分布式存储系统的数据修复方法及存储介质与流程
本发明涉及分布式存储领域,具体涉及用于乘积矩阵最小存储再生码的数据修复方法。
背景技术:
近年来随着互联网,大数据和云计算等新兴技术的飞速发展,对海量数据存储的需求也激增,使得分布式数据存储系统日益成为存储技术的主流。相比于单节点存储系统,分布式存储系统具有更高的可靠性、可用性和可扩展性。在分布式存储系统中,可能会有一个或若干个节点发生故障。在这种情况下,可以通过副本或纠删码等冗余技术来保证整个系统的服务不被中断。相比于简单的复制数据,纠删码的空间利用率相对较高,因此在业界被广泛使用。例如微软的azure和oceanstore等分布式存储系统均采用了纠删码。而纠删码中的最大距离可分码(maximumdistanceseparable,mds)由于能够最大化空间利用率,尤其为业界所重视。
当有节点发生故障时,分布式存储系统应当及时恢复出丢失的数据,以保持系统的冗余度,并避免长时间的“降阶读取”,即通过读取多个非原始的数据片段然后通过某种方法计算出所需的数据。这一过程通常通过替换或修复失效的节点,并在新节点上执行数据恢复操作来完成。由于一开始这些新节点对丢失的数据内容一无所知,它们需要从其他的未发生故障的节点处获得“辅助数据”(helperdata),而这些提供辅助数据的节点被称为“辅助节点”(assistantnode)。在一个比较繁忙的存储系统中,包括传输辅助数据在内的数据修复所需的带宽,简称“修复带宽”,其对整个系统的性能有至关重要的影响。因此,使修复带宽最小化是分布式存储系统设计优化的必要考量。基于网络编码思想的再生码恰好能够达到这一目标。其中,最小存储再生码(minimumstorageregeneratingcode,msr)作为一类在最小化修复带宽的同时,还能最大化空间利用率的再生码,具有十分重要的价值。
采用乘积矩阵(productmatrix,pm)的msr码构造简单巧妙,是一种重要的最小存储再生码。遗憾的是,原始的pmmsr码仅给出了单节点失效情况下的修复方法。而在实际工程中,经常会有多个节点同时失效的情况出现。针对这种情况,一种解决办法是像处理单节点失效那样,一个节点接一个节点地修复,这个方法虽然简单直接,但是会浪费带宽。另一种思路是,对多个失效节点进行联合修复,从而使整体所需的带宽最小化。该思路的另一个好处是,不必在节点失效时马上进行修复,可以等失效节点的数量达到某一个阈值,或者降阶读取持续了某一特定时间后再启动修复,这样可以进一步降低修复的开销。
一些现有的研究对这个问题进行了多方面的考虑,提出了一种采用“虚拟符号”的方法,能够同时修复多个失效节点,还证明了同时修复所需的最小带宽的下限。但是这种方法通常需要对复杂的方程组进行求解,运算开销巨大且难以实施。还有的研究人员提出了由代理协助的最小存储再生码,使用这种码进行修复时,辅助节点传输辅助数据之前无需对数据进行编码。但是这种码只能处理有1或2个失效节点的情形。针对任意失效节点数目和任意编码参数的联合修复方案仍未被提出。
另一类多数据块同时修复方法采用了节点间协作的策略。这类方法首先让新节点从正常节点下载辅助数据,然后在新节点之间交换数据。通过巧妙地设计编码的结构,可以减小修复带宽,甚至达到理论的下限。尽管这类方法从理论上可以使修复带宽最小化,实际应用却面临很大难度。这种“先下载-再交换”的方式增加了修复所需的时间和各种开销,需要复杂的协议来控制且容易出错。
从工程实现的角度讲,数据修复方法可分为两类:集中式和分布式。前者通常会指定一个代理节点,由代理节点负责收集辅助数据,重建丢失的数据并最终将修复好的数据传送到新的节点上。后者则相反,没有代理节点协助,由新节点自身负责收集和重建数据。也可以将二者结合起来,例如前面提到的节点间协作策略,但这样做复杂度较高。绝大多数已有的研究成果都采用了集中式修复,且只考虑了采集辅助数据所需的带宽。但实际上将重建的数据上传到新节点上也需要消耗带宽。这一点在已有的方法中并未考虑。有一些研究探讨了网络拓扑结构对修复带宽和修复策略的影响,但只在一些简单的拓扑结构,如直线级联,星形和网格结构上,获得了准确的数学表达式。
此外,现有的数据修复策略在重建数据的时候都使用了尽可能多的辅助节点,以达到降低修复带宽的目的。理论上也证明了,当系统中除失效节点外所有的正常节点,或称“幸存节点”都作为辅助节点参与数据重建时,所需的带宽最小。但在实际系统中,使用更多的辅助节点意味着更大的延迟和开销,因此在综合考虑多方面性能的情况下,使用的辅助节点数目并非越多越好。
技术实现要素:
本申请提供一种用于乘积矩阵的最小存储再生码的分布式存储系统的数据修复方法,要解决的技术问题是,提供一种分布式存储系统的数据修复方法,能够对分布式存储系统中的多个失效节点进行同时修复。
一种分布式存储系统的数据修复方法,用于分布式存储系统有节点失效时的数据修复过程,分布式存储系统采用分布式存储系统的编码方法。本申请中提供了两种使用乘积矩阵的最小存储再生码(pmmsr)的数据修复方法,分别为集中式和分布式。在集中式数据修复模式下,根据失效节点数量选取辅助节点,辅助数据子块的收集、修复矩阵运算和重建丢失数据块过程由中心代理节点完成;在分布式模式下,根据失效节点数量选取辅助节点,每个新节点重建其所替换的失效节点上存储的数据块,辅助数据子块收集、修复矩阵运算和重建丢失数据块过程由新节点完成。
数据修复过程包括如下步骤:
步骤1:从正常节点中选取辅助节点,用辅助节点计算得到辅助数据子块,并将辅助数据子块发送给重建数据的节点,所选取的辅助节点的数量与待修复的失效节点的数量有关;
步骤2:根据pmmsr码和丢失的数据信息,计算修复矩阵;
步骤3:通过将修复矩阵与辅助数据子块相乘得到丢失的数据块,完成数据块重建。
在实际操作过程中,为了得到修复矩阵,需要向丢失列表中增加未包含丢失数据块的节点信息,或用未包含丢失数据块的节点信息替换原丢失列表中的节点信息。例如在分布式模式下,一个新节点不仅可以重建自己所替换的失效节点上存储的数据块,还可能同时重建其他新节点所需的数据块。这种情况下,该新节点可以选择将额外重建的数据块发送给需要的其他新节点,以免这些新节点自己去重建这些数据块。这样可以进一步降低修复带宽和计算开销,
本发明的有益效果是:通过使用乘积矩阵的最小存储再生码提供的分布式存储系统的数据修复方法,能够同时重建一个或多个数据块,克服了最小修复带宽理论下限难以实现的困难,同时不需要在新节点之间交换数据,能够在任意数量的失效节点和任意编码参数的情况下对数据进行修复。
附图说明
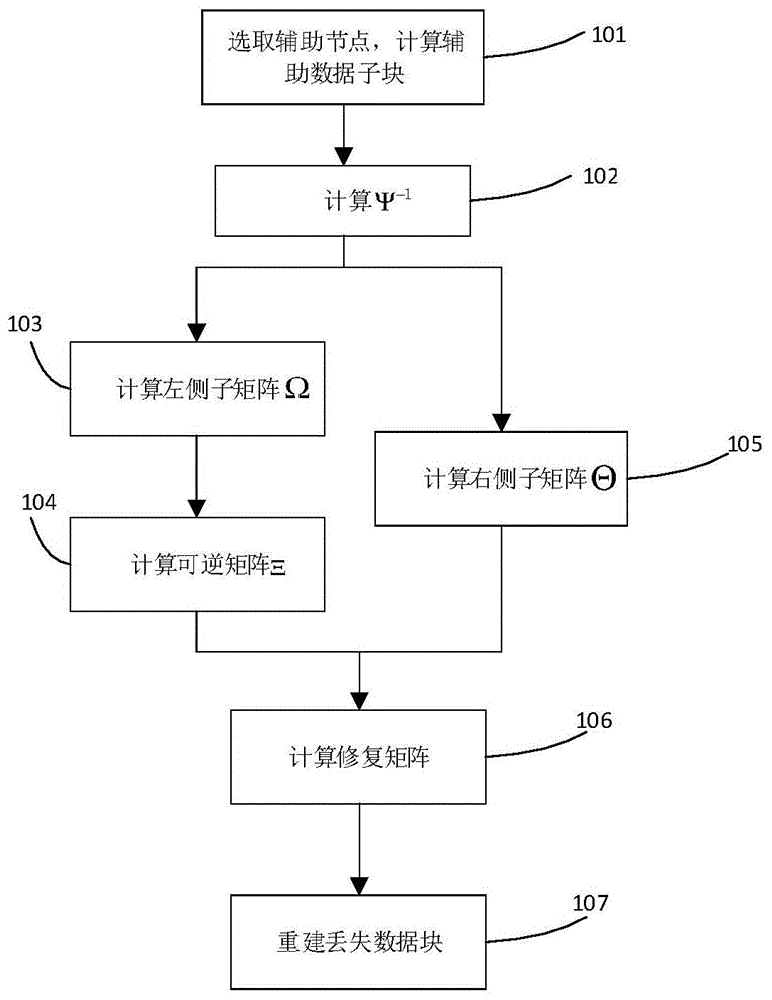
图1为数据块修复计算过程的流程图;
图2为集中式修复模式下数据修复的系统模型图;
图3为分布式修复模式下数据修复的系统模型图;
图4为修复矩阵的左侧子矩阵的计算过程图;
图5为修复矩阵的右侧子矩阵的计算过程图;
图6为集中式修复模式下数据修复算法流程图;
图7为分布式修复模式下数据修复算法流程图。
具体实施方式
下面通过具体实施方式结合附图对本发明作进一步详细说明。在以下的实施方式中,很多细节描述是为了使得本申请能被更好的理解。然而,本领域技术人员可以毫不费力的认识到,其中部分特征在不同情况下是可以省略的,或者可以由其他方法所替代。在某些情况下,本申请相关的一些操作并没有在说明书中显示或者描述,这是为了避免本申请的核心部分被过多的描述所淹没,而对于本领域技术人员而言,详细描述这些相关操作并不是必要的,他们根据说明书中的描述以及本领域的一般技术知识即可完整了解相关操作。
另外,说明书中所描述的特点、操作或者特征可以以任意适当的方式结合形成各种实施方式。同时,方法描述中的各步骤或者动作也可以按照本领域技术人员所能显而易见的方式进行顺序调换或调整。因此,说明书和附图中的各种顺序只是为了清楚描述某一个实施例,并不意味着是必须的顺序,除非另有说明其中某个顺序是必须遵循的。
在本发明实施例中,提出了一种用于乘积矩阵最小存储再生码(pmmsr)的分布式存储系统的数据修复方法。基本思路是构造出能够适用于任何数量的失效节点和任意编码参数的修复矩阵,将辅助数据与修复矩阵作简单相乘从而得到丢失的数据块。
本发明实施例中提供了两种用于pmmsr码的数据修复方法,包括集中式和分布式。如图2和图3分别描述了集中式和分布式修复模式下,数据块联合修复的系统模型。在一个分布式存储系统中,设存储节点的总数为n,编号分别为n1,n2,.....,nn,失效节点的个数为t。如图2和图3所示,不失一般性地假定前t个节点n1,n2,.....,nt失效。在集中式修复模式下,有一个中心代理负责收集辅助数据和重建丢失的数据,然后将重建好的数据发送到t个新节点上。而在分布式的修复模式下,由t个新节点自己独立地完成收集辅助数据和重建丢失数据的过程,且每个新节点只需要重建自己所替代的失效节点上丢失的数据。
为了叙述方便,这里先给出本发明中所用到的符号及其定义。首先,一个使用乘积矩阵的最小存储再生码(pmmsr)用c(n,k,d)表示,其中n是节点的总数,k是“系统节点”的数量,那么m=n-k即为“校验节点”的数量。其中,系统节点是指存放未编码数据块的节点,校验节点是指存放编码数据块的节点。d为“修复度”,指当只有一个失效节点时,修复数据所需要的辅助节点的数目。
设待存储的数据总量为b。根据pmmsr码的要求,编码时首先将长度为b的数据等分为k段,然后编成n个数据块,分别用b1,b2,...,bn表示,其数据块编号分别为1,2,...,n。每个数据块bi包含α个子块si1,si2,...,siα。根据msr码的相关理论,有如下两个等式:
α=d-k+1(1)
b=kα=k(d-k+1)(2)
pmmsr码要求d≥2k-2,因此有n≥d+1≥2k-1,以及α≥k-1。
针对这种一般情形,数据总量b将被基于扩展的pmmsr码c(n',k',d')编码成n'个数据块,其中n'=n+δ,k'=k+δ并且d'=d+δ。δ表示扩展增加的虚拟节点的数量,其选择应使得d'=2k'-2,因此有:
δ=d-(2k-2)(3)
以及
d'=2(k+δ)-2=2(d-k+1)=2α(4)
pmmsr码通过如下的公式来构建:
c=ψm(5)
其中m是如下式所示的d'×α维的消息矩阵:
其中s1和s2均为α×α维对称矩阵,其上三角部分的(α+1)α/2个元素分别由不同的数据子块充当。ψ=[φλφ]则为n'×d'维编码矩阵,φ的第i行用φi表示。λ是如下所示的n'×n'对角阵:
c是编码后得到的n'×α维矩阵,其每个元素都是编码后得到的数据子块,c的第i行为:
其中
当有节点失效时,在修复数据之前,首先为系统添加δ个虚拟节点。这些虚拟节点上的数据全部为0。用{ni|1≤i≤n'}表示由虚拟节点和真实节点共同组成的集合,其中n1~nδ为虚拟节点,而nδ+1~nn'是真实节点。因此可以认为{ci|1≤i≤n'}分别存储在n'个节点上。需要指出的是,本实施例中所说的“节点”既可以是物理上的,也可以是逻辑上的,也就是说,多个逻辑节点可以位于一个或多个物理机器上,不影响本发明的有效性。其次,本发明中所提到的虚拟节点并非真实存在,其是为了理论推理而臆想出来的,是发明者的思维过程,也为了便于本领域技术人员理解。
设一共有t≥1个失效节点。所有丢失数据块的编号所组成的集合x={xi|i=1,...,t,δ<xi≤n'}被定义为丢失列表。用
ne={nj|nj∈naorj∈x}(9)
由上面的叙述可以看出集合ne中有d'+1个元素。
在修复数据时,每个辅助节点nj∈na首先计算自己存储的数据块cj(将其视为由子块[cj1,cj2,...,cjα]组成的向量)与
然后将这些编码后的子块作为辅助数据发送给重建数据的节点。这样重建数据的节点将获得一共t(d'-t+1)个辅助子块。需要指出的是,上述提到的从正常节点中选择d'-t+1个节点作为辅助节点,前提条件是假设t个失效节点被同时修复,实际应用中也可根据实际情况选择待修改的节点,这种情况下选择的辅助节点个数将会发生变化,具体情况将在下述集中式和分布式修复模式下介绍。
本发明中,数据重建节点通过“修复矩阵”来恢复丢失的数据块。修复矩阵通过如下方式得到。
首先,对每一个xi,xj∈x,j≠i,按照下式(11)计算α×α矩阵
其中
公式(12)中的
也就是说,(13)中的
下一步,首先用xi=x|xi表示丢失列表x去掉xi后剩余编号的有序集合,用
其中
结合上面的计算,可以得到
其中,
是每个辅助节点通过计算自己存储的数据块与
对于每个xi,向量
令
如果ξx矩阵可逆,则可以通过如下式(18)算得修复矩阵:
算出修复矩阵后,用rx左乘辅助数据子块组成的向量
公式(18)给出的修复矩阵适用于任意t<min{k,α}。对于t≥min{k,α}的情形,可以用解码的方式来重建丢失的数据,也就是说,从正常节点中任选k个节点作为辅助节点,从所有辅助节点上下载共k×α个数据子块,然后对这些数据子块作解码操作,得到原始数据,然后将得到的原始数据编码成丢失的数据块。但对于t>m的情形,丢失的数据将无法恢复,因为由m=n-k可知此时正常节点的数目n-t<k。
另外,如果矩阵ξx不可逆,则无法通过公式(18)计算出修复矩阵。对于这个问题,有几种方法可以解决,包括但不限于:1)向x中增加一个或若干个节点,使ξx变为可逆;2)将x中的某个或某些节点替换成其他节点,使ξx变为可逆;3)用解码的方式实现数据重建。由于这种情况出现的概率很小,无论采用何种解决办法,对整体性能的影响都是微乎其微的。采用第1)和/或2)种方法时,实际修复的数据块不仅包括真正丢失的数据块,还包括新增加或新替换的节点上的数据块。
修复矩阵的计算过程如图1所示步骤102至步骤106,其中每一步的具体操作如下:
第1步:对每一个xi∈x,按照公式(9)和(13)计算
第2步:对每个xi,xj∈x,j≠i,按照图4和公式(11)计算ωi,j;
第3步:基于第2步得到的结果,按照公式(17)构造矩阵ξx;
第4步:对每个xi∈x,按照图5和公式(14)计算θ'i,并将得到的θ'i,i=1,...,t按照公式(18)排成广义对角阵;
第5步:如果ξx可逆,按照公式(18)用
如图1所示,第2,3步执行时可以在第4步之前,也可以在第4步之后。
下面将针对集中式和分布式两种数据修复模式,分别对分布式存储多数据块联合修复方法进行具体描述。
对于采用集中式的修复模式,用于pmmsr再生码的多数据块联合修复算法如图6所示。其中每一步的具体操作如下所述。由于是集中式的修复,除了提供辅助数据以外,其他的操作都在中心代理节点上进行。数据重建后,中心代理节点还需将重建后的数据发送到对应的新节点上。当t>m时,丢失的数据将无法恢复,为了简洁起见,t>m的情形这里不再描述。如图6,步骤600,判断t≥min{k,α}是否成立。
(1)如果t≥min{k,α}:
步骤611:从正常节点中任选k个节点作为辅助节点,中心代理节点向辅助节点发起请求,要求辅助节点将自己存储的数据块发送至中心代理节点;
步骤612:中心代理节点等待,直至收到所有的k×α个辅助数据子块;
步骤613:中心代理节点对收到的数据子块作解码,得到原始数据;
步骤614:中心代理节点用编码的方式重建丢失的数据块,并将重建好的数据库发送至t个新节点上。
(2)如果t<min{k,α}:
步骤621:按照图1步骤102至104计算ξx;
步骤622:如果ξx不可逆,任选下面a)到c)的3种操作之一,否则执行下一步;
a)返回至步骤611,用解码的方式实现数据重建;
b)向x中增加一个节点,重新计算ξx,如果可逆,到步骤623,否则执行a),b)或c);
c)将x中的一个节点替换为x之外的某个节点,重新计算ξx,如果可逆,到步骤623,否则执行a),b)或c);
设x中元素的个数为z,如果在执行b)和/或c)的过程中,已经穷尽所有z<min{k,α}的可能组合,须执行a);
步骤623:如图1步骤101从正常节点中选择d-t+1个节点作为辅助节点,中心代理节点向辅助节点发起请求,要求每个辅助节点按照公式(10)计算并提供t个辅助数据子块;
步骤624:中心代理节点等待,直到收到所有的t(d-t+1)个辅助数据子块;
步骤625步:按照图1步骤106计算修复矩阵rx;
步骤626:按照公式(16)对收到的辅助数据子块进行重新排列,使之与公式(18)中的广义对角阵相对应;
步骤627:如图1步骤107所示用修复矩阵rx左乘步骤626中重排得到的辅助数据子块组成的向量,重建丢失的数据块,并将重建好的数据发送至t个新节点上。
对于分布式的修复模式,每个新节点只需要重建其所替换的失效节点上存储的数据块。如果t≤n-d,则一个新节点可以选择d个正常节点作为辅助节点,从每个辅助节点处获得1个编码后的辅助数据子块,进而重构出其丢失的数据块,这样的修复带宽总共为td个子块。如果t>n-d,那么对于一个新节点来说,只重建自己丢失的1个数据块就行不通了,因为辅助节点的个数不够,这时每个新节点至少需要同时重建t-(n-d)+1个数据块,需要的辅助节点的数目为n-t。
在分布式的修复模式下,用于pmmsr再生码的多数据块联合修复算法如图7所示。其中每一步的具体操作如下所述。除了提供辅助数据以外,其他的操作都在新节点上进行。
如图7,步骤700,检测t的大小。
(1)如果t≥n-d-1+min{k,α}:
步骤711:从正常节点中任选k个节点作为辅助节点,新节点向辅助节点发起请求,要求辅助节点将自己存储的数据块发至新节点;
步骤712:新节点等待,直至收到所有的k×α个数据子块;
步骤713:对收到的辅助数据子块作解码,得到原始数据;
步骤714:用编码的方式重建丢失的数据块,返回。
(2)如果t≤n-d:
步骤721:从正常节点中任选d个节点作为辅助节点,新节点向辅助节点发起请求,要求辅助节点按照公式(10)各自计算并提供1个辅助数据子块;
步骤722:新节点等待,直到收到全部d个辅助数据子块;
步骤723:按照图1步骤106所示计算修复矩阵
步骤724:按照公式(16)对收到的辅助数据子块进行重新排列,使之与公式(18)中的广义对角阵相对应;
步骤725:用修复矩阵
(3)其他情况
步骤731:任选另外u=t-n+d个丢失的数据块
步骤732:按照图1所示步骤计算ξx;
步骤733:如果ξx不可逆,任选下面a)到c)的3种操作之一,否则执行下一步;
a):返回至第1.1步,用解码的方式实现数据重建;
b):向x中增加一个节点,重新计算ξx,如果可逆,到步骤734,否则执行a),b)或c);
c):将x中的一个节点替换为x之外的某个节点,重新计算ξx,如果可逆,到步骤734,否则执行a),b)或c);
设x中元素的个数为z,如果在执行b)和/或c)的过程中,已经穷尽所有z<min{k,α}的可能组合,须执行a);
步骤734:将n-t个正常节点全部选为辅助节点,新节点向辅助节点发起请求,要求每个辅助节点按照公式(10)计算并提供u+1个辅助数据子块;
步骤735:新节点等待,直到收到所有的(n-t)(u+1)个辅助数据子块;
步骤736:按照图1步骤106计算修复矩阵rx;
步骤737:按照公式(16)对收到的辅助数据子块进行重新排列,使之与公式(18)中的广义对角阵相对应;
步骤738:用修复矩阵rx左乘步骤737中重排得到的辅助数据子块组成的向量,重建丢失的数据块,返回。
需要说明的是,如果应用上述算法,当t>n-d时,一个新节点不仅重建了自己所替换的失效节点上存储的数据块,还可能同时重建了其他新节点所需的数据块。这时该新节点可以选择将额外重建的数据块发送给需要的其他新节点,以免这些新节点自己去重建这些数据块。这样可以进一步降低修复带宽和计算开销,但是需要节点间的协调配合,而且可能增加修复时间,已经属于协作式修复的范畴。实际应用中应根据系统性能需要进行权衡选择。
以上应用了具体实施例对本发明进行阐述,只是用于帮助理解本发明,并不用以限制本发明。对于本发明所属技术领域的技术人员,依据本发明的思想,还可以做出若干简单推演、变形或替换。
- 还没有人留言评论。精彩留言会获得点赞!