基于分组卷积自编码器的航空发动机故障检测方法及系统与流程
本发明涉及航空发动机技术领域,尤其涉及一种基于分组卷积自编码器的航空发动机故障检测方法及系统。
背景技术:
伴随着民航事业的发展,飞机发动机的安全性、可靠性以及经济性受到越来越多地关注。发动机故障检测是改善上述性能的一条重要途径,它可以帮助管理者更加合理地分配监控资源,提高每次飞行的安全性与可靠性,制定科学的维修计划,最大程度地降低运营与维护成本。
当前很多发动机故障检测方法都依赖于性能偏差数据。但是性能偏差数据来源于发动机制造商(OEM),航空公司需要支付高昂的费用来获取性能偏差数据。如果航空公司与OEM之间的合作因为某些不可预测的原因而中断,航空公司将难以获取性能偏差数据,无法有效地进行发动机故障检测,容易引起不安全的飞行事件以及巨大经济损失。
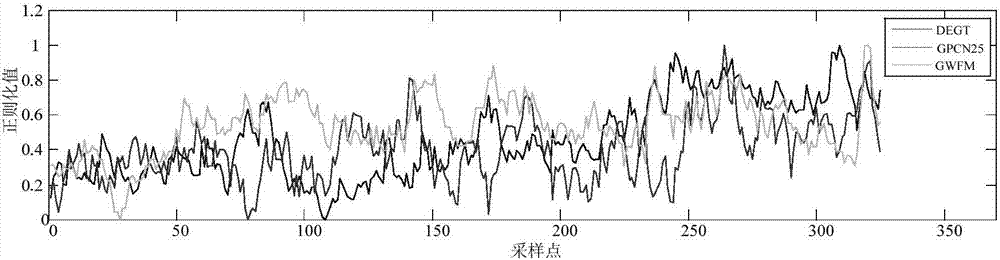
为提高自主的发动机故障检测能力,需要一种能够替代性能偏差数据的状态监控数据,而飞机通信寻址与报告系统(ACARS)数据是比较合适的选择。然而,ACARS数据与性能偏差数据在某些方面存在差异,飞行巡航阶段中一段平滑后的性能偏差数据与其对应的ACARS数据分别如图1a和图1b所示。首先,ACARS数据的维度通常要比性能偏差数据高。在每次飞行的巡航阶段,ACARS数据可以达到几十个参数而性能偏差数据通常只有3个参数,如图所示。其中性能偏差数据包含DEGT(发动机排气温度偏差值)、GPCN25(核心机转速偏差值)和GWFM(燃油流量偏差值)。ACARS数据则至少包括ZALT(高度)、ZPCN12(风扇指示转速)、ZPCN25(核心机指示转速)、ZT1A(大气总温)、ZT49(排气温度)、ZWF36(燃油流量)和ZXM(马赫数)等参数。其次,性能偏差数据可以消除工况以及外界环境变化带来的影响,比较明显地反映发动机状态。而ACARS数据中各参数受工况及环境变化影响较大,且各参数之间相关关系复杂,故障模式通常隐藏在多参数的复杂变化中。最后,ACARS数据中通常包含大量噪音,容易干扰分析结果。
综上所述,与性能偏差数据相比,ACARS数据通常包含了更加丰富的发动机状态信息。如果采用有效的方法对其进行处理,故障检测效果可能会比基于性能偏差数据的方法更好。但是ACARS数据维度高、参数之间关系复杂以及包含大量噪音等特点也给故障检测方法带来了挑战。现有技术中提出了基于性能偏差数据的方法,它们采用机器学习模型构建故障与性能偏差数据的映射关系。尽管它们在性能偏差数据上取得了不错的故障检测结果,但是它们难以发现隐藏在ACARS多参数复杂变化之中的故障。另一类方法采用发动机仿真模型产生的数据进行验证。而真实的ACARS数据容易受工况和外界环境变化的影响而发生复杂变化。因此,与仿真数据相比,真实的ACARS数据质量较低且复杂性较高。此外,还有另一类方法使用少数几个性能参数进行发动机故障检测,此类方法难以运用于高维的ACARS数据。因此,当前大多数发动机故障检测方法难以有效地处理ACARS数据。
由于在很多高维复杂的模式识别问题中取得了很好的结果,最近几年卷积自动编码器(CAE)得到了越来越多研究者的关注。现有技术中存在一种采用卷积稀疏自编码器对电力传输线路进行故障检测与分类的方法,该方法中的卷积去噪自动编码器模型对多维时间序列的所有变量同步进行处理,然而其试验数据集维度仅为6。当采用它来处理参数关系复杂、维度高且包含大量噪声的ACARS数据时,可能会面临局部特征被淹没,特征表示能力下降,模型复杂度高,参数数量庞大,计算资源与时间消耗多等问题。
技术实现要素:
本发明要解决的技术问题在于,针对现有的故障检测方法不适于处理关系复杂、维度高且包含大量噪声的ACARS数据的问题,将分组操作、卷积神经网络、自编码器以及支持向量机相结合,提出了一种基于分组卷积去噪自编码器的航空发动机故障检测方法及系统,用于处理ACARS数据。
为了解决上述技术问题,本发明第一方面,提供了一种基于分组卷积自编码器的航空发动机故障检测方法,包括以下步骤:
变量分组步骤、基于变量之间的相关性将飞机通讯寻址与报告系统数据的变量分成多个变量组;
特征提取步骤、采用卷积去噪自动编码器模型独立地提取每个变量组的特征;
故障识别步骤、将所有变量组的特征融合起来形成特征向量,基于该特征向量采用支持向量机来识别故障样本。
在根据本发明所述的基于分组卷积自编码器的航空发动机故障检测方法中,优选地,所述特征提取步骤包括以下子步骤:
无监督学习子步骤、采用去噪自动编码器模型对每个变量组的卷积核进行无监督学习;
卷积操作子步骤、将每个变量组的ACARS数据片段与对应的卷积核进行卷积,求得每个变量组的卷积特征图;
池化操作子步骤、基于每个变量组的卷积特征图进行池化操作,得到每个变量组的池化特征。
在根据本发明所述的基于分组卷积自编码器的航空发动机故障检测方法中,优选地,所述故障识别步骤中将每个变量组的池化特征向量化,组合所有变量组的池化特征构成样本的特征向量,基于特征向量采用支持向量机进行模式识别,识别ACARS数据中的故障样本。
本发明第二方面,提供了一种基于分组卷积自编码器的航空发动机故障检测系统,包括:
变量分组模块,用于基于变量之间的相关性将飞机通讯寻址与报告系统数据的变量分成多个变量组;
特征提取模块,用于采用卷积去噪自动编码器模型独立地提取每个变量组的特征;
故障识别模块,用于将所有变量组的特征融合起来形成特征向量,基于该特征向量采用支持向量机来识别故障样本。
在根据本发明所述的基于分组卷积自编码器的航空发动机故障检测系统中,优选地,所述特征提取模块包括:
无监督学习单元,用于采用去噪自动编码器模型对每个变量组的卷积核进行无监督学习;
卷积操作单元,用于将每个变量组的ACARS数据片段与对应的卷积核进行卷积,求得每个变量组的卷积特征图;
池化操作单元,用于基于每个变量组的卷积特征图进行池化操作,得到每个变量组的池化特征。
在根据本发明所述的基于分组卷积自编码器的航空发动机故障检测系统中,优选地,所述故障识别模块中将每个变量组的池化特征向量化,组合所有变量组的池化特征构成样本的特征向量,基于特征向量采用支持向量机进行模式识别,识别ACARS数据中的故障样本。
实施本发明的基于分组卷积自编码器的航空发动机故障检测方法及系统,具有以下有益效果:本发明首先依据ACARS数据变量之间的相关性将所有变量划分为几组,然后采用卷积去噪自动编码器模型独立地提取每个变量组的特征,最终融合所有特征形成特征向量,基于这些特征向量识别故障样本;本发明不需要大量的专家知识与经验;本发明避免了繁琐的数据预处理工作;本发明在没有大量良好的有标签样本的情况下仍然具有较好的综合故障检测性能;本发明鲁棒性较好,适合于工程实践;本发明计算与时间成本较低。
附图说明
图1a和图1b分别为巡航阶段一段平滑的性能偏差数据与对应的原始ACARS数据图;
图2为根据本发明优选实施例的基于分组卷积自编码器的航空发动机故障检测方法的流程图;
图3为根据本发明的优选实施例的基于分组卷积自编码器的航空发动机故障检测方法的整体技术框架图;
图4为根据本发明的卷积核无监督学习的示意图;
图5为大部分机器学习模型与本发明采用的卷积神经网络对比示意图;
图6为全连接网络与本发明采用的稀疏连接网络的对比示意图;
图7为卷积神经网络的参数共享示意图;
图8为本发明采用滑动窗提取ACARS数据片段的示意图;
图9为本发明的ACARS卷积特征图生成过程示意图;
图10为根据本发明优选实施例的基于分组卷积自编码器的航空发动机故障检测系统的模块框图;
图11为根据本发明优选实施例的基于分组卷积自编码器的航空发动机故障检测系统中特征提取模块的示意图;
图12a和图12b分别为变量分组结果的系统树图和成本随着分组数量的变化图;
图13为测试集中三种方法精度的箱形图;
图14为测试集中三种方法召回率的箱形图;
图15为测试集中三种方法F1值的箱形图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明提出一种新颖且有效的基于ACARS数据的基于分组卷积自编码器的航空发动机故障检测方法。该方法在没有要大量良好的有标签样本的情况下仍然具有较好的综合故障检测性能,计算与时间成本较低,并且不需要大量的专家知识与经验,避免了繁琐的数据预处理工作。首先,该方法没有对ACARS数据的所有变量直接提取特征,而是基于变量之间的相关性将它们划分为几个变量组。然后,对每一变量组独立地进行无监督特征提取,并将提取的特征权重转化为卷积核。接着,对每一变量组进行卷积特征映射与池化操作来提取ACARS变量组的特征。最后将所有变量组的特征融合起来形成特征向量,基于特征向量采用支持向量机(SVM)来识别故障。在某型民航发动机的真实ACARS数据上进行故障检测试验验证本发明方法与其他几种对比方法。试验结果表明本发明方法的综合故障检测性能最好,参数数量相对较少,计算速度较快,证明了本发明方法的优越性。
请参阅图2,为根据本发明优选实施例的基于分组卷积自编码器的航空发动机故障检测方法的流程图。如图2所示,该实施例提供的基于分组卷积自编码器的航空发动机故障检测方法包括以下步骤:
首先,在步骤S1中,执行变量分组步骤,基于变量之间的相关性将飞机通讯寻址与报告系统(ACARS)数据的变量分成多个变量组。
随后,在步骤S2中,执行特征提取步骤,采用卷积去噪自动编码器模型独立地提取每个变量组的特征。
最后,在步骤S3中,执行故障识别步骤,将所有变量组的特征融合起来形成特征向量,基于该特征向量采用支持向量机来识别故障样本。
请参阅图3,为根据本发明的优选实施例的基于分组卷积自编码器的航空发动机故障检测方法的整体技术框架图。下面结合图3对本发明方法的具体实现过程进行详细介绍。
S1、变量分组步骤:对ACARS变量进行分组;
本发明引入了变量分组操作,根据ACARS变量之间的相关性对它们进行分组,将相关性较强的变量放在同一组,将不相关或者弱相关变量放入不同的组中。完成变量分组操作以后,对每一变量组进行无监督学习可以获得能够更好表示ACARS数据分布空间的特征。除此以外,变量分组以后的参数数量与时间复杂度相比原先都大大减少,网络计算效率大大提高。目前常用的变量分组方法有时间序列k-means聚类、独立变量分组分析(IVGA)、凝聚独立变量分组分析(AIVGA)等。本发明采用AIVGA方法对ACARS数据变量进行分组,具有自动确定最优分组数量、计算速度快等优势。
优选地,上述变量分组步骤S1中采用AIVGA方法对ACARS数据的变量进行分组,其中给定一个ACARS数据集X=[x1x2,…,xm],xi代表第i个变量,变量xi=(xi(1),...,xi(T))是一个时间序列,T是时间序列长度。该步骤中AIVGA算法的目的是对ACARS数据集的多维变量进行分割,将m维变量分割成n个互不相连的子集G={Gi|j=1,...,n},使得不同变量组的模型Hi的边缘对数似然性的总和最大化,其中Gi为第i个变量组的ACARS变量集合。
为近似获得边缘对数似然性,采用变量贝叶斯近似qi(θi)拟合不同变量组模型的后验分布在模型拟合过程中成本函数C被最小化。成本函数C如下所示:
式中,DKL(q||p)表示q和p之间的Kullback-Leibler散度。
成本函数与交互信息的关系可以被表示为:
H(x)表示x的熵,IG(x)表示分组G中的交互信息。
S2、特征提取步骤
优选地,步骤S2包括:
S21、无监督学习子步骤,采用去噪自动编码器模型对每个变量组的卷积核进行无监督学习。
S22、卷积操作子步骤,将每个变量组的ACARS数据片段与对应的卷积核进行卷积,求得取每个变量组的卷积特征图。
S23、池化操作子步骤,基于每个变量组的卷积特征图进行池化操作,得到每个变量组的池化特征。
下面对特征提取步骤进行详细介绍。
常用的无监督特征学习模型有自动编码器(AE)、去噪自动编码器(DAE)、受限波尔兹曼机(RBM)等。其中,DAE模型容易构造,降维效果好,去噪能力强,提取的特征鲁棒性好。Dropout可以对DAE模型进行优化,进一步改善DAE提取的特征,因此本研究中采用带有dropout的DAE模型提取ACARS数据的特征。
以往的方法中都是将所有变量作为一个DAE模型的输入,提取的特征集是所有变量的函数f的集合,此时提取的ACARS数据特征集如式3所示。
features={f(ZT49,ZPCN12,ZPCN25,ZWF36,…)} (3)
式3中ZT49(排气温度)、ZPCN12(风扇指示转速)、ZPCN25(核心机指示转速)、ZWF36(燃油流量)均为ACARS数据的变量。
本发明中每个DAE都是在某个变量组Gi中单独训练的,因此DAE的数量与变量组相同,提取的特征集是同组变量的函数集合。假设ACARS数据中的所有变量被划分为G1、G2、G3三个变量组,提取的特征集如式4所示:
features={f1(G1),f2(G2),f3(G3)}
式中ZALT(高度),ZT1A(大气总温)均为ACARS数据的变量。
在每个变量组而不是在所有变量上训练卷积核至少有两点好处。首先,分组进行无监督学习获得的特征具有更强的代表性,能够更好地表示ACARS数据的分布空间。这是因为将大型问题转化为可以独立建模的子问题是提高模型紧密性的有效手段。现有技术中已经证明将多维变量依据相关性划分为变量子集时,独立对变量子集进行建模可以获得更加紧密且有效的模型,具有更好的鲁棒性以及泛化性。
其次,本发明提出的方法中网络参数数量大幅减少,时间复杂度降低。假设ACARS数据片段长度为l,维度为m,则DAE模型的输入维度为ml。为使提取的特征不丢失太多的原始数据信息,隐层节点数量通常应比输入层稍微低一点,假设隐层节点数为ml-s1,s1<<ml。如果将ACARS数据的所有变量平均划分为n组,每个DAE模型的输入向量维度为ml/n,隐层节点数为ml/n-s2,n<<ml,s2<<ml/n。对比文件1的方法(Chen KJ,Hu J,He JL.Detection and Classification of Transmission Line Faults Based on Unsupervised Feature Learning and Convolutional Sparse Autoencoder.IEEE T SMART GRID,2016;(99):1-11.)与本发明方法各指标对比如表1所示。
表1对比文件1的方法与本发明方法各指标对比
两种方法的参数总量之比为:
本发明提出的方法中的权重参数总量与时间复杂度近似减小为对比文件1的1/n,这样不仅可以加快计算速度,还对实现网络的并行训练有帮助。现有技术中也证明了并行训练可以突破单台设备的性能极限,训练更大规模的网络并在分类任务中获得更高的精度。
该步骤S21中通过DAE对卷积核进行无监督学习。卷积核无监督学习的示意图如图4所示。该无监督学习子步骤S21具体包括:
(1)将每个ACARS数据片段向量化成为一维向量A。DAE模型只能接受一维向量形式的输入,因此每个ACARS数据片段需要向量化成为一维向量A=[ZT49(t)ZPCN12(t)ZPCN25(t)ZWF36(t)…](t=1,2,…T)。
(2)通过一个随机函数sf(·),将一维向量A污染成
图4中,A是原始输入数据,是污染后的输入数据。本发明中采用了遮蔽方法污染输入数据,它随机让λ比例的样本变为0。通过一个随机函数sf(·),A被污染成如下式所示:
(3)随后,将映射到隐层表示h,如下式所示:
式中,σ表示输入层与隐层之间的激活函数,优选地,本发明中采用的激活函数为Sigmoid函数。W是输入层与隐层之间的权重矩阵,b是偏置向量。
(4)通过Dropout模型正则化技术,产生一个包含0-1随机数且服从伯努利分布的向量bv,将该向量与隐层表示h进行内积运算得到
Dropout是一种模型正则化技术,它具有计算方便以及正则化效果好等优势。
(5)将映射到A的重构Z,该过程可以表示如下:
式中,WT是输入层与隐层之间的权重矩阵W的转置,c是隐层与输出层之间的偏置向量。
(6)基于输入数据A、输出数据Z以及正则化项构建目标函数,通过最小化目标函数得到权重矩阵W和偏置向量b的最优值Wopt与bopt,其中最优值Wopt变形为卷积核,bopt作为偏置向量在卷积操作中使用。
DAE的训练目标是使输出数据Z与原始输入数据A尽可能一致。DAE的目标函数J可以表示为:
式中,m是训练样本的数量,Zi是输出数据,Ai是输入数据,Wi是输入层节点与隐层节点之间的权重,D是KL散度函数,ρ是稀疏参数,是隐层节点j对所有输入层节点的平均激活度,λ和β是对应项的系数。
通过最小化目标函数J,可以得到权重矩阵W和偏置向量b的最优值Wopt与bopt:
然后,Wopt变形为卷积核,bopt作为偏置向量在卷积特征映射与池化中使用。
机器学习领域中的大部分模型只能接受向量形式的输入。因此可以将ACARS时间序列向量化,然后输入到机器学习模型中进行模式识别。然而ACARS时间序列向量化以后会丢失不同变量之间的相关关系。卷积神经网络(CNN)可以直接处理网格结构数据,能够将ACARS的各变量值以及它们之间的关系一起输入。两种方法对比如图5所示。
CNN中每个隐层的节点只与部分输入节点连接,这种性质叫做稀疏连接。稀疏连接与全连接神经网络的对比如图6所示。稀疏连接能够有效地提取数据局部特征,非常适合于检测ACARS时间序列中的局部故障片段。图6中,神经网络输入层中有1个故障节点x1(红色)和4个正常节点x2、x3、x4、x5。全连接网络中,隐层节点h1与x1、x2、x3、x4、x5相连,x1的故障模式被其他正常模式掩盖,隐层节点h1、h2、h3激活度都较低。稀疏连接中,h1只与x1、x2、x3相连,h1受到x1影响较大,激活度较高。
除了能够有效捕捉ACARS数据中的局部特征外,稀疏连接还可以大大减少网络参数数量,降低模型复杂度。假设输入层与隐层分别有r和s个节点,全连接神经网络中会有(r+1)×s个参数,计算时间复杂度为O(r×s+s)。稀疏连接网络中隐层的每个节点只跟输入层t(t<r)个节点连接,参数数量为(t+1)×s,计算时间复杂度为O(t×s+s),降为原来的(t+1)/(r+1)。比如图6中全连接网络中参数数量为18,稀疏连接网络中参数数量为12。
除了稀疏连接,CNN还具有参数共享的性质,即同一隐层的所有节点都具有相同的权重,如图7所示。这样不仅可以进一步减少模型参数数量,还能用卷积运算代替计算成本较高的矩阵乘法运算,提高网络计算速度。
本发明中采用滑动窗口方法提取ACARS数据片段。滑动窗口sldwin长度为lw,u是ACARS数据变量组的维度。假设滑动窗口的起始点到达ACARS数据第i列时,sldwin的起始点是pi,结束点是pi+lw-1。获得当前窗口的ACARS数据片段以后,sldwin会前移一步。此时,pi点将会从sldwin中排除,pi+lw点会被添加进sldwin,窗口的起始点和结束点变为pi+1和pi+lw。该窗口在ACARS时间序列数据中不断向前滑动,生成ACARS数据片段,如图8所示。
卷积计算也是分组进行的,对每个变量组的ACARS数据片段与对应的卷积核进行卷积,求得每个变量组的卷积特征图。值得注意的是卷积运算以前需要对ACARS数据进行归一化处理,这是因为卷积核是在归一化以后的ACARS数据上训练的。第i个ACARS数据片段seg(i)∈Ru×lw与第j个卷积核k(j)∈Ru×lk进行卷积运算可以得到卷积特征图fm∈R1×(lw-lk+1),计算公式如式12所示,计算过程如图9所示。
fm=σ(seg(i)*k(j)+bj) (12)
式中,bj为偏置,“*”为卷积运算符号。
池化操作使特征集具有局部平移不变性。局部平移不变性对于ACARS片段故障检测非常有用,因为我们判断某段ACARS序列片段是否为故障片段时,只关心故障是否出现,而不关心故障出现的位置。此外,池化还能够选择明显的ACARS特征,降低特征维度,提高网络计算效率。较为常用的池化方法有最大池化、平均池化、空间金字塔池化、随机池化,L2池化等。本发明中选取最大池化与平均池化方法进行研究。
与卷积一样,池化也是在ACARS数据每个变量组的卷积特征图上独立进行的。
S3、执行故障识别步骤
完成池化操作以后,将ACARS数据每个变量组的池化特征向量化,组合所有变量组的池化特征构成样本的特征向量。SVM在解决小样本,非线性以及高维数据分类问题中具有较强优势,因此本发明采用SVM对特征向量进行分类,识别ACARS数据中的故障片段。
请参阅图10,为根据本发明优选实施例的基于分组卷积自编码器的航空发动机故障检测系统的模块框图。如图10所示,该实施例提供的基于分组卷积自编码器的航空发动机故障检测系统100包括:变量分组模块110、特征提取模块120和故障识别模块130。
其中,变量分组模块110用于基于变量之间的相关性将飞机通讯寻址与报告系统数据的变量分成多个变量组。该变量分组模块110与前述方法中变量分组步骤S1的实现过程相同,在此不再赘述。
特征提取模块120用于采用卷积去噪自动编码器模型独立地提取每个变量组的特征。
故障识别模块130用于将所有变量组的特征融合起来形成特征向量,基于该特征向量采用支持向量机来识别故障样本。
请参阅图11,为根据本发明优选实施例的基于分组卷积自编码器的航空发动机故障检测系统中特征提取模块的示意图。如图11所示,优选地,特征提取模块120进一步包括:无监督学习单元121、卷积操作单元122和池化操作单元123。
其中,无监督学习单元121用于采用去噪自动编码器模型对每个变量组的卷积核进行无监督学习。该无监督学习单元121与前述方法中无监督学习子步骤S21的实现过程相同,在此不再赘述。
卷积操作单元122用于将每个变量组的ACARS数据片段与对应的卷积核进行卷积,求得每个变量组的卷积特征图。该卷积操作单元122与前述方法中卷积操作子步骤S22的实现过程相同,在此不再赘述。
池化操作单元123用于基于每个变量组的卷积特征图进行池化操作,得到每个变量组的池化特征。该池化操作单元123与前述方法中池化操作子步骤S23的实现过程相同,在此不再赘述。
故障识别模块130将每个变量组的池化特征向量化,组合所有变量组的池化特征构成样本的特征向量,基于特征向量采用支持向量机进行模式识别,识别ACARS数据中的故障样本。
下面通过对真实的ACARS数据进行试验来比较本发明方法与其他几种方法的故障检测性能。
1、数据集的准备
不同类型的发动机的操作特性存在差异。为了尽可能减小这种差异性,实验中的所有ACARS数据都来自于CFM56-7B26发动机。为了帮助航空公司及时发现发动机故障,OEM通常会向航空公司发送客户通知报告(CNR)。CNR记录了发动机性能偏差数据的异常变化,并判断发动机可能发生的故障类型。因此,本实验中根据CNR确定ACARS数据标签。试验中选取的19个ACARS参数如表2所示。
表2试验中选取的19个ACARS参数
根据CNR的记录,试验中选定的所有发动机都至少发生过一次故障。具体来说,发生的故障类型有:排气温度指示器故障、燃油流量指示器故障、大气总温传感器指示故障、核心机衰退故障以及风扇不平衡故障。性能参数偏差值发生异常变化期间的发动机运行数据被认为是故障样本,其他时间内发动机运行数据被认为是正常样本。变量分组以及卷积核的无监督学习时使用了18530个正常样本。训练和测试支持向量机时使用了6606个样本(其中857个是故障样本)。
2、试验流程
按照以下步骤进行试验:
(1)对ACARS变量进行分组
AIVGA算法将正则化处理后的数据作为输入,变量分组结果如图12a和图12b所示。
图12a为变量分组结果的系统树图,它给出了每一步的分组结果,虚线处表示最佳分组方案。图12b为成本随着分组数量的变化。显然,分组数量为4时成本最小。表3给出了ACARS参数的最优分组结果。
表3 ACARS参数的最优分组结果
(2)构建DAE模型
由于输入变量被划分为4个变量组,针对每个变量组训练一个DAE,一共建立4个DAE模型。采用深度学习工具箱构建DAE模型。DAE模型的超参数主要依靠其基本原理与多次试验确定。所有DAE模型的超参数值如表4所示。
表4所有DAE模型的超参数值
(3)卷积特征映射与池化
每一片段的长度为30。经多次试验验证,最终采用了最大池化方法。池化维度为5时,故障检测效果最好。
(4)支持向量机
试验中采用功能强大的LIBSVM工具箱构建支持向量机模型,支持向量机的参数设置如表5所示。
表5支持向量机的参数设置
给定的数据集被划分为训练集与测试集。由于故障样本数量有限,采用5层交叉验证方法来选择最好的模型。
(5)评价指标的选择
本发明在试验中使用的数据集是严重不平衡的。在这种情况下,精度、召回率以及F1值3个指标可以较好地度量故障检测性能。它们的计算公式见于文献(Luo H,Zhong SS.Gas turbine engine gas path anomaly detection using deep learning with Gaussian distribution.PHM-Harbin:2017Prognostics and System Health Management Conference;2017July 9-12;Harbin,China.New York:IEEE,2017.p.1-6)。
所有的算法都是在MATLAB R2010b中运行的,使用的计算机包含两个英特尔酷睿i5(2.3GHz主频)CPU、8GB内存以及Windows10专业版操作系统。
3、试验结果与讨论
表6中的值是五次交叉验证试验结果的平均值。每一列中最高分用粗体表示(除了无限大以外)。
表6五次交叉试验结果的平均值
表6中上标处:1、此处精度与F1值无穷大是因为算法将所有样本都识别为正常样本从表6中可以观察到SVM在训练集中故障检测性能最好,但是在测试集中性能最差。这是因为ACARS序列样本维度太高,且属性之间存在冗余,导致使用SVM时出现了过拟合。在SVM前增加DAE可以降低特征维度,去除ACARS数据中的冗余,部分消除ACARS数据中的噪音,因此该方法在测试集中的性能要优于第一种方法。
因为稀疏连接网络能够较好地提取数据中的局部特征,相对于前两种方法,后三种方法具有更优的故障检测性能,是本研究中的重点比较对象。后三种方法的精度、召回率以及F1值的箱形图如图13-15所示。
从图13至图15可以发现,尽管本发明方法精度上比全维度CDAE方法差一点,但是在召回率、F1值上不论是中位值还是分布范围都要明显优于另外两种方法。相比于精度和召回率,F1值更能代表故障检测的综合性能。更重要的是,在发动机健康管理工程实践中,召回率一般比精度更重要。这是因为精度降低会增加工作量,但是召回率降低会减少飞行安全性。两者相比,安全毫无疑问是更加重要的。因此,相比于另外两种方法,本发明提出的方法更加适合于发动机健康管理的工程实践。
局部维度CDAE方法能够较好地提取图像表示。但ACARS序列与图片之间存在结构差异。一般来说,图片中像素点距离越近,相关性较强。对于ACARS序列来说,时间轴上的点的距离越近,相关性较强,这点与图像比较一致。但是属性轴上的变量之间的相关性和距离远近没有关系。因此该方法在ACARS数据上效果并不很好。
与对比文件1的方法相比,本发明方法中引入了变量分组操作,提取特征的所有步骤都是每个变量组上独立进行的。前文已经分析,分组提取特征能够更好地表示ACARS数据的分布空间,因此本发明提出的方法具有更好的故障检测综合性能,且鲁棒性更强。
本发明方法与对比文件1方法的计算时间与参数数量对比如表7所示。从表中可以发现,本发明方法参数数量近似为对比文件1的1/4,计算时间也明显少于对比文件1的方法,实验结果证明了本发明前述方法部分的分析。
表7本发明方法与对比文件1方法的计算时间以及参数数量对比
综上所述,本发明的基于分组卷积自编码器的航空发动机故障检测方法及系统,具有以下特点:
(1)当前大多数航空发动机故障检测方法都以OEM提供的性能偏差数据为基础。为提高自主发动机故障检测能力,本发明提出一种全新的基于原始的ACARS数据的航空发动机故障检测方法。该方法摆脱了对OEM的依赖,并且具有较好的综合故障检测性能。
(2)本发明针对以往的卷积去噪自编码器不能适用于高维度、参数关系复杂的ACARS数据,提出一种分组卷积去噪自编码器模型。该模型能够从ACARS数据中提取更加有代表性的特征。同时该方法还能减少参数数量,降低模型时间复杂度,减小计算与时间成本。最后,本发明方法不需要大量专家知识经验,也避免了繁琐的数据预处理工作。
(3)收集CFM56-7B26发动机的真实的ACARS数据验证本发明方法以及对比方法的有效性。试验结果证明本发明方法在故障检测综合性能以及鲁棒性方面都要优于其他方法,更加适合于发动机健康管理的工程实践。除此以外,本发明方法中的参数数量与时间成本与对比文件1中的标准卷积去噪自编码器方法相比要少很多。
- 还没有人留言评论。精彩留言会获得点赞!