超导单磁通量子处理器的算术逻辑单元运算方法和系统与流程
本发明涉及计算机系统中的超导单磁通量子(RSFQ)微处理器领域,特 别涉及一超导单磁通量子处理器的算术逻辑单元运算方法和系统。
背景技术:
当今微处理器和计算机系统主要采用CMOS技术,而现在最好的64位 Intel CPU主频低于4GHz,功耗却达到2W以上。CMOS的制造工艺也正在逼 近物理极限。
因为需要半导体晶体管的最小转换能量来确保可靠性和速度,数据中心和 超级计算机的功耗很难降低。而随着集成电路线宽尺寸接近原子直径,到2021 年后,如果继续缩小半导体集成电路的线宽尺寸,从经济上来说,已经不再可 取。因此,CMOS电路技术面临着前所未有的挑战。
我国的超级计算机天河2号的整机功耗17808千瓦,在搭载水冷散热系统 以后,功耗将达到24兆瓦,无论水冷系统的搭载与否,都是目前TOP500里 功耗最大的。消耗的电费每年达1亿人民币。而现有CMOS技术的功耗已经 接近它的物理极限,集成电路的线宽尺寸已经接近原子直径。因此为了降低功 耗同时提高速度,需要高速低耗的可代替电路技术,而RSFQ(高速单磁通量 子)因具备超高速度和超低功耗成为最有可能的下一代集成电路技术。
因为受到约瑟夫森结集成度的约束,过去的研究工作都是集中在研制8 位RSFQ微处理器。随着制造工艺的发展,制造64位RSFQ微处理器成为可 能,而ALU(算术逻辑单元)是微处理器中最重要的核心部件,它负责执行 算术和逻辑运算,即使最小的微处理器也包含ALU作为计数功能的部件。所 以,本发明对RSFQALU进行了逻辑电路设计。
在选择算术逻辑单元体系结构时,一方面考虑到虽然串行结构处理硬件复 杂度较低,但是在处理64位数据时延迟很大。这就导致了指令执行的吞吐量 过低同时降低了微处理器的性能。另一方面,虽然并行结构处理速度快、吞吐 量大,但其消耗的硬件资源多,就目前的工艺来看还无法实现64位并行算术 逻辑单元。综上所述,本发明采用了串-并体系结构,这是因为它不仅相对于 串行体系结构处理64位数据时的速度更快,而且相对于并行体系结构所消耗 的硬件资源更少。对于串-并体系结构来说,该结构是将操作数分为几串、每 串几位进行处理,就目前所能达到的工艺来说,串-并体系结构对于研制64位 超导RSFQ微处理器是一个可行的方案。
在选取加法器的过程中,主要考虑到加法器扇出和布线复杂度的问题。三 个基本加法器:Brent-Kung加法器、Kogge-Stone加法器和Sklansky加法器中, Brent-Kung加法器的逻辑级数太多,Kogge-Stone加法器的布线复杂,Sklansky 加法器的扇出复杂。但是对于串-并结构来说,最大扇出总是进位反馈回路的 扇出,因此Sklansky加法器扇出大的缺点没有影响。综上所述,本发明采用 了Sklansky加法器进行RSFQALU的逻辑电路设计。
技术实现要素:
为了解决上述技术问题,本发明目的在于提供一种高速低耗的超导单磁通 量子处理器的算术逻辑单元运算方法和系统。
具体地说,本发明公开了一种超导单磁通量子处理器的算术逻辑单元运算 方法,其中包括64位的高速单磁通量子处理器,该高速单磁通量子处理器中 的算术逻辑单元采用16位串-并结构的Sklansky加法器进行运算处理,且该 Sklansky加法器在整个运算处理过程中,将64位操作数分为4串16位操作数 进行运算。
该超导单磁通量子处理器的算术逻辑单元运算方法,其中该运算处理包 括:
步骤1、接收该64位操作数并将其分为4串16位操作数;
步骤2、该Sklansky加法器运算该16位操作数,生成进位信号和PG信 号;
步骤3、判断当前该16位操作数是否为4串中的最后一串,若是,则抛 弃该进位信号,否则将该进位信号反馈给下一串16位操作数,用于运算该下 一串16位操作数;
步骤4、根据该进位信号和该PG信号中的进位传输信号,计算本位和, 并将该本位和输出。
该超导单磁通量子处理器的算术逻辑单元运算方法,其中该步骤2还包 括:根据该运算处理的指令代码,确定要处理的运算类型,并根据该运算类型 调用相应的运算电路,其中该运算类型包括逻辑运算和算术运算。
该超导单磁通量子处理器的算术逻辑单元运算方法,其中该步骤2中还包 括:根据公式Ci+1=Gi:0∨(Pi:0∧Cin)计算各输出位置i的进位值Ci+1,Cin表示 输入进位值,Pi:0代表第0组到第i组的进位传播信号,Gi:0代表第0组到第i 组的进位产生信号。
该超导单磁通量子处理器的算术逻辑单元运算方法,其中该步骤3还包 括:根据公式计算各输出接口的本位和,其中Zi为第i个输出位 置的本位和,Ci为各输出位置i的该进位值,Pi:i表示第i组的进位传输信号。
本发明还提出了一种超导单磁通量子处理器的算术逻辑单元运算系统,其 中包括64位的高速单磁通量子处理器,该高速单磁通量子处理器中的算术逻 辑单元采用16位串-并结构的Sklansky加法器进行运算处理,且该Sklansky 加法器在整个运算处理过程中,将64位操作数分为4串16位操作数进行运算。
该超导单磁通量子处理器的算术逻辑单元运算系统,其中该运算处理包 括:
操作数拆分模块,用于接收该64位操作数并将其分为4串16位操作数;
运算模块,用于调用该Sklansky加法器运算该16位操作数,生成进位信 号和PG信号;
判断模块,用于判断当前该16位操作数是否为4串中的最后一串,若是, 则抛弃该进位信号,否则将该进位信号反馈给下一串16位操作数,用于运算 该下一串16位操作数;
本位和计算模块,用于根据该进位信号和该PG信号中的进位传输信号, 计算本位和,并将该本位和输出。
该超导单磁通量子处理器的算术逻辑单元运算系统,其中该运算模块还包 括:根据该运算处理的指令代码,确定要处理的运算类型,并根据该运算类型 调用相应的运算电路,其中该运算类型包括逻辑运算和算术运算。
该超导单磁通量子处理器的算术逻辑单元运算系统,其中该运算模块中还 包括:根据公式Ci+1=Gi:0∨(Pi:0∧Cin)计算各输出位置i的进位值Ci+1,Cin表 示输入进位值,Pi:0代表第0组到第i组的进位传播信号,Gi:0代表第0组到第 i组的进位产生信号。
本发明还提出了一种容纳超导单磁通量子处理器的算术逻辑单元运算系 统的计算机。
本发明具有的技术进步包括:
1、采用超导RSFQ技术;超导RSFQ技术以其超高速超低耗的优势克服 了CMOS技术低速度高功耗的问题;
2、采用串-并体系结构;目前的工艺还无法实现64位并行体系结构,且 并行结构硬件资源消耗太大,串行体系结构处理数据时的速度太慢,而串-并 体系结构比串行结构速度更快,比并行结构需要的硬件资源更少;
3、采用Sklansky加法器;在串-并体系结构中,最大扇出总是进位反馈回 路的扇出,因此Sklansky加法器扇出大的缺点没有影响,同时又能保证流水 线级数浅且布线相对简单。
因此本发明与现有技术相比,在实现超高速度的同时也保证了超低功耗。 在基于国内外RSFQ大规模集成电路工艺满足64位RSFQ微处理器核心部件 的条件下,对64位RSFQALU进行逻辑设计,为将来设计超高速64位RSFQ 微处理器以及计算机系统奠定基础。
附图说明
图1为串-并结构图;
图2为基于16位串-并结构Sklansky加法器的体系结构图;
图3为基于16位串-并结构Sklansky加法器的RSFQ逻辑电路图;
图4为ALU指令编码图。
具体实施方式
本发明具体来说公开了一种超导单磁通量子处理器的算术逻辑单元运算 方法,其中包括64位的高速单磁通量子处理器,该高速单磁通量子处理器中 的算术逻辑单元采用16位串-并结构的Sklansky加法器进行运算处理,且该Sklansky加法器在整个运算处理过程中,将64位操作数分为4串16位操作数 进行运算。
该超导单磁通量子处理器的算术逻辑单元运算方法,其中该运算处理包 括:
步骤1、接收该64位操作数并将其分为4串16位操作数;
步骤2、该Sklansky加法器运算该16位操作数,生成进位信号和PG信 号;
步骤3、判断当前该16位操作数是否为4串中的最后一串,若是,则抛 弃该进位信号,否则将该进位信号反馈给下一串16位操作数,用于运算该下 一串16位操作数;
步骤4、根据该进位信号和该PG信号中的进位传输信号,计算本位和, 并将该本位和输出。
为让本发明的上述特征和效果能阐述的更明确易懂,下文特举实施例,并 配合说明书附图作详细说明如下。
请参看图1,本发明的ALU(算术逻辑单元)将64位操作数分为4串16 位操作数进行运算,4串16位操作数从最低有效串开始依次输入,然后运算 结果的4串16位也从最低有效串依次输出,4串之间串行,每串内的16位并 行,以实现串-并体系结构,详细来说“串”体现在把一个64位数据从最低16 位开始划分,每16位为一串,直至最高16位,共分成4串;运算时也从最低 16位开始,依次进行运算,直至最高16位,需要进行4次相同的串行运算。 “并”体现在每串内部的16位数据是一次完成该16位数据的全并行运算。请 参考图4,该算术逻辑单元要实现MIPS指令系统中的加法(ADD)、减法 (SUB)、比较操作(set on less than,SLT)、与操作(AND)、或操作(OR)、 异或操作(XOR)、或非操作(NOR)以及操作数是否相等(EQ)等指令。 该算术逻辑单元的逻辑电路包括控制信号电路、操作数取反电路、计算PG信 号电路、ALU操作选择电路即选择进行操作的类型是逻辑运算还是算术运算、 PG进位网络电路、计算进位电路以及计算结果输出电路。需要说明的是,本 发明采用的ALU与普通ALU的区别在于所采用的材料不同,目前的技术都是 基于半导体的,而本次发明是基于超导的,因此本发明ALU须用在超导处理 器上。PG信号代表进位传输信号P和进位产生信号G。
在串-并结构的ALU中,一串最高有效位的进位输出必须作为下一串的最 低有效位的进位输入,所以必须要有一个进位反馈回路。如果使用行波进位加 法器来实现串-并结构的超导单磁通量子ALU,该ALU每一串等待上一串进 位反馈的时间过长,且流水线级数大,导致硬件资源消耗多。如果使用超前进 位加法器来实现串-并结构的超导单磁通量子ALU,它的吞吐量低而且反馈回 路大,从而需要的硬件成本就高。所以,本发明采用了并行前置加法器。
一个基于Kogge-Stone加法器的4位串-并结构的RSFQ加法器已经被研 制出来。但是它的4个反馈信号分为4级流水线,使得超前进位电路很复杂。 因此,本发明采用Sklansky加法器来设计,它是并行前置加法器之一。对于 基于16位串-并结构的ALU来说,最大的扇出都是进位反馈回路的扇出。因 此,Sklansky加法器扇出较大的缺点没有影响。而且,基于Sklansky加法器的 ALU进位反馈信号只有一个,这就使得它的超前进位电路相对简单。同时, 它的流水线级数和基于Kogge-Stone加法器的ALU是相同的,但是布线比基 于Kogge-Stone加法器的ALU简单很多。
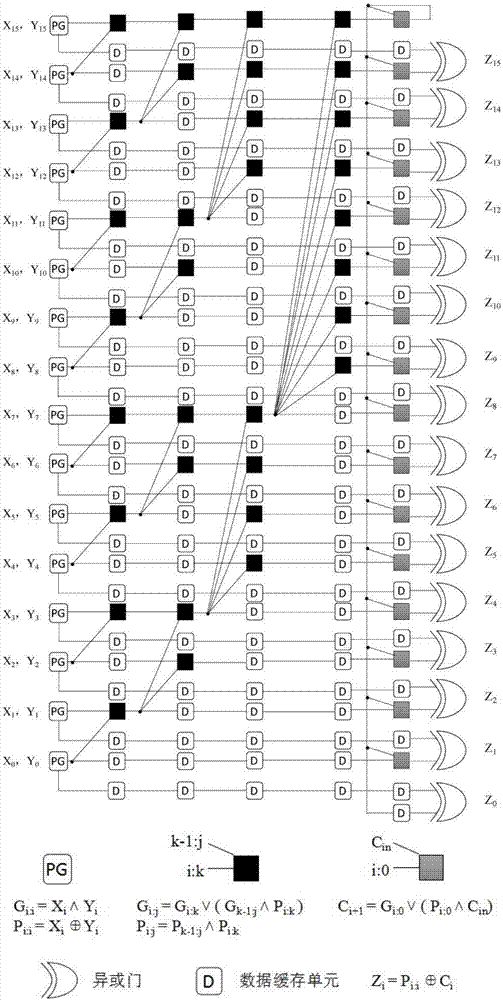
请参看图2,对于16位串-并结构的Sklansky加法器来说,每一个16位 串的计算步骤可以分为以下9步:
(1)每一串16位操作数从加法器的输入接口(即X0-X15和Y0-Y15)输 入,在第一个时钟周期和第二个时钟周期内,分别计算每一个位置i(0-15) 的PG信号(即P0:0,P1:1,P2:2,P3:3,P4:4,P5:5,P6:6,P7:7,P8:8,P9:9,P10:10, P11:11,P12:12,P13:13,P14:14,P15:15,G0:0,G1:1,G2:2,G3:3,G4:4,G5:5,G6:6, G7:7,G8:8,G9:9,G10:10,G11:11,G12:12,G13:13,G14:14,G15:15)。其中,Pi:i=Xi⊕Yi,Gi:i=Xi∧Yi,Pi:i、Gi:i分别表示第i组的进位传输信号P和进位产生信号 G;Xi、Yi分别表示X、Y的第i位,X、Y代表参与运算输入的两个操作数。
(2)在第三个时钟周期内选择相应的控制信号,即确定要处理的运算类 型,并根据该运算类型调用相应的运算电路。Op_ARITH控制信号用来区分算 术运算和逻辑运算。
(3)在第四个时钟周期内,P1:0、P3:2、P5:4、P7:6、P9:8、P11:10、P13:12、P15:14、G1:0、G3:2、G5:4、G7:6、G9:8、G11:10、G13:12、G15:14都被计算出来。其中,G1:0= G1:1∨(P1:1∧G0:0),P1:0=P1:1∧P0:0,其它PG信号的确定可在多位组所 包括的位i…j范围内,对于i≥k>j,是生成进位还是传播进位,递归地定 义为Gi:j=Gi:k∨(Gk-1:j∧Pi:k),Pi:j=Pk-1:j∧Pi:k,举例来说,若多位组中的位 数从第0位到第3位为一组,则i为0,j为3。同时,P0:0、P1:1、P2:2、P3:3、 P4:4、P5:5、P6:6、P7:7、P8:8、P9:9、P10:10、P11:11、P12:12、P13:13、P14:14、P15:15、G0:0、 G2:2、G4:4、G6:6、G8:8、G10:10、G12:12、G14:14都存储在数据缓存单元DFF中, 其中若P或G的下标不相等则代表组间的进位传播或进位产生信号,例如P1:0代表第0组到第1组的进位传播信号,G1:0代表第0组到第1组的进位产生信 号,其他下标以此类推。
(4)在第五个时钟周期内,P2:0、P3:0、P6:4、P7:4、P10:8、P11:8、P14:12、P15:12、 G2:0、G3:0、G6:4、G7:4、G10:8、G11:8、G14:12、G15:12都被计算出来。其中,G2:0= G2:2∨(P2:2∧G1:0),P2:0=P2:2∧P1:0,其它PG信号的计算方法同上述公式。
(5)在第六个时钟周期内,P4:0、P5:0、P6:0、P7:0、P12:8、P13:8、P14:8、P15:8、 G4:0、G5:0、G6:0、G7:0、G12:8、G13:8、G14:8、G15:8都被计算出来。其中,G4:0=G4:4∨(P4:4∧G3:0),P4:0=P4:4∧P3:0,其它PG信号的计算方法同上述公式。
(6)在第七个时钟周期内,P8:0、P9:0、P10:0、P11:0、P12:0、P13:0、P14:0、P15:0、 G8:0、G9:0、G10:0、G11:0、G12:0、G13:0、G14:0、G15:0都被计算出来。其中,G8:0= G8:8∨(P8:8∧G7:0),P8:0=P8:8∧P7:0,其它PG信号的计算方法同上述公式。
(7)在第八个时钟周期内,即进入反馈回路之前,需要通过控制信号 End_bar判断该串是否为4串16位操作数中的最后一串,若是,则不必反馈 进位信号;否则将进位信号反馈给下一串。
(8)在第九个时钟周期内,利用来自前一串的进位信号计算每个输出位 置i(0-15)的进位值(即C0、C1、C2、C3、C4、C5、C6、C7、C8、C9、 C10、C11、C12、C13、C14、C15)。其中,例如C1=G0:0∨(P0:0∧C0), 其它i+1位置的进位计算根据公式Ci+1=Gi:0∨(Pi:0∧Ci),Ci表示第i位的进 位。同时,P0:0、P1:1、P2:2、P3:3、P4:4、P5:5、P6:6、P7:7、P8:8、P9:9、 P10:10、P11:11、P12:12、P13:13、P14:14、P15:15存储在DFF中。C16将作 为下一串C0的反馈给下一串。
(9)最后,在第十个时钟周期内,每一位置i(0-15)的本位和(即Z0、 Z1、Z2、Z3、Z4、Z5、Z6、Z7、Z8、Z9、Z10、Z11、Z12、Z13、Z14、Z15)都被计 算出来。其中,其它位置i的本位和计算根据公式其中Zi为第i个输出接口的本位和,Ci为第i位的进位值。
上述过程即为加法的基本执行步骤。而减法是通过实现的,其中 是对Y进行取反。因此,控制信号Cmpl_Y控制对Yi进行取反的操作,而控 制信号Carry_in实现“+1”的操作。相对于加法而言,减法运算除了进位信 号Carry_in在第一个时钟周期为1之外,其他的都和加法运算相同。进位信号 在第一个时钟周期为1,是因为减法运算需要在最末位(最低位)加1,该ALU 是从最低16位开始计算的,因此需要在第一个周期就把Carry_in为1传进来, 一直传到高位。其中需要注意的是指令的类型(或运算类型)是由在第一个周 期输入的指令代码确定的,并不是在第三个周期才得知,第三个周期只是选择 相应的运算电路去执行这条指令(或这种运算)。
对于SLT运算来说,当且仅当X-Y<0时,它的结果为1。因此SLT运算 必须要执行减法,而且它的运算结果是减法运算结果的最高有效位。对于有符 号的SLT运算来说,它的运算结果就是最后一串的Z15;对于无符号的SLT运 算来说,它的运算结果就是最后一串的C16。输出接口Carry_out用来输出运 算结果C16。
对于EQ运算来说,当且仅当X=Y时,EQ的运算结果为1。该运算结 果可以通过将加法器中每一串所有位置i(0-15)的Gi:i设置为0、Pi:i设置为 来获得执行结果,它的运算结果就是最后一串的C16。在这里需要注 意的是,当X=Y时,所有Pi:i都等于1。
在逻辑运算中,为了选择与运算或者异或运算,该ALU分别提供了控制 信号Op_AND和Op_XOR。对于与运算,可以利用每个位置i(0-15)的Gi:i来实现。对于异或运算,可以利用每个位置i(0-15)的Pi:i来实现。对于或运 算,可以通过来获得,并且该ALU采用了融合缓 冲(CB)逻辑门来实现∨运算,这样就减少了该ALU的流水线级数。对于或 非运算,可以通过进行计算,因此,这里就需要控制信号Cmpl_X 对Xi进行取反。为了将逻辑运算结果传输到输出接口并且减少数据延迟单元(DFF)和布线的规模,本次设计直接将每个位置i(0-15)的Pi:i逻辑运算结 果传给Zi。
一个64位的操作数从第一个时钟周期到第四个时钟周期从最低有效串依 次输入。控制信号End_bar在第四个时钟周期为0,第一个到第三个时钟周期 均为1。Carry_in信号在第一个时钟周期输入,如果执行“+1”操作,则Carry_in 信号在第一个周期为1。其它5个控制信号,即Op_ARITH、Op_AND、Op_XOR、 Cmpl_X和Cmpl_Y的值在四个时钟周期内保持不变。
该ALU的流水线级数为10,这是因为本次设计采用了CB代替或门来执 行或运算,减少了时钟逻辑门的数量,从而在一定程度上降低了流水线级数, 同时也降低了硬件资源的消耗。该ALU的前一个运算操作的最高有效串输入 一结束就可以开始下一个ALU操作。也就是说,每4个时钟周期,该ALU 就能执行一次64位运算。运算结果的第一串也就是最低有效串在第十个时钟 周期后输出,运算结果的最后一串在第十三个周期后输出。
该ALU的最大扇出即进位反馈回路的扇出是17。对于本次设计所采用的 反馈回路而言,所有基于串-并结构ALU的最大扇出都是进位反馈回路的扇 出,也就是说所有16位串-并ALU的最大扇出都是17。为了最小化进位反馈 回路的延迟,在进入反馈回路之前先通过控制信号End_bar判断该串是否为最 后一串,同时根据进位信号Carry_in判断是否执行“+1”操作。同样,为了 最小化进位反馈回路的延迟,进位信号被分为两个方向:一个立即进入进位反 馈回路的与门,另一个反馈给下一串的每一位用来计算Z0-Z15和Carry_out。
请参考图4,该ALU包含基本的RSFQ逻辑门(与门、异或门和数据缓 存单元DFF)以及AISTADP2[26]RSFQ单元库的布线器件(约瑟夫森传输线、 无源传输线、分支器和融合缓冲CB)。其中,该ALU一共包含147个与门, 64个异或门,258个分支器,263个数据缓存单元(DFF)以及66个融合缓冲 (CB)。该ALU的约瑟夫森结一共为5723个(其中不包含约瑟夫森传输线、 无源传输线等)。
以下为与上述方法实施例对应的系统实施例,本实施系统可与上述实施方 式互相配合实施。上述施方式中提到的相关技术细节在本实施系统中依然有 效,为了减少重复,这里不再赘述。相应地,本实施系统中提到的相关技术细 节也可应用在上述实施方式中。
本发明还提出了一种超导单磁通量子处理器的算术逻辑单元运算系统,其 中包括64位的高速单磁通量子处理器,该高速单磁通量子处理器中的算术逻 辑单元采用16位串-并结构的Sklansky加法器进行运算处理,且该Sklansky 加法器在整个运算处理过程中,将64位操作数分为4串16位操作数进行运算。
该超导单磁通量子处理器的算术逻辑单元运算系统,其中该运算处理包 括:
操作数拆分模块,用于接收该64位操作数并将其分为4串16位操作数;
运算模块,用于调用该Sklansky加法器运算该16位操作数,生成进位信 号和PG信号;
判断模块,用于判断当前该16位操作数是否为4串中的最后一串,若是, 则抛弃该进位信号,否则将该进位信号反馈给下一串16位操作数,用于运算 该下一串16位操作数;
本位和计算模块,用于根据该进位信号和该PG信号中的进位传输信号, 计算本位和,并将该本位和输出。
该超导单磁通量子处理器的算术逻辑单元运算系统,其中该运算模块还包 括:根据该运算处理的指令代码,确定要处理的运算类型,并根据该运算类型 调用相应的运算电路,其中该运算类型包括逻辑运算和算术运算。
该超导单磁通量子处理器的算术逻辑单元运算系统,其中该运算模块中还 包括:根据公式Ci+1=Gi:0∨(Pi:0∧Cin)计算各输出位置i的进位值Ci+1,Cin表 示输入进位值,Pi:0代表第0组到第i组的进位传播信号,Gi:0代表第0组到第 i组的进位产生信号。
本发明还提出了一种容纳超导单磁通量子处理器的算术逻辑单元运算系 统的计算机。
虽然本发明以上述实施例公开,但具体实施例仅用以解释本发明,并不用 于限定本发明,任何本技术领域技术人员,在不脱离本发明的构思和范围内, 可作一些的变更和完善,故本发明的权利保护范围以权利要求书为准。
- 还没有人留言评论。精彩留言会获得点赞!