一种基于AdaBoost‑SVM集成学习算法的行人检测方法与流程
本发明涉及计算机视觉及安防监控领域,尤其涉及一种基于adaboost-svm(adaptiveboost-supportvectormachine,简称adaboost-svm)集成学习算法的行人检测方法。
背景技术:
行人检测时在某段时间里对待检测图像采用一种特定方法来搜索确定行人的存在与否,如果存在,则返回检测到行人的数量,并计算区域范围内行人密度。近年来,随着网络技术的日新月异,行人检测的应用发展越来越广泛,由于行人个体之间的差异性、运动姿态的多样性、行人出现场景的复杂性和自遮挡、视角、光照、尺度等因素的影响,目前还没有一个实时的、精确的、统一的行人检测方法。
目前,行人检测方法主要分为四个大类:基于特征的方法、基于统计学方法、模板匹配方法和基于深度学习的方法。基于统计学习方法中比较常见的行人检测方法是基于外观的方法,此类方法能从样本集中学习行人的不同特征,从而具备很好的推广性;统计学中的两大主要问题是目标特征的提取和机器学习算法的选择,在行人检测的目标特征提取方面,haar特征提取具有实时性较好的特点,广泛使用于智能辅助系统的行人检测,但这种特征的精度不高,而且容易受检测目标移动和光线等因素的影响。hog特征具有较高精确性和鲁棒性,但实时性较低;机器学习算法的选择方面adaboost算法和svm算法取得了一定的成功,但还是存在过度拟合和训练时间过长等特点。
技术实现要素:
本发明的目的是针对传统行人检测方法中计算耗时且错误率高的问题,提出了一种基于adaboost-svm集成学习算法的行人检测方法。这种方法能提高检测的准确率、提高识别的速度。
实现本发明目的的技术方案是:
一种基于adaboost-svm集成学习算法的行人检测方法,所述方法包括如下步骤:
s1:使用高清摄像装置采集道路上的行人图像,作为样本集存入数据库中;
s2:对每一幅图像样本使用hog检测算子提取特征,得到每一幅图像样本的特征向量;
s3:对样本集使用并行式集成学习方法(bagging)进行采样,得到t组样本集,每组样本集包含m个样本;
s4:对每一组样本集使用adaboost-svm算法训练一个分类器,以此得到t个分类器;
s5:使用高清摄像装置采集道路上需要检测的行人图像;
s6:对需要检测的图像使用hog检测算法提取特征,得到需要检测图像的特征向量;
s7:将需要检测图像的特征向量放入步骤s4中训练好的t个分类器进行检测,这样得到t个检测结果;
s8:采用投票法,根据t个检测结果中哪个图像的特征向量被检测到的次数结果多,就将此图像作为最终的行人检测结果。
所述步骤s1-步骤s4为训练单元,所述步骤s5-步骤s8为检测单元。
所述步骤s2包括:
s21.图像标准化:将输入图像转化为灰度图;
s22.计算梯度:图像中像素点(x,y)的梯度以及梯度幅值和方向为:
gx(x,y)=f(x+1,y)-f(x-1,y)
gy(x,y)=f(x,y+1)-f(x,y-1)
其中gx(x,y)和gy(x,y)分别表示输入图像中像素点(x,y)处的水平、垂直方向梯度值,m(x,y)表示梯度幅值,θ(x,y)表示梯度方向;
s23.将输入图像分割成相等大小的小格,并将几个小格合并为一个小块;
s24:方向通道的选取:将0°-180°或者0°-360°平均分成n个通道;
s25:直方图的获取:对每个小格中的每个像素统计它们的梯度方向直方图,直方图的横坐标为步骤s24中选取的n个方向通道,直方图纵坐标为属于某个方向通道的像素的梯度大小的累加和,最终得到一组向量;
s26:归一化处理:以向量对应的像素所在的小块为单位,对向量进行归一化处理,其公式如下:
其中,v*表示归一化之后的向量,v表示归一化之前的向量,
s27:形成hog特征:将上面处理过的所有n个向量连接起来,形成一组向量,即为hog特征。
所述步骤s3包括:给定包含m个样本的数据集,先随机取出一个样本放入采样集中,再把该样本放回初始数据集,使得下次采样时该样本仍有可能被选中,经过m次随机采样操作,就可以得到含m个样本的采样集,依此,采样出t个含m个训练样本的采样集。
所述步骤s4包括:
s41.确定非线性支持向量机高斯核函数的参数σ={σ1,σ2,…},c={c1,c2…};
s42.初始化训练数据的权值分布:
其中i=1,2,...,n;
s43:对于m=1,2,…,m:
(a)使用具有权值分布dm的训练数据集学习,得到一个基于高斯核函数的非线性svm分类器hm;
(b)计算hm在训练数据集上的分类误差率:
(c)计算hm的系数:
这里的对数是自然对数;
(d)更新训练数据集的权值分布:
dm+1=(wm+1,1,…,wm+1,i,…,wm+1,n)
其中,i=1,2,…,n,这里,zm是规范化因子:
它使dm+1成为一个概率分布;
s44.构建基本分类器的线性组合:
得到最终的分类器:
g(x)=sign(f(x))。
与现有技术相比,本技术方案有以下优点:
1.本技术方案通过使用bagging(步骤s3)方法提取样本集,可以防止过拟合问题的发生;
2.本技术方案通过使用adaboost-svm分类器,提高了检测的准确率;
3.本技术方案通过选择合适的svm核函数的参数,采用训练好的svm弱分类器作为adaboost的的基分类器,提高了识别的速度。
这种方法提高了检测的准确率、提高了识别的速度。
附图说明
图1为实施例中方法的流程示意图;
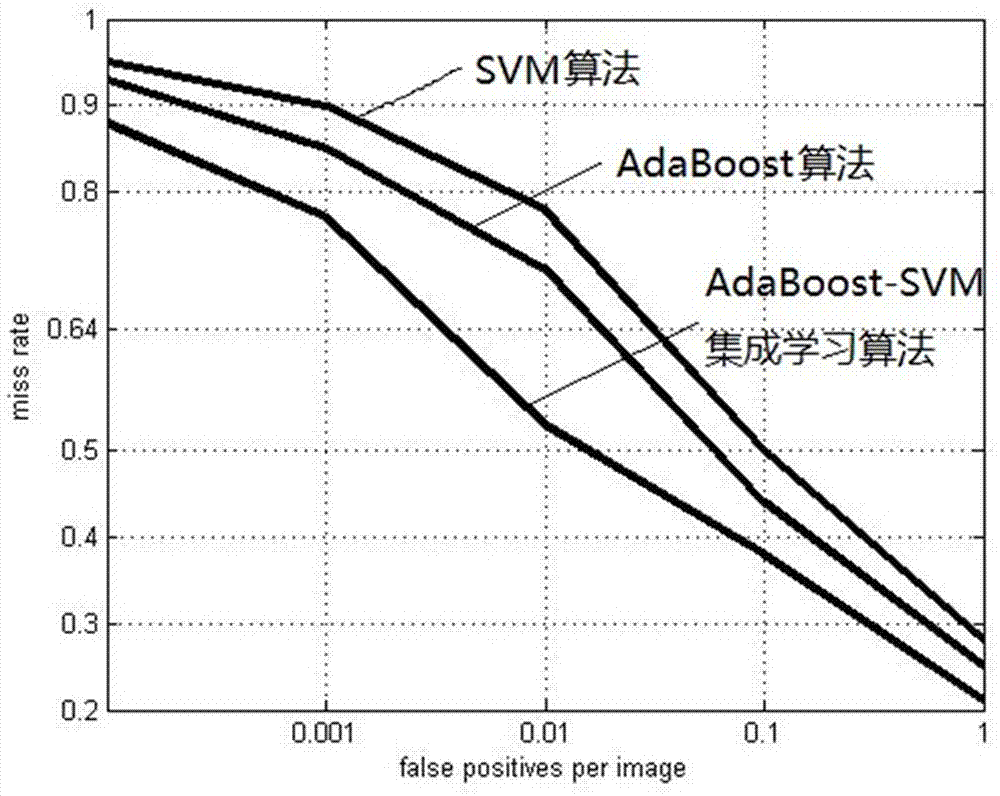
图2为采用实施例中的方法与其他方法的检测结果对比图。
具体实施方式
下面结合附图和实施例对本发明内容作进一步的阐述,但不是对本发明的限定。
实施例:
参照图1,一种基于adaboost-svm集成学习算法的行人检测方法,所述方法包括如下步骤:
s1:使用高清摄像装置采集道路上的行人图像,作为样本集存入数据库中;
s2:对每一幅图像样本使用hog检测算子提取特征,得到每一幅图像样本的特征向量;
s3:对样本集使用并行式集成学习方法(bagging)进行采样,得到t组样本集,每组样本集包含m个样本;
s4:对每一组样本集使用adaboost-svm算法训练一个分类器,以此得到t个分类器;
s5:使用高清摄像装置采集道路上需要检测的行人图像;
s6:对需要检测的图像使用hog检测算法提取特征,得到需要检测图像的特征向量;
s7:将需要检测图像的特征向量放入步骤s4中训练好的t个分类器进行检测,这样得到t个检测结果;
s8:采用投票法,根据t个检测结果中哪个图像的特征向量被检测到的次数结果多,就将此图像作为最终的行人检测结果。
所述步骤s1-步骤s4为训练单元,所述步骤s5-步骤s8为检测单元。
所述步骤s2包括:
s21.图像标准化:将输入图像转化为灰度图;
s22.计算梯度:图像中像素点(x,y)的梯度以及梯度幅值和方向为:
gx(x,y)=f(x+1,y)-f(x-1,y)
gy(x,y)=f(x,y+1)-f(x,y-1)
其中gx(x,y)和gy(x,y)分别表示输入图像中像素点(x,y)处的水平、垂直方向梯度值,m(x,y)表示梯度幅值,θ(x,y)表示梯度方向;
s23.将输入图像分割成相等大小的小格,并将几个小格合并为一个小块;
s24:方向通道的选取:将0o-180o或者0o-360o平均分成n个通道;
s25:直方图的获取:对每个小格中的每个像素统计它们的梯度方向直方图,直方图的横坐标为步骤s24中选取的n个方向通道,直方图纵坐标为属于某个方向通道的像素的梯度大小的累加和,最终得到一组向量;
s26:归一化处理:以向量对应的像素所在的小块为单位,对向量进行归一化处理,其公式如下:
其中,v*表示归一化之后的向量,v表示归一化之前的向量,
s27:形成hog特征:将上面处理过的所有n个向量连接起来,形成一组向量,即为hog特征。
所述步骤s3包括:给定包含m个样本的数据集,先随机取出一个样本放入采样集中,再把该样本放回初始数据集,使得下次采样时该样本仍有可能被选中,经过m次随机采样操作,就可以得到含m个样本的采样集,依此,采样出t个含m个训练样本的采样集。
所述步骤s4包括:
s41.确定非线性支持向量机高斯核函数的参数σ={σ1,σ2,…},c={c1,c2…};
s42.初始化训练数据的权值分布:
其中i=1,2,...,n;
s43:对于m=1,2,…,m:
(a)使用具有权值分布dm的训练数据集学习,得到一个基于高斯核函数的非线性svm分类器hm;
(b)计算hm在训练数据集上的分类误差率:
(c)计算hm的系数:
这里的对数是自然对数;
(d)更新训练数据集的权值分布:
dm+1=(wm+1,1,…,wm+1,i,…,wm+1,n)
其中,i=1,2,…,n,这里,zm是规范化因子:
它使dm+1成为一个概率分布;
s44.构建基本分类器的线性组合:
得到最终的分类器:
g(x)=sign(f(x))。
本实施例随机抽取了单行人、多行人、远视图、近视图四种情况的视频图像作为测试样本集,采用hog检测算法提取图像的特征,将adaboost-svm集成学习算法分别于adaboost和svm进行比较;其中漏检率为未检测出来的行人样本数目与行人样本总数的比值;误检率为非行人样本被检测为行人的数量与非行人样本的总数的比值,从检测指标反映出本发明adaboost-svm集成学习算法检测性能优于其他两种算法。
为了说明实验的结果定义,如图2所示,对检测对比结果进行了比较,实验时随机抽取样本600个作为测试样本集,取3次实验平均值在相同试验环境下对adaboost-svm集成学习算法、adaboost、svm三种算法的运算时间比较,结果如表1所示。
表1三种算法的运行时间和漏检率比较
由表可见在相同误检率下,adaboost-svm集成学习算法具有最少的漏检率和运算时间,由此本实施例adaboost-svm集成学习算法实时性较高。
- 还没有人留言评论。精彩留言会获得点赞!