用于操作数字计算机以降低与大向量之间点积相关联的计算复杂度的方法与流程
本申请要求于2016年3月29日提交的澳大利亚临时申请2016901146的优先权,所述澳大利亚临时申请通过引用结合在此。
背景技术
数字信号处理已变得普遍。例如,如低通滤波器、带通滤波器和高通滤波器等信号滤波器现在是通过以下方式来实现的:对模拟信号进行数字化以创建数字值序列,然后通过有限脉冲滤波器对所述数字值序列进行处理,在所述有限脉冲滤波器中,信号值向量与滤波器系数向量的标量积或“点”积提供表示经滤波信号在每个时刻的数字值。
两个n分量向量a与b的标量积被定义为
其中,ai和bi分别是a和b的第i个向量,并且n是每个向量中的分量数。执行此计算时固有的计算工作负荷为n次乘法和n-1次加法。乘法的计算负荷明显大于加法的计算负荷。在整数乘法和加法的简单情况下,乘法通过n次相加和n-1次移位来执行。在浮点数的更复杂情况下,计算负荷甚至更大。因此,当应用需要两个大向量的标量积时,计算工作负荷会对基础滤波器或其他模型施加实际限制。
例如,数字滤波器的质量通常随着所涉及的向量的大小而增强。具有50个滤波器系数的带通滤波器的带外抑制明显小于具有500个滤波器系数的滤波器。不幸的是,较大滤波器中固有的计算工作负荷会使得优异的滤波器不具吸引力。类似地,利用基于神经网络的算法的模式识别系统面临执行大量标量积的问题。
技术实现要素:
本发明包括一种用于操作数据处理系统以计算对第一向量与第二向量之间的标量积的近似的方法,其中,每个向量由n个分量来表征。所述方法包括:由第三向量代替所述第一向量,所述第三向量是由以下各项表征的金字塔整数向量:n个分量;以及等于所述n个分量的绝对值之和的整数k;以及计算所述第三向量与所述第二向量的标量积,以提供对所述第一向量与所述第二向量之间的所述标量积的所述近似。
在本发明的一方面,计算所述第二向量与所述第三向量的所述标量积包括:将所述第二向量的每个分量加到寄存器中由所述第三向量中所述分量中的相应分量指定的次数,以提供所述第二向量与所述第三向量的所述标量积。
在本发明的另一方面,所述第二向量由第二向量长度来表征,所述第三向量由第三向量长度来表征,并且针对所述第二向量长度与所述第三向量长度的差来校正所述第二向量与所述第三向量的所述标量积,以提供对所述第一向量与所述第二向量的所述标量积的所述近似。
在本发明的另一方面,对所述第一向量与所述第二向量的所述标量积的所述近似由所述第一向量与所述第二向量的所述标量积中的允许误差来表征,并且k被选择为具有所述第二向量和所述第三向量的所述标量积与所述第一向量和所述第二向量的所述标量积相差小于所述允许误差的最小值。在一方面,k<n。
在本发明的另一方面,所述第一向量的所述分量由需要预定位数n的数值表示来表征,并且k<nn。
附图说明
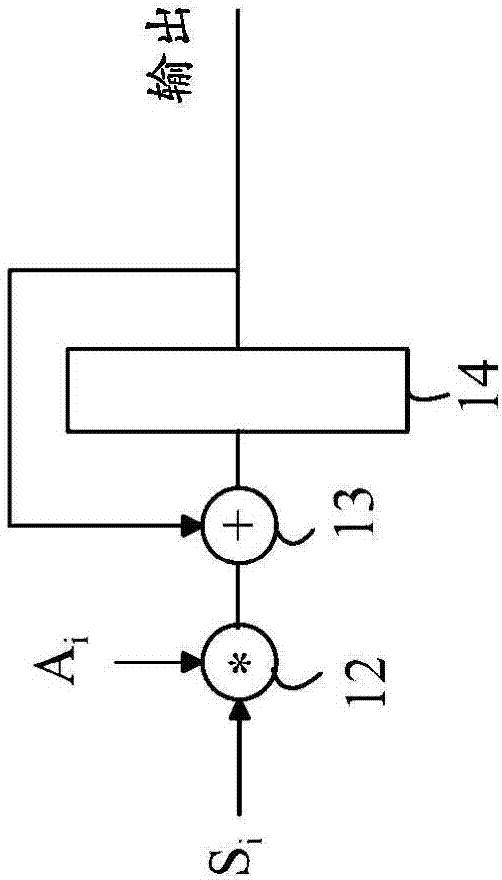
图1展示了用于计算a与s之间标量积的常规计算硬件。
图2展示了用于计算整数分量向量与s的标量积的硬件。
图3展示了整数值的分布。
图4展示了近似向量的分量的频率分布。
图5展示了这些滤波器中每一个的衰减。
具体实施方式
可以参考简单的带通滤波器来更容易地理解本发明提供其优点的方式,所述带通滤波器被实施为计算引擎上的有限响应滤波器,所述计算引擎生成滤波器系数向量与从信号中导出的、具有相同长度的向量的标量积,所述信号已经被数字化以提供表示随时间变化的信号强度的数字值序列。由a=[a1,a2,……,an]来表示滤波器系数向量。通常,信号由数字值序列di组成,i=1到nd,其中,nd>>n。可以将信号视为被移位到n个单元长的寄存器中。此寄存器中的值对应于信号向量,s=[s1,s2,……,sn]。在计算了a与s之间的每个标量积之后,寄存器的内容被移位预定数量的单元,并且di的新值被移位到寄存器中。以这种方式生成的标量积序列形成来自滤波器的输出数字信号。
在实时应用中,必须在比生成将要移位到寄存器中的下一组信号值并移位所述寄存器所需时间短的时间内计算标量积。虽然可以通过并行处理来放宽时间约束,但是附加硬件的成本可能会限制可以使用此提升速度选项的程度。
本发明基于以下观察:在一些感兴趣的情况下,向量a可以由相同长度的近似向量a'来代替,所述近似向量具有两种感兴趣特性。第一,a'与s的标量积是对a与s的标量积的良好近似。第二,a'与s的标量积需要的计算资源明显少于a与s的标量积。
在对a进行近似时可以容忍的误差程度取决于正在使用标量积的具体应用。考虑被实施为在通过对某一传感器的输出进行数字化而生成的数字序列上进行运算的有限脉冲响应滤波器的常规数字滤波器。被滤波的信号将具有一定程度的噪声,所述噪声是由于传感器中的噪声以及由模数转换器(adc)引入的数字化噪声而产生的,所述模数转换器用于将根据时间变化的传感器模拟输出电压转换为数字序列di。来自滤波器的输出信号由另一个数字序列fi组成。每个输出序列值是通过形成a与一向量的标量积来获得的,所述向量的分量是输入的数字序列的子序列。例如,输出信号值fk是通过a与向量[sk,sk+1,……,sk+n-1]的标量积来获得的。输出信号还将具有一定程度的噪声,所述噪声是由输入信号中的噪声产生的。如果a被a'代替,则将会在输出信号中引入附加噪声。如果附加噪声比由输入信号中的噪声产生的噪声小得多,则附加噪声将不会明显改变输出信号的准确度。例如,如果选择a'以使得由对a的近似所引入的附加噪声小于由信号引入的噪声的25%,则所述近似将几乎不会影响输出噪声幅度。
一种用于减少由标量积所施加的计算负荷的方法是使用近似向量,其中所述向量的所有分量都是整数。在下面的讨论中,这种向量将被称为整数分量向量。如果输入数据流是整数序列,则可以仅使用整数乘法和加法来计算标量积,这需要的计算资源比实数乘法和加法少得多。如果输入信号是由在不具有非常大的电压差的传感器输出上进行运算的adc生成的,则输入数据流可以被调整为这样的整数数据流。
一种用于为a生成整数分量向量的方法是对a进行缩放,以使得a中的最大分量的绝对值由具有所期望的最大大小的整数来很好地近似。然后将经缩放向量的分量取整为整数。出于本讨论的目的,这种类型的量化方案将被称为标量量化,因为一次一个地对分量进行近似,而不考虑向量的其他分量。虽然这种简单的算法生成了整数分量向量,但从减少由近似引入的噪声或降低计算复杂度的角度来看,所述整数分量向量不一定是最佳整数分量向量。此外,即使在如a'的整数分量向量的情况下,标量积仍然需要n次乘法和n-1次加法。如果信号向量是实数向量,则具有涉及一个整数和一个实数的乘法的计算节省明显较少。
本发明利用以下观察:在需要标量积的许多现实世界问题中,有待由整数分量向量近似的向量的系数具有特定的统计特性。考虑向量的分量作为具有统计分布的一组数。如果统计分布是拉普拉斯,则可以找到更优的整数分量向量。此外,可以生成具有不同近似误差的多个整数分量向量,并且可以确定针对给定误差提供最佳计算减少的整数分量向量。许多感兴趣的问题涉及分量具有近似拉普拉斯的统计分布的向量a。
出于本讨论的目的,假设a的分量具有基本上为拉普拉斯的分布。考虑如上所讨论的那样通过对a进行缩放并对分量进行取整而生成的简单整数分量向量a'。由k来表示a'的整数分量的绝对值之和。n和k在n维空间中定义一组整数分量向量。出于本讨论的目的,这些向量将被称为金字塔向量。这种向量组及其生成方法在向量量化领域中是已知的,并且因此,这里将不再详细讨论。出于本讨论的目的,应当注意,如果分量的统计分布是拉普拉斯并且经量化分量具有总和为k的绝对值,则此向量组对于用整数分量向量表示n维空间中的向量而言是最佳的。因此,对于给定的k,此组中方向为n维空间中最接近a的方向的整数分量矢量利用此特定k来提供a'的最佳选择。还可表明a'与其他一些矢量的标量积可以利用k次加法来完成。随着k的增加,此组中的向量数也增加,并且因此,可以通过增大k来找到对a的更好近似。因此,在计算工作负荷与通过由a'来近似a而生成的误差之间存在折中。
在许多情况下,可以测量由a'近似a所引入的误差。例如,在滤波器的情况下,对于每个k值,可以针对近似滤波器确定滤波器的带通和带外抑制。然后可以使用提供可接受的通带和带外抑制的最小k值。如果已知误差界限,则可以针对预期向量s的某个样本尝试来本发明的近似。如果满足误差界限,则可以使用所述近似。
现在参照图1,其展示了用于计算a与s之间的标量积的常规计算硬件。为了简化附图,已经从附图中省略了控制电路系统。通常,存在初始地被设置为零的寄存器14。对于从1到n的每个i,si和ai被输入到乘法器12,所述乘法器的输出被输入到加法器13,所述加法器将乘法器输出加到寄存器14的当前内容。在所述过程结束时,寄存器14存储标量积。
如上文所指出的,用于利用由k表征的整数分量向量来计算标量积的计算工作负荷是k次加法。现在参照图2,其展示了用于计算整数分量向量与s的标量积的硬件。再次,为了简化附图,已经从附图中省略了控制电路系统。在计算开始时,寄存器14再次被设置为零。考虑a'的第i个分量对标量积的贡献,即a'i*si。可以通过乘法来生成此贡献,然后将所述贡献加到寄存器14的内容中。可替代地,可以通过使用加法器16将si加到寄存器14的内容a'i次来生成贡献。出于本讨论的目的,执行涉及整数j和第二个数x的乘法(通过将x加到累加器j次)的硬件部件将在下文讨论中被称为重复相加乘法器。如果j为负,则重复相加乘法器从累加器中减去x。由于a'i的绝对值之和为k,因此一共需要k次加法。注意,x可以是浮点数或整数。
标量积需要n次乘法。如果每个分量的贡献由重复相加乘法器来提供,则总相加次数为k,假设寄存器被重置为0。如果表示a的分量的尾数所需的位数是n,则每个倍数将需要至少n次加运算和n-1次移位运算。还将会有附加的n-1次加运算。因此,由于移位运算,总工作负荷将大于nn+n-1次加法。因此,如果k小于nn+n-1,则将通过使用金字塔向量近似和重复加法乘法来实现净计算节省。
即使使用了对a的标量量化,通常n也将至少为16;因此,通过进行乘法所引起的计算负荷将需要16次加法和15次移位。哪种方法需要最少的计算工作负荷取决于a'中分量的大小。相反,可以通过使用重复相加乘法器进行乘法运算来以明显更短的时间实施a'与s的标量积,其中a'具有许多的小分量,即在-15与15之间的整数值。因此,选择a'以使其具有大量小分量是有利的。如果k<16*n,则将实现净节省。
应当注意,针对特定n和k所定义的向量组中的整数分量向量具有某些预定长度,通常这些长度将不同于a的长度。由y来表示从由n和k定义的组中所获得的向量。通常,y将具有不同于a的长度。因此,
a'=cy
其中,c是a的长度与y的长度之比。因此,
除了n个积之外,标量积还需要进行如上文所指出的可以作为k-1次加法被执行的一次乘法。
虽然使用上文所讨论的整数分量向量来执行标量积的计算工作负荷受到一次实数乘法以及k-1次加法的时间的限制,但实际上,工作负荷可以小于此界限。如上文所指出的,如果a'i的绝对值小于与存储最大a'i值所需位数相关的值,则可以在重复相加乘法器中利用a'i次加法或减法而不是常规的乘法来执行此a'i与相应分量si的乘积。k-1次加法界限对应于通过使用重复相加乘法器计算乘积来执行对标量积的所有a'i*si贡献,其中,累加器最初被设置以第一个非零s分量的值。如果在标量积计算开始时将重复相加乘法器中的累加器设置为零,则需要k次加法。但是,在一些情况下,对于某些i值,a'i的绝对值大于此截止值。在这些情况下,执行常规乘法在计算上更高效。在本发明的一方面,a'的分量被分组以使得si和具有较小a'i值的分量被发送到重复相加乘法器,而具有更大绝对值的那些则被发送到常规乘法器。
在利用未知向量执行标量积并且仍然提供足够的标量积准确度时,找到提供最低计算工作负荷的近似向量的计算工作负荷远大于执行一次标量积时固有的计算工作负荷。因此,本发明的方法最适合于将要执行使用同一向量a的大量标量积的情况。这种类型的情况的许多示例在本领域中是已知的。有限脉冲响应滤波器以及基于神经网络的模式识别是本发明的优点可以提供显著节省和/或对结果的显著改进的情况的示例。
现在将参照特定带通滤波器更详细地讨论有限脉冲响应滤波器的示例,以说明可以使用本发明的减少的计算工作负荷来实施具有与常规有限脉冲响应滤波器相同的计算工作负荷同时具有更好滤波器特性的有限脉冲响应滤波器的方式。考虑以下常规有限脉冲响应带通滤波器:其具有在220hz与400hz之间的通带,具有57个“抽头”,即,n=57。在常规的实施方式中,有限脉冲响应滤波器需要57次浮点乘法和56次浮点加法来生成输出信号流的一个样本。在对浮点系数进行缩放并且然后将这些系数取整到最接近的整数之后,可以通过用整数替换实数滤波器系数来去除浮点乘法。图3中示出了整数值的分布。应当注意,这些系数需要16位整数来表示每个系数,并且基本上所有滤波器系数对于标量积中所有乘法而言都太大,以至于无法被重复相加乘法器代替。因此,标量积中的每次乘法都需要16次相加和15次移位。另外,需要56次相加来对乘法结果进行求和。因此,执行标量积以生成一个经滤波分量的计算工作负荷是16*57+56=968次相加以及15*57=855次移位运算。
考虑用于相同通带的197抽头滤波器,其中原始滤波器系数由来自用n=197和k=999表征的一组金字塔向量的最接近金字塔向量所代替,以得到用于计算标量积的近似向量。在下文讨论中,此滤波器将被称为近似滤波器。图4中示出了近似向量的分量的频率分布。与57抽头滤波器的权重分布相反,除了13个系数之外的所有系数都具有小于20的绝对值,并且因此,计算标量积所需的乘法可以利用重复相加乘法器来完成。如果所有乘法都是由重复相加乘法器执行的,则总工作负荷为999次相加。因此,近似滤波器的计算工作负荷稍微小于没有金字塔向量近似的57抽头滤波器。
现在参照图5,其展示了这些滤波器中每一个的衰减。197抽头近似滤波器示出在54处,并且57抽头滤波器示出在52处。近似滤波器在通带外的下降(fall-off)比57抽头滤波器更陡峭。此外,对于近似滤波器,带外信号抑制约为20db。
上述示例假设近似滤波器中的所有乘法都是由重复相加乘法器执行的。然而,如上文所指出的,在常规的相加和移位乘法器中执行对较大滤波器系数的乘法、同时在重复相加乘法器中执行剩余乘法的实施例也是可能的。近似滤波器的分量可以用符号位加7个位来表示。因此,常规的乘法需要7次相加和6次移位。如果具有大于16的绝对值的所有分量都使用常规乘法,则工作负荷将减少到大约500次相加。
在上述示例中,k>n。然而,k<n的实施例也是可能的。如上文所指出的,k值越大,原始向量a与针对a的金字塔向量近似a'的方向之间的差就越小。然而,如果特定应用将允许a与a'之间的差,则计算节省可以非常大。如果k<n,则a'的至少n-k个分量将为零。在k=n-1的情况下,相加次数等于常规标量积中的相加次数,但是乘法不需要时间。因此,相对于用于计算标量积的普通方法,时间计算负荷节省可以是16倍或更多。
本发明特别适用于神经网络。在神经网络中,每一层包括多个神经节点或处理器。每个神经节点基本上是一个滤波器,其输出由非线性函数来处理,以提供传递给神经网络下一层的输出。第一层接收与正由这些滤波器处理的信号类似的多个传感器输入。每个滤波器对包括所有传感器输入的子集的向量进行运算。在训练时段期间确定滤波器系数,在所述时间段内神经网络被“示出”为有待彼此区分的各个项,并且调整滤波器系数,直到最后一层正确地识别各种类别。本发明基于以下观察:对于许多神经网络实施的模式识别问题,最终滤波器系数的统计分布近似于拉普拉斯。因此,这些滤波器系数向量可以由上文所讨论类型的金字塔整数分量向量来近似,并且计算复杂度如上文所讨论的那样被降低。可以通过将初始k值减小为观察到学习集的分类中的误差的点来确定最佳k值。
可以在能够提供累加器和重复相机乘法器的任何数据处理系统上实施本发明的标量积近似。本发明特别好地适用于具有可并行运行的大量处理器的数据处理器,比如图形处理器,因为每个处理器可以与其他处理器并行地生成标量积的一个项。另外,由于实施根据本发明的标量积所需的简单硬件,本发明可以在现场可编程门阵列和特殊处理芯片上实施。
已经提供了本发明的上述实施例以说明本发明的各个方面。然而,要理解的是,在不同的具体实施例中所示的本发明的不同方面可以进行组合以提供本发明的其他实施例。此外,对本发明的各种修改将在上述说明和附图中变得清晰。因此,本发明仅受以下权利要求书的范围的限制。
- 还没有人留言评论。精彩留言会获得点赞!