一种数据关联分析方法及系统与流程
本发明涉及数据安全领域,具体涉及一种数据关联分析方法及系统。
背景技术:
spark流处理,sparkstreaming是将流式计算分解成一系列短小的批处理作业。这里的批处理引擎是spark,也就是把sparkstreaming的输入数据按照batchsize(如1秒)分成一段一段的数据(discretizedstream),每一段数据都转换成spark中的rdd(resilientdistributeddataset),然后将sparkstreaming中对dstream的transformation操作变为针对spark中对rdd的transformation操作,将rdd经过操作变成中间结果保存在内存中。
关联分析,在业务数据中查找存在于对象之间的相关性的分析,具体为根据业务日志中的根据指定字段信息对业务数据进行关联。
随着互联网技术在各行业的不断普及和应用,企业工作流程中各环节产生的业务数据规模迅速扩展。管理者对基于业务数据形成报表管理、事件告警、行为审计的需求日趋强烈。随着大数据技术的发展,为基于业务数据的集中收集和关联分析提供了技术基础。通过业务数据的关联分析技术,可以快速对业务数据进行审计、事件告警,定位问题出现的相关原始信息。
现有技术中存在基于日志的分析系统,如splunk、日志易等关联分析技术。
上述现有技术基本的分析方案包括:
步骤1,从数据源提取待处理的业务数据。
步骤2,对业务数据进行spark流处理。
步骤3,将经过spark流处理的业务数据按照分类结果放入数据缓存区。
步骤4,根据指定的关联规则对放入数据缓存区的数据进行关联分析。
步骤5,判断是否关联成功,关联成功,则将关联的结果数据放入缓存区,并进行数据展示,结束;否则将关联失败的数据放入关联失败数据缓存区。
步骤6,判断关联失败的数据是否还在生命周期,如果在,则返回到步骤4进行进行关联分析,否则放弃关联。
然而上述现有技术存在以下问题:
关联规则和关联数据固定,无法适应数据的实时变化;
并且当有可疑信息出现时直接通过这些信息很难快速定位问题的所在。
技术实现要素:
为了实现以下目的:
1、基于spark的流处理技术,可以近乎实时的对业务数据进行关联分析,基于分析结果可以动态的对业务进行跟踪,对满足阀值的问题触发警报。
2、关联分析之后的结果数据,查询时可以快速定位到与该数据相关联的原始数据资料。
本发明提供了一种数据关联分析方法,其特征在于,该方法包括以下步骤:
对待处理数据进行预分类,根据分类结果将待处理数据放入不同数据缓存队列;
确定基础数据,并加载基础数据到内存;
根据所述基础数据对放入数据缓存队列的数据进行关联分析;
向用户输出关联分析结果。
根据本发明的方法,优选的,对所述基础数据通过机器学习实行动态管理,使得加载到内存中的基础数据使用频率最高。
根据本发明的方法,优选的,根据放入数据缓存队列的待处理数据与所述基础数据之间具有相同的标识符从而产生关联,并根据关联的基础数据对待处理数据进行分析。
根据本发明的方法,优选的,所述基础数据至少包括:用户信息、与ip地址相关的位置信息和组织机构信息。
根据本发明的方法,优选的,对所述关联分析结果处理包括:实时报表展示和/或数据预警。
本发明提供了一种数据关联分析装置,其特征在于,该装置包括:
数据分类模块,对待处理数据进行预分类,根据分类结果将待处理数据放入不同数据缓存队列;
基础数据加载模块,确定基础数据,并将加载基础数据到内存;
关联分析模块,根据所述基础数据对放入数据缓存队列的数据进行关联分析;
结果输出模块,向用户输出关联分析结果。
根据本发明的装置,优选的,所述基础数据加载模块进一步包括:基础数据管理子模块,对所述基础数据通过机器学习实行动态管理,使得加载到内存中的基础数据使用频率最高。
根据本发明的装置,优选的,所述关联分析模块,根据放入数据缓存队列的待处理数据与所述基础数据之间具有相同的标识符从而产生关联,并根据关联的基础数据对待处理数据进行分析。
根据本发明的装置,优选的,所述结果输出模块通过实时报表展示和/或数据预警向用户输出关联分析结果。
根据本发明的装置,优选的,该介质存储有计算机程序指令,其特征在于,当执行所述计算机程序指令时,实现上述之一所述的方法。
采用本发明的技术方案,取得了以下技术效果:
功能扩展:可以由用户根据具体业务需求指定灵活的指定关联规则。灵活指定基础数据的预加载和对预加载区数据的机器学习管理可以有效减少关联分析中数据库查询的次数,提高处理效率。
实时性:基于spark流处理的关联分析使得业务数据的关联分析以近乎实时的速度完成,强化了系统审计功能和警报功能的失效性。
附图说明
图1为现有技术数据分析流程图。
图2为本发明的数据关联分析流程图。
图3为本发明的整体数据关联分析流程图。
具体实施方式
<关联分析方法>
结合附图2、附图3对数据关联分析方法进行介绍。
本发明提供了一种数据关联分析方法,该方法包括以下步骤:
步骤1,对待处理数据进行预分类,根据分类结果将待处理数据放入不同数据缓存队列。
通过spark流处理技术从消息队列中收集业务数据,对收集到的业务数据根据预先配置好的条件进行分类,将处理后的数据发送到各类数据的缓存队列,数据以json格式传输,通过其中的业务类型字段进行数据分类等待进行下一步的关联操作。对业务数据按照预定义的数据类型字段的值来对数据进行分类。
比如包括两种业务数据:业务数据a和业务数据b。
其中业务数据a、b既包括相同的数据内容:用户id、数据类型、软件名称、事件消息、ip地址、记录时间等相关信息,又包括一些互不相同的其他数据内容;
流处理模块收到a、b两类业务数据之后,将数据解析为json格式,根据预定义的数据类型字段的值将数据放入对应的队列中,进入下一步的关联操作。
步骤2,确定基础数据,并将加载基础数据到内存。
对所述基础数据通过机器学习实行动态管理,使得加载到内存中的基础数据使用频率最高。所述基础数据至少包括:用户信息、与ip地址相关的位置信息和组织机构信息。
可以预先指定需要预加载的关联分析基础数据,该基础数据是那些相对变化较少的数据,比如人员身份信息,设备基础信息等。并通过机器学习对加载的数据实行动态管理,加载区中的基础数据始终是当前使用频率最高的,比如通过对容器中的数据根据使用频率进行排名,将排名在后面的10%的数据清理出容器,以此重复保持基础数据的使用频率为最高,此仅为优选实施例,其他相同思想的变换形式均在本发明的保护范围之内。比如该基础数据包括用户信息数据和用户单位数据。其中用户信息数据包括:用户id、移动号码、用户单位名称id、用户位置等;用户单位数据包括:用户单位名称id、单位注册代码、单位注册时间、单位所在城市、单位所在省份等信息。
该基础数据仅为示例,在实际操作过程中还可以包括其他基础信息,比如软件相关信息,业务相关信息等,在此不做限定。通过预加载这些基础信息,可以根据待分析的业务数据,通过用户id、用户单位id等快速提取业务数据的相关基础数据,从而快速分析业务数据。
该功能可以有效减小关联分析时与数据库的io,极大提升关联分析处理效率。该功能具体实现举例如下所述:例如要对某网络中人员的外发信息进行审计,相应的业务数据包括:用户id、数据类型、软件名称、事件消息、信息源ip地址、服务器ip地址和记录时间等相关信息。
该信息中通过相应的标识符标识用户、软件名称,还包括数据发送ip地址和服务器ip地址等信息,当有可疑信息出现时直接通过这些信息很难快速定位问题的所在。因此,通过对这些字段所标识的信息进行关联补充显得极为重要。上述可疑信息(或者敏感信息)的发现方法仅属于现有技术的方法,在此不对其进行具体描述。
但是在数据量很大的情况下,如果每次收到该消息之后直接查询数据库去补充这些基础信息,会形对数据库进行频繁访问,造成很大的压力。为此,在关联分析开始之前对分析中可能用到的基础数据(如用户信息、与ip地址相关的位置信息、组织机构信息等)可以进行预先指定加载,通过页面指定,因为这些基础信息相对来说是比较固定的。通过基础数据预加载功能,可疑对业务信息进行补充,方便后续操作。如根据用户id补充人员基础信息,如所在组织机构、名字、年龄等。
当接收到一条业务日志时,通过与基础数据的关联分析,快速定位到文件出处的所有者、所在位置等信息。本发明通过提供一个预加载模块和机器学习功能来提升这一部分的效率,将使用频繁的基础数据加载到内存中,可以有效减少读取数据库的次数,通过机器学习,对预加载模块中的数据集进行优化,减少关联分析中的目标数据搜索次数。
预加载模块中加载的基础内容可以由用户根据指定的,可根据具体需求具体指定,有效提高了场景的适应能力。但要保证预加载基础数据始终是当前使用频率较高的或者最高的,从而便于快速的进行后续的关联分析。
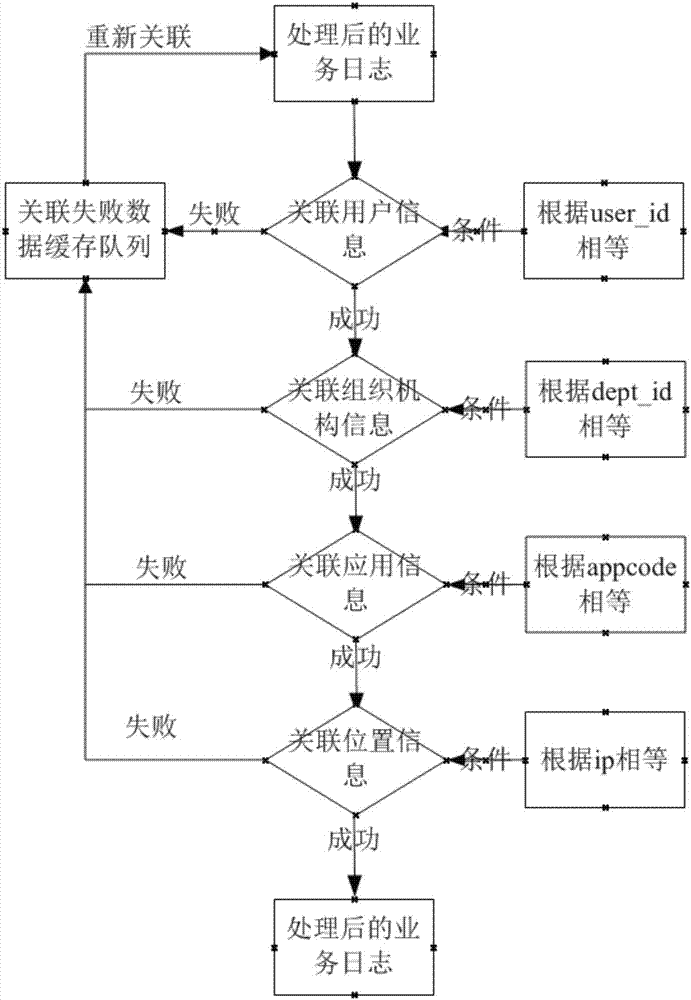
步骤3,根据所述基础数据对放入数据缓存队列的数据进行关联分析。
根据放入数据缓存队列的待处理数据与所述基础数据之间具有相同的标识符从而产生关联,并根据关联的基础数据对待处理数据进行分析。
根据指定的关联规则对数据进行关联分析,若成功则将结果数据存入结果数据缓存区,进行下一步的数据展示操作(包括数据报表、行为审计、警报触发等);若失败则进入关联失败缓存区,根据预先制定的规则对数据进行重新关联操作(此处理主要解决各业务数据因进入流处理器的时间差超过流处理时间间隔造成的关联分析误差)。关联规则是用户预先指定的,比如:根据用户id关联用户信息,根据ip地址关联地理位置信息,根据硬件id关联硬件信息等。
具体关联过程如下:
通过外发信息业务日志中的用户id找到关联的用户基础信息,比如用户姓名、移动号码、相应的单位名称id等;
然后又通过单位名称id找到单位基础信息,比如单位注册代码、单位所在城市、单位所在省份以及单位注册时间等相关信息。
根据业务日志与用户信息数据中用户id相等的条件对这两类数据进行关联,得到关联后的业务日志数据,根据关联后的业务日志数据与组织机构信息中单位id名称相等的条件对这两类数据进行关联,得到关联后的业务日志数据,可依此原理对其他需要关联的基础数据进行关联。如上所示,关联后的日志数据包括用户基础信息和单位基础信息。对关联成功的数据,将结果保存在指定的数据集合中;对关联失败的数据,则将该业务日志放入失败队列中,根据指定的重试规则进行重新关联,比如失败后等待10分钟、20分钟重新关联。如果关联成功,则将数据放入关联成功的数据集合中,如果失败,则放弃该条数据的关联。
步骤4,向用户输出关联分析结果。
该步骤:包括实时报表展示、预警功能等。
根据关联后的业务日志可以多维度的对业务结果进行展示报表,预警等。如可根据位置信息统计业务日志的区域分布情况,根据组织结构信息统计各部门的业务日志分布情况等。
<关联分析装置>
本发明还公开了一种数据关联分析装置,该装置包括:
数据分类模块,对待处理数据进行预分类,根据分类结果将待处理数据放入不同数据缓存队列;
基础数据加载模块,确定基础数据,并将加载基础数据到内存;
关联分析模块,根据所述基础数据对放入数据缓存队列的数据进行关联分析;
结果输出模块,向用户输出关联分析结果。
所述基础数据加载模块进一步包括:基础数据管理子模块,对所述基础数据通过机器学习实行动态管理,使得加载到内存中的基础数据使用频率最高。
所述关联分析模块,根据放入数据缓存队列的待处理数据与所述基础数据之间具有相同的标识符从而产生关联,并根据关联的基础数据对待处理数据进行分析。
所述结果输出模块通过实时报表展示和/或数据预警向用户输出关联分析结果。
所述基础数据至少包括:用户信息、与ip地址相关的位置信息和组织机构信息。
通过本发明的方案,可以由用户根据具体业务需求指定灵活的指定关联规则。灵活指定基础数据的预加载和对预加载区数据的机器学习管理可以有效减少关联分析中数据库查询的次数,提高处理效率。基于spark流处理的关联分析使得业务数据的关联分析以近乎实时的速度完成,强化了系统审计功能和警报功能的失效性。
以上实施例仅作为本发明保护方案的示例,不对本发明的具体实施方式进行限定。
- 还没有人留言评论。精彩留言会获得点赞!