一种基于应用安装偏好判定用户年龄段的方法和装置与流程
本发明涉及信息分析领域,尤其涉及一种基于应用安装偏好判定用户年龄段的方法和装置。
背景技术:
随着移动互联网和移动互联网的普及和发展,应用软件的开发商及运营商越来越关心其产品的当前主要使用群体的信息,例如群体的年龄段分布、性别以及使用习惯等等,以便在后继阶段更有针对性地开发产品的功能,从而为客户提供更准确的商品或服务。
以手机游戏为例,用户所处的年龄段不同,对具体的游戏需求也不相同。譬如,小孩子喜欢色彩明快且规则简单的益智休闲类的游戏;青少年则更喜欢玩社交类的游戏。为了提高手机游戏推荐的效果,可以根据不同的年龄段的用户定向推荐适合其年龄段特点的游戏和游戏内的虚拟装备道具,以优化用户体验,并提高推送的点击率。
但是,一方面为了提高注册的时间效率,应用软件一般不要求用户在在注册时必须填报年龄;另一方面,即使部分用户填写了这方面信息,也不能保证其填写正确。这造成相关信息在数据库中缺失。目前业界一般是基于用户操作应用软件的行为,通过构建分类器捕捉用户的行为与年龄段之间的关系。例如,公开号为cn103927675a的发明提出了一种基于用户的消费数据,利用朴素贝叶斯分类方法根据消费商品的分布,预判用户的年龄段。由于上述方法依赖于用户的商品交易数据,而一般情况下只有电商领域的企业才拥有相关的数据,因此上述技术方案并不能推广应用到其他类型应用软件。此外,一方面部分用户的商品交易数据对年龄段的区分度不显著,不同年龄段的用户可以具有类似的交易行为(日常家居用品,例如厨具、餐具和洗涤用品等等,不具有明显的年龄段区分度);另一方面,用户的商品交易数据也可能会受到电商的促销或团购等活动而影响。因此,基于商品交易数据来判断用户的年龄段,准确率并不高。
技术实现要素:
本发明的目的是解决现有技术的不足,提供一种基于应用安装偏好判定用户年龄段的方法和装置,能够获得更为通用和准确地预测用户年龄段的效果。
为了实现上述目的,本发明采用以下的技术方案:
首先,本发明提出一种基于应用安装偏好判定用户年龄段的方法,包括以下步骤:从应用列表中获取用户已安装应用的列表文本;根据用户已安装应用的列表文本以及记录已标注用户年龄段的标注库,构建训练样本;基于训练样本,建立并训练多层感知分类器;以及利用已训练的多层感知分类器预测用户的年龄段。
在本发明的一个方法实施例中,列表文本通过检测是否安装特有的应用或当前运行进程的信息形成。
在本发明的一个方法实施例中,标注库至少包括用户的特征向量和标注年龄段。
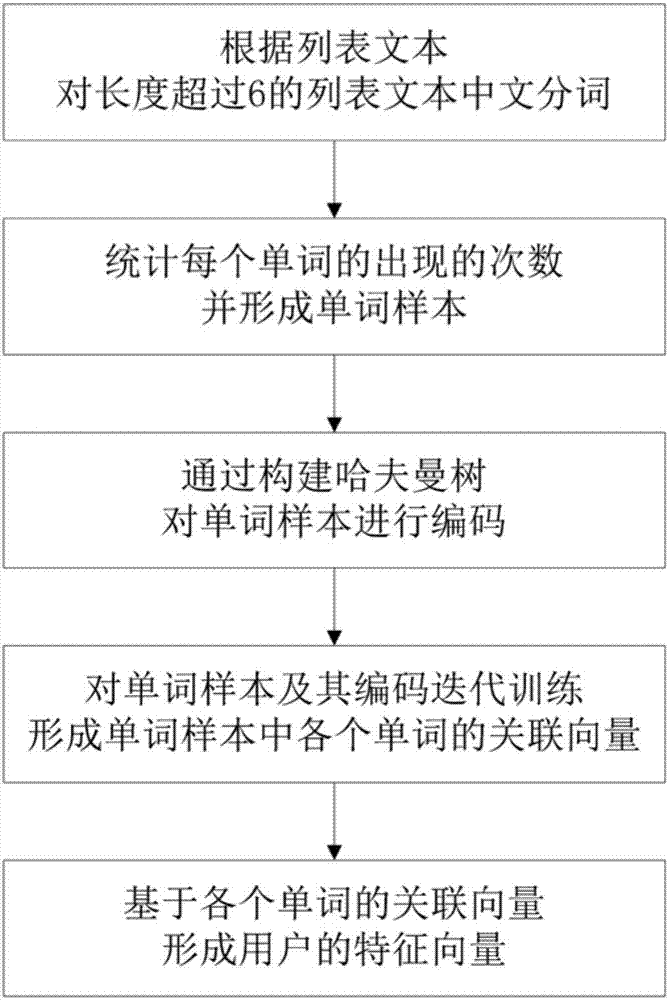
进一步地,在本发明的上述方法实施例中,根据用户已安装应用的列表文本以及记录已标注用户年龄段的标注库,构建训练样本进一步包括以下步骤:根据列表文本,对长度超过6的列表文本中文分词;统计每个单词的出现次数,并去除停用词,以及出现次数高于次数上限或低于次数下限的单词,以形成单词样本;通过构建哈夫曼树(huffmantree)对单词样本进行编码;对单词样本及其编码迭代训练,形成单词样本中各个单词的关联向量;基于各个单词的关联向量,形成用户的特征向量。
再进一步地,在本发明的上述方法实施例中,单词样本中各个单词的关联向量是基于cbow模型(连续词袋模型,continuousbagofwordsmodel)迭代形成。
在本发明的一个方法实施例中,标注年龄段是基于游戏中的实名登记信息获取。
在本发明的一个方法实施例中,多层感知分类器采用梯度下降法训练。
其次,本发明提出一种基于应用安装偏好判定用户年龄段的装置,包括以下模块:读取模块,用于从应用列表中获取用户已安装应用的列表文本;构建模块,用于根据用户已安装应用的列表文本以及记录已标注用户年龄段的标注库,构建训练样本;训练模块,用于基于训练样本,建立并训练多层感知分类器;以及预测模块,用于利用已训练的多层感知分类器预测用户的年龄段。
在本发明的一个装置实施例中,读取模块通过检测是否安装特有的应用或当前运行进程的信息形成列表文本。
在本发明的一个装置实施例中,构建模块所形成的标注库至少包括用户的特征向量和标注年龄段。
进一步地,在本发明的上述装置实施例中,构建模块进一步包括以下子模块:分词模块,用于根据列表文本,对长度超过6的列表文本中文分词;统计模块,用于统计每个单词的出现次数,并去除停用词,以及出现次数高于次数上限或低于次数下限的单词,以形成单词样本;编码模块,用于根据单词的出现次数初始化哈夫曼树,以对单词样本进行编码;第一关联模块,用于对单词样本及其编码迭代训练,形成单词样本中各个单词的关联向量;第二关联模块,用于基于各个单词的关联向量,形成用户的特征向量。
再进一步地,在本发明的上述装置实施例中,第一关联模块基于cbow模型迭代形成单词样本中各个单词的关联向量。
在本发明的一个装置实施例中,构建模块基于游戏中的实名登记信息获取标注年龄段。
在本发明的一个装置实施例中,训练模块采用梯度下降法训练多层感知分类器。
最后,本发明还公开了一种计算机可读存储介质,其上存储有计算机指令,该指令被处理器执行时实现如前述任一项所述方法的步骤。
本发明的有益效果为:通过获取用户已安装应用的列表而不依赖于用户的商品交易数据等相关领域的数据,更方便快捷地获取用于预测的信息,并能够提高预测的准确率。
附图说明
图1所示为本发明所公开的基于应用安装偏好判定用户年龄段方法的方法流程图;
图2所示为图1中构建训练样本进的子步骤方法流程图;
图3所示为验证预测用户的年龄段方法流程的示意图;
图4所示为本发明所公开的基于应用安装偏好判定用户年龄段装置的装置模块图。
具体实施方式
以下将结合实施例和附图对本发明的构思、具体结构及产生的技术效果进行清楚、完整的描述,以充分地理解本发明的目的、方案和效果。需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。附图中各处使用的相同的附图标记指示相同或相似的部分。
本发明所公开技术方案是基于以下的假设:不同年龄段的用户受所处的社会阶段和周围环境的影响,其所使用的应用软件在类型和频率上都是有差异的。例如,处于中小学生阶段的用户多使用工具类的应用,譬如“某某英语词典”、“某某汉语词典”或“某某公式查询”等等,较少甚至不会使用金融理财类的手机应用。事实上,即使仅在手机游戏领域,不同年龄段的用户所游玩的手机游戏的类型也是不一样的。因此,基于已经安装的应用软件偏好差异,可以预测用户所处的年龄段。进一步地,与现有技术方案所需要获取用户的商品交易数据相比较,软件应用的信息更为宽泛,从而能够更准确地预测用户的年龄段。
为方便说明本发明所列举的实施例,本发明按照实际业务场景中用户的消费模式,将用户的年龄段划分为4个类别:少年(18岁以下)、青年(18岁至26岁)、中青年(26岁至40岁)和中年(40岁及以上)。上述分类仅作为年龄段分类的一个例子。本领域技术人员可以根据具体的应用场景,采用不同的年龄段划分方式。本发明对此不予限定。
基于上述理由,本发明所公开的技术方案将已安装的应用软件作为判断标准,预测用户的年龄段。具体地,参照图1所示的方法流程图,根据本发明所公开的一个实施例,基于应用安装偏好判定用户年龄段的方法包括以下步骤:从应用列表中获取用户已安装应用的列表文本;根据用户已安装应用的列表文本以及记录已标注用户年龄段的标注库,构建训练样本;基于训练样本,建立并训练多层感知分类器;以及利用已训练的多层感知分类器预测用户的年龄段。
在本发明的上述方法实施例中,列表文本通过检测是否安装特有的应用或当前运行进程的信息形成。具体地,列表文本可以仅记录某些对用户的年龄段敏感的特定应用,作为判断用户的年龄段的依据。例如,可以预先设置一批目标人群是特定年龄段的用户,且被广泛使用的应用软件的urlscheme;并通过检测用户的移动终端是否对这批urlscheme是否有响应,以判断对应的应用软件是否已经安装。替代地,列表文本也可以通过捕获用户当前正在运行的进程(例如,可以使用adb或者packagemanager等工具捕获),再从进程的信息中获取已安装应用软件的信息,以全面地了解具体用户的应用软件安装偏好。关于获取列表文本的具体方式,本领域技术人员可以根据具体的应用场景而采用本领域常规技术手段实现。本发明对此不予限定。
在本发明的上述方法实施例中,标注库包括但是不限于用户的特征向量和标注年龄段。其中,用户的特征向量是基于用户已安装应用的列表文本形成的。标注年龄段是根据已经确认年龄段的用户形成的。此外,标注库还可以包括用户的活跃天数、注册时间、注册ip地址和登陆ip地址等辅助判断信息。例如,若注册ip地址或者登陆ip地址可确定为校园网的,则用户的年龄段是少年或者青年的概率比较大。
对于用户的特征向量,传统的方案是通过构造列表文本的文本类特征形成,即把列表文本视为普通文本,并先后对列表文本执行中文分词、词语筛选和特性表示等文本处理技术,构造对应的特征向量。具体地,可采用本领域常用的开源工具结巴分词对列表文本执行中文分词处理;然后,利用tf-idf(词频—逆向文件频率,termfrequency–inversedocumentfrequency)排序筛选方法,把区分度较小的词语滤除;最后,特性向量采用词语0-1表示法生成。
但是,上述方法只考虑列表文本中各个应用软件的词语的含义,并没有考虑应用软件之间的相互关联以及应用软件的使用频次。换句话说,应用列表至少包含以下三方面的信息:应用软件文本,应用软件间的关系,和应用软件的使用频次。而上述传统方法构建文本类特征时,由于只考虑了应用软件文本这单一的信息,忽略了另外两类重要信息(即应用软件间的相互关系和应用软件的使用频次);因此,诸如用户使用某两款应用比用户使用某一款应用具有更多的信息量和更强的区分度的信息没有被利用,从而降低了用户的特征向量的区分度。
基于上述理由,为了进一步地提高区分度,用户的特征向量是通过词嵌入(wordembedding)的方式形成。具体地,参照图2所示的构建训练样本进的子步骤方法流程图,在本发明的上述方法实施例中,根据用户已安装应用的列表文本以及记录已标注用户年龄段的标注库,构建训练样本进一步包括以下步骤:根据列表文本,对长度超过6的列表文本中文分词;统计每个单词的出现次数,并去除停用词(stopword,即“的”、“是”和“了”等虽然出现次数较高,但是没有实质内容的单词),以及出现次数高于次数上限或低于次数下限的单词(次数上限与次数下限可以预先设置,用于去除停用词外的一些因过于常用而区分度较低的单词,和与日常使用习惯不符而少用的单词),以形成单词样本;根据单词的出现次数初始化哈夫曼树,以对单词样本进行编码;对单词样本及其编码迭代训练,形成单词样本中各个单词的关联向量;基于各个单词的关联向量,形成用户的特征向量。其中,哈夫曼树的非叶节点存储有一个参数向量,用于形成单词的关联向量。所有的叶节点分别代表了列表文本中的一个词语。参数向量初始化为零向量。当经过适当的迭代训练使得用于单词样本编码的哈夫曼树稳定后,各个单词的关联编码可以通过从哈夫曼树的根节点遍历到相应的叶节点的具体路径确定。此外,用户的特征向量可采用以下的方式形成:首先,检索该用户对应的应用列表中的多个文本词语;然后,找出这些文本内的单词对应的关联向量,把这些关联向量累计即可获得该用户对应的特征向量。
进一步地,在本发明的上述方法实施例中,单词样本中各个单词的关联向量是基于cbow模型迭代形成。由于cbow模型的具体迭代训练为本领域的公知常识,本文在此不再详细描述,只是再次指出迭代训练所用的分类器是基于应用软件间的关系和应用软件的使用频次而构建的。本领域技术人员可以根据实际情况具体设置的分类器。本发明对此不予限定。
在本发明的一个方法实施例中,标注年龄段是基于游戏中的实名登记信息获取。例如,若实名登记的方式是采用身份证验证,则用户的标注年龄段可以根据身份证上的编号获取。
在本发明的一个方法实施例中,基于已经构建的训练样本,多层感知分类器采用梯度下降法训练,以在适当的时间内获得具有可用的多层感知分类器。具体的多层感知分类器创建和训练可以本领域的常用技术手段实现。本发明对此不予限定。
参照图3所示的方法流程的示意图,在本发明的一个方法实施例中,可基于已确定年龄的用户,验证多层感知分类器所预测用户的年龄段。例如,应用软件的运营商可随机筛选1万个用户。这些用户在注册的时候有登记身份,从而可以通过身份证判定该用户的年龄段。该标注数据与本发明输出的预测结果做匹配,从而统计所提供技术方案准确率,或者作为反馈信息调整分类器的参数。
参照图4所示的装置模块图,根据本发明所公开的一个实施例,基于应用安装偏好判定用户年龄段的装置包括以下模块:读取模块,用于从应用列表中获取用户已安装应用的列表文本;构建模块,用于根据用户已安装应用的列表文本以及记录已标注用户年龄段的标注库,构建训练样本;训练模块,用于基于训练样本,建立并训练多层感知分类器;以及预测模块,用于利用已训练的多层感知分类器预测用户的年龄段。
在本发明的上述装置实施例中,读取模块通过检测是否安装特有的应用或当前运行进程的信息形成列表文本。具体地,读取模块所生成的列表文本可以仅记录某些对用户的年龄段敏感的特定应用,作为判断用户的年龄段的依据。例如,读取模块可以预先设置一批目标人群是特定年龄段的用户,且被广泛使用的应用软件的urlscheme;并通过检测用户的移动终端是否对这批urlscheme是否有响应,以判断对应的应用软件是否已经安装。替代地,读取模块也可以通过捕获用户当前正在运行的进程(例如,可以使用adb或者packagemanager等工具捕获),再从进程的信息中获取已安装应用软件的信息形成列表文本,以全面地了解具体用户的应用软件安装偏好。关于读取模块获取列表文本的具体方式,本领域技术人员可以根据具体的应用场景而采用本领域常规技术手段实现。本发明对此不予限定。
在本发明的上述方法实施例中,构建模块所形成的标注库包括但是不限于用户的特征向量和标注年龄段。其中,构建模块可基于用户已安装应用的列表文本形成用户的特征向量。标注年龄段是构建模块根据已经确认年龄段的用户形成的。此外,标注库还可以包括用户的活跃天数、注册时间、注册ip地址和登陆ip地址等辅助判断信息。例如,若注册ip地址或者登陆ip地址可确定为校园网的,则用户的年龄段是少年或者青年的概率比较大。
为了进一步地提高区分度,在本发明的上述装置实施例中,构建模块进一步包括以下模块:分词模块,用于根据列表文本,对长度超过6的列表文本中文分词;统计模块,用于统计每个单词的出现次数,并去除停用词,以及出现次数高于次数上限或低于次数下限的单词,以形成单词样本;编码模块,用于根据单词的出现次数初始化哈夫曼树,以对单词样本进行编码;第一关联模块,用于对单词样本及其编码迭代训练,形成单词样本中各个单词的关联向量;第二关联模块,用于基于各个单词的关联向量,形成用户的特征向量。
其中,哈夫曼树的非叶节点存储有一个参数向量,用于形成单词的关联向量。所有的叶节点分别代表了列表文本中的一个词语。参数向量初始化为零向量。当经过适当的迭代训练使得用于单词样本编码的哈夫曼树稳定后,各个单词的关联编码可以通过从哈夫曼树的根节点遍历到相应的叶节点的具体路径确定。此外,第二关联模块可采用以下的方式形成用户的特征向量:首先,检索该用户对应的应用列表中的多个文本词语;然后,找出这些文本内的单词对应的关联向量,把这些关联向量累计即可获得该用户对应的特征向量。
进一步地,在本发明的上述装置实施例中,第一关联模块基于cbow模型迭代形成单词样本中各个单词的关联向量。由于cbow模型的具体迭代训练为本领域的公知常识,本文在此不再详细描述,只是再次指出迭代训练所用的分类器是基于应用软件间的关系和应用软件的使用频次而构建的。本领域技术人员可以根据实际情况具体设置的分类器。本发明对此不予限定。
在本发明的一个装置实施例中,构建模块基于游戏中的实名登记信息获取标注年龄段。例如,若实名登记的方式是采用身份证验证,则用户的标注年龄段可以根据身份证上的编号获取。
在本发明的一个方法实施例中,基于已经构建的训练样本,多层感知分类器采用梯度下降法训练,以在适当的时间内获得具有可用的多层感知分类器。具体的多层感知分类器创建和训练可以本领域的常用技术手段实现。本发明对此不予限定。
尽管本发明的描述已经相当详尽且特别对几个所述实施例进行了描述,但其并非旨在局限于任何这些细节或实施例或任何特殊实施例,而是应当将其视作是通过参考所附权利要求考虑到现有技术为这些权利要求提供广义的可能性解释,从而有效地涵盖本发明的预定范围。此外,上文以发明人可预见的实施例对本发明进行描述,其目的是为了提供有用的描述,而那些目前尚未预见的对本发明的非实质性改动仍可代表本发明的等效改动。
- 还没有人留言评论。精彩留言会获得点赞!