一种多标签图像识别方法及装置与流程
本发明涉及计算机视觉、模式识别领域,特别是涉及一种识别出多标签图像中各个物体的标签的多标签图像识别方法及装置。
背景技术:
图像分类作为一个计算机视觉领域的基础问题在研究领域中得到了日益增加的关注。因为深度卷积神经网络(CNNs)的巨大成功,图像分类获得了显著的进步。但是现有的方法大多只关注只包含单个物体的单标签图像分类。相比,多标签图像识别更具实际价值,因为现实世界中的图像一般具有图像标签,而且对这些丰富的语义信息进行建模有助于高级别图像理解任务。
目前,对于多标签图像识别,一种直接的方法就是扩展卷积神经网络到多标签图像识别任务:通过微调已经在单标签数据集上进行预训练的网络来为多标签识别任务提取整张图片的特征。尽管这个方法是可端到端训练,但因为多标签图像具有多个区域、大小、占比和类别,这个基于整张图像特征表达训练的分类器往往不能在多标签图像中泛化。
另外一种替代的方法是引入物体候选区域,这些候选区域包含图像中所有可能的前景物体,然后从这些候选区域中提取特征并融合这些局部信息以用于多标签图像识别。尽管相比整张图片的特征提取,该方法有显著性的改进,但仍旧有许多瑕疵:首先,该方法需要提取几百个候选区域来达到较高的查全率,但是把这些候选区域送入卷积神经网络进行分类很耗时;其次,一张照片经常只包含几个物体,大多数候选区域要么提供了非常粗略的信息,要么往往都指向同一个物体,因此在这种方法中,多余的计算量和次优的性能不可避免,特别是在复杂的情况下;再者,该方法经常简化各个前景物体的全局依赖性,导致无法捕获图片中正确的标签。
技术实现要素:
为克服上述现有技术存在的不足,本发明之目的在于提供一种多标签图像识别方法及装置,以通过将循环注意力机制和增强学习相结合的方法应用到多标签图像的识别中,提高了多标签图像识别的计算效率和分类精度。
为达上述及其它目的,本发明提出一种多标签图像识别方法,包括如下步骤:
步骤S1,获取多标签图像,提取图片特征,获得所述多标签图像的特征图;
步骤S2,于所述特征图上进行剪切获得区域特征,多次调用已训练好的循环注意感知模块进行处理,以获得所有区域的标签分数;
步骤S3,融合每一次循环注意感知模块得到的各区域的标签分数,获得最终的标签分布,输出最终结果。
进一步地,所述循环注意感知模块包括长短时记忆网络和全连接网络,其输入为截取的各个特征区域和上一次运行该模块得到的隐藏状态,输出为各个特征区域的分类向量以及预测的下一次运行最佳位置。
进一步地,步骤S2包括:
在特征图上截取不同形状、不同尺度的区域,并把该些区域缩放到统一尺度;
于该些区域特征提取后,利用长短时记忆网络将之前运行的隐藏态以及该些区域特征作为输入,输出为每个区域的分类分数和搜索到的下一次运行的最优位置,该过程不断重复直到达到最大运行次数,获得各区域的标签分数。
进一步地,于步骤S3中,对于每一次循环注意感知模块得到的各区域的标签分数的融合,使用种类最大池化方法来得到最终的结果。
进一步地,于步骤S1之前,还包括如下步骤:
步骤S0,获取多标签图像,通过提取特征获得所述多标签图像的特征图,设计循环注意感知模块,根据所述特征图多次调用循环注意感知模块进行训练。
进一步地,步骤S0包括:
获取多标签图像,利用深度卷积神经网络提取图片特征,获得该多标签图像的特征图;
在所述特征图上截取不同形状、不同尺度的区域,并把该些区域缩放到统一尺度;
设计该循环注意感知模块;
多次调用循环注意感知模块,使得模型能考虑图片的各个部分和全局信息,以此进行训练而调整整个模型的参数。
进一步地,所述循环注意感知模块每次运行时预测当前各个区域的标签分数和搜索为下一次运行搜索最相关的区域,在每一次运行中,它给出当前值得注意的区域预测标签分数然后根据当前状态预测下一次运行的最优位置,这个过程不断重复直到达到最大运行次数,最后,所有区域的标签分数通过融合得到最终的标签分布。
进一步地,于训练过程中,根据最终融合的结果定义一延迟奖励函数,并指导循环注意感知模块的训练过程。
进一步地,于训练过程中,设计分类损失函数,利用所述分类损失函数与延迟奖励函数指导循环注意感知模块的训练过程。
为达到上述目的,本发明还提供一种多标签图像识别装置,包括:
特征提取单元,用于获取多标签图像,提取图片特征,获得该多标签图像的特征图;
识别处理单元,于所述特征图上进行剪切获得区域特征,多次调用已训练好的循环注意感知模块进行处理,以获得所有区域的标签分数;
融合单元,用于融合每一次循环注意感知模块得到的各区域的标签分数,获得最终的标签分布,输出最终结果。
与现有技术相比,本发明一种多标签图像识别方法及装置通过把循环注意力机制和增强学习相结合的方法应用到通用多标签分类任务中,相比于最近的基于假设候选区域的多标签识别方法,本发明不仅拥有更好的计算效率和更高的分类精度,而且提供了一种仅仅基于图片级别标签的语义感知物体寻找机制。
附图说明
图1为本发明一种多标签图像识别方法的步骤流程图;
图2为本发明一种多标签图像识别装置的系统架构图;
图3为本发明具体实施例的网络架构图。
具体实施方式
以下通过特定的具体实例并结合附图说明本发明的实施方式,本领域技术人员可由本说明书所揭示的内容轻易地了解本发明的其它优点与功效。本发明亦可通过其它不同的具体实例加以施行或应用,本说明书中的各项细节亦可基于不同观点与应用,在不背离本发明的精神下进行各种修饰与变更。
图1为本发明一种多标签图像识别方法的步骤流程图。如图1所示,本发明一种多标签图像识别方法,包括如下步骤:
步骤S1,获取多标签图像,提取图片特征,获得该多标签图像的特征图。
在本发明具体实施例中,利用深度卷积神经网络提取图片特征,具体地说,获取多标签图像,将该图像缩放到W×H,送入深度卷积神经网络,该深度卷积神经网络则会通过堆叠多个卷积层来产生特征图fI∈RC×W′×K′。
步骤S2,于所述特征图上进行剪切获得区域特征,多次调用已训练好的循环注意感知模块进行处理,以获得所有区域的标签分数。在本发明具体实施例中,该循环注意感知模块包括长短时记忆网络和全连接网络,该模块输入为截取的各个特征区域和上一次运行该模块得到的隐藏状态,输出为各个特征区域的分类向量以及预测的下一次运行最佳位置,也就是说,循环注意感知模块每次运行时都会预测当前各个区域的标签分数和搜索为下一次运行搜索最相关的区域,即给出当前值得注意的区域预测标签分数并根据当前状态预测下一次运行的最优位置,这个过程不断重复直到达到最大运行次数。具体地,步骤S2进一步包括:
步骤S200,在特征图上截取不同形状、不同尺度的区域,并把该些区域缩放到统一尺度。
具体地说,该循环注意感知模块在第t次运行时,该循环注意感知模块首先接受之前运行时计算好的位置lt并基于位置lt提取区域信息。在之前的方法中,仅仅是提取以lt为中心的方框区域的特征,然而,一般物体在形状和尺度上会有各种变化,因此简单地提取方框区域信息很难覆盖这些物体,因此本发明以lt为中心获取k个不同尺度区域的特征:
其中表示以fI为中心剪切不同大小和形状的区域Rtr,然后进行双线性插值把该些剪切的特征图缩放到同样的大小ftr。以前的方法是在原输入图像上进行剪切然后利用卷积神经网络重复性地对每个区域进行特征提取,这样导致高的计算负担。本发明提出的方法则是在特征图上进行剪切操作,可有效提高效率。
步骤S201,于该些区域特征提取后,利用长短时记忆网络将之前运行的隐藏态以及该些区域特征作为输入,输出为每个区域的分类分数和搜索到的下一次运行的最优位置,该过程不断重复直到达到最大运行次数,获得各区域的标签分数。获得公式表达为:
{at1,at2,...,atk,lt+1}=Tπ(ft1,ft2,...,ftk,ht-1;θ)
其中Tπ(·)代表循环注意感知模块,θ代表网络参数,atr是区域Rtr预测出来的标签分值向量。
这里需说明的是,对于初始化的区域设置成整张图片,所以R0只有一个区域,其输出只是用来决定下次运行时的位置l1。
步骤S3,融合每一次循环注意感知模块得到的各区域的标签分数,获得最终的标签分布,输出最终结果。在本发明具体实施例中,采用种类最大池化方法对每一次循环注意感知模块得到的各区域的标签分数进行融合,具体地说,循环注意感知模块运行T+1次时将产生T×k个标签分数向量,也就是{atr|t=1,2,...,T;r=1,2,...,k},其中是区域Rtr的C个种类标签的分数向量,使用种类最大池化方法来得到最终的结果a={a0,a1,...,aC-1},具体为挑出各个区域的最大值,公式表达为:
优选地,于步骤S1之前,还包括如下步骤:
步骤S0,获取多标签图像,通过提取特征获得所述多标签图像的特征图,设计循环注意感知模块,根据所述特征图多次调用循环注意感知模块,并通过分类损失函数和延迟奖励函数训练循环注意感知模块。具体地,步骤S0进一步包括:
步骤S001,获取多标签图像,利用深度卷积神经网络提取图片特征,获得该多标签图像的特征图。由于该步骤与步骤S1的步骤相同,在此不予赘述。
步骤S002,在所述特征图上截取不同形状、不同尺度的区域,并把该些区域缩放到统一尺度,由于该步骤与步骤S200相同,在此不予赘述。
步骤S003,设计该循环注意感知模块,该循环注意感知模块包括长短时记忆网络和全连接网络,其输入为截取的缩放到统一尺度的各个区域特征以及上一次运行该模块得到的隐藏状态,输出为各个特征区域的分类向量以及预测的下一次运行最佳位置
步骤S004,多次调用循环注意感知模块,使得模型能考虑图片的各个部分和全局信息,以此进行训练而调整整个模型的参数,使识别有更好的效果。具体地说,循环注意感知模块每次运行时都会预测当前各个区域的标签分数和搜索为下一次运行搜索最相关的区域,在每一次运行中,它给出当前值得注意的区域预测标签分数然后根据当前状态预测下一次运行的最优位置,这个过程不断重复直到达到最大运行次数,最后,所有区域的标签分数通过融合得到最终的标签分布。
优选地,于步骤S004中,还包括如下步骤:
于训练过程中,根据最终融合的结果定义一延迟奖励函数,并指导循环注意感知模块的训练过程。
具体地说,在循环注意感知模块每一次运行做出动作后,模块更新状态并得到一个奖励信号。对于多标签图像识别任务,因为每一个区域与一个语义标签相对应,需要融合各个区域的预测来计算奖励,因此,本发明根据最终融合的结果定义一个延迟奖励赋予机制,对于有n个正确标签的样本,它的标签集是计算预测的分数,抽取前n个最大的分数,到预测集是在第t次运行时,奖励定义为
其中|·|表示集合的数目。本发明的目标是最大化折扣奖励,因此,最终的延迟奖励函数如下:
其中γ是折扣因子。在实验中,γ设置为1,总体的回报为R=γT,在本发明具体实施例中,可利用延迟奖励函数通过类似于梯度下降的方法调整整个模块的参数权重。
优选地,于步骤S004中,还包括如下步骤
于训练过程中,设计分类损失函数,利用分类损失函数与延迟奖励函数指导循环注意感知模块的学习。
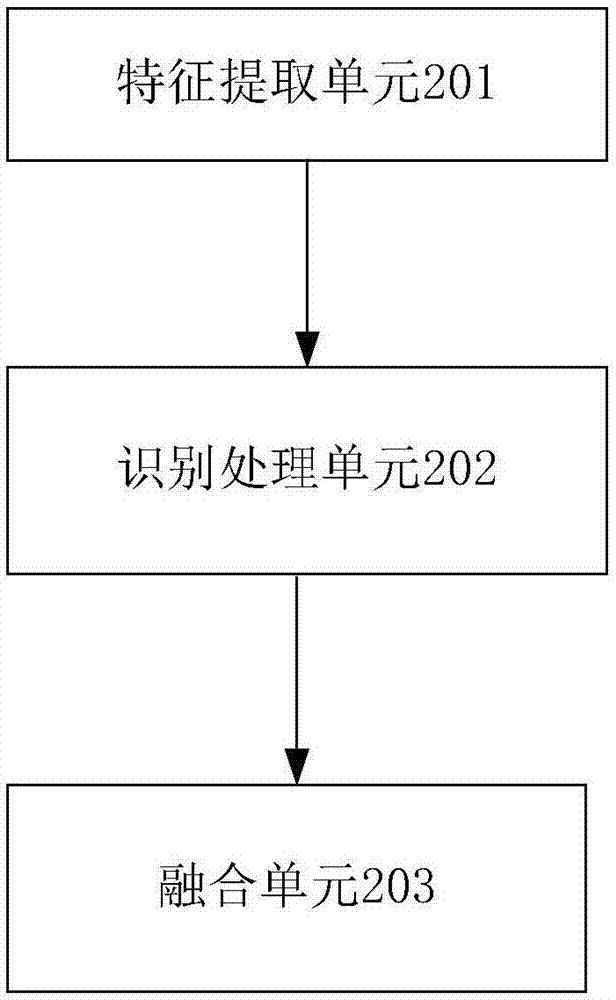
图2为本发明一种多标签图像识别装置的系统架构图。如图2所示,本发明一种多标签图像识别装置,包括:
特征提取单元201,用于获取多标签图像,提取图片特征,获得该多标签图像的特征图。
在本发明具体实施例中,特征提取单元201利用深度卷积神经网络提取图片特征,具体地说,特征提取单元201获取多标签图像,将该图像缩放到W×H,送入深度卷积神经网络,该深度卷积神经网络则会通过堆叠多个卷积层来产生特征图fI∈RC×W′×H′。
识别处理单元202,于所述特征图上进行剪切获得区域特征,多次利用已训练好的循环注意感知模块进行处理,以获得所有区域的标签分数。在本发明具体实施例中,该循环注意感知模块包括长短时记忆网络和全连接网络,该模块输入为截取的各个特征区域和上一次运行该模块得到的隐藏状态,输出为各个特征区域的分类向量以及预测的下一次运行最佳位置,也就是说,循环注意感知模块每次运行时都会预测当前各个区域的标签分数和搜索为下一次运行搜索最相关的区域,即给出当前值得注意的区域预测标签分数并根据当前状态预测下一次运行的最优位置,这个过程不断重复直到达到最大运行次数。具体地,识别处理单元202进一步包括:
截取缩放单元,在特征图上截取不同形状、不同尺度的区域,并把该些区域缩放到统一尺度。
具体地说,循环注意感知模块在第t次运行时,该截取缩放单元首先接受之前运行时计算好的位置lt并基于位置lt提取区域信息。在之前的方法中,仅仅是提取以lt为中心的方框区域的特征,然而,一般物体在形状和尺度上会有各种变化,因此简单地提取方框区域信息很难覆盖这些物体,因而本发明以lt为中心获取k个不同尺度区域的特征:
其中表示以fI为中心剪切不同大小和形状的区域Rtr,然后进行双线性插值把该些剪切的特征图缩放到同样的大小ftr。以前的方法是在原输入图像上进行剪切然后利用卷积神经网络重复性地对每个区域进行特征提取,这样导致高的计算负担。本发明提出的方法则是在特征图上进行剪切操作,可有效提高效率。
循环注意感知模块,用于于提取该些区域特征后,利用长短时记忆网络将之前运行的隐藏态以及该些区域特征作为输入,输出为每个区域的分类分数和搜索到的下一次运行的最优位置,不断重复直到达到最大运行次数,获得各区域的标签分数。获得公式表达为:
其中代表循环注意感知模块,θ代表网络参数,atr是区域Rtr预测出来的标签分值向量。
这里需说明的是,对于初始化的区域设置成整张图片,所以R0只有一个区域,其输出只是用来决定下次运行时的位置l1。
融合单元203,用于融合每一次循环注意感知模块得到的各区域的标签分数,获得最终的标签分布,输出最终结果。在本发明具体实施例中,采用种类最大池化方法对每一次循环注意感知模块得到的各区域的标签分数进行融合,具体地说,循环注意感知模块运行T+1次时将产生T×k个标签分数向量,也就是{atr|t=1,2,...,T;r=1,2,...,k},其中是区域Rtr的C个种类标签的分数向量,使用种类最大池化方法来得到最终的结果a={a0,a1,...,aC-1},具体为挑出各个区域的最大值,公式表达为:
优选地,所述多标签图像识别装置还包括:
训练单元200,用于获取多标签图像,通过提取特征获得所述多标签图像的特征图,设计循环注意感知模块,根据所述特征图多次调用循环注意感知模块以进行训练。具体地,训练单元200具体用于:
获取多标签图像,利用深度卷积神经网络提取图片特征,获得该多标签图像的特征图。由于该过程与特征提取单元201相同,在此不予赘述。
在所述特征图上截取不同形状、不同尺度的区域,并把该些区域缩放到统一尺度,由于该过程与截取缩放单元相同,在此不予赘述。
设计该循环注意感知模块,该循环注意感知模块包括长短时记忆网络和全连接网络,其输入为截取的缩放到统一尺度的各个区域特征以及上一次运行该模块得到的隐藏状态,输出为各个特征区域的分类向量以及预测的下一次运行最佳位置
循环训练单元,用于多次调用循环注意感知模块,使得模型能考虑图片的各个部分和全局信息,以此进行训练而调整整个模型的参数,使识别有更好的效果。具体地说,循环注意感知模块每次运行时都会预测当前各个区域的标签分数和搜索为下一次运行搜索最相关的区域,在每一次运行中,它给出当前值得注意的区域预测标签分数然后根据当前状态预测下一次运行的最优位置,这个过程不断重复直到达到最大运行次数,最后,所有区域的标签分数通过融合得到最终的标签分布。
优选地,循环训练单元还用于:
于训练过程中,根据最终融合的结果定义一延迟奖励函数,并指导循环注意感知模块的训练过程。
具体地说,在循环注意感知模块每一次运行做出动作后,模块更新状态并得到一个奖励信号。对于多标签图像识别任务,因为每一个区域与一个语义标签相对应,需要融合各个区域的预测来计算奖励,因此,本发明根据最终融合的结果定义一个延迟奖励赋予机制,对于有n个正确标签的样本,它的标签集是计算预测的分数,抽取前n个最大的分数,到预测集是在第t次运行时,奖励定义为
其中|·|表示集合的数目。本发明的目标是最大化折扣奖励,因此,最终的延迟奖励函数如下:
其中γ是折扣因子。在实验中,γ设置为1,总体的回报为R=γT。在本发明具体实施例中,可利用延迟奖励函数通过类似于梯度下降的方法调整整个模块的参数权重。
优选地,循环训练单元还用于:于训练过程中,设计分类损失函数,利用分类损失函数与延迟奖励函数指导循环注意感知模块的学习。
图3为本发明具体实施例的网络架构图。以下将配合图3进一步说明本发明的多标签图像的识别:给定输入图像I,首先把图像缩放到W×H然后送入VGG16等卷积神经网络,这个卷积神经网络通过堆叠多个卷积层来产生特征图fI∈RC×W′×H′,本发明的核心是循环注意感知模块,这个模块在一次运行时找出值得注意的区域和给这个区域产生一个标签分数。最后,这些分数融合成一个最终的标签分布。具体地:
在第t次运行时,循环注意感知模块首先接受之前运行时计算好的位置lt并基于位置lt提取区域信息。在本发明具体实施例中,以lt为中心获取k个不同尺度区域的特征:
其中表示以fI为中心剪切不同大小和形状的区域Rtr,然后进行双线性插值把这些剪切的特征图缩放到同样的大小ftr。
这些区域特征提取后,长短时记忆网络把之前运行的隐藏态和该些区域特征作为输入,输出为每个区域的分类分数和搜索到的下一次运行的最优位置,公式表达为:
其中代表循环注意感知模块,θ代表网络参数。atr是区域Rtr预测出来的标签分值向量。初始化的区域设置成整张图片,所以R0只有一个区域,所以只是用来决定下次运行时的位置l1。
循环注意感知模块运行T+1次时将产生T×k个标签分数向量,也就是{atr|t=1,2,...,T;r=1,2,...,k},其中是区域Rtr的C个种类标签的分数向量。本发明使用种类最大池化方法来得到最终的结果a={a0,a1,...,aC-1},具体为挑出各个区域的最大值,公式表达为:
循环注意感知模块每次运行时都会预测当前各个区域的标签分数和搜索为下一次运行搜索最相关的区域,因此可以看做是序列决策问题。在每一次运行中,它给出当前值得注意的区域预测标签分数然后根据当前状态预测下一次运行的最优位置。这个过程不断重复直到达到最大运行次数。做出动作后,状态通过一个新的隐藏状态和新的值得注意的区域来更新。最后,所有区域的标签分数通过融合得到最终的标签分布。延迟奖励基于预测的结果和真实的标签计算得到,这个奖励用来指导模块的训练。以下,将更为详细地介绍本发明涉及的状态、动作和奖励信号:
状态:状态st应该提供充足的信息来使得模块做出决策。更为详细地,状态应该能编码当前环境和之前运行的知识。为此,它包含两部分:1)当前区域的特征(也就是这个信息能为分类提供指导和提供丰富的信息来帮助模块挖掘更为完整的判别性区域;2)上一次运行的隐藏状态ht-1,这个信息编码之前运行的信息,然后通过长短时记忆网络进行时间上的更新。此外,同时考虑以前运行信息可以帮助捕获覆盖全部已经捕获区域和标签的信息。在这种方式中,通过观察连续的状态st={ft1,ft2,...,ftk,ht-1},这个模块能对当前的区域进行分类和决定下一个最优区域。
动作。给定状态st,这个模块可以采取两种动作:1)对当前值得注意的区域进行分类;2)在特征图fI上所有可能位置{lt+1=(x,y)|0≤x≤W′,0≤y≤H′}找出一个最优的位置lt+1。正如图1所示,对于每一个注意到的区域,一个全连接层被用来把提取到的特征ftr映射到语义表达。长短时记忆单元把语义表达和上一次运行的隐藏状态作为输入,然后输出一个新的隐藏状态htr。最后,通过一个简单的分类网络可以计算得到分类分数,记作:
atr=fcls(htr;θcls),r=1,2,...,k,
其中分类网络fcls(·)通过全连接网络实现,θcls为网络的参数。对于定位动作,所有隐藏状态最终整合成一个隐藏状态,记作然后这个模块建立一个高斯分布P(lt+1|floc(ht;θloc),σ)。在这个等式中,floc(ht;θloc)是定位网络的输出,被当作分布的平均值。σ是分布的标准差,根据实验经验,设置为0.11。相似的,定位网络floc(·)通过一个全连接层实现,参数为θloc。在第t次运行时,模块通过随机抽取分布上的一个位置来选择位置lt+1。
奖励:在每一次运行做出动作后,模块更新状态并得到一个奖励信号。对于多标签图像识别任务,因为每一个区域与一个语义标签相对应,需要融合各个区域的预测来计算奖励。因此,可以根据最终融合的结果定义一个延迟奖励赋予机制。对于有n个正确标签的样本,它的标签集是计算预测的分数,抽取前n个最大的分数,到预测集是在第t次运行时,奖励定义为
其中|·|表示集合的数目。本发明的目标是最大化折扣奖励:
其中γ是折扣因子。在实验中,γ设置为1,总体的回报为R=γT。本发明使用奖励来指导模块寻找最优动作。
在训练过程,除了定义分类损失,也把延迟奖励考虑进来优化区域定位策略,导出了一个总体目标函数。在训练中,模型通过总体目标函数进行端到端的训练。
具体地,模块需要学习一个策略π((at,lt+1)|St;θ),这个策略基于之前的观察和模块之前做出的动作预测出一个动作分布,也就是St=R0,l1,R1,a1,l2,...,Rt。为此,定义一个目标函数来最大化奖励期望,表达成:
其中P(ST;θ)是所有可能序列的分布,它依赖于策略。本发明使用增强学习的算法来估计反向传播的梯度,表达为
其中i=1,2,...,M为M段的标识。但是利用上式计算梯度是高变化的,因此训练过程很难收敛。为了解决这个问题,本发明进一步采用一种变化减少的策略来得到无偏低变化梯度估计。
这个策略通过使用延迟奖励信号进行学习,因此在每一次运行做出最好的动作是不可能的。在多标签分类识别的语境下,每个样本存在正确的标签。因此,本发明定义一个分类损失函数来作为进一步的监督。假定存在N个训练样本,每个样本有它的标签向量被标记为1如果这个样本存在种类标签C,反之则为0。第i个样本的正确分布向量可以表达成因此分类损失函数可以表达成:
其中pi是预测的向量分布,可由下式计算:
通过利用分类损失函数和延迟奖励函数共同调整整个模块的参数权重以使模型达到更好的识别效果。
综上所述,本发明一种多标签图像识别方法及装置通过把循环注意力机制和增强学习相结合的方法应用到通用多标签分类任务中,相比于最近的基于假设候选区域的多标签识别方法,本发明不仅拥有更好的计算效率和更高的分类精度,而且提供了一种仅仅基于图片级别标签的语义感知物体寻找机制。
上述实施例仅例示性说明本发明的原理及其功效,而非用于限制本发明。任何本领域技术人员均可在不违背本发明的精神及范畴下,对上述实施例进行修饰与改变。因此,本发明的权利保护范围,应如权利要求书所列。
- 还没有人留言评论。精彩留言会获得点赞!