一种基于选择性集成最小二乘支撑向量机的二噁英软测量系统的制作方法
本发明属于固废处理技术领域,尤其涉及一种基于选择性集成最小二乘支撑向量机的二噁英软测量系统。
背景技术:
城市固废焚烧(mswi)已成为目前国内外多数城市处理可燃垃圾的主要手段。焚烧过程产生多氯代二苯并二英(pcdds)和多氯代二苯并呋喃(pcdfs)等污染物,该类物质的通俗名称是二噁英(后文简称为dxn)[1]。dxn是目前已知的一种剧毒的持久性污染物。目前,多数mswi过程的运行很难以减少二噁英的排放浓度为优化目标,其最为主要的原因之一是dxn难以在线实时检测[2,3]。mswi过程固有的复杂物理和化学特性使得dxn的机理模型难以建立[4]。通常,工业现场dxn的浓度是以月或季为周期在现场采样后,再经长达一周的离线实验室化验与分析才能得到。作为dxn替代测量的dxn指示物检测方法成为当前的关注点之一[5,6],但该方法检测时间的滞后特性导致其也难以用于mswi过程的优化和控制,而且指示物与dxn之间的映射模型精度也有待于进一步提高。因此,采用一种有效的替代方法实现dnx浓度的实时检测非常必要。
数据驱动软测量方法能够对需要离线化验的过程参数或需要专家基于经验认知的质量变量进行在线估计和检测[7,8]。软测量模型具有较好的推理估计能力,已在多个不同的工业过程得到成功应用[9]。显然,本发明研究的dxn浓度的实时在线检测问题可以采用构建软测量模型的方法予以实现,但能够获得建模样本数量是极其有限的。最常用的软测量模型构建方法是人工神经网络(ann)和支撑向量机(svm),其中基于结构风险最小化原则的svm适合对小样本数据建模,可用于本发明所面对的dxn软测量建模问题,但svm需要解决二次规划(qp)问题。最小二乘支撑向量机(lssvm)通过求解一组线性等式简化了svm的qp问题,但其建模参数,如核参数和惩罚参数,通常均与建模数据有关,难以有效合理选择。采用优化算法可实现这些建模参数的选择[10],但其运行过程耗时较长并只能得到次优解。上述这些基于lssvm的方法大多只能构建单一模型,预测性能有待提升。
通常,选择性集成(sen)建模方法通过从候选子模型中选择多个集成子模型并采用线性或非线性的方法进行合并,可得到比单一模型更好的预测性能。sen建模的首要问题是进行集成构造,即如何基于原始的训练数据集构造具有差异性的候选子模型的建模数据集。采用训练样本重采样集成构造策略的遗传算选择性集成(gasen)算法,验证了集成部分可用的候选子模型可获得比集成全部候选子模型更好的泛化性能[11],但建模参数的选择问题在该方法中并未予以解决。采用操纵输入特征集成构造策略的sen算法,有效的用于多源多尺度高维频谱数据建模[12,13,14];该方法通过采用基于分支定界(bb)和自适应加权融合(awf)算法的sen(bbsen-awf)方法,其关注点是如何从sen和信息融合的视角进行多源信息的选择性融合。
本发明只关注面向dxn软测量的基于lssvm的sen方法。研究表明,对于核学习方法而言,不同背景的建模数据往往需要不同的核参数[15]。文献[16]提出了基于模糊c均值的sen-lssvm方法,但其并不适用于小样本数据建模。基于优化算法的多层lssvm可以优化选择输入特征、子模型及其权重[17],但其显然存在启发式优化算法的固有缺点。上述sen-lssvm方法均未解决建模参数的自适应选择问题。通常,多个不同核参数可以更清晰的从不同视角描述建模数据的固有特性。因此,可以采用基于多个候选核参数的集成构造策略构建面向dxn的sen-lssvm模型。通常,基于小样本数据构建lssvm模型时,惩罚参数的选择比较重要,并且其也具有依赖于建模数据的特性。因此,采用与基于核参数的集成构造策略相类似,也可以采用不同的惩罚参数构建不同的候选子模型。
技术实现要素:
本发明要解决的技术问题,提出了一种基于选择性集成最小二乘支撑向量机(sen-lssvm)的dxn软测量系统,首先基于先验知识获得候选核参数集和候选惩罚参数集(后文统一称为建模参数集);接着,基于这些候选建模参数集构建基于lssvm的候选子子模型集合;然后,采用基于分支定界(bb)和自适应加权(awf)的sen(bbsen-awf)算法对具有相同核参数和不同惩罚参数的候选子子模型进行选择和合并进而得到候选sen子模型集合;最后,对候选sen子模型集合再次运用bbsen-awf算法获得sen-lssvm模型。采用文献中的真实数据构建dxn软测量模型,验证了所提方法的有效性。
为实现上述目的,本发明采用如下的技术方案:
一种基于选择性集成最小二乘支撑向量机的二噁英软测量系统,其特征在于,包括:
基于先验知识预处理模块,用于基于先验知识know对原始输入变量
候选子子模型构建模块,用于构建数量为k×r的基于lssvm的候选子子模型集合,可表示为
候选sen子模型构建模块,用于对具有相同核参数和不同惩罚参数的候选子子模型集合采用bbsen-awf方法构建候选sen子模型集合,其可表示为
sen模型构建模块,用于对候选sen子模型集合再次采用bbsen-awf方法构建最终的sen-lssvm模型,其输入为候选sen子模型的预测输出集合
作为优选,候选子子模型构建模块的处理过程为:
用于lssvm模型构建的候选建模参数可用如下矩阵表示:
其中,
以第jth个建模参数
其中,w是权重系数,b是偏置,olssvm表示优化目标,ζn是第nth样本的预测误差。
采用拉格朗日方法求解上述问题,
其中,β=[β1,…,βn,…,βn]β=[β1,l,βn,l,βn]是拉格朗日算子向量,ζ=[ζ1,…,ζn,…,ζn]ζ=[ζ1,l,ζn,l,ζn]是预测误差向量,
对上述问题求偏导,
采用核参数为
上述问题的求解可改写为如下的线性方程组,
通过求解上述方程组得到β和b,
因此,基于lssvm构建的第jth个候选子子模型可表示为:
为表示的简洁性,上式被重新改写为:
因此,全部候选子子模型的集合可表示为
作为优选,候选sen子模型构建模块的工作过程为:
全部候选子子模型的输出集合可改写为下式:
其中,k和r是候选核参数和惩罚参数的个数,
显然,上式表明候选子子模型与其输出间存在如下的对应关系:
公式(10)表明第kth行的候选子子模型是基于相同的核参数
通过选择性的集成公式(12)中每行的基于不同惩罚参数的候选子子模型可以得到候选sen子模型集合;
以第kth行,即
其中,
第kth个sen子模型的输出采用下式计算:
通过重复上述过程k次,得到基于不同核参数的候选sen子模型集合,其预测输出可表示为
作为优选,sen模型构建模块的工作过程为:
通过上述过程,可得到基于相同核参数和不同惩罚参数的候选sen子模型集合。公式(12)可以重新改写为:
由公式(15)可知,通过对候选sen子模型再次运用bbsen-awf方法可得到最终的sen-lssvm模型,该过程可表示为:
其中,
最终的sen-lssvm软测量fsen(·)可表示为:
二噁英(dxn)是城市固废焚烧(mswi)过程排放的一种剧毒的持续性污染物。因燃烧过程所固有的复杂物理和化学特性导致二噁英的机理模型难以建立。在实际工业过程中,二噁英浓度通常以月或季为周期经耗时一周的离线化验方式得到。针对这些问题,本发明提出了一种基于选择性集成最小二乘支撑向量机(sen-lssvm)的dxn软测量系统。首先,基于先验知识给出数量为k的候选核参数集和数量为r的候选惩罚参数集。接着,采用lssvm算法构建基于这些候选核参数和候选惩罚参数的数量为k×r的候选子子模型集合。然后,采用基于分支定界(bb)和自适应加权(awf)的sen(bbsen-awf)算法对具有相同核参数和不同惩罚参数的候选子子模型进行选择和合并,进而得到数量为k的候选sen子模型集合。最后,对数量为k的候选sen子模型集合再次采用bbsen-awf算法,获得基于sen-lssvm的dxn软测量模型。采用文献中的工业过程真实数据构建的dxn软测量模型验证了所提方法的有效性。
附图说明
图1基于炉排炉的mswi工艺流程;
图2二噁英生成过程的温度特性示意图;
图3基于sen-lssvm软测量策略;
图4候选核参数与rmse间的关系;
图5不同集成尺寸的sen模型与rmse间的关系;
图6不同的lssvm模型的预测结果。
具体实施方式
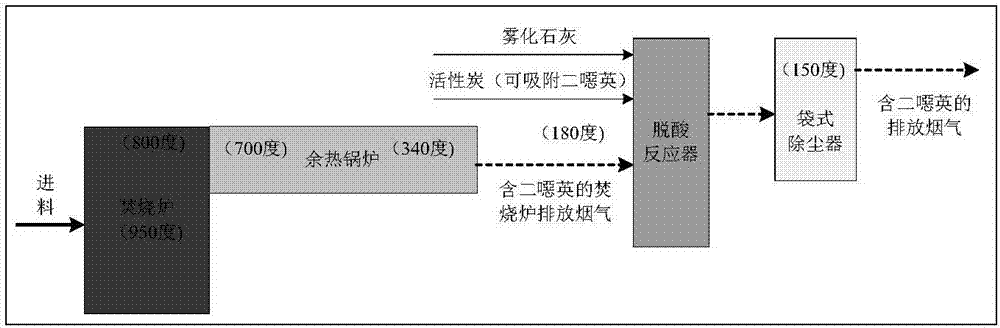
城市垃圾焚烧处理主要由垃圾储运、炉内燃烧、烟气处理、汽轮机发电等4部分组成。基于炉排炉的mswi工艺流程如图1所示。
生活垃圾由专用的垃圾运输车收集后运至卸料车间,倾倒至密封的垃圾池内;池内垃圾由人工操控的液压抓斗自动抓起放入焚烧炉的进料斗内,液压给料机将斗内垃圾推至往复式机械炉排炉;垃圾在焚烧炉内依次经历干燥、点燃、燃烧和烧尽四个阶段,其中:燃尽后的垃圾残渣掉入水冷渣斗内,再由输渣机将其推入炉渣池内,收集后送至填埋场处理;焚烧产生的烟气在炉膛内大于850℃、并停留2s后将垃圾焚烧产生的二噁英分解后由废热锅炉转换为高压蒸汽并推动汽轮机组发电,锅炉出口的待处理烟气进入脱酸反应器进行中和反应,并在反应器入口处添加石灰和活性炭,以去除其中的酸性气体并吸附其中的二噁英和重金属,其中:飞灰进入飞灰储仓,烟气进入布袋除尘器;烟气在袋式除尘器中被除去烟气颗粒物、中和反应物和活性炭吸附物,处理后分为三个部分,其中:尾部飞灰进入灰仓后再运走进行无害化处理,部分烟灰混合物在混合器中加水后重新进入脱酸反应器,尾部烟气则由引风机经烟囱排入大气,排放的尾气中含有hcl、so2、nox、hf和dxn等物质。
基于目前的仪器检测水平,对焚烧过程尾气排放的dxn浓度还无法实现实时的在线连续检测。利用烟气中与dxn存在良好关联关系的其他相对高浓度的化学物质(如单氯苯)作为指示物,通过对指示物的在线检测实现对dxn排放的间接测量是目前研究的关注点之一[18,19,20]。目前采用的方法是对焚烧尾气以月为周期进行人工采样,通过离线化验与分析获得dxn浓度,其成本高、时间长,如不同等级dxn检测机构对每个样本的检测费用均高达几千元到近万元,从采样到化验的时间接近1周。因此,人工采样化验存在滞后大、周期长、成本高等缺点。
本发明所关注的dxn的生成机理非常复杂。目前研究认为除垃圾本身含有的未能完全分解在燃烧后被排放的部分外,主要是在炉内燃烧和烟气处理阶段,具体为:在焚烧炉内燃烧时在某些温度区间中由含氯前体物生成;烟气中的未燃尽物质经重金属等触媒在某些温度区间内生成。dxn生成过程的温度特性示意图如图2所示。
由图2可知,dxn的生成过程与炉内温度、烟气压力、风门开度、烟气温度、风流量等数十个输入变量、过程变量及排放尾气中co、hcl等其它能够实时检测污染物均相关。现场dcs控制系统可以对这些过程变量以毫秒或秒为周期进行采集和存储。显然,这些过程数据中蕴含着与dxn生成和领域专家经验知识等有价值信息。因此,构建dxn的软测量模型是切实可行的。
基于上述分析,本发明所提出的基于sen-lssvm的dnx软测系统,能够实现建模参数的自适应选择。其组成包括基于先验证知识预处理模块、候选子子模型构建模块、候选sen子模型构建模块和sen模型构建模块,如图3所示。
在图3中,know表示用于输入变量预处理和候选建模参数预处理的先验知识;
上述不同模块的功能是:
(1)基于先验知识预处理模块:基于先验知识know对原始输入变量
(2)候选子子模型构建模块:构建数量为k×r的基于lssvm的候选子子模型集合,可表示为
(3)候选sen子模型构建模块:对具有相同核参数和不同惩罚参数的候选子子模型集合采用bbsen-awf方法构建候选sen子模型集合,其可表示为
(3)sen模型构建模块:对候选sen子模型集合再次采用bbsen-awf方法构建最终的sen-lssvm模型,其输入为候选sen子模型的预测输出集合
基于先验知识预处理模块
从mswi工业过程采集的原始输入数据
候选子子模型构建模块
用于lssvm模型构建的候选建模参数可用如下矩阵表示:
其中
以第jth个建模参数
其中w是权重系数,b是偏置,olssvm表示优化目标,ζn是第nth样本的预测误差。
采用拉格朗日方法求解上述问题,
其中β=[β1,…,βn,…,βn]β=[β1,l,βn,l,βn]是拉格朗日算子向量,ζ=[ζ1,…,ζn,…,ζn]ζ=[ζ1,l,ζn,l,ζn]是预测误差向量。
对上述问题求偏导,
采用核参数为
上述问题的求解可改写为如下的线性方程组,
通过求解上述方程组得到β和b。
因此,基于lssvm构建的第jth个候选子子模型可表示为:
为后文表示的简洁性,上式被重新改写为:
因此,全部候选子子模型的集合可表示为
候选sen子模型构建模块
全部候选子子模型的输出集合可改写为下式:
其中k和r是候选核参数和惩罚参数的个数。
显然,上式表明候选子子模型与其输出间存在如下的对应关系:
公式(10)表明第kth行的候选子子模型是基于相同的核参数
这样,通过选择性的集成公式(12)中每行的基于不同惩罚参数的候选子子模型可以得到候选sen子模型集合。以第kth行,即
其中
第kth个sen子模型的输出采用下式计算:
通过重复上述过程k次,得到基于不同核参数的候选sen子模型集合,其预测输出的可表示为
sen模型构建模块
通过上述过程,可得到基于相同核参数和不同惩罚参数的候选sen子模型集合。公式(12)可以重新改写为:
由公式(15)可知,通过对候选sen子模型再次运用bbsen-awf方法可得到最终的sen-lssvm模型,该过程可表示为:
其中
最终的sen-lssvm软测量fsen(·)可表示为:
由上可知,最终的sen-lssvm软测量模型是由内嵌的两层sen组成,其中内层是基于惩罚参数的自适应选择,外层是基于核参数的自适应选择。显然,该方法同时实现了核参数和惩罚参数的自适应的选择,能够符合建模数据的固有特点。
实验研究
数据描述
利用文献[21]中的焚烧数据基于本发明所提出的sen-lssvm算法构建dxn软测量模型。建模数据的输入包括:(1)蒸汽负荷(tone/h);(2)烟气中h2o含量(%);(3)烟道温度(℃);(4)烟气流量(nm3/min);(5)co浓度(ppmv);(6)hcl浓度(ppml);(7)pm浓度(mg/nm3);(6)燃烧室上方温度(℃);其输出是dxn浓度(ng/nm3)。将全部22个样本数量等间隔的分为两部分,分别作为建模数据和测试数据。
实验结果
lssvm模型中的核类型选择为通常采用的径向基函数(rbf),其相应的核参数和惩罚参数的候选集合依据建模经验选择为{0.1,1,100,1000,2000,4000,6000,8000,10000,20000,40000,60000,80000,160000}和{0.1,1,6,12,25,50,100,200,400,800,1600,3200,6400,12800,25600,51200,102400}。这些建模参数具有较宽的取值范围是考虑了本发明所采用dxn建模数据所覆盖的工况范围。为便于后文分析,此处对这些参数进行编码,其取值与编码的对应情况如表1所示。
表1建模参数的候选取值及其编码序
基于上述候选建模参数的取值个数可知,此处首先总共构建了14*17=238个基于lssvm的候选子子模型。然后,采用bbsen-awf方法构建了14个候选sen子模型,其中每个候选sen子模型均基于相同的核参数建立,其统计结果如表2所示。表2中,在取相同核参数的情况下,enall-sub-sub表示集成全部候选子子模型的集成子模型,sen-sub表示选择性的集成部分候选子子模型的sen子模型,best-sub-sub表示具有最佳预测性能的候选子子模型。
表2候选sen子模型的统计结果
表2表明:(1)具有最佳性能best-sub-sub模型对应的建模参数对是(2000,1600)和(4000,3200),其rsme是82.62。可见,无论是核参数和惩罚参数,其取值都比较大,表明了小样本dxn数据的分散特性;(2)enall-sub-sub模型在采用核参数100时具有最佳的预测误差123.5。但该模型在三种模型中的预测性能最差,表明了仅仅是简单的全部集成基于不同惩罚参数的候选子子模型是不合理的;(3)sen-sub模型在核参数取10000时具有最小的预测误差82.21,其相应集成的候选子子模型的编码是10到17,对应的惩罚参数是{800,1600,3200,6400,12800,25600,51200,102400}。但是,与最佳的best-sub-sub模型相比较,其预测误差也只是从82.62减少到了82.21,并没有显著的提升,这表明不同惩罚参数的贡献率是有限的。
候选核参数与rmse间的关系如图4所示,图4表明,从提高dxn软测量模型泛化性能的视角出发,构建基于不同核参数的sen模型是很有必要的。
基于上述过程构建的14个候选sen子模型,再次采用bbsen-awf方法,得到面向dxn的具有不同集成尺寸的sen-lssvm模型。不同集成尺寸的sen模型与rmse间的关系如图5所示,图5表明sen-lssvm模型的预测性能随着集成尺寸的增加而增加,但是当集成尺寸达到5的时候,预测性能的增加幅度比较小;这表明了采用5个不同的核参数可较好的描述dxn的建模数据,这也表明基于多核参数的sen模型的合理性。同时,图5表明具有较小集成尺寸的sen模型的预测性能要弱于最佳的sen子模型,表明多个不同核参数sen子模型间具有较好的互补性。从另外一个视角出发,这应该与建模数据的不同特点相关。更为详细的具有不同集成尺寸sen模型的统计结果如表3所示。
表3不同集成尺寸sen模型的统计结果
表3表明,集成尺寸为5的sen模型,其核参数的集合为{10000,8000,6000,1,0.1},具有比核参数为10000的最佳sen子模型更好的预测性能;其选择的核参数的范围也比较大,如最小值0.1,最大值10000。表3的结果表明,通过进一步的融合更多的基于不同核参数的sen子模型,其预测误差虽然进一步降低,但降低幅度并不高。集成全部候选sen子模型的集成模型(enallsen-sub)的rmse是79.81,其预测误差也较小。由于较大的集成尺寸意味着更为复杂的sen模型结构,因此需要依据实际应用需求在模型性能和模型结构间取得均衡。
不同软测量模型的测试曲线如图6所示,其中“sen”表示最终的sen-lssvm模型,“bestsensub”表示预测性能最佳的sen子模型,“ensensub”表示集成全部候选sen子模型的模型。
比较结果
本发明所提方法与pls、kpls、gasen-bpnn和gasen-lssvm方法进行了比较。此处,为所有的核学习方法采用了相同的rbf核函数。其中,pls的潜在变量(lv)个数采用交叉验证方法确定,kpls在采用与pls相同的lv个数的基础上,采用交叉验证方法确定核参数;基于gasen的方法将种群数量设为20,选择阈值为0.05,其中bpnn隐层神经元的个数取为输入特征的2倍加1个,lssvm的建模参数是选择所有候选子子模型中具有最佳精度的预测模型所采用的建模参数。统计结果如表4所示。
表4不同建模方法的统计结果
表4表明,本发明所提方法具有最佳的平均预测性能。基于gasem-bpnn的方法具有最大的平均预测误差和较大的波动范围,表明该方法所固有的随机性难以对基于小样本数据的dxn建模。基于gasen-lssvm的方法在预测结果的随机性上强于基于bpnn的方法,其预测值误差的最小值小于基于pls/kpls的建模方法;由于gasen-lssvm的建模参数采用的是本发明所提方法中具有最佳预测性能的候选子子模型的核参数和惩罚参数,难以保证该建模方法的最优预测性能。本发明所提方法能够自适应从候选建模参数中选择多个核参数和惩罚参数构建sen模型,提高了dxn模型的预测性能,但其同时也使得模型结构变得较为复杂。下一步需要研究不同集成构造策略的综合应用,以获得简单结构和有效互补机制的dxn软测量模型。
本发明提出了一种新的基于选择性集成(sen)最小二乘支撑向量机(lssvm)算法的二噁英(dxn)软测量系统,首先构建基于先验知识的候选核参数和候选惩罚参数集合,然后采用lssvm算法构建基于这些候选建模参数的dxn候选子子模型集合,再对具有相同核参数不同惩罚参数的候选子子模型采用基于分支定界(bb)和自适应加权(awf)的sen方法(bbsen-awf)获得候选sen子模型集合,最后再采用bbsen-awf算法对这些候选sen子模型进行选择和合并后得到最终的基于sen-lssvm的dxn模型。采用文献中的工业数据验证了本发明所提方法的有效性。本发明的主要贡献是提出了能够进行建模参数自适应选择的基于sen-lssvm的dxn建模算法。参考文献
[1]h.zhou,a.meng,y.q.long,q.h.li,andy.g.zhang,areviewofdioxin-relatedsubstancesduringmunicipalsolidwasteincineration[j].wastemanagement,36:106-118,2015.
[2]z.zhou,b.zhao,h.kojima,s.takeuchi,y.takagi,andn.tateishi,simpleandrapiddeterminationofpcdd/fsinfluegasesfromvariouswasteincineratorsinchinausingdr-ecoscreencells[j].chemosphere,102:24-30,2014.
[3]h.kojima,s.takeuchi,m.iida,s.f.nakayama,andt.shiozaki,asensitive,rapid,andsimpledr-ecoscreenbioassayforthedeterminationofpcdd/fsanddioxin-likepcbsinenvironmentalandfoodsamples[j].environmentalscience&pollutionresearch,22:1-12,2015.
[4]b.r.stanmore,modelingtheformationofpcdd/finsolidwasteincinerators[j].chemosphere,47:565-773,2002.
[5]m.pandelova,d.lenoir,andk.w.schramm,correlationbetweenpcdd/f,pcbandpcbzincoal/wastecombustioninfluenceofvariousinhibitors[j].chemosphere,62:1196-1205,2006.
[6]b.k.gullett,l.oudejans,d.tabor,a.touati,ands.ryan,near-real-timecombustionmonitoringforpcdd/pcdfindicatorsbygc–rempi–tofms[j].environmentalengineeringscience,46:923-928,2012.
[7]w.wang,t.y.chai,andw.yu,modelingcomponentconcentrationsofsodiumaluminatesolutionviahammersteinrecurrentneuralnetworks[j].ieeetransactionsoncontrolsystemstechnology,20:971-982,2012.
[8]j.tang,t.y.chai,w.yu,andl.j.zhao,modelingloadparametersofballmillingrindingprocessbasedonselectiveensemblemultisensorinformation[j].ieeetransactionsonautomationscience&engineering,10:726-740,2013.
[9]m.kano,andk.fujiwara,virtualsensingtechnologyinprocessindustries:trends&challengesrevealedbyrecentindustrialapplications[j].journalofchemicalengineeringofjapan,46:1-17,2013.
[10]j.tang,t.y.chai,w.yuandl.j.zhao,featureextractionandselectionbasedonvibrationspectrumwithapplicationtoestimatetheloadparametersofballmillingrindingprocess[j].controlengineeringpractice,20(10):991-1004,2012.
[11]z.h.zhou,j.wu,andw.tang,ensemblingneuralnetworks:manycouldbebetterthanall[j].artificialintelligence,137(1-2):239-263,2002.
[12]j.tang,t.y.chai,q.m.cong,l.j.zhao,z.liu,andw.yu,modelingmillloadparametersbasedonselectivefusionofmulti-scaleshellvibrationfrequencyspectrum[j].controltheory&application,32(12):1582-1591,2015.
[13]j.tang,t.y.chai,q.m.cong,b.c.yuan,l.j.zhao,z.liu,andw.yu,softsensorapproachformodelingmillloadparametersbasedonemdandselectiveensemblelearningalgorithm[j].actaautomaticasinica,40(9):1853-1866,2014.
[14].tang,w.yu,t.y.chai,z.liu,andx.j.zhou,selectiveensemblemodelingloadparametersofballmillbasedonmulti-scalefrequencyspectralfeaturesandspherecriterion[j].mechanicalsystems&signalprocessing,66-67:485-504,2016.
[15]j.tang,z.liu,j.zhang,z.w.wu,t.y.chai,andw.yu.kernellatentfeatureadaptiveextractionandselectionmethodformulti-componentnon-stationarysignalofindustrialmechanicaldevice[j].neurocomputing,216(c):296-309,2016.
[16]y.lv,j.liu,andt.yang,anovelleastsquaressupportvectormachineensemblemodelfornox,emissionpredictionofacoal-firedboiler[j].energy,55(1):319-329,2013.
[17]c.a.d.a.padilha,d.a.c.barone,anda.d.d.neto,amulti-levelapproachusinggeneticalgorithmsinanensembleofleastsquaressupportvectormachines[j].knowledge-basedsystems,106(c),85-95,2016.
[18]b.k.gullett,l.oudejans,andd.tabor,near-realtimecombustionmonitoringforpcdd/pcdfindicatorsbygc-rempi-tofms[j].environmentalscience&technology,46(2):923-928,2012.
[19]郭颖,陈彤,杨杰,曹轩,陆胜勇,李晓东.基于关联模型的二恶英在线检测研究[j].环境工程学报,2014,8(8):3524-3529.
[20]李阿丹,洪伟,王晶.激光解吸/激光电离-质谱法二恶英及其关联物的在线检测[j].燕山大学学报,2015,39(6):511-515.
[21]n.b.chang,ands.h.huang,statisticalmodellingforthepredictionandcontrolofpcddsandpcdfsemissionsfrommunicipalsolidwasteincinerators[j].wastemanagement&research,13(4):379-400,1995。
- 还没有人留言评论。精彩留言会获得点赞!