行为数据的识别方法及装置与流程
本发明涉及数据处理技术领域,尤其是涉及到一种行为数据的识别方法及装置。
背景技术:
在电商业务的发展过程中,营销行为越发的依赖于个性化营销,即在不同业务场景下,可以灵活的对用户行为,如交易记录等数据进行分析建模运算,识别出符合用户行为的营销策略,实现准确的营销目的。例如,通过某交易平台APP产生了仅一天电商购物记录且首单客单价在88-87的新客,对这个新客进行用户反馈活动的营销策略。其中,为了找到准确的营销策略,需要识别出特定时间范围内的行为数据,如通过时间窗口来统计识别营销成本、利润转化率统计数据等。
目前,现有的行为数据识别通过关系型数据库Mysql存储行为数据,然后按照指定时间段及不同业务需求,通过特定的代码语句查询不同时间段内影响营销策略的因素,并建立不同业务场景对应的用户行为列表,以便进行统计识别等操作。但是,Mysql只能支持查询,业务需求单一,无法满足持续变化的业务需求,技术人员需要重新开发对应的查询程序,浪费大量开发资源;另外,由于在Mysql中进行数据的识别需要占用数据库资源,在数据库无法拓展的情况下,无法满足业务需求的不断扩大,导致系统内存卡顿,影响整个系统的运行速度。
技术实现要素:
本发明实施例提供了行为数据的识别方法及装置,解决了相关技术中行为数据识别时,Mysql只能支持查询,业务需求单一,无法满足持续变化的业务需求,技术人员需要重新开发对应的查询程序,浪费大量开发资源;另外,由于在Mysql中进行数据的识别需要占用数据库资源,在数据库无法拓展的情况下,无法满足业务需求的不断扩大,导致系统内存卡顿,影响整个系统的运行速度的问题。
根据本发明实施例的一个方面,提供一种行为数据的识别方法,包括:
确定待识别行为数据的时间标识,所述时间标识用于标识不同业务场景下用户进行交易时不同行为特征对应行为数据的时间点;
通过预设非关系型数据库中的预设时间窗口模式对所述时间标识对应行为数据进行读取,所述预设时间窗口模式为按照时间序列对存储在预设非关系型数据库中多个连续的行为数据的累计值进行识别的方式。
进一步,所述确定待识别行为数据的时间标识之前,所述方法还包括:
统计不同时间标识下的行为数据的累计值;
判断所述时间标识是否处于无效时间范围,若处于无效时间范围,则保留所述无效时间范围中最大累计值及对应的时间标识,并删除所述无效时间范围中其余的累计值及对应的时间标识;
按照时间序列将不同时间标识下的行为数据的累计值存储至预设非关系型数据库中。
进一步,所述确定待识别行为数据的时间标识之前,所述方法还包括:
若待冲正的时间标识处于有效时间范围内,根据业务流程查找所述有效时间范围内时间标识下的累计值小于或等于预设阈值的行为数据;
将所述行为数据的累计值与当前冲正金额进行相加,并更新至所述预设非关系型数据库中。
进一步,所述按照时间序列将不同时间标识下的行为数据的累计值存储至预设非关系型数据库中之后,所述方法还包括:
判断所述预设非关系型数据库中不同时间标识下的行为数据的累计值是否存在于预设分布式数据库中;
若不存在,则所述累计值更新至所述预设分布式数据库中,并对不同时间标识下的行为数据进行冲正处理。
进一步,所述通过预设非关系型数据库中的预设时间窗口模式对所述时间标识对应行为数据的累计值进行读取包括:
根据扫描式滑动区间模式对时间顺序下的行为数据的累计值按照第一预设窗口长度进行滑动读取;或,
根据周期性特定范围模式对时间顺序下的行为数据的累计值按照第二预设窗口长度进行定时读取。
进一步,所述统计不同时间标识下的行为数据的累计值包括:
获取不同时间标识下的行为数据;
对相同时间标识下的不同行为数据的累计值分别进行排序,将最大累计值确定为所述时间标识下的行为数据的累计值。
进一步,所述方法还包括:
根据不同的业务场景、行为特征、第一预设窗口长度、第二预设窗口长度为所述扫描式滑动区间模式及所述周期性特定范围模式选取存储累计值以及读取累计值的程序引擎。
根据本发明实施例的另一方面,提供一种行为数据的识别装置,包括:
确定单元,用于确定待识别行为数据的时间标识,所述时间标识用于标识不同业务场景下用户进行交易时不同行为特征对应行为数据的时间点;
读取单元,用于通过预设非关系型数据库中的预设时间窗口模式对所述时间标识对应行为数据进行读取,所述预设时间窗口模式为按照时间序列对存储在预设非关系型数据库中多个连续的行为数据的累计值进行识别的方式。
依据本发明又一个方面,提供了一种存储设备,其上存储有计算机程序,该程序被处理器执行时实现以下步骤:
确定待识别行为数据的时间标识,所述时间标识用于标识不同业务场景下用户进行交易时不同行为特征对应行为数据的时间点;
通过预设非关系型数据库中的预设时间窗口模式对所述时间标识对应行为数据进行读取,所述预设时间窗口模式为按照时间序列对存储在预设非关系型数据库中多个连续的行为数据的累计值进行识别的方式。
依据本发明再一个方面,提供了一种终端设备,包括存储设备、处理器及存储在存储设备上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现以下步骤:
确定待识别行为数据的时间标识,所述时间标识用于标识不同业务场景下用户进行交易时不同行为特征对应行为数据的时间点;
通过预设非关系型数据库中的预设时间窗口模式对所述时间标识对应行为数据进行读取,所述预设时间窗口模式为按照时间序列对存储在预设非关系型数据库中多个连续的行为数据的累计值进行识别的方式。
借由上述技术方案,本发明提供的一种行为数据的识别方法及装置,与目前通过关系型数据库Mysql存储行为数据相比,本发明可以根据确定待识别的行为数据的时间标识来运行预设时间窗口模式的识别方式对行为数据进行读取,从而实现多样化的行为数据查询,满足不同业务需求的变化,无需技术人员重新开发对应的程序,降低资源消耗,而预设非关系型数据库可以最大化拓展,减少系统卡顿,提高系统运行速度,从而提高行为数据的识别效率。
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其它目的、特征和优点能够更明显易懂,以下特举本发明的具体实施方式。
附图说明
此处所说明的附图用来提供对本发明的进一步理解,构成本申请的一部分,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
图1示出了本发明实施例提供的一种行为数据的识别方法流程示意图;
图2示出了本发明实施例提供的另一种行为数据的识别方法流程示意图;
图3示出了本发明实施例提供的一种时间标识与行为数据对应示意图一;
图4示出了本发明实施例提供的一种时间标识与行为数据对应示意图二;
图5示出了本发明实施例提供的一种扫描式滑动区间模式读取示意图;
图6示出了本发明实施例提供的一种时间标识与行为数据对应示意图三;
图7示出了本发明实施例提供的一种周期性特定范围模式读取示意图;
图8示出了本发明实施例提供的一种行为数据的识别装置框图;
图9示出了本发明实施例提供的另一种行为数据的识别装置框图;
图10示出了本发明实施例提供的一种终端设备的实体装置结构示意图。
具体实施方式
下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
本发明实施例提供了一种行为数据的识别方法,如图1所示,所述方法包括:
101、确定待识别行为数据的时间标识。
其中,所述时间标识用于标识不同业务场景下用户进行交易时不同行为特征对应行为数据的时间点,所述行为数据可以包括用户在使用交易平台时触发行为产生的数据,例如购买行为中的订单数据、缴费行为中的缴费数据等,本发明实施例不做具体限定。一般的,由于当前行为数据的识别方法的执行主体为服务端,由于对交易平台可以在一个时间点接收到多个用户触发的行为,因此,一个时间标识可以对应多个用户的行为数据,当进行行为数据的识别时,即需要确定待识别行为数据的时间标识,时间标识为key,即年、月、日的具体数据,或一个数字标识,本发明实施例不做具体限定。
需要说明的是,在电商发展中,不同业务场景即包括了电商的具体交易内容,例如购买商品、生活缴费、用户二手兑换等,在这些业务场景下,交易平台服务端可以根据分析不同的用户行为数据来对用户推送针对性的营销活动,从而促使用户进行更多的交易行为,因此,需要对不同时间标识下的行为数据进行识别分析。另外,由于当前的行为数据全部预先存储在预设非关系型数据库中,在进行时间标识的确定时,可以根据输入的待识别行为数据的时间标识来查询出存储在预设非关系型数据库中的时间标识,从而确定需要识别的行为数据。
102、通过预设非关系型数据库中的预设时间窗口模式对所述时间标识对应行为数据进行读取。
其中,所述预设时间窗口模式为按照时间序列对存储在预设非关系型数据库中多个连续的行为数据的累计值进行识别的方式,所述时间标识下可以对应多个行为数据,且为了便于统计及分析,每个行为数据都会存储于自身行为特征对应的累计值,例如,行为特征为购买次数,则时间标识下的用户的行为数据的累计值,即在key为2017.5.4.21.05的购买累计次数为500次。另外,由于时间标识可以对应多个用户行为,在进行行为数据读取时,还可以根据具体的营销需求,读取出来行为数据累计值的其他数据,如用户图像、是否为新客等,以便根据这些数据来确定出待进行营销活动的成本、利润转化率等统计数据,如用户静态属性、用户动态属性、用户品牌属性、用户行为属性、用户购买属性、用户品类行为。所述预设非关系型库为具有开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型的Key-Value数据库,如redis数据库,由于redis数据库中存储的数据即以key关键字与value数据值进行对应,因此,完全匹配预设时间窗口模型下根据时间标识key读取对应的累计值value。所述预设时间窗口模型为通过预先设定的窗口大小、步长、时间范围交换确定的时间窗口,然后通过移动时间窗口来对时间标识下的行为数据进行读取的模式,可以对存储在预设非关系型数据库中的按照时间序列存储的时间标识及行为数据进行窗口大小的移动式读取,从而获取需要的累计值,本发明实施例不做具体限定。
借由上述技术方案,本发明提供的一种行为数据的识别方法,与目前通过关系型数据库Mysql存储行为数据相比,本发明可以根据确定待识别的行为数据的时间标识来运行预设时间窗口模式的识别方式对行为数据进行读取,从而实现多样化的行为数据查询,满足不同业务需求的变化,无需技术人员重新开发对应的程序,降低资源消耗,而预设非关系型数据库可以最大化拓展,减少系统卡顿,提高系统运行速度,从而提高行为数据的识别效率。
本发明实施例提供了另一种行为数据的识别方法,如图2所示,所述方法包括:
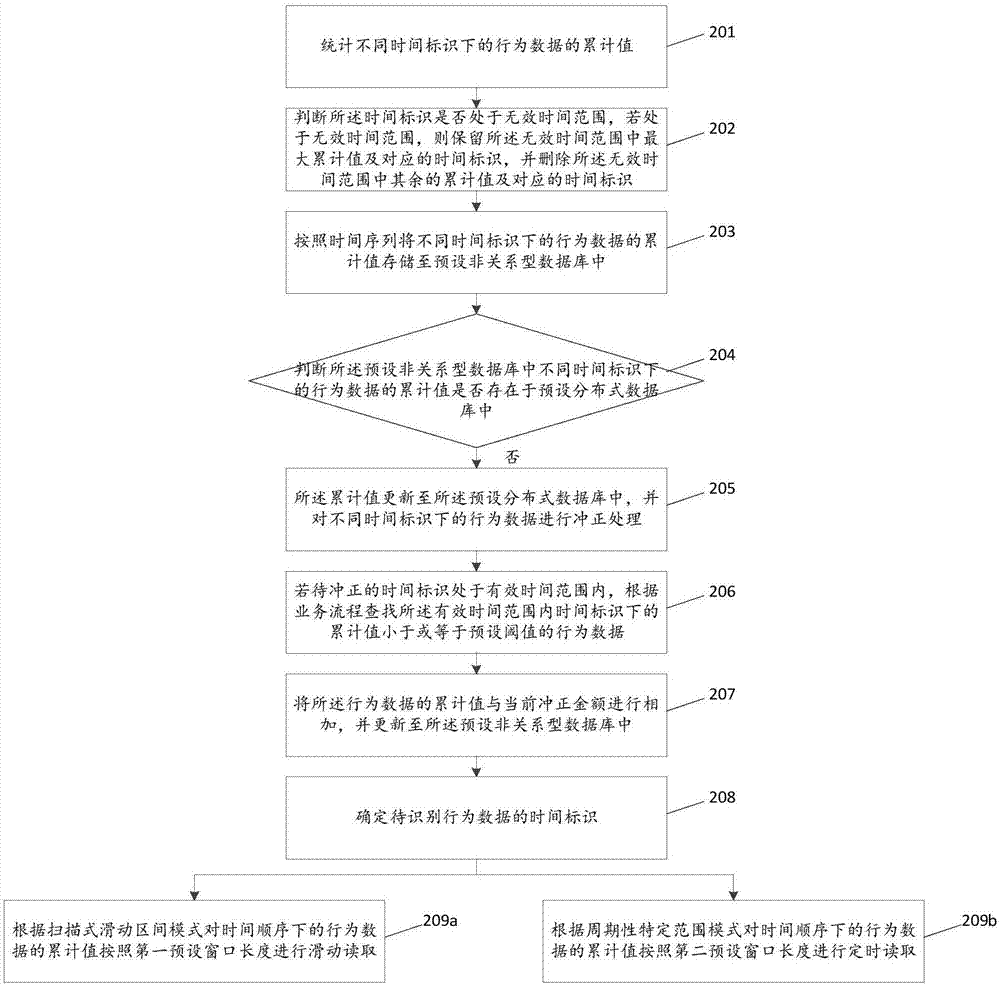
201、统计不同时间标识下的行为数据的累计值。
对于本发明实施例,为了便于将行为数据的累计值作为营销策略的建模基础,需要按照时间间隔统计行为数据的累计值,其中,统计行为数据的累计值对应的时间标识可以按照预设的时间间隔进行标记统计,即按照年、月、日、时、分等时间维度进行设定,本发明实施例不做具体限定。另外,由于当前的数据统计是直接以预设非关系型数据库redis平台进行的,因此,可以利用redis字符串value自增长特性increment和redis单线程模型来实现,每个请求通过INCRBY key increment获取最新累计值,保证次的累计值不被重复累计。
需要说明的是,由于存储至redis中,进一步地的,可以对行为数据进行求和、求均值、求众数、求最大最小值、求范围、求过均值点个数、求系数,从而实现窗口时间自定义配置,从而满足不同需求的行为数据的识别。
对于本发明实施例,步骤201具体可以为:获取不同时间标识下的行为数据;对相同时间标识下的不同行为数据的累计值分别进行排序,将最大累计值确定为所述时间标识下的行为数据的累计值。
对于本发明实施例,为了避免相同时间标识下的不同行为数据中的累计值出现重复累计,以及避免使得每次读取累计值时都要先判断是否为行为数据的最大累计值,影响读取数据的效率,可以对相同时间标识下的所有行为数据的累计值进行排序,然后将最大的累计值确定为行为数据的累计值。其中。由于一个时间标识下可以对应多个行为数据,且redis在使用sorted set存储时,累计值对应一个时间标识,使得时间标识下的累计值无法修改,因此,需要对行为数据的累计值进行排序,将排序最大的累计值作为这个行为数据的累计值,且一个行为数据只对应一个累计值,则可以不进行排序比较,直接确定为这个行为数据的累计值。例如,在一个时间标识下,存在多个累计值,则保留最大的累计值,删除最小的累计值。
需要说明的是,redis的sorted set特性,具有排序数据流水模型,Sorted-Sets中的每一个行为数据都会有一个时间标识与之关联,累计实现思想正是利用时间标识来为集合中的行为数据的累计值进行从小到大的排序,尽管Sorted-Sets中的行为数据必须是唯一的,但是累计值是可以重复的。
202、判断所述时间标识是否处于无效时间范围,若处于无效时间范围,则保留所述无效时间范围中最大累计值及对应的时间标识,并删除所述无效时间范围中其余的累计值及对应的时间标识。
对于本发明实施例,为了避免由于无效时间范围内的数据被清除,而使得行为数据在进行时间差的数据统计过程中不连贯导致的缺少被减数,需要将无效时间范围内的数据做一个数据重现,即保留无效时间范围中的一个待进行数据清除的最大累计值的行为数据,以便作为统计依据。其中,所述无效时间范围即为已过期的时间及对应的数据,包括已经进行行为数据识别的时间范围,或者已经被确认为是无效数据的时间范围,如图3所示,本发明实施例不做具体限定。例如,如图3所示,时间标识1、2处于无效时间范围,则保留最大累计值对应的时间标识2的行为数据。
203、按照时间序列将不同时间标识下的行为数据的累计值存储至预设非关系型数据库中。
对于本发明实施例,为了满足多样化业务场景下对行为数据识别的需求,以便实现时间窗口的快速读取行为数据的累计值,可以将不同时间标识下的行为数据的累计值存储在预设非关系型数据库中。其中,所述时间序列即是指按照时间顺序及时间标识生成的时间维度,通过时间序列可以将每个时间标识下的行为数据进行时间排序,以便通过预设时间窗口模式对行为数据进行读取。
需要说明的是,预设非关系型数据库即为redis数据库,可以通过redis数据库中自带的算法进行数据的存储及读取,本发明实施例不做具体限定。
204、判断所述预设非关系型数据库中不同时间标识下的行为数据的累计值是否存在于预设分布式数据库中。
对于本发明实施例,由于预设非关系型数据库的内存大小有限,且预设非关系型数据库会按照预设时间间隔进行数据更新,存储的行为数据很可能再还没有被读取的情况下就被更新掉了,因此,可以通过将预设非关系型数据库中的数据备份至具有大容量存储量及高性能数据存储的数据库中。其中,所述预设分布式数据库即为具有大容量存储量及高性能数据存储的数据库,如MongoDB,本发明实施例不做具体限定。
需要说明的是,为了可以及时并准确的将数据备份至预设分布式数据库中,可以将redis数据库中不同时间标识下行为数据的累计值按照特定时间间隔进行判断,判断是否已经处在与MongoDB中,若是,则说明已经进行了备份,当进行行为数据识别时,根据时间标识在redis中读取不到行为数据是,则将查询目标转移至MongoDB中,确保行为数据存储的准确性及避免行为数据丢失。
205、若不存在,则所述累计值更新至所述预设分布式数据库中,并对不同时间标识下的行为数据进行冲正处理。
对于本发明实施例,为了确保行为数据存储的连续性及准确性,避免行为数据丢失,若在redis中存在的时间标识下行为数据的累计值不存在于MongoDB中,则将时间标识下的行为数据的累计值更新至MongoDB中。其中,所述冲正处理为对行为数据中交易行为失败时采取的补救方法,例如,订单交易行为数据在终端中已经设置为成功,但是发送到当前服务端的账务并没有响应,可能存在交易超时等情况,为了确保用户的利益,会取消当前订单交易行为数据,若是交易成功了,则回滚交易,从而实现冲正。通过对不同时间标识下的行为数据的冲正处理,确保MongoDB中的所有数据都是准确的。
需要说明的是,冲正处理不仅仅是针对存储在MongoDB中的数据进行的,也可以为对存储在redis中的数据进行,以便确保所有的数据都进行了修复。
206、若待冲正的时间标识处于有效时间范围内,根据业务流程查找所述有效时间范围内时间标识下的累计值小于或等于预设阈值的行为数据。
对于本发明实施例,为了确保数据修复的准确性,避免批量冲正处理影响行为数据的识别或存储,需要对有效时间范围内时间标识下的累计值进行进一步地的修复。其中,所述业务流程即是指按照业务场景下用户行为触发的流程,所述预设阈值等于累加当前冲正值后的总值-当前冲正值,若累计值小于预设阈值,说明当前时间标识下的累计值是未进行修复的,因此,可以通过将时间标识下的所有行为数据的累计值统一增加当前冲正值,从而实现冲正修复。
需要说明的是,为了避免在增加了当前冲正值后,出现步骤201中的情况,需要将其他累计值进行删除,确保冲正后的累计值为最大的累计值。另外,若无效时间分为内,冲正没有意义,可以不进行冲正。
207、将所述行为数据的累计值与当前冲正金额进行相加,并更新至所述预设非关系型数据库中。
例如,如图4所示的时间点1、5、10中当处于5-10之间的时间点时冲正存在意义,A为当前冲正金额、B为冲正累计总金额、C为累加当前冲正金额后的总金额,首先,increment A到B,返回C值,查询有效时间段内,时间标识key的累计值小于等于(C-A)的行为数据,然后每个行为数据的累计值+A,放入集合中,删除小于当前累计值的其他累计值。
208、确定待识别行为数据的时间标识。
本步骤与图1所示的步骤101方法相同,在此不再赘述。
209a、根据扫描式滑动区间模式对时间顺序下的行为数据的累计值按照第一预设窗口长度进行滑动读取。
对于本发明实施例,由于不同的业务需求对营销策略的影响,可以选择不同的时间窗口读取模型进行读取。所述扫描式滑动区间模式即为按照第一预设窗口长度对存储在redis或MongoDB中带有时间标识的行为数据按照窗口长度中的时间标识一组一组进行读取,如图5所示,其中,预设窗口长为一次读取数据时的时间标识对应的长度,可以为1分钟,也可以为5分钟,本发明实施例不做具体限定。例如,第一个时间窗口显示的时间标识有a、b、c、d,窗口长度为1分钟,则读取完这1分钟内的时间标识a、b、c、d的行为数据的累计值,再读取下1分钟时间标识为e、f、g、h的行为数据的累计值,依次类推。
例如,如图6所示,Sorted-Set中添加、删除或更新一个行为数据都是非常快速的,其时间复杂度为集合中行为数据的对数,由于Sorted-Sets中的行为数据在集合中的位置是有序的,因此,即便是访问位于集合中部的行为数据也仍然是非常高效的。减少网络、IO等应用服务器之间交互带来的无谓压力。获取方式如下:A、5分钟以前累计金额:ZREVRANGEBYSCORE key 5 0LIMIT 0 1;B、5分钟以内累计金额:(ZREVRANGEBYSCORE key 10 5 LIMIT 0 1)–(ZREVRANGEBYSCORE key(5 0LIMIT 0 1)。
对于本发明实施例,与步骤209a并列的步骤209b、根据周期性特定范围模式对时间顺序下的行为数据的累计值按照第二预设窗口长度进行定时读取。
对于本发明实施例,由于不同的业务需求对营销策略的影响,可以选择不同的时间窗口读取模型进行读取。周期性特定范围模式即为按照第二预设窗口长度对存储在redis或MongoDB中带有时间标识的行为数据按照窗口中特定个数的时间标识一个一个进行读取,如图7所示,预设窗口长为一次读取数据时的时间标识对应的长度,可以为1分钟,也可以为5分钟,本发明实施例不做具体限定。例如,时间标识为a、b、c、d、e、f、g,第一个时间窗口对应时间标识为a、b、c、d,当读取完全部的行为数据的累计值时,按照窗口大小1分钟的移动范围,将窗口移动至对应时间标识为b、c、d、e,将时间标识e对应的行为数据累计值读取完毕后,依次类推。
进一步地,本发明实施例还包括:根据不同的业务场景、行为特征、第一预设窗口长度、第二预设窗口长度为所述扫描式滑动区间模式及所述周期性特定范围模式选取存储累计值以及读取累计值的程序引擎。
对于本发明实施例,为了优化通过扫描式滑动区间模式及周期性特定范围模式识别行为数据的效率及准确性,可以分别对扫描式滑动区间模式及周期性特定范围模式选择不同的程序引擎来执行具体的读取、存储等程序。其中,程序引擎包括搜索聚合引擎、跨度排序引擎,根据不同业务场景、行为特征、第一预设窗口长度、第二预设窗口长度来选择引擎的准则可以设置为:时间频次高场景优先使用跨度排序算法,反之使用搜索聚合算法;秒、分、时、天时间窗口单位优先使用搜索聚合,月、年时间窗口单位优先使用跨度排序;窗口步长m>30的优先使用跨度排序,反之优先使用搜索聚合。例如,跨度排序算法适用于窗体大,步长短的数据分析,比如物业当前时间40分钟内收单次数;搜索聚合法适用于窗体小,步长长的数据累计查询,比如当前业务前3月到前5月物业缴费的金额。
需要说明的是,针对不同的引擎进行行为数据的存储过程不同,例如,搜索聚合引擎实现redis存储包括:创建Storm实时计算拓扑流;通过哈希表赋予具有代表某一业务特性的key,如赋予享有电商大促打折优惠的新物业业主人群,代号RQ-001,统一内部ID:80001,其key设置为80001RQ-001;组装存储map里面键值对key(通过滑动设定的原时间单位维度换算),例如:通过恒腾密蜜APP注册成的新业主注册时间为统计维度,注册时间是2017年9月24号,20点00分14秒,若步长的单位设定为小时,转换为field就是1506254400000,若步长的单位设定为天,转换为field是1506182400000;通过redis命令:HINCRBYFLOAT KEY_NAME FIELD_NAME INCR_BY_NUMBER采用增量increment累计数,对应redis的api:hincrbyfloat(key,insertion,value);删除无效时间数据,这个查询key下所有数据,通过redis命令:HGETALL[key],删除无效数据,通过redis命令:HDEL key field2[field2];设置这个map的过期时间,好释放空间,通过redis命令:EXPIRE[key seconds]。搜索聚合引擎实现MongoDB存储包括:哈希map使用的数据类型BSON;mongoDB可以根据列的范围带条件的查出有效时间的值;通过find条件检索,具体实现如下:mongodb数据库的查询操作即使用find()或者findOne()函数,也可根据不同的条件进行查询。
另外,跨度排序引擎实现redis存储包括:查看需要插入的分数列上是否有值,通过redis命令:ZCOUNT[key min max],对应redis的api:zrangeByScore(key,insertion,insertion);zset的特性(不允许重复的行为数据出现在一个Set中)使这里同时间标识下不能直接修改对应的值,必须要先删除,所以先删除同时间维度下数据并返回最大成员,删除命令:ZREM key member[member...],对应redis的api:zrem(key,lo);在一种业务情况下,可能会产生数据冲突问题,所以必须要解决先修复冲突数据,问题是插入时间不一定是最新的时间,所有要修复插入时间后面的数据(例如对冲正订单的计算),也就是每个累计值都累加下,操作命令:ZREM key member[member...],然后ZADD key score1member1[score2member2],对应redis的api:zrem(key,lo1)、zadd(key,lo2);插入累计数据,插入redis命令:ZADD key score1 member1[score2 member2],对应redis的api:zadd(key,insertion,String.valueOf(insertionValueOf));删除无效时间数据,这个查询key下所有数据,通过redis命令:HGETALL[key],删除无效数据,通过redis命令:HDEL key field2[field2];设置这个map的过期时间,好释放空间,通过redis命令:EXPIRE[key seconds]。
借由上述技术方案,本发明提供的另一种行为数据的识别方法,本发明可以使用redis和MongDB的存储特征,利用不同的程序引擎执行扫描式滑动区间模式及周期性特定范围模式对时间标识下行为数据的读取,确保多场景、多维度、时间范围自定义、数据实时性和响应高效性的要求,为经过在真实环境中大量营销运营场景提供撑,准确性高,从而实现多样化的行为数据查询,满足不同业务需求的变化,无需技术人员重新开发对应的程序,降低资源消耗,而预设非关系型数据库可以最大化拓展,减少系统卡顿,提高系统运行速度,从而提高行为数据的识别效率。
进一步的,作为对上述图1所示方法的实现,本发明实施例提供了一种行为数据的识别装置,如图8所示,该装置包括:确定单元31、读取单元32。
确定单元31,用于确定待识别行为数据的时间标识,所述时间标识用于标识不同业务场景下用户进行交易时不同行为特征对应行为数据的时间点;
读取单元32,用于通过预设非关系型数据库中的预设时间窗口模式对所述时间标识对应行为数据进行读取,所述预设时间窗口模式为按照时间序列对存储在预设非关系型数据库中多个连续的行为数据的累计值进行识别的方式。
在具体的应用场景中,如图9所示,所述装置还包括:
统计单元33,用于统计不同时间标识下的行为数据的累计值;
第一判断单元34,用于判断所述时间标识是否处于无效时间范围,若处于无效时间范围,则保留所述无效时间范围中最大累计值及对应的时间标识,并删除所述无效时间范围中其余的累计值及对应的时间标识;
存储单元35,用于按照时间序列将不同时间标识下的行为数据的累计值存储至预设非关系型数据库中。
在具体的应用场景中,所述装置还包括:
查找单元36,用于若待冲正的时间标识处于有效时间范围内,根据业务流程查找所述有效时间范围内时间标识下的累计值小于或等于预设阈值的行为数据;
更新单元37,用于将所述行为数据的累计值与当前冲正金额进行相加,并更新至所述预设非关系型数据库中。
第二判断单元38,用于判断所述预设非关系型数据库中不同时间标识下的行为数据的累计值是否存在于预设分布式数据库中;
处理单元39,用于若不存在,则所述累计值更新至所述预设分布式数据库中,并对不同时间标识下的行为数据进行冲正处理。
在具体的应用场景中,所述读取单元32包括:
滑动读取模块3201,用于根据扫描式滑动区间模式对时间顺序下的行为数据的累计值按照第一预设窗口长度进行滑动读取;或,
定时读取模块3202,用于根据周期性特定范围模式对时间顺序下的行为数据的累计值按照第二预设窗口长度进行定时读取。
在具体的应用场景中,统计单元33包括:
获取模块3301,用于获取不同时间标识下的行为数据;
确定模块3302,用于对相同时间标识下的不同行为数据的累计值分别进行排序,将最大累计值确定为所述时间标识下的行为数据的累计值。
在具体的应用场景中,所述装置还包括:
选取单元310,用于根据不同的业务场景、行为特征、第一预设窗口长度、第二预设窗口长度为所述扫描式滑动区间模式及所述周期性特定范围模式选取存储累计值以及读取累计值的程序引擎。
借由上述技术方案,本发明提供的一种行为数据的识别装置,本发明可以使用redis和MongDB的存储特征,利用不同的程序引擎执行扫描式滑动区间模式及周期性特定范围模式对时间标识下行为数据的读取,确保多场景、多维度、时间范围自定义、数据实时性和响应高效性的要求,为经过在真实环境中大量营销运营场景提供撑,准确性高,从而实现多样化的行为数据查询,满足不同业务需求的变化,无需技术人员重新开发对应的程序,降低资源消耗,而预设非关系型数据库可以最大化拓展,减少系统卡顿,提高系统运行速度,从而提高行为数据的识别效率。
基于上述如图1所示方法,相应的,本发明实施例还提供了一种存储设备,其上存储有计算机程序,该程序被处理器执行时实现以下步骤:确定待识别行为数据的时间标识,所述时间标识用于标识不同业务场景下用户进行交易时不同行为特征对应行为数据的时间点;通过预设非关系型数据库中的预设时间窗口模式对所述时间标识对应行为数据进行读取,所述预设时间窗口模式为按照时间序列对存储在预设非关系型数据库中多个连续的行为数据的累计值进行识别的方式。
基于上述如图1所示方法和如图4所示装置的实施例,本发明实施例还提供了一种终端设备的实体装置,如图10所示,该云端服务器包括:处理器41、存储设备42、及存储在存储设备42上并可在处理器上运行的计算机程序,所述处理器41执行所述程序时实现以下步骤:收集不同客户端发送的伪基站短信的短信特征信息;根据所述短信特征信息,确定伪基站对应的基站位置信息;根据所述基站位置信息,确定伪基站的分布情况以及历史轨迹;该终端设备还包括:总线43,被配置为耦接处理器41及存储设备42。
在此提供的算法和显示不与任何特定计算机、虚拟系统或者其它设备固有相关。各种通用系统也可以与基于在此的示教一起使用。根据上面的描述,构造这类系统所要求的结构是显而易见的。此外,本发明也不针对任何特定编程语言。应当明白,可以利用各种编程语言实现在此描述的本发明的内容,并且上面对特定语言所做的描述是为了披露本发明的最佳实施方式。
在此处所提供的说明书中,说明了大量具体细节。然而,能够理解,本发明的实施例可以在没有这些具体细节的情况下实践。在一些实例中,并未详细示出公知的方法、结构和技术,以便不模糊对本说明书的理解。
类似地,应当理解,为了精简本公开并帮助理解各个发明方面中的一个或多个,在上面对本发明的示例性实施例的描述中,本发明的各个特征有时被一起分组到单个实施例、图、或者对其的描述中。然而,并不应将该公开的方法解释成反映如下意图:即所要求保护的本发明要求比在每个权利要求中所明确记载的特征更多的特征。更确切地说,如下面的权利要求书所反映的那样,发明方面在于少于前面公开的单个实施例的所有特征。因此,遵循具体实施方式的权利要求书由此明确地并入该具体实施方式,其中每个权利要求本身都作为本发明的单独实施例。
本领域那些技术人员可以理解,可以对实施例中的设备中的模块进行自适应性地改变并且把它们设置在与该实施例不同的一个或多个设备中。可以把实施例中的模块或单元或组件组合成一个模块或单元或组件,以及此外可以把它们分成多个子模块或子单元或子组件。除了这样的特征和/或过程或者单元中的至少一些是相互排斥之外,可以采用任何组合对本说明书(包括伴随的权利要求、摘要和附图)中公开的所有特征以及如此公开的任何方法或者设备的所有过程或单元进行组合。除非另外明确陈述,本说明书(包括伴随的权利要求、摘要和附图)中公开的每个特征可以由提供相同、等同或相似目的的替代特征来代替。
此外,本领域的技术人员能够理解,尽管在此所述的一些实施例包括其它实施例中所包括的某些特征而不是其它特征,但是不同实施例的特征的组合意味着处于本发明的范围之内并且形成不同的实施例。例如,在下面的权利要求书中,所要求保护的实施例的任意之一都可以以任意的组合方式来使用。
本发明的各个部件实施例可以以硬件实现,或者以在一个或者多个处理器上运行的软件模块实现,或者以它们的组合实现。本领域的技术人员应当理解,可以在实践中使用微处理器或者数字信号处理器(DSP)来实现根据本发明实施例的行为数据的识别方法及装置中的一些或者全部部件的一些或者全部功能。本发明还可以实现为用于执行这里所描述的方法的一部分或者全部的设备或者装置程序(例如,计算机程序和计算机程序产品)。这样的实现本发明的程序可以存储在计算机可读介质上,或者可以具有一个或者多个信号的形式。这样的信号可以从因特网网站上下载得到,或者在载体信号上提供,或者以任何其他形式提供。
应该注意的是上述实施例对本发明进行说明而不是对本发明进行限制,并且本领域技术人员在不脱离所附权利要求的范围的情况下可设计出替换实施例。在权利要求中,不应将位于括号之间的任何参考符号构造成对权利要求的限制。单词“包含”不排除存在未列在权利要求中的元件或步骤。位于元件之前的单词“一”或“一个”不排除存在多个这样的元件。本发明可以借助于包括有若干不同元件的硬件以及借助于适当编程的计算机来实现。在列举了若干装置的单元权利要求中,这些装置中的若干个可以是通过同一个硬件项来具体体现。单词第一、第二、以及第三等的使用不表示任何顺序。可将这些单词解释为名称。
- 还没有人留言评论。精彩留言会获得点赞!