基于多尺度卷积神经网络的实时人体异常行为识别方法与流程
本发明涉及计算机视觉和机器学习领域,特别涉及视频中人体异常行为的检测技术。
背景技术:
火车站、银行、机场等对安全性要求较高的场合对人体行为识别有巨大的需求,如果系统可以识别人体行为,就可以自动判定异常情形并报警,从而大大降低人力成本,并提升监控力度,做到在线监控,实时报警。
传统人体行为识别的方案基本都是基于背景建模和和特征匹配的,该类方案含三个步骤:第一步是主要提取时空特征点,即具备时间和空间特性的像素点,使用背景差分或者光流法进行背景的建模和前景的提取;第二步是根据选定的特征,利用第一步获取的视频的特征点对其特征点周围区域的视频进行特定转换和处理,来获取描述特定行为的特征,其中多数是基于静态场景和物体识别技术;第三步是将这些特征输入分类器进行训练,获得分类器并应用于识别中。
专利号为101719216A提出了一种基于模板匹配的运动人体异常行为识别方法,该方案的主要步骤是,先用高斯滤波方法对视频进行预处理和去噪,再将预处理过后的图像分割为W*W的小分区,对每个分区进行高斯背景建模;将运动目标提取出来后在HSV色彩空间下去除阴影,将这个运动目标与建立的标准模型库进行匹配比较,以此来判断行为的类别。
但是上述方法均存在以下问题:
1、在高斯背景建模的方法中如果前景与背景的颜色相同或相近,在判断前景和找寻连通区域时,很容易将部分前景错误的判断为背景,导致提取区域的缺失;
2、使用提取图片的特征再进行比对的方法,这在一定程度上不能很好的把时间域的特性利用起来;
3、行为识别上使用模板匹配的方式,由于训练集视频的特征分布和真实监测环境的差异,并不能很好的识别一些与样本库中样本有差异的情况,比如视频角度的变化、行为动作的变化,容易出现误报和漏报。
技术实现要素:
本发明为解决上述技术问题,提出了一种基于多尺度卷积神经网络的实时人体异常行为识别方法,使用了卷积神经网络取代传统的特征提取算法,并且将卷积神经网络进行改进,增加了三维卷积、三维下采样、NIN、三维金字塔结构,使得卷积神经网络可以对人体异常行为有更强的特征提取能力;在特定的视频集中训练,获得更具有分类能力的特征,增强整个识别算法的鲁棒性和准确性;另外,进行了GPU加速,可以满足多路视频的实时监测。
本发明采用的技术方案是:基于多尺度卷积神经网络的实时人体异常行为识别方法,包括:
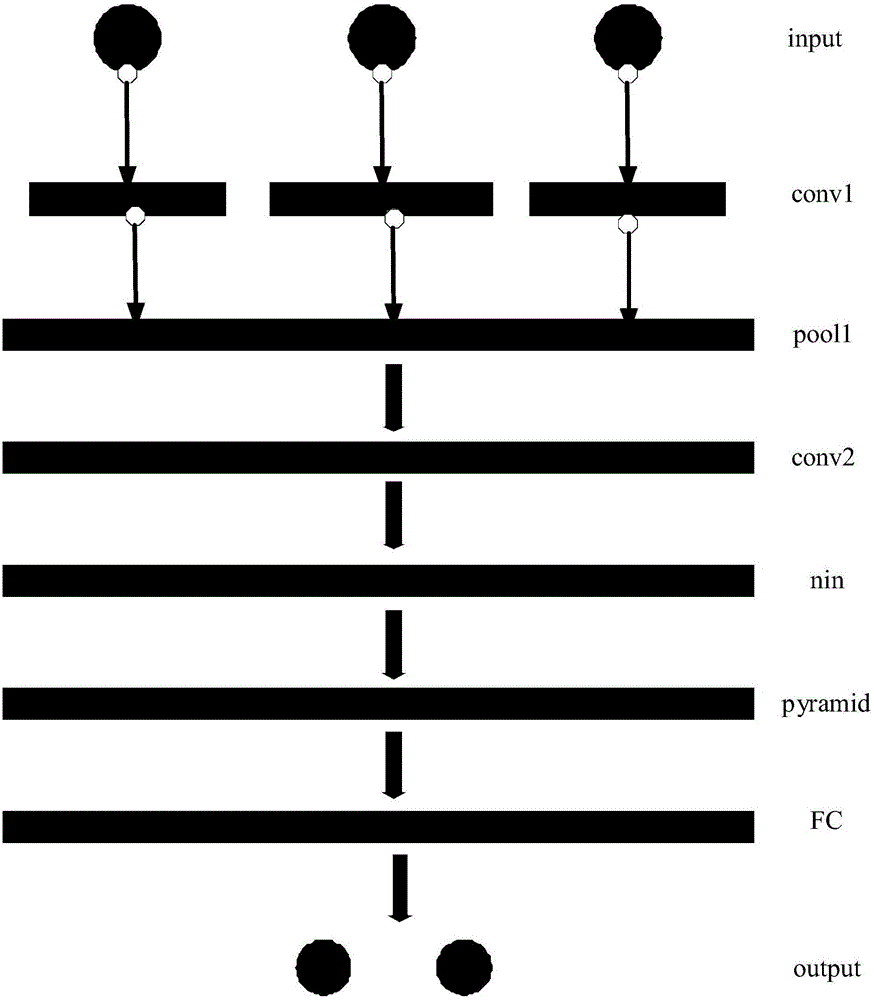
S1、确定多尺度卷积神经网络的结构;包括第一层、第二层、第三层、第四层、第五层、第六层以及第七层;所述第一层是输入层,包含三个通道,该三个通道分别接受灰度转换后的当前时刻上一秒的视频图像信息和该视频计算出的稠密光流的两个通道Ox,Oy;第二层是三维卷积层,用数量为n、尺度为cw*ch*cl的卷积核对第一层输入的视频和光流进行卷积运算;第三层是三维下采样层,用尺度为pw,ph,pl的卷积核对第二层的输出进行最大池化;第四层是三维卷积层,用于对第三层的输出进行卷积运算;第五层是NIN层,采用由两层感知机卷积层的网络组成,用于根据第四层的输出提取人体行为的非线性特征;第六层是金字塔下采样层,由不同大小的三维下采样层组成,用于对第五层输出的人体行为的非线性特征进行下采样处理;第七层是全连接层,根据第六层的输出得到固定维度的特征向量;
其中,Ox表示光流在x方向轴上的分量,Oy表示光流在y方向轴上的分量;cw表示卷积核的宽度,ch表示卷积核高度,cl表示卷积核在时间轴上的长度;
S2、多尺度卷积神经网络的离线训练;通过在异常人体行为库中进行学习,得到网络参数模型结合步骤S1确定的多尺度卷积神经网络的结构作为在线识别时的模型文件;
S3、卷积神经网络的在线识别;通过将视频输入模型文件得到作为识别依据的特征向量。
进一步地,第三层所述的三维下采样采用以下公式:
其中,x′表示输入向量,y′表示采样后得到的输出,s、t和r分别是图像宽度、高度跟视频时间长度三个方向的采样步长;在三维卷积中上一层输出的特征图为二维的矩阵,S1、S2分别为该二维矩阵的总行数跟总列数,m、n则代表该矩阵中的第m行、n列,且0≤m<S1,0≤n<S2;S3代表视频的时间长度,也就是视频共长S3帧,l代表第l帧,且0≤l<S3;i表示该二维矩阵行数序号;j表示该二维矩阵列数序号;k表示视频帧序号。
进一步地,所述下采样处理具体为:对第五层输出的人体行为的非线性特征进行多种窗口尺寸和步长的重叠下采样,然后将得到的特征图的每个单元拼接成一个向量,作为第六层的输出。
进一步地,步骤S2所述的网络参数模型;具体包含以下分步骤:
S21、加载收集并标注好的样本库,所述样本库包含正样本和负样本,所述正样本为异常的人体行为视频,负样本为正常的人体行为视频;
S22、加载由步骤S1确定的多尺度卷积神经网络;
S23、将视频进行预处理后输入多尺度卷积神经网络;
S24、判断多尺度卷积神经网络的误差是否小于阈值,若是则转至步骤S25;否则将多尺度卷积神经网络的输出结果与真实标签的差值反向传导进入多尺度卷积神经网络,并调整网络参数,执行步骤S23重新训练;
S25、保存多尺度卷积神经网络的网络参数。
更进一步地,所述预处理为:转换为灰度色彩空间,并减去均值,提取灰度信息和光流信息。
进一步地,步骤S3所述的卷积神经网络的在线识别;具体包括以下分步骤:
S31、从摄像头或者视频文件中获取一秒的视频V;
S32、将步骤S31获取的视频根据需求缩放到固定分辨率;
S33、将步骤S32缩放后的视频先进行灰度化处理,并计算稠密光流得到两个光流通道Ox,Oy;
S34、将步骤S33中灰度化处理后得到的图像进行白化处理;
S35、将由步骤S34白化处理后得到的图像、以及步骤S33得到的Ox,Oy分别输入到多尺度卷积神经网络中,通过网络计算后输出特征向量F;
S36、将视频特征F输入到分类器C中,判断该视频的行为种类,如果属于异常行为则处理异常。
本发明的有益效果:本申请采用卷积神经网络取代了传统的特征提取算法,并将卷积神经网络改进,适应人体行为分类的需求;具体的增加了三维卷积、三维下采样、NIN、三维金字塔结构,使得卷积神经网络可以对人体异常行为有更强的特征提取能力;在特定的视频集中训练,获得更具有分类能力的特征,增强整个识别算法的鲁棒性和准确性;另外,为了满足实际应用的需求进行了GPU加速,可以满足多路视频的实时监测;
本申请的方法具有以下优点:
1、用卷积神经网络代替了传统的特征提取的方法,使得卷积神经网络可以对人体异常行为有更强的特征提取能力;
2、使用了三维卷积提取了时间域的信息,更好地捕获运动信息;
3、采用三维下采样技术不仅大大降低了计算量,而且引入了算法在时间域上的时间不变性,提升了识别的稳定性和更高的识别率;
4、采用NIN可以使得本申请提出的多尺度卷积神经网络的结构提取更加复杂的人体行为非线性特征;
5、采用金字塔结构提升了系统的灵活性,使得不同分辨率和时长的视频片段可以不做任何改动都能使用该系统,提升了系统的灵活性和应用范围;
6、在输入中增加了光流通道,让整个算法在时间域上有更强的识别能力;
7、网络采用了特定的异常人体行为识别库进行学习,通过尽可能增加样本数量和增加样本的场景种类,能够更好地训练模型;
8、利用gpu加速使得整个识别算法可以满足多视频实时检测。
附图说明
图1为本发明提供的多尺度卷积神经网络架构示意图。
图2为本发明提供的三维卷积与二维卷积的对比图;
其中,a图为三维卷积的示意图,b图为二维卷积的示意图。
图3为本发明提供的线性卷积和MLP卷积示意图。
图4为本发明提供的金字塔结构示意图。
图5为本发明提供的参数模型训练流程图。
图6为本发明提供的在线识别流程图。
具体实施方式
为便于本领域技术人员理解本发明的技术内容,下面结合附图对本发明内容进一步阐释。
本发明的技术方案为:基于多尺度卷积神经网络的实时人体异常行为识别方法,包括:
S1、确定多尺度卷积神经网络的结构;如图1所示,包括第一层、第二层、第三层、第四层、第五层、第六层以及第七层;每一层均包含若干节点,节点数目决定了提取特征种类的多少,数据越多,提取的特征信息越多,但计算量也越大。
第一层是输入层input,包含三个通道,该三个通道分别接受灰度转换后的当前时刻上一秒的视频图像信息和该视频计算出的稠密光流的两个通道Ox,Oy;在原有视频输入通道的基础上添加两个光流通道可以较大程度上增强对行为动作的敏感性,在行为识别中有更高的识别率。
第二层conv1是三维卷积层,用数量为n、尺寸为cw*ch*cl的卷积核对第一层输入的视频和光流进行卷积运算;本申请采用三维卷积运算加入了时间域信息,能更好地捕获了运动信息。
具体内容为:在处理视频的任务中,需要从多个连续的帧捕获运动的信息,本申请不同于其他的卷积神经网络,使用了三维的卷积层。三维卷积的公式如公式(1):
其中,w为卷积核的权重,u是输入矢量,代表三个通道的图像灰度值、光流的水平分量和垂直分量,yefg是输出,上标e,f,g代表指相应位置的元素值,即第g帧第e行第f列的元素,P、Q、R分别是三个维度的大小,在三维卷积中上一层输出的特征图feature map为二维的矩阵,P、Q分别为该二维矩阵的总行数跟总列数,小写p、q则代表该矩阵中的第p行、q列,且0≤p<P,0≤q<Q;R代表视频的长度,也就是视频共长R帧,小写r代表第r帧,且0≤r<R。
这里的三维卷积运算可以看作用三维的核来卷积多个帧累积起来的立方体,如图2a所示为三维卷积的示意图,坐标轴表示出了三个维度:图像的宽度、高度和视频的时间,下方的立方体表示卷积的输入,上方的立方体表示卷积的输出。图2b是二维卷积的示意图,它的输入与输出都是二维的矩形,只包括图像的宽度、高度信息,无时间域的信息。用三维卷积,每个卷积层的feature map是关联到前一层的多个连续帧的,这样就捕获了运动信息。
第三层pool1是三维下采样层,用尺度为pw,ph,pl的卷积核进行最大池化;本申请采用的三维下采样技术不仅大大降低了计算量,而且引入了算法在时间域上的时间不变性,提升了识别的稳定性和更高的识别率。
具体内容为:和三维的卷积一样,在卷积神经网络处理视频的时候,下采样层也需要拓展到三维。处理图片的卷积神经网络的下采样层,可以使得数据量急剧减小、加速后面的计算,同时也使得网络具有一定的不变性,这里的不变性是空间域上的不变性。而在处
理视频的时候,在时间域上也需要一定的不变性,并且视频的数据处理比单帧的图片要大很多,所以,必须要把下采样也拓展到三维。三维的重叠最大下采样的公式如(2):
其中,x′为三维输入向量,表示前一个卷积层提取的特征(feature map),即第二层三维卷积提取的特征,y′为采样后得到的输出,s、t和r分别是图像宽度、高度跟视频时间长度三个方向的采样步长;在三维卷积中上一层输出的特征图feature map为二维的矩阵,即本申请中的第二层输出的特征图为二维矩阵,S1、S2分别为该二维矩阵的总行数跟总列数,m、n则代表该矩阵中的第m行、n列,且0≤m<S1,0≤n<S2;S3代表视频的长度,也就是视频共长S3帧,小写l代表第l帧,且0≤l<S3;i表示该二维矩阵行数序号,i=1,2,···,S1;j表示该二维矩阵列数序号,j=1,2,···,S2;k表示视频帧序号,k=1,2,···,S3;虽然在第三层的三维卷积运算中S1、S2、S3、m、n、l与第二层的三维卷积运算中P、Q、R、p、q、r所对应表达相同的含义,但是在第二层和第三层中各自的取值并不相同,这里采用不同的字母用以区分;采样后的feature map数据量成倍减少,计算量也会大大减小,同时,网络对在时间域上的变化更加鲁棒。
第四层conv2是三维卷积层,与第二层类似,用于对第三层的输出做卷积运算。
第五层是NIN(Network in Network)层,采用由两层的感知机卷积层的网络组成,用于根据第四层的输出提取人体行为的非线性特征;使用NIN可以使得本系统可以提取更加复杂的人体行为非线性特征。
具体内容为:本申请中采用了NIN结构改进了整个网络结构。卷积神经网络中的卷积是一个广义线性模型(generalized linear model,GLM)。GLM只在样本是线性可分的时候有好的抽象。卷积神经网络的卷积暗含了这个线性可分的假设,但人体行为模型并不满足该假设。所以,把GLM替换成具有非线性表征能力的模型能够提升算法的抽象能力。
前向神经网络或者多层感知机(MLP)是一个抽象能力强的非线性模型,如果把用普通的线性卷积核替换成用MLP做非线性的卷积操作,必然会增加模型的抽象能力。网络中用了MLP做卷积的层这里称为MLP卷积层,只用线性核做卷积的卷积层称为线性卷积层。使用了这种MLP卷积层的网络这里称为NIN(Networks in Networks)。
经典的卷积操作和MLP卷积操作如图3所示。经典的卷积是对一块区域的输入做线性加权求和,并通过一个非线性激活函数得到输出,拟和简单的非线性模型。MLP卷积使用一个由多个全连接层构成的多层感知机在上一层的feature map上进行滑动计算,再通过一个非线性激活函数(这里采用ReLU),这样就得到了当前层的feature map。MLP卷积的计算方式如(3):
其中,(i,j)是当前层的feature map的像素索引,xij是中心在(i,j)的输入块,kn是当前层的feature map的索引,n是MPL的层数。因为是使用的ReLU(Y=max(0,X))激活函数,所以公式中使用与0比较的最大值。
从另一种观点来看,MLP卷积层相当于多个线性卷积层,假如一个MLP有n层,则一个MLP卷积层可以看成是n个线性卷积层,只是这n个卷积层的后n-1层是1×1的核,而且每个feature map只卷积上一层的部分feature map,使用NIN可以使得本系统可以提取更加复杂的人体行为非线性特征。
第六层pyramid是三维金字塔下采样层,由不同大小的三维下采样层组成,用以对第五层的输出进行下采样处理,得到不同分辨率的输出feature map;本申请采用的三维金字塔下采样层这一技术提升了系统的灵活性,使得不同分辨率和时长的视频片段可以不做任何改动都能使用该系统,提升了系统的灵活性和应用范围。
具体内容为:本申请的三维金字塔下采样层是由多种分辨率的feature map组成,以往的下采样层都是用相同的采样尺度并且输入的feature map有相同的尺寸,所以得到的feature map都有相同的分辨率。而金字塔下采样层使用多种采样尺度来得到一系列固定的不同分辨率的feature map。
行为识别的样本都是一些视频片段,可能有不同的分辨率,也可能不同的视频长度。这些差异性,使得传统的卷积神经网络没有办法处理,因为传统的卷积神经网络每个feature map都是固定大小的。造成传统卷积神经网络无法处理不同分辨率和长度视频的原因不在于卷积层和下采样层,而是在全连接层(图1中的FC层),因为全连接层的框架是固定的,没有办法改变,导致了该层输入的feature map的尺寸也必须是固定的。而在卷积层,输入的feature map的尺寸不会影响网络的结构,只是输出的feature map的尺寸会随着该层输入的feature map尺寸的变化而变化,因为卷积核只是在输入feature map上滑动。在下采样层,只是把输入feature map按照某种方式来减少尺寸,也不会影响网络的结构。由此看来,就必须在全连接层前进行适当的feature map尺寸的处理,使得不同尺寸的输入feature map得到相同的尺寸。
这种处理可以使用不同窗口大小和不同步长的重叠下采样来实现。以二维情况为例,三维的情况可以很自然的扩展。假设输入的feature map的尺寸为a×a,需要下采样到尺寸n×n,现在使用窗口大小:
滑动的步长为:
式中为向上取整操作,为向下取整操作。比如现在有a=13,n=3,则按照公式(4)和(5)我们得到win=5和str=4。
使用以上的公式来确定窗口大小和滑动步长可以有效的从不同输入尺寸的feature map得到输出尺寸相同的feature map。但是不同的分辨率使用完全相同的尺寸会使得高分辨率的feature map损失太多信息,而低分辨率的feature map可能采样太少而没有不变性,所以,这里采用金字塔的方式。如图4所示。金字塔是由一些不同分辨率的feature map来组成的,既有相对来说大一点的分辨率,也有小的分辨率,中间也有一些过渡大小的分辨率。(如图3中16*256-d,4*256-d,256-d)从输入的feature map想要得到不同分辨率的输出feature map需要进行多种窗口尺寸和步长的重叠下采样。得到的这些feature map的每个单元再拼接成一个向量,如图4的L-Fix层,然后,再接入全连接层。在图4中的例子是一个3级金字塔,固定的分辨率分别为3×3,2×2,1×1,并且上一层有256个feature map。
金字塔层的输出单元总个数都是固定的,所以能够以固定的输出feature map连接全连接层,而且,金字塔模型的引入,会形成多种分辨率的feature map,也避免了规整不同分辨率的输入所带来的影响。
在本发明中,使用的都是三维feature map,把金字塔模型拓展成三维也非常的方便,每一维的窗口大小和步长都根据公式(4)和(5),通过计算输入与输出的边长的比值E,再通过向上取整获得窗口大小,向下取整获得步长。
第七层FC是全连接层,用于输出固定维度的特征向量,提供给分类器(softmax)作为识别人体行为的分类特征。
S2、多尺度卷积神经网络的离线训练;通过在异常人体行为库中进行学习,得到网络参数模型结合步骤S1确定的多尺度卷积神经网络的结构作为在线识别时的模型文件;如图5所示所述参数模型具体包含以下分步骤:
S21、加载标注好的样本库,所述样本库包含正样本和负样本,所述正样本为异常的人体行为视频,负样本为正常的人体行为视频;
S22、加载由步骤S1确定的多尺度卷积神经网络;
S23、将视频进行预处理后输入多尺度卷积神经网络;所述预处理为:转换为灰度色彩空间,并减去均值,提取灰度信息和光流信息;
S24、判断多尺度卷积神经网络的输出结果与真实标签的差值是否小于阈值,若是则转至步骤S25;否则将多尺度卷积神经网络的输出结果与真实标签的差值反向传导进入多尺度卷积神经网络,并调整网络参数,执行步骤S23;这里的网络参数包括卷积神经网络的权重系数和分类器的连接权重,学习到合适的参数是多尺度卷积神经网络的离线训练的目的。
S25、保存多尺度卷积神经网络的网络参数;这些网络参数将用于行为检测。
S3、卷积神经网络的在线识别;通过将视频输入模型文件得到作为识别依据的特征向量。如图6所示具体包括以下分步骤:
S31、从摄像头或者视频文件中获取一秒的视频V,若为N帧图像组成,那么就有每一帧图像Vi,i=[1,N];每次针对一秒长度的视频进行人体行为的识别。
S32、将步骤S31获取的视频根据需求缩放到固定分辨率,Vi=resize(Vi)。
S33、将步骤S32缩放后的视频先进行灰度化处理,并计算稠密光流得到两个光流通道Ox,Oy;稠密光流是一种针对视频中的相邻图像进行逐点匹配的图像配准方法,不同于稀疏光流只针对图像上若干个特征点,稠密光流计算图像上所有的点的偏移量,从而形成一个稠密的光流场。通过这个稠密的光流场,可以进行像素级别的图像配准,所以其配准后的效果也明显优于稀疏光流配准的效果。
S34、将步骤S33中得到的经灰度化处理后的图像H进行白化处理;即减去每一帧图像的均值Hi(mean),Hi:=Hi-Hi(mean),再将H归一化,H:=(H-0)/(256-0);白化和归一化的目的是将输入的信息进行一定程度的去噪,也便于之后卷积神经网络的运算。
S35、将由步骤S34得到的经白化处理的图像、以及步骤S33得到的Ox,Oy分别输入到多尺度卷积神经网络中,通过网络计算后输出特征向量F,F就是这一秒的视频提取出的用于对视频人体行为分类的特征;
S36、将视频特征F输入到分类器C中,判断该视频的行为种类,如果属于异常行为则处理异常。
这样记录结果后再循环到步骤S31获取下一秒的视频。卷积神经网络的在线识别过程中每次针对一秒长度的视频进行人体行为的识别;每一秒的视频缩放到固定的分辨率后,采用稠密光流算法,计算光流特征;接着将视频灰度化后与光流特征一起进行白化处理和归一化处理;之后会通过卷积神经网络得到高维的抽象特征。这些输出的特征就是最后人体行为分类器的输入。
本申请中的使用的卷积神经网络拥有很强的特征提取能力,所以可以训练出识别能力优秀的多种不同行为的分类器。为了满足不同的应用场景可以将卷积神经网络输出的特征向量输入不同的分类器中,例如C1分类器(分类打斗与正常行为)、C2分类器(分类打斗、奔跑、正常行为)。这样的组合将具有更强的环境适应能力和应用价值。
在本发明中考虑到使用的卷积神经网络,参数数量大、三维卷积运算计算消耗大以及网络结构复杂的特点,采用了GPU加速的技术。在本发明中使用了CUDA库和cuDNN库优化了整个算法的识别速度。CUDA库在整个网络运算中主要用于卷积运算,先根据矩阵大小分配相应的显存,之后在多个GPU核心上并行的分配多个任务,实际就是把整个矩阵拆分为多个小矩阵,而cuDNN库主要是进一步优化三维运算时的计算效率。表1是一分钟的视频的识别速度。
表1并行检测速度表
从表中不难发现,本算法在同时检测多个视频时,利用GPU加速技术,可以满足接近20个视频的实时检测,相比传统人体行为识别的算法反而在识别速度上有优势。这样的识别速度完全可以在各种真实的应用场景中进行实时检测。
本领域的普通技术人员将会意识到,这里所述的实施例是为了帮助读者理解本发明的原理,应被理解为本发明的保护范围并不局限于这样的特别陈述和实施例。对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的权利要求范围之内。
- 还没有人留言评论。精彩留言会获得点赞!