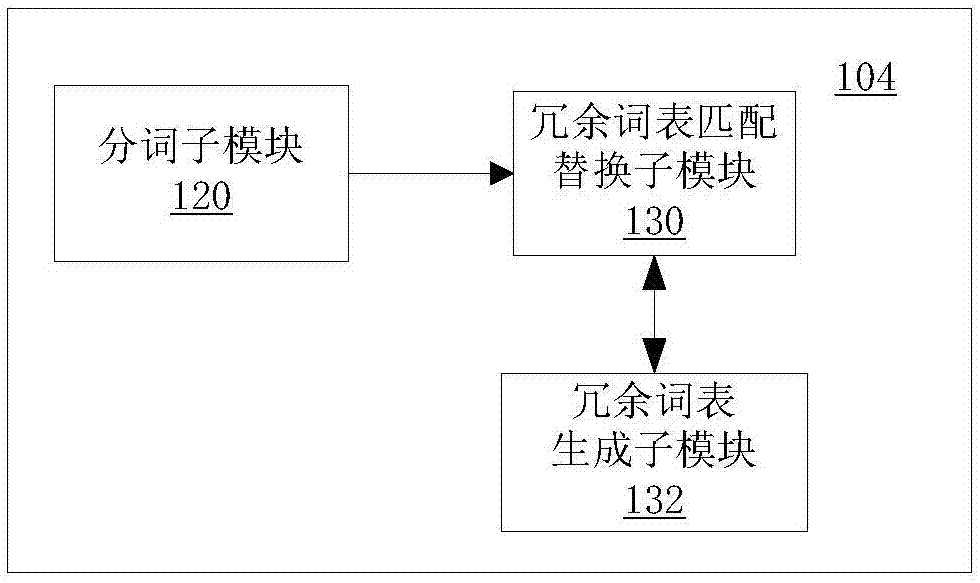
图书评论挖掘系统100包括预处理模块104,对原始语料库进行分词和冗余词匹配替换的预处理。图2是根据本发明的实施例的预处理模块的结构框图。下文中,将参照图2对预处理模块104进行详细描述。
参照图2,预处理模,104进一步包括冗余词表匹配替换子模块130,用于对原始评论与冗余词汇表进行比较并根据比较结果进行冗余词替换。具体地,冗余词汇表生成子模块132,用于结合常见中文频项词非产品特征表和同义词表预先形成冗余词汇表。此外,冗余词汇表生成子模块132还根据冗余词表匹配替换子模块130提供的反馈信息,扩展冗余词汇表。预处理模块进一步包括分词子模块120,用于对原始语料库中的原始评论进行分词并进行词性标注,其中,词性标注包括标注名词、名词短语、动词、形容词。具体地,冗余词表匹配替换子模块130从分词子模块接收进行分词处理并进行词性标注的原始评论并将接收到的原始评论进与冗余词汇表进行比较并根据比较结果进行冗余词替换。例如,将“书”、“图书”和“书籍”等冗余词进行替换。
图书评论挖掘系统100包括特征提取及挖掘模块106,用于从原始语料库中提取产品特征并且对产品特征进行挖掘,以获得出现频率高的评论特征词的数据库。特征提取及挖掘模块利用apriori算法对评论进行产品特征挖掘。具体地,apriori算法是一种挖掘关联规则的频繁项集算法,其核心思想是通过候选集生成和情节的向下封闭检测两个阶段来挖掘频繁项集。而且算法已经被广泛的应用到商业、网络安全等各个领域。该算法的基本思想是:首先找出所有的频集,这些项集出现的频繁性至少和预定义的最小支持度一样。然后由频集产生强关联规则,这些规则必须满足最小支持度和最小可信度。然后使用第1步找到的频集产生期望的规则,产生只包含集合的项的所有规则,其中每一条规则的右部只有一项,这里采用的是中规则的定义。一旦这些规则被生成,那么只有那些大于用户给定的最小可信度的规则才被留下来。为了生成所有频集,使用了递归的方法。
图书评论挖掘系统100包括评论极性分析模块108,用于对评论的数据库进行分类以获得具有整体极性分类的结果数据库。评论极性分析模块还包括转义处理子模块,用于对评论的数据库中评论进行转义复句处理,以能够获得整体极性分类,而不是获得个别词的极性分类。评论极性分析模块采用svm(supportvectormachine)支持向量机算法对转义复句处理的评论进行整体极性分析以构建svm分类模型。评论极性分析模块通过svm分类模型对评论情感极性进行分类并生成结果数据库。最后,结果数据库和评论特征词的数据库以图形化或图表化的形式展示给消费者。将整体评论结果的结果数据库和评论特征词的局部的数据库以图形化或图表化的形式展示给消费者,使消费者能够直观地观看到图书各属性的整体评论和特征词评论以为用户购买图书提供有参考价值的参考。其中,svm是一种判别方法,在机器学习领域,是一个有监督的学习模型,通常用来进行模式识别、分类以及回归分析。
为解决现有技术在挖掘评论挖掘过程中出现的问题,使得评论挖掘过程系统化呈现,本发明提出一种图书评论挖掘系统。本系统的开发基于eclipse、apachetomcat7.0、mysql数据库。使用的框架主要为springmvc框架,并集成mybatis进行系统开发。整个图书评论挖掘系统的流程设计如图3所示。即,首先从诸如京东或亚马逊等的图书网站上获取图书评论语料库。对图书评论语料库进行特征提取以获取图书特征集合。对图书评论语料库进行主观句定位,从而获取主观句集合。从图书特征集合和主观句集合中提取用户态度,对提取的用户态度进行评论极性分析以生成评论结果数据库,最后,结果数据库以图形化或图表化的形式展示给消费者。
图书评论挖掘系统100包括以下主要模块:模块一进行网络评论数据抓取及数据清洗(参考图4)。具体地,参考图4对模块一进行详细描述。采用jsoup方式从京东等大型网站上抓取手机评论信息,分析页面html标签,构建文本抽取模块,包括评论用户、评论标题、评论内容、评论星级等,形成原始数据。对原始数据进一步进行数据清洗,不仅对数据去噪,去除不规范数据,而且根据评论时间、评论用户和评论内容制定规则进行数据去重。去除原始数据库中的重复数据,提高数据的质量,继而形成原始语料库。其中,jsoup是一款java的html解析器,可直接解析某个url地址、html文本内容。它提供了一套非常省力的api,可通过dom、css以及类似于jquery的操作方法来取出和操作数据。
模块二进行分词、词性标注。具体地,为了对图书评论进行产品特征提取,需要对原始评论语料进行分词,而且分词的好坏直接决定了研究结果的准确性。本文使用中国科学研究院开发的nlpir汉语分词系统。具体地,nlpir汉语分词系统的主要功能包括中文分词;词性标注;命名实体识别;用户词典功能;支持gbk编码、utf8编码、big5编码。新增微博分词、新词发现与关键词提取。该分词工具可以达到较好的分词和词性标注效果,准确率很高。由于本次研究主要是提取评论特征,评论特征主要集中在名词和名词短语上,故在进行特征词提取时,抽取名词或名词短语作为产品特征提取元素。
模块三进行冗余词表匹配替换。具体地,为了解决目前技术方法提取产品特征时造成的冗余度大的问题,本文提出结合常见中文频繁项词非产品特征表和同义词表形成冗余词汇表,在使用算法提取产品特征前对所有数据进行冗余词匹配替换,使得在提取产品特征时冗余度减小,提高提取结果准确度。
模块四采用apriori算法进行产品特征挖掘。具体地,使用apriori算法对评论进行产品特征挖掘,从评论中得到产品特征,且由于上一步冗余词表匹配替换已将同义词或冗余词进行统一,故算法挖掘结果冗余度有了明显的降低,对整体图书挖掘系统的结果呈现做出改进。
模块五进行评论情感分析。评论情感分析的流程图如图5所示:本系统采用svm支持向量机算法对评论预料进行整体极性分类,构建svm分类模型,并针对转义复句进行处理,使得转义句整体情感极性以转义词后的情感为主,使得评论情感分析更加准确。
模块六进行图形化界面展示。以图形化,图表化的形式展示挖掘结果。使消费者可以直观看到图书各属性的好评度,帮助消费者做出正确的购书决策。
下文中,将参照图6,对图书评论挖掘方法进行描述。参考图6,图书评论挖掘方法600包括以下步骤:在步骤610中,从大型网站上抓取评论信息的原始数据并对原始数据进行清洗,以形成评论的原始语料库;在步骤620中,对原始语料库进行分词和冗余词匹配替换的预处理;在步骤630中,从原始语料库中提取产品特征并且对产品特征进行挖掘,以获得出现频率高的评论特征词的数据库;以及在步骤640中,对评论的数据库进行分类以获得具有整体极性分类的结果数据库。
图书评论挖掘方法的具体步骤与图书评论挖掘系统一致,为了避免重复,本文中省略了其详细描述。
产品评论作为消费者购物的直接关注点,对于产品的销售情况有着重大影响,也是其他消费者做出购买决策的重要参数,更是生产者和销售商改进产品和服务的重要依据。本文提出的图书评论挖掘系统和方法,改进了挖掘流程,使得图书评论产品特征提取及情感分析更加准确。本文的系统和方法具有良好的性能,有望在一定程度上帮助解决评论数据挖掘中出现的问题,提供了一套比较完善的系统设计及实现方法,采用系统的方式流畅地进行图书评论挖掘分析。结果,图书评论挖掘系统以流程化的方式挖掘出图书评论中的有用信息。
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
- 还没有人留言评论。精彩留言会获得点赞!