基于智能交互式增强现实的用户交互平台的制作方法
本申请要求以下专利申请的优先权:提交于2016年8月11日,发明名称为“基于智能增强现实(iar)平台的通信系统(anintelligentaugmentedreality(iar)platform-basedcommunicationsystem)”,申请号为62/373,822的美国临时专利申请;提交于2016年8月11日,发明名称为“智能用户交互平台(anintelligentuserinterfaceplatform)”,申请号为62/373,864的美国临时专利申请;提交于2016年12月1日,发明名称为“个人化交互式智能搜索方法和系统(methodsandsystemsforpersonalized,interactiveandintelligentsearches)”,申请号为15/367,124的美国专利申请;提交于2017年4月4日,发明名称为“用于基于增强现实的通信中的实时图像和信号处理的方法和系统(methodsandsystemsforreal-timeimageandsignalprocessinginaugmentedrealitybasedcommunications)”,申请号为15/479,269的美国专利申请;提交于2017年4月4日,发明名称为“具有增强现实强化的基于场景的实时广告(real-timeandcontextbasedadvertisementwithaugmentedrealityenhancement)”,申请号为15/479,277的美国专利申请;提交于2017年7月31日,发明名称为“实时交互式控制的真实感人类全息增强现实通信方法和系统(methodsandsystemsforphotorealistichumanholographicaugmentedrealitycommunicationwithinteractivecontrolinreal-time)”,申请号为15/665,295的美国专利申请;提交于2017年8月11日,发明名称为“基于智能增强现实(iar)平台的通信系统(anintelligentaugmentedreality(iar)platform-basedcommunicationsystem)”,申请号为15/675,635的美国专利申请;其中的每一个全文以引用的方式并入本申请文件中。
本发明涉及用于智能交互式增强现实(ar)的用户交互平台的方法和系统。更具体地说,本发明涉及方法和系统,用于提供用户输入数据和所得ar数据之间的实时智能交互式控制、用于提供实时有效的基于ar的通信,以及用于通过网络连接提供对物理设备的实时控制。
背景技术:
当代基于实时增强现实(ar)的系统和方法(尤其是那些用于通信的系统和方法)存在严重缺陷,因为对输入数据的不完整或浅表分析和理解,较差的数据整合速度和质量,以及缺乏用户、基于ar的数据和真实世界之间的交互式控制。需要用于克服这些缺陷的方法。
技术实现要素:
一方面,本申请文件公开一种用于提供对计算机设备的交互式智能用户控制的方法。所述方法包括以下步骤:在计算机设备处对用户的实时输入数据进行综合解释;其中所述输入数据的至少一部分包括用户的视觉输入数据,所述视觉输入数据与增强现实(ar)相关的输入数据组合以创建实时ar数据,所述实时ar数据使用户沉浸到ar世界中;其中使用与计算机设备相关联的相机实时采集用户的视觉输入数据;且其中所述综合解释是基于一个或多个标准的,所述一个或多个标准包括用户偏好、系统设定、整合参数、用户的特性、视觉输入数据的对象或场景、从视觉输入数据提取的信息、从所提取信息学习到的知识、先前交互式用户控制,或其任意组合;在计算机设备处基于综合解释的一个或多个结果和可由计算机设备使用人工智能访问的额外信息执行用户输入命令;以及响应于在计算机设备处执行所述用户输入命令,使得一个或多个事件发生。
在一些实施例中,可由计算机设备访问的额外信息包括用户生物识别数据、用户个人数据、允许用户访问的其他人的信息、现有搜索记录、存储在计算机设备中的信息、计算机设备的系统信息、在修改搜索查询时通过实时网络通信所提取的信息或其任意组合。
在一些实施例中,所述使得一个或多个事件发生包括:在计算机设备或另一设备处向用户实时呈现与输入命令相关联的数据内容;改变实时ar数据的内容,其中基于视觉输入数据和ar相关的输入数据实时创建所述实时ar数据;或使得可通信地连接到计算机设备的物理设备改变状态。
在一些实施例中,所述输入数据进一步包括音频输入数据或感觉输入数据。在一些实施例中,感觉输入数据包括用户的生物状态数据、用户的行为数据、环境数据,或用户附近的对象的状态数据。在一些实施例中,感觉输入数据包括从群组中选择的数据,该群组由以下数据组成:用户的生物状态数据、心跳数据、血压数据、体温数据、方向数据、环境温度数据、运动数据、压力数据、海拔高度数据、距离(proximity)数据、加速度数据、陀螺仪数据、地理位置数据、全球定位系统(gps)数据及其任意组合。
在一些实施例中,物理设备形成物联网(iot)网络的一部分。在一些实施例中,物理设备的状态包括二进制状态、连续值调整状态或离散值调整状态。在一些实施例中,物理设备的状态包括从群组中选择的状态,该群组由以下组成:开/关状态、打开和关闭状态、是和否状态、温度状态、运动状态、高度状态、重量状态、尺寸状态、强度状态、声级状态及其任意组合。在一些实施例中,物理设备包括一件家具、车辆、器具、电子器具、建筑物、传感器、灯具、玩具或另一计算机设备。
在一些实施例中,物理设备包括从群组中选择的物理设备,该群组由以下组成:门、窗、灯、冰箱、一件家具、灯具、窗帘、百叶窗、计算机、计算机设备、真空吸尘器、加热器、空调、a/c系统、游泳池、轿车、车库门、水龙头、自行车、小型摩托车、电视机、扬声器、音频播放器、视频播放器、风扇、游戏设备、玩具、时钟、牙刷、碎纸机、可调整的桌子或椅子、相机、传感器或其任意组合。
在一些实施例中,本申请文件所公开的方法进一步包括:在计算机设备处基于实时用户输入数据和ar相关的输入数据提供实时ar数据,所述用户输入数据包括视觉输入数据,所述实时ar数据包括一个或多个广告要素,所述一个或多个广告要素根据综合内容匹配机制确定;其中所述综合内容匹配机制是基于一个或多个因素的,所述一个或多个因素包括广告内容、从用户输入数据提取的信息、从所提取信息学习到的知识、用户交互式控制、用户偏好、场景或其任意组合。
在一些实施例中,场景包括日期和时间信息、通信场景、内容场景、广告商场景、地理位置场景、呈现场景或其任意组合,且其中广告商场景包括广告商指定的内容匹配标准,内容匹配标准包括有利的或不利的呈现论坛或定价信息。
在一些实施例中,计算机设备进一步接收对应于现实事件的额外数据,且所述实时ar数据包括与现实事件相关联的至少一视觉表示。
在一些实施例中,本申请文件所公开的方法还包括:在由第一用户操作的计算机设备处提供不可由计算机设备访问的第二用户的实时ar数据,其中所述第二用户的实时ar数据是根据与第二用户相关联的一个或多个标准基于第二用户的输入数据、ar输入数据、信息输入和知识输入的,所述一个或多个标准包括用户偏好、系统设定、整合参数、输入数据的对象或场景的特性、交互式用户控制或其任意组合;以及用适于在计算机设备上呈现第二用户的实时ar数据的多个数据参数集合表示第二用户的实时ar数据的至少一部分,其中每一数据参数集合包括文本、一个或多个代码、一个或多个数字、一个或多个矩阵、一个或多个图像、一个或多个音频信号、一个或多个传感器信号或其任意组合。
在此类实施例中,第二用户的输入数据在第二设备处采集,且包括第二用户的视频数据以及任选地音频数据、传感器数据或其组合中的一个或多个。信息输入在一个或多个时间点基于与第二用户相关联的一个或多个标准从第二用户的输入数据或其变体中实时提取,所述一个或多个标准包括用户偏好、系统设定、整合参数、输入数据的对象或场景的特性、交互式用户控制或其任意组合。知识输入是基于从多个时间点提取的信息而学习得到的。且第二用户的实时ar数据包括对应于信息输入的信息数据和对应于知识输入的知识数据。
一方面,本申请文件公开一种用于提供实时增强现实(ar)数据的系统。所述系统包括:一个或多个处理器;以及非暂时性计算机可读介质。所述非暂时性计算机可读介质包括一个或多个指令序列,所述一个或多个指令序列在由所述一个或多个处理器执行时使得所述一个或多个处理器执行以下的操作:在计算机设备处对用户的实时输入数据进行综合解释,其中所述输入数据的至少一部分包括用户的视觉输入数据,所述视觉输入数据与增强现实(ar)相关的输入数据组合以创建实时ar数据,其中所述实时ar数据使用户沉浸到ar世界中;其中使用与计算机设备相关联的相机实时采集用户的视觉输入数据,且其中所述综合解释是基于一个或多个标准的,所述一个或多个标准包括用户偏好、系统设定、整合参数、用户的特性、视觉输入数据的对象或场景、从视觉输入数据提取的信息、从所提取信息学习到的知识、先前交互式用户控制或其任意组合;在计算机设备处基于综合解释的一个或多个结果和可由计算机设备使用人工智能访问的额外信息执行用户输入命令;以及响应于在计算机设备处执行所述用户输入命令,使得一个或多个事件发生。
在一些实施例中,可由计算机设备访问的额外信息包括用户生物识别数据、用户个人数据、允许用户访问的其他人的信息、现有搜索记录、存储在计算机设备中的信息、计算机设备的系统信息、在修改搜索查询时通过实时网络通信所提取的信息或其任意组合。
在一些实施例中,所述使得一个或多个事件发生包括:在计算机设备或另一设备处向用户实时呈现与输入命令相关联的数据内容;改变实时ar数据的内容,其中基于视觉输入数据和ar相关的输入数据实时创建所述实时ar数据;或使得物理设备可通信地连接到计算机设备以改变状态。
在一些实施例中,所述输入数据进一步包括音频输入数据或感觉输入数据。在一些实施例中,感觉输入数据包括用户的生物状态数据、用户的行为数据、环境数据,或用户附近的对象的状态数据。在一些实施例中,感觉输入数据包括从群组中选择的数据,该群组有以下数据组成:用户的生物状态数据、心跳数据、血压数据、体温数据、方向数据、环境温度数据、运动数据、压力数据、海拔高度数据、距离(proximity)数据、加速度数据、陀螺仪数据、地理位置数据、全球定位系统(gps)数据及其任意组合。
在一些实施例中,物理设备形成物联网(iot)网络的一部分。在一些实施例中,物理设备的状态包括二进制状态、连续值调整状态或离散值调整状态。在一些实施例中,物理设备的状态包括从群组中选择的状态,该群组由以下组成:开/关状态、打开和关闭状态、是和否状态、温度状态、运动状态、高度状态、重量状态、尺寸状态、强度状态、声级状态及其任意组合。在一些实施例中,物理设备包括一件家具、车辆、器具、电子器具、建筑物、传感器、灯具、玩具或另一计算机设备。
在一些实施例中,物理设备包括从群组中选择的物理设备,该群组由以下组成:门、窗、灯、冰箱、一件家具、灯具、窗帘、百叶窗、计算机、计算机设备、真空吸尘器、加热器、空调、a/c系统、游泳池、轿车、车库门、水龙头、自行车、小型摩托车、电视机、音箱、音频播放器、视频播放器、风扇、游戏设备、玩具、时钟、牙刷、碎纸机、可调整的桌子或椅子、相机、传感器或其任意组合。
在一些实施例中,本申请文件所公开的操作进一步包括:在计算机设备处基于实时用户输入数据和ar相关的输入数据提供实时ar数据,所述用户输入数据包括视觉输入数据,所述实时ar数据包括一个或多个广告要素,所述一个或多个广告要素根据综合内容匹配机制确定;其中所述综合内容匹配机制是基于一个或多个因素的,所述一个或多个因素包括广告内容、从用户输入数据提取的信息、从所提取信息学习到的知识、用户交互式控制、用户偏好、场景或其任意组合。
在一些实施例中,场景包括日期和时间信息、通信场景、内容场景、广告商场景、地理位置场景、呈现场景或其任意组合,且其中广告商场景包括广告商指定的内容匹配标准,内容匹配标准包括有利的或不利的呈现论坛或定价信息。
在一些实施例中,计算机设备进一步接收对应于现实事件的额外数据,且所述实时ar数据包括与现实事件相关联的至少一视觉表示。
在一些实施例中,本申请文件所公开的操作进一步包括:在由第一用户操作的计算机设备处提供不可由计算机设备访问的第二用户的实时ar数据,其中所述第二用户的实时ar数据是根据与第二用户相关联的一个或多个标准基于第二用户的输入数据、ar输入数据、信息输入和知识输入的,所述一个或多个标准包括用户偏好、系统设定、整合参数、输入数据的对象或场景的特性、交互式用户控制或其任意组合;以及用适于在计算机设备上呈现第二用户的实时ar数据的多个数据参数集合表示第二用户的实时ar数据的至少一部分,其中每一数据参数集合包括文本、一个或多个代码、一个或多个数字、一个或多个矩阵、一个或多个图像、一个或多个音频信号、一个或多个传感器信号或其任意组合。
在此类实施例中,第二用户的输入数据在第二设备处采集,且包括第二用户的视频数据以及任选地音频数据、传感器数据或其组合中的一个或多个,信息输入在一个或多个时间点基于与第二用户相关联的一个或多个标准从第二用户的输入数据或其变体中实时提取,所述一个或多个标准包括用户偏好、系统设定、整合参数、输入数据的对象或场景的特性、交互式用户控制或其任意组合,知识输入是基于从多个时间点提取的信息而学习得到的,且第二用户的实时ar数据包括对应于信息输入的信息数据和对应于知识输入的知识数据。
一方面,本申请文件公开一种非暂时性计算机可读介质,其包括一个或多个指令序列,所述一个或多个指令序列在由一个或多个处理器执行时使得处理器执行操作。在一些实施例中,所述操作包括:在计算机设备处对用户的实时输入数据进行综合解释,其中所述输入数据的至少一部分包括用户的视觉输入数据,所述视觉输入数据与增强现实(ar)相关的输入数据组合以创建实时ar数据,其中所述实时ar数据用户沉浸到ar世界中,其中使用与计算机设备相关联的相机实时采集用户的视觉输入数据,且其中所述综合解释是基于一个或多个标准的,所述一个或多个标准包括用户偏好、系统设定、整合参数、用户的特性、视觉输入数据的对象或场景、从视觉输入数据提取的信息、从所提取信息学习到的知识、先前交互式用户控制或其任意组合;在计算机设备处基于综合解释的一个或多个结果和可由计算机设备使用人工智能访问的额外信息执行用户输入命令;以及响应于在计算机设备处执行所述用户输入命令,使得一个或多个事件发生。
在一些实施例中,可由计算机设备访问的额外信息包括用户生物识别数据、用户个人数据、允许用户访问的其他人的信息、现有搜索记录、存储在计算机设备中的信息、计算机设备的系统信息、在修改搜索查询时通过实时网络通信所提取的信息或其任意组合。
在一些实施例中,所述使得一个或多个事件发生包括:在计算机设备或另一设备处向用户实时呈现与输入命令相关联的数据内容;改变实时ar数据的内容,其中基于视觉输入数据和ar相关的输入数据实时创建所述实时ar数据;或使得物理设备可通信地连接到计算机设备以改变状态。
在一些实施例中,所述输入数据进一步包括音频输入数据或感觉输入数据。在一些实施例中,感觉输入数据包括用户的生物状态数据、用户的行为数据、环境数据,或用户附近的对象的状态数据。在一些实施例中,感觉输入数据包括从群组中选择的数据,该群组有以下数据组成:用户的生物状态数据、心跳数据、血压数据、体温数据、方向数据、环境温度数据、运动数据、压力数据、海拔高度数据、距离(proximity)数据、加速度数据、陀螺仪数据、地理位置数据、全球定位系统(gps)数据及其任意组合。
在一些实施例中,物理设备形成物联网(iot)网络的一部分。在一些实施例中,物理设备的状态包括二进制状态、连续值调整状态或离散值调整状态。在一些实施例中,物理设备的状态包括从群组中选择的状态,该群组由以下组成:开/关状态、打开和关闭状态、是和否状态、温度状态、运动状态、高度状态、重量状态、尺寸状态、强度状态、声级状态及其任意组合。在一些实施例中,物理设备包括一件家具、车辆、器具、电子器具、建筑物、传感器、灯具、玩具或另一计算机设备。
在一些实施例中,物理设备包括从群组中选择的物理设备,该群组由以下组成:门、窗、灯、冰箱、一件家具、灯具、窗帘、百叶窗、计算机、计算机设备、真空吸尘器、加热器、空调、a/c系统、游泳池、轿车、车库门、水龙头、自行车、小型摩托车、电视机、音箱、音频播放器、视频播放器、风扇、游戏设备、玩具、时钟、牙刷、碎纸机、可调整的桌子或椅子、相机、传感器或其任意组合。
在一些实施例中,本申请文件所公开的操作进一步包括:在计算机设备处基于实时用户输入数据和ar相关的输入数据提供实时ar数据,所述用户输入数据包括视觉输入数据,所述实时ar数据包括一个或多个广告要素,所述一个或多个广告要素根据综合内容匹配机制确定;其中所述综合内容匹配机制是基于一个或多个因素的,所述一个或多个因素包括广告内容、从用户输入数据提取的信息、从所提取信息学习到的知识、用户交互式控制、用户偏好、场景或其任意组合。
在一些实施例中,场景包括日期和时间信息、通信场景、内容场景、广告商场景、地理位置场景、呈现场景或其任意组合,且其中广告商场景包括广告商指定的内容匹配标准,内容匹配标准包括有利的或不利的呈现论坛或定价信息。
在一些实施例中,计算机设备进一步接收对应于现实事件的额外数据,且所述实时ar数据包括与现实事件相关联的至少一视觉表示。
在一些实施例中,本申请文件所公开的操作进一步包括:在由第一用户操作的计算机设备处提供不可由计算机设备访问的第二用户的实时ar数据,其中所述第二用户的实时ar数据是根据与第二用户相关联的一个或多个标准基于第二用户的输入数据、ar输入数据、信息输入和知识输入的,所述一个或多个标准包括用户偏好、系统设定、整合参数、输入数据的对象或场景的特性、交互式用户控制或其任意组合;以及用适于在计算机设备上呈现第二用户的实时ar数据的多个数据参数集合表示第二用户的实时ar数据的至少一部分,其中每一数据参数集合包括文本、一个或多个代码、一个或多个数字、一个或多个矩阵、一个或多个图像、一个或多个音频信号、一个或多个传感器信号或其任意组合。
在此类实施例中,第二用户的输入数据在第二设备处采集,且包括第二用户的视频数据以及任选地音频数据、传感器数据或其组合中的一个或多个,信息输入在一个或多个时间点基于与第二用户相关联的一个或多个标准从第二用户的输入数据或其变体中实时提取,所述一个或多个标准包括用户偏好、系统设定、整合参数、输入数据的对象或场景的特性、交互式用户控制或其任意组合,知识输入是基于从多个时间点提取的信息而学习得到的,且第二用户的实时ar数据包括对应于信息输入的信息数据和对应于知识输入的知识数据。
可以理解,在适用时可在本发明的任何方面中单独地或以任何组合的形式应用本申请文件中所公开的任何实施例。
以下附图及描述中阐述了一个或多个实施方案的细节。其它特征、方面和潜在优点将从所述描述和图式以及从权利要求书而显而易见。
附图说明
所属领域的技术人员可以理解,下文描述的图式仅出于说明性目的。所述图式并不希望以任何方式限制本发明教导的范围。
图1a描绘了基于实例基于智能交互式ar的平台的示例系统。
图1b描绘了示范性基于智能交互式ar的平台。
图1c描绘了包括智能平台设备的示例网络。
图1d描绘了包括多个智能平台设备的示例网络。
图2a描绘了用于智能综合交互式实时输入数据处理的实例系统。
图2b描绘了用于智能综合交互式实时输入数据处理的实例过程。
图3a描绘了用于基于实时输入数据和虚拟现实要素创建基于ar的数据的示例系统。
图3b描绘了用于基于实时输入数据和虚拟现实要素创建基于ar的数据的示例系统。
图3c描绘了用于在基于实时ar的数据中包括广告要素的示例系统。
图3d描绘了用于在基于实时ar的数据中包括内容匹配的广告要素的示例处理。
图3e描绘了用于整合实时输入数据和虚拟现实要素以创建基于实时ar的数据的示例处理。
图4a描绘了用于基于ar的数据实时通信的示例系统。
图4b描绘了用于基于ar的数据实时通信的示例过程。
图4c描绘了用于基于ar的数据实时通信的示例过程。
图4d描绘了用于基于ar的数据实时通信的示例过程。
图5a描绘了用于实时自适应智能学习的示例过程。
图5b描绘了用于实时自适应智能学习的示例过程。
图5c描绘了用于实时自适应智能学习及处理的示例过程。
图6a描绘了多层数据整合的示例过程。
图6b以不同透视图描绘用于创建实时预计数据的示例过程。
图7描绘了用于实施图1-6的特征和过程的实例系统架构的图式。
各图式中的相同参考符号指示相同元件。
具体实施方式
概述
如本申请文件所公开的,术语“实时”指代在几乎没有或无时间延迟的情况下执行功能。例如,一旦捕获到图像,或捕获图像之后不久,图像经历噪声减少时实时发生图像处理。类似地,一旦所捕获的图像经历一个或多个处理步骤,或所捕获的图像经历一个或多个处理步骤之后不久,实时发生图像提取。例如,可在正采集额外图像的同时发生图像处理。在此,术语处理可以是对图像进行的任何分析或操作。如本申请文件所公开的,只要不存在不当延迟,过程或其部分就是实时的。在存在延迟的情况下,在一些实施例中,所述延迟可在数秒或数毫秒或数微秒或数纳秒内。在一些实施例中,所述延迟可由关于计算机处理速度,或数据传递速度,或网络通信容量的硬件局限性导致。
如本申请文件所公开的,术语“现实对象”和“对象”有时可互换使用。在此,现实对象可包括人。在一些实施例中,现实对象可以是例如桌子等物体,或例如狗等动物。在一些实施例中,现实对象可以是基于ar的系统的用户。在一些实施例中,现实对象是计算机设备的操作者,且控制包括图像捕获的功能中的一个或多个。在一些实施例中,现实对象是使用例如相机、麦克风、传感器等数据采集设备捕获数据的主体。
如本申请文件所公开的,术语“实际环境”和“场景”可互换使用。其指代除现实对象以外的信息,特别是对象所处的物理环境。在一些实施例中,当特定人为既定对象时,图像或视频中捕获的其他人可视为实际环境或场景的一部分。
如本申请文件所公开,术语“图像”可用于指代在视频中的不连续时间点或图像帧处拍摄的单独照片。除非另外规定,否则术语“图像”和“视频”可互换使用。视频实际上是连续捕获的多个图像的集合。对于一些图像捕获设备,所有图像具有相同的类型(例如,商用数码相机);一些图像捕获设备,其可捕获多个图像类型,例如微软体感游戏机(microsoftkinect)可同时捕获深度图像、近红外图像和彩色图像。
如本申请文件所公开的,术语“原始数据”指代使用例如相机、麦克风、传感器等数据采集设备或装置采集的未组织起来的客观事实、数字或信号。所述事实、数字或信号与物件或事件相关联;且其可定量,且可反复测量、存储和传递。在一些实施例中,数据采集设备可以是例如音频记录器等独立的设备或工具。在一些实施例中,数据采集设备可以是较大设备的部件,例如计算机或智能电话设备上的相机。如本申请文件所公开的,除非另外规定,术语“原始数据”、“用户输入数据”、“要素”、“事实”、“数字”、“信号”和“测量值”可互换使用。例如,视频数据、音频数据和传感器数据都是原始数据的形式。如本申请文件所论述的,例如已经历解噪操作的原始数据等经处理的原始数据仍视为原始数据。
使用可检测和捕获现象或事件的一个或多个方面的设备采集原始数据。数据采集可在不同层级发生。例如,对于视频数据,设备可检测和测量可见光信号的强度和颜色(包括色调hue、色彩tint、阴影shade、饱和度、亮度、色度chroma等)的量值和/或变化。较复杂的设备将能够检测和测量例如反射、折射、发散、内部反射、干扰、衍射、光散射和偏光等性质。这些性质常常反映光如何与其环境交互。再者,裸眼不可见的光信号可由例如红外相机等特殊设备检测和捕获。如本申请文件所公开的,在一些实施例中,原始数据可在任何进一步处理之前处理以增强性能,例如质量、效率、准确性和有效性。
如本申请文件所公开的,原始数据可经处理以导出信息,接着导出知识。例如,信息可从原始数据提取,而知识可从所提取的信息学习得到。
相比而言,术语“数据”将被更广泛地解释为包括原始数据和从原始数据导出的任何内容,例如信息、知识、ar数据或其组合等。此外,如本申请文件所公开的,术语“数据”还包括(但不限于)本地存储在计算机设备上的材料、通过网络连接从另一计算机设备接收的材料,或可从因特网(internet)获取的材料。例如,数据可包括与现实对象相关联的图像、音频、视频、传感器、文本、空间、地理或任何其它材料。数据还包括元数据或反映现实对象的状态的其它嵌入式信息。其可进一步包括间接与现实对象相关联的数据,例如,反映现实对象的地理位置的例如图像或视频等信息。如本申请文件所公开的,“信号”和“数据”可包括内部和/或外部数据。在此,内部数据指代现实对象在其实际环境(也称为图像中的场景)中的实时捕获期间采集的数据,包括视觉、音频和其它类型的信息。外部数据指代超出实时采集的内容的内容,包括但不限于:已经存储在本地用户设备上的数据、来自另一用户设备(通过网络连接可访问)的数据、存储在服务器上的数据(例如,包括存储在广告供应服务器上的广告要素),或使用网络采集实时获取的数据。本申请文件中所公开的大多数实例指代图像,然而,这不应以任何方式限制本发明的范围。
如本申请文件所公开的,术语“信息”可用于指代场景化的、经分类的、经计算的和经压缩的数据。信息可从原始数据中提取,例如通过组织以及通过应用关联性、用途、场景等。例如,温度读数本身可提供极少价值或无价值。然而,如果读数与特定用途和关联性联系,那么原始数据可提供信息。例如,具有相同值的环境温度测量值和体温测量值将提供不同含义。例如,环境温度将反映天气状况,而体温可反映健康状况。
例如,信息可从视觉特性、音频特性、传感器特性或其组合中提取。例如,视觉特性包括(但不限于)空间特性、尺寸特性、边缘特性、形状特性、运动特性、颜色特性、曝光(exposure)特性、亮度特性、阴影特性、高光(highlight)特性、对比度特性、光照度和反射率特性、时间特性或透明度特性、深度特性、材料特性或其组合。在一些实施例中,视觉特性包括三维空间特性。
在一些实施例中,音频特性包括(但不限于)音高/音调特性、频率特性、量值(magnitude)/振幅(amplitude)特性、速度特性、语音模式特性、声学特性、噪声特性(例如,周围环境噪声或其它环境噪声)、延迟特性、失真特性、相位特性或其组合。
在一些实施例中,传感器特性可包括灵敏度特性、频率特性、量值/振幅特性或其组合。
在一些实施例中,信息可与来自原始数据的对象或场景相关联。
如本申请文件所公开的,信息可在不同层级提取,这取决于原始数据的质量和数量,或取决于用于提取的一个或多个标准。例如,简单的超声设备(例如多普勒)可用于测量胎儿的心率,而复杂的超声机器可允许医生“视觉化”胎心的结构。由此,从通过复杂超声机器获得的数据提取的信息将处于更深以及更完整的层级。
在一些实施例中,当从原始数据提取信息时,应用一个或多个标准。示范性标准包括(但不限于)用户偏好、系统设定、来自原始数据的对象或场景的特性、整合参数、交互式用户控制、基于大数据的至少一个标准或其组合。在一些实施例中,还可应用基于大数据的标准。
如本申请文件所公开的,术语“知识”可用于指代过程性知识(know-how)、经验、领悟(insight)、理解和场景化的信息。知识通常是可操作的。例如,环境温度为100℉被认为是热的,而110℉将被认为是非常热。当天气热时,人们可采取预防措施,饮用更多的水且在室外时呆在阴凉处。当天气非常热时,人们可完全避免室外活动。
获得知识包括将复杂的认知过程,例如感知、综合、提取、联想、推理和通信获得信息,应用于信息。大体来说,知识与信息更有价值,因为他们是对理解、解释和描绘事物或或某事件的领悟的基础,所述洞察可用于制定策略和行动。
在一些实施例中,不同场景中的相同信息可提供不同知识。例如,如果成人的体温读数达到100.4℉或以上,那么将被视为发烧。然而,幼儿不会被视为发烧直到体温读数达到101.4℉或以上。一旦诊断出“发热”的病因,医生就可为患者开药,针对症状或病因进行治疗。
如本申请文件所公开的,可通过信息的累积学习获得知识。在一些实施例中,信息可与多个时间点相关联。在一些实施例中,时间点是连续的。在一些实施例中,时间点是不连续的。在一些实施例中,从多个类型的信息中学习知识,例如两个或两个以上类型、三个或三个以上类型、四个或四个以上类型、五个或五个以上类型,或者六个或六个以上类型等。在一些实施例中,可使用十个或十个以上类型的信息。
在一些实施例中,辅助特性也可与来自原始数据的对象或场景相关联。
如本申请文件所公开的,知识还可在不同层级学习,这取决于可用信息的数量和质量(其最终确定原始数据的质量和数量)。在与复杂超声机器相对的使用多普勒的相同实例中,医生可能够使用多普勒来解读不规则的胎儿心跳(知识)。使用复杂超声机器,经过培训的医生将能够确定不规则心跳是否对应于胎儿的心脏的任何结构缺陷(知识)。可依赖于来自较复杂分析的知识而作出关于是否应在具有严重先天性心脏缺陷的婴儿一出生就立刻实施心脏手术以挽救她的决策。
在一些实施例中,当从信息中学习知识时,应用一个或多个标准。在此,所使用的标准可与提取信息时使用的标准相同或不同。示范性标准包括(但不限于)用户偏好、系统设定、来自原始数据的对象或场景的特性、整合参数、交互式用户控制、基于大数据的至少一个标准,或其组合。
如本申请文件所公开,术语“增强现实输入数据”或“ar输入数据”指代不同于实时捕获的数据或信息的数据或信息。例如,ar输入数据可包括虚拟环境、实时捕获数据的经更改型式、人或对象,或正通过其它相机实时捕获的任何其它数据。在此,虚拟环境可包括任何类型的先前产生的数据。
如本申请文件所公开的,“辅助信号”是除反映现实对象本身的信号或数据以外的信号或数据。辅助信号还可包括内部或外部数据。在一些实施例中,辅助信号包括非视觉信号,例如音频声轨或外部音频文件。在一些实施例中,辅助信号包括可与所提取的现实对象、虚拟环境或最终整合的图像或视频合并在一起的广告要素。
如本申请文件所公开,术语“真实感全息ar通信”或“全息ar通信”或“ar通信”指代能够基于一个或多个系统设定、一个或多个用户偏好和/或一个或多个用户交互式控制信息提取现实对象(包括人类对象)、使其沉浸到虚拟环境中,且允许现实对象与虚拟对象交互的通信系统和/或方法。
示例性系统实施例
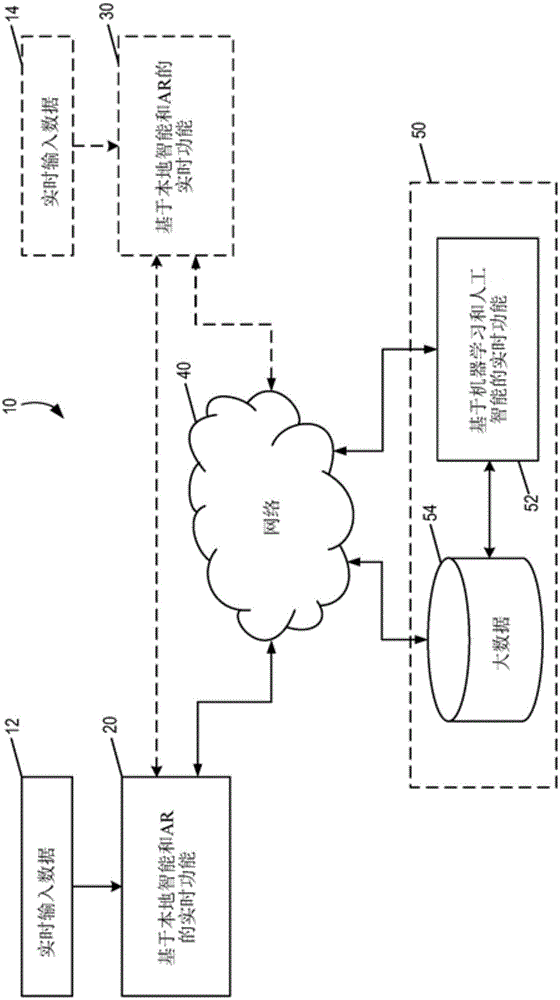
图1a描绘了基于一个或多个基于智能增强现实的用户交互平台的示例性系统。示例性系统10包括通过因特网40连接到远程智能服务器50的用户设备20和用户设备30。用户设备20和用户设备30两者可用于捕获实时输入数据(例如,要素12和要素14)。
如本申请文件所公开的,用户设备20和用户设备30可用于包括实行特定任务所需的功能。例如,此类任务包括(但不限于)输入数据的综合分析和解释、用户验证、与ar相关的输入数据的数据整合、基于ar的广告(例如,使用内容匹配实施),和基于ar的智能通信。可实施以执行这些任务的示范性功能模块在图1b中描绘。
对于与通信无关的任务,用户设备30可以是可选的。在一些实施例中,甚至远程智能服务器50也可以是可选的。在此类实施例中,用户设备20可单独用于包括实行特定任务所需的所有功能。然而,可能有利的是包括远程智能服务器50,这是归因于其高计算能力和存储容量。在此类实施例中,用于执行讨论中的任务的功能可在用户设备20和远程智能服务器50之间划分。所述划分可包括任何组合,有一个例外:数据获取始终在本地设备上发生且不由远程服务器执行。
对于通信相关任务,示例性系统包括至少两个用户设备(例如,用户设备20和30)和远程智能服务器50。再次,用于执行通信任务的功能可在用户设备(例如,用户设备20或用户设备30)和远程智能服务器50之间划分。所述划分可包括任何组合,有一个例外:数据获取必须在本地设备上发生且不由远程服务器执行。
下文中,基于实时通信的数据的多级实时学习和处理通过以下实例进行说明。
如本申请文件所公开的,除非另外规定,术语“数据”可广义上解释为涵盖原始数据、信息、知识、ar输入数据及其它。并且,如本申请文件所公开的,除非另外规定,学习和处理或仅处理广义上解释为包括数据、信息、知识及其它的所有形式的处置或提炼。示范性处置和/或提炼包括(但不限于)质量改进、误差校正、发现、消化、剥离、融合、分析、抽象化、理解、解释、操作、修改、推论、感知、综合、提取、识别、关联、推理、归纳、组织、应用、格式转换、传递、通信等。
如本申请文件所公开的,每一用户设备(例如,元件20和30)配备有以下功能:基于人工智能开展学习,基于增强现实(ar)对原始数据、信息和知识进行学习和处理。
在一些实施例中,数据学习和处理可以单独地或以任何可能的组合形式应用于原始数据、信息和知识中的一个或多个。
由数据、信息和知识的学习和处理产生的结果可在用户设备20和用户设备30之间传递,和/或用户设备20和用户设备30中的一个或两个与智能服务器50之间传递。
例如,用户设备20获取、处理和增强数据(例如,音频、视频和传感器数据)且通过有线或无线网络通信将处理后的数据发送到智能服务器50或用户设备30。在一些实施例中,用户设备20将处理后的数据直接发送到设备30(例如,通过红外传输)。在一些实施例中,除了处理后的数据之外,或代替处理后的数据,还可传递原始数据。
在一些实施例中,设备20和30中的一个或两个具有其自身的本地智能和ar处理模块以在本地增强数据。在一些实施例中,设备20和30中的一个或两个具有其自身具有一些智能分析和处理功能。在一些实施例中,设备20和30中的一个或两个其自身还能够利用远程大数据数据库(例如,在智能服务器50上)执行基于人工智能的更多和更深入的学习和处理,从而获得更完整和更深层级的信息、知识及其它。在一些实施例中,学习和处理可在相反方向上进行。例如,基于所学到的信息和/或知识,智能服务器50可使用或修改现有数据或创建包含信息和/或知识的新数据。
在一些实施例中,来自设备20和30的任一个或两个的数据、信息或知识可保存在大数据数据库中,并且还发送到用于基于人工智能的额外学习和处理的智能服务器50。
在一些实施例中,智能服务器50可基于大数据数据库(例如,在服务器上本地保存以便于通过网络通信访问)处理含有智能信息处理的数据,以自动领会信息/知识,并基于用户偏好和系统设定分别将所领会的信息/知识作为智能数据提供给发送了原始数据或处理后的数据的设备(例如,设备20)和接收设备(例如,设备30)。
在一些实施例中,发送到发送方设备或接收方设备的数据因它们不同的用户偏好和系统设定而不同。
在一些实施例中,接收方设备(例如,设备30)可从设备20和智能服务器中的一个或两个接收原始数据或处理后的数据。接收方设备30可进一步处理所接收的数据,包括,例如,解释所接收的数据且将所接收的数据转换为适于接收器方设备30的形式和格式、用学习的信息和/或知识增强数据,以及以各种形式输出所得数据。在一些实施例中,输出数据将基于用户的偏好和/或系统设定而呈现,例如显示视频数据、播放音频数据和控制对应的传感器。
在一些实施例中,设备30可充当发送方设备,且将数据传递到设备20和智能服务器50。在一些实施例中,可应用本申请文件公开的系统和方法来促进交互式双向/多向通信系统。
在一些实施例中,数据处理的所有方面(例如,原始数据处理、信息提取、知识学习、基于ar的数据增强、ar数据的表示、数据压缩等)可通过安全处理器和安全通道在一个设备中进行,其中受到保护的存储设备包括加密以确保数据安全。在一些实施例中,数据处理的一部分可通过安全处理器、安全通道进行,其中安全存储设备包括加密以确保安全性,而数据处理的其它部分可通过具有普通安全级的处理器、通道和存储设备进行。在一些实施例中,数据处理的所有方面可通过具有普通安全级的处理器、通道和存储设备进行。
如本申请文件所公开的,智能服务器50具有很多优点。例如,用于实行基于人工智能和ar的数据学习及处理的功能可在服务器50处以增强的效率和速度进行。此外,此数据学习和处理可在存储于服务器50上的数据库52的大数据上执行。
如本申请文件所公开的,计算机设备(例如,设备20或30)包括作为一体式部件的相机和可选地麦克风或者一个或多个传感器,或以通信方式连接到相机和可选地麦克风或者一个或多个传感器。在一些实施例中,相机是例如计算机、蜂窝电话或录像机等用户设备的组成部分。在一些实施例中,相机是可连接到用户设备的外部硬件部件。在一些实施例中,用户设备是具有网络功能的相机。优选地,所述相机是深度相机。在一些实施例中,图像/音频捕获设备包括一组相机。如本申请文件所公开的,用户设备应装备有cpu/gpu处理器、相机、麦克风、显示器、扬声器、通信单元和存储设备。其包括(但不限于)台式计算机、膝上型计算机、智能电话设备、个人数字助理、具有网络功能的相机、平板计算机、ar眼镜、ar头盔、虚拟现实(vr)眼镜、智能电视(tv)等。相机包括(但不限于)2d、3d或4d相机、彩色相机、灰度阶相机、普通的rgb相机、红外(ir)相机、近红外(nir)相机、热感相机、多光谱相机、高频谱相机、360度相机等。麦克风可以是能够检测和捕获音频信号的任何设备。传感器可以是可检测其环境中的事件或改变且将信号发送到另一设备(例如,计算机处理器)的任何部件、模块或子系统。示范性信号包括(但不限于)与心跳、血压、方向(orientation)、温度、运动、海拔高度、压力、近程、加速度、陀螺仪等相关联的信号。如本申请文件所公开,借助于实例描述用于产生实时ar数据的方法和系统。然而,所属领域的技术人员可以理解,所述方法和系统可应用于其它类型的数据。此外,其它类型的数据可单独地或与图像数据组合而处理以创建如本申请文件所公开的基于ar的数据。实例为声音数据与图像数据的组合。另一实例为传感器数据与图像数据的组合。如本申请文件所公开,传感器数据包括振动数据、温度数据、压力数据、方向数据、距离数据等。
结合图1b详细地描述用于实行数据的基于人工智能的学习和基于ar的处理的功能性的示范性实施方案。
一方面,本申请文件公开一种基于智能增强现实的用户交互平台,其能够执行大量任务,包括例如输入数据的综合分析和解释、用户验证、与ar相关的输入数据的数据整合、基于ar的广告(例如,使用内容匹配实施),和基于ar的智能通信。确切地说,大多数任务可使用基于ar数据增强的实时所提取信息,和/或使用实时学习的知识来实现。
图1b描绘用于基于智能增强现实的用户交互平台100的示范性计算机系统。
示范性实施例100通过在计算机设备102上实施以下模块而实现所述功能性:用户输入和输出(i/o)模块110、存储器或数据库115、处理器116、网络通信模块118、可选的数据捕获或获取模块120、数据处理模块130、智能模块140、增强模块150和表示模块160、交互式控制模块170,以及实行特定任务可能需要的任何其它功能模块(例如,误差校正或补偿模块、数据压缩模块等)。如本申请文件所公开的,用户i/o模块110可进一步包括输入子模块112和输出子模块114。例如,输入子模块112包括相机、麦克风、传感器(例如,扫描仪)等,输出子模块114包括显示器、扬声器和传感器(例如,触摸板)等。
本申请文件中还公开,特定任务可通过一个或多个功能模块来执行。确切地说,所枚举模块中的每一个自身可反过来包括多个子模块。例如,数据处理模块130可包括用于数据质量评估的模块、用于基于内容(例如,从其环境提取现实对象)或基于数据类型(例如,使视频数据与音频数据分离)的提取和分离数据的模块、用于组合多个数据类型(例如,图像数据与音频数据和/或传感器数据)的模块。
如本申请文件所公开的,与计算机设备102相关联的功能性可扩展到图2a中所说明的功能性,包括但不限于设备220、设备240或服务器250。如本申请文件所公开的,计算机设备102可以是本地用户设备或服务器设备:本地用户设备需要装备有数据捕获模块,而服务器设备通常不包括数据捕获部件。如本申请文件中所公开的,数据捕获模块可以作为用户设备的一体式部件或可通信地与用户设备连接的单独功能部件。
在一些实施例中,用户i/o模块110可捕获视觉音频和传感器数据,例如,可通过输入子模块112捕获这些数据。例如,i/o模块110可从用户接收手势输入、肢体运动或话音输入,以启动用于产生基于ar的实时图像数据的方法。在一些实施例中,此输入可用于通过实时指定用户偏好或选择系统偏好来改变方法的过程。在一些实施例中,i/o模块110还用于检测和跟踪眼睛移动、面部表情等。并且,例如,i/o模块110从设备102的触敏式显示器接收触摸输入。在其它实施例中,i/o模块110可耦合到其它输入设备,例如相机、键盘、鼠标、显示器、触敏显示屏、扬声器等,且从这些设备接收用户输入。在一些实施例中,i/o模块110包括相机、键盘、鼠标、显示器、触敏屏幕显示器、扬声器等,作为i/o模块110或设备102的组成部分。在一些实施例中,设备102可接收多个类型的用户输入。在一些实施例中,i/o模块110或设备102还包括一个或多个传感器设备,用于采集例如心跳、血压、方向、压力、距离、加速度等信息,或允许用户接收身体体验,例如触摸等(例如,用户可实时接收远程握手)。
在一些实施例中,i/o模块110还可向用户呈现音频、视觉、运动和/或触觉输出,例如,可通过输出子模块114向用户呈现这些输出。例如,i/o模块110在显示器上向设备102的用户显示整合的图像或视频。在一些实施例中,i/o模块110可呈现图形用户界面(gui),该gui启用或支持本申请文件中所描述的实时图像和信号处理方法/系统中的一个或多个的功能,包括但不限于数据捕获或获取模块120、数据处理模块130、智能模块140、增强模块150和表示模块160、交互式控制模块170,以及实行特定任务可能需要的任何其它功能模块(例如,误差校正或补偿模块、数据压缩模块等)。在一些实施例中,用户输入和输出模块包括多个菜单命令,每一个对应于查询处理模块中的一个或多个的功能。
在一些实施例中,i/o模块110允许用户查找图像处理所需的信息的位置。在实施例中,可提供菜单选项使得用户可以选择一个或多个选项以启用一个或多个功能。例如,用户可点击图标以开始图像捕获过程。并且,例如,可通过菜单选项提供多个类别的虚拟环境图像。
在一些实施例中,用户可使用i/o模块110来请求本地设备102上可用或可通过网络连接从远程服务设备或另一用户设备获得的信息。例如,i/o模块110可允许用户使用语音命令来请求ar输入数据,例如某一类型的虚拟环境(例如,欧洲中世纪城堡的图像)。一旦图像被传送(在本地传送或通过网络连接传送),用户可以请求处理图像以构造虚拟环境。
在一些实施例中,用户i/o模块110可用于管理各种功能模块。例如,用户可在实时通信过程中通过用户i/o模块122请求改变ar输入数据,例如,虚拟环境等。用户可通过在不中断通信的情况下通过分散地选择菜单选项或键入命令来完成此操作。
当本申请文件中所公开的方法/系统用于图像或视频处理和编辑时,用户可使用任何类型的输入来通过i/o模块110引导和控制所述过程。
在一些实施例中,计算机设备102包括用户输入和输出模块(i/o模块)110。例如,i/o模块110可使用文本、音频、视频、运动和/或触觉输出机制接收对设备102的用户输入且呈现来自设备102的输出。如本申请文件所公开的,用户i/o模块110还可包括输入子模块112和输出子模块114。例如,输入子模块112包括相机、麦克风、传感器(例如,扫描仪)等,输出子模块114包括显示器、扬声器和传感器(例如,触摸板)等。
在一些实施例中,输入模块112的相机可包括但不限于例如:高分辨率相机,其可获取高分辨率(hd)或超hd质量的图像和视频;近红外(nir)相机,其可获取nir频率中的图像和视频;红外相机,其可获取红外频率中的图像/视频;热传感相机,其可获取长波中的图像/视频;三维(3d)相机,其可获取3d图像/视频;多光谱相机,其可获取多光谱图像/视频;rgb相机,其可获取彩色图像/视频;高速相机,其可以极高帧速率获取图像/视频;等等。在一些实施例中,如本申请文件中所公开的相机包括一个或多个灯,其可通过适当地控制以向使用中的相机提供适当的照明和光。在一些实施例中,其它种类的图像获取设备/方法可包括在平台中。
在一些实施例中,输入子模块112的麦克风可包括但不限于:可以不同频率获取音频数据的麦克风、可获取40hz到20khz的声音的麦克风、可获取低于40hz的声音的超低声音设备、可获取高于20khz的声音的超声设备/方法等。本领域的技术人员可理解,输入模块112的功能可以是灵活的且可获取其它种类的声音信号。
在一些实施例中,输入子模块112的扬声器可实现不同的扬声器声音能力。示范性扬声器包括(但不限于):普通的声音设备/方法,其可产生40hz到20khz的频率范围中的声音,例如语音、音乐、噪声、警报等;3d声音设备/方法,其可产生3d音效;高分辨率声音设备,其可产生高分辨率音质;超声设备,其可产生超声(20khz或高于20khz);超低频率声音设备,其可产生超低频率声音(低于40hz);等等。本领域的技术人员可理解,输入模块112的功能可以是灵活的以包括其它种类的声音信号输出设备。
在一些实施例中,输出子模块114的显示器可包括多种特殊用户界面(ui)设备,包括但不限于可具有3个状态的双向视镜,反射状态用以反射光/对象/背景,透明状态用以展示显示,以及部分反射和部分透明状态用以具有部分反射和部分显示;可显示2d图像/视频的2d显示器;可显示3d图像/视频的3d显示器;在闪光或静止状态中以不同光强度和颜色点亮的界面灯。
在一些实施例中,用户i/o模块110可包括多种传感器,包括但不限于例如:振动设备,其产生具有不同频率的振动;移动设备,其可控制系统的机械移动,例如旋转、前向/后向移动、竖直移动和这些移动的组合;触摸设备,其通过触摸面板或触摸屏实现用户输入信息/命令;点击设备,其通过点击系统实现用户输入信息/命令;等等。
如本申请文件中所公开的,用户i/o模块110可与一个或多个相机、一个或多个麦克风、一个或多个扬声器、一个或多个手势输入设备、一个或多个生物识别输入/输出设备等通信并控制这些设备。
本领域的技术人员可理解,输入模块110的功能可以是灵活的以包括其它种类的声音用户交互设备。
在一些实施例中,设备102还包括存储器或数据库115。例如,存储器或数据库115可存储所捕获的用户输入数据,例如图像、音频数据和传感器数据、部分或完全处理的图像(例如,用于虚拟环境的所提取的现实对象和图像),或者部分或完全整合的图像。在一些实施例中,存储器或数据库115可存储用户特定信息;例如用户可存储一个或多个优选虚拟环境的信息用于产生基于ar的实时数据。在一些实施例中,存储器或数据库115可存储从另一设备(例如,用户设备或服务器)获取的信息。在一些实施例中,存储器或数据库115可存储通过因特网搜索而实时获取到的信息。
在一些实施例中,存储器或数据库115可将数据发送到功能模块中的一个或多个以及从功能模块中的一个或多个接收数据,所述功能模块包括但不限于数据捕获模块120、数据处理模块130、智能模块140、增强模块150、表示模块160和交互式控制模块170。
在一些实施例中,设备102包括数据捕获模块120。例如,数据捕获模块120可包括图像捕获设备,例如相机等。在一些实施例中,相机是深度启用的。在一些实施例中,使用两个或两个以上相机。在一些实施例中,可使用内置麦克风或外部麦克风进行音频采集。在一些实施例中,数据捕获模块126捕获多个图像。在一些实施例中,数据捕获模块126可捕获多个图像,且将其融合在一起例如以创建动画图像。在一些实施例中,数据捕获模块120连续捕获视频。在一些实施例中,数据捕获模块120通过使用与设备102相关联的一个或多个传感器捕获传感器数据。在一些实施例中,数据捕获模块120可包括传感器,包括但不限于一个或多个传感器设备,用于采集例如心跳、血压、方向、压力、距离、加速度及其组合等信息。
如本申请文件中所公开的,数据捕获模块120捕获用户的输入数据(例如,现实对象物理上位于的实际环境中所述现实对象的图像、声音或传感器数据)。在一些实施例中,用户不是现实对象,但控制设备102以捕获信号捕获模块126可访问的对象的图像。例如,现实对象可以是正由用户操作数据捕获模块126而被拍照的明星。
用于数据采集的任何设备或功能部件可用作数据捕获模块120(作为用户设备的组成部分或可通信地与用户设备连接)。示范性设备或功能部件包括(但不限于),例如,结合计算机设备102(图1b)的用户i/o模块110的输入子模块112公开的设备或功能部件。
本申请文件中所公开的方法和系统是有利的,因为其不需要现实对象处于特定类型的环境中来辅助图像处理。
在一些实施例中,设备102包括数据处理模块130。数据处理模块130可从i/o模块110、数据捕获模块120或存储器或数据库115接收实时数据。在一些实施例中,数据处理模块128可执行例如降噪或信号增强等标准数据处理算法。在一些实施例中,数据处理模块128可执行数据发现且从实时接收的数据提取信息。例如,可分析每一类型中的数据以识别例如人类特征模式(例如,脸、虹膜、身体、手势等)、语音模式、生物状态或对象的任何其它物理或非物理特征等信息。
在一些实施例中,数据处理模块130可单独地评估和分析每种类型的实时数据(例如,视觉、音频或传感器)。在一些实施例中,数据处理模块130可同时评估和分析多个类型的实时数据(例如,视觉和传感器数据可用于检测心脏病发作)。
在一些实施例中,设备102包括智能模块140。智能模块140可从数据处理模块130或存储器或数据库115接收处理后的数据。在一些实施例中,智能模块140可执行深度数据发现:例如从实时接收的数据提取信息以及基于所提取的信息学习知识。
如本申请文件中所公开的,可通过将数据场景化、分类、计算和压缩来提取信息。在一些实施例中,信息提取还可根据一个或多个标准发生,所述标准包括用户偏好、系统设定、整合参数、原始数据的对象或场景的特性、交互式用户控制或其任意组合。所述标准中的每一个可视为组织原始数据和将原始数据场景化的方式。在一些实施例中,至少一个标准是基于大数据的。
如本申请文件中所公开的,所提取的信息可由信息数据表示。在一些实施例中,信息数据可包括文本、一个或多个代码、一个或多个数字、一个或多个矩阵或其任意组合。在一些实施例中,信息数据可包括一个或多个图像、一个或多个音频信号、一个或多个传感器信号或其任意组合。在此,所述图像、音频信号和传感器信号可以并且优选地不同于包括在从其中提取信息的原始数据中的图像、音频信号和传感器信号。
在一些实施例中,一旦启动数据捕获就触发实时信息提取。在一些实施例中,通过组织数据实现信息提取。例如,当原始数据包括多个类型的数据(例如,对象或场景的视觉、音频或传感器数据)时,可通过根据其数据类型分离数据来实现数据的组织。在一些实施例中,每种类型的数据还基于数据的内容被进一步分离;例如,对应于对象的数据可与对应于场景的数据分开组织。例如,对象的实时信息提取包括识别对象和其环境之间的边界,例如,基于图像内的相对位置、对比度、照明、颜色、热特性等的差异进行识别。在一些实施例中,使用深度启用的相机采集图像数据,且在从背景和前景任一个中提取信息之前使用深度信息将对象划分为背景和前景。在一些实施例中,提取模块128可通过实时对象识别和数据分离提取信息。例如,对象识别包括使人与环境分离。在一些实施例中,对象识别包括检测人的不同身体部位。在一些实施例中,对象识别还包括使特性与人的身体部位相关联,这可促进关于运动、尺寸的信息的提取。
在一些实施例中,智能模块140通过基于一个或多个特性实时将数据进一步组织(例如,分离)为与对象和其环境相关联的一个或多个子类别来提取信息。例如,共享相同或类似视觉特性(例如,颜色、暗度)的相同对象的部分可组织在一起。在一些实施例中,信息提取使用基于综合特性的机制,包括基于人工智能的机制。例如,基于综合特性的机制可识别人、对象和环境的一个或多个特性及其差异。示范性特性可包括且不限于视觉特性,例如,空间特性、尺寸特性、形状特性、运动特性、颜色特性、光照度和反射特性、时间特性或透明度特性、深度特性、材料特性或其组合等。在一些实施例中,空间特性包括三维空间特性。在一些实施例中,所述特性可以是实时学习的特性,包括但不限于颜色、形状、边缘、光反射、光照度、曝光、亮度、阴影、高光、对比度、运动、深度、材料或其组合。在一些实施例中,预先学习的特征还包括但不限于颜色、形状、边缘、光反射、光照度、曝光、亮度、阴影、高光、对比度、运动、深度、材料或其组合。
在一些实施例中,根据用户偏好或系统设定来组织原始数据。例如,通过排除不相关数据或聚焦于一种或多种类型的数据来组织原始数据。在一些实施例中,可设置用户偏好以指定用于信息提取的数据的类型,可移除或忽略不相关数据以有利于从相关数据中提取信息。例如,如果医生对关于心脏状况的医疗数据感兴趣,那么信息提取将聚焦于例如脸的颜色、脉搏/心跳、呼吸数据、血压等数据。在另一实例中,如果医生对关于患者的皮肤状况的信息感兴趣,那么可仅针对皮肤相关数据实行信息提取。
在一些实施例中,可利用交互式用户控制执行信息提取。例如,在基于本发明的方法/系统的远程诊断会话中,医生可请求某一类型的信息。例如,医生可请求基于由一个或多个传感器捕获的心跳数据来计算心率。
在一些实施例中,本申请文件中所公开的系统/方法可包括指定数据类型的系统设定,该数据类型是在特定预定义场景中彼此相关的数据类型。指定数据类型的数据可被选择和处理以用于信息提取。
通过应用各种分析工具,表示不同对象和场景的数据可组织和放置到场景中。例如,通过比较来自不同时间点获得的不同图像的对象的位置数据,有可能提取对象的位置或运动信息。在一些实施例中,可有可能在多个对象存在于原始数据中时计算或比较相对速度。
在一些实施例中,智能模块140从一种类型的数据中提取信息。在一些实施例中,提取模块128从多个类型的数据中提取信息。例如,人的外表可与体温读数组合以用于额外信息提取。在一些实施例中,多个类型的数据可在信息提取之前融合。
在一些实施例中,如本申请文件中所公开的信息提取过程可在一个轮次中或多个轮次中完成。在一些实施例中,一个轮次的粗略信息提取可在实行一个或多个附加轮次的精细提取之前首先执行。例如,粗略提取可提供例如心率等信息,而更深层次的信息提取可得出一个或多个完整心博循环的信息:例如流入期、等容收缩、流出期和等容舒张的信息。更深层次的信息提取将包括提取与a-v瓣膜封闭、主动脉瓣膜打开、等容收缩、喷射、等容舒张、快速流入、a-v瓣膜打开相关联的信息。示范性信息可包括主动脉压力、心房压力、心室压力、心室容积。在一些实施例中,从心电图和心音图提取信息。如所提到的,可在其处提取信息的层级可能受可用的分析方法、原始数据的数量、类型和质量限制。
在一些实施例中,智能模块140可使用预先学习的信息提取实时信息。例如,对象和场景的预先存在的模式可在进一步实时信息学习之前用作开始点。在一些实施例中,信息提取可在不同设备上多次发生。例如,初始信息提取可在具有有限计算能力的本地设备上发生。初始信息提取可能是粗略的且深度受到限制。所提取的信息和原始数据可传递到另一计算机设备,该另一计算机设备具有较强计算能力,且对其中发生进一步信息提取的较综合数据库(例如,包括大数据)具有较好的访问能力。图3到5中说明多级信息提取过程的示范性实施例。
在一些实施例中,可基于机器学习和模式识别方法来执行信息提取,所述方法例如深度学习、神经网络、基于特征点的方法、主分量分析(pca)、线性判别分析(lda)等。
在一些实施例中,智能模块140可基于已从原始数据提取的信息的分析学习或导出知识。
在一些实施例中,通过理解信息和将信息场景化来学习知识。在一些实施例中,此类场景化可通过将相关信息组织成类别来实现。这种增加的组织层级可辅助理解数据。例如,在其中患者具有即将发生心脏病发作的高风险的实例中,医生可通过将相关信息组织在一起来学习此知识。例如,患者表现出令人担忧的症状,例如面色潮红、心率急促、血压很高、呼吸短促、行动缓慢等。
类似于信息提取,还可根据一个或多个标准进行知识学习,所述一个或多个标准包括用户偏好、系统设定、整合参数、原始数据的对象或场景的特性、交互式用户控制或其任意组合。例如,特别设计用于医疗诊断的方法/系统可具有每种疾病的一个或多个预定类别,每种疾病有可能可以基于例如视频数据、音频数据和传感器数据等非侵入性数据识别。例如,心脏病的类别将告知所述方法/系统聚焦于特定类型的信息,例如脸色、呼吸模式、心率、血压值等。在一些实施例中,所述方法/系统还提供参考标准,将对照所述参考标准比较所获得的信息,且可根据比较的结果产生学习的知识。在一些实施例中,至少一个标准是基于大数据的。
如本申请文件中所公开的,学习的知识可由知识数据表示。在一些实施例中,知识数据可包括文本、一个或多个代码、一个或多个数字、一个或多个矩阵或其任意组合。在一些实施例中,知识数据可包括一个或多个图像、一个或多个音频信号、一个或多个传感器信号或其任意组合。在此,图像、音频信号和传感器信号可以,且优选地,不同于从其间接导出知识的原始数据中包括的图像、音频信号和传感器信号。
在一些实施例中,知识学习包括基于一个或多个特性将可用信息实时组织(例如,分离)为与对象和其环境相关联的一个或多个子类别。例如,反映对象的视觉特性的信息可组织成一个类别。在一些实施例中,知识学习除使用例如基于人工智能的机制之外还利用基于综合特性的机制来促进学习。例如,基于综合特性的机制可识别人、对象和环境的一个或多个特性及其差异。示范性特性可包括(但不限于)视觉特性,例如空间特性、尺寸特性、形状特性、运动特性、颜色特性、光照度和反射特性、时间特性或透明度特性、深度特性、材料特性或其任意组合。在一些实施例中,空间特性包括三维空间特性。在一些实施例中,所述特性可以是实时学习的特性,包括但不限于颜色、形状、边缘、光反射、光照度、曝光、亮度、阴影、高光、对比度、运动、深度、材料或其任意组合。在一些实施例中,预先学习的特征还包括但不限于颜色、形状、边缘、光反射、光照度、曝光、亮度、阴影、高光、对比度、运动、深度、材料或其任意组合。
在一些实施例中,知识学习可与交互式用户控制一起执行。例如,在基于本发明的方法/系统的远程诊断会话中,医生可请求系统研究某人是否患有某一类型的疾病或病况的可能性。在一些实施例中,在接收此类用户指示后,系统可集合可能对于诊断特定疾病或病况有帮助的相关信息。
在一些实施例中,从一种类型的信息导出知识。在一些实施例中,可从多个类型的信息导出知识。大多数医疗诊断在知识层级发生。使用以上相同的实例,例如最大发热值、发热持续时间、暴露于热和病菌或水化状态等额外信息可导致不同的诊断和不同的治疗。
在一些实施例中,可基于机器学习和模式识别方法来执行信息提取。例如,所述方法包括深度学习、神经网络、基于特征点的方法、主分量分析(pca)、线性判别分析(lda)等。
在一些实施例中,设备102包括增强模块150。如本申请文件中所公开的,增强模块150可通过整合原始数据、ar输入数据、信息输入和知识输入来产生实时ar数据。在一些实施例中,根据一个或多个标准发生整合,所述一个或多个标准包括用户偏好、系统设定、整合参数、原始数据的对象或场景的特性、交互式用户控制或其任意组合。
如本申请文件中所公开的,数据增强可作为许多不同层级进行。可基于信息(实时学习的或现有的)、知识(实时学习的或现有的)、用户偏好、系统设定或附加输入数据中的一个或多个增强数据。在此,数据可包括原始数据、处理后的数据,或例如设备上预先存在的其它数据、通过网络通信实时获取的数据,或实时创建的数据,或它们的组合。
在一些实施例中,所提取的对象信息与增强现实(ar)输入数据组合以产生实时ar数据。如所公开的,ar输入数据包括虚拟现实信息或从所捕获数据处理得到的信息。在图像数据的情况下,组合过程也被称为图像整合。在一些实施例中,用户设备120包括单独的增强模块。例如,整合可逐像素进行以保证效率和准确性。
在一些实施例中,实时提取的信息可用于产生实时ar数据。在一些实施例中,实时学习到的知识也可用于产生实时ar数据。例如,在其中在关于旅游目的地的友好对话期间强调词语“夏威夷”的实例中。对于“夏威夷”的强调与面部表情和肢体运动组合允许系统得出结论:用户对于去夏威夷很激动。此结论(知识)促进系统创建包括关于夏威夷的内容的实时ar数据。
在一些实施例中,用户偏好可限定用户想要的ar输入数据的特定类型。例如,人们可在进行商务会议时选择虚拟的安静茶楼,但在与家庭成员或朋友交谈时选择沙滩设定。在一些实施例中,整合标准由系统基于所提取的现实对象(例如,用户)和ar输入数据(例如,系统选定的虚拟环境)完全自动限定。
在一些实施例中,用户可通过语音或手势输入提供实时交互式控制以在整合过程期间重新限定或修改所提取的现实对象(例如,用户)和ar输入数据(例如,虚拟环境)之间的关系。
产生实时ar数据的额外示范性方法可查阅以下专利申请文件,例如,提交于2017年4月4日,发明名称为“基于增强现实的通信中实时图像和信号处理的方法和系统(methodsandsystemsforreal-timeimageandsignalprocessinginaugmentedrealitybasedcommunications)”,申请号为15/479,269的美国专利申请;提交于2017年4月4日,发明名称为“具有增强现实强化的基于场景的实时广告(real-timeandcontextbasedadvertisementwithaugmentedrealityenhancement)”,申请号为15/479,277的美国专利申请;提交于2017年7月31日,发明名称为“实时交互控制的真实感人体全息增强现实通信方法和系统(methodsandsystemsforphotorealistichumanholographicaugmentedrealitycommunicationwithinteractivecontrolinreal-time)”,申请号为15/665,295的美国专利申请;以上每一申请在本申请文件中整体引用。
在一些实施例中,设备102包括表示模块160,其也可被称作“数据表示模块160”或“模块160”。如本申请文件中所公开的,表示模块160可使用数据参数表示一种或多种类型的数据。例如,数据参数可包括文本、一个或多个代码、一个或多个数字、一个或多个矩阵、一个或多个图像、一个或多个音频信号、一个或多个传感器信号;或它们的组合。例如,特定ar输入数据(例如,特定虚拟环境)可用数字代码表示。用户的表情可表示为一系列数字或矩阵。用户的手势可由使用特定针对用户的手势模型的手势模型参数来表示。
如本申请文件中所公开的,不同数据参数可用于表示相同信息。特定形式的数据参数可由若干因素确定,该因素包括但不限于文化背景、语言差异、个人习惯、个体差异等。例如,来自美国的用户向远程通信设备处的另一用户的典型初次问候语可由词语“hello”或“hi”表示,后跟短语“nicetomeetyou”,以及友好挥手致意。英国用户的相同问候语可包括短语“howdoyoudo?”和友好的点头致意。在此,表示问候语的数据参数包括口头问候语的音频信号和手或头移动的图像。
在一些实施例中,值得注意的是,基于文化差异,差异较大的数据参数可用于表示ar数据。例如,来自美国的用户与来自日本的用户在正式商务会议上使用根据本发明的方法/系统交流。日本的用户代表传统公司,因此美国的用户指示系统根据日本习俗定制所述交流。或者,系统可基于提供到系统的场景和背景信息自动建立设定以促进正式会议。在此,信息:词语“hello”或“hi”、短语“nicetomeetyou”、友好挥手致意和可选的背景信息可用于导出知识层级的数据;例如系统可自动学习会议的场景和目的。随后,可基于此信息和知识产生实时ar数据。在实时ar数据中,知识和信息可由不同于与输入数据相关联的数据参数的数据参数表示。例如,系统可使用表示美国用户的虚拟形象来通过根据标准日本习俗鞠躬而创建所述用户问候日本用户的动画。在此,实时ar数据显著不同于原始数据输入:挑选完全不同形式的数据参数来表示相同信息和知识。
表示模块160可将任何层级的数据表示为用于特定设备的合适的格式,包括但不限于包括完全或部分增强数据、信息数据、知识数据、ar输入数据等。例如,增强后的数据在为数据传输而压缩数据之前可被分离成多个文件。在一些实施例中,表示模块160可包括数据构造或重建功能,其可改变特定数据的数据参数形式或类型,例如,从而适应特定类型的硬件设计(例如,3d显示到2d显示,或反之亦然),或更好地向特定受众(例如,具有视觉、音频和其它形式的生理缺陷的人们)呈现数据。
在一些实施例中,计算机设备102中还包括交互式控制模块170。如本申请文件中所公开的,交互式控制模块170可从任何数目的其它功能模块接收指令,例如,这些功能模块包括数据处理模块130、智能模块140、增强模块150、表示模块160、通信模块118等。交互式控制模块170识别待采取的一个或多个动作,所述动作可随后由处理器116通过用户i/o模块110执行。例如,用户可通过输入新的手势来修改或改变先前输入的手势命令。用户还可通过交互式控制模块170改变实时ar数据的内容。例如,在基于实时ar的通信会话期间,用户可选择不同的虚拟现实环境。并且,用户可通过交互式控制改变实时ar数据的一部分。
在非通信设定中,用户还可通过基于智能ar的用户交互平台实时与虚拟内容交互。这在游戏或教育的设定中可能尤其有用。例如,用户可使用手势输入,有时与音频和传感器数据组合,来进入虚拟环境内的不同位置。例如,在古罗马的虚拟旅行中,用户可指向特定方向以改变旅行路线,从而使得有可能不同的人基于其自身兴趣具有不同的旅行体验。并且,例如,当到达新位置时,用户可按压不同虚拟按钮以请求额外信息。并且,例如,在音乐创作的应用中,用户可使用手势来识别音符的虚拟表示以编制音乐。当创作音乐时,可向用户播放音乐,且用户可选择编辑并修正先前创作的音乐。ar相关数据使得向有生理缺陷的人呈现信息成为可能。例如,光颜色、强度和持续时间可用于表示作曲中的音符,这将使失去听觉者能够通过基于智能ar的用户界面的交互式控制模块170通过交互式控制来创作。
如本申请文件中所公开的,交互式控制可在不同层级发生。在一些实施例中,交互式控制可从实时ar数据内发生。例如,在进行网络会议的场景中,讲话者的图像和音频数据将被采集且与其它呈现材料整合。例如,讲话者可展示为站在图表或表前方,且指向所述图表或表的不同部分以突出显示不同点。在一些实施例中,讲话者可使用手势调整表的尺寸以,例如,增大图表或表的一部分以实现较好的可读性。在此,可根据手势产生包括较大图表或表的实时ar数据。在一些实施例中,讲话者可使用语音命令实时实现相同效应。在一些实施例中,一个或多个手势和/或一个或多个语音命令可组合使用以交互式地修改来自实时ar数据内的实时ar数据的内容。
在一些实施例中,交互式控制可超出实时ar数据而发生且仍在实时ar数据中反映。例如,用户可使用手势、语音命令或其组合来执行在远程位置中开门的命令。在此,远程位置中的门在不可由用户直接控制时,也可以采集用户输入数据。如本申请文件中所公开的,门通过网络通信连接到用户可访问的设备,例如作为物联网(iot)内的物理设备中的一个。门还装备有接收和响应于传达到门的数据的能力。例如,基于装弹簧的机构可用于响应于穿过所述装弹簧的控制器的电流的改变而解锁门。在其自然状态中,弹簧拉伸并推动螺栓从而锁门。当用于开门的用户命令(从一个或多个手势和/或一个或多个语音命令解读得到)通过网络通信传达到门所位于的本地iot时,开门命令转化成电脉冲,所述电脉冲可接通电磁机制以将装弹簧的门螺栓拉动在缩回位置,借此打开门。一旦终止电流,装弹簧的螺栓就可返回到伸展位置且锁门。
本申请文件中所公开的方法/系统可用于使可通信地连接到计算机设备的任何物理设备改变其状态。计算机设备通过实施例如图1b的设备102等交互式ar平台来实现此目的。如本申请文件中所公开的,物理设备包括门、灯、冰箱、窗帘、百叶窗、计算机、真空吸尘器、加热器、空调、a/c系统、游泳池、轿车、车库门、水龙头、自行车、小型摩托车、电视机、音频播放器、视频播放器、风扇、游戏设备、时钟、牙刷、碎纸机、可调整的桌子或椅子、相机、传感器或其任意组合。物理设备的状态可包括以下状态:开/关状态、打开和关闭状态、温度状态、运动状态、高度状态、重量状态、尺寸状态、强度状态、声级状态或其任意组合。
在一些实施例中,随着门在现实中打开,实时ar数据可包括现实事件的表示。所述表示可以是现实的、动画、隐喻式或除时序外不相关。例如,实时ar数据可将开门描绘为视频或动画。在一些实施例中,实时ar数据随着门在现实中打开而同时改变其内容。在一些实施例中,实时ar数据可随着门在现实中打开而同时描绘符号视觉表示。例如,实时ar数据可展示表示新世界的开始的新场景。实时ar数据还可展示随着门实时打开水沿着大坝向下流动。
在一些实施例中,现实事件可首先发生且在实时ar数据中反映。在与上文描述的实例类似的实例中,门在现实中打开。门是包括许多其它物理设备的iot的一部分。在一些实施例中,关于门的打开和关闭状态的数据可通过网络通信发送到计算机设备(例如,图1b的设备102)。数据可以不同格式或数据类型(例如,通过表示模块160)表示。不同格式或数据类型可与其它用户输入数据、ar相关输入数据组合以创建实时ar数据。实时ar数据可包括现实中的开门事件的表示。所述表示可以是现实的、动画、隐喻式或除时序外不相关。
如本申请文件中所公开的,网络通信模块118可用于通过有线或无线网络连接促进用户设备和任何其它系统或设备之间的通信。可使用任何通信协议/设备,包括(不限于)调制解调器、以太网连接、网卡(无线或有线)、红外通信设备、无线通信设备和/或芯片组(例如蓝牙bluetoothtm设备、802.11设备、wifi设备、wimax设备、蜂窝式通信机构等)、近场通信(nfc)、紫蜂(zigbee)通信、射频(rf)或射频识别(rfid)通信、电力线通信(plc)协议、基于3g/4g/5g/lte的通信等等。例如,具有基于智能交互式ar的用户交互平台的用户设备可与具有相同平台的另一用户设备、无相同平台的普通的用户设备(例如,普通的智能电话)、远程服务器、远程或本地iot本地网络的物理设备、可穿戴式设备、可通信地连接到远程服务器的用户设备等通信。
在一些实施例中,远程或本地iot的物理设备包括选自由以下组成的群组的物理设备:门、窗、灯、冰箱、一件家具、灯具、窗帘、百叶窗、计算机、计算机设备、真空吸尘器、加热器、空调、a/c系统、游泳池、轿车、车库门、水龙头、自行车、小型摩托车、电视机、扬声器、音频播放器、视频播放器、风扇、游戏设备、玩具、时钟、牙刷、碎纸机、可调整的桌子或椅子、相机、传感器或其任意组合。
例如,用户设备可与物理设备通信以改变其状态。在一些实施例中,物理设备的状态包括二进制状态、连续值调整状态或离散值调整状态。在一些实施例中,物理设备的状态包括选自由以下组成的群组的状态:开/关状态、打开和关闭状态、是和否状态、温度状态、运动状态、高度状态、重量状态、尺寸状态、强度状态、声级状态及其任意组合。在一些实施例中,物理设备包括一件家具、车辆、器具、电子器具、建筑物、传感器、灯具、玩具或另一计算机设备。
本申请文件中所描述的功能模块借助于实例而提供。应理解,不同功能模块可组合以创建不同效用。还可以理解,可创建额外功能模块或子模块以实施特定效用。
如本申请文件中所公开的基于智能ar的用户交互平台具有完全不同的场景中的大量应用,尤其实时应用。通过实施不同功能模块的组合实现不同应用。示范性应用包括(但不限于)智能交互式搜索;用于沉浸式和非侵入性内容显示/体验(例如,用于教育或广告)的交互式显示屏或布告板;ar输入数据的实时图像和信号处理及整合(通信和非通信场景中);基于场景的实时广告;以及具有交互式实时控制的拟真人类全息基于ar的通信。
图1c说明基于当前系统和方法的智能设备可如何与大量设备交互,例如通过本地或远程网络连接与大量设备交互。例如,智能平台设备可直接或通过本地计算机、智能电话设备等连接到本地物联网(iot)网络上的设备。并且,例如,智能平台设备可通过例如计算机、智能电话等一个或多个中间设备通过因特网连接连接到远程iot网络。在一些实施例中,智能平台设备可通过因特网连接直接连接到远程iot网络。
图1d说明多个智能设备可如何直接或通过网络连接和一个或多个中间设备彼此交互。在一些实施例中,智能设备可与一个或多个专门功能(例如,视频会议、家用功能、智能轿车相关应用、健康相关应用)相关联。在一些实施例中,相同智能设备可具有相关的多个类型的功能。
这些和类似应用的额外细节和实例可查阅以下专利申请的申请文件:提交于2016年12月1日,发明名称为“用于个人化交互式智能搜索的方法和系统(methodsandsystemsforpersonalized,interactiveandintelligentsearches)”,申请号为15/367,124的美国专利申请;提交于2017年4月4日,发明名称为“用于基于增强现实的通信中的实时图像和信号处理的方法和系统(methodsandsystemsforreal-timeimageandsignalprocessinginaugmentedrealitybasedcommunications)”,申请号为15/479,269的美国专利申请;提交于2017年4月4日,发明名称为“具有增强现实强化的实时和基于场景的广告(real-timeandcontextbasedadvertisementwithaugmentedrealityenhancement)”,申请号为15/479,277的美国专利申请;以及提交于2017年7月31日,发明名称为“用于具有实时交互式控制的真实感人类全息增强现实通信的方法和系统(methodsandsystemsforphotorealistichumanholographicaugmentedrealitycommunicationwithinteractivecontrolinreal-time)”,申请号为15/665,295的美国专利申请;提交于2017年8月11日,发明名称为“基于智能增强现实(iar)平台的通信系统(anintelligentaugmentedreality(iar)platform-basedcommunicationsystem)”,申请号为15/675,635的美国专利申请;其中的每一个全文以引用的方式并入本申请文件中。
示范性实施例:输入数据的智能综合解释
一方面,本申请文件公开用于综合解释输入数据的方法和系统。综合解释可在许多层级发生,包括但不限于例如多个类型的输入数据(例如,视觉、音频和传感器数据)的使用;多个层级处输入数据的选择性处理(例如,通过关于不相关的人的输入数据的移除和聚焦于所关注的一个或多个用户;使用户数据与环境或场景数据分离,这里的环境或场景数据是基于场景,从数据的子集提取的信息和基于所提取信息学习的知识,交互式用户控制的;以及基于例如用户偏好、系统设定、整合参数、原始数据的对象或场景的特性、交互式用户控制或其组合等标准选择数据),以及深度理解原始数据、部分或完全处理后的数据(例如,基于例如用户偏好、系统设定、整合参数、原始数据的对象或场景的特性、交互式用户控制或其组合等大量标准)。
图2a说明用于实行用于执行用户输入数据(例如,图像、视频、音频和/或传感器数据)的综合迭代和交互式解释/分析的功能的示例性系统200。在此,多个用户设备(例如,220和240)通过网络238连接到服务器设备250。用户输入数据的处理可在所说明的设备中的一个或多个上发生。例如,用户设备220可作为独立设备本地执行所有必需功能。用户设备240表示依赖于一个或多个其它设备(例如,服务器250或例如用户设备220等用户设备)的设备。如本申请文件所论述的,执行特定应用所必需的功能以任何组合在用户设备240和所述一个或多个其它设备之间共享,具有一个限制:数据捕获或获取通常在用户可访问的用户设备处发生。
在一些实施例中,用户输入数据进一步包括音频输入数据或感觉输入数据。在一些实施例中,感觉输入数据包括用户的生物状态数据、用户的用户行为数据、环境数据,或用户附近的对象的状态数据。如本申请文件中所公开的,示范性生物状态数据包括(但不限于)心跳数据、血压数据、体温数据、用户脉搏数据、用户方向数据、呼吸模式数据等。示范性用户行为数据包括(但不限于)加速度数据、运动数据、陀螺仪数据、压力数据、距离数据等。示范性环境数据包括(但不限于)环境温度、湿度、风速、海拔高度、地理位置数据、全球定位系统(gps)数据等。如本申请文件中所公开的,用户附近的对象可以是物理对象或另一人。对象的示范性数据包括(但不限于)行为数据或用户生物状态数据。如本申请文件中所公开的,在一些实施例中,所述系统和方法可将人自动识别为系统的用户,且因此聚焦于与特定用户相关联的输入数据。用于从用户附近的一个或多个对象识别用户的标准可包括例如用户相比于所述一个或多个对象在身体上或情绪上的活跃程度。在一些实施例中,活跃度水平可基于感觉数据确定。在一些实施例中,所述系统和方法可基于相对活跃度一次识别一个用户;即,所述系统和方法可从一个人自动切换到另一人。
在一些实施例中,感觉输入数据包括选自由以下组成的群组的数据:用户的生物状态数据、心跳数据、血压数据、体温数据、方向数据、环境温度数据、运动数据、压力数据、海拔高度数据、距离数据、加速度数据、陀螺仪数据、地理位置数据、全球定位系统(gps)数据及其任意组合。
用户设备220描绘装备有多个功能的本地设备(例如,用户或现实对象可访问的设备)。具体地说,用户设备220包括用户输入和输出(i/o)模块202、本地数据库204和多个功能模块(例如,模块206、208、210、212等),所述功能模块用于捕获用户输入数据(例如,场景中的现实对象的图像、声音和传感器数据)、使现实对象与其周围环境分离、基于实时学习和分析提取关于现实对象或场景的信息/知识,以及基于用户输入数据的综合和实时解释提供本地设备的实时交互式控制。如本申请文件中所公开的,综合和实时解释可以是用户偏好、系统设定、来自原始数据的对象或场景的特性、已从其提取信息的选定数据、已从其学习知识的选定信息,或任何其它可适用的标准。
在一些实施例中,用户设备220可作为独立的设备本地执行所有必需功能。在一些实施例中,执行特定应用必需的功能在用户设备240和所述一个或多个其它设备(例如,远程服务器或另一用户设备)之间共享。如本申请文件中所公开的,所述功能可以任何组合共享,具有一个限制:数据捕获或获取通常在用户可访问的用户设备处发生。
在一些实施例中,用户设备220包括用户输入输出模块(i/o模块)202。例如,i/o模块202可接收对用户设备220的用户输入数据且使用文本、音频、视频、运动和/或触觉输出机制呈现来自用户设备220的输出。例如,i/o模块202可从用户接收手势输入、肢体运动或语音输入以启动用于产生基于ar的实时图像数据的方法。在一些实施例中,此输入可用于通过实时指定用户偏好或选择系统偏好来改变方法的过程。在一些实施例中,i/o模块202还用于检测和跟踪眼睛移动、面部表情等。并且,例如,i/o模块202从用户设备220的触敏式显示器接收触摸输入。在其它实施例中,i/o模块202可耦合到其它输入设备,例如相机、键盘、鼠标、显示器、触摸显示屏、扬声器等,且从这些设备接收用户输入。在一些实施例中,i/o模块202包括相机、键盘、鼠标、显示器、触摸显示屏、扬声器等,作为i/o模块202或用户设备220的组成部分。在一些实施例中,用户设备220可接收多个类型的用户输入。在一些实施例中,i/o模块202或用户设备220还包括一个或多个传感器设备,用于采集例如心跳、血压、方向、压力、距离、加速度等信息,或允许用户接收例如触摸等物理体验(例如,用户可实时接收远程握手)。
在一些实施例中,i/o模块202还可向用户呈现音频、视觉、运动和/或触觉输出。例如,i/o模块202在显示器上向设备220的用户显示整合的图像或视频。在一些实施例中,i/o模块202可呈现gui,其实现或支持本申请文件中所描述的实时图像和信号处理方法/系统中的一个或多个的功能,包括但不限于数据捕获模块206、数据处理模块208、基于智能的解释模块210和交互式控制模块212。在一些实施例中,用户输入和输出模块包括多个菜单命令,每一菜单命令对应于处理用户输入数据所需的功能模块中的一个或多个的功能。
在一些实施例中,i/o模块202允许用户查找输入数据处理所需的信息的位置。在实施例中,可提供菜单选项使得用户可选择一个或多个选项以启用一个或多个功能。例如,用户可点击图标或使用手势来开始数据捕获过程。
在一些实施例中,用户可使用i/o模块202来请求本地用户设备220上可用的信息或可通过网络连接从服务设备250或另一用户设备240获得的信息。例如,i/o模块202可允许用户使用语音或手势命令来请求可有助于较好地理解输入数据的额外数据,例如本地存储的数据(例如,用户偏好、系统设定、场景、本地用户日志数据等)或可通过网络通信访问的数据(例如,与用户的地理位置相关的趋势数据、关于特定主题或群体的大数据)。
在一些实施例中,用户可使用i/o模块122来管理各种功能模块。例如,如果用户设备将很可能由相同用户使用,那么用户可通过用户i/o模块122请求设定用户偏好。用户可通过在不中断通信的情况下分别选择菜单选项或键入命令来完成此操作。
当本申请文件中所公开的方法/系统用于处理和编辑输入数据(例如,图像、音频或传感器数据)时,用户可使用任何类型的输入来通过用户i/o模块202引导和控制所述过程。
适合用作用户界面的一部分的任何设备或功能部件可用作用户i/o模块122(作为用户设备的组成部分或可通信地连接到用户设备)。示范性设备或功能部件包括(但不限于)例如结合计算机设备102(图1b)的用户i/o模块110的输入子模块112和输出子模块114公开的设备或功能部件。
在一些实施例中,用户设备220进一步包括本地数据库204。如本申请文件中所公开的,“本地数据库204”和“数据库204”可互换使用。例如,本地数据库204可存储所捕获的用户输入数据,例如图像、音频数据和传感器数据、部分或完全处理的图像(例如,所提取的现实对象,和虚拟环境的图像),或部分或完全整合的图像。在一些实施例中,数据库204可存储用户特定信息;例如,先前输入数据和关于设备的常用用户的数据可存储在本地数据库204中。在一些实施例中,数据库204可存储从另一设备(例如,用户设备或服务器)获得的信息。在一些实施例中,存储器或数据库204可存储通过因特网搜索而实时获取到的信息。
在一些实施例中,本地数据库204将数据发送到功能模块中的一个或多个且从功能模块中的一个或多个接收数据,所述功能模块包括但不限于数据捕获模块206、数据处理模块208、基于智能的解释模块210和交互式控制模块212。
在一些实施例中,用户设备220包括数据捕获模块206。如本申请文件中所公开的,“数据捕获模块206”、“捕获模块206”和“模块206”可互换使用。例如,数据捕获模块206可包括例如相机等图像捕获设备。在一些实施例中,相机是深度启用的。在一些实施例中,使用两个或两个以上相机。在一些实施例中,内置麦克风或外部麦克风可用于音频采集。在一些实施例中,数据捕获模块206捕获多个图像。在一些实施例中,数据捕获模块206可捕获多个图像,且将其融合在一起例如以创建动画图像。在一些实施例中,数据捕获模块206连续捕获视频。在一些实施例中,数据捕获模块206通过使用与设备220相关联的一个或多个传感器来捕获传感器数据。
如本申请文件中所公开的,数据捕获模块206从用户捕获输入数据(例如,现实对象物理上所处的实际环境中该现实对象的实时图像、声音或传感器数据)。
适于数据采集的任何设备或功能部件可用作数据捕获模块206(作为用户设备的组成部分或可通信地连接到用户设备)。示范性设备或功能部件包括(但不限于)例如结合计算机设备102(图1b)的用户i/o模块110的输入子模块112公开的设备或功能部件。
在一些实施例中,用户设备220包括数据处理模块208。数据处理模块208可从i/o模块202、数据捕获模块206或本地数据库204接收实时数据。在一些实施例中,数据处理模块208可执行例如降噪或信号增强等标准数据处理算法。在一些实施例中,数据处理模块208可执行初始数据发现且从实时接收的数据中提取信息。例如,可分析每一类型中的数据以识别信息,例如人类特征模式(例如,脸、虹膜、身体、手势等)、语音模式、生物状态或对象的任何其它物理或非物理特征等。
在一些实施例中,数据处理模块208可基于数据类型分离用户输入数据。在一些实施例中,数据处理模块208可组合和整合多个类型的数据。在一些实施例中,数据处理模块208可单独地评估和分析每种类型的实时数据(例如,视觉、音频或传感器)。在一些实施例中,数据处理模块208可同时评估和分析多个类型的实时数据(例如,视觉和传感器数据可用于检测心脏病发作)。
在一些实施例中,用户输入数据中的用户特定信息可基于一个或多个标准与非用户相关数据分离,所述标准包括用户的特性和其环境之间的差异。例如,数据处理模块208可例如基于其在图像内的相对位置、对比度、照明、颜色、热特性等的差异识别用户和其环境之间的边界。在一些实施例中,图像数据使用深度启用的相机采集,且深度信息用于将用户输入数据分离为背景和前景。
在一些实施例中,数据处理模块208可执行实时对象识别,借此使用户(被视为现实对象)与其环境分离。在一些实施例中,对象识别包括检测人的不同身体部位。在一些实施例中,对象识别还包括使特定特性与人的身体部位相关联。例如,人的手可常常与移动相关联,且往往会与其它对象/人和环境交互。由此,与例如脸、胸部或躯干等其它身体部位相比,手的轮廓更可能形成人的边界。如本申请文件中所公开的,对象识别可跟踪用户移动且促进手势识别,借此促进用户输入数据的综合解释。
在一些实施例中,数据处理模块208可执行分段分析。例如,分段可根据一个或多个预设标准对来自现实环境的对象/用户实时分段。
在一些实施例中,数据处理模块208可使用预先学习的信息执行实时数据处理。例如,对象和场景的预先存在的模式可在进一步实时学习之前用作开始点。
在一些实施例中,基于综合特性的机制用于识别用户(例如,现实对象)的特定特性和环境的特定特性之间的一个或多个差异。例如,特性可包括且不限于视频剪辑中捕获的用户或实际环境的视觉特性、现实对象或实际环境的实时学习的特性,或关于用户或实际环境的预先学习的特征。在一些实施例中,视觉特性可包括但不限于包括空间特性、尺寸特性、形状特性、运动特性、颜色特性、光照度和反射特性、时间特性或透明度特性、深度特性、材料特性,或其任意组合。在一些实施例中,空间特性包括三维空间特性。
在一些实施例中,实时学习的特性包括但不限于颜色、形状、边缘、光反射、光照度、曝光、亮度、阴影、高光、对比度、运动、深度、材料或其任意组合。在一些实施例中,预先学习的特征还包括但不限于颜色、形状、边缘、光反射、光照度、曝光、亮度、阴影、高光、对比度、运动、深度、材料或其任意组合。学习方法可包括线性回归、决策树、支持向量机、k-最近邻域、k-均值、贝叶斯网络、逻辑回归、基于特征点的学习、神经网络、隐马尔可夫链或其任意组合。所述学习可受监督、部分受监督或无监督。
在一些实施例中,对象学习、对象识别和分段功能在很大程度上相关,且可同时和迭代地发生。具体地说,来自实时学习中的一个的结果可能影响另一个的结果。如本申请文件中所公开的,开发了实时自适应数据处理过程以优化用户输入数据的分析和理解。
在一些实施例中,数据处理模块208可选择性地识别与所关注的仅一个或多个用户相关的输入数据的部分。例如,可放置用于沉浸式和非侵入性内容显示/体验(例如,用于教育或广告)的交互式显示屏或布告板,其中许多人(例如,潜在用户)可同时存在。可安装交互式显示屏或布告板用于公共显示。为了实现有效体验,来自仅极少人的输入数据可能是相关的。在一些实施例中,来自仅一个人的输入数据可能是相关的。
如本申请文件中所公开的,数据处理模块208可智能地且选择性地根据一个或多个标准识别最相关用户输入数据。例如,通过对象和模式识别,数据处理模块208可在一时间周期内并行识别和跟踪多个用户的移动。在一些实施例中,具有最活跃移动轮廓的用户将识别为最相关用户。特定用户的输入数据将与其它人的输入数据分离且在智能模块210处进行进一步分析。
在一些实施例中,数据处理模块208可访问存储在数据库204中的用户活动历史,且可相对于第一次体验显示屏或布告板的人选择已经出现在显示屏或布告板前方的人。
在一些实施例中,尤其在广告场景中,数据处理模块208可识别和选择很可能在正广告的特定产品和/或服务的目标群体内的人。例如,当交互式显示屏或布告板用于广告特定化妆品线时,数据处理模块208可基于例如某人是否化了妆以及某人是否穿着时髦的服饰而将该人识别和选择为用户。例如,当显示屏或布告板用于广告西装时,数据处理模块208可相对于未穿着商务服装的人识别和选择穿着商务服装的人。在一些实施例中,数据处理模块208可基于一个或多个预设标准识别和选择目标用户。例如,当显示屏或布告板用于小学和幼儿园的交互式学习和娱乐时,可设定系统偏好使得数据处理模块208可基于例如身高、面部结构、走路方式和其它物理特性仅识别和选择来自特定年龄组的儿童的用户输入数据。
在一些实施例中,非视觉数据可用于促进选择性地识别相关用户的输入数据。例如,多个人在交互式显示屏或布告板前,且采集这些人的视觉和音频数据。除分析视频数据并确定此群组中的一个或多个人是否可能是相关用户外,还可使用非视频数据来帮助选择。例如,交互式显示屏或布告板用于广告特定化妆品线,且在所存在的人的群组当中,基于图像数据处理将两个人识别为化妆品广告的潜在目标。当处理音频数据时,两个人中的一个表达对化妆品生产线的强烈厌恶。基于该额外信息,数据处理模块208将使其它人的用户数据与所采集数据分离,且使其进行进一步分析和操作。例如,可能潜在地购买特定化妆品生产线的人将沉浸到结合特定化妆品生产线具有巧妙嵌入式要素的虚拟环境中。
在一些实施例中,用户设备120包括基于实时智能的解释模块210。如本申请文件中所公开的,“基于智能的解释模块210”、“智能模块210”、“解释模块210”和“模块210”可互换使用。智能模块210从数据处理模块208接收经过初始处理的输入数据,且执行用户输入数据的综合分析和学习。在一些实施例中,还接收原始数据,代替初始处理的输入数据。在此类实施例中,数据处理模块208可被绕过。在一些实施例中,在智能模块210处既接收原始数据又接收经过初始处理的输入数据。
在一些实施例中,智能模块210,例如使用信息提取子模块,执行从经过初始处理的输入数据和/或原始数据的实时信息提取。如本申请文件中所公开的,信息提取可基于一个或多个标准发生,所述一个或多个标准包括用户偏好、系统设定、整合参数、原始数据的对象或场景的特性、交互式用户控制或其任意组合。如本申请文件中所公开的,可通过将数据场景化、分类、计算和压缩来提取信息。在一些实施例中,信息提取还可根据一个或多个标准发生,所述一个或多个标准包括用户偏好、系统设定、整合参数、原始数据的对象或场景的特性、交互式用户控制或其任意组合。所述标准中的每一个可视为组织原始数据和将原始数据场景化的方式。在一些实施例中,至少一个标准是基于大数据的。
如本申请文件中所公开的,所提取的信息可由信息数据表示。在一些实施例中,信息数据可包括文本、一个或多个代码、一个或多个数字、一个或多个矩阵或其任意组合。在一些实施例中,信息数据可包括一个或多个图像、一个或多个音频信号、一个或多个传感器信号或其任意组合。在此,图像、音频信号和传感器信号可以,并且优选地,不同于包括在从其提取信息的原始数据中的图像、音频信号和传感器信号。
在一些实施例中,一旦启动数据捕获就触发实时信息提取。在一些实施例中,通过组织数据实现信息提取。例如,当原始数据包括多个类型的数据(例如,对象或场景的视觉、音频或传感器数据)时,可通过根据其数据类型分离数据来实现数据组织。在一些实施例中,每种类型的数据基于数据的内容而进一步分离;例如,对应于对象的数据可与对应于场景的数据分开组织。例如,对象的实时信息提取包括例如基于其在图像内的相对位置、对比度、照明、颜色、热特性等的差异识别对象和其环境之间的边界。在一些实施例中,使用深度启用的相机采集图像数据,且使用深度信息在从背景数据和前景数据中任一个提取信息之前将图像数据分离为背景数据和前景数据。在一些实施例中,提取模块128可通过实时对象识别和数据分离提取信息。例如,对象识别包括使人与环境分离。在一些实施例中,对象识别包括检测人的不同身体部位。在一些实施例中,对象识别还包括使特性与人的身体部位相关联,这可促进关于运动、尺寸的信息的提取。
在一些实施例中,智能模块210(或其子模块)可通过基于一个或多个特性进一步实时将数据组织(例如,分离)为与对象和其环境相关联的一个或多个子类别来提取信息。例如,共享相同或类似视觉特性(例如,颜色、暗度)的相同对象的部分可组织在一起。在一些实施例中,信息提取利用基于综合特性的机制,包括基于人工智能的机制。例如,基于综合特性的机制可识别人、对象和环境的一个或多个特性及其差异。示范性特性可包括且不限于视觉特性,例如空间特性、尺寸特性、形状特性、运动特性、颜色特性、光照度和反射特性、时间特性或透明度特性、深度特性、材料特性或其任意组合等。在一些实施例中,空间特性包括三维空间特性。在一些实施例中,所述特性可以是实时学习的特性,包括但不限于颜色、形状、边缘、光反射、光照度、曝光、亮度、阴影、高光、对比度、运动、深度、材料或其任意组合。在一些实施例中,预先学习的特征还包括但不限于颜色、形状、边缘、光反射、光照度、曝光、亮度、阴影、高光、对比度、运动、深度、材料或其任意组合。
在一些实施例中,根据用户偏好或系统设定,例如通过排除不相关数据或聚焦于一种或多种类型的数据来组织原始数据。在一些实施例中,可设置用户偏好以指定用于信息提取的数据的类型,可移除或忽略不相关数据以促进从相关数据的信息提取。例如,如果医生对关于心脏状况的医疗数据感兴趣,那么信息提取将聚焦于例如脸的颜色、脉搏/心跳、呼吸数据、血压等数据。在另一实例中,如果医生对关于患者的皮肤状况的信息感兴趣,那么可仅针对皮肤相关数据实行信息提取。
在一些实施例中,可结合交互式用户控制执行信息提取。例如,在基于本发明的方法/系统的远程诊断会话中,医生可请求某一类型的信息。例如,医生可请求基于由一个或多个传感器捕获的心跳数据计算心率。
在一些实施例中,本申请文件中所公开的系统/方法可包括指定在特定预定义场景中彼此相关的数据类型的系统设定。可选择和处理指定数据类型的数据以用于信息提取。
通过应用各种分析工具,表示不同对象和场景的数据可组织和放置到场景中。例如,通过比较来自不同时间点获得的不同图像的对象的位置数据,有可能提取对象的位置或运动信息。在一些实施例中,可有可能在多个对象存在于原始数据中时计算或比较相对速度。
在一些实施例中,智能模块210(或其子模块)可从一种类型的数据提取信息。在一些实施例中,提取模块128从多个类型的数据提取信息。例如,人的外表可与体温读数组合以用于额外信息提取。在一些实施例中,多个类型的数据可在信息提取之前融合。
在一些实施例中,如本申请文件中所公开的信息提取过程可在一个轮次中或多个轮次中完成。在一些实施例中,一个轮次的粗略信息提取可在实行一个或多个附加轮次的精细提取之前首先执行。例如,粗略提取可提供例如心率等信息,而更深层次的信息提取可得出一个或多个完整心博循环的信息:例如流入期、等容收缩、流出期和等容舒张的信息。更深层次的信息提取将包括提取与a-v瓣膜封闭、主动脉瓣膜打开、等容收缩、喷射、等容舒张、快速流入、a-v瓣膜打开相关联的信息。示范性信息可包括主动脉压力、心房压力、心室压力和心室容积。在一些实施例中,从心电图和心音图提取信息。如所提到的,可在其处提取信息的层级可能受可用的分析方法、原始数据的数量、类型和质量限制。
在一些实施例中,智能模块210(或其子模块)可使用预先学习的信息提取实时信息。例如,对象和场景的预先存在的模式可在进一步实时信息学习之前用作开始点。在一些实施例中,信息提取可在不同设备上多次发生。例如,初始信息提取可在具有有限计算能力的本地设备上发生。初始信息提取可能是粗略的且深度受到限制。所提取的信息和原始数据可传递到另一计算机设备,该另一计算机设备具有较强计算能力,且对其中发生进一步信息提取的较综合数据库(例如,包括大数据)的较好的访问能力。在一些实施例中,可基于机器学习和模式识别方法执行信息提取,例如,所述方法包括深度学习、神经网络、基于特征点的方法、主分量分析(pca)、线性判别分析(lda)等。
在一些实施例中,智能模块210可包括信息学习子模块,其可基于已从原始数据提取的信息的分析学习或导出知识。
在一些实施例中,通过对信息进行理解和场景化来学习知识。在一些实施例中,此场景化可通过将相关信息组织成类别来实现。此增加的组织层级可辅助理解数据。例如,在其中患者具有即将发生心脏病发作的高风险的实例中,医生可通过将相关信息组织在一起来学习此知识。例如,患者表现出令人担忧的症状,例如面色潮红、心率很快、血压很高、短促的呼吸、行动缓慢等。
类似于信息提取,还可根据一个或多个标准发生知识学习,所述一个或多个标准包括用户偏好、系统设定、整合参数、原始数据的对象或场景的特性、交互式用户控制或其组合。例如,特定设计用于医疗诊断的方法/系统可具有每种疾病的一个或多个预定类别,每种疾病有可能可以基于例如视频数据、音频数据和传感器数据等非侵入性数据识别。例如,心脏病的类别将告知所述方法/系统聚焦于特定类型的信息,例如脸色、呼吸模式、心率、血压值等。在一些实施例中,所述方法/系统还提供参考标准,将对照所述参考标准比较所获得的信息,且可根据比较的结果产生学习的知识。在一些实施例中,至少一个标准是基于大数据的。
如本申请文件中所公开的,学习的知识可由知识数据表示。在一些实施例中,知识数据可包括文本、一个或多个代码、一个或多个数字、一个或多个矩阵或其任意组合。在一些实施例中,知识数据可包括一个或多个图像、一个或多个音频信号、一个或多个传感器信号或其任意组合。在此,图像、音频信号和传感器信号可以,且优选地,不同于从其间接导出知识的原始数据中包括的图像、音频信号和传感器信号。
在一些实施例中,知识学习包括基于一个或多个特性将可用信息实时组织(例如,分离)为与对象和其环境相关联的一个或多个子类别。例如,反映对象的视觉特性的信息可组织成一个类别。在一些实施例中,知识学习除使用例如基于人工智能的机制之外还利用基于综合特性的机制来促进学习。例如,基于综合特性的机制可识别人、对象和环境的一个或多个特性及其差异。示范性特性可包括且不限于视觉特性,例如空间特性、尺寸特性、形状特性、运动特性、颜色特性、光照度和反射特性、时间特性或透明度特性、深度特性、材料特性或其任意组合等。在一些实施例中,空间特性包括三维空间特性。在一些实施例中,所述特性可以是实时学习的特性,包括但不限于颜色、形状、边缘、光反射、光照度、曝光、亮度、阴影、高光、对比度、运动、深度、材料或其任意组合。在一些实施例中,预先学习的特征还包括但不限于颜色、形状、边缘、光反射、光照度、曝光、亮度、阴影、高光、对比度、运动、深度、材料或其任意组合。
在一些实施例中,知识学习可与交互式用户控制一起执行。例如,在基于本发明的方法/系统的远程诊断会话中,医生可请求系统研究某人是否患有某一类型的疾病或病况的可能性。在一些实施例中,在接收此类用户指示后,系统可集合可能对于诊断特定疾病或病况有帮助的相关信息。
在一些实施例中,从一种类型的信息导出知识。在一些实施例中,可从多个类型的信息导出知识。大多数医疗诊断在知识层级发生。使用以上相同实例,例如最大发热值、发热持续时间、暴露于热和病菌或水化状态等额外信息可导致不同的诊断和不同的治疗。
在一些实施例中,可基于机器学习和模式识别方法来执行信息提取。例如,所述方法包括深度学习、神经网络、基于特征点的方法、主分量分析(pca)、线性判别分析(lda)等。
在一些实施例中,用户设备220包括误差补偿模块。例如,3d相机不能提供关于深色对象的准确深度信息。误差补偿模块可基于对象特性或区连续性补偿此类深度误差。在一些实施例中,3d相机不能提供关于快速移动对象的准确深度信息。误差补偿模块可基于对象特性、区连续性或对象移动特性补偿移动对象的此类深度误差。在一些实施例中,红外相机不能提供明亮反射对象的准确数据。误差补偿模块可基于对象特性或区连续性补偿关于明亮反射对象的红外相关的误差。在一些实施例中,误差补偿图像可用作进一步实时对象学习的参考。在一些实施例中,来自数据处理模块208的结果还可用于误差补偿。在一些实施例中,误差补偿模块可执行任何硬件和/或软件部件的调整和优化,包括,例如,响应于光照条件的变化调整相机的设定。
在一些实施例中,实时学习的特性包括但不限于颜色、形状、边缘、光反射、光照度、曝光、亮度、阴影、高光、对比度、运动、深度、材料或其任意组合。在一些实施例中,预先学习的特征还包括但不限于颜色、形状、边缘、光反射、光照度、曝光、亮度、阴影、高光、对比度、运动、深度、材料或其任意组合。学习方法可包括线性回归、决策树、支持向量机、k-最近邻域、k-均值、贝叶斯网络、逻辑回归、基于特征点的学习、神经网络、隐藏马尔可夫链或其任意组合。所述学习可受监督、部分受监督或无监督。
数据捕获模块206、数据处理模块208、实时学习模块210和误差补偿模块的功能共享许多类似性,且在一些实施例中,这些模块中的两个或两个以上可组合。
在一些实施例中,可使用具有多个隐蔽层的深度结构学习。深度学习可受监督、部分受监督或无监督。示范性深度结构学习方法可包括(但不限于)深度神经网络、深度信念网络、递归神经网络、这些深度结构的混合,以及深度结构与其它模式识别方法的混合。归因于其深度结构和极大程度的非线性特性,有时解释学习的内容、什么特性较重要、学习的特性将如何反映对象的物理特性是具有挑战性的。在此,从深度学习中学习得到的参数也称为对象特性。
如本申请文件中所公开的提取或学习过程可在一个轮次中或多个轮次中完成。在一些实施例中,可在实行一个或多个附加轮次的精细提取之前首先执行一个轮次的粗略信息提取。例如,粗略提取可跟踪现实对象的轮廓,而精细提取可细化分离现实对象和其实际环境的边缘。在一些实施例中,一个或多个轮次的精细提取还可识别实际上为环境的一部分的现实对象的轮廓内的区域,且随后从现实对象中移除该区域。
在一些实施例中,用户设备220包括交互式控制模块212。如本申请文件中所公开的,交互式控制模块170可从任何数目的其它功能模块接收指令,例如,这些功能模块包括数据处理模块206、智能模块210、通信模块118等。交互式控制模块170识别待采取的一个或多个动作,所述动作可随后由处理器通过用户i/o模块202执行。例如,用户可通过输入新手势来修改或改变先前输入的手势命令。用户还可通过交互式控制模块212改变实时ar数据的内容。例如,在基于实时ar的通信会话期间,用户可选择不同的虚拟现实环境。并且,用户可通过交互式控制从实时ar数据内改变实时ar数据的至少一部分。
在一些实施例中,示例性系统200进一步包括用户设备240。在一些实施例中,用户设备240可具有与用户设备220相同的功能模块;例如,用户输入和输出模块222、本地数据库224、数据捕获模块226、数据处理模块228、基于智能的解释模块230等。当呈现功能模块时,其可类似于用户设备220中或根据任何可适用的已知技术来实施。
在一些实施例中,用户设备240可具有较少功能模块,且改为依赖于服务器250来提供一个或多个功能。如图1a中所说明,除数据捕获模块外,包括数据捕获模块226、数据处理模块228、基于智能的解释模块230等所有其它主要功能模块可对于用户设备240为可选的。实际上,这些功能可以任何组合在用户设备240和服务器250之间划分。例如,用户设备240可将所捕获图像发送到服务器170用于数据处理(例如,对象提取)和智能解释。尽管未描绘,但可以理解,例如结合计算机设备102、用户设备220和用户设备240公开的任何已知输入/输出设备或部件可由服务器250使用。
在一些实施例中,示例性系统200进一步包括服务器250。如本申请文件中所公开的,服务器250可与一个或多个用户设备通信且包括例如服务器数据库254、数据处理模块258、基于智能的解释模块260、交互式控制模块262等功能模块。在一些实施例中,数据处理模块258、基于智能的解释模块260、交互式控制模块262类似于结合用户设备220或用户设备240公开的模块。在一些实施例中,这些模块可归因于相比用户设备来说服务器的增强的计算能力和存储空间而在服务器250上以不同方式执行。例如,整合可以比用户设备将允许的像素数目更高的像素数目并行发生。
本申请文件中所公开的方法/系统在许多方面是有利的。在一些实施例中,用户输入数据的综合迭代和交互式解释/分析允许更准确地理解用户意图且因此可帮助较好地执行所述意图。例如,用户输入数据的综合迭代和交互式解释/分析可搜索和检索更精确和相关的结果。所述搜索可在许多不同场景中的任何层级进行。例如,其可搜索本地设备本身上的内容或信息。替代地,所述搜索可通过网络连接在远程设备或远程服务器上执行;例如基于网页的搜索。额外细节可查阅提交于2016年12月1日,发明名称为“用于个人化交互式智能搜索的方法和系统(methodsandsystemsforpersonalized,interactiveandintelligentsearches)”,申请号为15/367,124的美国专利申请,其全文以引用的方式并入本申请文件中。
输入数据(例如,用于后续实时增强的实时图像数据)的综合、迭代和智能解释及分析的额外细节可查阅图5a到5c的描述以及提交于2017年7月31日,发明名称为“用于具有实时交互式控制的真实感人类全息增强现实通信的方法和系统(methodsandsystemsforphotorealistichumanholographicaugmentedrealitycommunicationwithinteractivecontrolinreal-time)”,申请号为15/665,295的美国专利申请,其全文以引用的方式并入本申请文件中。
在一些实施例中,用户输入数据的综合迭代和交互式解释/分析允许本地设备处的交互式动态控制。在一些实施例中,如本申请文件中所公开的方法/系统可内嵌于交互式显示布告板中用于沉浸式和非侵入性内容显示/体验(例如,用于教育或广告),所述沉浸式和非侵入性内容显示/体验可在独立的用户设备220中实施。
图2b描绘用于执行输入数据的实时智能综合解释的示范性过程270。
在步骤272,实时用户输入数据由数据捕获模块使用一个或多个数据采集部件采集。例如,数据采集部件包括相机、麦克风和一个或多个传感器等。可使用任何合适的数据捕获设备和/或部件,包括但不限于结合图1a的输入数据模块112描述的数据捕获设备和/或部件;图1b的数据捕获模块120;以及图2a的数据捕获模块206和226。
此步骤采集的用户输入数据可包括视频数据(例如图像和视频)。在一些实施例中,也可包括音频数据和/或传感器数据。
步骤274,例如由数据处理模块处理所采集的用户数据用于初始数据解释。如本申请文件中所公开的,数据处理可包括数据选择(例如,排除不相关的输入数据,这些输入数据与人或对象相关);数据分离(例如,使表示所关注用户的数据与周围环境和不相关对象的数据分离);数据组织(例如,相同类型的数据可组织在一起);组合数据(例如,与选定视频数据相关联的非视频数据可彼此相关联以用于进一步分析);等。
可应用任何合适的方法和机制;包括但不限于结合图1b的数据处理模块130;图2a的数据处理模块208;数据处理模块228;数据处理模块258描述的方法和机制。
步骤276,对输入数据执行基于实时智能的学习和解释。如本申请文件中所公开的,与所关注的用户或对象相关的信息可从步骤276处理的数据提取。此外,所提取的信息可用作学习与所关注的用户或对象相关的知识的基础。
与所关注的用户或对象相关的信息和/或知识可应用于相关输入数据以用于对用户输入数据进行进一步解释。例如,可分析用户移动、面部表情、手势以提取信息和知识层级的含义,该提取的含义随后用于进一步解释用户输入。例如,开心和愤怒的情绪都可能导致激动的身体移动。然而,当综合考虑表情、语言和场景信息(有时具有其它数据/信息/知识)时,可获得用户输入数据中观察到的激动的用户移动的更精确解释。
步骤278,可使用额外标准来进一步优化数据解释。此类标准包括(但不限于)用户偏好、系统设定、用户或其环境的学习到的特性和任何其它参数。例如,可设定用户偏好使得处理和分析将有利于基于智能ar的用户交互平台的最频繁用户。在一些实施例中,特定用户的特定数据/信息/知识可用于优化用户输入的解释。例如,当了解到特定用户具有严重的心脏病时,激动的用户移动的解释可改变到不同方向,因为急症现变为可能的解释。
在一些实施例中,在优化期间使用多个类型的输入数据。例如,如果传感器数据指示特定用户具有快速且不规则的心跳,那么急症变为更大的可能性。
步骤280,用户输入数据的解释可基于步骤278的额外分析来更新和/或修改。
步骤282,系统可向用户自动提示关于用户的健康状况的问题。如果确认急症,那么系统可自动联系应急团队且促使将用户运送到医疗机构。
步骤284,实时用户反馈可用于进一步更新或修改解释。如果用户确认特定事实,那么系统可促使执行额外或替代的动作。例如,用户可选择确认良好健康状况且拒绝请求医疗协助。
在一些实施例中,当未提供实时用户反馈时,系统在步骤288继续接收额外用户输入数据。例如,当用户输入用于在本地用户设备上或通过来自远程数据库的网络连接进行特定内容的搜索时,没有用户反馈可以被视为搜索结果的接受。系统可继续接收任何新的用户输入数据。
步骤290,当未接收到额外的用户输入数据时,过程完成。
步骤292,接收额外的用户输入数据,且过程可返回到步骤274以重新开始对新输入数据的分析和解释过程。
示范性实施例:基于内容匹配对ar相关要素的实时整合
一方面,本申请文件公开的是用于通过将输入数据与含有虚拟现实要素的ar相关输入数据整合来增强选定的输入数据的方法和系统。如本申请文件中所公开的,ar相关的输入数据可大致指代用于增强所选定的输入数据的任何数据/信息/知识(例如,所选定的输入数据可基于智能学习和分析从原始用户输入数据提取)。在一些实施例中,“ar相关的输入数据”和“虚拟现实要素”可互换使用。
在一些实施例中,ar相关的数据是虚拟现实要素。在一些实施例中,ar相关的数据包括关于虚拟现实要素及其与所选定的输入数据在整合之前的关系的额外数据/信息/知识。例如,增强可使用不同类型的虚拟现实要素发生,包括(但不限于)例如并不存在的非现实或幻想的要素(例如,虚构要素)、修改后的现实要素(例如,用户所位于在的实际环境的失真型式),以及未修改的实际现实要素(例如,用巴黎街道的照片或视频替代旅馆房间的背景-两者都是真实的但脱离现实场景)。在一些实施例中,虚拟现实要素可包括广告数据元素。在一些实施例中,虚拟现实要素可包括并非输入数据的一部分的其它外部数据(例如,外部音乐文件,或者实际采集的音频数据的实时音频或文本翻译)。
图3a说明在示范性的基于ar的实时图像和信号处理系统300中存在的要素。当现实对象物理上位于实际环境中(例如,方框302)时,捕获例如现实对象(例如,当前方法/系统的实施例的用户)的图像等数据。所捕获的图像随后实时处理以提取现实对象的图像信息(例如,方框304)。例如虚拟环境(例如,方框306)等虚拟现实要素可预先或与提取现实对象同时构造。所提取的现实对象随后与选定的虚拟环境整合。可包括广告要素和额外数据(例如,方框308)作为系统300中的虚拟现实要素的一部分。整个过程可在正在捕获现实对象的图像时实时发生,但在一些实施例中,可预先构造特定虚拟环境要素。
如本申请文件中所公开的,术语“数据”和“信号”可以可互换地使用。例如,其可包括与现实对象相关联的图像、音频、视频、文本、空间、地域或任何其它信息。其还包括元数据或反映现实对象的状态的其它嵌入式信息。其可进一步包括间接与现实对象相关联的数据,例如,反映现实对象的地理位置的例如图像或视频等信息。如本申请文件所公开的,“信号”和“数据”可包括内部和/或外部数据。在此,内部数据指代现实对象在其实际环境中的实时捕获期间采集的数据,包括视觉、音频和其它类型的信息。外部数据指代超出实时采集的内容的内容,包括但不限于:已经存储在本地用户设备上的数据、来自另一用户设备(通过网络连接可访问)的数据、存储在服务器上的数据(例如,包括存储在广告供应服务器上的广告要素),或使用网络采集实时获取的数据。本申请文件中所公开的大多数实例指代图像,然而,这不应以任何方式限制本发明的范围。
如本申请文件所公开的,“辅助信号”是除反映现实对象本身的数据或信号以外的数据或信号。辅助信号还可包括内部或外部数据。在一些实施例中,辅助信号包括非视觉信号,例如音频声轨或外部音乐文件。在一些实施例中,辅助信号包括可与所提取的现实对象、虚拟环境或最终整合的图像或视频合并在一起的广告要素。
在方框302处,使用例如具有例如相机等的图像/音频捕获设备的用户设备正捕获现实对象(例如,操作当前系统/方法的用户)的数据(例如,图像或音频信号)。在一些实施例中,相机是用户设备的组成部分。在一些实施例中,相机是可连接到用户设备的外部硬件部件。在一些实施例中,用户设备是具有网络功能的相机。优选地,相机是深度相机。在一些实施例中,图像/音频捕获设备包括一组相机。在一些实施例中,用户设备应装备有cpu/gpu处理器、相机、麦克风、显示器、扬声器、一个或多个传感器、通信单元和存储设备。其包括(但不限于)台式计算机、膝上型计算机、智能电话设备、个人数字助理、具有网络功能的相机、平板计算机、ar眼镜、ar头盔、vr眼镜、智能tv等。相机可以是3d相机、普通的rgb相机、ir相机、多光谱相机、高频谱相机、360度相机等。
在一些实施例中,现实对象是人,例如操作当前系统/方法的用户。在一些实施例中,现实对象是动物或物体。在一些实施例中,拍摄现实对象的多个图像。在一些实施例中,连续拍摄图像且所述图像形成视频。在所有实施例中,用于捕获现实对象的图像的计算机设备可由现实对象或计算机设备的用户访问。
如本申请文件中所公开的,当正捕获图像时,现实对象可处于任何环境中。对于用于图像捕获的环境没有特殊要求。例如,不需要均一或接近均一颜色的背景屏幕。在大多数实施例中,正如现实对象处于其实际物理环境中时那样捕获现实对象的图像。在一些实施例中,当现实对象正进行常规活动时拍摄现实对象的图像。
在方框304处,当正捕获图像时,提取现实对象的图像信息。在一些实施例中,通过基于现实对象和实际环境之间的特性的一个或多个差异使现实对象与其实际环境分离来执行提取。在一些实施例中,所述特性可以是视觉特性,包括但不限于空间特性、尺寸特性、形状特性、运动特性、颜色特性、光照度和反射特性、时间特性,或透明度特性、深度特性、材料特性,或其任意组合。
在一些实施例中,视觉特性包括三维空间特性。
在一些实施例中,所述特性可以是关于现实对象或实际环境的实时学习或预先学习的特征。实时学习或预先学习的特性包括(但不限于)例如颜色、形状、边缘、光反射、光照度、运动、深度、材料、对比度或其任意组合。
在一些实施例中,以逐图像的方式进行现实对象的提取。这还适用于以逐帧方式进行的视频提取。在一些实施例中,同时并行处理多个图像。
在方框306处,可提供例如虚拟环境等虚拟现实要素。在一些实施例中,可在图像提取乃至图像捕获之前构造虚拟环境。在一些实施例中,可在图像提取或图像捕获同时构造虚拟环境。
在一些实施例中,虚拟环境不同于实际环境。在一些实施例中,虚拟环境是实际环境的修改型式。在一些实施例中,用于构造虚拟环境的图像可以是修改后的图像特性,包括但不限于尺寸、形状、图像质量、颜色、视角、照明、视觉效应或其任意组合。
在一些实施例中,虚拟环境可与实际环境相同,但可改变一个或多个特性。例如,可处理实际环境以增强用于渲染虚拟环境的特定要素。此外,可修改实际环境以增强用于渲染虚拟环境的图像质量。在一些实施例中,更改实际环境的一个或多个要素的视觉特性,例如颜色、形状、尺寸、照明等。
在一些实施例中,虚拟环境可与实际环境相同,但改变了其与现实对象的关系。在一些实施例中,现实对象相对于其环境的尺度变为小得多或大得多,正如电影“爱丽丝漫游仙境(aliceinwonderland)”中一样。例如,在所捕获图像中正喝茶的人可在最终整合的图像中显示在茶杯内,而环境的其它要素保持不变。
在一些实施例中,服务器可将虚拟环境集合提供给用户。虚拟环境可基于其中呈现的主题而划分成不同类别。示范性主题包括(但不限于)自然、动物、太空、电影、建筑、文化、旅行等。用户对于特定类型的主题的选择可存储在用户偏好中。
在一些实施例中,虚拟环境包括图像。在一些实施例中,虚拟环境包括视频。在一些实施例中,可包括多个虚拟环境,每一虚拟环境在图像或视频整合期间视为单独要素。
在方框308处,广告要素和/或其它辅助数据可提供为虚拟现实要素的子类别。在一些实施例中,广告要素是所存在的唯一虚拟现实要素。在一些实施例中,广告要素与例如虚拟环境等其它虚拟现实要素整合。广告要素和/或其它辅助数据均可包括内部或外部数据。内部数据指代方框302处捕获的数据。外部数据可预先存储在本地设备上或服务器上。广告要素和/或其它辅助数据的示范性形式包括(但不限于)图像、音频、视频、文本、空间、地域或任何其它类型的信息。在大多数实施例中,广告要素由服务器提供。在一些实施例中,可预先创建广告材料。在一些实施例中,依据用户的请求实时创建广告材料。
在一些实施例中,广告要素和/或其它辅助数据包括例如音频信号等非视觉信号,例如捕获现实对象的图像信息时采集的声音信息。在一些实施例中,音频信号包括内部或现有音频信号或外部音频信号。在一些实施例中,从所捕获图像或视频获得内部或现有音频信号,且所述内部或现有音频信号有待进一步处理(例如,声音识别和后续语言翻译)。在一些实施例中,可处理视频的音频信号以实现增强的音响效果。例如,可移除环境噪声以增强现实对象(例如,电话会议期间的讲话者)的声音。在一些实施例中,特殊音响效果可添加到合乎需要的声音中。例如,声音可经渲染以具有三维中空效应以模仿回声环境中的声音。
在一些实施例中,广告要素可与产品或服务相关联。在一些实施例中,广告要素包括内部或现有音频信号或外部音频信号。在一些实施例中,广告要素可与现实对象相关联(例如,要素322或304)。例如,现实对象可佩戴或握持包括广告要素的产品。在一些实施例中,广告要素添加到虚拟环境306中。例如,广告要素可显示为虚拟环境的一部分。在一些实施例中,广告要素可为已实现整合的图像或视频。例如,广告要素可在整合期间视为除现有虚拟环境外的另一虚拟环境。在一些环境中,广告要素可在整合后添加;例如,在用户查看整合的图像或视频时。
在一些实施例中,基于本地存储在用户设备上或存储在服务器上(例如,作为用户配置的一部分)的用户偏好提供广告要素。在一些实施例中,由用户购物历史确定用户偏好。在一些实施例中,用户可特定地请求产品、服务、一种类型的产品或一种类型的服务。在一些实施例中,例如年龄和性别等一般用户信息可用作参考。在一些实施例中,可使用通常可用的趋势信息。
另外且有利的是,基于场景信息提供广告要素。场景信息包括(但不限于)通信场景、广告内容场景、演示场景等。例如,如果在公司的网络会议期间呈现广告,那么广告可包括关于公司的特定产业的产品和服务的内容。当广告待呈现为内嵌于例如网站或网页等公共论坛中的线上广告时,可考虑网站和/或网页的内容。如果此类网站和/或网页上的内容被认为是不当的,那么将不提供广告。不当的内容包括(但不限于)宗教狂热主义、恐怖主义、色情资料等。标准可由提供广告内容的服务器设定。在一些实施例中,广告商可设定针对其不想要与之相关联的内容的标准。
在一些实施例中,当多个广告商可提供相同或类似的合适内容时,可实施投标过程来选择广告内容。
在一些实施例中,外部音频信号可添加到现有音频信号中。例如,用户可选择在视频会议呼叫期间播放背景音乐。在一些实施例中,外部音频信号用于替代现有音频信号(例如,捕获现实对象的图像时采集的音频信号)。此类音频信号(外部或内部)可与系统中的任何要素相关联(例如,方框302、304、306和310)。在一些实施例中,音频信号与虚拟环境相关联。在一些实施例中,音频信号可添加到整合图像中。
在方框310处,所提取的现实对象和虚拟环境整合或组合以渲染虚拟环境内的现实对象的图像或视频。为实现整合,将限定所提取的现实对象和虚拟环境之间的关系。在一些实施例中,在图像提取和/或虚拟环境构造同时限定所述关系。在一些实施例中,一旦提取现实对象的图像信息和构造虚拟环境就限定了所述关系。
在一些实施例中,系统或用户提供对于所述关系的一般预定义指南。在一些实施例中,所述关系由系统基于来自所提取的现实对象和虚拟环境的信息而完全自动限定。在一些实施例中,用户可提供实时调整以在整合过程期间再限定或修改所提取的现实对象和虚拟环境之间的关系。
在一些实施例中,所提取的现实对象和虚拟环境之间的关系包括深度关系。例如,所提取的现实对象可部分或完全在虚拟环境的要素“前方”或“后方”。在一些实施例中,所提取的现实对象可部分或完全在相同虚拟环境的一个要素“前方”,但部分或完全在相同虚拟环境的另一要素“后方”。在一些实施例中,所提取的现实对象的全部或一部分之间的深度关系在时间上随不同图像之间的时间进程而改变。在一些实施例中,所提取的现实对象的全部或一部分之间的深度关系在空间上在相同图像中的不同元素上改变。
在一些实施例中,所提取的现实对象和虚拟环境之间的关系包括透明度关系。例如,所提取的现实对象可相对于虚拟环境的要素部分或完全透明。在一些实施例中,所提取的现实对象的全部或一部分之间的透明度关系在时间上随不同图像之间的时间进程而改变。在一些实施例中,所提取的现实对象的全部或一部分之间的透明度关系在空间上在相同图像中的不同元素上改变。
图3b说明了用于实行本申请文件中所公开的功能的示例性系统340。在此,多个用户设备(例如,328和330)通过网络332连接到服务器设备334。
在一些实施例中,系统340包括用户i/o模块312、本地数据库314、数据捕获模块316、数据处理模块318、智能模块320、增强模块322和交互式控制模块324。如本申请文件中所公开的,这些模块的功能(例如,i/o模块312、本地数据库314、数据捕获模块316、数据处理模块318、智能模块320、增强模块322和交互式控制模块324的功能)可与(图1b的)计算机设备102、用户设备220、用户设备240和服务器250(每一个都来自图2a)相关联的对应功能模块相同或类似。用户设备220、240和服务器250之间描述的相互关系和其任何变化还可应用到用户设备328、330和服务器334。应理解,只要可实现其功能模块的既定用途,就可作出替代和变化。
系统300的唯一功能可由图3b中展示的实施例中的智能模块320、增强模块322和交互式控制模块322的某些方面例示。
除与输入数据的智能解释相关的各种特征外,智能模块320还可促进以虚拟现实要素对选定输入数据的增强。如本申请文件中所公开的,在一些实施例中,智能模块320可执行虚拟现实要素的额外智能解释。例如,信息和/或知识可从虚拟现实要素提取或学习,且与所选定的输入数据相关的信息和/或知识组合使用。在一些实施例中,智能模块320可并行或依次处理用户输入数据和虚拟现实要素。在一些实施例中,与虚拟现实要素相关的信息和/或知识可事先或实时获得。在一些实施例中,与所选定的用户输入数据相关的信息和/或知识会影响虚拟现实要素的选择。在一些实施例中,信息和/或知识可以组合的形式同时从所选定的输入数据和虚拟现实要素提取或学习。
输入数据(例如,用于后续实时增强的实时图像数据)的综合、迭代和智能学习的额外细节可查阅图5a到5c的描述,以及提交于2017年7月31日,发明名称为“用于具有实时交互式控制的真实感人类全息增强现实通信的方法和系统(methodsandsystemsforphotorealistichumanholographicaugmentedrealitycommunicationwithinteractivecontrolinreal-time)”,申请号为15/665,295的美国专利申请,其全文以引用的方式并入本申请文件中。
在一些实施例中,增强模块322可从智能模块320选择ar相关输入数据(例如,虚拟现实要素)信息和/或知识。例如,所述信息和知识可用于所选定的输入数据和虚拟现实要素之间的内容匹配。内容选择和内容匹配的示范性实施例在图3c和3d中说明。
在一些实施例中,增强模块322可基于从所选定的输入数据和虚拟现实要素获得的信息和知识限定整合期间所述两者之间的相互关系。在一些实施例中,所选定的输入数据和虚拟现实要素的整合基于多层方法(例如,图3e)发生。
图3c说明了用于提供广告内容的示例系统200。例如,服务器342基于若干内容匹配参数确定哪些广告内容将通过网络350提供到计算机设备(例如,348或352)。此处的内容匹配参数包括,但不限于,例如,用于整合的所选定得和已处理得的用户输入数据和与其相关联的特性、与所选定的用户输入数据相关的信息和知识、基于ar的输入数据(例如,包括与虚拟现实要素相关的广告的虚拟现实要素)和与其相关联的特性、与基于ar的输入数据相关联的信息和知识、一个或多个用户偏好、一个或多个系统设定、先前用户历史数据、大数据、地理位置和与其相关联的趋势信息、一般趋势数据、交互式用户控制和任何其它场景参数。
在一些实施例中,服务器342将广告内容344存储在其本地数据库中。在一些实施例中,服务器342从另一服务器接收广告内容;例如直接从广告商接收广告内容。广告内容包括(但不限于)视频内容、音频内容、文本内容和任何其它形式的合适的内容。
在一些实施例中,服务器342包括广告提供模块346。广告提供模块346在计算机设备(例如,352和348)和广告内容344之间提供接口。在此,计算机设备可为个人计算机设备或例如交互式显示屏或布告板等专用设备。广告提供模块346识别用户偏好信息。此类用户偏好可本地存储在用户设备上或存储在服务器上(例如,作为用户配置的一部分)。在一些实施例中,例如年龄和性别等较一般的用户信息可存储在服务器上的用户配置文件中,而较私密信息存储在用户设备上本地。在一些实施例中,用户偏好由用户指定的信息、用户传记信息、用户行为信息、用户活动、用户心理状态、用户社交状态、用户社会经济状态、用户实时请求信息或其任意组合确定。在一些实施例中,通常可用的趋势信息可用于预测用户偏好。
在一些实施例中,例如日期和时间信息、通信场景、内容场景、广告商场景、地理位置场景、演示场景或其任意组合等基于场景的信息也可用于为查看者识别适当的广告内容。在此,查看者可主动寻求广告信息,或在参与例如视频会议或视频游戏等其它活动时被动地被呈现此类信息。
在一些实施例中,用户可特定地请求产品、服务、一种类型的产品或一种类型的服务。在一些实施例中,此类请求可实时作出或在存储在服务器342或一个或多个用户设备(例如,352和348)上的文件中事先指定。
在一些实施例中,广告商配置文件可创建和存储在服务器342上。例如,广告商可指定其不希望展示其广告的论坛或场所。此外,广告商可设定定价信息,该定价信息用于多个广告商确定为适于特定论坛时进行实时投标。如本申请文件中所使用的,论坛可以是网站、网页、视频会议平台,或其中可呈现本申请文件中所公开的图像和视频的任何形式的平台。
在一些实施例中,基于用户偏好和广告商配置文件选择广告内容。在一些实施例中,基于通常可用的趋势信息选择广告内容。在一些实施例中,在广告内容并入到最终整合的图像和/或视频中之前进一步处理广告内容。
如本申请文件中所公开的,使广告内容与用户设备匹配可以沉浸式和非侵入性方式实时发生。例如,细微的广告要素可在通信会话期间并入到基于ar的背景中。广告内容还可呈现为交互式体验的一部分;例如,作为计算机游戏或教育程序的交互式要素)。在一些实施例中,广告内容可相对于用户和通信的场景改变。在一些实施例中,可依据用户的请求提供广告内容。
如本申请文件中所公开的,可基于上文枚举的任何数目的内容匹配参数或其组合根据综合方法进行广告内容的内容匹配。在一些实施例中,可向不同内容参数指派不同权重。例如,可向用户偏好指派比从一般趋势数据或地理位置数据推断的信息更高的权重。
图3d描绘了基于用于广告的场景信息进行内容匹配的实例过程380。如本申请文件中所公开的整合的图像和视频用作用于内嵌广告要素的媒体。然而,基于场景的内容匹配广告方法不限于此些方法,且可适用于任何媒体。在此,示范性内容匹配过程根据所选定的内容匹配参数的所感知重要性而进行。本领域的技术人员可以理解,可作出变化,且可包括额外参数以促进内容匹配。步骤354,识别用户偏好信息。在此,可在内容匹配期间向用户偏好信息指派较高权重。用户偏好信息包括用户指定的信息、用户传记信息、用户行为信息、用户活动、用户心理状态、用户社会经济状态、状态、用户实时请求信息或其组合。例如,用户行为信息包括用户习惯、与系统的即时交互性等。用户活动包括购买活动、浏览活动、社交媒体活动等。例如,心理状态可通过面部表情和用户行为获得以了解用户是否开心、愤怒、沮丧等。可基于所感知的用户情绪状态而选择广告内容。社交状态包括婚姻状态、关系状态、与朋友的活跃或非活跃社交参与度、受欢迎度等。这些信息可从用户的社交媒体信息、用户偏好设定等获得。社会经济状态(ses)是某人的工作经验以及个体或家庭相对于其他人的经济和社交地位(基于收入、教育和职业)的经济和社会学组合总量度。
步骤356,识别场景信息。场景信息包括,但不限于,日期和时间信息、通信场景、内容场景、广告商场景、地理位置场景、演示场景或其任意组合。例如,当用户正进行公司视频会议时呈现给用户的广告内容可不同于当用户正通过视频会议与朋友或家庭成员聊天时呈现给相同用户的广告内容。此外,当用户进行视频游戏时呈现的广告内容可仍不同于任一先前指定的内容。
在一些实施例中,确认与潜在的呈现论坛相关联的场景以识别用于呈现特定类型的广告内容的论坛的适当性。例如,与幼童可访问的儿童开发内容相关联的网站将不显示对于未成年儿童不适当的任何广告内容。
步骤358,搜索含有广告内容的数据库以识别与所识别的用户偏好和场景信息匹配的内容。
步骤360,当仅识别出单一命中时,内容将被选择且并入到广告媒体中(例如,最终整合的图像或视频)。
步骤362,当识别出多个命中时,可启动投标过程来识别广告商。在一些实施例中,投标过程是基于定价信息的。在一些实施例中,广告内容的质量还可能影响是否可选择特定广告内容。
步骤364,当未识别出命中时,可使用额外信息来确定广告内容。此类额外信息包括,但不限于,诸如性别、年龄、地理位置等一般用户信息,和诸如趋势信息等与所述性别、年龄和地理位置相关联的通常可访问的信息。在一些实施例中,与特定位置相关联的天气和主要事件也可用作用于搜索含有广告内容的数据库的标准。
步骤366,进一步搜索含有广告内容的数据库以识别与所识别的用户偏好和场景信息匹配的内容。
步骤368,重复步骤360的方法:当仅识别出单一命中时,所述内容将被选择且并入到最终整合的图像或视频中。
步骤370,重复步骤362的方法:当识别出多个命中时,可启动投标过程来识别广告商。在一些实施例中,投标过程是基于定价信息的。在一些实施例中,广告内容的质量可能影响是否可选择特定广告内容。
步骤372,当未识别出命中时,系统可决定不呈现广告内容或任意地呈现任何广告内容。在一些实施例中,用户可请求随机广告内容。
在一些实施例中(图3d中未描绘),以实时翻译、特殊音效或音乐背景呈现选定的广告内容(例如,作为特定整合的图像和视频的一部分)。
在任一点处,用户可打开和关闭广告特征,或指定用于极其个人化广告体验的任何设定。此外,用户可提供实时反馈以请求特定广告内容或特定类型的广告内容。
如本申请文件中所公开的,内容匹配可实时发生。例如,广告内容可本地存储在基于智能ar的用户交互平台上;例如,在交互式显示屏或布告板或合适的用户设备上。在一些实施例中,可在基于智能ar的用户交互平台处通过到本地或远程主机的网络通信接收广告内容。
图3e提供逐像素整合过程390的示范性实施例的说明。在此,简化的所提取的现实对象392由三角形表示。简化的虚拟环境表示为394,具有网格图案的矩形,其中每一网格表示一像素。通过将现实对象392与虚拟环境394整合而获得的图像称为整合图像396。如所描绘的,现实对象392的特定像素变得不可见(位于虚拟环境394后方);参看,例如,像素396(x1,y1)。现实对象392的一些像素部分可见且部分不可见(部分位于虚拟环境394前方且部分位于虚拟环境394后方);参看,例如,像素396(x2,y2)。现实对象392的一些像素完全可见(位于虚拟环境394前方);参看,例如,像素396(x3,y3)。整合图像396中的一些像素完全缺乏来自现实对象392的任何信息;参看,例如,像素396(x4,y4)。
使用三层方法,像素396(x1,y1)具有由虚拟环境394中的像素限定的前层,且其中间层或背景层可填充有来自源自现实对象392的对应像素的信息。然而,因为前层的透明度值设定为0,所以前层后方的任何内容完全被虚拟环境394中的像素遮挡。由此,或者,可通过用来自虚拟环境394的像素信息限定其前层,同时将中间层或背景层的值设定为空来获得像素396(x1,y1)。
像素396(x2,y2)描绘来自现实对象392和虚拟环境394两者的信息。此像素可通过以下操作获得:用来自现实对象392的部分信息限定前层,用来自虚拟环境394中对应像素的信息限定中间层,且用来自现实对象392的部分信息限定背景层。再次,每一层的透明度级别设定为0,如此部分显示中间层且完全遮挡背景层。当不同层的透明度级别设定为非零值时,来自现实对象392和虚拟环境394的信息将遍及所述像素彼此混合。
像素396(x3,y3)与像素396(x1,y1)相反。其具有由现实对象392中的像素限定的前层,且其中间层或背景层可填充来自虚拟环境394中对应像素的信息。然而,因为前层的透明度值设定为0,所以前层后方的任何内容被现实对象392中的像素完全遮挡。由此,或者,可通过用来自现实对象392的像素信息限定其前层,同时将中间层或背景层的值设定为空来获得像素396(x3,y3)。
像素396(x4,y4)位于一区域中,该区域中现实对象392和虚拟环境394不重叠。在此情况下,现实对象392完全缺失。其可通过以下操作获得:用来自虚拟环境394中对应像素的信息限定三个层中的任一个,同时将剩余层级的值设定为空。
在一些实施例中,如上文所说,可同时针对多个像素进行并行计算。在一些实施例中,可通过识别非重叠区中的像素来简化计算。在一些实施例中,还可通过仅限定完全不透明的实心像素的顶层来简化计算。
在一些实施例中,所提取的现实对象包括可以任何组合在前层、中间层和背景层中的一个或多个之间划分的三维图像信息。在一些实施例中,虚拟环境包括可以任何组合在前层、中间层和背景层中的一个或多个之间划分的三维图像信息。
在一些实施例中,所提取的现实对象(例如,392)和虚拟环境(例如,394)之间的关系动态地改变。在一些实施例中,随着时间的过去在整合的图像之间发生此类动态改变。例如,现实对象392可移入和移出虚拟环境394。在一些实施例中,现实对象的至少一部分与虚拟环境的一个或多个要素交互。例如,这可在游戏设定中出现,其中现实对象(用户)可使用手势来使球弹跳离开虚拟环境中的墙壁或将球传递到虚拟环境中的玩家。
主动广告和被动广告
本申请文件中所公开的系统和方法可应用于建立主动和/或被动广告体验。
主动广告体验可与内容创建以及内容供给相关联。例如,房地产经纪人可通过将自己的实时图像插入到已有的房产照片中来创建传单,而不必重新拍摄照片。此外,此处的方法允许在整合图像时通过实时修改来增强房产的现有照片。
作为另一实例,用户可在本地用户设备上创建小预算广告,无论是否有服务器的帮助。例如,一家花店的店主可以在视频剪辑中把自己的特色插花的图像整合到她最喜欢的场景中。
用户还可在一个或多个外部服务器的帮助下,使用本申请文件中所公开的实施例创建图像或视频。图像或视频可供个人娱乐或作为一种语音形式(例如,为广告而包括)。如本申请文件中所公开的,广告要素可在服务器上执行的任何一个或多个方法步骤中添加。
对于广告提供,使用场景信息实时地创建目标广告材料给观众。例如,为了宣传奥运会,可以提供一个关于比赛的通用视频为虚拟环境。不同的现实对象,例如明星、演员、运动员、计算机设备的普通用户等,可以拍摄他们自己的个人视频,随后将个人视频与虚拟环境整合以创建尽可能多的宣传视频。
在一些实施例中,可事先拍摄广告视频的一部分,在查看者请求材料时进行实时整合。例如,当一个中国人点击奥运会官方网站上的链接时,服务器检测该人的地理位置和可能其它信息,并专门为该中国人创建一个视频,该视频显示中国运动员在视频中作为特写,且不同的与中国相关的要素将融入到这个通用视频中。视频将以中文呈现,例如使用该人熟悉的人的声音。当一个美国人点击相同链接时,将实时创建一个不同视频,为该美国人提供不同的观看体验,视频中展示与前述不同的运动员、不同的与美国相关的元素,使用英语旁白,旁白者为美国人所熟悉。
如上所述,在进行其他活动如视频会议或视频游戏时,广告可以被动地呈现。虽然进行视频会议或视频游戏等活动的用户并不主动寻求广告信息,但是本申请文件所公开的基于场景的内容匹配方法以非侵入性方式用嵌入式广告元素提供无缝相关体验。传统广告通常被认为浪费时间并会引起观众的不愉快反应,相比之下,本申请文件所公开的被动广告可以是沉浸式和互动式的,从而使体验变得有趣。本申请文件所公开的被动广告可以大量应用并能产生巨大收益。
例如,在视频会议之前或期间,用户可以选择夏威夷作为虚拟环境的主题选项。该系统又可以识别可以用作虚拟环境或作为虚拟环境的一部分的许多可能的广告元素。例如,过去用户最喜欢的目的地是毛伊岛。毛伊岛最受欢迎的地点和活动可以作为虚拟环境的一部分来呈现。此外,如果用户喜欢冲浪,而且夏威夷的另一个岛有比毛伊岛更好的冲浪体验,那么这另一个冲浪地点的照片或视频就可以呈现给用户。广告元素的选择也可以基于视频会议的场景来进行。如果用户正在与朋友和家人交谈,则可以呈现更多针对家庭的地点或活动的虚拟环境,例如,如果用户有两个孩子,虚拟环境就可以将更多的儿童喜欢的活动的图像或视频包含在内。在一些实施例中,可以根据他们各自与毛伊岛上用户最喜欢的酒店的距离来选择目的地。
通常,可以提供多种类型的广告内容。特定类型的内容的最终选择可以在竞价过程中决定。内容适当和定价最佳的广告商可能会中选。
对在与商业伙伴的视频会议期间选择夏威夷作为虚拟环境的主题选项的同一个用户,将呈现更安静的广告内容。例如,可以选择夏威夷的一个安静的森林、安静的沙滩的前景作为虚拟环境的一部分。同时,将有许多可能的选择。最终选择也可以在竞价过程中决定。可以选择具有适当内容和最佳定价的广告商。
在另一个示例中,用户可以被动地参与合成广告材料。例如,到达机场的旅者可以选择通过本申请文件所公开的系统来查看新目的地的视频素材。旅者可以与视频素材中的元素交互。旅者可以选择创建和保存反映这种有趣互动的图像和/或视频。在一些实施例中,广告材料可以嵌入图像和/或视频中。在一些实施例中,没有广告材料嵌入图像和/或视频中,但是整体体验本身可以被认为是广告。这样的体验可以为任何目的而设计,或适合任何行业的需要。例如,化妆品公司可以创建一个平台,用户可以在平台上虚拟地试用不同的化妆品。化妆品的效果可以生成为虚拟环境,并与用户合并以创建佩戴化妆产品的用户的修改后的图像或视频。类似地,服装公司可以根据用户偏好智能地向用户展示服装选项。服饰可被创建为虚拟环境,并与用户合并以创建穿着服饰的用户的修改后的图像或视频。
图4a描绘了用于基于多级智能实时智能学习和处理(例如,信息提取和知识学习)进行基于实时ar的通信的示例性系统。示例性系统400包括通过因特网418连接到远程智能服务器424的计算机设备420和计算机设备422。如本申请文件中所公开,可在单一设备上或多个设备上进行数据的智能学习和处理。
在一些实施例中,系统400包括用户i/o模块402、本地数据库404、数据捕获模块406、数据处理模块408、智能模块410、增强模块412、表示模块414和压缩模块416。如本申请文件中所公开的,这些模块的功能(例如,用户i/o模块402、本地数据库404、数据捕获模块406、数据处理模块408、智能模块410和增强模块412的功能)可与(图1b的)计算机设备102、用户设备220、用户设备240和服务器250(每一个都来自图2a)以及用户设备328、用户设备330和服务器334(每一个都来自图3b)相关的对应功能模块相同或类似。
用户设备220、240和服务器250或328、330和服务器334之间描述的相互关系和其任何变化还可应用到用户设备420、422和服务器424。应理解,只要可实现其功能模块的既定用途,就可作出替代和变化。
系统400的唯一功能由i/o模块402、表示模块414和压缩模块416的某些方面例示,如下文所述。
在一些实施例中,用户i/o模块402可接收对用户设备的用户输入,且使用文本、音频、视频、运动和/或触觉输出机制呈现来自另一设备的输出。例如,i/o模块402包括一个或多个数据采集部件,例如相机、麦克风、键盘、鼠标、触敏屏幕、一个或多个传感器等。在一些实施例中,i/o模块402还用于检测和跟踪眼睛移动、面部表情等。在一些实施例中,i/o模块402或用户设备420进一步包括一个或多个传感器设备,用于采集例如心跳、血压、方向、温度、运动、海拔高度、压力、近程、加速度等数据。
在一些实施例中,i/o模块402还可向用户呈现音频、视觉、运动和/或触觉输出。例如,i/o模块402在显示器上向设备420的用户显示整合的图像或视频。在一些实施例中,i/o模块402包括一个或多个输出部件,例如显示器(可为触敏式)、扬声器、触摸显示屏和一个或多个传感器等。在一些实施例中,输出设备允许用户接收例如触摸等物理体验(例如,用户可接收远程握手或接吻)。这些功能促进有效通信。
可通过表示模块414进行数据类型的变换和数据形成,表示模块还可被称作“数据表示模块414”或“模块414”。如本申请文件中所公开的,表示模块414可使用数据参数表示一种或多种类型的数据。例如,数据参数可包括文本、一个或多个代码、一个或多个数字、一个或多个矩阵、一个或多个图像、一个或多个音频信号、一个或多个传感器信号,或其任意组合。例如,特定ar输入数据(例如,特定虚拟环境)可用数字代码表示。用户的表情可表示为一系列数字或矩阵。用户的手势可由使用特定针对用户的手势模型的手势模型参数来表示。
如本申请文件中所公开的,不同数据参数可用于表示相同信息。特定形式的数据参数可由若干因素确定,这些因素包括,但不限于,文化背景、语言差异、个人习惯、个体差异等。例如,来自美国的用户的典型初次问候语可由词语“hello”或“hi”表示,后跟短语“nicetomeetyou”,以及向远程通信设备处的另一用户的友好挥手致意。英国用户的相同问候语可包括短语“howdoyoudo?”和友好的点头致意。在此,表示问候语的数据参数包括口头问候语的音频信号和手或头移动的图像。
在一些实施例中,基于文化差异,显著不同的数据参数可用于表示ar数据。例如,来自美国的用户与来自日本的用户在正式商务会议上使用根据本发明的方法/系统交流。日本的用户代表传统公司,因此美国的用户指示系统根据日本习俗定制所述交流。或者,系统可基于提供到系统的场景和背景信息自动建立设定以促进正式会议。在此,信息:词语“hello”或“hi”、短语“nicetomeetyou”、友好挥手致意和可选的背景信息可用于导出知识层级的数据;例如系统可自动学习会议的场景和目的。随后,可基于此信息和知识产生实时ar数据。在实时ar数据中,知识和信息可由不同于与输入数据相关联的数据参数的数据参数表示。例如,系统可使用表示美国用户的虚拟形象来通过根据标准日本习俗鞠躬而创建美国用户问候日本用户的动画。在此,实时ar数据显著不同于原始数据输入:挑选完全不同形式的数据参数来表示相同信息和知识。如本申请文件中所使用的,“原始数据”和“用户输入数据”可互换使用。
表示模块414可将任何层级的数据表示为恰当格式,包括但不限于包括完全或部分增强的数据、信息数据、知识数据、ar输入数据等。例如,经增强的数据可在压缩以用于数据传送之前分离成多个文件(例如,图4b中的步骤446-449或图4c中的步骤416-420)。在一些实施例中,表示模块414可包括数据构造或重建功能,其可改变特定数据的数据参数形式或类型,例如以适合特定类型的硬件设计(例如,3d显示到2d显示,或反之亦然),或更好地向特定受众(例如,具有视觉、音频和其它形式的生理缺陷的人们)呈现数据。
在一些实施例中,设备420包括压缩模块416,其还可被称作“数据压缩模块416”或“模块416”。如本申请文件中所公开的,数据经压缩以达到最佳压缩率,同时保持数据完整性。无损压缩和有损压缩两种方法都可用于数据压缩,例如由系统或用户指定。示范性无损方法包括(但不限于)lempel-ziv(lz)方法、lempel-ziv-welch(lzw)方法、lzx(lz77系列压缩算法)、霍夫曼编码、基于语法的代码、概率建模、基于小波的方法等。
在有损数据压缩期间,一些数据损失是可接受的。在此,数据包括原始数据或用户输入数据、信息乃至知识,这取决于其相应的关联性。从数据源丢弃非必需的细节可节省存储空间。有损数据压缩方案通过研究关于人们如何感知所讨论的数据而设计。例如,人眼对于亮度的细微变化比其对于颜色的变化更敏感。jpeg图像压缩在某种程度上通过舍弃非必需的信息位而工作。在保持信息和缩减尺寸之间存在对应折衷。若干流行的压缩格式采用这些感知的差异,包括音乐文件、图像和视频中使用的格式。
在一些实施例中,数据类型在有损数据压缩期间用作参数。在有损音频压缩中,心理声学方法用于移除音频信号的非可听(或不太可听)的部分。常常利用更加专门的技术执行人类语音的压缩;语音译码或话音译码有时区分为与音频压缩分离的规范。不同的音频和语音压缩标准在音频译码格式下列出。话音压缩在因特网电话中使用,例如,音频压缩用于cd分离(cdripping)且由音频播放器解码。
在一些实施例中,无论什么数据类型,都可应用选择性压缩。例如,选择性压缩方法可组合无损和有损数据压缩方法。在此,不同压缩方法根据其相应重要性而应用于不同数据位。对于需要完全预留的数据,将应用有损压缩方法,包括例如lempel-ziv(lz)方法、lempel-ziv-welch(lzw)方法、lzx(lz77系列压缩算法)、霍夫曼编码、基于语法的代码、概率建模、基于小波的方法等。例如,当虹膜扫描用作一种验证形式时,几乎所有信息将驻留在图像的虹膜部分(眼睛的彩色部分)内。压缩数据,可以保持眼睛的完整性,同时脸乃至整个人的剩余部分可以大幅度压缩。例如,除脸以外的任何东西甚至可完全移除。组合方法允许在相关数据中保持关键特性,同时减小不相关数据的负担。
在一些实施例中,压缩模块416还可执行各种层级处的数据解压缩,包括完全或部分增强的数据、信息数据、知识数据、ar输入数据等。
如本申请文件中所公开的,数据(例如,分析的数据或结果)可在数据获取模块406、数据处理模块408、智能学习模块410、增强模块412、表示模块414、压缩模块416和此处未提到的任何其它功能模块之间共享。
在一些实施例中,可应用预定义的用户偏好和系统设定来指定或限制本申请文件中所公开的功能模块中的任一个的功能。
这些功能模块的更多细节可查阅与图4b-4d相关的描述。
图4b描绘了用于在计算机设备上执行数据处理的示范性实施例。示范性实施例430包括用于执行数据获取/处理、信息提取、知识学习、数据增强、数据表示、数据压缩、数据传输等的多个步骤。此处的许多步骤可由结合图4a描述的功能模块实行。在此,计算机设备可为本地设备或服务器。
步骤432,单个地或组合地捕获图像数据以及任可选的音频和传感器数据。示范性数据捕获单元包括(但不限于)麦克风、相机(例如,2d、3d、ir等),以及一个或多个传感器。如本申请文件中所公开的,传感器设备采集心跳、血压、方向、温度、运动、海拔高度、压力、距离、加速度等数据。如本申请文件中所公开的,传感器可记录和存储用户或传感器所位于的环境的测量值。
步骤434,视觉数据处理单元处理相机数据以用于场景理解和对象检测、跟踪及识别。例如,视觉数据包括(但不限于)使用2d、3d、4d、彩色、近红外(nir)数据、红外ir数据、热感、多光谱和/或高频谱图像或其组合的面部表情表、手势、身体语言跟踪和识别。此单元还可基于脸、手势、体型、手掌、虹膜、巩膜等进行身份识别。在一些实施例中,可包括文本数据作为视觉数据。
步骤436,音频数据处理单元处理来自一个或多个麦克风的麦克风数据,用于音频数据理解和/或音频噪声缓解。此单元还可基于话音模式进行身份识别。在一些实施例中,特定音频数据不提供有意义的信息,且可视为背景噪声。此音频数据可视为场景。
步骤438,传感器数据处理单元处理传感器数据,用于环境理解、用户生物状态监视和/或人类行为理解。
在一些实施例中,每一功能数据单元单独地和个别地处理输入数据。例如,多类型数据可由两个不同的单元同时或循序处理。在一些实施例中,一个或多个功能数据单元可组合成一个功能数据单元。
步骤440,数据融合单元基于用户偏好和系统设定将音频数据、视觉数据和传感器数据融合在一起。在数据融合期间,整合多个数据源以产生比由任何个别数据源提供的信息更恒定、准确和有用的信息。实例数据融合是将视觉数据和音频数据融合在一起以分析用户情绪。在另一实例中,系统可进一步融合视觉数据、音频数据和传感器数据(例如反映用户的生物状态的数据;例如心跳、血压等)以提供对用户情绪更精确的分析。
步骤442,在多个层级执行智能学习或处理。例如,在步骤442-1,基于一个或多个标准从原始数据或融合的数据提取必需的信息,一个或多个标准包括,例如,用户偏好、系统设定、整合参数、原始数据的对象或场景的特性、交互式用户控制或其任意组合。在一些实施例中,还可使用基于大数据的标准。例如,系统可提取表示用户表情信息的用户面部肌肉移动。对于另一实例,系统可使用话音量值改变和音调改变提取用户语音重点。可选地,在此步骤,所提取的信息(实时学习或现有)可用于根据一个或多个标准基于实时数据、ar输入数据和额外数据创建增强现实数据,其中,一个或多个标准包括用户偏好、系统设定、来自实时数据的对象或场景的特性或其任意组合。
同样在步骤442-2,可进一步分析先前所获得的信息以确定知识。如所描述的,从所提取信息中学习知识可基于一个或多个标准,包括例如用户偏好、系统设定、整合参数、原始数据的对象或场景的特性、交互式用户控制或其任意组合。在一些实施例中,还可使用基于大数据的标准。
步骤444,知识与先前信息组合将用于增强实时数据(经处理的或原始)、ar输入数据(444-1)和额外数据以根据一个或多个标准创建实时ar数据,其中,一个或多个标准包括例如用户偏好、系统设定、整合参数、原始数据的对象或场景的特性、交互式用户控制或其任意组合。在一些实施例中,还可使用基于大数据的标准。在一些实施例中,仅将知识用于增强。在一些实施例中,仅将信息用于增强。
如本申请文件中所公开的,任何合适的数据可用作ar输入数据(444-1)。例如,其可为实时数据或预先创建的数据。ar输入数据(444-1)可以是现实的或包括虚拟要素。
在一些实施例中,在数据增强之前,可排除或添加一些数据。例如,可排除关于用户隐私的数据。可排除特定数据以获得较好压缩结果。或者,可添加额外数据以创建特定效应(例如,表现为冷酷、有趣、神秘、友好、严肃等)。还可添加数据以促进较好的对话参与。如本申请文件中所公开的,可基于用户偏好、系统设定、对象/场景的特性、信息、知识和/或交互式用户控制等任何原因排除或添加数据。例如,基于知识/信息的增强单元将从相机数据中排除背景场景,且出于隐私保护原因使用用户所选定的背景场景替代真实背景信息。在另一实例中,增强单元可移除用户的脸和身体,同时使用预先选择的虚拟形象来表示用户,但为了娱乐而将用户的面部肌肉移动、眼睛移动、手势、身体移动等复制到虚拟形象中。在再一实例中,信息增强单元可移除用户的真实话音信息,但保持用户的语音音调和量值的变化连同语音内容以实现较好的对话参与。在又一实例中,基于知识/信息的增强单元将执行用户的脸/身体/话音/背景场景等的实时变形。
除以上实例外,增强单元的一个重要功能是:其可以以一个形式提取实时信息,且将所述实时信息变换为另一类型的信息以用于显示器、音频和/或传感器控制。例如,一个单元可提取用户的心跳变化且使用该心跳变化作为另一单元中的一些传感器的控制信号,或将该心跳变化显示为虚拟世界中人的身高。
步骤446,数据表示单元使用数据呈现来自步骤314的实时ar数据。作为一实例,用户的表情可表示为表示表情模型参数的一系列数字/矩阵。在另一实例中,如果用户选择增强场景背景,那么背景场景可以是系统中的场景数字。在再一实例中,用户的手势可由使用用户的手势模型的参数表示。在又一实例中,用户身份可在系统识别之后通过使用id号表示。在一些实施例中,经增强的数据可分离成多个文件以为后续动作(例如数据压缩和传输)做准备。例如,实时ar数据的视频/音频部分可呈现为既有视频又有音频信号的mpeg文件。或者,实时ar数据的视频/音频部分可在单独的视频和音频文件中表示。类似地,传感器相关数据可在单独文件中表示。
步骤448,数据压缩单元压缩数据以获得最佳压缩率,同时保持数据的完整性。无损压缩或有损压缩两种方法可用于基于设计需要进行数据压缩,例如lempel-ziv(lz)方法、lempel-ziv-welch(lzw)方法、lzx(lz77系列压缩算法)、霍夫曼编码、基于语法的代码、概率建模、基于小波的方法等。在有损数据压缩期间,数据的一些损失是可接受的。在此,数据包括原始数据、信息乃至知识,这取决于其相应关联性。从数据源丢弃非必需的细节可节省存储空间。在一些实施例中,可通过组合无损和有损数据压缩方法来使用选择性压缩方法。在此,不同压缩方法根据其相应重要性而应用于不同数据位。对于需要完全预留的数据,将应用有损压缩方法,包括例如lempel-ziv(lz)方法、lempel-ziv-welch(lzw)方法、lzx(lz77系列压缩算法)、霍夫曼编码、基于语法的代码、概率建模、基于小波的方法等。例如,当虹膜扫描用作一种验证形式时,几乎所有信息将驻留在用户的眼睛图像内。数据可经压缩使得保持对于眼睛的完整性,同时脸乃至人的剩余部分可很大程度上压缩。例如,除脸以外的任何东西甚至可完全移除。组合方法允许在相关数据中保持关键特性,同时减小不相关数据的负担。步骤449,经压缩的数据可使用适当的通信协议(例如使用数据传输单元)传递到适当的接收器设备和云端。在一些实施例中,数据还可经加密以确保安全变换。
如本申请文件中所公开的,每一个步骤本身可为包括许多轮次的分析或处理的迭代过程。由此,许多步骤可在实时同时并行过程中实行。例如,视觉、音频和传感器数据的处理(例如,步骤434、436和438)可同时发生。并且,例如,一旦在442-1处提取一些信息,就可开始442-2处的知识学习,同时连续接收正同时提取的额外信息。
在一些实施例中,数据处理的所有方面可在一个设备中通过安全处理器、安全通道和受保护的存储设备进行,其中受保护的存储设备包括加密以确保数据安全。在一些实施例中,数据处理的一部分可通过安全处理器、安全通道和安全的存储设备而进行,其中安全的存储设备包括加密以确保安全性,同时处理的其它部分可通过具有普通安全级的处理器、通道和存储设备进行。在一些实施例中,数据处理的所有方面可通过具有普通安全级的处理器、通道和存储设备而发生。如本申请文件中所公开的,数据处理包括原始数据、信息、知识及其它的处理。
图4c描绘用于在计算机设备上执行数据处理的示范性实施例。示范性实施例400包括用于执行数据处理、信息提取、知识学习、数据增强、数据表示、数据压缩、数据传输等的多个步骤。此处的许多步骤可由结合图4a描述的功能模块实行。在此,计算机设备还可为本地设备或服务器,优选地为服务器。
步骤452,计算机设备(例如,服务器)从另一设备(例如,用户设备)接收数据。如本申请文件中所公开的,所接收的数据包括原始数据、经部分处理的数据、经完全处理的数据(包括经增强的数据)或其任意组合。示范性实施例400说明其中计算机设备处接收的数据已经在不同设备上增强的情境。在一些实施例中,所接收的数据解压(例如,先前经增强的数据)为适于在服务器上处理的适当格式。如果数据经加密用于安全传递,那么在此单元中数据将被解密。解压缩可由压缩模块(例如图4a的元件416)执行。
步骤454,所接收的数据保存在计算机设备(例如,服务器)上的数据库中。大数据信息也保存在服务器数据上,其可用于促进深入信息提取和深度知识学习。
步骤456,可解封所接收数据中的现有信息/知识。例如,表情模型参数可变换成表情信息。在另一实例中,背景数字还可变换为选定的背景场景,例如,由发送数据的设备的用户先前选择的。在一些实施例中,手势模型参数可变换成手和手臂位置及形状,且反之亦然。如所公开,此步骤的功能可由表示模块(例如,图1b的元件160和图4a的元件414)执行。
步骤458,与来自先前步骤的音频、视频、传感器数据相关联的解封的现有信息/知识可用一个或多个数据参数重建,所述数据参数常常涉及一种或多种类型的变换。例如,用户面部表情信息、手势信息和肢体移动信息可连同用户的音频信息和用户的传感器信息一起重建。在一些实施例中,经重建的数据可包括在集中智能理解,例如在步骤462。
步骤460,可访问大数据资料用于后续处理。在一些实施例中,可实时检索大数据资料。在一些实施例中,大数据资料可保存在计算机设备上的数据库中。在一些实施例中,来自步骤452和454的所接收的数据也可保存在数据库中。在一些实施例中,所接收的数据和大数据资料可以在后续处理中使用;例如用于深入信息提取和知识学习。
步骤462,基于所构造的信息/知识、所接收的数据和大数据的更加集中的智能理解可根据一个或多个用户偏好和/或系统设定实行。在此,可通过利用大数据的可用性和例如服务器等设备的高计算能力实现较完整和深入的智能理解。在此,可在步骤462-1基于现有信息从先前经增强的数据中提取新信息。类似地,在步骤462-2,可基于与先前经增强的数据相关联的现有知识学习新知识。例如,对于智能通信应用,智能信息消化单元(例如,被实施为图1b的元件140或图4a的元件4108)可确定用户意图、用户的情绪状态(开心、悲伤、疼痛、正常等),或用户的行为状态(正常、异常等)。在另一实例中,对于远程医疗诊断应用,智能信息消化单元可基于当前信息和过去信息以及健康和患病群体的其它健康状况信息进行用户健康状况的深入分析。在又一实例中,对于国际商业通信应用,所述单元可提供智能信息以缓解文化差异:例如,如果日本用户在交流期间避免眼神接触,那么所述单元可向非日本用户告知在日文化中避免眼神接触是尊重的表现。同时,所述系统可向日本用户告知在交流期间进行眼神接触是美国文化。在再一实例中,如果在商业会议期间已经使用了在参与交流的另一用户的特定文化环境下可能被感知为具有侵犯性的不当语言,那么系统自动警告用户。作为一种补救或缓解形式,系统可允许用户或另一用户(例如,对于交流具有优先控制权的监管员)停止传输具有侵犯性的内容。
在一些实施例中,智能信息消化单元还可执行自动语言翻译和行为翻译。例如,其可自动将英文翻译为中文,且反之亦然。其还可将美国用户的“hi”自动翻译为日本用户的例如“鞠躬”等行为,同时将日本用户的鞠躬翻译为“hi”或其它形式的问候语。在多方群组交流中,相同语言或行为可基于交流的其它参与者的文化背景而翻译为不同形式。
步骤464,基于知识/信息的增强单元(例如,被实施为图1b的元件150或图4a的元件412)可通过应用从步骤462学习的信息和知识增强所接收的数据和额外的ar输入数据(例如,464-1)。在此,还可通过利用大数据的可用性和例如服务器等设备的高计算能力执行数据的增强。在一些实施例中,步骤464应用机器学习和模式识别方法来执行智能数据增强。例如,在先前步骤中将美国用户的“hi”变换为“鞠躬”之后,增强单元将例如使用表示美国用户的虚拟形象增强手势、肢体移动和用户的表情以执行“鞠躬”。例如,在增强期间,可构建用户的3d模型并在问候语中使用用户鞠躬的3d场景。
步骤466,数据表示单元将经增强的信息数据翻译为表示不同类型的数据(例如,文本、数字、矩阵、图像、信号等)的数据参数。如本申请文件中所公开的,数据表示单元可被实施为例如图1b的元件160或图4a的元件414。
步骤468,数据压缩单元压缩经变换的数据以获得最佳压缩率,同时保持数据完整性等。如本申请文件中所公开的,数据压缩单元可被实施为图1b的元件160或图4a的416。
步骤469,数据传输单元使用适当的通信协议将经压缩的数据传递到一个或多个适当的接收器单元。在一些实施例中,经压缩的数据可传递回到发送器设备。数据传递单元还可对数据进行加密用于安全传输需要。尽管先前未说明,人们可以理解,数据传输单元可利用例如图1b的网络通信模块118的功能实施于用户设备或服务器的任一个上。
如本申请文件中所公开的,每一个步骤可本身为包括许多轮次的分析或处理的迭代过程。由此,许多步骤可在实时同时并行过程中实行。例如,保存数据(例如,步骤454)、访问大数据(例如,步骤460)和解封所接收的数据(例如,步骤456)可同时发生。并且,例如,一旦在462-1处提取一些信息,就可开始462-2处的知识学习,同时连续接收正同时提取的额外信息。
在一些实施例中,数据处理的所有方面可在一个设备中通过安全处理器、安全通道和受保护的存储设备进行,其中受保护的存储设备包括加密以确保数据安全。在一些实施例中,数据处理的一部分可通过安全处理器、安全通道和安全的存储设备而进行,其中安全的存储设备包括加密以确保安全性,同时处理的其它部分可通过具有普通安全级的处理器、通道和存储设备进行。在一些实施例中,数据处理的所有方面可通过具有普通安全级的处理器、通道和存储设备进行。如本申请文件中所公开的,数据处理包括原始数据、信息、知识及其它的处理。
图4d描绘用于在计算机设备上执行数据处理的示范性实施例。示范性实施例470包括用于执行数据处理、信息提取、知识学习、数据增强、数据表示、数据压缩、数据发射等的多个步骤。此处的多个步骤可由结合图1b、3b和4a描述的功能模块实行。在此,计算机设备还可为本地设备或服务器,优选地为服务器。
步骤474,在计算机设备处从另一设备(例如,用户设备或智能服务器)接收数据。在一些实施例中,所接收的数据可基于接收器设备的确认而解压为一个或多个适当的格式。如果数据经加密用于安全传递,那么数据可在此步骤解密。
步骤476,所接收的数据(例如,经解压/解密的数据)可基于一个或多个用户偏好和系统设定翻译为适当的信息。例如,如果计算机设备并不具有3d显示能力,那么在此步骤3d信息可恰当地变换成2d可显示信息。在另一实例中,计算机设备的功能可能有限,使得大量处理、分析和操作在另一设备(例如服务器)上发生。当用户更喜欢具有轻微能力的本地设备时,这是合适的。此步骤执行的功能使系统能够适应用户正使用的特定硬件单元。在一些实施例中,此处的计算机设备可为接收器设备,从而形成与发送器设备(例如,图4b)和服务器设备(例如,图4b和4c)的完全通信循环。
步骤478,可基于接收器的偏好、接收器设备的设定、接收侧上对象/场景的特性、接收者的交互式控制来进一步增强数据。例如,在远程医疗通信会话中,发送者是医生,且接收者是儿童。儿童将其健康水平表达和理解为其心仪的玩具熊的愉悦程度。玩具熊越高兴,他就越健康。系统可将医生评估的健康水平增强为他手上的玩具熊的愉悦程度。例如,屏幕可展示健康例行检查之后的开心的熊,且当儿童遭受例如发热、疼痛、咳嗽等不适状况时为熊提供舒缓的话音以提供安抚。
步骤480,所述方法可决定可用以呈现经增强信息的格式和设备。例如,此系统可决定使用显示器呈现所有图像相关信息,且使用扬声器为盲人呈现所有音频相关信息。对于另一实例,系统可为失聪者将所有音频信号重建为视觉信号。在一些实施例中,此处的功能性还可由表示模块执行。在一些实施例中,重建功能可在先前增强步骤实施。
步骤482,经重建的信息和知识可翻译为具有适当格式的适当数据。
步骤484,视觉数据可变换成恰当格式且递送到例如显示器或屏幕以供显示。步骤486,音频数据可变换成恰当音频格式且递送到例如扬声器。
步骤488,传感器数据可变换成合适的控制信号且递送到对应传感器。例如,可递送振动信号且所述振动信号导致与计算机设备相关联的一个或多个马达振动。对于另一实例,所述单元传递运动控制信号可被递送且致使与计算机设备相关联的一个或多个设备移动。
如本申请文件中所公开的,每一个步骤可本身为包括许多轮次的分析或处理的迭代过程。由此,许多步骤可在实时同时并行过程中实行。例如,步骤484到488的数据解封和传送可同时发生。实际上,在一些实施例中,数据的传送必须在时序上协调以创建特定所要效果。例如,人说出hi的视觉和音频数据应与传送握手感觉同时发生。并且,例如,一旦在步骤478已经增强一些数据,就可开始步骤480和482的数据重建和/或数据表示,同时连续接收来自步骤478的额外数据。
在一些实施例中,数据处理的所有方面可在一个设备中通过安全处理器、安全通道和受保护的存储设备进行,其中受保护的存储设备包括加密以确保数据安全。在一些实施例中,数据处理的一部分可通过安全处理器、安全通道和安全的存储设备进行,其中安全的存储设备包括加密以确保安全性,同时处理的其它部分可通过具有普通安全级的处理器、通道和存储设备进行。在一些实施例中,数据处理的所有方面可通过具有普通安全级的处理器、通道和存储设备进行。如本申请文件中所公开的,数据处理包括原始数据或用户输入数据、信息、知识及其它的处理。
如本申请文件中所公开的,智能、迭代和交互式处理可在多个设备上同时进行以促进基于ar的通信。在每一设备上,用户可设定用户偏好,这里的用户偏好是关于隐私、优选语言和优选数据格式或设定的。数据在用户设备之间直接或通过中间服务器设备传输。所接收的数据可经表示以实现接收设备上的优化效应。
图5a-5c说明数据的智能学习可以迭代方式进行。在此,数据包括输入数据、经部分处理的数据、所提取的对象或场景,甚至ar输入数据(未图示)。
图5a描绘用于产生基于ar的实时数据(例如,图像数据)的实例方法。示范性实施例500说明如何在对象或场景被提取并有待进一步处理之前通过误差补偿和自适应学习实时处理实时图像数据。具体地说,实时自适应学习可基于本申请文件中所公开的任何智能学习和处理方法。智能学习可实时进行且为迭代和交互式的。在一些实施例中,实施例500还说明如何并行提取现实对象和人类对象以便执行更精确的人类对象提取,同时保持人类对象和实时所提取的一般对象之间的更精确的关系。所提取且经进一步处理的数据随后与ar输入数据组合以基于投影参数产生基于ar的实时图像数据。在此,针对人类对象,处理三个单独种类的学习:一个在步骤552执行,其中人类对象视为一般对象;第二个在步骤556执行,其中执行基于专门设计的人类对象的学习和过程;第三个在步骤558执行,其中学习和识别人类手势、肢体移动和面部表情。在步骤536的投影过程中,提取数据融合并集成到投影过程中。
在步骤502,实时捕获图像数据,例如通过数据捕获模块58使用相机设备实时捕获。所捕获的图像数据可保存在本地数据库中或直接传递到不同功能模块上以进行处理。在一些实施例中,正捕获的捕获对象包括例如音频数据或传感器数据等额外类型的信号。
步骤504,所捕获的数据经历处理以改进数据质量。在此步骤,数据经历特殊处理以补偿误差。例如,3d相机不能提供关于深色对象的准确深度信息。在另一实例中,3d相机不能提供关于快速移动对象的准确深度信息。有时,深度相关误差可导致未知的深度值。有时,误差可导致区域中一个像素到另一像素(或一个丛集小群组到另一丛集小群组)的显著深度值变化。在一些实施例中,此步骤的处理由误差补偿模块实行。例如,误差补偿模块可基于这些特性检测相机深度误差,且接着通过基于对象特性、区域连续性特性或对象移动特性通过弥合空隙来补偿深度误差。例如,一些红外相机不能提供明亮反射对象的准确数据。因此,图像热图可具有未知值或任意值改变区域。误差补偿模块可基于对象特性或区域连续性补偿红外信息。例如,一些rgb摄像机可在相机感测到一些环境光改变且执行对于输出图像的自动动态颜色/强度调整时具有显著颜色/强度改变。然而,连续时间图像中的颜色/强度的不一致常常可能导致提取过程中的误差。在步骤504,误差校正模块可通过数据的时间连续性检测此种相机误差。误差校正模块可通过基于场景特性以及基于时间和特殊的连续性补偿由自动相机动态范围改变而引起的不必要的改变来补偿此种相机误差。
在一些实施例中,经误差补偿的图像可用作进一步实时对象学习的参考。注意,误差补偿结果将不会改变原始实时数据。事实上,经误差补偿的图像保存为单独数据集。在一些实施例中,经误差补偿的图像可用作中间暂时性结果用于下一迭代处理,且不永久地保存在系统中。此步骤的目的主要是数据质量补偿;例如通过补偿假的、不精确的或错误的数据来改进后续处理。
步骤510,来自处理步骤504的数据可经受实时自适应学习。实时学习可包括多个方面;例如对象学习512、对象识别514或图像分割516。
步骤512,将实时对象学习方法用来学习实时数据的特性以实时检测对象和场景。在一些实施例中,此步骤的处理由实时智能学习模块执行。例如,实时学习包括基于对象和其环境在图像内的相对位置、对比度、照明、颜色、热特性等的差异识别对象和其环境之间的边界。在一些实施例中,使用具有深度功能的相机采集图像数据,且深度信息用于将对象划分为背景和前景用于实时学习。从在此,实时学习模块可学习跨越连续时间线的对象改变。在一些实施例中,基于深度的方法可通过3d相机深度信息获取。在一些实施例中,使用连续视频图像可构造对象的3d深度。在一些实施例中,实时学习模块可学习实时数据中的关键特征点,且从所述关键特征点中学习对象特性。实例的基于关键特征点/线/区域的学习包括(但不限于)sift(尺度不变特征变换)方法或类似sift的方法(例如,surf(加速稳健特征)、盖伯特征点等)。另一实例基于关键特征点和线特征的方法为slam(即时定位与映射)或类似slam的方法。在一些实施例中,可使用深度结构学习。有时,可能具有挑战性的是,使用深度结构学习方法解释学习的是什么、什么特性较重要,和/或学习的特性将如何反映对象的物理特性。如本申请文件中所公开的,所学习的参数称为学习的对象特性。在一些实施例中,多个识别方法可组合以改进识别结果。
步骤514,可分析经处理的图像数据以用于对象识别。步骤514和512的不同之处在于:在步骤512仅学习对象特性,而在步骤514,分析(例如,分类、聚类和/或识别)来自步骤512的学习到的对象特性。注意,在一些实施例中,步骤512和步骤514可组合以构成对象学习和识别过程或仅简单地称为对象识别过程。
如本申请文件中所公开的,步骤514的对象识别包括使对象(包括人)从环境中分离。在一些实施例中,对象识别包括基于使数据特性与对象特性匹配而将多个区域分组为候选对象区域。在一些实施例中,在步骤512学习得到的特性可用于使潜在的数据与用于对象识别的候选对象匹配。例如,sift或类似sift的特征点可用于识别对象。在一些实施例中,简单的基于区域的分离连同无监督学习可用于执行连续时间图像之间的对象匹配。在一些实施例中,slam或类似slam的特征可用于使实时数据中的对象匹配。在一些实施例中,对象识别可包括人类对象的检测。在一些实施例中,对象识别还可包括使特定特性与人的身体部位相关联。例如,人的手可常常与移动相关联,且往往会与其它对象/人和环境交互。由此,与例如脸、胸部或躯干等其它身体部位相比,手的轮廓更可能形成人的边界。在一些实施例中,离线数据(例如,已知对象的现有模式)用于促进对象识别。在一些实施例中,红外相机或近红外相机可用于提供实时数据的热图式图像,其可提供信息以使人类对象与环境投影分离,因为人类对象常常具有体温范围,且人类皮肤具有可用于使人类对象与其它对象分离的特殊红外或近红外光吸收/反射特性。同时,不同种类的对象可具有红外或近红外光下的不同特性,其可用于使实时获取的数据特性与对象特性匹配。在一些实施例中,深度结构学习可以在对象识别中使用。在一些实施例中,多个识别方法可组合以改进识别结果。
步骤516,经处理的图像数据可进行图像分割处理。例如,来自现实环境的对象/人可基于识别结果和/或预设标准实时分割成多个部分或片区。例如,预设标准可包括,但不限于,用户偏好、系统默认设定和/或基于来自用户的交互式反馈实时学习的标准。例如,有可能在步骤514获得识别出的人类对象。图像分割可帮助将数据的分析区分优先级。例如,包括完整深色背景的部分或片区可接受快速潦草的分析,而包括所关注对象的部分或片区将接受较精确和详细的分析。
在一些实施例中,实时自适应学习510为迭代和交互式过程。在一些实施例中,来自先前时间点的学习结果可应用于后续时间点。在一些实施例中,来自一个方面的学习结果会影响分析的另一方面的结果。
在一些实施例中,步骤502到520可并行执行且影响彼此的结果。关于迭代和交互式方面的额外细节在图5b中描绘,且将在本发明的后续部分中描述。
图像误差补偿块504将使用来自方框510的实时学习结果来补偿相机误差。同时,图像误差补偿结果可以在对象学习步骤512、识别步骤514和图像分割步骤516中使用。在一些实施例中,相机误差校正步骤、对象学习步骤512、对象识别步骤514和图像分割步骤516也可包括到相同迭代过程中。例如,在第n次迭代中,相机误差校正可以是状态n。此校正的结果可以在步骤/过程510的下一迭代学习中使用,且用于提供第(n+1)次学习状态,该第(n+1)次学习状态用于第(n+1)次迭代中的相机校正,以产生相机误差校正状态n+1。在一些实施例中,可包括相机误差校正步骤504,作为不同于对象学习步骤512、对象识别步骤514和图像分割步骤516的迭代过程。例如,在第n次迭代中,相机误差校正可以是状态n。此校正的结果将在510的接下来的x(x>1)个迭代学习中使用,且用于提供第(n+1)次学习状态,该第(n+1)次学习状态用于第(n+1)次迭代中的相机校正,以产生相机误差校正状态n+1。对于另一实例,在第n次迭代中,相机误差校正可以是状态n。此校正的结果可在针对另外y(y>1)个迭代的相机误差补偿步骤内重复迭代,且输出n+y个迭代结果,用于步骤510中接下来x(x>=1)个学习迭代中的实时自适应学习510,且用于提供接下来的学习状态用于相机校正。
在一些实施例中,对象学习步骤512、识别步骤514和图像分割步骤516聚焦于学习背景环境的特性。
步骤552,可从经处理的和学习得到的图像数据中提取对象或场景。例如,可通过基于综合特性的机制(包括基于人工智能的机制)使现实对象的图像信息与其实际环境分离而从图像中提取现实对象。基于综合特性的机制识别现实对象的特定特性和实际环境的特定特性之间的一个或多个差异。例如,特性可包括且不限于图像中捕获的现实对象或实际环境的视觉特性、现实对象或实际环境的实时学习的特性,或关于现实对象或实际环境的预先学习的特征。在一些实施例中,视觉特性可包括,但不限于包括:空间特性、尺寸特性、形状特性、运动特性、颜色特性、光照度和反射特性、时间特性或透明度特性、深度特性、材料特性,或其任意组合。在一些实施例中,空间特性包括三维空间特性。在一些实施例中,步骤552和步骤516可显著不同。例如,步骤552处理提取对象的边界的更多细节以确保提取准确性,例如通过考虑边界特性、区域连续性、提取参数等。步骤556还可不同于步骤516;例如在一些实施例中,步骤556通过大量考虑人类边界特性、人类区域连续性和人类提取参数而处理提取人类对象的边界的更多细节以确保提取准确性。在一些实施例中,步骤552和步骤556可显著不同。例如,步骤556的方法聚焦于人类对象特性,且基于诸如身体、头、脸、头发、手等专门学习的人类相关特性以更详细的水平执行学习、误差补偿和提取。
在一些实施例中,实时学习的特性包括,但不限于:颜色、形状、边缘、光反射、光照度、曝光、亮度、阴影、高光、对比度、运动、深度、材料或其任意组合。在一些实施例中,预先学习的特征还包括,但不限于:颜色、形状、边缘、光反射、光照度、曝光、亮度、阴影、高光、对比度、运动、深度、材料或其任意组合。在一些实施例中,实时学习的特性可能由于学习过程的非线性而不能容易地映射到对象物理特性,当使用深度结构学习方法时尤其如此。
如本申请文件中所公开的提取过程可在一个轮次中或多个轮次中完成。例如,粗略提取可跟踪现实对象的轮廓,而精细提取可细化分离现实对象和其实际环境的边缘。在一些实施例中,一个或多个精细提取轮次还可识别实际上为环境的一部分的现实对象的轮廓内的区域,且随后从现实对象中移除该区域。
在一些实施例中,在步骤552基于提取参数提取对象/场景,这里的提取参数可来自预定义用户偏好或系统设定,例如特定深度区内的对象、位于特定空间区域内的对象、具有特定特性的对象、特定种类的对象、特定对象、具有与实时数据中的人类对象的特定关系的对象等。
在一些实施例中,精细提取可达到子像素层级。在一些实施例中,在适当分离对象边界的过程中执行边缘检测。示例边缘检测方法是索贝尔边缘检测(sobeledgedetection)、坎尼边缘检测(cannyedgedetection)、基于模糊逻辑的边缘检测方法等。
在一些实施例中,对象提取基于步骤510学习得到的背景环境的提取的减法。换句话说,在这些实施例中,步骤510中的自适应学习可聚焦于学习背景环境(场景),且步骤552首先基于步骤510的学习结果提取背景环境,且接着从所提取的背景环境减去真实数据以获得所提取的对象区域。
值得注意的是,在步骤552,对象可包括一个或多个人类对象。然而,因为步骤552使用一般化学习方法(或通用(one-for-all)提取方法),所以所提取的人类对象可常常极其粗略且不满足准确性要求。
步骤556,进一步处理所提取的数据以识别诸如人类对象的脸、身体部位等更详细的特征。在此,可使用人类对象的已知特征的离线数据。在一些实施例中,脸和/或身体部位检测是基于对象识别结果的。在一些实施例中,步骤556和步骤552可显著不同。例如,步骤556的目标是聚焦于人类对象提取处置。如本申请文件中所公开的,步骤556和步骤552两者可能够访问原始实时数据和自适应学习结果。然而,步骤556将针对人类对象应用图像误差补偿。可理解,步骤552可包括针对所有对象的通用提取方法;而在步骤556实施更加细化且更加集中的人类对象提取方法。为进一步确保人类对象提取的准确性,可在步骤556基于每一人类对象部位的特性和图像误差补偿的需要不同地对待人类对象的身体的每一部位的提取。例如,对于脸/头来说,头发常常是提取中的最具挑战性部分。例如,包括头发边界特性的头发特性在人类头部的提取过程中专门加权。此外,学习过程中的图像误差补偿结果将在人类头发相关误差补偿中特别地强调。对于另一实例,与头发相比,人类的手是用于准确提取的另一具挑战性部分。这常常是因为手的快速移动。在一些实施例中,学习过程中的图像误差补偿结果可在运动相关补偿中特别地强调。本申请文件中所公开的特殊人体部位的更详细学习和提取比现有通用提取方法优越得多。因此,本申请文件中所公开的方法和系统处理起来更精确且更快以满足实时全息ar通信中的速度和准确性需求。
步骤556,基于人类对象提取参数提取一个或多个人类对象,所述人类对象提取参数可来自预定义用户偏好或系统设定,例如特定深度区内的人类对象、位于特定空间区域内的人类对象、具有特定特性的人类对象、特定种类的人类对象、特定人类对象、具有与实时数据中的人类对象的特定关系的对象等。
步骤558,实时数据经受手势的分析和身体语言识别,包括面部表情。在步骤558,原始实时数据、来自步骤510的自适应实时学习结果和来自504的图像误差补偿均可被访问。身体语言常常与特定文化背景相关。在此,需要关于文化背景的额外信息来解释身体语言。例如,印度人在与某人意见一致时摇晃她的头。在一些实施例中,递归神经网络用于学习和识别手势和身体语言。在一些实施例中,基于时域和空域特征点的方法用于学习和识别手势和身体语言。实例基于特征点的方法为sift、surf、hog(方向梯度直方图)等。在一些实施例中,来自步骤556的脸/身体部位提取结果用于改进手势和身体语言学习和识别。
在一些实施例中,来自步骤558的手势和身体语言识别的结果用于进一步细化步骤556中一个或多个人类对象的脸/身体部位的提取。
步骤530,从诸如手势和身体语言识别信息(例如,在步骤556获得的)等经处理的图像数据进一步解释移动和/或投影信息。所述移动和/或投影信息可用于限定所提取的对象和(例如,步骤532)所接收的ar输入数据之间的关系。换句话说,在步骤530,分析人类行为要素以为系统接受交互式控制和来自用户的反馈做准备。在一些实施例中,所述解释可包括使手势和/或身体语言(包括面部表情)与系统可识别的手势和/或身体语言匹配,以解释其含义。在一些实施例中,人工智能方法可用于逐步地学习和理解用户行为,以具有人类行为的智能解释。在一些实施例中,由系统在每一解释之后向用户请求确认,以确保解释的准确性和/或执行基于强制执行的学习。
步骤532,接收ar输入数据。如所公开的,ar输入数据可包括虚拟环境,以及实际环境或场景、人或对象的更改型式,或不是正实时捕获的数据或信号的一部分的任何其它数据。在其中ar输入数据与正捕获的数据或信号不相关的情况下,步骤532独立于其它处理步骤且可在步骤502到530中的任一个之前执行。在此,ar输入数据可以是系统预先产生的图像、视频、3d数据等。ar输入数据还可为从另一计算机/相机发送的数据。
步骤534,可基于用户偏好或系统设定接收投影输入数据。在一些实施例中,投影参数可以是深度相关的,例如所述参数可提供所提取的对象、人类对象和ar输入数据之间的绝对或相关深度关系。在一些实施例中,所提取的对象、所提取的人类对象和ar输入数据可具有其自身的内部深度信息。在一些实施例中,投影参数可包括透明度关系,通过透明度关系为所提取的对象、所提取的人类对象和ar输入数据设定透明度参数。在一些实施例中,投影参数可包括基于位置关系的方法,其中其设定绝对或相关空间关系以及所提取的对象、人类对象和ar数据的尺寸。在一些实施例中,投影参数可包括基于视觉关系的方法。在一些实施例中,所述方法基于不同视角设定所提取的对象、人类对象和ar数据之间的绝对或相关视觉投影关系。在一些实施例中,投影参数可包括来自步骤534的人类交互式控制信息。在一些实施例中,投影参数可包括两个或两个以上上述参数的组合。
步骤536,从实时数据中提取的信息与ar输入数据整合,以基于投影参数产生2d/3d以及静止/时间系列数据投影。在此,通过基于预设系统标准、实时学习的移动/投影信息或来自手势/身体语言的交互式控制命令将输入数据和所提取的数据一起投影到空间中而获得投影。例如,开发新颖的基于3层的逐像素投影方法将对象极快地投影到相机视图(参看,例如,图3e)。
步骤538,产生整合的或投影的数据。如本申请文件中所公开的,图5a中所说明的过程实时且连续执行。可以理解,输出步骤538也实时且连续执行,使得实时且连续地处理和呈现在步骤502捕获的原始数据。
在一些实施例中,步骤538输出的所提取的对象和人类对象还可用作在步骤510中的下一学习迭代的输入。在一些实施例中,还可在步骤538提供输出背景环境,例如通过从实时数据减去所提取的对象和人类对象,且将其用作在步骤510中的下一学习的输入。在一些实施例中,步骤538可基于连续地累积学习输出学习得到的背景环境,作为下一学习迭步骤510的起始材料。可使用许多不同学习方法。在一些实施例中,学习方法可以是先前学习得到的背景环境和新学习得到的背景环境的简单加权相加。在一些实施例中,可应用深度学习。
图5b描绘用于产生基于ar的实时图像数据的迭代实时学习的实例步骤和系统。示范性实施例540说明从在步骤542首先接收实时数据时到在步骤576输出对象结果时的数据学习。
步骤542,在实时迭代学习过程的开始处捕获实时数据。所捕获的数据可包括,但不限于:音频、视觉和传感器数据。
在一些实施例中,相机误差补偿步骤544、数据处理步骤546和对象处理步骤248可共同地形成初始实时数据处理级550。例如,在对象处理步骤548期间,深度结果可用于将对象大致分离为背景和前景。在一些实施例中,可检测到深度分离的可能误差,且随后基于已知深度特性进行校正。在一些实施例中,对象或场景可划分成片区,且对象或场景的特性可基于颜色/强度特性从所述片区单独地学习。在一些实施例中,对象或场景可划分成片区,且对象或场景的特性可基于红外光响应的差异从所述片区单独地学习。在一些实施例中,对象或场景可基于学习结果划分成片区。
在一些实施例中,对象处理模块用于实施对象处理,特别是人类对象处理。对象处理模块可通过使现实对象的图像信息与其实际环境分离而从图像中提取现实对象。基于来自实时学习模块的信息实现分离。在一些实施例中,使用由数据捕获模块126捕获的原始图像。在一些实施例中,由数据捕获模块捕获的图像首先经处理来改进数据质量(例如,通过数据处理模块进行的降噪)。如本申请文件中所公开的,对象提取可在正连续采集图像数据的同时与数据处理、误差补偿、实时学习同时进行。
所述提取利用基于综合特性的机制,包括基于人工智能的机制。基于综合特性的机制识别现实对象的特定特性和实际环境的特定特性之间的一个或多个差异。例如,特性可包括且不限于视频剪辑中捕获的现实对象或实际环境的视觉特性、现实对象或实际环境的实时学习的特性,或关于现实对象或实际环境的预先学习的特征。在一些实施例中,视觉特性可包括,但不限于包括:空间特性、尺寸特性、形状特性、运动特性、颜色特性、光照度和反射特性、时间特性或透明度特性、深度特性、材料特性,或其任意组合。在一些实施例中,空间特性包括三维空间特性。
在一些实施例中,实时学习的特性包括,但不限于:颜色、形状、边缘、光反射、光照度、曝光、亮度、阴影、高光、对比度、运动、深度、材料或其任意组合。在一些实施例中,预先学习的特征还包括,但不限于:颜色、形状、边缘、光反射、光照度、曝光、亮度、阴影、高光、对比度、运动、深度、材料或其任意组合。学习方法可包括线性回归、决策树、支持向量机、k-最近邻域、k-均值、贝叶斯网络、逻辑回归、基于特征点的学习、神经网络、隐马尔可夫链或其任意组合。所述学习可受监督、部分受监督或无监督。
在一些实施例中,可使用具有多个隐蔽层的深度结构学习。深度学习可受监督、部分受监督或无监督。示范性深度结构学习方法可包括,但不限于:深度神经网络、深度信念网络、递归神经网络、这些深度结构的混合,以及深度结构与其它模式识别方法的混合。归因于其深度结构和极大程度的非线性特性,有时解释学习的内容、什么特性较重要、学习的特性将如何反映对象的物理特性是具有挑战性的。在此,从深度学习中学习得到的参数也称为对象特性。
如本申请文件中所公开的提取过程可在一个轮次中或多个轮次中完成。在一些实施例中,对象处理模块134在实行一个或多个额外轮次的精细提取之前首先执行粗略提取轮次。例如,粗略提取可跟踪现实对象的轮廓,而精细提取可细化分离现实对象和其实际环境的边缘。在一些实施例中,一个或多个轮次的精细提取还可识别实际上为环境的一部分的现实对象的轮廓内的区域,且随后从现实对象移除该区域。
在一些实施例中,对象处理模块可将所提取的对象信息与增强现实输入数据组合,以产生实时ar增强型数据内容。如所公开的,ar输入数据包括虚拟现实信息或从所捕获的数据处理得到的信息。用于将所提取的信息与ar输入数据组合的过程将结合图5a和5b更详细阐述。在图像数据的情况下,组合过程也被称为图像整合。在一些实施例中,用户设备包括单独的整合模块。如结合图3e详细说明的,整合可逐像素进行以实现效率和准确性。
在一些实施例中,对象处理模块可创建和修改ar输入数据(例如,虚拟环境)以用于后续图像整合。例如,对象处理模块可基于存储在本地数据库中的一个或多个图像构造虚拟环境。对象处理模块还可通过网络连接从服务器接收预先构造的虚拟环境。虚拟环境可以是二维或三维的。虚拟环境可包括虚拟环境所基于的图像中不存在的特征。例如,对象处理模块可通过修改对应图像而更改或调整虚拟环境中的一个或多个要素。在一些实施例中,基于现实对象的一个或多个特征作出此类修改或调整使得所提取的现实对象和虚拟环境可更高效地整合。示范性修改或调整包括,但不限于:缩放比例、改变方向、改变形状、改变颜色、图像质量调整(例如,曝光、亮度、阴影、高光或对比度)等。所述修改或调整可在虚拟环境内的个别要素上局部或整个虚拟环境上全局作出。在一些实施例中,虚拟环境可不同于实际环境。在一些实施例中,虚拟环境可与实际环境相同,其中虚拟环境中的一个或多个要素经修改用于后续图像整合。
如本申请文件中所公开的,过程可在多个功能模块上同时执行。来自一个特定步骤的结果能够影响一个或多个其它步骤的结果。例如,信息(例如,分析的数据或结果)可在数据捕获模块、数据处理模块、实时智能学习模块、误差补偿模块和对象处理模块之间共享。例如,在误差补偿之后,由数据捕获模块获得的图像数据影响来自实时学习模块的结果,这随后可能影响来自对象处理模块的结果。例如,与对象学习、识别和图像分割相关联的结果可因为改进的图像质量而得以改进,这将改进对象提取的质量。
在一些实施例中,这些步骤可以迭代方式执行直至满足预先定义的标准。例如,一旦处理误差降到阈值以下从而指示经处理的数据的收敛,步骤550就将完成。此类数据细化技术在所属领域中广泛地知晓。关于误差补偿、数据处理和对象处理(包括例如对象学习、对象识别和图像分割)的额外细节可查阅结合图1b和5a的描述。
步骤552,产生实时学习结果(可与术语“学习结果”互换使用,除非另外指出)。在一些实施例中,直至满足阈值才在实时实时/处理初始阶段创建输出对象结果。所述阈值可能具有时间限制。例如,可在约半秒内采集的数据已进行实时学习之后产生输出对象结果。时间限制可由系统或用户例如从数秒到数分钟或几十分钟任意设定。在实践中,所述系统/方法可包括产生和传输经增强的数据之前的初始校准步骤。在一些实施例中,初始校准步骤期间学习得到的信息可保存且用于优化后续操作,包括例如缩短使用本申请文件中所公开的方法/系统的下一实时通信会话的校准步骤。
步骤558,系统继续实时接收数据(例如,在时间点tn)。
步骤560,实时学习步骤(例如,图像误差补偿步骤562、数据处理步骤564和对象处理步骤566)应用于在步骤558接收的数据。如本申请文件中所公开的,图像误差补偿步骤562、数据处理步骤564和对象处理步骤566可并行执行,且来自一个步骤的结果能够影响一个或多个其它步骤的结果且以迭代方式进行。关于误差补偿、数据处理和对象处理(包括例如对象学习、对象识别和图像分割)的额外细节可查阅结合图1b和5a的描述。
步骤554,先前学习结果应用于实时学习步骤560。例如,在图像误差补偿步骤562、数据处理步骤564和/或对象处理步骤566中的任一个中。
步骤556,离线学习的对象数据(例如,用于身份识别的数据)可应用于实时学习步骤560。例如,在图像误差补偿步骤562、数据处理步骤564和/或对象处理步骤566中的任一个中。另外或可选地,预定义用户偏好或系统设定可应用于实时学习步骤560。在一些实施例中,在误差补偿562期间,深度分离的可能误差可被检测到且随后基于已知相机特性来校正。在数据处理564期间,进行降噪。在对象处理步骤566期间,深度结果可用于将对象大致分离为背景和前景。在一些实施例中,在对象处理步骤566期间,对象或场景可划分成片区,且对象或场景的特性可从片区单独地学习。
在一些实施例中,实时学习步骤560可迭代地执行。例如,一旦处理误差降到阈值以下从而指示经处理的数据的收敛,步骤560就将完成。此类数据细化技术在所属领域中广泛地知晓。
在一些实施例中,在实时学习步骤560,所提取的对象和人类对象信息从先前时间步骤接收且用于此步骤的学习。在一些实施例中,在步骤560,背景环境信息从先前步骤或时间点接收且用于当前步骤背景信息和对象信息的学习。
步骤570,产生经更新的学习结果。如本申请文件中所公开的,从先前学习结果(例如,在时间点tn-1)和离线学习的对象数据(例如,用于身份识别的数据)导出更新的学习结果。在一些实施例中,通过使用当前学习结果和先前学习结果(例如,时间点tn-1)两者更新学习结果。通过这种方式,可缓和对于学习结果的噪声影响。同时,系统可较好地适应改变。
步骤572,经更新的学习结果用于促进对象或场景的提取。如图1b和5a中所公开的,对象学习、对象识别和图像分割中的任一个或全部可在提取期间应用。在一些实施例中,诸如用户偏好或系统设定等额外信息可应用于对象或场景的提取。在一些实施例中,还在对象处理572期间使用基于深度的分离结果。
步骤574,系统检查是否正在下一时间点采集数据,如果正接收更多数据,那么方法返回到步骤558以重新开始实时学习和处理。
当不再接收更多数据时,方法在步骤576结束。在一些实施例中,产生最终对象结果以总结所述方法。
图5c描绘用于产生基于ar的实时图像数据的总体实例过程。示范性实施例580概述关键步骤582到598,其大多数已经结合图1b、5a和5b详细描述。
步骤582,实时接收数据(例如,图像、声音和/或传感器数据)。
步骤584,处理实时图像数据来改进数据质量,例如通过降噪。
步骤586,实行实时对象学习,例如通过对象学习、对象识别和图像分割。
步骤588,可基于来自步骤584和586的结果执行诸如相机和图像误差补偿等硬件和软件调整。在一些实施例中,也可针对软件部件执行误差补偿。例如,依赖于初始学习结果,系统可依赖于校准结果而增加或减少校准步骤(例如,图5b中的步骤552)的持续时间。
步骤590,基于实时学习结果和额外信息(例如,先前学习结果、离线数据、用户偏好或系统设定)从经处理的数据中提取对象或场景。在一些实施例中,图像数据中的深度相关信息可用于将对象与其背景大致分离。
步骤592,进一步处理所提取的对象或场景;例如图5a中的步骤5556到530中所公开的处理。额外细节可查阅例如与对象处理相关的描述。
步骤594,组合经处理的对象或场景与ar相关输入数据。如本申请文件中所公开的,ar输入数据可与实时图像数据相关或不相关。这两个类型的数据连同其它额外数据(例如用于翻译的额外音频或文本数据,或广告相关数据)的组合或整合可如图5a所公开一样执行。结合图3e详细地描述多层和逐像素整合过程。例如,图像数据中的深度相关信息可用于将对象大致分离为多层:部分分离为背景且部分分离为前景。
步骤596,实行实时数据投影/整合。在一些实施例中,投影数据实时传递到另一设备(例如,用户设备或服务器)。
步骤598,当系统停止接收实时图像数据时,终止所述过程。
图6a和6b提供额外细节以说明图3e中展示的多层整合过程。
图6a描绘用于从所提取的数据和ar输入数据产生基于ar的实时图像数据的实例步骤。示范性实施例600展示所提取的对象或场景数据和ar输入数据如何通过逐像素过程分离成多层(例如,3层)且整合/投影。本申请文件中所描述的功能可由例如对象处理模块执行。
步骤602,接收一个视野的ar输入数据和所提取的对象/场景。还接收限定所提取的对象/场景和ar输入数据中的对应像素之间的关系的运动/投影关系(例如,如结合图5a所描述的)。
步骤604,ar输入数据和所提取的对象/场景分离成三个层。在一些实施例中,分离在逐像素过程中进行。在一些实施例中,分离通过像素群组进行。例如,在特定像素群组中,ar输入数据大部分分离成前景层。在另一像素群组中,所提取的对象/场景可分离成前景层。
步骤606,从第一层(例如,像素的前景层)开始整合/投影。例如,基于整合关系分配特定像素的ar输入数据和所提取的对象/场景,以填充所述像素。在一些实施例中,像素中的总填充率被定义为1。在一些实施例中,填充率被定义为不透明度。
步骤608,系统检查特定像素是否被完全填充。如果是,那么方法向前跳到步骤616并产生完整像素输出。在一些实施例中,如果来自前景或前景组合的像素具有不透明度1(即,α=1),那么所述像素将被视为完全填充。过程将跳到步骤616。如果像素未完全填充(或具有小于1的填充率),那么过程移动到步骤610,步骤610执行第二层(例如,中间层)的整合/投影。
步骤610,组合第一层(或前景)数据与第二层(或中间层)数据。
步骤612,系统检查特定像素是否被完全填充。如果是,那么方法向前跳到步骤616并产生完整像素输出。在一些实施例中,来自前景和中间层组合的像素具有填充率或不透明度1(即,α=1),像素被完全填充。处理将跳到步骤616。
如果像素未被完全填充(或具有小于1的填充水平),那么过程移动到步骤614,步骤614执行第三层(例如,背景层)的整合/投影。默认地,像素在三层整合之后将是完整的。步骤616,产生完整像素。
作为步骤618,系统确定是否存在额外像素在特定视野中保持空或不完整。如果存在,那么方法在步骤620继续以接收新像素的ar输入数据、所提取的对象/场景和运动/投影关系,且回到步骤604以重新开始整合过程。
如果无像素为空,那么过程在步骤622结束。
图6b描绘用于从所提取的数据和ar输入数据产生基于ar的实时图像数据的实例步骤。在此,示范性实施例650展示可如何针对每一像素实现相机视图。
步骤652,对于视野中的每一像素,查看像素的视角基于例如实时学习结果、用户偏好或系统设定分离成不同相机视角。
步骤654,检测到与给定像素相关联的相机视角,且指派适当的视角给所述像素。再次,所述指派可基于例如实时学习结果、用户偏好或系统设定。
步骤656,应用基于多层的实时投影方法(例如,图3e和5b)以产生具有特定相机视角的整合像素。
步骤658,系统确定图像数据中是否存在额外像素。如果不存在额外像素,那么方法跳到步骤662。如果存在,那么过程进行到步骤660。
步骤660,接收新像素的数据,且方法返回到步骤652。针对新像素重复步骤652到658。
步骤662,产生特定视角的完全投影数据。
值得注意的是,尽管图5a为了方便绘图而提供输出图像的2d视图,但投影的描述可适用于2d和3d输出。大体来说,显示器可分离成2d显示器和3d显示器。在此,2d显示器可包括平面屏幕显示器、曲面屏幕显示器或立体显示器。一些2d屏幕显示器可通过3d眼镜展示3d效果,或为裸眼展示3d效果。然而,这些在本专利申请案中仍称为2d显示器,因为查看者正查看相同视角(2d或3d视图)。现有视图产生方法通常执行3d操坐作,随后在显示产生步骤执行3d到2d的投影。对于2d屏幕3d视图,其仅在左眼和右眼之间添加视差以为人脑构造2d创建合成两个稍微不同的2d视图。然而,这极其低效。如本申请文件中所公开的,当处理ar数据时,其基于视角直接投影;且因此,不需要额外3d到2d的映射。且极大地简化了3d操作过程。通过这种方式,当前方法极大地简化了处理且使其快得多。
当显示器是真正3d显示器,例如显示器可展示立体像素,且来自不同角度的查看者可同时查看不同视角时,现有系统和方法使用3d操作,且因此2d投影方法在此情况下将不再起作用,因为现有处理方法不能提供适于真3d立体显示器的像素层级分辨率。本申请文件中所公开的输出可包括3d像素立体。过程将类似于如图5a所示。代替于处理2d阵列中的像素,我们的系统可处理3d阵列中的像素。通过这种方式,当前方法可支持3d立体式显示器。
实例系统架构
图7描绘用于实施图1-6的特征和过程的实例系统架构的图式。
一方面,一些实施例可采用计算机系统(例如计算机系统700)来执行根据本发明的各种实施例的方法。计算机系统700的示范性实施例包括总线702、一个或多个处理器712、一个或多个存储设备714、至少一输入设备716、至少一输出设备718、通信子系统720、工作存储器730,所述工作存储器730包括操作系统732、设备驱动程序、可执行库和/或其它代码,例如一个或多个应用程序734。
根据一组实施例,此类方法的程序中的一些或全部由计算机系统700响应于处理器712执行工作存储器730中所含有的一个或多个指令的一个或多个序列(其可能并入到操作系统732和/或例如应用程序734等其它代码中)而执行。此类指令可从诸如存储设备714中的一个或多个等另一计算机可读介质读取到工作存储器730中。仅作为例子,工作存储器730中所含有的指令序列的执行可能致使处理器712执行本申请文件所描述的方法的一个或多个过程。另外或可选地,可通过专门的硬件执行本申请文件中所描述的方法的部分。仅作为例子,关于上文所论述的方法(例如方法270、方法300、方法380、方法390、方法430、方法450、方法470、方法500、方法580、方法600、方法650以及图2-6中说明的方法的任何变化)所描述的一个或多个过程的一部分,可能由处理器712实施。在一些例子中,处理器712可以是用户设备102的智能模块140的实例。在一些实例中,应用程序734可以是执行图5a和5b中描绘的迭代实时学习方法的应用的实例。
在一些实施例中,计算机系统700可进一步包括一个或多个非暂时性存储设备714(和/或与之通信),所述非暂时性存储设备可包括(不限于)本地和/或网络可访问的存储设备;且/或可包括(不限于)磁盘驱动器、驱动阵列、光学存储设备、固态存储设备,例如随机存取存储器(“ram”)和/或只读存储器(“rom”),其可为可编程、可快闪更新的等等。此类存储设备可用于实施任何适当数据存储,包括但不限于各种文件系统、数据库结构和/或类似物。在一些实施例中,存储设备714可以是设备102的存储器115、用户设备220的本地数据库204、用户设备240的本地数据库2244或服务器250的服务器数据库254的实例。
在一些实施例中,计算机系统700可进一步包括一个或多个输入设备716,其可包括(不限于)允许计算机设备(例如,用户设备220或240)从用户、从另一计算机设备、从计算机设备的环境,或从可通信地与计算机设备连接的功能部件接收信息的任何输入设备。输入设备的实例包括(但不限于)相机、麦克风或传感器。示范性相机设备包括(但不限于)具有网络功能的相机、深度相机、一组相机、2d、3d或4d相机、彩色相机、灰度阶相机、普通的rgb相机、红外(ir)相机、近红外(r)相机、热感相机、多光谱相机、高频谱相机、360度相机等。麦克风可以是能够检测和捕获音频信号的任何设备。传感器可以是可检测其环境中的事件或变化且将信号发送到另一设备(例如,计算机处理器)的任何部件、模块或子系统。示范性信号包括(但不限于)与心跳、血压、方向、温度、运动、海拔高度、压力、距离、加速度等相关联的信号。
在一些实施例中,计算机系统700可进一步包括一个或多个输入输出设备718,其可包括(不限于)可从计算机设备(例如,设备102、220或240)接收信息且将此信息传送到用户、另一计算机设备、计算机设备的环境或可通信地与计算机设备连接的功能部件的任何输出设备。输入设备的实例包括(但不限于)显示器、扬声器、打印机、灯、传感器设备等。传感器设备可以可产生用户的感觉感知的形式接收和展现数据。此类形式包括(但不限于)热、光、触摸、压力、运动等。
可以理解,例如结合用户设备220、用户设备240或服务器250公开的任何可适用的输入/输出设备或部件可应用于输入设备716和输出设备718。
在一些实施例中,计算机系统700可能还包括通信子系统720,其可包括(不限于)调制解调器、以太网连接、网卡(无线或有线)、红外通信设备、无线通信设备和/或芯片组(例如蓝牙bluetooth.tm.设备、802.11设备、wifi设备、wimax设备、蜂窝式通信机构等)、近场通信(nfc)、zigbee通信、射频(rf)或射频识别(rfid)通信、plc协议、基于3g/4g/5g/lte的通信等等。通信子系统720可包括一个或多个输入和/或输出通信接口以准许与网络、其它计算机系统和/或任何其它电气设备/外围设备交换数据。在许多实施例中,计算机系统700将进一步包括工作存储器730,其可包括ram或rom设备,如上文所描述的一样。
在一些实施例中,计算机系统700还可包括展示为当前位于工作存储器730内的软件元件,包括操作系统732、设备驱动程序、可执行库和/或其它代码,例如一个或多个应用程序734,其可包括由各种实施例提供的计算机程序,和/或可经设计以实施其它实施例提供的方法和/或配置其它实施例提供的系统,如本申请文件所描述的一样。仅作为例子,相对于上文所论述的方法(例如相对于图2-6所描述的方法)描述的一个或多个过程的一部分可被实施为可由计算机(和/或计算机内的处理单元)执行的代码和/或指令;在一方面中,随后,此类代码和/或指令可用于配置。在一些实施例中,通用计算机(或其它设备)可适于执行根据所描述方法的一个或多个操作。在一些例子中,工作存储器730可以是设备102、220或240的存储器的实例。
这些指令和/或代码的集合可能存储在例如上文描述的存储设备714等非暂时性计算机可读存储介质上。在一些情况下,存储介质可能并入到例如计算机系统600等计算机系统内。在其它实施例中,存储介质可能与计算机系统(例如,可移除介质,例如光盘)分开,及/或提供于安装包中,使得存储介质可用于编程、配置及/或调适其上存储有指令/代码的通用计算机。这些指令可能呈可由计算机系统700执行的可执行代码的形式和/或可能呈源和/或可安装代码的形式。所述源和/或可安装代码在编译和/或安装于计算机系统700上之后(例如,使用多种通常可用的编译程序、安装程序、压缩/解压缩工具等中的任一个)即刻呈可执行代码的形式。在一些例子中,存储设备730可以是设备102、220或240的存储器的实例。
本领域的技术人员将显而易见可根据特定要求作出大量变化。例如,还可能使用定制硬件,且/或可将特定元件实施于硬件、软件(包括便携式软件,例如小程序等)或两者中。另外,可利用到其它计算设备(例如网络输入/输出设备)的连接。
如本申请文件中所使用的,术语“机器可读介质”和“计算机可读介质”指代参与提供致使机器以特定方式操作的数据的任何介质。在使用计算机系统700实施的实施例中,各种计算机可读介质可能参与将指令/代码提供到处理器712以用于执行,及/或可能用于存储和/或携带此类指令/代码。在许多实施方案中,计算机可读介质是物理和/或有形存储介质。此媒体可呈非易失性介质或易失性介质的形式。非易失性介质包括例如光盘和/或磁盘,例如存储设备714。易失性介质包括(但不限于)例如工作存储器730等动态存储器。
常见形式的物理及/或有形计算机可读介质包括(例如)软盘、柔性磁盘、硬盘、磁带,快闪盘、快闪驱动器或任何其它磁性媒体、cd-rom、任何其它光学介质、具有孔图案的任何其它物理介质、ram、prom、eprom、快闪eprom、任何其它存储器芯片或盒带,或计算机可从其读取指令及/或代码的任何其它介质。
在将一个或多个指令的一个或多个序列携载到处理器712以用于执行时可涉及各种形式的计算机可读介质。仅作为例子,起初可将指令携载于远程计算机的磁盘和/或光盘上。远程计算机可能将指令加载到其动态存储器中,并通过传输介质将指令作为信号进行发送以由计算机系统700接收和/或执行。
通信子系统720(和/或其部件)通常接收信号,且总线702随后可能将信号(和/或所述信号携带的数据、指令等)携载到工作存储器730,处理器712从工作存储器730获取和执行所述指令。由工作存储器730接收的指令可选地在由处理器712执行之前或之后存储在非暂时性存储设备714上。
应用的示范性实施例
提供本发明的方法/系统的可能应用的实例。如本申请文件中所公开的,除非另外指定,所有方法步骤和过程实时发生。
视频会议
本发明的方法和系统可用于利用增强现实进行视频会议。以下是可使用当前方法/系统实现的特征的实例。
在一些实施例中,用户可选择由方法/系统提供的标准背景或指定个人准备的背景。例如,用户可选择用例如静止图像(例如,使用专业办公室的图像替代由相机捕获的真实杂乱旅馆卧室视图)、视频(例如,使用预先录制的视频作为背景以替代实际背景),或来自另一相机的实时视频(例如,使用时代广场的监视相机视图替代当前用户背景)等虚拟背景替代真实背景。
在一些实施例中,用户可选择在视频会议期间增强其自身的外貌。例如,用户可使其自身看起来更瘦/更胖、更矮/更高,改变其肤色(例如,以描绘更多棕黄色或移除皮肤的明显瑕疵,例如深色可见疣或胎记)、添加配饰(例如,添加耳环、帽子、项链、眼镜、纹身、虚拟化妆等)。
在一些实施例中,用户可各自选择虚拟形象来表示其自身,且使所述虚拟形象复制其表情、身体移动和/或手势。
在一些实施例中,用户可增强其话音以使其听起来更好、作为娱乐或隐藏其身份。
在一些实施例中,用户可在其彼此远程通信时使其出现在与远程方相同的虚拟空间中。
在一些实施例中,所述系统/方法还可通过基于智能增强现实(iar)的通信系统允许相同物理空间处的用户远程地出现。
在一些实施例中,用户可选择随不是她的实际环境的一部分的另一人或对象出现。其它人或对象不是通信的一部分,且可为相机上先前或同时捕获的现实人或对象。例如,某人可选择随她心仪的流行歌手偶像的视频出现。所述视频可以是现场音乐会的预先录制的镜头或同时广播的视频。
在一些实施例中,方法/系统可执行通信内容的实时监视,且可在检测到一些文化/社交不当内容(例如手势、词汇等)的情况下向用户提供警告,且让用户决定是否撤回通信内容。同时,系统将暂停信号发送到远程用户以中止通信。
在一些实施例中,本申请文件中所公开的方法/系统可提供仅单方通信,以供用户自己娱乐或用于广告应用。在通信的另一侧不存在远程方。
在一些实施例中,所述方法/系统可提供自动语言翻译来帮助不同语言的用户彼此通信。
在一些实施例中,所述方法/系统可提供实时分析,且在通信期间提供用户表情、意图和文化暗示的智能。
在一些实施例中,所述方法/系统可提供实时智能和需要特定领域的专门知识来理解的一些特殊术语的阐释。此外,所述系统还可向用户提供实时智能、阐释和特定文化背景的背景以使通信更有效。
实时交互式控制
在一些实施例中,当前方法/系统可用于在通信期间向用户提供营销和电子商务信息。
例如,用户可在通信期间点击视频屏幕的着装/配饰/背景对象,且系统向用户提供关于类似产品或相关产品的价格信息和实时商品推荐信息。
在一些实施例中,所述方法/系统可用于向用户提供旅行、尝试新产品、培训技能、体验新事物、展示新不动产(办公室、家、建筑物、购物中心等)、探究新设备设计、参观新机构和上课等的虚拟现实体验。
在一些实施例中,所述方法/系统可用于供用户利用增强现实表达情绪和喜爱。例如,用户可利用增强的传感器控制以心率数据、呼吸模式和体温改变向其他人发送其喜爱。例如,其可使用心率增加来控制通信的另一侧的灯颜色改变。其可使用呼吸模式改变来致使与远程通信单元相关联的一个或多个马达振动。温度改变可用于控制通信系统的另一侧的声音改变。
在一些实施例中,所述方法/系统可用于增强远程性爱且帮助改进性爱体验。例如,系统可使用手势、肢体运动和生物响应来控制其他人的性爱玩具、装置、设备和图像。
在另一实例中,所述方法/系统可根据一个或多个用户偏好和系统设定使用用户的生物状态、表情、话音、行为等来以灯光、音频、振动、性爱玩具、图像、视频等提供增强的性爱。
远程医疗服务
一方面,本申请文件中所公开的方法和系统可用于实时远程医疗服务。
在一些实施例中,患者可使用所述系统依据其家居舒适度向医疗服务提供者提供生物状态,同时隐藏背景以保护更多隐私。在一些实施例中,医疗服务提供者(例如,医生或护士)还可利用增强现实居家工作以隐藏背景来保护更多隐私且维持专业形象。
在一些实施例中,所述方法/系统可提供患者的当前生物状态数据连同患者的过去健康状况信息的较好视觉化和数据呈现。所述系统可提供患者的当前生物状态和过去健康状况信息的智能摘录以为服务提供者提供用户健康状况的更个人化和整体了解来帮助服务提供者提供更好的定制医疗服务。
在一些实施例中,所述方法/系统还可使用患者的生物状态信息(例如心率、呼吸模式、体温等)来控制一些远程传感器(例如警报、灯光、振动、音频、视频等)以警告远程医疗服务提供者与用户相关联的任何异常健康状况。
在一些实施例中,所述方法/系统还可将医生的命令、手势、肢体运动翻译为针对患者侧的一个或多个传感器控制,以帮助控制传感器(例如心率监视器、体温监视和/或一些医疗设备控制)。
在一些实施例中,系统还可为患者提供医疗术语的实时翻译以帮助患者具有较好的理解。
远程教育和培训
一方面,本申请文件中所公开的方法和系统可用于提供远程教育和培训。
教育提供者(例如,教授、老师、讲师、助教等)可使用系统将经增强的教育内容递送给用户。例如,在教授人类解剖学中,系统可使人类解剖学与学生的真实身体在场景中叠加来帮助学生将解剖学信息与其自身身体相关。学生可能变得更感兴趣且更加促动对所述主题进行研究。此还可帮助教育提供者更生动地阐释内容且使学生更容易理解。
在一些实施例中,所述方法/系统还可用于帮助学生远程地协作完成项目且参与课堂讨论,但他们可看上去在相同虚拟教室工作以促进较好的合作和学习体验。
在一些实施例中,所述方法/系统可通过提供沉浸式ar环境帮助学生更容易地探究太空未知领域。
在一些实施例中,所述方法/系统还可帮助较好地用智能ar数据培训学生、专业人士、军队以提供沉浸式和交互式培训环境。
与物联网(iots)的通信
本申请文件中所公开的方法和系统可用于智能家居、智能办公室、智能建筑物、智能车辆、智能太空站等。
在一些实施例中,所述方法/系统可将用户数据(例如,表情、行为、肢体运动、手势和生物状态)表示为其它形式,例如传感器控制信号。这些控制信号可由iot(物联网)接收用于对于智能家居、智能办公室、智能建筑物和智能车辆的实时控制。
例如,用户的生物状态可再呈现和智能地分析以理解用户的环境需求,且这些需求随后翻译为经增强的信息来控制用户的家居、办公室、建筑物、太空站等的条件(例如,房间温度、照明条件、湿度等)。
在另一实例中,系统可基于用户的手势、肢体运动和/或命令远程地控制智能车辆。
在一些实施例中,所述方法/系统可用于供用户试穿衣服和配饰。系统的ar能力让用户在购买之前虚拟地试穿衣服和配饰。
在一些实施例中,所述方法/系统可用于供用户进行体育运动。系统的ar能力让用户进行体育运动,且为用户记录其运动来研究/分析和学习。所述系统的智能还可为用户提供如何更好地进行体育运动的指导方针。
在一些实施例中,所述方法/系统可用作用户玩游戏的游戏顾问。
在一些实施例中,所述方法/系统可用于供用户使用其命令、肢体运动、手势、生物状态等来控制远程机器、航天飞机、太空控制器、轮船、水下机器、无人驾驶车辆、无人驾驶航空运载工具并向其发送控制信号等。通信单元的远程侧可与本地/远程机器、航天飞机、太空控制器、轮船、水下机器、无人驾驶车辆、无人驾驶航空运载工具连接并向其发送控制信号。所述方法/系统可将用户的命令、肢体运动、手势、生物状态等表示和增强为控制信号。
附加通信实例
本申请文件中所公开的方法和系统可用于与动物、植物和外星生物交互式地和智能地通信。例如,所述方法/系统可使用机器学习和模式识别方法使用大数据、科学原理学习动物、植物和可能外星生物的语言、行为和表情;所述方法例如深度学习、主分量分析(pca)、线性判别分析(lda)等。
在一些实施例中,所述方法/系统还可学习人类语言、行为和表情与动物、植物和可能外星生物的语言、行为和表情之间的关系。
在通信期间,所述方法/系统可将人类语言、行为和表情翻译为动物、植物和可能外星生物的语言、行为和表情,且反之亦然。
在一些实施例中,所述方法/系统可由一组人类、动物、植物和可能外星生物使用以利用基于ar和智能的分析与另一组(或多组)人类/动物/植物/外星生物通信。
额外效用
如本申请文件中所公开的基于智能和交互式增强现实(ar)的用户交互平台具有大量效用。本申请文件中所描述的示范性实施例说明可通过例如多个层级处输入数据的综合理解和分析、智能和迭代机器学习、交互式用户控制等实施所述效用。提供额外实例以进一步说明基于智能和交互式ar的用户交互平台所实现的广范围效用。
智能通信助理:当前智能平台可用作通信工具(例如,用于电话会议、教学、磋商会等)。有利的是,智能平台允许用户选择适于通信时间和性质的背景。
例如,智能平台为用户提供在任何时候和任何地方进行专业会议的选择。取决于通信性质,智能平台可通过用户数据和虚拟要素的实时整合提供正确的背景、合适的服装乃至化妆品。智能平台的交互性质允许会议呈现更有效和动态,因此使接收端的用户更有参与感。因此,智能平台可用作有效的教学工具。
当前智能平台使得容易在任何时间和任何地方递送专业演讲和讲座。
如本申请文件中所公开的,增强的现实背景可用作企业的品牌推广方案。智能平台还可使用户/企业灵活地添加标识和其它编辑消息。当前智能平台和方法可用于tv/电影制造,且可显著减少生产成本。
此智能平台可用于消费者在家中进行网络会议。此智能平台可用于与智能电话/设备、网络会议电话、电话会议电话等通信。
智能管理助理:当前智能平台还可充当管理工具。例如,智能平台可充当组织助理且帮助管理用户的会议时间表。智能平台将自动更新用户的日历并向用户提供通知。如果用户可能参加会议会迟到,那么智能平台将在用户同意的情况下向主持人或参加会议的其他人发送迟到通知。如果出于某一原因,用户可能不能参加会议,那么智能平台将提供取消通知。
在一些实施例中,智能平台可帮助用户处理许多琐碎任务,例如帮助在设计阶段期间记录和组织用户的想法、基于用户偏好向用户提供经组织的新闻信息、帮助用户设置/取消会议、起草电子邮件(例如感谢电子邮件、祝贺电子邮件、吊唁电子邮件、响应告别电子邮件、面试邀请电子邮件、面试拒绝电子邮件、会议邀请等)、帮助用户进行电话/视频会议连接等。
在一些实施例中,智能平台可充当健康助理。例如,智能平台可监视用户的生物状态,必要时提醒用户放松或锻炼。智能平台还可从智能椅子(例如,作为iot网络的一部分)获取数据以检验用户是否具有正确的姿态且为用户具有正确坐姿提供推荐/指导。如果用户需要周期性地服药或具有常规体检,那么智能平台将提供自动通知。智能平台将为用户提供健康报告。
在一些实施例中,智能平台可充当情绪质量助理。例如,智能平台可例如通过一个或多个传感器监视用户的生物状态和情绪改变。当智能平台确定用户非常沮丧时,其将提供建议使用户平静下来。例如,智能平台可向用户提供冥想选择。
结合功能性的任一个,智能平台可例如通过智能平台提供的迭代和交互式学习过程学习用户的偏好并适应随着时间的改变。
智能家居应用:当前智能平台还可用作智能家居的一部分,例如智能闹铃。在一些实施例中,智能平台可帮助智能地设置闹铃。例如,智能平台可检查用户的日历并在存在可能冲突的情况下通知用户。智能平台可为用户提供改变闹铃时间的选择。这帮助用户避免因不当的闹铃时间而错过重要事件。
在一些实施例中,如果用户有在闹铃响起之后击按打盹按钮的习惯,那么智能闹铃可让用户设置临界唤醒时间。同样,智能闹铃可检查用户的日历并在存在可能冲突的情况下通知用户。
在一些实施例中,智能平台可让用户作出是否改变临界唤醒时间的决策。
在一些实施例中,智能闹铃利用多媒体和多个功能唤醒方法来帮助唤醒用户,例如通过控制或改变以通信方式与智能闹铃连接的一个或多个设备的设定。所述多媒体和多个功能唤醒方法可包括灯光、声音、打开窗帘、温度改变、湿度改变、气味、可穿戴式设备的振动等。
如本申请文件中所公开的,智能闹铃可具有两个层级的闹铃设定:在接近临界唤醒时间之前的渐进闹铃设定;以及在接近临界唤醒时间时的激进闹铃设定。
在一些实施例中,智能闹铃不会因为用户意外地推动了按钮而停止。其将连续监视用户的生物状态、移动、声音、心率、eeg、体温等以检验用户是否真正醒来。另一方面,用户也不需要推动按钮来关闭闹铃。一个或多个所监视生物状态,例如心率、体温、eeg等,可提供用户是否醒来的信息,且闹铃可随后自动停止。这将避免用户可能找不到闹铃按钮且非常恼火的沮丧。
在一些实施例中,智能平台还具有自动学习能力来改进智能。其将自动采集每一闹铃设定和闹铃事件的效力信息来改进所述过程。在一些实施例中,智能平台还与用户的电子邮件和日历同步以获得最新的会议邀请且通知用户可能的闹铃/唤醒时间改变。
以下是典型的智能闹铃设定过程。此包括两个阶段:智能闹铃设定和智能闹铃。
下文概述示范性智能闹铃设定过程。
·步骤1.每天晚上,智能平台将通知用户设定唤醒闹铃。用户可选择不设置闹铃,且将不存在闹铃。在此情况下,智能闹铃设定过程将完成。
·步骤2.智能平台还将检查用户的日历(在云端且在本地智能平台中同步)以参看闹铃时间是否与用户的日历冲突。如果不存在冲突,那么方法转到步骤5。
·步骤3.如果存在冲突,那么智能平台将基于日历通知用户可能错过的事件,且让用户决定是否重设闹铃时间。
·步骤4.如果用户决定重设闹铃时间,那么智能平台将回到步骤2。否则,其将转到步骤5。
·步骤5.智能平台基于日历和用户过去唤醒模式建议临界唤醒时间。
·步骤6.如果用户不喜欢所建议的唤醒时间,那么转到步骤7,否则,转到步骤8。
·步骤7.用户修改临界唤醒时间。
·步骤8.设置闹铃。且将整个过程的反馈提供到智能平台来改进闹铃设定智能。
以下是典型的智能闹铃过程。
·步骤1.闹铃开始
·步骤2.如果用户醒来,则闹铃结束。如果否,那么方法转到下一步骤。
·步骤3.检查时间是否接近临界闹铃时间。如果时间尚未经过临界闹铃时间,那么方法转到步骤4。如果其已过了临界闹铃时间,则转到步骤5。
·步骤4.使用渐进闹铃方法唤醒用户。渐进闹铃方法可包括通过控制房间内的智能灯、窗帘打开、用音乐发出闹铃声、话音或具有渐进声强的闹铃噪声、频率改变、温度改变、用户手上的可穿戴式带振动、气味等进行镜面灯的光强度和颜色调整以及房间光强度/颜色改变。智能平台连续监视用户的状态且转到步骤2。
·步骤5.如果较接近临界闹铃时间,那么智能平台将执行激进闹铃方法,例如高强度光、具有不太令人愉快的音乐/话音/闹铃的较高强度声音、较高频率的闹铃、用户的可穿戴设备上的较强振动、激进温度改变、较强气味等。
·步骤6.智能平台连续监视用户的状态。如果用户醒来,则闹铃结束。如果否,则转到步骤5。
在一些实施例中,智能平台可提供智能房间设置。例如,在早晨期间用户起床之后,智能平台可自动打开窗帘,调整照明,调整湿度,接通音乐/广播。在一些实施例中,如果天气允许,那么智能平台还可打开窗户来帮助新鲜空气进入房内。智能平台还可与智能床一起工作来整理床铺。
在一些实施例中,智能平台可向用户提供智能天气信息。例如,智能平台(例如,镜子或显示器)将向用户提供本地和用户优选的其它地点的最新天气和天气预报信息。如果用户将要旅行,那么智能平台还将自动显示旅行目的地天气和天气预报信息。如果存在可能的恶劣天气,那么其将向用户提供警示。
在一些实施例中,智能平台可为用户提供早晨例程(例如,梳洗、化妆)的辅助。在梳洗/化妆之前,如果用户请求,则智能平台可基于用户的面部结构、用户的过去选择、用户的偏好、当天的活动需要、一定程度上与用户类似的其他人的梳洗/化妆,和/或用户心仪的人的梳洗/化妆来推荐梳洗/化妆选项。如果用户请求,则智能平台还可将用户连接到用户的朋友或专业梳洗/化妆大师以提供建议。智能平台可展示梳洗/化妆在用户脸上的效果,且通过将其叠加到用户脸上来以3d视图显示所述效果。如果用户选择特定梳洗/化妆,那么智能镜将基于用户的请求向用户逐步骤提供化妆指令以供遵循。智能镜可在梳洗/化妆过程期间为用户提供指导以帮助用户实现令人满意的化妆效果。
在一些实施例中,智能平台可组织智能每日活动。智能平台可基于电子邮件邀请/取消自动更新用户的日历。其可通知用户任何新的更新,同时提供信息以获得用户的同意来确认或拒绝新的邀请。智能平台可改变或取消任何用户发起的会议。所述组织可在用户正执行早晨例程(例如,梳洗、个人卫生、化妆、打扮等)时发生。
在一些实施例中,智能平台可提供智能早晨电话/消息/社交网络辅助。如果已经在用户的用户优选睡眠时间期间阻挡任何电话呼叫/视频会议,那么智能平台可向用户提供列表并从用户接收输入来立即发起呼叫/会议或设置针对所述呼叫和会议的约定。在一些实施例中,智能平台可浏览新的电子邮件、社交媒体消息、文本消息和对于用户重要的其它信息。基于用户的输入,其可将信息标记为已读、未读、重要或用户喜欢的其它类别。如果用户决定传回一些消息/电子邮件或起草一些新的电子邮件/消息,那么平台将为用户提供多个选项:话音指示的消息/电子邮件、话音转文本消息/电子邮件、视频会议、语音呼叫等。如本申请文件中所公开的,这些活动可在用户正执行早晨例程的同时进行。
在一些实施例中,智能平台可向用户呈现新闻。智能平台可基于用户的兴趣和偏好向用户呈现最重要的新闻。这可在用户正执行早晨例程时进行。在一些实施例中,智能平台可提供智能打扮建议。如果用户请求,则智能平台可基于若干因素推荐当天的恰当着装,所述因素包括但不限于天气条件、用户当天的活动、用户过去的打扮习惯、用户衣橱内可用的服装、用户的社交圈着装风格、用户心仪的人的着装、当前潮流,和与用户类似的人的着装。如果用户请求,则智能平台可直接将用户连接到朋友、具有与用户类似的打扮偏好或类似风格或体格的随机的人,和/或专业顾问以寻求建议。在打扮过程期间,如果用户希望,则智能平台还可辅助用户线上购买新服装并使交易无缝进行。
在一些实施例中,智能平台可在用户正执行早晨例程时帮助他或她煮咖啡和准备早餐。智能平台将基于用户过去的习惯、日历为用户预测煮咖啡/烤面包/煮鸡蛋/准备其它早餐的恰当时间,且允许用户确认/修改时间和项目。智能平台可随后启动通过iot网络连接的多种设备,例如咖啡机、烤箱、电饭锅、煮蛋器等。煮/泡自动开始且然后停止机器。且其将通知用户它们何时准备就绪。
在一些实施例中,智能平台可在用户离开家之前智能地为用户准备汽车。例如,在非常炎热的夏季或非常寒冷的冬季,汽车可在用户进入车辆之前预冷或预热。更重要的是,在一夜之后,车辆内的空气可能不新鲜,且最好交换空气让一些新鲜空气进来。在一些实施例中,智能平台可通过在用户正执行早晨例程时预计用户将进入轿车的时间来使轿车准备就绪。在一些实施例中,用户的确认和/或调整可用于准备车辆。当车辆准备就绪时,智能平台可向用户发送通知。
在一些实施例中,智能平台可为用户智能地预约出租车/uber。如果用户没有轿车或不想要驾驶,那么智能平台可在用户正执行早晨例程时预测用户需要使用轿车的时间,且获得用户对时间/轿车类型的确认和/或调整以将预约请求发送到出租车或共乘平台。平台还可在车辆到达时向用户发送通知。当用户准备好且离开家门时,车辆已经就位来接用户。
在一些实施例中,智能平台可在用户离开之后以适当智能地设定房间来节省能量。在检测到用户已离开家之后,智能平台可基于天气条件和用户偏好将室温和湿度设定为适当水平,调整窗帘位置,打开/关闭窗户以节省能量。
在一些实施例中,智能平台可智能地为用户提供物品的位置且提供智能提示。有时,我们可能忘记了我们将我们的钥匙、电话、id、钱夹和我们当天需要携带的一些其它物品放在哪里。智能镜将向用户提供这些物品的位置通知并且还向用户提供提示列表。
智能健康助理:如上文所论述的,增强的通信能力可扩展到提供远程医疗保健以使患者直接远程地与看护人通信。在此情境下,智能平台将不增强患者的身体/脸,但其可增强背景以帮助保护患者的隐私。
在一些实施例中,智能平台可通信地与频谱仪连接,所述频谱仪可提供关于患者皮肤的准确且丰富的信息,且可用于获取耳、鼻、喉、口腔、眼睛图像(其提供比由看护人进行的传统的面对面眼球检查更多的频谱信息和分析)。具有恰当频谱设置的频谱仪可穿透皮肤以提供关于患者的皮下信息、血流、血液信息等的丰富的信息。
在一些实施例中,智能平台可自动监视患者的心跳、体温、呼吸模式、其它生物状态、心理状态和情绪状态。在一些实施例中,智能平台可在患者准许后将这些状态、模式的患者历史信息与分析信息一起自动发送给看护人。智能平台将自动突出显示异常状态,且基于看护人的请求和需要在不打扰患者的情况下为看护人检测数据模式以供在任何时间查看。
对于具有特殊需要的患者,智能平台还可与特殊医疗设备/系统连接以测量、监视、跟踪和诊断患者。
在一些实施例中,智能平台还可在患者应进行特定所要求测试的情况下或在患者需要在特定时间采取一些行动(例如,参加理疗)的情况下等等,自动提醒患者。
在一些实施例中,智能平台可通过在屏幕上展示理疗活动,同时允许患者查看他/她自身的图像来使理疗更加交互式;且同时,其可向患者提供患者是否正确地遵循了指令的实时反馈并且还提供鼓励。
在一些实施例中,智能平台可用于促进冥想锻炼。在一些实施例中,智能平台可提供合意的冥想环境。例如,智能平台可提供合适的背景声音(例如,音乐、自然声音等)、调整灯光和湿度、关闭/打开窗帘和提供环境的适当香氛等。
在一些实施例中,智能平台可在冥想期间监视和学习用户的状态并提供指导。智能平台可连续监视用户生物状态(例如,心率、体温、呼吸模式、eeg、血流等)且相应地为用户提供冥想指导。
在一些实施例中,智能平台可提供用户反馈。例如,智能平台可在仲裁之前和之后向用户提供数据。所述数据可包括(但不限于)例如用户的生物状态、情绪状态、心理状态等的一个或多个测量值。在一些实施例中,智能平台可提供累积数据以允许用户查看和分析趋势。
智能轿车应用:在一些实施例中,智能平台可结合智能轿车使用。在一些实施例中,智能平台可提供基于生物特征的访问控制以避免使用钥匙且改进安全性。例如,智能平台可自动识别驾驶者,且在驾驶者正接近时开门并在用户离开时锁门。这将避免寻找或丢失钥匙的麻烦,且改进安全性。
在一些实施例中,智能平台可为驾驶者提供个人化设定。例如,一旦门打开,智能平台就可识别用户,且基于用户偏好对车辆编程,包括例如设置座椅高度、视镜位置、温度、湿度、音乐选项等。
在一些实施例中,智能平台可预测驾驶终点且向用户呈现以供确认。例如,基于驾驶者的日历上的活动或用户过去的驾驶行为,智能平台可预测用户的驾驶目的地且为用户提供一个或多个选项以供确认。基于gps和交通信息,智能平台将为用户自动识别最佳路线。与当前市场上可用的基于用户输入的导航系统相比,这可节省大量时间。当车辆正在去往特定目的地的路上时,如果存在可能的日历改变(取消、会议位置改变等),智能平台可自动通知驾驶者且寻求继续当前路线还是基于更新的信息更新目的地的确认。
在一些实施例中,智能平台可在驾驶之前和期间监视和学习驾驶者的状态来改进驾驶安全。例如,智能平台可在驾驶之前和期间监视驾驶者的生物状态、情绪和心理状态。
在一些实施例中,智能平台可通过监视驾驶者的生物状态来避免醉驾或非安全驾驶。例如,如果智能平台检测到驾驶者可能醉酒、太疲劳而不能驾驶,或将致使驾驶者不能驾驶的某一其它状态,那么智能平台将通知驾驶者以采取缓解策略。
在一些实施例中,智能平台可避免疲劳驾驶、分心驾驶或路怒症。例如,智能平台可在驾驶过程期间保持监视驾驶者的生物状态、心理状态和行为。如果智能平台检测到驾驶者疲劳,那么智能平台可提醒用户休息一下。如果智能平台检测到驾驶者漫不经心(例如,目光移开、检查文本消息、参与除驾驶外的使用户从驾驶分心的某一其它任务),那么智能平台可提醒用户将注意力放在驾驶上。如果智能平台检测到用户正陷于路怒症,那么智能平台可提供平静机制来抚慰用户的心情且提醒用户他/她今天的时间表或驾驶目的地等,以帮助用户避免路怒症。
在一些实施例中,智能平台可与现有后视镜整合或作为所设计的新智能后视镜的一部分而包括。
在一些实施例中,智能平台可基于可能的驾驶相关问题提供会议通知。例如,可能存在非预期的交通状况或延迟。并且,可能存在与车辆本身相关联的机械问题。如果智能平台预测潜在延迟且确定所述延迟可能影响用户下一会议的时间表,那么智能平台可通知会议主持人/参与者(在得到用户批准或确认的情况下)所述可能的延迟、取消或重新安排。
在一些实施例中,与车辆相关联的智能平台可与用户家中或办公室内的其它智能平台合作,且执行针对家、办公室和轿车的相关设定。所述智能平台可与办公室和家中的智能平台一起无缝工作。当用户正接近办公室或家时,智能平台将分别通知办公室/家庭智能平台依据用户的偏好设置房间(温度、湿度、照明、音乐、娱乐、办公室机器等)。同时,当用户即将离开办公室/家时,智能平台也将分别通知办公室/家庭智能平台设置另一状态,例如设置以节省能量等,且反之亦然,办公室/家庭智能平台还可在其检测到用户即将离开办公室或家时通知轿车智能平台准备就绪。
所属领域的技术人员可以理解,智能平台可采用任何可适用的设计。例如,有时,智能平台还可在无视镜显示功能的情况下工作。在一些实施例中,智能平台可设计有模块的子集。在一些实施例中,智能平台可设计有更多附加模块。
上文描述的各种方法和技术提供实行本发明的若干方式。当然,应理解,不一定可根据本申请文件中所描述的任何特定实施例实现所描述的所有目标或优点。因此,例如,所属领域的技术人员将认识到,所述方法可按实现或优化如本申请文件中教导的一个优点或一组优点的方式执行,而不一定实现如本申请文件中可能教导或表明的其它目标或优点。本申请文件提及多种有利的和不利的替代形式。应理解,一些优选实施例特定地包括一个、另一个或若干有利的特征,而其它优选实施例特定地排除一个、另一个或若干不利特征,而另外其它优选实施例特定地通过包括一个、另一个或若干有利特征来缓解当前不利特征。
此外,技术人员将认识到来自不同实施例的各种特征的适用性。类似地,上文所论述的各种元件、特征和步骤以及每一此类元件、特征或步骤的其它已知等效物可由所属领域的一般技术人员混合和匹配以执行根据本申请文件中所描述的原理的方法。在各种元件、特征和步骤当中,在多种多样的实施例中将特定地包括一些元件、特征和步骤且特定地排除其它元件、特征和步骤。
尽管已在某些实施例和实例的场景中公开本发明,但所属领域的技术人员可以理解,本发明的实施例扩展超出特定公开的实施例到其它替代实施例和/或用途及修改和其等效物。
本发明的实施例中已经公开许多变化和替代要素。更多的变化和替代要素对所属领域的技术人员来说仍将是显而易见的。
本申请文件所公开的本发明的替代要素或实施例的分组不应解释为限制。每个群组成员可以个别地或与所述群组的其它成员或本申请文件中所见的其它要素以任何组合形式提及和要求。群组的一个或多个成员可出于便利性和/或专利性原因包括在群组中或从群组删除。当任何这类包括或删除发生时,本说明书在本申请文件中被认为含有所修改的群组,因此满足所附权利要求书中所用的所有马库西(markush)群组的书面描述。
最后,应理解,本申请文件所公开的本发明实施例说明本发明的原理。可以采用的其它修改在本发明的范围内。因此,作为实例而非限制,可以根据本申请文件的教导来利用本发明的替代性配置。因此,本发明的实施例不限于所精确展示和描述的实施例。
- 还没有人留言评论。精彩留言会获得点赞!