一种数据处理方法和系统与流程
本发明涉及信息技术领域,尤其涉及一种数据处理方法及数据处理系统。
背景技术:
近年来,大数据处理与分析已经成为全球性问题,随着经济社会信息化和自动化水平不断提高,在公共管理、公共服务、科学研究、商业应用等许多领域面临大数据问题,需要有各种针对性和经济有效的解决方案。大数据平台为行业大数据提供处理能力,集数据接入、数据处理、数据存储、查询检索、分析挖掘、应用接口等功能为一体。
在数据处理领域,当前的环境越来越重视数据的累积,随着数据量的越来越大,对处理数据的能力以及对系统的基本架构有更高的要求,需要更快的处理速度、更大的数据存储能力和易维护性。
在一些业务场景下,需要记录关键字段的数据变化历史信息,以满足用户的需求,即需要周期性地对数据库中的数据进行更新。在一些大数据平台中,文件系统是基于分布式文件存储的,即文件被存在了不同的节点,传统的对这样的数据平台的数据进行历史更新的处理方式,需要对所说有数据逐行扫描,即在存储区域内从第一个文件的第一行开始扫描,直到找到需要的数据进行修改,但是面对日益增长的数据量和日益复杂的业务,尤其是数据量巨增的大数据时代,这样进行所有数据的扫描,效率低,耗时长,尤其是数据量越大,需要的查询时间和反馈时间越长,无法满足目前数据量越来越大的情形下的时效需求,导致现有的数据处理系统由于计算量大,以及耗时较长等原因,数据处理系统稳定性较差,易出现系统卡顿,甚至卡死的情况。
技术实现要素:
本发明实施例提供一种数据处理方法及数据处理系统,以解决现有的数据处理系统由于数据处理的效率低和耗时长等原因,导致数据处理系统稳定性差的问题。
为了解决上述技术问题,本发明实施例提供了一种数据处理方法,所述方法包括:
接收外部系统传输的第一数据集合;
在数据处理系统中生成与待更新的目标数据集合相关联的第二数据集合;
清空所述目标数据集合中的数据;
使用所述第一数据集合和所述第二数据集合中的数据对所述目标数据集合进行数据更新。
进一步的,在所述在数据处理系统中生成与待更新的目标数据集合相关联的第二数据集合的步骤之前,所述方法包括:
从所述第一数据集合中确定第一关键字或者关键字段;
使用所述第一关键字或者关键字段在所述目标数据集合中进行查询;
若在所述目标数据集合中查询到所述第一关键字或者关键字段,或者查询到与所述第一关键字或者关键字段相匹配的数据,执行所述在数据处理系统中生成与待更新的目标数据集合相关联的第二数据集合的步骤。
进一步的,在所述使用所述第一关键字或者关键字段在所述目标数据集合中进行查询的步骤之后,所述方法包括:
若在所述目标数据集合中未查询到所述第一关键字或者关键字段,并且未查询到与所述第一关键字或者关键字段相匹配的数据,将所述第一数据集合的数据更新至所述目标数据集合中。
进一步的,所述使用所述第一数据集合和所述第二数据集合中的数据对所述目标数据集合进行数据更新的步骤,包括:
从所述第二数据集合中确定第二关键字或者关键字段;
使用所述第二关键字或者关键字段在所述第一数据集合中进行查询;
若在所述第一数据集合中未查询到所述第二关键字或者关键字段,并且在所述第一数据集合中未查询到与所述第二关键字或者关键字段相匹配的数据,将所述第二数据集合中与所述第二关键字或者关键字段相匹配的数据更新至所述目标数据集合中;
将所述第一数据集合中与所述第一关键字或者关键字段相匹配的数据更新至所述目标数据集合中。
进一步的,当所述目标数据集合为拉链数据集合时,所述使用所述第一数据集合和所述第二数据集合中的数据对所述目标数据集合进行数据更新的步骤,包括:
从所述第二数据集合中确定第二关键字或者关键字段;
使用所述第二关键字或者关键字段在所述第一数据集合中进行查询;
若在所述第一数据集合中未查询到所述第二关键字或者关键字段,并且在所述第一数据集合中未查询到与所述第二关键字或者关键字段相匹配的数据,将所述第二数据集合中与所述第二关键字或者关键字段相匹配的数据更新至所述目标数据集合中;
确定所述第二数据集合中与所述第一关键字或者关键字段相匹配的第一拉链数据;
修改所述第一拉链数据中处于开链状态的第一子拉链数据的闭链时间为生成所述第二数据集合的时间,并基于所述第一数据集合中与所述第一关键字或者关键字段相匹配的数据,生成所述第一拉链数据的第二子拉链数据,其中,所述第二子拉链数据的开链时间为生成所述第二数据集合的时间,闭链时间为空或极大值;
若在所述第二数据集合中未查询到与所述第一关键字或者关键字段相匹配的数据,基于所述第一数据集合中与所述第一关键字或者关键字段相匹配的数据生成第二拉链数据,其中,所述第二拉链数据的开链时间为生成所述第二数据集合的时间,闭链时间为空或极大值;
将修改后的第一拉链数据及所述第二拉链数据更新至所述目标数据集合中。
进一步的,在所述清空所述目标数据集合中的数据的步骤之后,所述方法包括:
若检测到对所述目标数据集合进行数据更新时出现更新错误,使用生成的第二数据集合中的数据恢复所述目标数据集合中的数据;或者
若检测到对所述目标数据集合进行数据更新时出现数据更新错误,获取预先备份的备份数据集合,使用所述备份数据集合中的数据恢复所述目标数据集合中的数据。
进一步的,所述在数据处理系统中生成与待更新的目标数据集合相关联的第二数据集合的步骤,包括:
获取接收到所述第一数据集合之前的预设时间段内,已经更新的目标数据集合中存储过的所有数据,或者获取接收到所述第一数据集合后,本次待更新的目标数据集合中的数据,备份已经更新的目标数据集合中存储过的所有数据或者本次待更新的目标数据集合中的数据以生成第二数据集合;或者
获取上一次接收到第一数据集合时生成的第二数据集合,将当前所述目标数据集合中的数据插入至上一次接收到第一数据集合时生成的第二数据集合中,以生成本次的所述第二数据集合。
本发明实施例还提供一种数据处理系统,所述数据处理系统包括:
数据存储模块,用于存储所述数据处理系统的内部数据,以及从外部获取的数据;
业务逻辑模块,用于管控业务逻辑;
数据服务模块,用于向数据处理系统的外部系统提供数据服务;
数据处理引擎模块,用于对数据进行处理。
进一步的,所述数据处理系统包括:
信息交互模块,用于接收用户输入的操作指令,对所述数据处理系统进行管理及设置。
进一步的,所述数据存储模块为分布式文件存储系统,所述数据存储模块存储从外部获取的数据包括直接抽取式数据和文件形式数据。
进一步的,所述业务逻辑模块包括:
存储单元,用于存储所述数据处理系统的业务逻辑,所述业务逻辑包括下述至少之一:调度规则、数据血缘关系、模型元数据和脚本工具。
进一步的,所述数据服务模块包括:
推送单元,用于向数据处理系统的外部系统推送信息队列和数据;
存档单元,用于存储文件形式数据;
数据传输接口单元,用于与数据处理系统的下游系统或者服务系统连接,通过所述接口单元为所述下游系统或者服务系统提供数据。
进一步的,所述数据处理系统还包括自动化工具模块,所述自动化工具模块包括:
参数接收单元,用于接收输入的参数;
脚本生成单元,用于基于预设规则及所述参数,生成自动化工具脚本。
进一步的,所述数据处理引擎模块包括:
接收单元,用于接收外部系统传输的第一数据集合;
生成单元,用于在数据处理系统中生成与待更新的目标数据集合相关联的第二数据集合;
清除单元,用于清空所述目标数据集合中的数据;
第一更新单元,用于使用所述第一数据集合和所述第二数据集合中的数据对所述目标数据集合进行数据更新。
进一步的,所述数据处理引擎模块还包括:
第一确定单元,用于从所述第一数据集合中确定第一关键字或者关键字段;
查询单元,用于使用所述第一关键字或者关键字段在所述目标数据集合中进行查询;
执行单元,用于若在所述目标数据集合中查询到所述第一关键字或者关键字段,或者查询到与所述第一关键字或者关键字段相匹配的数据,执行所述在数据处理系统中生成与待更新的目标数据集合相关联的第二数据集合的步骤。
进一步的,所述数据处理引擎模块还包括:
第二更新单元,用于若在所述目标数据集合中未查询到所述第一关键字或者关键字段,并且未查询到与所述第一关键字或者关键字段相匹配的数据,将所述第一数据集合的数据更新至所述目标数据集合中。
进一步的,所述第一更新单元包括:
第一确定子单元,用于从所述第二数据集合中确定第二关键字或者关键字段;
第一查询子单元,用于使用所述第二关键字或者关键字段在所述第一数据集合中进行查询;
第一更新子单元,用于若在所述第一数据集合中未查询到所述第二关键字或者关键字段,并且在所述第一数据集合中未查询到与所述第二关键字或者关键字段相匹配的数据,将所述第二数据集合中与所述第二关键字或者关键字段相匹配的数据更新至所述目标数据集合中;
第二更新子单元,用于将所述第一数据集合中与所述第一关键字或者关键字段相匹配的数据更新至所述目标数据集合中。
进一步的,当所述目标数据集合为拉链数据集合时,所述第一更新单元包括:
第二确定子单元,用于从所述第二数据集合中确定第二关键字或者关键字段;
第二查询子单元,用于使用所述第二关键字或者关键字段在所述第一数据集合中进行查询;
第三更新子单元,用于若在所述第一数据集合中未查询到所述第二关键字或者关键字段,并且在所述第一数据集合中未查询到与所述第二关键字或者关键字段相匹配的数据,将所述第二数据集合中与所述第二关键字或者关键字段相匹配的数据更新至所述目标数据集合中;
第三确定子单元,确定所述第二数据集合中与所述第一关键字或者关键字段相匹配的第一拉链数据;
修改子单元,用于修改所述第一拉链数据中处于开链状态的第一子拉链数据的闭链时间为生成所述第二数据集合的时间,并基于所述第一数据集合中与所述第一关键字或者关键字段相匹配的数据,生成所述第一拉链数据的第二子拉链数据,其中,所述第二子拉链数据的开链时间为生成所述第二数据集合的时间,闭链时间为空或极大值;
生成子单元,用于若在所述第二数据集合中未查询到与所述第一关键字或者关键字段相匹配的数据,基于所述第一数据集合中与所述第一关键字或者关键字段相匹配的数据生成第二拉链数据,其中,所述第二拉链数据的开链时间为生成所述第二数据集合的时间,闭链时间为空或极大值;
第四更新子单元,用于将修改后的第一拉链数据及所述第二拉链数据更新至所述目标数据集合中。
进一步的,所述数据处理引擎模块包括:
第一恢复单元,用于若检测到对所述目标数据集合进行数据更新时出现更新错误,使用生成的第二数据集合中的数据恢复所述目标数据集合中的数据;或者
第二恢复单元,用于若检测到对所述目标数据集合进行数据更新时出现数据更新错误,获取预先备份的备份数据集合,使用所述备份数据集合中的数据恢复所述目标数据集合中的数据。
进一步的,所述生成单元还用于获取接收到所述第一数据集合之前的预设时间段内,已经更新的目标数据集合中存储过的所有数据,或者获取接收到所述第一数据集合后,本次待更新的目标数据集合中的数据,备份已经更新的目标数据集合中存储过的所有数据或者本次待更新的目标数据集合中的数据以生成第二数据集合;
或者,所述生成单元还用于获取上一次接收到第一数据集合时生成的第二数据集合,将当前所述目标数据集合中的数据插入至上一次接收到第一数据集合时生成的第二数据集合中,以生成本次的所述第二数据集合。
本发明实施例提供的数据处理方法及数据处理系统,接收外部系统传输的第一数据集合;在数据处理系统中生成与待更新的目标数据集合相关联的第二数据集合;清空所述目标数据集合中的数据;使用所述第一数据集合和所述第二数据集合中的数据对所述目标数据集合进行数据更新。这样,在接收到外部系统传输的第一数据集合,需要进行数据更新时,可以保证数据处理系统的稳定性,无需对所有数据进行扫描,节省大量时间,并提高数据更新的效率。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对本发明实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1是本发明一实施例提供的数据处理方法的流程图;
图2是本发明另一实施例提供的数据处理方法的流程图;
图3是表示未更新前目标数据集合中的数据表示的业务信息表;
图4是表示第一数据集合中的数据表示的信息表;
图5是表示第二数据集合中的数据表示的信息表;
图6和图7是表示对目标数据集合中的数据表示的信息进行更新的过程示意图;
图8是表示更新后的目标数据集合中的数据表示的业务信息表;
图9是表示未更新前目标数据集合中的拉链数据表示的业务信息表;
图10是表示第二数据集合中的拉链数据表示的信息表;
图11是表示第一数据集合中的数据表示的信息表;
图12和图13是表示对目标数据集合中的数据表示的信息进行更新的过程示意图;
图14是表示更新后的目标数据集合中的数据表示的业务信息表;
图15是本发明一实施例提供的数据处理系统的结构图;
图16为图15中所示数据处理系统的数据处理引擎模块的结构图之一;
图17为图15中所示数据处理系统的数据处理引擎模块的结构图之二;
图18为图15中所示数据处理系统的数据处理引擎模块的结构图之三;
图19图15中所示数据处理系统的数据处理引擎模块的结构图之四;
图20为图16中所示的第一更新单元的结构图之一;
图21为图16中所示的第一更新单元的结构图之二。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
参见图1,图1是本发明一实施例提供的数据处理方法的流程图。所述方法可以应用于数据处理系统,如图1所示,所述方法包括以下步骤:
步骤101、接收外部系统传输的第一数据集合。
在一些业务场景下,需要记录关键字段的数据变化历史信息,以满足客户需求,例如在金融领域,需记录某客户银行账户余额变化历史信息,以满足客户查询银行账户余额的需求。所以,需要对数据库中的数据进行周期性的数据更新。
因此,在该步骤中,数据处理系统会定期性的接收从外部系统传输的第一数据集合。
其中,数据处理系统定期性的接收所述第一数据集合,可以是以固定周期期限的接收所述第一数据集合,如1天接收一次,或者12小时接收一次;为了数据的时效性,数据处理系统也可以是实时的接收或者近似实时的接收所述第一数据集合,如1小时接收一次,或者半小时接收一次,甚至几分钟接收一次等,并不做任何限定。第一数据集合中可以是包含有成批的修改数据。
其中,所述第一数据集合,可以是单一数据的集合,如单一业务类型数据的集合,如只包含存款数据或者流水支出数据等的金融业务数据,也可以是单一客户或者目标的数据,如只包含张三,或者只包含李四的相关业务数据,也可以是综合数据的集合,如包含不同业务类型的数据,如可以同时包含存款数据和流水支出数据等金融业务数据,以及通信数据等,还可以同时包含多个客户或者目标的数据,如同时包含张三和李四的相关业务数据等。
其中,接收外部系统传输的第一数据集合,可以是直接从外部系统接收第一数据集合,也可以是通过数据处理系统的有关存储模块在存储了外部系统的第一数据集合后,从存储模块中获取外部系统的第一数据集合。
步骤102、在数据处理系统中生成与待更新的目标数据集合相关联的第二数据集合。
该步骤中,当所述数据处理系统接收到所述第一数据集合之后,所述数据处理系统可以控制在所述数据处理系统中,生成一个与所述待更新的目标数据集合相关联的第二数据集合。
其中,与所述目标数据集合相关联的第二数据集合的类型,可以是所述第二数据集合中包含的数据类型或者数据所表示的类型,与所述目标数据集合中数据类型或者数据所表示的类型相同。
举例来讲,比如所述目标数据集合中的数据是某客户张三的银行存款数据或者业务流水数据等,那么生成的所述第二数据集合中的数据也是客户张三的银行存款数据或者业务流水数据,而如果所述目标数据集合中的数据包含某客户张三的银行存款数据或者业务流水数据,以及李四的银行存款数据或者业务流水数据,那么生成的所述第二数据集合中的数据也是客户张三的银行存款数据或者业务流水数据,以及李四的银行存款数据或者业务流水数据。
其中,所述第二数据集合中包含的数据,可以是最完整的数据,即所述第二数据集合是时间跨度最大的数据集合,例如所述第二数据集合中包含的数据,可以是从生成所述目标数据集合开始,截止当前时刻所述目标数据集合中记录过的所有数据,也就是说,所述第二数据集合记录数据的时间跨度,是从该业务数据产生开始直到当前的时间,也就是最长的时间。
其中,相对应的,所述目标数据集合中包含的数据,可以是最完整的数据,即所述目标数据集合是时间跨度最大的数据集合;所述目标数据集合中包含的数据,也可以是只包含最完整的数据中的部分数据,如只包含上一次更新到本次更新期间的数据,即只包含一个更新周期内的数据,或者几个更新周期内的数据。
优选的,所述目标数据集合和所述第二数据集合中的数据,都是包含最大时间跨度中的数据信息。
其中,所述第二数据集合为所述目标数据集合的时间域快照数据集合。
对于生成所述第二数据集合,可以是通过备份的方式,使用历史数据即本次更新前的目标数据集合进行备份的方式生成所述第二数据集合。
进一步的,所述第二数据集合可以是基于既定的频率进行生成或更新,例如所述第二数据集合的生成或更新频率可以设置为一天一次,优选的,所述第二数据集合的生成或更新频率,可以是与成批的修改数据传输至数据处理系统的频率相同,即与数据处理系统定期性的接收所述第一数据集合的频率相同。
这样,在数据处理系统接收到第一数据集合后,可以通过控制生成与目标数据集合相关联的第二数据集合,无需对数据处理系统中所有数据进行扫描来确定目标数据集合中数据的位置和数据节点,省时省力,可以有效降低数据处理系统的工作量,提高工作效率。
步骤103、清空所述目标数据集合中的数据。
该步骤中,当所述数据处理系统控制在所述数据处理系统中生成了所述第二数据集合之后,所述数据处理系统可以控制将所述目标数据集合中的数据清空,以便后续对所述目标数据集合中进行数据更新。
步骤104、使用所述第一数据集合和所述第二数据集合中的数据对所述目标数据集合进行数据更新。
该步骤中,在所述数据处理系统将所述目标数据集合中的数据清空后,所述数据处理系统可以提取所述第一数据集合中需要更新的数据,和所述第二数据集合中的相关数据,来插入、添加或写入所述目标数据集合中,从而将所述目标数据集合进行数据更新。
优选的,本实施方式中,是采用查询插入的方式将所述第一数据集合和所述第二数据集合中的数据更新至所述目标数据集合中,来对所述目标数据集合中的数据进行更新。
举例来讲,比如所述目标数据集合中的数据是某客户张三的银行存款数据或者业务流水数据等,那么使用所述第一数据集合和所述第二数据集合中的数据对所述目标数据集合进行数据更新,就可以是使用所述第一数据集合中张三的新的银行存款数据或者业务流水数据,以及所述第二数据集合中张三过往的银行存款数据或者业务流水数据,来存储至所述目标数据集合中,来对所述目标数据集合进行数据更新,又或者比如所述目标数据集合中的数据是某客户张三的银行存款数据或者业务流水数据,以及客户李四的银行存款数据或者业务流水数据,而比如本次是需要对张三的数据进行更新,即所述第一数据集合中有张三的新的银行存款数据或者业务流水数据,那么就可以是使用所述第一数据集合中张三的新的银行存款数据或者业务流水数据,以及所述第二数据集合中张三过往的银行存款数据或者业务流水数据,以及客户李四的过往的银行存款数据或者业务流水数据,来存储至所述目标数据集合中,来对所述目标数据集合进行数据更新。
其中,对所述目标数据集合进行数据更新,也可以是周期性的更新,如一天更新一次,或者12小时更新一次等,优选的,所述目标数据集合的更新周期,可以是与所述数据处理系统接收所述第一数据集合的频率相同。
这样,在数据处理系统接收到第一数据集合后,可以通过生成与待更新的目标数据集合相关联的第二数据集合,并清空目标数据集合后,将第一数据集合和第二数据集合中的数据通过查询插入的方式插入到目标数据集合,以对目标数据集合进行更新,无需对数据处理系统进行全部数据的扫描,即可完成目标数据集合中数据的更新,可以节省全盘扫描的时间,进而有效降低数据处理系统的工作量,提高工作效率。
本发明实施例中,上述数据处理系统,可以是用于开发和运行处理数据的后台平台等,实现在大量计算机组成的集群中对海量数据进行分布式计算,优选的,所述数据处理系统为大数据平台。
上述数据处理系统,可以应用于金融系统、医疗系统和教育系统等的大数据应用场景,如银行数据系统、医院数据系统和学校数据系统等。
本发明实施例提供的数据处理方法,接收外部系统传输的第一数据集合;在数据处理系统中生成与待更新的目标数据集合相关联的第二数据集合;清空所述目标数据集合中的数据;使用所述第一数据集合和所述第二数据集合中的数据对所述目标数据集合进行数据更新。这样,在接收到外部系统传输的第一数据集合,需要进行数据更新时,可以通过在数据处理系统中提取与所述目标数据集合中的数据相关的数据,从而生成与待更新的目标数据集合相关联的第二数据集合,然后通过查询插入的方式将第一数据集合和第二数据集合中的数据插入目标数据集合中,以对目标数据集合中的数据进行更新,无需对所有数据和节点进行扫描,即可完成目标数据集合中数据的更新,可以节省全盘扫描的大量时间,进而有效降低数据处理系统的工作量,提高数据更新的效率。
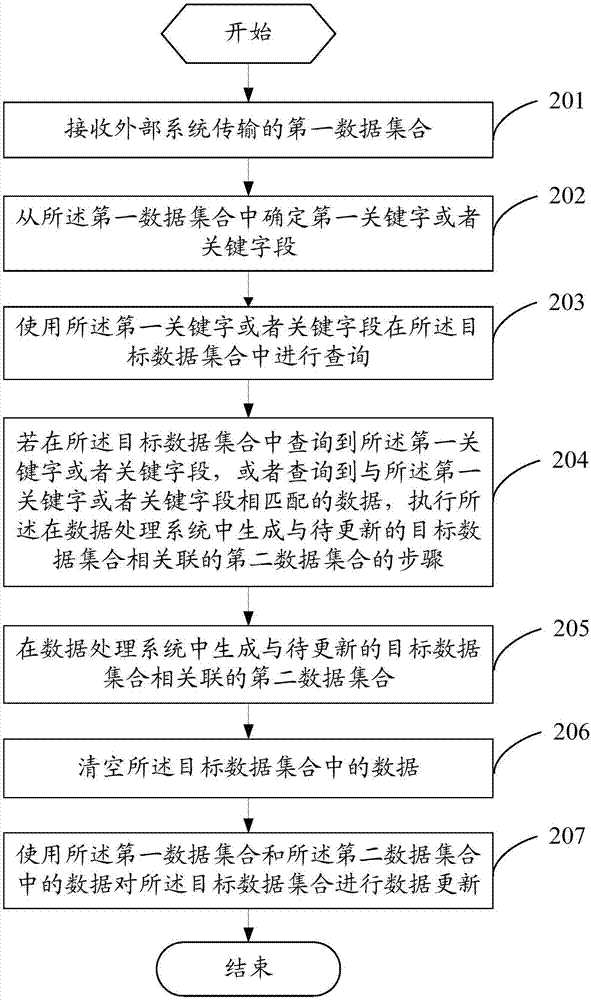
参见图2,图2是本发明另一实施例提供的数据处理方法的流程图。所述方法应用于数据处理系统,如图2所示,所述方法包括以下步骤:
步骤201、接收外部系统传输的第一数据集合。
步骤202、从所述第一数据集合中确定第一关键字或者关键字段。
该步骤中,当所述数据处理系统接收到外部系统传输的第一数据集合后,所述数据处理系统可以根据所述第一数据集合中需要存储或者更新的数据,来从所述第一数据集合中确定相应的第一关键字或者关键字段。
其中,所述第一关键字或者关键字段,仅是泛指,比如所述第一数据集合中包括多个类型的业务数据或者多个客户的数据时,可以是分别对每个类型的业务数据或者每个客户的数据进行更新,每次对相应的类型的业务数据或者客户的数据更新时,相应的类型的业务数据或者客户的数据都具有相应的第一关键字或者关键字段。
其中,第一关键字或者关键字段,可以根据实际需求进行设定,如使用一个关键字就可以表示待更新的数据,即可只确定关键字即可,反之,需要多个关键字组成的关键字段才能表示待更行的数据,即需要确定关键字段。
步骤203、使用所述第一关键字或者关键字段在所述目标数据集合中进行查询。
该步骤中,当所述数据处理系统确定所述第一关键字或者关键字段后,所述数据处理系统可以控制使用所述第一关键字或者关键字段进行查询,即使用所述第一关键字或者关键字段在所述目标数据集合中进行查询,从而所述数据处理系统可以通过查询得知,在所述目标数据集合中是否已经存在与所述第一关键字或者关键字段表示的数据相匹配的数据的历史信息或者数据记录等。
步骤204、若在所述目标数据集合中查询到所述第一关键字或者关键字段,或者查询到与所述第一关键字或者关键字段相匹配的数据,执行所述在数据处理系统中生成与待更新的目标数据集合相关联的第二数据集合的步骤。
该步骤中,当所述数据处理系统使用所述第一关键字或者关键字段在所述目标数据集合中进行查询,并且在所述目标数据集合中查询到所述第一关键字或者关键字段,或者查询到所述目标数据集合中存在与所述第一关键字或者关键字段相匹配的数据的话,那么所述数据处理系统就可以认为所述目标数据集合中存在与所述第一关键字或者关键字段相匹配的数据的过往信息,那么所述数据处理系统就可以控制执行所述在数据处理系统中生成与待更新的目标数据集合相关联的第二数据集合的步骤,从而通过后续动作来完成对所述目标数据集合中的数据进行更新。
其中,查询到与所述第一关键字或者关键字段相匹配的数据,可以是指在所述目标数据集合中进行查询时,由于某些数据的排列顺序等问题,可能陈列在较靠后的位置,这样直接查询到所述第一关键字或者关键字段的话可能耗费时间较长,这时,当查询到与所述第一关键字或者关键字段相匹配的数据的话,就可以认为是查询到了所述第一关键字或者关键字段,这样,可以节省时间,减小数据扫描量。
其中,与所述第一关键字或者关键字段相匹配的数据,可以是与所述第一关键字或者关键字段表示的数据相关联的数据,比如所述第一关键字或者关键字段是张、张三或者张三的id,那么所述第一关键字或者关键字段相匹配的数据可以是表示张、张三或者张三的id的数据,也可以是表示张、张三或者张三的id在某个日期的某些存款或者流水记录的数据,或者可以表示张、张三或者张三的id的电话号码或者身份证号等信息的数据等。
步骤205、在数据处理系统中生成与待更新的目标数据集合相关联的第二数据集合。
步骤206、清空所述目标数据集合中的数据。
步骤207、使用所述第一数据集合和所述第二数据集合中的数据对所述目标数据集合进行数据更新。
其中,步骤201和步骤205至步骤207的描述可以参照上述实施例中的步骤101至步骤104的描述,在此不做赘述。
可选的,在步骤203之后,所述方法包括:
若在所述目标数据集合中未查询到所述第一关键字或者关键字段,并且未查询到与所述第一关键字或者关键字段相匹配的数据,将所述第一数据集合的数据更新至所述目标数据集合中。
该步骤中,当所述数据处理系统使用所述第一关键字或者关键字段在所述目标数据集合中进行查询,而在所述目标数据集合中未查询到所述第一关键字或者关键字段,并且在所述目标数据集合中未查询到与所述第一关键字或者关键字段相匹配的数据的话,那么所述数据处理系统就可以认为,所述第一目标数据集合中所述第一关键字或者关键字段表示的数据,相对于所述目标数据集合来讲是全新的数据,所述数据处理系统就可以直接将所述第一数据集合中的数据插入、添加或者写入至所述目标数据集合中,从而对所述的目标数据集合中的数据进行更新。
可选的,步骤207包括:
从所述第二数据集合中确定第二关键字或者关键字段,使用所述第二关键字或者关键字段在所述第一数据集合中进行查询,若在所述第一数据集合中未查询到所述第二关键字或者关键字段,并且在所述第一数据集合中未查询到与所述第二关键字或者关键字段相匹配的数据,将所述第二数据集合中与所述第二关键字或者关键字段相匹配的数据更新至所述目标数据集合中;将所述第一数据集合中与所述第一关键字或者关键字段相匹配的数据更新至所述目标数据集合中。
该步骤中,在所述数据处理系统将所述目标数据集合中的数据清空后,所述数据处理系统可以根据所述第二数据集合中包含的数据,来确定第二关键字或者关键字段,然后使用所述第二关键字或者关键字段在所述第一数据集合中进行查询,来查询所述第一数据集合中是否有与所述第二关键字或者关键字段相匹配的数据,如果所述数据处理系统通过查询,确定在所述第一数据集合中未查询到所述第二关键字或者关键字段,并且,确定在所述第一数据集合中未查询到与所述第二关键字或者关键字段匹配的数据的话,所述数据处理系统可以认为所述第二数据集合中与所述第二关键字或者关键字段匹配的数据不需要更新,所以,所述数据处理系统可以将第二数据集合中与所述第二关键字或者关键字段相匹配的数据更新至清空后的所述目标数据集合中,然后再根据所述第一关键字或者关键字段,从所述第一数据集合中将确定与所述第一关键字或者关键字段相匹配的数据提取出,并将提取出的数据更新至清空后的所述目标数据集合中,从而完成对所述目标数据集合的数据更新。
其中,将所述第二数据集合中与所述第二关键字或者关键字段相匹配的数据更新至所述目标数据集合中,以及将所述第一数据集合中与所述第一关键字或者关键字段相匹配的数据更新至所述目标数据集合中,可以是通过在查询后,将数据通过插入、添加或者写入等方式,更新至所述目标数据集合中。
举例来讲,请参阅图3至图5,比如图3中表示未更新前目标数据集合中的数据表示的业务信息表,图4中表示第一数据集合中的数据表示的信息表,图5中表示第二数据集合中的数据表示的信息表,图6和图7表示对目标数据集合中的数据表示的信息进行更新的过程示意图,图8中表示更新后的目标数据集合中的数据表示的业务信息表。如未更新前的所述目标数据集合中的数据表示张三和李四的存款余额信息,所述第一数据集合中的数据表示在过去一段时间中进行业务办理的人员张三、王五、赵六等的相关存款业务信息,所述第二数据集合中的数据表示所述目标数据集合中相同人员的所有业务信息,即张三和李四的存款余额信息。
那么在对所述目标数据集合进行数据更新时,将所述目标数据集合中的数据清空,即将图3中的数据表中的信息清空后,得到空白的目标数据表示的图6中所示的空白信息表;然后所述数据处理系统可以从所述第二数据集合中确定第二关键字或者关键字段(例如张三的id或者李四的id),然后根据所述第二关键字或者关键字段在所述第一数据集合中进行查询,查询所述第一数据集合中是否有与所述第二关键字或者关键字段相匹配的数据,即在所述第一数据集合中查询是否有表示张三或者李四的相关业务信息的数据,如果在所述第一数据集合中未查询到与所述第二关键字或者关键字段相匹配的数据,如在所述第一数据集合中未查询到与李四的关键字或者关键字段相匹配的数据,就表示此次数据更新,没有李四的业务数据需要更新,那么就可以将所述第二数据集合中与所述第二关键字或者关键字段相匹配的数据,即与李四相关的业务数据,更新至清空后的所述目标数据集合中,从而完成第一步更新,得到图7所示的李四的相关业务信息表,反之,如果在所述第一数据集合中查询到与所述第二关键字或者关键字段相匹配的数据,如在所述第一数据集合中查询到与表示张三的关键字或者关键字段相匹配的数据,就表示此次数据更新,有张三的业务数据需要进行更新,就不需将第二数据集合中张三的业务数据添加到清空后的所述目标数据集合中,即不将所述第二数据集合中与所述第二关键字或者关键字段相匹配的数据添加至清空后的所述目标数据集合;接着,所述数据处理系统可以根据所述第一数据集合中的第一关键字或者关键字段,如与张三、王五和赵六的业务数据相关的第一关键字或者关键字段(如张三、王五和赵六的id等),将所述第一数据集合中与所述第一关键字或者关键字段(如张三、王五和赵六的id等)相匹配的数据直接添加至清空后的所述目标数据集合中,从而完成对所述目标数据集合的数据更新,从而得到图8表示的更新后的所述目标数据集合中的数据表示的业务信息表。
可选的,当所述目标数据集合为拉链数据集合时,步骤207包括:
使用所述第二关键字或者关键字段在所述第一数据集合中进行查询;若在所述第一数据集合中未查询到所述第二关键字或者关键字段,并且在所述第一数据集合中未查询到与所述第二关键字或者关键字段相匹配的数据,将所述第二数据集合中与所述第二关键字或者关键字段相匹配的数据更新至所述目标数据集合;确定所述第二数据集合中与所述第一关键字或者关键字段相匹配的第一拉链数据,修改所述第一拉链数据中处于开链状态的第一子拉链数据的闭链时间为生成所述第二数据集合的时间,并基于所述第一数据集合中与所述第一关键字或者关键字段相匹配的数据,生成所述第一拉链数据的第二子拉链数据,其中,所述第二子拉链数据的开链时间为生成所述第二数据集合的时间,闭链时间为空或极大值;若在所述第二数据集合中未查询到与所述第一关键字或者关键字段相匹配的数据,基于所述第一数据集合中与所述第一关键字或者关键字段相匹配的数据生成第二拉链数据,其中,所述第二拉链数据的开链时间为生成所述第二数据集合的时间,闭链时间为空或极大值;将修改后的第一拉链数据、所述第二拉链数据更新至所述目标数据集合中。
该步骤中,如果所述目标数据集合为拉链数据集合,即所述目标数据集合中的数据为拉链数据的话,在所述数据处理系统将所述目标数据集合中的数据清空后,所述数据处理系统可以根据所述第二数据集合中包含的数据,来确定第二关键字或者关键字段,然后使用所述第二关键字或者关键字段在所述第一数据集合中进行查询,来查询所述第一数据集合中是否有与所述第二关键字或者关键字段相匹配的数据,如果所述数据处理系统通过查询,确定在所述第一数据集合中未查询到所述第二关键字或者关键字段,并且,确定在所述第一数据集合中未查询到与所述第二关键字或者关键字段匹配的数据的话,所述数据处理可以认为所述第二数据集合中与所述第二关键字或者关键字段匹配的数据不需要更新,所以,所述数据处理系统可以将第二数据集合中与所述第二关键字或者关键字段相匹配的数据更新至清空后的所述目标数据集合中。
然后,所述数据处理系统可以使用所述第一关键字或者关键字段在所述第二数据集合中查询,如果所述第二数据集合中有与所述第一关键字或者关键字段相匹配的数据的话,所述数据处理系统可以在所述第二数据集合中,确定与所述第一关键字或者关键字段相匹配的第一拉链数据,然后所述数据处理系统可以对所述第一拉链数据进行修改,从而将所述第一拉链数据中处于开链状态的第一子拉链数据的闭链时间设置为生成所述第二数据集合的时间,进一步的,所述数据处理系统可以重新设置所述第一拉链数据的开链时间,即生成所述第一拉链数据的处于开链状态的第二子拉链数据,具体的,所述数据处理系统可以获取所述第一数据集合中与所述第一关键字或者关键字段相匹配的数据,并根据所述第一数据集合中与所述第一关键字或者关键字段相匹配的数据,来生成所述第一拉链数据的第二子拉链数据,所述第二子拉链数据的开链时间为生成所述第二数据集合的时间,闭链时间为空或极大值,表示截止目前还是处于开链状态。
如果所述数据处理系统在所述第二数据集合中未查询到与所述第一关键字或者关键字段相匹配的数据的话,那么就说明所述第一数据集合中与所述第一关键字或者关键字段相匹配的数据都是新的数据,所述数据处理系统就可以根据所述第一数据集合中与所述第一关键字或者关键字段相匹配的数据,来生成新的拉链数据,即第二拉链数据,其中,所述第二拉链数据的开链时间为生成所述第二数据集合的时间,闭链时间为空或极大值。
最后,所述数据处理系统将修改后的第一拉链数据以及新生成的所述第二拉链数据更新至所述目标数据集合中,完成对所述目标数据集合的数据更新。
举例来讲,请同时参阅图9至图11,图9中表示未更新前目标数据集合中的拉链数据表示的业务信息表,图10中表示第二数据集合中的拉链数据表示的信息表,图11表示第一数据集合中的数据表示的信息表,图12和图13表示对目标数据集合中的数据表示的信息进行更新的过程示意图,图14中表示更新后的目标数据集合中的数据表示的业务信息表。如未更新前的所述目标数据集合中的拉链数据表示张三和李四的存款余额明细信息,所述第一数据集合中的数据表示在过去一段时间中进行业务办理的人员张三、王五、赵六等的相关存款业务信息,所述第二数据集合中的数据表示与所述目标数据集合中相同存款人员的所有业务信息,即所述第二数据集合中的数据表示张三和李四的存款余额的明细信息。
那么在对所述目标数据集合进行数据更新时,将所述目标数据集合中的数据清空,即将图9中的数据表中的信息清空后,得到空白的目标数据表示的图12中所示的空白信息表;然后所述数据处理系统可以从所述第二数据集合中确定第二关键字或者关键字段(例如张三的id或者李四的id),然后根据所述第二关键字或者关键字段在所述第一数据集合中进行查询,查询所述第一数据集合中是否有与所述第二关键字或者关键字段相匹配的数据,即在所述第一数据集合中查询是否有表示张三或者李四的相关业务信息的数据,如果在所述第一数据集合中未查询到与所述第二关键字或者关键字段相匹配的数据,如在所述第一数据集合中未查询到与李四的关键字或者关键字段相匹配的数据,就表示此次数据更新,没有李四的业务数据需要更新,那么就可以将所述第二数据集合中与所述第二关键字或者关键字段相匹配的数据,即与李四相关的业务数据,更新至清空后的所述目标数据集合中,从而完成第一步更新,得到图13所示的李四的相关业务信息的明细表;接着,使用所述第一关键字或者关键字段在所述第二数据集合中进行查询,如果在所述第二数据集合中查询到与所述第一关键字或者关键字段相匹配的数据,如在所述第二数据集合中查询到与表示张三的关键字或者关键字段相匹配的数据,就表示此次数据更新,有张三的业务数据需要进行更新,接着,所述数据处理系统可以在所述第二数据集合中,根据所述第一关键字或者关键字段确定表示张三的相关业务信息的数据,即表示张三的存款信息明细的第一拉链数据,然后将所述第一拉链数据中处于开链状态的第一子拉链数据的闭链时间修改为生成所述第二数据集合的时间,即数据更新的时间(对所述目标数据集合进行数据更新的时间),并根据所述第一数据集合中与所述第一关键字或者关键字段相匹配的数据,即表示张三新的业务信息的数据,来生成一条新的表示张三的存款信息明细的拉链数据,即第二子拉链数据,设置该第二子拉链数据的开链时间为生成所述第二数据集合的时间,即数据更新时间,闭链时间为空或极大值;然后将所述第二数据集合中与所述第一关键字或者关键字段相匹配的数据,即与张三相关的业务数据,更新至清空后的所述目标数据集合中,从而完成第二步更新;反之,如果在所述第二数据集合中未查询到与所述第一关键字或者关键字段相匹配的数据,如未查询到表示王五和赵六的相关信息的数据,则所述数据处理系统可以根据所述第一数据集合中与所述第一关键字或者关键字段,即所述第一数据集合中表示王五和赵六的相关的数据,来生成所述第一数据集合中与所述第一关键字或者关键字段相匹配的数据的第二拉链数据,来表示王五和赵六的相关业务信息的明细表,并且可以设置所述第二拉链数据的开链时间为数据更新时间,闭链时间为空或极大值;然后将所述第一拉链数据,即表示张三的相关业务的数据,以及生成的第二拉链数据,即表示王五和赵六的相关的业务数据,更新至清空后的所述目标数据集合中,以完成对所述目标数据集合的数据更新,从而得到图14表示的更新后的所述目标数据集合中的数据表示的业务信息表。
可选的,在步骤201之后,所述方法包括:
若检测到对所述目标数据集合进行数据更新时出现更新错误,使用生成的第二数据集合中的数据恢复所述目标数据集合中的数据。
该步骤中,在所述目标数据集合完成数据更新或者在所述目标数据集合进行数据更新时,所述数据处理系统可以对所述目标数据集合的数据更新进行实时的监测,如果监测到对所述目标数据集合进行数据更新时出现更新错误,即在步骤206和/或步骤207中出现更新错误的情况时,所述数据处理系统可以对所述目标数据集合进行数据恢复,具体的,所述数据处理系统可以获取在步骤205中生成的第二数据集合,然后使用生成的第二数据集合中的数据恢复所述目标数据集合中的数据。
在恢复所述目标数据集合中的数据后,所述数据处理系统可以控制停止数据更新。
这里,可以直接使用第二数据集合,即目标数据集合的时间域快照数据集合进行数据恢复,简单快捷,相对适用于数据更新周期较短的数据更新方式。
或者,若检测到对所述目标数据集合进行数据更新时出现数据更新错误,获取预先备份的备份数据集合,使用所述备份数据集合中的数据恢复所述目标数据集合中的数据。
该步骤中,在所述目标数据集合完成数据更新或者在所述目标数据集合进行数据更新时,所述数据处理系统可以对所述目标数据集合的数据更新进行实时的监测,如果监测到对所述目标数据集合进行数据更新时出现更新错误,所述数据处理系统可以对所述目标数据集合进行数据恢复,具体的,所述数据处理系统可以获取预先备份好的备份数据集合,然后使用所述备份数据集合中的数据对所述目标数据集合进行数据恢复。
其中,所述备份数据集合的备份周期,可以是根据需要进行备份周期的设定,如备份1个月的数据量。
其中,所述备份数据集合可以是保存所述第一数据集合中的数据,并对所述第二数据集合,即时间域快照数据集合中的数据按照预设备份周期备份一次全量数据。
在恢复所述目标数据集合中的数据后,所述数据处理系统可以控制停止数据更新。
这里,使用备份机制,即备份多久的数据就恢复多久的数据,例如备份了一个月的数据就恢复一个月的数据,简单快捷,相对适用于数据更新周期较长的数据更新方式。
本实施方式中,在监测到对所述目标数据集合进行数据更新时出现数据更新错误时,可以使用上述两种方式回滚来进行数据恢复,但并不局限于此,在其他实施方式中,也可以忽略数据更新错误的警报,继续进行数据更新,还可以是在回滚恢复数据后,重新进行数据更新。
可选的,步骤205包括:
获取接收到所述第一数据集合之前的预设时间段内,已经更新的目标数据集合中存储过的所有数据,或者获取接收到所述第一数据集合后,本次待更新的目标数据集合中的数据,备份已经更新的目标数据集合中存储过的所有数据或者本次待更新的目标数据集合中的数据以生成第二数据集合。
对于生成所述第二数据集合,可以是通过备份的方式,使用历史数据备份的方式生成所述第二数据集合。
因此,在该步骤中,在所述数据处理系统接收到所述第一数据集合后,所述数据处理系统可以对历史数据进行检测,使用在接收到所述第一数据集合后,本次待更新的目标数据集合进行备份的方式生成所述第二数据集合;或者,获取在此次接收到所述第一数据集合之前的预设时间段内,已经更新过的目标数据集合中存储的所有数据,从而将已经更新过的目标数据集合中存储过的所有数据备份至一个集合中,从而生成所述第二数据集合。
或者,获取上一次接收到第一数据集合时生成的第二数据集合,将当前所述目标数据集合中的数据插入至上一次接收到第一数据集合时生成的第二数据集合中,以生成本次的所述第二数据集合。
对于生成所述第二数据集合,可以是通过对现有数据插入更新的方式,结合现有的历史数据生成所述第二数据集合。
因此,该步骤中,在此次所述数据处理系统接收到所述第一数据集合后,所述数据处理系统可以获取在此次接收到所述第一数据集合之前的,上一次接收到第一数据集合时生成的第二数据集合,然后,再获取所述目标数据集合中的数据,并将所述目标数据集合中的数据插入至上一次接收到第一数据集合时生成的第二数据集合中,从而来生成本次的所述第二数据集合。
本发明实施例提供的数据处理方法,接收外部系统传输的第一数据集合;从所述第一数据集合中确定第一关键字或者关键字段;使用所述第一关键字或者关键字段在所述目标数据集合中进行查询;若在所述目标数据集合中查询到所述第一关键字或者关键字段,或者查询到与所述第一关键字或者关键字段相匹配的数据,执行所述在数据处理系统中生成与待更新的目标数据集合相关联的第二数据集合的步骤;在数据处理系统中生成与待更新的目标数据集合相关联的第二数据集合;清空所述目标数据集合中的数据;使用所述第一数据集合和所述第二数据集合中的数据对所述目标数据集合进行数据更新。这样,通过查询插入的方式使用第一数据集合和第二数据集合中的数据对目标数据集合中的数据进行更新,无需对所有数据和节点进行扫描,即可完成目标数据集合中数据的更新,可以节省全盘扫描的大量时间,进而有效降低数据处理系统的工作量,提高数据更新的效率。
参见图15至图21,图15是本发明一实施例提供的数据处理系统的结构图,图16为图15中所示数据处理系统的数据处理引擎模块的结构图之一,图17为图15中所示数据处理系统的数据处理引擎模块的结构图之二,图18为图15中所示数据处理系统的数据处理引擎模块的结构图之三,图19图15中所示数据处理系统的数据处理引擎模块的结构图之四,图20为图16中所示的第一更新单元的结构图之一,图21为图16中所示的第一更新单元的结构图之二。如图15所示,数据处理系统1500包括数据存储模块1510、业务逻辑模块1520、数据服务模块1530和数据处理引擎模块1540。
所述数据处理系统1500可以是一种数据工程平台(dataengineeringplatform,dep)。
其中,所述数据存储模块1510用于存储所述数据处理系统1500的内部数据,以及从外部获取的数据。
所述数据存储模块1510可以是分布式文件存储(hadoopdistributedfilesystem,hdfs)系统。hdfs系统为存储层,用于存储dep的内部数据,以及存储dep从外部系统获取的数据。dep从外部系统获取数据,可以是直接抽取数据,例如关系型数据库系统db2中的数据、数据库云服务器oracleexadata中的数据、excel格式的数据,还可以是文件形式数据,即以文件形式发送至dep的数据,例如文本形式的数据,还包括非结构式数据,例如log日志、音频/视频多媒体文件。
其中,所述业务逻辑模块1520用于管控业务逻辑。所述业务逻辑模块1520可以包括存储所述数据处理系统的业务逻辑的存储单元,所述业务逻辑包括下述至少之一:调度规则、数据血缘关系、模型元数据和脚本工具(例如自动化工具)等。
其中,所述数据服务模块1530用于向数据处理系统的外部系统提供数据服务,其包括:
推送单元1531,用于向外部系统推送信息队列和数据,例如推送消息队列、推送数据至数据库。
存档单元1532,用于存储文件形式数据。
数据传输接口(representationalstatetransferapi,restapi)单元1533,用于与数据处理系统的下游系统或者服务系统连接,通过所述接口单元为所述下游系统或者服务系统提供数据,比如报表系统、分析服务等。
所述数据处理引擎模块1540用于对数据进行处理,其可以是结构化查询语言(structuredquerylanguage)引擎模块,简称sql引擎模块,sql引擎模块可以由hive和/或spark等引擎构成。
可选的,所述数据处理系统1500还包括:
信息交互模块1550,用于接收用户输入的操作指令,对所述数据处理系统进行管理及设置。用户可以包括业务人员(业务线上人员)、运维人员(技术线上的人员)等,用户交互模块可以设置相应的ui用户界面。
可选的,所述数据处理系统1500还包括自动化工具模块,其可以基于规则(例如通过所述数据处理方法进行数据更新的方法)编写自动化工具(即一段程序),仅需了解在dep中哪些数据集合需要通过拉链法记录变化的历史,通过该自动化工具即可实现该算法程序的自动化生成,例如在hive中生成sql语句。
其中,所述自动化工具模块可以包括:
参数接收单元,用于接收输入的参数。
脚本生成单元,用于基于预设规则及所述参数,生成自动化工具脚本。
具体的,所述参数接收单元,用于接收用户的输入数据处理系统的参数,可以是根据接收到的指令写入与所述指令对应的参数。所述参数包括下述至少之一:数据集合的名称、字段、数据类型。
举例来讲,如果想知道某客户银行账户余额变化情况,即需要了解客户的余额(目标数据集合中表示的余额信息表)和收支明细(目标数据集合中表示的余额明细信息表),可以通过该自动化模块对应的自动化工具,自动化生成实现上述实施例中的进行数据更新的方法(联表查询比对及插入算法)的相关代码,实动查询。基于业务需要运行,在hadoop平台记录数据变化历史的操作,具体的可以通过hadoop平台把数据变化历史记录到hdfs中。
其中,如图16所示,所述数据处理引擎模块1540包括:
接收单元1541,用于接收外部系统传输的第一数据集合。
生成单元1542,用于在数据处理系统中生成与待更新的目标数据集合相关联的第二数据集合。
清除单元1543,用于清空所述目标数据集合中的数据。
第一更新单元1544,用于使用所述第一数据集合和所述第二数据集合中的数据对所述目标数据集合进行数据更新。
其中,所述接收单元1541接收的外部系统传输的第一数据集合,可以是直接从外部系统接收所述第一数据集合,也可以是通过外部系统传输的第一数据集合存储在所述数据存储模块1510后,从所述数据存储模块1510中获取所述第一数据集合。
可选的,如图17所示,所述数据处理引擎模块1540还包括:
第一确定单元1545,用于从所述第一数据集合中确定第一关键字或者关键字段。
查询单元1546,用于使用所述第一关键字或者关键字段在所述目标数据集合中进行查询。
执行单元1547,用于若在所述目标数据集合中查询到所述第一关键字或者关键字段,或者查询到与所述第一关键字或者关键字段相匹配的数据,执行所述在数据处理系统中生成与待更新的目标数据集合相关联的第二数据集合的步骤。
可选的,如图17所示,所述数据处理引擎模块1540还包括:
第二更新单元1548,用于若在所述目标数据集合中未查询到所述第一关键字或者关键字段,并且未查询到与所述第一关键字或者关键字段相匹配的数据,将所述第一数据集合的数据更新至所述目标数据集合中。
可选的,如图18所示,所述数据处理引擎模块1540还包括:
第一恢复单元1549,用于若检测到对所述目标数据集合进行数据更新时出现更新错误,使用生成的第二数据集合中的数据恢复所述目标数据集合中的数据。
或者,如图19所示,所述数据处理引擎模块1540包括:
第二恢复单元15410,用于若检测到对所述目标数据集合进行数据更新时出现数据更新错误,获取预先备份的备份数据集合,使用所述备份数据集合中的数据恢复所述目标数据集合中的数据。
可选的,如图20所示,所述第一更新单元1544包括:
第一确定子单元15441,用于从所述第二数据集合中确定第二关键字或者关键字段。
第一查询子单元15442,用于使用所述第二关键字或者关键字段在所述第一数据集合中进行查询。
第一更新子单元15443,用于若在所述第一数据集合中未查询到所述第二关键字或者关键字段,并且在所述第一数据集合中未查询到与所述第二关键字或者关键字段相匹配的数据,将所述第二数据集合中与所述第二关键字或者关键字段相匹配的数据更新至所述目标数据集合中。
第二更新子单元15444,用于将所述第一数据集合中与所述第一关键字或者关键字段相匹配的数据更新至所述目标数据集合中。
可选的,如图21所示,当所述目标数据集合为拉链数据集合时,所述第一更新单元1544包括:
第二确定子单元15445,用于从所述第二数据集合中确定第二关键字或者关键字段。
第二查询子单元15446,用于使用所述第二关键字或者关键字段在所述第一数据集合中进行查询。
第三更新子单元15447,用于若在所述第一数据集合中未查询到所述第二关键字或者关键字段,并且在所述第一数据集合中未查询到与所述第二关键字或者关键字段相匹配的数据,将所述第二数据集合中与所述第二关键字或者关键字段相匹配的数据更新至所述目标数据集合中。
第三确定子单元15448,用于确定所述第二数据集合中与所述第一关键字或者关键字段相匹配的拉链数据。
修改子单元15449,用于修改所述第一拉链数据中处于开链状态的第一子拉链数据的闭链时间为生成所述第二数据集合的时间,并基于所述第一数据集合中与所述第一关键字或者关键字段相匹配的数据,生成所述第一拉链数据的第二子拉链数据,其中,所述第二子拉链数据的开链时间为生成所述第二数据集合的时间,闭链时间为空或极大值。
生成子单元154410,用于若在所述第二数据集合中未查询到与所述第一关键字或者关键字段相匹配的数据,基于所述第一数据集合中与所述第一关键字或者关键字段相匹配的数据生成第二拉链数据,其中,所述第二拉链数据的开链时间为生成所述第二数据集合的时间,闭链时间为空或极大值。
第四更新子单元154411,用于将修改后的拉链数据及所述第一数据集合中与第一关键字或者关键字段相匹配的数据更新至所述目标数据集合中。
可选的,所述生成单元1542还用于获取接收到所述第一数据集合之前的预设时间段内,已经更新的目标数据集合中存储过的所有数据,或者获取接收到所述第一数据集合后,本次待更新的目标数据集合中的数据,备份已经更新的目标数据集合中存储过的所有数据或者本次待更新的目标数据集合中的数据以生成第二数据集合。
或者,所述生成单元1542还用于获取上一次接收到第一数据集合时生成的第二数据集合,将当前所述目标数据集合中的数据插入至上一次接收到第一数据集合时生成的第二数据集合中,以生成本次的所述第二数据集合。
本发明实施例提供的数据处理系统1500能够实现图1至图2的方法实施例中数据处理系统实现的各个过程,为避免重复,这里不再赘述。
本发明实施例提供的数据处理系统,在接收到外部系统传输的第一数据集合,需要进行数据更新时,可以使用联表查询方式通过查询插入的手段进行数据更新,以保证数据处理系统的稳定性,无需对所有数据进行扫描,节省大量时间,并提高数据更新的效率。
上面结合附图对本发明的实施例进行了描述,但是本发明并不局限于上述的具体实施方式,上述的具体实施方式仅仅是示意性的,而不是限制性的,本领域的普通技术人员在本发明的启示下,在不脱离本发明宗旨和权利要求所保护的范围情况下,还可做出很多形式,均属于本发明的保护之内。
- 还没有人留言评论。精彩留言会获得点赞!