按照多级类目处理信息的方法和装置与流程
本发明涉及计算
技术领域:
,特别地涉及一种按照多级类目处理信息的方法和装置。
背景技术:
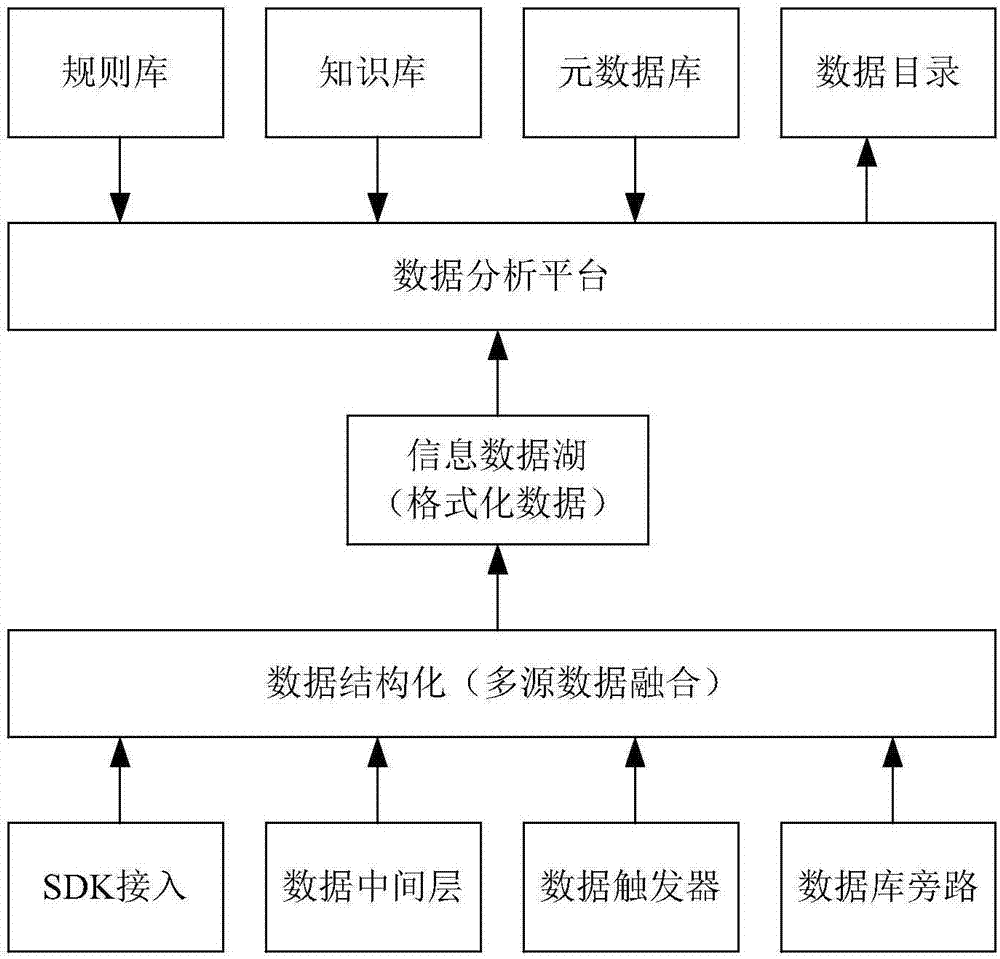
:目前的很多单位都有自己的信息系统,用以记录经过分类和汇总的信息;近期,在政务管理或者其他应用场合下,需要将各单位的信息作进一步的汇总以及共享。各单位的数据通常具有一定程度的结构化,可称作元数据,一条元数据的内容例如表1所示。表1对于汇总以及共享的政务信息,可以根据事先提供的目录进行管理。例如,确定目录编制的依据为上海市地方标准DB31/T745—2013政务信息资源共享与交换实施规范。目录的一种结构如表2所示。表2ZA综合政务ZAA00政务综合类ZAB00方针政策ZAC00中共党务ZB经济管理ZBA00经济管理综合类ZBB00经济发展计划ZC国土资源、能源ZCJ00电力ZCK00其他其中“ZA”、“ZB”、“ZC”为一级目录,其余为二级目录。将各单位作为数据源,从各单位的数据库中获取数据然后按给定的目录进行保存。因为各目录的设置体现了信息内容所属的类目,所以目录也可以称作类目。发明人在实现本发明的过程中发现,在从数据源获取数据然后按给定目录进行保存时,根据数据本身的内容,有时难以归到合适的目录下。对于这种情况,需要有一种合适的处理方式。技术实现要素:有鉴于此,本发明提供一种按照多级类目处理信息的方法和装置,有助于比较合理地处理来自于数据源但难以归到事先给定的目录的合适位置的数据,从而有助于提高信息汇总的质量。本发明的其他目的和有益效果将结合具体实施方式加以说明或体现。为实现上述目的,根据本发明的一个方面,提供了一种按照多级类目处理信息的方法。本发明的按照多级类目处理信息的方法包括:对于包含有多个属性项的文本元数据,确定能够体现该元数据所属类目的一个或多个特征属性;其中所述类目是给定的多级类目系统中的类目;对获取的多条文本元数据中的各条文本元数据的特征属性一一进行判断,以确定该条文本元数据是否属于所述给定的多级类目中某一级别的某一类目,若是,则将该文本元数据保存在该类目下,否则将该文本元数据保存在待分类集合中;使用聚类算法将所述待分类集合中的文本元数据按特征属性聚为多个组,从中确定出成员数量达到预设阈值的组,确定在该组文本元数据的特征属性中出现频率最高的词,将该词作为在所述给定的多级类目中的指定类目下的新建类目的类目名称,然后将该组的文本元数据保存在该新建类目下。可选地,所述对获取的多条文本元数据中的各条文本元数据一一进行判断的步骤之前,该方法还包括采用如下的一种或多种方式获取所述多条文本元数据:使用程序接入服务方式从数据源获取数据然后按照规定格式处理该数据从而得到所述多条文本元数据;使用数据中间层从数据源获取所述多条文本元数据;在数据源的数据库中设置数据库触发器,使得一旦有元数据写入该数据库,即从该数据库中获取该元数据,从而得到所述多条文本元数据;监控数据源的流量,在该流量发生改变的情况下,从数据源的数据库中获取元数据,从而得到所述多条文本元数据。可选地,在所述从中确定出成员数量达到预设阈值的组的步骤之后,该方法还包括:采用卷积神经网络算法确定该组对应的特征属性与所述给定的多级类目中的指定级别的类目名称的相似概率,然后将大于预设值的相似概率对应的指定级别的类目作为所述指定类目。可选地,在所述从中确定出成员数量达到预设阈值的组的步骤之后,该方法还包括:从该组对应的特征属性中获取类目的名称,然后将该名称的类目作为所述指定类目。可选地,所述对获取的多条文本元数据中的各条文本元数据一一进行判断的步骤包括:采用规则匹配的方式,一一判断所获取的多条文本元数据中的各条文本元数据是否属于给定的多级类目中某一级别的类目。可选地,所述对获取的多条文本元数据中的各条文本元数据一一进行判断的步骤包括:采用卷积神经网络算法,一一判断所获取的多条文本元数据中的各条文本元数据是否属于给定的多级类目中某一级别的类目。根据本发明的另一方面,提供了一种按照多级类目处理信息的装置。本发明的按照多级类目处理信息的装置包括:确定模块,用于对于包含有多个属性项的文本元数据,确定能够体现该元数据所属类目的一个或多个特征属性;其中所述类目是给定的多级类目系统中的类目;归类模块,用于对获取的多条文本元数据中的各条文本元数据的特征属性一一进行判断,以确定该条文本元数据是否属于所述给定的多级类目中某一级别的某一类目,若是,则将该文本元数据保存在该类目下,否则将该文本元数据保存在待分类集合中;类扩展模块,使用聚类算法将所述待分类集合中的文本元数据按特征属性聚为多个组,从中确定出成员数量达到预设阈值的组,确定在该组文本元数据的特征属性中出现频率最高的词,将该词作为在所述给定的多级类目中的指定类目下的新建类目的类目名称,然后将该组的文本元数据保存在该新建类目下。可选地,还包括数据获取模块,用于采用如下的一种或多种方式获取所述多条文本元数据:使用程序接入服务方式从数据源获取数据然后按照规定格式处理该数据从而得到所述多条文本元数据;使用数据中间层从数据源获取所述多条文本元数据;在数据源的数据库中设置数据库触发器,使得一旦有元数据写入该数据库,即从该数据库中获取该元数据,从而得到所述多条文本元数据;监控数据源的流量,在该流量发生改变的情况下,从数据源的数据库中获取元数据,从而得到所述多条文本元数据。可选地,还包括类目确定模块,用于:采用卷积神经网络算法确定该组对应的特征属性与所述给定的多级类目中的指定级别的类目名称的相似概率,然后将大于预设值的相似概率对应的指定级别的类目作为所述指定类目。可选地,还包括类目确定模块,用于:从该组对应的特征属性中获取类目的名称,然后将该名称的类目作为所述指定类目。可选地,所述归类模块还用于采用规则匹配的方式,一一判断所获取的多条文本元数据中的各条文本元数据是否属于给定的多级类目中某一级别的类目。可选地,所述归类模块还用于采用卷积神经网络算法,一一判断所获取的多条文本元数据中的各条文本元数据是否属于给定的多级类目中某一级别的类目。根据本发明的又一方面,提供了一种电子设备,包括:一个或多个处理器;存储装置,用于存储一个或多个程序,当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现如本发明所述的方法。根据本发明的又一方面,提供了一种计算机可读介质,其上存储有计算机程序,所述程序被处理器执行时实现如本发明所述的方法。根据本发明的技术方案,在文本元数据无法归类到给定类目系统的情况下,结合聚类方法确定这种文本元数据所属的新建类目,实现了对目录的优化,使得当文本元数据在难以归到合适的现有目录的情况下能够被归入新的合适的目录。对于新建类目,本发明中同样将其归入合适的指定类目,该指定类目是该新建类目的上一级类目。附图说明附图用于更好地理解本发明,不构成对本发明的不当限定。其中:图1是根据本发明实施方式的按照多级类目处理信息的方法的主要步骤的示意图;图2是根据本发明实施方式的一种处理信息的系统的处理逻辑的示意图;图3是根据本发明实施方式的信息资源名称生成的主要逻辑的示意图;图4是根据本发明实施方式的主题分类生成的逻辑的示意图;图5是根据本发明实施方式的按照多级类目处理信息的装置的主要模块的示意图。具体实施方式以下结合附图对本发明的示范性实施例做出说明,其中包括本发明实施例的各种细节以助于理解,应当将它们认为仅仅是示范性的。因此,本领域普通技术人员应当认识到,可以对这里描述的实施例做出各种改变和修改,而不会背离本发明的范围和精神。同样,为了清楚和简明,以下的描述中省略了对公知功能和结构的描述。在本发明实施方式中,对于从数据源获取的文本元数据,在存在给定的目录结构的情况下,若不能归类到已有的多级类目系统的某一级别的类目中,则暂存到待分类集合中,再对待分类集合中的数据进行处理,将其中的部分数据保存到新建的类目下。以下结合附图进行详细说明。图1是根据本发明实施方式的按照多级类目处理信息的方法的主要步骤的示意图。步骤S10:确定元数据中的特征属性。以表1所示的元数据为例,其中的第1、3、6、7行的属性相对能够更好地体现该元数据所属的类目,本实施方式中,将这样的属性称作特征属性。这样,元数据中存在一个或多个特征属性。而像“首次发布日期2017-06-22”这样的属性则难以体现该元数据所属的类目。这里的类目是事先给定的多级类目系统中的已有的或者新建的类目,例如表2所示的多级类目。在本步骤中,确定元数据中的特征属性时,可以利用规则库和/或知识库,采用规则匹配的方式来判断元数据中的各条属性是否为特征属性。此外也可以采用机器学习的方式,例如采用卷积神经网络算法来进行判断。元数据中的一些属性往往已经能够体现该元数据所属的在上述给定的多级类目系统中的较高级的类目,因此主要需要确定还有哪些属性是体现元数据在较低级别中的类目,并且这些类目往往需要新建。为此,可以人工根据大量元数据的内容,新建一些类目,并在类目下保存一定数量的元数据,从而得到训练数据,再采用卷积神经网络算法进行训练之后得到模型。该模型能够识别新接收到的元数据中的特征属性。因为元数据是结构化的数据,所以能够确定其中的特征属性是哪几个属性,例如对于表1所示的元数据,其第1、3、6、7行的属性为特征属性。在确定特征属性是哪些属性之后,可以对从数据源中获取的大量元数据进行处理,以下进行具体的说明。步骤S11:从数据源获取一条文本元数据。获取文本元数据的方式有多种。例如,可以使用程序接入服务方式从数据源获取数据然后按照规定格式处理该数据从而得到多条文本元数据。又如,使用数据中间层从数据源获取多条文本元数据。再如,在数据源的数据库中设置数据库触发器,使得一旦有元数据写入该数据库,即从该数据库中获取该元数据,从而得到多条文本元数据。此外还可以监控数据源的流量,在该流量发生改变的情况下,从数据源的数据库中获取元数据,从而得到多条文本元数据。步骤S12:判断获取的当前文本元数据是否属于给定的多级类目的某一级别的类目。若是,则进入步骤S13;否则进入步骤S14。具体判断时,可采用规则匹配的方式进行判断;也可以采用机器学习的方法例如卷积神经网络算法的模型进行识别。步骤S13:将当前文本元数据保存在步骤S12中所确定的该文本元数据所属的类目下。本步骤之后返回步骤S11,继续获取文本元数据然后按照类似的方式进行处理。步骤S14:将当前文本元数据保存在待分类集合中。该待分类集合是预先设置的并且用来保存在步骤S12中无法归类的文本元数据。步骤S15:使用聚类算法对待分类集合中的文本元数据按特征属性分为多个组。这样每个组对应一个特征属性。步骤S16:对于成员数量达到预设阈值的组,确定在该组文本元数据的特征属性中出现频率最高的词,将该词作为新建类目的类目名称,将该组的文本元数据保存在该新建类目下。需要说明的是,该新建类目是指定类目下的类目。如上文所述,元数据中的一些属性往往已经能够体现该元数据所属的在上述给定的多级类目系统中的较高级的类目,如果成员数量达到预设阈值的组对应的特征属性也是这种情况,那么可以直接从特征属性中获取类目的名称,将该名称的类目作为指定类目。也可以采用卷积神经网络算法确定成员数量达到预设阈值的组对应的特征属性与给定的多级类目中的指定级别的类目名称的相似概率,然后将大于预设值的相似概率对应的指定级别的类目作为指定类目。根据图1所示的流程,实现了对目录的优化,使得当文本元数据在难以归到合适的现有目录的情况下能够被归入新的合适的目录。以下通过具体的实例进一步对本发明实施方式加以说明。该实例中,通过对信息系统的信息采集,建立数据基础库。通过利用词向量的模式,利用卷积神经网络对采集的基础数据进行分析。通过目录设定、信息采集和数据分析,来实验证数据目录的正确性和建立填充完整的数据目录的目标。本实施例涉及的处理组件主要包含建立目录服务、数据采集服务、数据分析服务。其中各服务的主要功能如下:建立目录服务:通过对现在上海市地方标准DB31/T745—2013政务信息资源共享与交换实施规范,来设定目录规范,建立完整的目录规则。数据采集服务:主要负责各项元数据的收集、整理和汇总。数据分析服务:将数据采集服务收集来的元数据根据建立目录规则,根据卷积神经网络算法验证本身目录的正误,错误的予以纠正,放入正确的目录下。各组件的技术方案主要有以下方面:建立目录服务:确定目录编制的依据为上海市地方标准DB31/T745—2013政务信息资源共享与交换实施规范;确定目录编制规范的格式为10个必选的元数据实体/元数据元素;确定元数据实体/元数据元素的规则:自动生成、预先设定的知识库。数据采集服务:数据通过多种方式采集,SDK接入、数据中间层、数据库触发器、数据库旁路等方式来采集数据;设置一个信息数据湖,专门用来放置采集来的信息;将采集来的数据以格式化的方式放置信息数据湖中。数据分析服务:对搜集到的数据进行词向量分析;解析出以词为单位的二维矩阵的词序列;连接卷积层、激活层和池化层,进入全连接阶段,并在激活层输出属于类目的概率;若所有属性概率均大于60%,放置相应目录下;将本数据加入数据集中;不大于60%的放置队列末尾继续循环,若在重复预先设定的次数例如50次之后,依旧不能确定本数据属于哪个类目,则将本数据放入待分类目录下。在待分类目录中已经存在较多数据(具体数据量可以设定)的情况下,根据聚类算法将待分类目录中的数据按关键属性分类成多个组,对于成员数量达到预设阈值的组,例如成员数量达到5000,则将该组中的成员的关键属性中,出现频率最高的词作为新类目的名称。如采用上述的目录编制的依据,则新类目可以是三级目录,另再确定该三级目录所属的二级目录。以上技术方案主要具有如下优点:制定规范完整的编目规则,为现有元数据提供编目和规整依据;通过多种方式的数据扩展,多项收集各项数据,为数据的有效编目提供强有力的支撑;通过卷积神经网络算法和模型,对数据进行分析和规整,最终实现对数据的自动编目;通过制定编目规则、对数据收集和数据分析,实现了元数据的自动编目,可以促使各个单位之间数据交流和互通;通过使用卷积神经网络算法,有效提高自动编目的正确率。以下结合附图做进一步说明。图2是根据本发明实施方式的一种处理信息的系统的处理逻辑的示意图。该系统分为数据采集(实现图中的数据结构化)、信息数据湖、数据分析平台三个大的模块。首先采集数据。采集数据的方式有多种,可以有SDK接入、数据中间层、数据库触发器、数据旁路等。将通过各种方式采集来的数据以结构化的方式放入数据结构化平台。系统支持多种数据源同时接入,即支持多来源融合。将格式化后的数据放入信息数据湖中。这些数据的标签尽量按照信息资源公开方式、信息资源获取方式、信息资源提供方的格式存入。至此,收集来的数据已经准备完毕,等待进入数据分析平台。信息数据湖的数据已经按照规则大致放入对应的目录下。在数据分析平台,每个目录按照或规则库、或知识库的形式存在,根据卷积神经网络算法,将之前格式化好的数据放置入对应的位置,若无对应,则根据规则,即生成目录。知识库的内容例如:市级机构代码、区县级机构区域代码、国家主题分类、上海市/部门主题分类二级类目代码、信息资源共享方式、信息资源更新频度、信息资源交换方式、信息资源公开方式、信息资源获取方式、信息资源收费方式、数据类型等。数据采集服务主要负责各项元数据的收集、整理和汇总。通过不同收集方式获取数据时,尽可能按照建立目录服务中需要的格式采集数据详尽的信息,再将格式化的数据汇入信息数据湖。数据采集服务采用多种采集技术相结合的方式。主要是SDK接入、数据中间层、数据库触发器、数据旁路等。SDK接入:程序接入服务,提供数据采集的SDK,将数据按照规定格式处理好,放入信息数据湖中。数据中间层:应用层接入,在数据库和客户端之间增加数据中间层,通过这种方式拿到数据信息。数据库触发器:这个是位于数据库的数据采集方式,采用植入部署的方式。一旦有元数据写入数据库,即将元数据信息汇总。数据库旁路:采用旁路部署方式,不需要植入部署,采用数据库流量监控的方式来获取到元数据。现在以数据库旁路为例介绍目录关键信息生成方法。数据采集时,数据旁路方式能采集到的信息主要有:信息系统名称、操作方式(增加/修改/查询)、数据表名称、数据列名称、数据列数据等。在数据整理阶段,将采集到的信息,例如数据列名称、数据等根据公共目录需要的信息整理,提取出相关信息,即形成格式化数据。提取方式则是根据数据列名称直接拿到相关信息,以结构化的方式保存。最后将格式化数据回收,存入信息数据湖中。在数据采集的基础上,可以实现信息资源名称生成和主题分类生成。图3是根据本发明实施方式的信息资源名称生成的主要逻辑的示意图。在数据采集之后,将采集到的数据经过整理和属性分析模型的分类,变成格式化后的元数据信息,可以拿到数据项的属性信息。根据现有目录、现有部门的资源名称的汇总、对数据的某些属性进行规则匹配,匹配成功,则完成数据项归类。若不成功,需要根据数据匹配模型来分析和学习,即卷积神经网络算法,最终将数据项归类。若依旧不成功,即建立新的资源名称。图4是根据本发明实施方式的主题分类生成的逻辑的示意图。将采集整理后或者通过属性分析模型建立的元数据信息,提取属性信息,根据数据匹配规则来归类,成功则生成信息主体分类,不成功,继续根据知识库中的信息,通过卷积神经网络算法这个数据匹配模型,得到最终的信息主体分类,如果不存在,继续学习,直至能够判别成功。主题分类生成的具体过程如下:(1)预处理,创建数据集。将国家主题分类、部门主题分类作为知识库。(2)从信息数据湖中取出一条格式化的元数据。将元数据的特征属性一一列出,等待分析成词向量。(3)将数据的各个属性一一通过词向量训练,进入压平卷积,来分析属于每个类别中的概率。如果有某个属性相近概率超过90%,直接判别属于的国家主题分类或者部门主题分类。(4)若没有超过90%的,获取所有的属性概率,计算均值,超过60%则判断为所属国家主体分类或者部门。将这一部分数据放置数据集中。(5)若依旧没有得到所属分类,将这条元数据放置全连接循环队列,继续循环。以下对于建立目录服务再加以说明。作为举例,以下的描述中,通过对现在上海市地方标准DB31/T745—2013政务信息资源共享与交换实施规范,来设定目录规范,建立完整的目录规则。自动编目系统的目录的主要内容例如有如下10个,以及该10个必选的元数据实体/元数据元素和获取方法分别如下:1)信息资源名称:自动生成2)信息资源摘要:自动生成3)信息资源提供方:知识库,预先设定4)信息资源分类:自动生成,取值:国家主题分类、部门主题分类5)信息资源共享属性:知识库6)信息资源公开属性:知识库7)信息资源所属系统说明:知识库8)信息资源标识符:自动生成(结合知识库)前段码(6位)/后段码(6位),自动生成机构代码(3位)+内部扩展码(3位)/系统流水号(6位)9)元数据标识符:自动生成(结合知识库)分类号-目录编制年份-流水号,总长度为16位字符,自动生成分类号:机构代码(3)+二级类目(1)+扩充类目(5位)二级类目:机构职能0、政策法规1、规划计划2、业务类3、其他类910)数据项描述:自动生成本实例中,对于初始目录,允许向其中增加目录。例如表2所示的初始目录。该目录是依据为上海市地方标准DB31/T745—2013政务信息资源共享与交换实施规范。分为类目代码和类目名称。类目分为四级:其中一二级是依据国家主题分类码,三四级为自建。三级存在,四级可能不存在。最初始,有录入一部分准确信息作为基础库。对于三级目录,可以自建,例如在二级目录“ZCJ00电力”目录下,新建三级目录“ZCJ0001预测”这一目录。这样,表2中的“ZCJ00电力”的相关目录结构如表3所示:表3ZC国土资源、能源ZCJ00电力ZCJ0001预测ZCK00其他以表1中的元数据为例,从该元数据中可以拿到二级类目相关的信息是国家主题分类、摘要、关键字和资源信息名称这几个信息,即这几项是关键属性。类似地,与三级类目相关的关键属性是资源信息名称、关键字、摘要。对于新获取的元数据,信息目录生成过程如下:(1)从信息数据湖中取出一条本身已经具有各种标签和属性的元数据。将元数据的特征属性一一列出,等待分析成词向量。(2)词向量训练,将文本转化成词的序列。首先读入元数据,将它的属性依次读入,得到一个数组型的词顺序,并给每一个读入词语一个编号,且编号唯一,之后在将文本修改为2维矩阵。(3)进入压平卷积。词向量层将信息平铺,信息量会很大,这一步骤主要是压缩信息。通过三块神经网络,卷积窗口均为4×30。经过卷积层、激活层和池化层,通过压平卷积得到分析后的压缩数据。(4)分析所属类别。经过全连接,分析出各个属性值属于不同元数据实体的概率。概率超过60%的即确认为信息相近,放置入当前数据实体类别的数据集下。(5)循环上述过程,直至所有信息匹配完全,放置相应目录下。若在重复预先设定的次数之后,依旧没有得到信息完全匹配,则将本数据放入待分类目录下。在待分类目录中已经存在较多数据(具体数据量可以设定)的情况下,根据聚类算法将待分类目录中的数据按关键属性分类成多个组,对于成员数量达到一定阈值的组,将该组中的成员的关键属性中,出现频率最高的词作为新类目的名称。如采用上述的目录编制的依据,则新类目可以是三级目录,另再从元数据中拿到二级类目,将该三级目录保存到该二级目录下。以下以表4所示的元数据的处理过程为例做具体说明。表4在获取了表4所示的元数据的情况下,通过分词得到词序列,下面以资源名称举例。电力供需平衡预测,转化为[‘电力’,‘供需’,‘平衡’,‘预测’],词编号[1,10,27,32],采用词向量转换工具例如word2vec得到词向量为[(1.1,2,3),(1.2,2,5),(1.6,2.8),(2.1,3,3)]。经过压平、卷积,经过全接层和激活层等得到数据的属于电力类的相似概率为88%。超过规定值60%,则直接判定这条数据是属于ZCJ00/电力的二级类目。再一次分词再压平卷积,通过全接层和激活层,得到属于预测类的概率为79%,则判断这条数据属于ZCJ0001/预测三级类目。至此,编目结束,将从经信委拿到的数据放置到一级类目ZC/国土资源、能源,二级类目ZCJ00/电力,三级类目ZCJ0001/预测下。根据分词之后自动生成十个数据源信息:(1)信息资源名称:电力供需平衡预测(2)信息资源摘要:电力供需平衡预测(3)信息资源提供方:经信委(4)信息资源分类:电力(5)信息资源共享属性:共享(6)信息资源公开属性:普遍公开(7)信息资源所属系统说明:经信委(8)信息资源标识符:AG8001/000001前段码(6位)/后段码(6位),自动生成机构代码(3位)+内部扩展码(3位)/系统流水号(6位)(9)元数据标识符:AG8201000-2017-001分类号-目录编制年份-流水号,总长度为16位字符,自动生成分类号:机构代码(3)+二级类目(1)+扩充类目(5位)二级类目:机构职能0、政策法规1、规划计划2、业务类3、其他类9(10)数据项描述:日期,星期,天气,气温,预计最高负荷,最高可用出力,电力供需平衡作为举例,在以上的描述中,数据的属于电力类的相似概率为88%,属于预测类的概率为79%,最终放置到二级类目ZCJ00/电力,三级类目ZCJ0001/预测下。在实际情况下,上述的相似概率也有可能达不到规定的值,例如若经过分词、卷积神经网络得到二级类目、三级类目相似概率为50%,40%,即不满足,放入循环队列末继续遍历,遍历五十次,依旧不成立,即放入一个名为待分类集合中。然后通过聚类算法,按关键属性进行聚类,从而将这些待分类的元数据分为若干组,如果其中一组的总量超过一个阈值(例如设置为5000)时候,将该组的元数据中的关键属性中出现频率最高的词拿出来,作为类目名称。以表4所示的元数据为例,例如该元数据属于上述的总量超过阈值的组,该组还有其他元数据,此处不再一一列出,对于该组元数据,确定这些元数据的关键属性中出现频率最高的词,例如“服务”,这样可以新建名为“服务”的三级类目,代码遵循电力下的三级类目编码的规则。以下再对本发明实施方式中的按照多级类目处理信息的装置进行说明。图5是根据本发明实施方式的按照多级类目处理信息的装置的主要模块的示意图。该装置50可以用计算机软件实现,主要包括确定模块、归类模块、以及类扩展模块,可设置在上文中的数据分析平台中,另外该装置50还可以进一步包含有数据获取模块(图中未示出),设置在上文的数据采集模块中。确定模块用于对于包含有多个属性项的文本元数据,确定能够体现该元数据所属类目的一个或多个特征属性;其中所述类目是给定的多级类目系统中的类目;归类模块,用于对获取的多条文本元数据中的各条文本元数据的特征属性一一进行判断,以确定该条文本元数据是否属于所述给定的多级类目中某一级别的某一类目,若是,则将该文本元数据保存在该类目下,否则将该文本元数据保存在待分类集合中;类扩展模块,使用聚类算法将所述待分类集合中的文本元数据按特征属性聚为多个组,从中确定出成员数量达到预设阈值的组,确定在该组文本元数据的特征属性中出现频率最高的词,将该词作为在所述给定的多级类目中的指定类目下的新建类目的类目名称,然后将该组的文本元数据保存在该新建类目下。归类模块还可用于采用规则匹配的方式,一一判断所获取的多条文本元数据中的各条文本元数据是否属于给定的多级类目中某一级别的类目。归类模块还可用于采用卷积神经网络算法,一一判断所获取的多条文本元数据中的各条文本元数据是否属于给定的多级类目中某一级别的类目。数据获取模块用于采用如下的一种或多种方式获取所述多条文本元数据:使用程序接入服务方式从数据源获取数据然后按照规定格式处理该数据从而得到所述多条文本元数据;使用数据中间层从数据源获取所述多条文本元数据;在数据源的数据库中设置数据库触发器,使得一旦有元数据写入该数据库,即从该数据库中获取该元数据,从而得到所述多条文本元数据;监控数据源的流量,在该流量发生改变的情况下,从数据源的数据库中获取元数据,从而得到所述多条文本元数据。装置50还可以包括一种类目确定模块,用于采用卷积神经网络算法确定该组对应的特征属性与所述给定的多级类目中的指定级别的类目名称的相似概率,然后将大于预设值的相似概率对应的指定级别的类目作为所述指定类目。装置50还可以包括另一种类目确定模块,用于:从该组对应的特征属性中获取类目的名称,然后将该名称的类目作为所述指定类目。作为另一方面,本发明实施方式提供一种电子设备,该电子设备包含一个或多个处理器;以及存储装置,用于存储一个或多个程序,当上述一个或多个程序被上述一个或多个处理器执行,使得上述一个或多个处理器实现本发明实施例所述的方法,例如按照图1所执行的方法。作为再一方面,本发明实施方式还提供了一种计算机可读介质,该计算机可读介质可以是上述实施例中描述的设备中所包含的;也可以是单独存在,而未装配入该设备中。上述计算机可读介质承载有一个或者多个程序,当上述一个或者多个程序被一个该设备执行时,使得该设备能够执行本发明实施例所述的方法,例如按照图1所执行的方法。上述具体实施方式,并不构成对本发明保护范围的限制。本领域技术人员应该明白的是,取决于设计要求和其他因素,可以发生各种各样的修改、组合、子组合和替代。任何在本发明的精神和原则之内所作的修改、等同替换和改进等,均应包含在本发明保护范围之内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1