一种监控网页的方法、服务器及计算机可读存储介质与流程
本发明涉及计算机技术领域,特别是涉及一种监测网页的方法、服务器及计算机可读存储介质。
背景技术:
近年来,随着互联网的普及,网站已成为政府、学校、企业等组织机构信息发布和传播的重要途径,网站安全也成为网络安全的重要领域。cncert监测发现,每年境内有数万个网站被篡改。
目前网页篡改检测方式主要有基于页面hash值对比、基于页面链接数量对比、基于页面文本相似度对比等算法,这些算法都在一定程度上实现了对网页篡改情况的监测,但都暴露出一些明显的问题,比如:误报率高,不能有效反映网页真实篡改情况,也就是说,现有对网页监测的方法的准确率不高。
技术实现要素:
本发明提供了一种监测网页的方法、服务器及计算机可读存储介质,以解决现有技术中对网页监测的方法的准确率不高的问题。
一方面,本发明提供了一种监测网页的方法,该方法包括:将待检测的网页抽取为网页内容和网页结构;计算网页内容相似度,并计算网页结构相似度,对所述网页内容的相似度和所述网页结构的相似度进行融合,根据融合后的相似度值判断所述网页是否发生篡改。
进一步地,所述将待检测的网页抽取为网页内容和网页结构之前,还包括:
对所述网页的页面富文本进行hash,并与基线库中网页的hash值进行对比;
如果hash值未发生变化,则确定页面未发生篡改;
如果hash值发现变化,则将待检测的网页抽取为网页内容和网页结构。
进一步地,所述计算网页内容相似度,具体包括:
提取基线库中所述网页的页面内容与当前网页的页面内容进行对比,基于余弦相似度算法计算所述网页的页面内容相似度。
进一步地,所述计算网页结构相似度,具体包括:
抽取基线库中所述网页的页面结构与当前网页的页面结构,基于页面结构,分别获取页面结构中每个叶子节点的xpath和对应层次深度,并分别对每个层次深度设置不同的权重,计算得到页面结构相似度。
进一步地,所述分别对每个层次深度设置不同的权重,具体包括:
分别对每个层次深度设置不同的权重,且深度越小设置的权重越小。
进一步地,基于页面结构,分别获取页面结构中每个叶子节点的xpath和对应层次深度,并分别对每个层次深度设置不同的权重,计算得到页面结构相似度,具体包括:
遍历基线库中页面树形结构封装为原始节点map(xpath,depth),其中,xpath为叶子节点在整体树结构中的xpath值,depth为叶子节点所在的深度层次;将原始节点map结构转换为mapa(nonumxpath,xpathnode),其中,nonumberxpath为原始节点xpath清除数字下标后的值,xpathnode为相同nonumxpath对应的重复次数和深度对应的数据结构;
并将当前页面的原始节点结构转换为mapb(nonumxpath,xpathnode);
结合不同层次深度的权重,分别计算综合权重值suma=mapa.depth.weight*count和sumb=mapb.depth.weight*count,并计算分母值sumvalue=suma+sumb;
遍历mapa,根据mapa的key:nonumxpath,查找mapb中是否存在对应项;
如果存在,计算mapa.xpathnode.count和mapb.xpathnode.count差值的绝对值,并赋值给mapb.xpathnode.count,删除mapa的对应项;
如果不存在,则不作处理;
遍历完成后得到newmapa和newmapb,计算分子值offsetsumvalue=newmapa-newmapb;
根据公式pagestructuresim=1-offsetsumvalue/sumvalue计算得到页面结构相似度值。
进一步地,对所述网页内容的相似度和所述网页结构的相似度进行融合,根据融合后的相似度值判断所述网页是否发生篡改,具体包括:
根据相似度值=pagecontentsim*a+pagestructuresim*b,其中pagecontentsim为页面内容相似度值,pagestructuresim为页面结构相似度值,a、b分别为预设的权重值;
根据所述相似度值,结合判定篡改策略,得出页面是否篡改的结果。
进一步地,根据融合后的相似度值判断网页是否被篡改,具体包括:
根据融合后的相似度值,结合浏览器渲染机制和网页特性计算出基于富文本的网页相似度值,判断网页是否被篡改。
另一方面,本发明还提供一种服务器,所述服务器包括处理器、存储器及通信总线;
所述通信总线用于实现处理器和存储器之间的连接通信;
所述处理器用于执行存储器中存储的计算机指令,以实现上述任一种所述的监控网页的方法。
再一方面,本发明还提供一种计算机可读存储介质,计算机可读存储介质存储有一个或者多个程序,一个或者多个程序可被一个或者多个处理器执行,以实现本发明提供的任一种所述的监控网页的方法。
本发明有益效果如下:
本发明立足于网页内容的富文本特性以及浏览器的渲染可视化机制,从根本上将网页内容理解为两个相互独立的部分:网页内容和网页结构,将待检测的网页内容抽取为网页内容和网页结构两部分,并根据网页内容相似度算法和网页结构相似度算法分别计算出两个不同维度的相似度,并根据该相似度值做出网页是否被篡改的判定,提高网页篡改检测的准确性,有效降低检测的误报率。
附图说明
图1是本发明实施例的一种监控网页的方法的流程示意图;
图2是本发明实施例的另一种监控网页的方法的流程示意图;
图3是本发明实施例的计算网页结构相似的方法的流程示意图;
图4是本发明实施例的终端的结构示意图。
具体实施方式
为了解决现有技术中对网页监测的方法的准确率不高的问题,本发明提供了一种监测网页的方法,本发明立足于网页内容的富文本特性以及浏览器的渲染可视化机制,从根本上将网页内容理解为两个相互独立的部分:网页内容和网页结构,将待检测的网页内容抽取为网页内容和网页结构两部分,并根据网页内容相似度算法和网页结构相似度算法分别计算出两个不同维度的相似度,并根据该相似度值做出网页是否被篡改的判定,提高网页篡改检测的准确性,有效降低检测的误报率。以下结合附图以及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不限定本发明。
本发明实施例提供了一种监控网页的方法,参见图1,该方法包括:
s101、将待检测的网页抽取为网页内容和网页结构;
s102、计算网页内容相似度,并计算网页结构相似度;
s103、对所述网页内容的相似度和所述网页结构的相似度进行融合,并根据融合后的相似度值判断所述网页是否发生篡改。
也就是说,本发明立足于网页内容的富文本特性以及浏览器的渲染可视化机制,从根本上将网页内容理解为两个相互独立的部分:网页内容和网页结构,将待检测的网页内容抽取为网页内容和网页结构两部分,并根据网页内容相似度算法和网页结构相似度算法分别计算出两个不同维度的相似度,并根据该相似度值做出网页是否被篡改的判定,提高网页篡改检测的准确性,有效降低检测的误报率。
具体实施时,本发明实施例所述将待检测的网页抽取为网页内容和网页结构之前,还包括:对所述网页的页面富文本进行hash,并与基线库中网页的hash值进行对比;如果hash值未发生变化,则确定页面未发生篡改;如果hash值发现变化,则将待检测的网页抽取为网页内容和网页结构。
具体来说,本发明实施例首先对页面富文本进行hash,并与基线库中的hash值进行对比,如果hash值未发生变化表示页面整体未发生任何变化,直接判定页面未发生篡改,结束本次检测;如果hash值发现变化,执行步骤s101。
具体实施时,本发明实施例中,所述计算网页内容相似度,具体包括:提取基线库中所述网页的页面内容与当前网页的页面内容进行对比,基于余弦相似度算法计算所述网页的页面内容相似度。
所述计算网页结构相似度,具体包括:抽取基线库中所述网页的页面结构与当前网页的页面结构,基于页面结构,分别获取页面结构中每个叶子节点的xpath和对应层次深度,并分别对每个层次深度设置不同的权重,计算得到页面结构相似度。
并且,本发明实施例需分别对每个层次深度设置不同的权重,且深度越小设置的权重越小。
进一步地,本发明实施例所述基于页面结构,分别获取页面结构中每个叶子节点的xpath和对应层次深度,并分别对每个层次深度设置不同的权重,计算得到页面结构相似度,具体包括:
遍历基线库中页面树形结构封装为原始节点map(xpath,depth),其中,xpath为叶子节点在整体树结构中的xpath值,depth为叶子节点所在的深度层次;将原始节点map结构转换为mapa(nonumxpath,xpathnode),其中,nonumberxpath为原始节点xpath清除数字下标后的值,xpathnode为相同nonumxpath对应的重复次数和深度对应的数据结构;
并将当前页面的原始节点结构转换为mapb(nonumxpath,xpathnode);
结合不同层次深度的权重,分别计算综合权重值suma=mapa.depth.weight*count和sumb=mapb.depth.weight*count,并计算分母值sumvalue=suma+sumb;
遍历mapa,根据mapa的key:nonumxpath,查找mapb中是否存在对应项;
如果存在,计算mapa.xpathnode.count和mapb.xpathnode.count差值的绝对值,并赋值给mapb.xpathnode.count,删除mapa的对应项;
如果不存在,则不作处理;
遍历完成后得到newmapa和newmapb,计算分子值offsetsumvalue=newmapa-newmapb;
根据公式pagestructuresim=1-offsetsumvalue/sumvalue计算得到页面结构相似度值。
具体实施时,本发明实施例所述对所述网页内容的相似度和所述网页结构的相似度进行融合,根据融合后的相似度值判断所述网页是否发生篡改,具体包括:根据相似度值=pagecontentsim*a+pagestructuresim*b,其中pagecontentsim为页面内容相似度值,pagestructuresim为页面结构相似度值,a、b分别为预设的权重值;根据所述相似度值,结合判定篡改策略,得出页面是否篡改的结果。
具体实施时,本发明实施例是根据融合后的相似度值,结合浏览器渲染机制和网页特性计算出基于富文本的网页相似度值,判断网页是否被篡改。
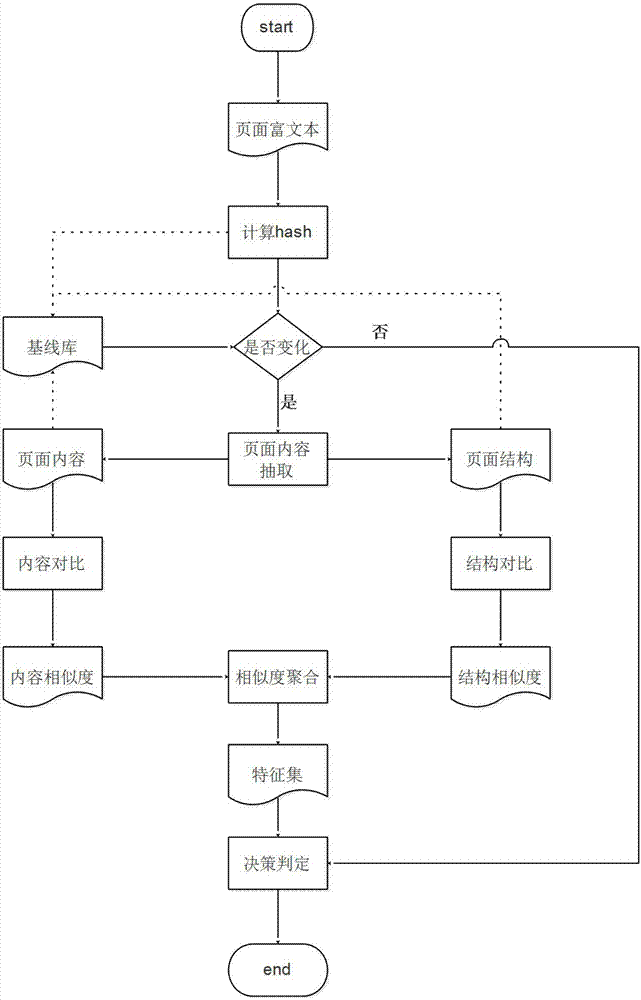
图2是本发明实施例的另一种监控网页的方法的流程示意图,下面将结合图2对本发明所述的方法进行详细的解释和说明:
1.首先对页面富文本进行hash,并与基线库中的hash值进行对比,如果hash值未发生变化表示页面整体未发生任何变化,直接判定页面未发生篡改,结束本次检测;如果hash值发现变化,执行步骤2;
2.基于html的解析工具jsoup和xml解析工具jdom,从富文本中分别抽取出页面内容和页面结构,其中页面内容包括:html显示文本和url链接文本,页面结构包括:html标签的树形结构,不包含标签属性信息。抽取完成后分别将页面内容和页面结构数据执行步骤3和步骤4;
3.提取基线库中页面内容与当前页面内容进行对比,页面内容相似度对比基于余弦相似度算法。余弦相似度算法是测量两个文本之间角度的余弦的内积空间的两个非零向量之间的相似度的量度,其结果在[0,1]中整齐地界定,适用于页面内容的文本相似度对比。对比的结果为[0—1]之间的相似度值,执行步骤5;
4.抽取基线库中页面结构与当前页面结构进行对比,页面结构相似度算法基于页面结构的富文本特性,获取树形页面结构中每个叶子节点的xpath和对应层次深度,如:xpath为html/body/div[2],层次深度为3,每个层次深度可定义不同的权重,一般说来深度越小对应的权重越小,体现在页面渲染上对整体结构的影响也较大。基于历史页面结构数据和当前页面结构数据,计算页面结构的相似度算法的整体步骤如图3所示,具体包括:
(1)遍历页面树形结构封装为节点原始map,map结构为map(xpath,depth),其中xpath代表叶子节点在整体树结构中的xpath值,depth代表叶子节点所在的深度层次;
(2)将原始map结构转换为map(nonumxpath,xpathnode),其中nonumberxpath代表节点xpath清除数字下标后的值:如html/body/div[2]→html/body/div[];xpathnode结构为{depth:int,count:int},count代表相同nonumxpath对应的重复次数,获取基线库中该页面的map(nonumxpath,xpathnode)简称mapa,生成新的map(nonumxpath,xpathnode)简称mapb,作为步骤(3)、步骤(4)的输入;
(3)计算分母:输入mapa和mapb,并结合不同层次深度的权重,分别遍历mapa和mapb根据公式:mapa.depth.weight*count,计算出整个对应map的综合权重值:suma,sumb,定义sumvaule=suma+sumb,表示两个map整体的权重值,即为结果值。将该结果值即为分母值;
(4)计算分子:输入mapa和mapb,遍历mapa,根据mapa的key:nonumxpath查找mapb中是否存在对应项,如果存在,计算mapa.xpathnode.count和mapb.xpathnode.count差值的绝对值,赋值给mapb.xpathnode.count并删除mapa的对应项;如果不存在,不作处理。遍历完成后得到两个新的map:newmapa和newmapb。将newmapa和newmapb作为输入,执行步骤(3)得到结果值定义为offsetsumvalue,即为分子;
(5)执行公式:1-offsetsumvalue/sumvalue结果即为页面结构相似度值。
5.相似度聚合:根据步骤3和步骤4中得到的页面内容相似度和页面结构相似度,结合权重策略也即结构和内容在页面中的权重值,执行公式页面相似度计算公式,如:pagecontentsim*0.1+pagestructuresim*0.9,其中pagecontentsim代表页面内容相似度值,pagestructuresim代表页面结构相似度值,0.1、0.9代表对应的权重,可根据实际情况自行定义该策略值,根据页面相似度值,结合判定篡改策略,得出页面是否篡改的结果。
具体来说,本发明实施例步骤5具体是,根据融合后的相似度值,结合浏览器渲染机制和网页特性计算出基于富文本的网页相似度值,判断网页是否被篡改。
总体来说,本发明实施例通过将页面内容以富文本化的方式从内容和结构两个维度进行分析,有效的提升了检测的准确性,降低了误报率。同时,结合网页的hash进行过滤,减少了无用检测的执行,提升了对应系统的检测能力。
相应的,如图4所示,本发明的实施例还提供一种服务器,包括:处理器,存储器以及通信总线;
通信总线用于实现处理器和存储器之间的连接通信;
存储器用于存储计算机指令,处理器用于运行存储器存储的计算机指令,以实现方法实施例中的任一种对网页监测的方法的步骤,并达到相应的技术效果,具体可参见方法实施例以及公共交通设备实施例进行理解,在此不再进行详细赘述。
相应的,本发明的实施例还提供一种计算机可读存储介质,计算机可读存储介质存储有一个或者多个程序,一个或者多个程序可被一个或者多个处理器执行,以实现前述实施例提供的任一种对网页监测的方法,因此也能实现相应的技术效果,具体可参见方法实施例以及公共交通设备实施例进行理解,在此不再进行详细赘述。
尽管为示例目的,已经公开了本发明的优选实施例,本领域的技术人员将意识到各种改进、增加和取代也是可能的,因此,本发明的范围应当不限于上述实施例。
- 还没有人留言评论。精彩留言会获得点赞!