用于大规模并行处理的基于代价的动态计算节点分组优化的制作方法
背景技术:
大规模并行处理(massivelyparallelprocessing,简称mpp)无共享关系数据库管理系统(relationaldatabasemanagementsystem,简称rdbms)通常包括多个无共享节点。一个无共享节点可以包括耦合到至少一个计算节点的至少一个存储器。通常,在mpp无共享rdbms中,将若干存储器静态分配给特定无共享节点中的若干计算节点。
在处理对mpp无共享rdbms的查询时,可能需要对数据进行重新分区,并将所述数据从一个无共享节点传输到另一个无共享节点,其中,所述另一个无共享节点存储可能需要对该查询做出响应的其它数据。这种在存储器和计算节点之间静态分配的架构可能会导致某些计算节点使用不足或过度使用。此外,特定计算节点还可能被检索对该查询做出的响应的次优逻辑计划低效使用,而非有效使用存储器和计算节点的逻辑计划。
技术实现要素:
在第一实施例中,本技术涉及一种大规模并行处理无共享关系数据库管理系统,其包括分配给多个计算节点的多个存储器。所述系统包括一个或多个处理器,其中,所述一个或多个处理器与用于存储指令的非瞬时性存储器通信。所述一个或多个处理器执行所述指令以用于:将数据集存储在所述多个存储器中的第一组存储器中,其中,所述第一组存储器分配给所述多个计算节点中的第一组计算节点;通过哈希对所述数据集进行重新分区得到重新分区的数据集;将所述第一组存储器重新分配给所述多个计算节点中的第二组计算节点;将所述重新分区的数据集重分布到所述第二组计算节点;通过所述第二组计算节点对所述重新分区的数据集执行数据库操作。
根据所述第一实施例的第二实施例,其中,所述对所述数据集进行重新分区包括通过哈希形成所述数据集的较小哈希桶。
根据所述第一实施例的第三实施例,其中,当重新分区键与用于对所述数据集进行分区的键相同时,则省略所述重新分区。
根据所述第一实施例的第四实施例,其中,所述重新分配包括在所述第一组存储器和所述第二组计算节点之间形成网络连接,所述分发包括通过所述网络连接将所述重新分区的数据集分发给所述第二组计算节点。
根据所述第四实施例的第五实施例,其中,所述第一组存储器和所述第一组计算节点在所述系统中形成无共享节点,所述数据库操作包括内部连接、扫描和重分布中的至少一个。
根据所述第一实施例的第六实施例,还包括所述一个或多个处理器执行所述指令以用于:获取多个逻辑计划,其中包括对存储在所述第一组存储器中的数据集进行的所述数据库操作;针对所述多个逻辑计划中的每个逻辑计划确定将所述数据集重分布到至少一个其他计算节点的代价;还针对所述多个逻辑计划中的每个逻辑计划确定通过分区间并行降低的代价;基于重分布所述数据集的代价以及所述通过分区间并行降低的代价,从所述多个逻辑计划中选择最优逻辑计划。
在另一实施例中,本技术涉及一种计算机实现的用于访问数据的方法。所述方法包括:获取多个逻辑计划以响应查询;针对所述多个逻辑计划中的每个逻辑计划确定将存储在分配给计算节点的存储器中的数据集重分布到至少一个其他计算节点的代价;还针对所述多个逻辑计划中的每个逻辑计划确定通过分区间并行降低的代价;基于重分布所述数据集的代价以及所述通过分区间并行降低的代价,从所述多个逻辑计划中选择逻辑计划。
在又一实施例中,本技术涉及一种用于存储计算机指令的非瞬时性计算机可读介质,其中,当一个或多个处理器执行所述计算机指令时,使得所述一个或多个处理器执行以下步骤。所述步骤包括:将数据集存储在多个存储器中的第一组存储器中,其中,所述第一组存储器分配给多个计算节点中的第一组计算节点;获取多个逻辑计划以响应访问所述数据集的查询;针对所述多个逻辑计划中的每个逻辑计划确定将所述第一组存储器中存储的数据集重分布到第二组计算节点的代价;针对所述多个逻辑计划中的每个逻辑计划确定通过分区间并行降低的代价;基于重分布所述数据集的代价以及所述通过分区间并行降低的代价,从所述多个逻辑计划中选择逻辑计划;通过哈希对所述数据集进行重新分区得到重新分区的数据集;将所述第一组存储器重新分配给所述第二组计算节点;将所述重新分区的数据集分发到所述第二组计算节点;通过所述第二组计算节点对所述重新分区的数据集执行数据库操作,以提供对所述查询的应答。
提供本发明内容是为了以简化的形式引入概念的选择,这些概念将在以下具体实施方式中进行进一步的描述。本发明内容和/或标题的目的不在于识别权利要求书保护的主题的关键特征或必要特征,也不在于协助确定权利要求书保护的主题的范围。权利要求书保护的主题不限于用于解决在背景技术中提到的任何或全部缺点的实现方式。
附图说明
图1a为本技术实施例提供的一种mpp无共享rdbms的方框图;
图1b-c示出了本技术实施例提供的与图1中所示系统关联的各表;
图2示出了本技术实施例提供的语法查询解析树和关联逻辑计划;
图3示出了本技术实施例提供的具有估计代价的逻辑计划以及选择具有最低估计代价的逻辑计划;
图4为本技术实施例提供的静态存储器组和动态计算组的方框图;
图5示出了本技术实施例提供的获取多个逻辑计划以响应查询的过程;
图6a示出了本技术实施例提供的代价结构;
图6b示出了本技术实施例提供的数据重分布代价;
图6c示出了本技术实施例提供的通过分区间并行降低的代价;
图7示出了本技术实施例提供的确定与多个逻辑计划关联的总代价;
图8为本技术实施例提供的一种用于动态计算节点分组的方法的流程图;
图9a-c为本技术实施例提供的一种用于从多个逻辑计划中选择最优逻辑计划的方法的流程图;
图9d为本技术实施例提供的一种用于选择最优逻辑计划和节点分组的方法的流程图;
图10为本技术实施例提供的一种硬件架构的方框图;
图11是为本技术实施例提供的一种软件架构的方框图。
除非另有指示,否则不同图中的对应标号和符号通常指代对应部分。绘制各图是为了清楚地说明实施例的相关方面,因此未必是按比例绘制的。
具体实施方式
本技术通常涉及动态计算节点分组,其中,所述动态计算节点分组将大规模并行处理(massivelyparallelprocessing,简称mpp)无共享关系数据库管理系统(relationaldatabasemanagementsystem,简称rdbms)中的存储和计算解耦。本技术通过mpp节点之间的数据重分布实现了支持更高的分区间处理并行度的灵活性。动态计算节点分组还会为查询或计划优化器增加另一维度,以便在构建提供对查询做出的响应的最优逻辑计划时加以考虑。
数据倾斜感知代价模型可用于在所述查询处理管道的正确阶段选择最佳计算节点组。数据倾斜感知代价模型使计划优化器能够根据表统计信息以及从中间结果导出的统计信息,分析和比较通过网络重分布数据的估计代价和通过分区间并行降低的代价。
具有多个计算节点的mpp无共享rdbms可提供自动查询优化和执行。计算节点可以包括分配或耦合到至少一个计算节点的至少一个存储器。在各实施例中,计划优化器选择最优逻辑计划以响应接收的查询,并形成一个或多个计算节点组以执行所述最优逻辑计划。在各实施例中,mpp无共享rdbms包括计划优化器和动态计算节点组软件组件,用于选择所述最优逻辑计划并动态分组所述计算节点以执行所述最优逻辑计划。在各实施例中,mpp无共享rdbms解耦存储和计算层(或分配的组)以高效执行复杂的查询。所述选择的最优逻辑计划可以访问存储在多个不同大小的存储器组中的数据集(或表)中,所述系统通过存储所述表的多个存储器对多个计算节点进行动态分组来执行所述最优逻辑计划。
可以理解的是,本技术可以以许多不同的形式实现,并且不应视为对本文所阐述的实施例的限制。相反,提供这些实施例是为了透彻完整地理解本发明。事实上,本发明公开旨在覆盖包括在由所附权利要求书限定的本发明公开的精神和范围内的这些实施例的替代物、修改和等同物。另外,下文描述中陈述许多具体细节,以对本技术各实施例进行通彻理解。然而,可以清楚的是,实际应用中,可以不包括本技术的这样特定细节。
在一实施例中,rdbms是一种计算机实现的数据库管理系统,其采用关系方法存储和检索数据。关系数据库是计算机化的信息存储和检索系统,其通常存储表格形式的数据(也称为“关系”)以在存储器上使用,例如处理器可读存储器。“表”包括一组跨多列的行(也称为“元组”或“记录”)。表中的每一列都包含对其数据内容的“限制”,在各实施例中可以指定为主键或外键。
rdbms结构化为接受采用例如结构化查询语言(structuredquerylanguage,简称sql)等高级查询语言存储、检索和删除数据的语句。所述术语“查询”表示用于从存储的数据库检索数据的一组语句。sql标准已由国际标准协会颁布。sql标准的示例可包括由ansi发布的sql-92标准“数据库语言sql”,即ansix3.135-1992,以及由iso发布的sql-92标准“数据库语言sql”,即iso/iec9075:1992,用作所述结构化查询语言1992年版本的官方规范。
mpp无共享架构是一种实现方式,其中每个计算节点包括计算节点,所述计算节点包含至少一个具有本地存储器的处理器,以及分配的存储器,所述分配的存储器可包括直接访问存储设备(directaccessstoragedevice,简称dasd),例如,磁盘驱动器。所有处理器间通信都通过使用耦合所述计算节点或处理器的网络上传输的消息实现。在一实施例中,这种类型的系统架构称为mpp系统。虽然此架构可能是最具可扩展性的架构,但它需要复杂的处理器间通信设施来在处理器之间发送消息和数据。mpp无共享rdbms架构实施例可能有多种实施方式,例如ibmdb2dpf、pivotalgreenplum、amazonredshift、actianmatrix等。
计算节点组(或节点组)是mpp计算节点的分区,在一实施例中可包括一个或多个mpp无共享计算节点。在一实施例中,在mpp无共享rdbms中可以分配多个mpp节点组,其中一组特定数据(或特定表)可以静态存储在一个节点组中。可以通过指定的分区方法将表存储在所述分配的节点组的存储器中。特定的分区方法可以使用哈希、全距法和/或循环方法。查询可以在一个节点组中处理。当连接数据库操作需要连接不同节点组上存储的表时,其中一个表需要重新分区并传送到另一个表的节点组中,以便执行共定位的连接数据库操作。
重分布操作包括处理查询的数据库操作,其中,在一实施例中,通过哈希分区方法对数据集进行重分区,并将所述重新分区的数据分发到目标节点组中。根据所述节点组定义或分配,重分布操作可能会也可能不会产生网络流量。
广播操作包括处理查询的数据库操作,其中,在一实施例中,将数据集复制并传送到目标节点组的每个存储器中。
分区间并行是指将数据库操作细分为多个部分,然后在分区数据库的一个或多个分区(这些分区可能位于一个或多个计算节点上)上并行执行所述多个部分。使用分区间并行时,使用的并行度在很大程度上取决于创建的分区数量以及节点组的定义或分配方式。
通常,将计算层(或特定计算节点)紧密耦合或静态分配给mpp无共享rdbms中的存储层(或特定存储器)。例如,系统可以将许多连接操作中涉及的表分配给具有相同分区策略的同一节点组,以便可以将并置的连接用于组节点之间的零数据重排,从而可以实现更高性能。
相比之下,较小的表可能会分配或存储在单个节点或较小的节点组中,以使小表在访问时不会消耗太多资源。繁重事务操作涉及的表而不是主要参与决策支持查询的表可能会被分配给不同的节点组。
但是,有时可能需要将来自不同节点组的表连接在一起才能对查询产生有意义的响应。类似地,来自一个节点组的表可能会大量聚合,而来自其它节点组的表可能很少被访问。在这些场景中,mpp无共享rdbms可能只考虑一个节点组(所述表静态驻留的节点组)来处理整个查询,而来自不同节点组的表在连接的情况下需要根据哈希策略重新分区,并通过网络重分布到所述连接涉及的另一个表的同一节点组。
可以看出,在这些场景中可能未充分利用资源(一个或多个节点组),因为所述计算中不涉及其中部分节点。一种方法是启发式指示查询优化器使用更多节点或更大的节点组来处理所述查询。但是,由于不考虑单独运营代价和总计划代价(或总代价),这种方法可能效率低下。通过网络向计算中使用的目标节点传输数据所产生的开销代价可能被所述目标节点中分区间并行的优势抵消。在处理查询时,智能且动态地选择特定阶段的若干最佳计算节点可以提高mpp无共享rdbms的效率和性能。
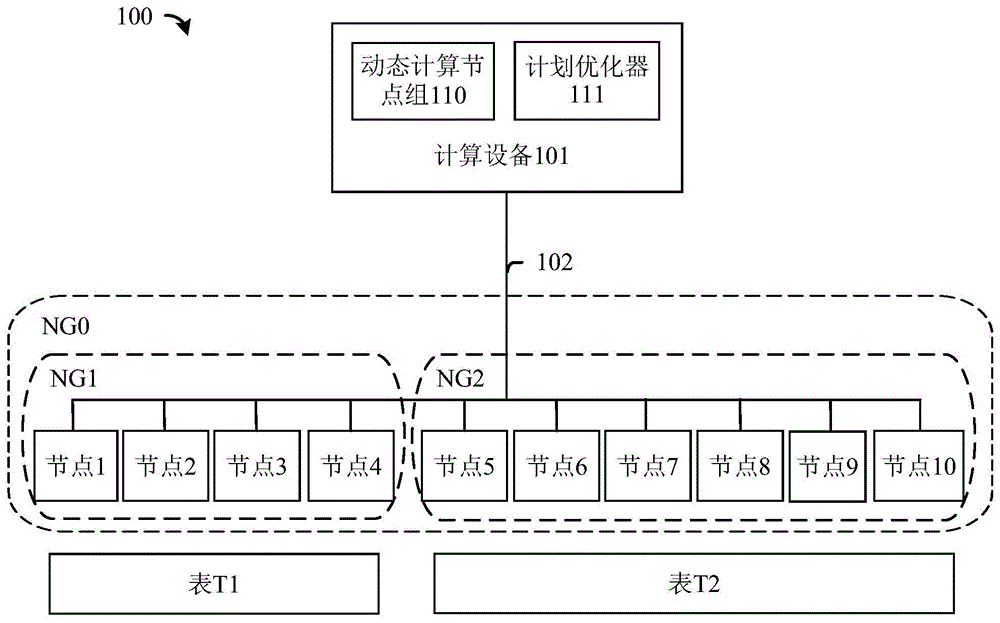
图1示出了mpp无共享rdbms100中的动态计算节点组110和计划优化器111,其中,所述mpp无共享rdbms100选择一个最佳计算节点组用于处理基于各种操作代价对接收到的查询做出响应(应答)的最优逻辑计划。正如本领域普通技术人员所了解的,为了清楚地说明本技术,未示出mpp无共享rdbms100的各部分。在一实施例中,动态计算节点组110和计划优化器111是计算设备101执行的软件组件。在一实施例中,计算设备101通过网络102耦合到计算节点ng0。在一实施例中,计算设备101可以是控制器。
mpp无共享rdbms100通常被划分为多个节点组,例如节点组ng1和节点组ng2,其包含各种大小的数据集,例如表t1和表t2。对查询的响应可能需要特定节点组执行数据库操作,例如扫描、聚合、重分布或(内部)连接数据库操作。为了将两个表连接到一起(例如表t1和表t2),需要通过一致的哈希方法将所述两个参与表的连接键分区到同一节点组中。由于节点组通常通过数据定义语言(datadefinitionlanguage,简称ddl)命令静态创建,并且表被静态分配给相应的节点组,因此某些算子例如扫描由于所述无共享架构而只能在该特定节点组内执行。
但是,一旦将表(或数据集)从存储器中加载到mpp节点的存储器中,所述数据集可以通过另一种哈希方法重新分区,并由重分布算子通过网络102传输到其它计算节点。在一实施例中,计算节点不受存储层(或存储器)约束,并且可以弹性或动态增加以实现更高的分区间并行度。在一实施例中,计算设备101执行的动态计算节点组110执行该功能。
在一实施例中,与静态节点组相比,用户不必手动创建动态节点组。节点组中的所有计算节点均可视为一个动态计算节点组,除非用户由于资源限制要求等原因专门限制此节点组的大小。
虽然可以将数据重新分区并重分布到更大的动态节点组以获得更高并行处理能力,但是网络102的重分布代价会被视为这种系统的瓶颈。为了确定用于计算的最佳节点组而不牺牲过多的通过网络102在计算节点之间传输数据的代价,可以通过更多计算节点来平衡数据重分布代价与通过实现更高并行度而降低的代价,从而进行后续查询处理。
例如,考虑对包含4个计算节点的小节点组ng1中的小表t1进行简单的连接操作;从包含6个计算节点的大节点组ng2连接大表t2。在节点组ng0(包括节点组ng1和ng2)中,共有10个计算节点(节点1-10)被视为一个动态计算节点组。为了执行此连接,典型的mpp无共享rdbms可能会生成计划,将表t1重分布到所述较大的节点组ng2,并使用存储在节点组ng2内的表t2完成该连接。mpp无共享rdbms100会将所述动态计算节点组包括在多个重分布策略中,并仔细评估每个重分布策略的代价:
1、表t1重分布/广播到节点组ng2,然后连接表t2;
2、表t2重分布/广播到节点组ng1,然后连接t1;
3、表t1和表t2均重分布到节点组ng0,然后执行该连接。
在一实施例中,然后以自下而上的方式递归进行代价评估,直至一组完整的逻辑计划用于所述查询,其中,每个逻辑计划都具有通过网络102重分布数据的总代价以及通过分区间并行降低的算子代价。在一实施例中,计划优化器111从一组可能的(或候选)逻辑计划中选择最优逻辑计划,以通过选择总代价最低的逻辑计划来响应所述查询。需要注意的是,在上述重分布策略#3中,虽然表t1和表t2都被重分布到最大的节点组ng0中,这可能会在数据重分布上造成比其它两个重分布策略#2和#3更高的代价,但重分布策略#3的总代价实际上可能更低,因为它能使更多计算节点参与后续数据库操作,例如另一个连接算子或排序算子等。当计划优化器111获得一组逻辑计划以响应总代价非常相似(例如,在1%的误差容限内)的所有查询时,在一实施例中,计划优化器111选择使用数量最少的计算节点的逻辑计划。
下文介绍了通过动态计算节点组110和计划优化器111为特定查询选择特定最优逻辑计划和特定计算节点组的示例。如上所述,图1示出了mpp无共享rdbms100,包括节点组ng0,其中,所述节点组ng0被划分为用于存储表t1和表t2的更小节点组ng1和ng2。
表示mpp无共享rdbms100节点分组的元信息可以按图1b所示的表150的形式存储在数据库目录中。同样,表t1和较大的表t2分别分配给节点组ng1和ng2。关系与节点组之间的这种映射关系可以按图1c中所示的表180的形式在另一数据库目录中表示。在各实施例中,包括表150和表180的数据库目录可以存储在图10所示的计算设备101的存储器1020中。
如图5和下文所示的示例性查询500可以提交到mpp无共享rdbms100:
从t1、t2中选择t1.a,其中,t1.a=t2.b分组依据t1.a;
其中,t1被哈希分发在(t1.a,ng1)上,t2被哈希分发在(t2.b,ng2)上。所述语法查询解析树200如图2所示。
图3示出了本技术实施例提供的具有估计总代价的逻辑计划以及选择具有最低估计总代价的逻辑计划。计划优化器111通过获得与逻辑计划ng0、ng1和ng2相关的估计总代价z、x和y中的最低估计总代价,在选择最优逻辑计划时具有类似于漏斗300的功能。比较所述估计的总代价z、x和y,并在一实施例中选择与所述最低估计总代价相关的逻辑计划。
根据一组预定义规则和数据库目录中的元信息,查询500将在查询编译期间在语法上重写为等效查询算子,并进一步转换为一组优化逻辑计划。在一实施例中,计划优化器111执行该功能。从图2、3和7所示的候选逻辑计划中可以看出,有三种执行所述连接和分组依据操作的方法。
计划ng1:将t2重分布到ng1中,并在ng1中连接t1和t2,也在ng1中执行转换为哈希聚合的后续分组依据操作。
计划ng2:将t1重分布到ng2中,并在ng2中连接t1和t2,然后在ng2中执行后续哈希聚合。
计划ng3:将t1和t2重分布到ng0中,并在ng0内执行连接和所述后续哈希聚合。
可以看出,计划ng0、ng1和ng2之间的主要区别在于,动态计算节点组由动态计算节点组110和数据库目录中的信息组成。计划ng0使用所有计算节点执行所述连接和哈希聚合操作,而在一实施例中,所述计划ng1和ng2仅使用计算节点的子集。
在一实施例中,计划优化器111随后将枚举每个逻辑计划,并仔细计算每个算子的代价并求和,以获得每个逻辑计划的总代价。为了计算动态节点组引入的额外维度的总代价,在所述逻辑计划评估过程中会保留一些新变量。这些新变量包括数据重分布到目标节点组的代价(重分布的代价)以及所述目标节点组中通过分区间并行降低的代价。
图6a示出了动态组信息的代价结构或模型以及分区间并行度。代价值是一个查询算子的估计代价。p是一种用于表示分区间并行度的数据结构。ng是用于算子(操作)的节点组的标识,其中,变量d是将参与所述操作的计算节点的估计数量。在一实施例中,变量d表示为:
d=min(ndistinct,sizeng)×倾斜因子(1)
ndistinct是指连接键的列基数或对哈希处理的列进行重分布的列基数。这可以从基表的目录列统计信息中获得,也可以从所述重分布的数据恰好是中间结果时导出的统计信息中获得。sizeng是指所述目标节点组的大小。
需要注意的是,由于哈希分区可能引入数据倾斜(或倾斜因子),上述代价表示中的变量d可能等于或可能不等于所述参与节点组的大小(此处的大小指节点组中的节点数量)。变量d背后的基本原理是将数据倾斜的影响模型化成如下所述的并行度。
为了计算数据重分布代价,应在所述目标节点组中使用的哈希分区方法的上下文中理解mpp无共享rdbms中的重分布操作。这是为了确保重分布后的最终结果与目标节点组中的表共享完全相同的哈希分区策略,从而使来自两个表的数据能够正确地连接。尽管哈希桶可能会在所述节点组中随机分发以避免数据倾斜,但所述数据的值本身的分发和使用的哈希方法仍然可能会引入一定程度的倾斜,因此如图6a和下文所示引入了倾斜因子。
倾斜因子用于进一步评估在重分布后每个计算节点上的数据倾斜。倾斜因子可以表示为浮点数,范围为:
倾斜因子可以通过查看所述基表的直方图或导出的统计信息并计算中间结果的表基数或复合基数中mcv(最常见值)的百分比计算。
以下场景示出了变量d(或预计参与操作的计算节点数量)的计算模型:
首先,被重分布的列的不同值比所述目标节点组中的节点数少,然后可以知道,只有通过哈希方法重分布后计算节点的不同值的数量才将会保留数据,否则它将是所述目标节点组的大小。
其次,一旦数据被分发到计算节点k上,在最佳场景中,所有节点都会接收相同数量的数据,并且所述倾斜因子将为1,而最坏情况是一个节点接收大部分数据,并且所述倾斜因子将接近1/k。
一旦计算出变量d的值,就可以通过倾斜感知很好地估计出分区间并行度,并且可以进一步计算数据重分布代价,如下文和图6b所述。
例如,在图4中,逻辑计划ng0用于演示如何将数据从静态节点组ng1重分布到动态计算节点组ng0,如mmp无共享rdbms400所示。mmp无共享rdbms400包括节点组ng1,所述节点组ng1包括四个存储器1-4,所述存储器1-4通过网络102耦合到具有计算节点1-10的节点组ng0。在一实施例中,计算设备101耦合到网络102,如图1所示。
如图4所示,需要将节点组ng1中的表t1重新划分为一系列哈希桶b1-b12(不同的数据库系统可能使用不同大小的哈希桶)。然后,根据表150中记录的与节点组ng0关联的哈希桶到节点映射,将所述哈希桶b1-b12分发到节点组ng0中的计算节点(节点1-10)。在某些示例中,较大的哈希桶可能会重新分区为较小的哈希桶。在一实施例中,所述总rediscost可以分为哈希函数的代价加上通过网络102发送数据的代价,如图6b中所示的rediscost公式所示。
或者,在图6b所示的rediscost实施例中,数据重分布代价可以解释为固定数据量的前期哈希代价,其表示为通过具有固定单通道网络速度s(平均传输速度)乘以变量d(具有倾斜因子的分区间并行度)的网络传输大量数据。对于在节点组之间重分布数据的所用时间,这种重分布数据的估计代价可能相当准确。但是,可能需要考虑在同一计算节点内传输数据。例如,图4中的一些哈希桶在同一节点之间传输,因为节点组ng1是节点组ng0的子集。对于从节点组ngx向节点组ngy传输数据不会产生任何网络流量(所有数据在一台物理机器中重排)的特例,可以对变量s进行调整,以降低计算rediscost时的传输代价。
在图5所示的逻辑计划ng1、ng2和ng0中,需要注意的是,剩余的内部哈希连接和哈希聚合操作/步骤是在所述目标计算节点组内从所述数据集的重分布开始执行的。借助从所述重分布步骤中导出的变量d,可以通过将哈希连接或哈希聚合操作的典型算子代价除以变量d(具有倾斜因子的分区间并行度)来获取估计的并行降低代价。哈希连接或哈希聚合操作的代价可以由特定系统定义或从统计信息中获取。因此,在一实施例中,估计的通过分区间并行度d(ipparallcostreduction)降低的代价等于:
图7示出了本技术实施例提供的确定与多个逻辑计划关联的代价。特别地,图7示出了如何通过考虑数据重分布代价和随后分区间并行降低的代价来计算与逻辑计划ng1、ng2和ng0关联的总估计代价x、y和z。图7示出了总估计代价z(以及总估计代价x和y)是每个数据库操作的代价,例如代价1,以及与逻辑计划ng0中的扫描(t1,ng1)数据库操作关联的统计信息的代价总和。在一实施例中,总估计代价z是与至少6个数据库操作相关联的6种代价的函数。每个数据库操作的每个代价还包含每个中间结果/步骤的关联统计信息(统计信息)或直方图信息。
通过重分布到不同计算节点组的代价和随后分区间并行降低的代价两者的综合代价视图,计划优化器111能够确定在正确步骤中待使用的最佳计算节点组。假设在数据均匀分发的场景中,当所述连接和分组依据操作比通过网络重新分区和分发数据更密集时,则更可能选择计划ng0,因为处理所述连接和聚合数据库操作将涉及更多计算节点。当大量数据通过网络分发时,则更可能选择计划ng2,但所述后续连接和分组依据操作的负载较轻。计划ng1可能会在优化的早期阶段进行精简,以节省搜索空间,因为计划ng1的并行度低于计划ng0和ng2。
图8为本技术实施例提供的一种用于动态计算节点分组的方法的流程图。图9a-c为本技术实施例提供的一种用于从多个逻辑计划中选择最优逻辑计划的方法的流程图。图9d为本技术实施例提供的一种用于从多个逻辑计划中选择最优逻辑计划和用于动态计算节点分组的方法的流程图。
在各实施例中,图9a-d中的流程图是至少部分由图1、图4和图10-11中所示的硬件和软件组件执行的计算机实现的方法,如下所述。在一实施例中,图11中所示的软件组件由一个或多个处理器执行,例如图10中所示的处理器1010,执行所述方法中的至少一部分。
图8为本技术实施例提供的一种用于动态计算节点分组的方法800的流程图。在图8中的步骤801,将数据集存储在多个存储器中的第一组存储器中,其中,所述第一组存储器分配给多个计算节点中的第一组计算节点。在一实施例中,将数据集例如表t1存储在节点组ng1的存储器1-4中,如图4所示。在一实施例中,处理器1010执行软件组件以存储所述数据集。
在步骤802,通过哈希对所述数据集进行重新分区得到重新分区的数据集。在一实施例中,由处理器1010执行的动态计算节点组110,尤其是重新分区110a,执行该功能的至少一部分,如本文所述和图10-11所示。当重新分区键与在实施例中用于对所述数据集进行分区的键相同时,则可以省略所述重新分区。
在步骤803,将所述第一组存储器重新分配给所述多个计算节点中的第二组计算节点。在一实施例中,由处理器1010执行的动态计算节点组110,尤其是分配110b,执行该功能的至少一部分。特别地,为响应计算设备101通过网络接口1050生成的信号,重新配置网络102。
在步骤804,将所述重新分区的数据集分发(或重分布)到所述第二组计算节点。与上述类似,处理器1010和动态计算节点组110,尤其是重分布110c,执行该功能的至少一部分。
在步骤805,通过所述第二组计算节点对所述重新分区的数据集执行数据库操作,例如图4中所示的节点组ng0中的计算节点1-10。在各实施例中,数据库操作可以包括但不限于哈希聚合(hashaggregate,简称hashagg)、内部哈希连接、扫描、重分布、内部连接或分组依据操作。
图9a为本技术实施例提供的一种用于获取用于响应rdbms查询的最优逻辑计划的方法900的流程图。在图9a中的步骤901,获取多个逻辑计划以响应查询,例如对mpp无共享rdbms的查询。在一实施例中,由处理器1010执行的计划优化器111,尤其是计划111d,执行该功能的至少一部分,如本文所述和图10-11所示。在一实施例中,从句法查询解析树中获取多个逻辑计划。
在步骤902,针对所述多个逻辑计划中的每个逻辑计划确定将存储在分配给计算节点的存储器中的数据集重分布到至少一个其他计算节点的代价。在一实施例中,由处理器1010执行的计划优化器111,尤其是数据重分布代价111a,执行该功能的至少一部分。
在步骤903,针对所述多个逻辑计划中的每个逻辑计划确定通过分区间并行降低的代价。在一实施例中,由处理器1010执行的计划优化器111,尤其是并行降低代价111b,执行该功能的至少一部分。
在步骤904,基于重分布所述数据集的代价以及所述通过分区间并行降低的代价,从所述多个逻辑计划中选择最优逻辑计划。在一实施例中,由处理器1010执行的计划优化器111,尤其是计划111d,执行该功能的至少一部分。在一实施例中,选择总估算代价最低的逻辑计划,如本文实施例所述和图3和图7所示。
图9b为本技术实施例提供的一种用于计算重分布数据集的代价的方法950的流程图。在一实施例中,方法950执行上述图9a中步骤902的功能。在一实施例中,由处理器1010执行的计划优化器111,尤其是数据重分布代价111a,执行该功能的至少一部分,以及方法950中的其它功能,如本文所述和图10-11所示。
在步骤951,计算所述数据集中待处理的元组数量。
在步骤952,计算所述数据集中元组的宽度。
在步骤953,计算所述数据集的哈希代价因子。
在步骤954,计算耦合到至少所述存储器和至少一个其他计算节点的网络的平均数据传输速度。
在步骤955,计算使用倾斜因子的分区间并行度。
在步骤956,计算重分布所述数据集的代价,以至少响应所述待处理的元组数量、所述元组的宽度、所述哈希代价因子、所述平均数据传输速度以及所述使用倾斜因子的分区间并行度。
图9c为本技术实施例提供的一种用于计算使用倾斜因子的通过分区间并行降低的代价的方法980的流程图。在一实施例中,方法980执行上述图9a中步骤903的功能。在一实施例中,由处理器1010执行的计划优化器111,尤其是并行降低代价111b,执行该功能的至少一部分,以及方法980中的其它功能,如本文所述和图10-11所示。
在步骤981,计算对所述数据集进行哈希连接的算子代价。
在步骤982,计算对所述数据集进行哈希聚合的算子代价。
在步骤983,计算所述数据集的哈希代价因子。
在步骤984,计算使用倾斜因子的分区间并行度。在一实施例中,由处理器1010执行的计划优化器111,尤其是倾斜因子111c,执行该功能的至少一部分。
在步骤985,计算所述通过分区间并行降低的代价,以响应所述哈希连接的算子代价或所述哈希聚合的算子代价以及所述使用倾斜因子的分区间并行度。
图9d为本技术实施例提供的一种用于从多个逻辑计划中选择最优逻辑计划和用于动态计算节点分组的方法990的流程图。在一实施例中,由处理器1010执行的计划优化器111和动态计算节点组110执行该功能的至少一部分,如本文所述和图10-11所示。
在步骤991,将数据集存储在多个存储器中的第一组存储器中,其中,所述第一组存储器分配给多个计算节点中的第一组计算节点。
在步骤992,获取多个逻辑计划以响应访问所述数据集的查询。
在步骤993,针对所述多个逻辑计划中的每个逻辑计划确定将所述第一组存储器中存储的数据集重分布到第二组计算节点的代价。
在步骤994,针对所述多个逻辑计划中的每个逻辑计划确定通过分区间并行降低的代价。
在步骤995,基于重分布所述数据集的代价以及所述通过分区间并行降低的代价,从所述多个逻辑计划中选择逻辑计划。
在步骤996,通过哈希对所述数据集进行重新分区得到重新分区的数据集。
在步骤997,将所述第一组存储器重新分配给所述第二组计算节点。
在步骤998,将所述重新分区的数据集重分布到所述第二组计算节点。
在步骤999,通过所述第二组计算节点对所述重新分区的数据集执行数据库操作,以提供对所述查询的应答。
图10示出了一种用于计算设备101的硬件架构1000,其中,所述硬件架构1000用于形成动态计算节点组并选择用于响应查询的最优逻辑计划。计算设备101可以包括处理器1010、存储器1020、用户接口1060和由互连1070耦合的网络接口1050。互连1070可以包括用于传递具有一种或多种类型的架构的信号的总线,例如存储器总线、内存控制器或外围总线等。
计算设备101可以在各实施例中实现。在各实施例中,计算设备可以利用所示的全部硬件和软件组件,或者组件的子集。集成程度可以根据实施例而变化。例如,存储器1020可以包括多个存储器。此外,计算设备101可包括组件的多个实例,例如多个处理器(核)、存储器、数据库、发射器、接收器等。计算设备101可包括处理器,该处理器配备有一个或多个输入/输出设备,例如网络接口和存储接口等。
在一实施例中,计算设备101可以是访问与存储在数据库中的蜂窝网络相关的大量数据的大型计算机或者其一部分。在替代实施例中,计算设备101可以体现为不同类型的计算设备。在一实施例中,计算设备类型包括但不限于控制器、笔记本电脑、台式计算机、嵌入式计算机、服务器、大型机和/或超大型机(计算机)。
存储器1020存储动态计算节点组110和计划优化器111,其包括计算机程序中包含的计算机指令。在各实施例中,其它计算机程序,例如具有调度器、应用程序和数据库的操作系统存储在存储器1020中。在一实施例中,用于存储和检索数据的计算机程序存储在存储器1020中。在替代实施例中,网络1103中包括mpp无共享rdbms系统,所述系统具有通过网络耦合到多个计算节点的多个存储器,其中,计算设备101可以访问所述网络1103。
在一实施例中,处理器1010可以包括具有一个或多个核的一种或多种类型的电子处理器。在一实施例中,处理器1010是一种集成电路处理器,其执行(或读取)存储在非瞬时性存储器中的代码和/或计算机程序可包括的计算机指令,以提供本文所述的至少一些功能。在一实施例中,处理器1010是能够执行多个线程的多核处理器。在一实施例中,处理器1010是数字信号处理器、基带电路、现场可编程门阵列、数字逻辑电路和/或等效器件。
执行线程(线程或超线程)是一系列计算机指令,在一实施例中可以独立管理所述指令。可能包含在操作系统中的调度器也可以管理线程。线程可以是进程的组成部分,在一个进程中可以存在多个线程,同时执行(一个线程在其它进程结束之前启动)和共享资源例如内存,而不同的进程不共享这些资源。在一实施例中,进程的线程共享其指令(可执行代码)和上下文(所述进程的变量在任何特定时间的值)。
存储器1020可包括任何类型的系统存储器,例如静态随机存取存储器(staticrandomaccessmemory,简称sram)、动态随机存取存储器(dynamicrandomaccessmemory,简称dram)、同步dram(synchronousdram,简称sdram)、只读存储器(read-onlymemory,简称rom)或其组合等。在一实施例中,存储器1020可包括在开机时使用的rom,以及在执行指令时使用的存储程序和数据的dram。在各实施例中,存储器1020是非瞬时性或非易失性集成电路存储器。类似地,本文所述的存储器可以是非瞬时性或非易失性集成电路存储器。
此外,存储器1020可以包括任何类型的存储设备,用于存储数据、包括指令的计算机程序和其它信息,并使数据、计算机程序和其它信息通过互连1070能够被访问。存储器1020可以包括,例如,固态驱动器、硬盘驱动器、磁盘驱动器、光盘驱动器等中的一种或多种。类似地,在各实施例中,本文所述的存储器可以是固态驱动器、硬盘驱动器、磁盘驱动器、光盘驱动器等中的一种或多种。
计算设备101还包括一个或多个网络接口1050,所述网络接口1050可以包括有线链路,例如以太网电缆等,和/或接入网络1003的无线链路。网络接口1050允许计算设备101与网络1003通信。例如,网络接口1050可以提供控制信号以更改或重新分配网络1003中多个存储器和多个计算节点之间包括信号路径的网络连接。类似地,网络接口1050可以向网络1003中的多个存储器和多个计算节点提供数据和控制信号,以实现存储、重新分区和重分布数据等功能。
在一实施例中,网络1003可以包括单独或组合的有线或无线连接。在一实施例中,网络1003可包括单独或组合的因特网、广域网(wideareanetwork,简称wan)或局域网(localareanetwork,简称lan)。
在一实施例中,网络1003可以包括高速分组接入(highspeedpacketaccess,简称hspa)网络或其它合适的无线系统,例如无线局域网(wirelesslocalareanetwork,简称wlan)或wi-fi(电气和电子工程师学会(instituteofelectricalandelectronicsengineers,简称ieee)802.11x)。在一实施例中,计算设备101使用一种或多种协议来传输信息或报文,例如,传输控制协议/因特网协议(transmissioncontrolprotocol/internetprotocol,简称tcp/ip)报文。
在各实施例中,计算设备101包括输入/输出(input/output,简称i/o)计算机指令以及硬件组件,例如通过网络1003从其它计算设备和/或网络接收和输出信息的i/o电路。在一实施例中,i/o电路可以至少包括发射器电路和接收器电路。
在各实施例中,用户接口1060可以包括计算机指令以及硬件组件。用户接口1060可以包括触摸屏、麦克风、相机、键盘、鼠标、定点设备和/或位置传感器等输入设备。类似地,用户接口1060可以包括输出设备,例如显示器、振动器和/或扬声器,以输出作为输出的图像、文字、振动、语音和/或视频。用户接口1060还可以包括用户可以通过说话、触摸或做手势来提供输入的自然用户接口。
图11示出了本技术实施例提供的一种软件架构1100,用于形成动态计算节点组并选择用于响应查询的最优逻辑计划。在各实施例中,软件架构1100中示出的软件组件存储在图10的存储器1020中。在各实施例中,图11中所示的软件组件可以单独地或组合地实现为存储在电子文件中的计算机程序、对象、功能、子例程、方法、软件实例、脚本、代码片段。为了清楚地描述本技术,图11中所示的软件组件描述为单独的软件组件。在各实施例中,图11中所示的软件组件可单独或组合地存储(在单个或分布式计算机可读存储介质中)和/或由单个或分布式计算设备(处理器或多核处理器)架构执行。由本文描述的各种软件组件执行的功能是示例性的。在其它实施例中,本文所标识的软件组件可以执行更多或更少的功能。在各实施例中,软件组件可以组合或进一步分开。
在各实施例中,软件架构1100包括动态计算节点组110和计划优化器111。动态计算节点组包括重新分区110a、分配110b和重分布110c。计划优化器111包括重分布代价111a、并行降低代价、倾斜因子111c和计划111d。
除其它功能外,动态计算节点组110还负责将存储数据集例如表的多个存储器分配给多个目标计算节点。在一实施例中,动态计算节点组110将控制信号或命令发送到网络,以更改特定存储器和特定计算节点之间的网络连接或信号路径。在一实施例中,动态计算节点组110根据用于响应查询的所选择的最优逻辑计划分配网络连接。
除其它功能外,重新分区110a还负责将数据集例如表重新分区或分区成分区数据或哈希桶,以便传输到多个或一组目标计算节点。
除其它功能外,分配110b还负责分配多个存储器,这些存储器将所述数据集存储到特定的多个或一组计算节点。在一实施例中,分配110b将控制信号或命令发送到网络,以更改特定存储器和特定计算节点之间的网络连接或信号路径。
除其它功能外,在一实施例中,重分布110c还负责重分布或分发来自特定存储器的重新分区或分区的数据集,其中,所述特定存储器已分配给分配110b中可能分配的特定计算节点。在各实施例中,重分布110c可以在所述数据集中的至少一部分上使用重分布和/或广播操作。
除其它功能外,计划优化器111还负责从候选逻辑计划中选择最优逻辑计划以响应(或应答)查询。在一实施例中,计划优化器111从计划111d接收候选逻辑计划。在一实施例中,计划优化器111基于数据重分布代价和并行降低代价选择最优逻辑计划。在一实施例中,计划优化器在所述候选计划中的每个数据库操作步骤中将所述数据重分布代价和所述并行降低代价相加,以获得每个逻辑计划的总估计代价。然后,比较每个逻辑计划的总估计代价,并选择总估计代价最低的计划作为最优逻辑计划。在一实施例中,当一个或多个逻辑计划的估计总代价在预定容差内时,选择使用数量最少的计算节点的逻辑计划作为最优计划。
除其它功能外,数据重分布代价111a还负责获取数据集的数据重分布代价。在一实施例中,如图6a-b所示和本文所述,计算数据重分布代价。
除其它功能外,并行降低代价111b还负责在计算数据集时获取并行降低代价。在一实施例中,如图6c所示和本文所述,计算并行降低代价。
除其它功能外,倾斜因子111c还负责获取倾斜因子。在一实施例中,如图6b所示和本文所述,计算倾斜因子。在一实施例中,倾斜因子111c为数据重分布代价111a提供倾斜因子。
除其它功能外,计划111d还负责获取多个候选逻辑计划以响应查询。在一实施例中,计划111d解析查询,并且在一实施例中,在获取多个候选逻辑计划时形成语法查询解析树,例如语法查询解析树200。
本技术的优点可能包括但不限于在mpp无共享rdbm系统中解耦计算和存储层,从而提高效率、灵活性和性能。其它优点可包括选择最优逻辑计划以检索对查询的响应(或应答),所述查询可进一步增强mmp无共享rdbm系统中的性能、灵活性和响应时间。
附图中的流程图和框图示出了根据本发明的各方面的设备、装置、系统、计算机可读介质和方法的可能实现的架构、功能和操作。就此而言,流程图或框图中的每个框(或箭头)可以表示用于实现指定的逻辑功能的系统组件、软件组件或硬件组件的操作。还应注意的是,在一些替代实现方式中,框中提出的功能可不按图中提出的次序进行。例如,事实上,连续展示的两个框(或箭头)可以同时执行,或者有时候,框(或箭头)可以按照相反的顺序执行,这取决于所涉及的功能。还应注意的是,框图和/或流程图中每一个框(或箭头)以及框图和/或流程图中框(或箭头)的组合可以由基于专用硬件的系统执行,该系统执行指定的功能或动作,或者执行专用硬件和计算机指令的组合。
应当理解,流程图和/或框图的每个框(或箭头)以及流程图和/或框图中的框(或箭头)的组合可以由非瞬时性计算机指令来实现。可以将这些计算机指令提供给通用计算机(或计算设备)、专用计算机或其它可编程数据处理装置的处理器以产生机器,使得通过处理器执行的指令创建用于实现在流程图和/或框图中指定的功能/动作的机制。
如此处所述,本发明各方面至少可以采用以下形式:至少一个系统、具有执行存储在非瞬时性存储器中指令的一个或多个处理器的设备、计算机实现方法和/或存储了计算机指令的非瞬时性存储介质。
非瞬时性计算机可读介质包括所有类型的计算机可读介质,包括磁存储介质、光存储介质和固态存储介质,并且具体不包括信号。应理解,包括计算机指令的软件可以安装在具有计算机可读存储介质的计算设备中并与其一起出售。或者,可以获得软件并将其加载到计算设备中,包括通过光盘介质或从任何类型的网络或分配系统获得软件,例如包括从软件创建者拥有的服务器或者从软件创建者未拥有却使用的服务器获得软件。例如,该软件可以存储在服务器上以便通过因特网分发。
所述计算机可读介质的更多示例包括以下内容:便携式计算机磁盘、硬盘、随机存取存储器(randomaccessmemory,简称ram)、rom、可擦除可编程只读存储器(erasableprogrammableread-onlymemory,简称eprom,或闪存)、具有中继器的合适光纤、便携式只读光盘(compactdiscread-onlymemory,简称cd-rom)、光存储设备、磁性存储设备或上述任意合适组合。
本技术实施例中使用的非瞬时性计算机指令可以用一种或多种编程语言的任意组合编写。所述编程语言可包括面向对象的编程语言,例如java、scala、smalltalk、eiffel、jade、emerald、c++、cii、vb.net、python、r等,常规程序编程语言,例如“c”编程语言、visualbasic、fortran2003、perl、cobol2002、php、abap、动态编程语言(例如python、ruby和groovy)或其它编程语言。所述计算机指令可以完全在用户电脑(或计算设备)上执行,部分在用户电脑上执行,或作为独立的软件包,部分在用户电脑上执行,部分在远程计算机上执行,或完全在远程计算机或服务器上执行。在后一种场景下,远程计算机可以通过任何类型的网络连接到用户电脑,或者(例如,通过互联网服务提供商经由互联网)可以连接到外部计算机或在云计算环境连接或作为服务,例如软件即服务(softwareasaservice,简称saas)。
本文中所用的术语仅仅是出于描述特定方面的目的,并且并不打算限制本发明。除非上下文清楚说明,否则本文所用的单数形式“一”和“所述”包括其复数形式。应进一步了解,本说明书中所用的术语“包括”用于说明存在所述特征、整数、步骤、操作、元件和/或部件,但并不排除存在或添加一个或多个其它特征、整数、步骤、操作、元件、部件和/或它们的组合。
可以理解的是,本主题可以以许多不同的形式实现,并且不应视为对本文所阐述的实施例的限制。相反,提供这些实施例是为了使本主题内容更加透彻和完整,并将本发明完整地传达给本领域技术人员。事实上,本主题旨在覆盖包括在由所附权利要求书限定的本主题公开的精神和范围内的这些实施例的替代物、修改和等同物。另外,在本主题细描述中,阐述了许多特定细节以便提供对本主题的透彻理解。然而,所属领域的普通技术人员将清楚到,可以在没有这样具体细节的情况下实践本请求保护的主题。
虽然已经以特定于结构特征和/或方法论步骤的语言描述了主题,但是应该理解的是,权利要求书定义的主题不必局限于上面描述的具体特征或步骤(动作)。相反,上述具体的特征和步骤被公开作为实施权利要求的示例性方式。
- 还没有人留言评论。精彩留言会获得点赞!