运营管理方法及运营管理系统与流程
本发明涉及运营管理方法及运营管理系统,尤其涉及针对it系统运营管理中取得的数据的运营管理方法及运营管理系统。
背景技术:
随着虚拟机的普及和云计算等新的系统形态的出现,it系统的运营管理正变得日益复杂。另外,随着it系统所处理的数据量的爆发式增长,it系统的规模也逐年扩大,it系统管理软件所处理的对象数量(例如存储装置所提供的卷数)也不断增多。在管理具有复杂大量的数据的it系统时,需要控制管理成本。
关于如何控制管理成本,有如下的现有技术。例如,有的现有技术针对计算机系统中的构成要素的性能值分别设定阈值,在违反阈值的情况下判断为发生了问题,有的现有技术针对计算机系统中的构成要素的各种故障建立事件,并分析所发生的多个故障事件的因果关系,从而检测导致故障发生的事象(例如专利文献1)。
然而,上述现有技术都是在问题发生了之后以发生问题的事件作为契机实施的管理技术。为了控制管理成本,迫切要求在问题发生之前就能够发现其预兆,并事先进行处理。
在此能够应用的技术之一是机器学习技术。通过收集it系统的各对象中的各种信息并作为学习数据来学习,能够针对it系统内的任意要素与其他要素之间的关联,确定最符合学习数据的预测模型(函数等)。例如,非专利文献1通过学习来求出预测函数,该预测函数能够根据并行处理数量等关于进行处理时的设定的参数、以及要处理的数据的大小等关于处理对象的参数,预测it系统中执行的处理的响应性能。通过利用该函数,例如能够根据并行处理数量和数据大小来估计处理的响应时间,因此能够决定执行处理的计划。另外,能够估计提供所需的响应性能所要的并行处理数量,因此还能够估计提供所需的响应性能所要的资源量。
专利文献1:us7107185b1
非专利文献1:statistics-drivenworkloadmodelingforthecloud,archanaganapathi,universityofcaliforniaatberkeley,icde2010
技术实现要素:
在非专利文献1等上述现有技术中,为了针对it系统构建预测模型,需要考虑实际构成,但在it系统每次发生变化时,都需要重新从头构建模型,造成成本大幅上升。另外,在大规模且复杂的系统的情况下,决定以何种度量和构成单位来构建预测模型会耗费大量时间。
对此,上述非专利文献1所公开的技术是用于构成变化较少的环境,并未想到系统构成频繁变更的情况。然而,随着虚拟机的普及和云计算等新系统形态的出现,在实际的it系统中构成变得更容易变更。另外,以往难以实现的频繁(例如1天10次以上)的应用部署随着例如devops(development(开发)和operations(运营)的组合)的普及而变成现实,it系统构成的变更频度进一步上升。如果it系统中的构成发生变更,则在构成发生变更之后需要再次进行长时间的学习。而且,在构成发生变更后一段时间内,机器学习的精度难以提高,无法进行高效的管理业务。
本发明针对现有技术中上述技术问题中的至少一个,其目的在于,快速地自动决定以何种度量和构成单位来进行机器学习。
为此,本发明的实施方式提供一种运营管理方法,对包括多个构成要素的计算机系统的运营进行管理,其特征在于,包括:实际构成提取步骤,根据所述计算机系统的构成信息,提取所述计算机系统中的符合已保持的通用规则所表示的关联的实际构成,该通用规则表示某个构成类别的1个以上的度量与相对于所述构成类别的1个以上的度量在性能上存在依赖关系的构成类别的1个以上的度量之间的关联;展开规则生成步骤,基于提取的实际构成,根据所述通用规则生成与所述实际构成对应的展开规则,该展开规则表示某个构成要素的1个以上的度量与相对于所述构成要素的1个以上的度量在性能上存在依赖关系的构成要素的1个以上的度量之间的关联;以及学习单位决定步骤,基于生成的所述展开规则,决定学习单位,该学习单位是针对所述计算机系统进行机器学习的单位。
由此,通过使用基于性能依赖关系的通用规则,不需要由管理者决定应利用何种度量架构预测模型,而能够快速地自动决定以何种度量和构成单位来进行机器学习,能够减少后续处理中建立预测模型所花费的时间。
上述运营管理方法也可以还包括:学习结果汇集步骤,汇集具有相同条件的多个学习单位各自的学习结果。
由此,在具有相同条件的学习规则的系统之间共享学习数据,建立共通的预测模型,能够迅速地提供基于学习对计算机系统的高效监视。
上述运营管理方法也可以是,所述相同条件包括如下条件中的至少一种:所述多个学习单位中的各个学习单位分别对应于根据相同的所述通用规则生成的多个展开规则中的各个展开规则;在所述多个学习单位所对应的多个展开规则之间构成要素的连接关系相同;在所述多个学习单位所对应的多个展开规则之间构成要素具有相同或相似的硬件规格或类别。
由此,能够根据多种多样的条件对学习单位进行分组,从而在各组之间共享学习数据,建立共通的预测模型,能够根据系统状况或用户需求,更灵活地提供基于学习对计算机系统的高效监视。
上述运营管理方法也可以在所述学习结果汇集步骤中,汇集具有第一相同条件的多个学习单位各自的学习结果,并且汇集具有所述第一相同条件且具有不同于所述第一相同条件的第二相同条件的多个学习单位各自的学习结果,由此分级地汇集多个学习单位各自的学习结果。
一般而言,构成或设定类似的构成的学习构成也类似,因此通过多级分组,与仅利用通用规则等进行分组的情况相比,同组的构成更接近,预测模型的适合率更高。
上述运营管理方法也可以利用学习结果中的参数来汇集具有相同条件的多个学习单位各自的学习结果。
由此,利用具有相同条件的学习单位的参数共享学习数据来架构共通的预测模型,能够建立适合率更高的共通预测模型。
上述运营管理方法也可以在所述学习结果汇集步骤中,将与新的学习单位或构成变更后的学习单位具有相同条件的其他学习单位的学习结果,用于生成与该新的学习单位对应的预测模型的初始值或与该构成变更后的学习单位对应的预测模型的初始值。
由此,在具有相同条件的学习单位之间共享学习数据来架构共通的预测模型,将其用作构成发生了变更的学习单位的预测模型的初始值,能够缩短新追加构成时或构成发生了变更时架构预测模型(完成学习)所花费的时间。由此,能够迅速地提供基于学习对计算机系统的高效监视。
上述运营管理方法也可以还包括:学习单位删除步骤,在所述计算机系统的实际构成发生了变更之后,删除由于该变更而不再存在的学习单位的信息。
由此,能够根据计算机系统的构成变更自动地删除无用的学习单位的信息,节约管理负荷。
上述运营管理方法也可以还包括:性能监视分析步骤,基于与每个所述学习单位对应的预测模型,提供用于性能监视分析的事件通知及/或性能分析信息。
由此,在性能监视分析画面中,能够按每个学习单位显示警报通知、性能分析画面等。由此,无论计算机系统的构成如何复杂,都能够以共通且简明的形式来进行监视和分析。
上述运营管理方法也可以还包括:通用规则生成步骤,参照表示所述计算机系统所包括的构成要素的度量有可能发生的事件之间的关联的规则,针对每个在相同连接关系下观测事象相同或相似的事件,提取造成该事件的原因的观测事象并制作规则,从而生成通用规则。
由此,能够基于现有的计算机系统的管理中使用的信息即问题分析规则,自动地生成通用规则,不需要由管理者自身生成通用规则,节约了成本和劳力。
本发明的实施方式还提供一种运营管理系统,具备对包括多个构成要素的计算机系统的运营进行管理的至少1个管理计算机,其特征在于,由管理计算机执行如下处理:实际构成提取处理,根据所述计算机系统的构成信息,提取所述计算机系统中的符合已保持的通用规则所表示的关联的实际构成,该通用规则表示某个构成类别的1个以上的度量与相对于所述构成类别的1个以上的度量在性能上存在依赖关系的构成类别的1个以上的度量之间的关联;展开规则生成处理,基于提取的实际构成,根据所述通用规则生成与所述实际构成对应的展开规则,该展开规则表示某个构成要素的1个以上的度量与相对于所述构成要素的1个以上的度量在性能上存在依赖关系的构成要素的1个以上的度量之间的关联;以及学习单位决定处理,基于生成的所述展开规则,决定学习单位,该学习单位是针对所述计算机系统进行机器学习的单位。
上述运营管理系统也可以是,所述运营管理系统具备多个管理计算机,在所述多个管理计算机之间通过进行远程调用,分担所述实际构成提取处理、所述展开规则生成处理以及所述学习单位决定处理。
由此,能够灵活地切换要执行构成信息管理、性能信息管理、学习单位分割、学习等处理的站点,由此能够更迅速地实施以往花费时间的学习处理。
上述运营管理系统也可以是,所述多个管理计算机至少包括第一管理计算机和第二管理计算机,所述第一管理计算机还执行如下处理:学习结果汇集处理,汇集具有相同条件的多个学习单位各自的学习结果;以及学习结果分发处理,将汇集后的学习结果分发至所述第二管理计算机;所述第二管理计算机还执行如下处理:学习结果利用处理,将从所述第一管理计算机接收的学习结果,用于生成与具有所述相同条件的学习单位对应的预测模型的初始值。
由此,通过跨站点地管理/共享每个通用学习单位的预测模型,能够提高上述各实施方式中示出的各种效果。
本发明的运营管理方法的上述各方式及其效果,也能够通过运营管理系统、通过程序模块或硬件模块实现上述运营管理方法的各步骤的运营管理装置、运营管理电路、使计算机执行运营管理方法的运营管理程序、或者存储了运营管理程序的记录介质实现。
附图说明
图1是第一实施方式的运营管理系统的概要的说明图。
图2是第一实施方式的运营管理方法的一个具体例的流程图。
图3是第二实施方式的运营管理系统的概要的说明图。
图4表示第二实施方式的系统构成的一个具体例。
图5表示第二实施方式的构成信息表的一个具体例。
图6表示第二实施方式的性能履历信息表的一个具体例。
图7a、图7b及图7c表示第二实施方式的通用规则表的一个具体例。
图8a、图8b及图8c表示第二实施方式的展开规则表的一个具体例。
图9表示第二实施方式的分学习单位预测模型表的一个具体例。
图10表示第二实施方式的分通用学习单位预测模型表的一个具体例。
图11是第二实施方式的运营管理方法的一个具体例(学习单位分割处理)的流程图。
图12是第三实施方式的运营管理方法的一个具体例(学习单位分割处理)的流程图。
图13是第四实施方式中生成预测模型的处理(预测模型生成处理)的一个具体例的流程图。
图14是第五实施方式的基于预测的性能监视分析处理的一个具体例的流程图。
图15表示第五实施方式的基于预测的性能监视分析画面的一个具体例。
图16a、图16b及图16c表示第六实施方式的问题分析规则表的具体例。
图17是第六实施方式的通用规则生成处理的一个具体例的流程图。
图18是第七实施方式的运营管理系统的概要的说明图。
具体实施方式
以下结合附图、实施方式及具体例对本发明进行更详细的说明。其中,下述说明只是为了方便理解本发明而举出的例子,不用于限定本申请的范围。实施方式及具体例中说明的各要素及其组合不一定都是解决本发明所要解决的技术问题的必要技术特征。装置和系统所具备的部件可以根据实际情况变更、删减或追加,方法的步骤可以根据实际情况变更、删减、追加或改变顺序。在附图中。针对相同或等同的要素赋予相同的标记。另外,针对本发明中的信息有时采用“……表”等来说明,但本发明中的信息不限于表等数据结构,也可以采用其他数据结构。由于不依赖于数据结构,因此也有将“……表”称之为“……信息”的情况。在说明各信息的内容时,“识别信息”、“识别符”、“名称”、“id”等表现可以相互替换。
由于程序是由处理器执行并利用存储器、通信端口(通信设备、管理接口、数据接口)来进行规定的处理,所以下文的说明中由程序执行的处理也可以作为由处理器执行的处理,或者也可以作为由管理计算机(管理服务器)等计算机、信息处理装置执行的处理。或者,程序的一部分或全部也可以由专用硬件实现。因此,本发明中的“……程序”也可以称为“……处理”,或者作为程序模块或硬件模块而称为“……部”、“……单元”或“……电路”等。
另外,各种程序也可以由程序分发服务器通过网络分发并被安装在计算机中,或者被记录在计算机可读取的记录介质中并被安装在计算机中。另外,各种程序也可以在管理程序型(hypervisor型)或容器型(container型)等虚拟环境中执行。
在说明书中,有时将管理计算机系统并显示本发明的显示信息的一个以上的计算机的集合称为运营管理系统。在管理计算机显示本发明的显示信息的情况下,管理计算机自身成为运营管理系统。另外,管理计算机与显示用计算机的组合也可以成为运营管理系统。另外,为了提高管理处理的速度和可靠性,也可以利用多台计算机实现与管理计算机等同的处理,此时该多台计算机成为运营管理系统,在利用显示用计算机进行显示的情况下运营管理系统还包括显示用计算机。
(第一实施方式)
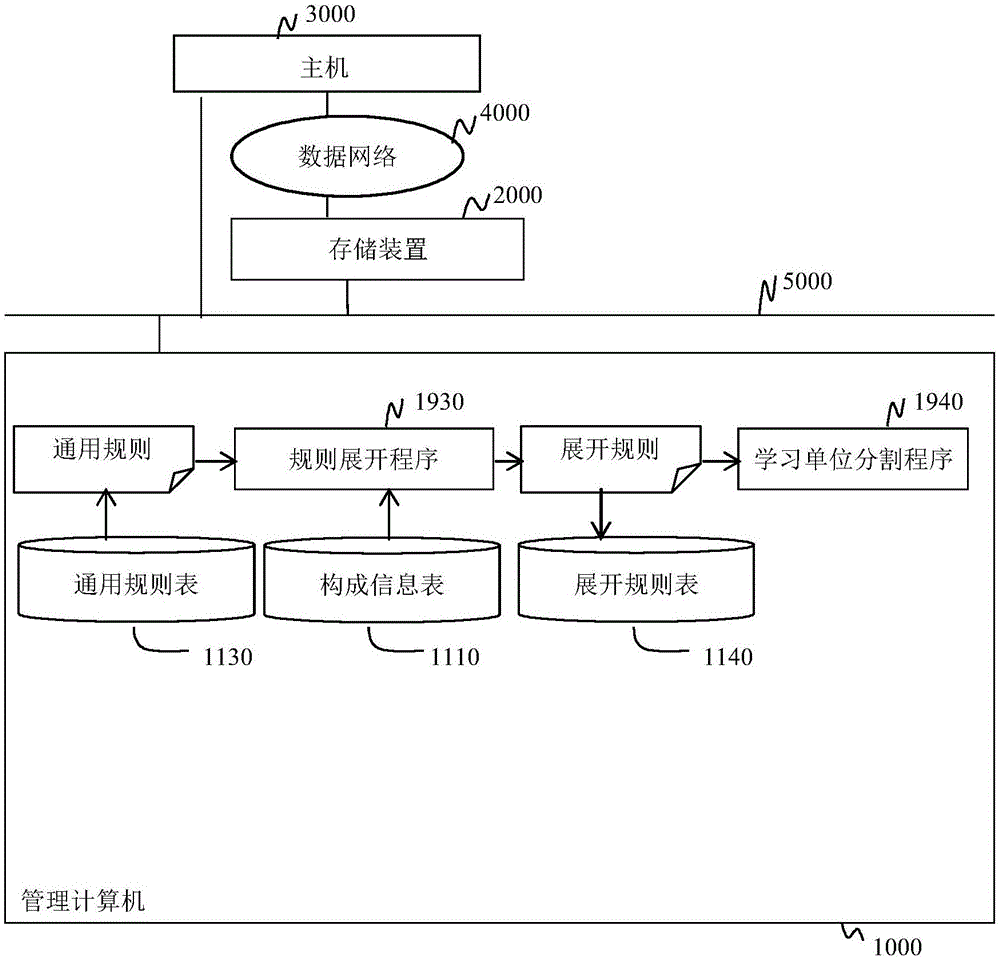
具体说明本发明的第一实施方式。图1是第一实施方式的运营管理系统的概要的说明图。如图1所示,运营管理系统具备至少1个管理计算机1000,该管理计算机1000对包括多个构成要素的计算机系统的运营进行管理。在此,计算机系统包括经由数据网络4000连接的存储装置2000和主机(主计算机)3000,但不限定于此。
如图1所示,管理计算机1000能够执行规则展开程序1930和学习单位分割程序1940,另外存储有通用规则表1130、构成信息表1110和展开规则表1140。通用规则表1130存放通用规则,通用规则表示某个构成类别的1个以上的度量与相对于该构成类别的1个以上的度量在性能上存在依赖关系的构成类别的1个以上的度量之间的关联。构成信息表1110存放计算机系统中的构成要素的信息以及构成要素之间的关联信息。展开规则表1140存放展开规则,展开规则表示计算机系统中的某个构成要素的1个以上的度量与相对于该构成要素的1个以上的度量在性能上存在依赖关系的构成要素的1个以上的度量之间的关联。
以下说明本实施方式的运营管理系统所执行的运营管理方法。图2是第一实施方式的运营管理方法的一个具体例的流程图。如图2所示,管理计算机1000通过执行规则展开程序1930,进行实际构成提取处理,根据构成信息表1110中存放的计算机系统的构成信息,提取计算机系统中的符合由通用规则表1130保持的通用规则所表示的关联的实际构成(实际构成提取步骤s10)。接着,管理计算机1000通过执行规则展开程序1930,进行展开规则生成处理,基于在步骤s10中提取的实际构成,根据通用规则生成与实际构成对应的展开规则(展开规则生成步骤s20)。接着,管理计算机1000通过执行学习单位分割程序1940,进行学习单位决定处理,基于在步骤s20中生成的展开规则,决定针对该计算机系统进行机器学习的学习单位(学习单位决定步骤s30)。
根据本实施方式的运营管理系统及运营管理方法,通过使用基于性能依赖关系的通用规则,不需要由管理者决定应利用何种度量架构预测模型,而能够快速地自动决定以何种度量和构成单位来进行机器学习,能够减少后续处理中建立预测模型所花费的时间。
(第二实施方式)
以下说明本发明的第二实施方式。本实施方式在第一实施方式的基础上,在生成学习单位时追加了分组(汇集)。在本实施方式中,关于与第一实施方式的相同或等同的部分省略说明。
图3是第二实施方式的运营管理系统的概要的说明图。如图3所示,本实施方式的运营管理系统在第一实施方式的基础上,追加了学习程序1950、性能履历信息表1120、分学习单位预测模型表1150。如第一实施方式所述,规则展开程序1930参照由通用规则表1130规定的通用规则、以及构成信息表1110,生成展开规则,并将展开规则存放至展开规则表1140。进而,学习单位分割程序1940基于生成的展开规则决定学习单位,要求学习程序1950以决定的学习单位进行学习。进而,学习程序1950参照构成信息表1110及性能履历信息表1120进行学习,将学习结果存放至分学习单位预测模型表1150,从而建立预测模型。
另外,在随着构成发生了变更而学习单位也发生变更时,学习单位分割程序1940参照分学习单位预测模型表1150。在与构成变更后的新学习单位属于同一组的预测模型已经存在于分学习单位预测模型表1150中的情况下,将该预测模型的信息设定为新学习单位的初始值,从而缩短学习完预测模型所花费的时间。
以下说明本实施方式的系统构成的一个具体例。图4表示第二实施方式的系统构成的一个具体例。该具体例的运营管理系统具备1台以上的管理计算机1000,该运营管理系统所管理的计算机系统具备1台以上的主机3000及存储装置2000。
主机3000及存储装置2000经由san(存储区域网络)等数据用网络4000相互连接。san的一个具体例是光纤通道。管理计算机1000、存储装置2000及主机3000经由ip(互联网协议)等管理用网络5000相互连接。
管理计算机1000具备内存1100、通信设备1200、处理器1300、输出设备1400、输入设备1500和存储设备1600,上述部件通过管理计算机1000内的内部总线1700相互连接。内存1100可以存放构成信息表1110、性能履历信息表1120、通用规则表1130、展开规则表1140、分学习单位预测模型表1150、分通用学习单位预测模型表1160、问题分析规则表1170、构成管理程序1910、性能监视分析程序1920、规则展开程序1930、学习单位分割程序1940、学习程序1950、通用规则生成程序1960中的全部或一部分。通信设备1200用于将管理计算机1000连接至管理用网络5000。管理计算机1000能够经由管理用网络5000与主机3000上运行的程序、存储装置2000上运行的程序进行通信。处理器1300执行在内存1100上展开的各种程序。输出设备1400输出由管理计算机1000执行的处理结果,例如是显示器等,也可以是与其他显示设备(例如显示用计算机)连接的输出接口。输入设备1500供管理者向管理计算机1000输入指示,例如是键盘、鼠标等。存储设备1600可以是用于存储信息的非易失性存储介质,例如是hdd(硬盘驱动器)、ssd(固态驱动器)、闪存等存储介质。
在图4所示的具体例中,各种程序和表存放在内存1100中,但也可以存储在存储设备1600或其他存储介质(未图示)中。此时,处理器1300在执行程序时将目标程序读取至内存1100上并执行。另外,也可以在存储装置2000的内存2100中存放上述的程序及表,由存储装置2000或主机3000执行所存放的程序。另外,也可以是其他计算机或交换机(未图示)等其他装置存放上述的程序或表并执行。
存储装置2000具备内存2100、数据存储区域提供部2200、盘接口控制器2300、管理接口2400、处理器2500及数据接口2600,上述部件经由存储装置2000内的内部总线等通信路径2700连接。内存2100具有方便磁盘读写的缓存2110。另外,内存2100可以存放构成性能信息收集程序2120。缓存2110是用于暂时存放信息的存储区域。构成性能信息收集程序2120收集存储装置2000的管理信息及性能信息等并与管理计算机1000之间收发。
数据存储区域提供部2200具有物理区域2210。物理区域2210可以是物理盘、由多个物理盘构成的奇偶校验群组、闪存等存储介质。作为一例,可以准备由物理区域2210构成的存储池,在逻辑上对存储池的存储区域进行分割,将该逻辑上分割后的存储区域作为卷,以供该存储装置2000以外的装置访问物理区域2210。另外,物理区域2210可以被赋予物理区域编号,存储装置2000能够唯一地识别物理区域2210。盘接口控制器2300是用于与数据存储区域提供部2200连接的接口设备。管理接口2400是用于与管理用网络5000连接的接口设备。处理器2500执行在内存2100上展开的程序。数据接口2600是用于与数据用网络4000连接的接口设备。
在图2所示的具体例中,构成性能信息收集程序2120被存放在内存2100中,但也可以被存放在其他存储装置(未图示)或其他存储介质(未图示)中。此时,处理器2500在执行处理时将构成性能信息收集程序2120读取至内存2100上并执行。
主机3000例如是物理服务器,具备内存3100、数据接口3200、处理器3300、物理区域3400及管理接口3500,上述部件经由主机3000的内部总线等通信路径3600相互联系。内存3100可以存放构成性能信息收集程序3110、业务程序3120。构成性能信息收集程序3110收集主机3000的管理信息、性能信息并与管理计算机1000之间收发。业务程序3120用于实现主机3000所执行的业务,例如是dbms(数据库管理系统)或文件系统等。数据接口3200是用于与数据用网络4000连接的接口设备。处理器3300执行在内存3100上展开的程序。物理区域3400可以是存放信息的非易失性存储介质,例如是hdd(硬盘驱动器)、ssd(固态驱动器)、闪存等存储介质。管理接口3500是用于与管理用网络5000连接的接口设备。主机3000利用由存储装置2000提供的物理区域2210或者主机3000中的物理区域3400来执行各种业务。
在图2所示的具体例中,各种程序被存放在内存3100上,但也可以存放在其他存储装置(未图示)。此时,处理器3300在执行处理时将目标程序读取至内存3100上并执行。另外,各种程序既可以在主机3000上架构的管理程序型(hypervisor型)的虚拟环境中执行,也可以在容器型(container型)虚拟环境中执行。
在图2所示的具体例中,主机3000与存储装置2000经由数据用网络4000相互连接。存储装置2000与主机3000之间的连接不限定于经由光纤通道直接连接,也可以经由1台以上的光纤通道交换机等网络设备连接。另外,存储装置2000与主机3000之间的连接是数据通信用的网络即可,也可以是ip网络。另外,也可以不利用存储装置2000,而仅包括主机3000和管理计算机1000。
图5表示第二实施方式的构成信息表1110的一个具体例。构成信息表1110存放由构成管理程序1910取得的图4所示的计算机系统中的构成要素的信息以及构成要素之间的关联信息。在此,构成要素(对象)包括物理上存在的构成要素以及逻辑上定义的构成要素。作为一个具体例,构成信息表1110管理表示从主机3000上运行的业务程序3120至主机3000所使用的存储装置2000的物理区域2210为止的输入输出路径上存在的物理/虚拟的装置/设备的信息、即表示基于输入输出路径的装置及设备的逻辑关系的信息。在此,逻辑关系基于设定,例如存放有“主机(物理机)”与“主机上运行的虚拟机”的关系、“物理区域”与“负责向物理区域的输入输出处理的处理器”的关系、“物理区域”与“暂时存储向物理区域的输入输出的方便磁盘读写的缓存”的关系等。
构成信息表1110具有物理机id1111、虚拟机id1112、逻辑盘id1113、存储装置id1114、数据区域id1115、处理器id1116、缓存id1117这些字段。物理机id1111中存放用于唯一地识别主机3000的识别符。虚拟机id1112中存放用于唯一地识别主机3000上架构的虚拟环境(虚拟机)的识别符。逻辑盘id1113中存放用于唯一地识别虚拟机id1112所示的虚拟环境上的业务访问时利用的物理区域的挂载点的识别符。存储装置id1114中存放用于唯一地识别存储装置2000的识别符。数据区域id1115中存放用于唯一地识别物理区域2210的识别符。处理器id1116中存放用于唯一地识别负责针对由数据区域id1115示出的物理区域进行处理的处理器2500的识别符。缓存id1117中存放用于唯一地识别针对由数据区域id1115示出的物理区域的处理被缓存的缓存2110的识别符。各列的字段中存放由构成管理程序1910从计算机系统收集的信息。收集及存放信息的方法不做特别限定。
本实施方式不限定于在此示出的构成信息表1110的信息,针对计算机系统中的任意管理对象(构成要素)都能够同样地对待。例如,也可以存放用于识别包括物理及虚拟的其他管理对象的识别符等,例如用于唯一地识别主机3000上运行的业务程序(dbms等)3120的识别符、用于唯一地识别主机3000在访问由数据区域id1115示出的物理区域2210时利用的主机3000的数据接口3200的识别符、用于唯一地识别交换机的数据接口或存储装置2000的数据接口2600的识别符等。另外,也可以将例如web服务器与dbms等的业务程序之间的调用关系建立关联并存放。另外,也可以将以业务程序所执行的处理作为单位的信息等建立关联并存放,例如将业务程序中的处理a与该处理a执行时所利用的主机、该主机的处理器、存储器等建立关联并存放。另外,作为构成要素的信息,也可以将计算机系统中的构成要素的硬件及软件的规格、设定值的信息,例如物理机id1111所示的主机3000上架构的虚拟环境的形式和类别、虚拟机id1112所示的虚拟机中安装的操作系统的类别、数据区域id1115所示的数据区域2210中利用的存储介质的类别等也一起存放。
图6表示第二实施方式的性能履历信息表1120的一个具体例。性能履历信息表1120存放通过计算机系统的运营由性能监视分析程序1920从各管理对象取得的性能信息。性能履历信息表1120对管理对象(构成要素)的性能的信息进行管理,例如管理与主机3000上运行的虚拟机、存储装置2000中的物理区域2210相关的性能的信息。性能履历信息表1120具有时刻1121、装置id1122、设备id1123、度量1124、性能值1125这些字段。
时刻1121中存放从管理对象收集了信息的时刻的数据。装置id1122中存放用于唯一地确定装置的识别符。设备id1123中存放用于唯一地确定被取得性能信息的设备的识别符。度量1124中存放表示性能信息的种类的信息,例如针对请求进行响应所需的时间(请求响应时间)、处理器使用率、每单位时间(例如1秒)针对存储装置的输入输出次数(iops)等。在性能值1125中存放由设备id1123所示的设备的由度量1124所示的种类的性能信息的值,其从设备所在的装置被取得。
性能履历信息表1120的信息不限定于图6所示。例如,也可以是存储装置2000的数据接口2600、主机3000的数据接口3200、交换机或交换机的端口(未图示)的性能信息、或者主机3000上运行的业务程序(dbms等)的性能信息。
另外,在图6中示出了请求响应时间(读响应时间、写响应时间)、处理器使用率、缓存使用量、单位时间输入输出量(iops)等作为度量,但不限定于此。也可以使用输入输出使用率、传输速率、吞吐量、数据库管理软件的缓存比特率、被插入、更新或删除的记录数量、web服务器的响应时间、文件系统或盘的剩余空间或使用率、输入输出数据量、网络接口的错误次数、缓存的上溢、帧错误等其他性能指标来作为度量。
另外,除了在此示出的由性能监视分析程序1920取得的各管理对象的性能信息之外,还可以设置其他字段,例如存放用于判断所取得的性能信息是否正常的条件的警报阈值(性能值的正常范围的上限或下限等的阈值)的信息、性能监视分析程序1920判断所取得的性能信息是否违反了警报阈值的结果等。在此,警报阈值的信息存放可能成为发出警报的契机的值,例如由用户指定的阈值、与利用性能信息的履历信息的平均值求出的基准值之间的差值等。
图7a、图7b及图7c表示第二实施方式的通用规则表1130的一个具体例。在本例中,管理计算机1000的内存1100中存放1个以上的通用规则表1130,通过1个通用规则表1130规定1个通用规则。该表的信息预先被规定即可,例如由用户通过手动输入来制作,或者利用后述的通过规则生成处理来自动生成s。
通用规则例如是表示如下关系的数据:构成要素中的1个度量与可能对该度量施加影响而导致问题发生的构成要素的1个以上的度量之间的关系。后述的展开规则也可以是表示同样关系的数据。另外,通用规则不限于图7a、图7b、图7c所举出的例子,可以存在更多的规则。
通用规则表1130具有目的部1134、说明部1135、通用规则id1136这些字段。在目的部1134及说明部1135中,分别存放装置类别1131、设备类别1132、度量1133。在装置类别1131中,存放表示被进行性能监视分析的装置的类别的数据。在设备类别1132中,存放表示被进行性能监视分析的装置中的设备的类别的数据。在度量1133中,存放表示性能信息的种类的数据,例如被进行性能监视分析的装置中的设备的处理器使用率、请求响应时间等。在此,度量1133的性能信息与性能履历信息表1120的度量1124中存放的性能信息同样也可以使用除了在此示出的性能信息以外的信息。
另外,在目的部1134中,存放表示装置类别1131彼此的连接关系的信息。具体而言,在图7a中,目的部1134记载了主机和存储装置这两种装置类别,由此表示主机与存储装置具有连接关系而成的构成适用于该通用规则。在此,仅举出了主机和存储装置作为装置类别,但也可以是ip交换机等其他装置类别,且不限于所记载的装置类别的数量。在此,利用通用规则表1130的目的部1134来规定连接关系的信息,但只要能够装置类别来规定适用该规则的连接关系即可,也可以通过其他方法来规定。在通用规则id1136中,存放作为通用规则的识别符的通用规则id。
通用规则可以示出如下情况:在目的部1134中记载的构成要素的度量1133的值与说明部1135中记载的构成要素的度量1133的值之间的关系变得不成立的情况下,判断为显示出发生问题的预兆。在图7a、图7b、图7c的具体例中,说明部1135记载了1至3个度量,但数量不限于此。例如,图7a所例示的通用规则(通用规则id1136为“rule1”)规定了:主机3000上的逻辑盘的读响应时间与存储装置2000中的处理器2500的使用率、存储装置2000中的方便磁盘读写的缓存2110的使用量、存储装置2000中的物理区域2210的使用率之间的关系。在基于该通用规则生成展开规则1140时,根据构成信息表1110取得上述信息。
图8a、图8b及图8c表示第二实施方式的展开规则表1140的一个具体例。在本例中,管理计算机1000的内存1100中存放1个以上的展开规则表1140,通过1个展开规则表1140规定1个展开规则。
展开规则1140是规则展开程序1930将通用规则1130展开为依赖于计算机系统的实际构成的形式而成的数据。规则展开程序1930例如通过将图7a所示的通用规则中的装置类别1131及设备类别1132的各值置换为实际构成、例如由构成信息表1110定义的特定装置的识别符(例如装置id)及特定设备的识别符(例如设备id),从而生成图8a、图8b及图8c所示的展开规则。
在此,在由构成信息表1110定义的构成要素之间的关联信息符合通用规则1130的目的部1134中规定的连接关系的情况下,规则展开程序1930实施上述置换来生成展开规则。
例如,针对构成信息表1110中有连接关系的server11与storagea,将图7a所示的通用规则“rule1”中的装置类别1131及设备类别1132的各值,置换为由构成信息表1110定义的特定装置(server11、storagea)的识别符及特定设备(逻辑盘“/var/www/data”、处理器“processor1”、缓存“cache1”、盘“disk1”)的识别符,从而生成图8a所例示的展开规则id为“exrule1-1”的展开规则。
展开规则表1140包括目的部1144、说明部1145、通用规则id1146及展开规则id1147这些字段。在目的部1144及说明部1145中,分别存放装置id1141、设备id1142、度量1143。在装置id1141中,存放表示要进行性能监视分析的实际装置的识别符的数据。在设备id1142中,存放表示要进行性能监视分析的实际装置中的实际设备的识别符的数据。在度量1143中,存放表示要进行性能监视分析的实际装置中的实际设备的性能信息的种类的数据,例如处理器使用率等。在此,度量1143的性能信息与性能履历信息表1120的度量1124中存放的性能信息同样也可以使用除了在此示出的性能信息以外的信息。在通用规则id1146中,存放被展开规则作为基础的通用规则的通用规则id。在展开规则id1147中,存放作为展开规则的识别符的展开规则id。在此,在判断为目的部1144中记载的构成要素的度量1143的值与说明部1145中记载的构成要素的度量1143的值之间的关系变得不成立的情况下,判断为发生了问题。
图9表示第二实施方式的分学习单位预测模型表1150的一个具体例。分学习单位预测模型表1150用于管理表示每个展开规则的预测模型的信息,存放预测模型中使用的度量以及与度量相关的系数等。在此,预测模型例如能够表示为:目的信息=说明信息1+说明信息2+说明信息3+说明信息4……。更具体而言,例如存放通过学习得到的如下函数的信息:
“server11”的逻辑盘(“/var/www/data”)的读响应性能=
系数1דstorage1/processor1/使用率”
+系数2דstorage1/cache1/使用量”
+系数2דstorage1/disk1/使用率”
分学习单位预测模型表1150包括展开规则id1151、目的信息1152、说明信息1153、模型状态1154这些字段。在展开规则id1151中,存放用于唯一地识别由学习单位分割程序1940基于展开规则决定的供学习程序1950生成学习模型用的单位的识别符。在目的信息1152中,包括预测模型中希望预测的管理对象的识别信息,例如包括装置id1155、设备id1156、度量1157这些字段。在说明信息1159中,包括与预测模型中希望预测的管理对象的度量的值存在依赖关系的其他管理对象的度量1159、以及说明该依赖关系所需的系数值1158这些字段。
在模型状态1154中,存放表示是否处于已经充分进行了预测模型的学习的稳定状态的标志。在图9中,在充分学习的稳定状态下存放字符串“ok”,在未充分学习的状态下存放字符串“-”,来作为模型状态1154中存放的值,但不限于此。
分学习单位预测模型表1150基于学习单位分割程序1940的学习单位的分割结果来存放数据,系数1158由学习程序1950实施学习来更新,另外,在判断为处于稳定状态后将模型状态1154更新为字符串“ok”。
在本具体例中,说明了逻辑盘的读响应性能作为目的信息1152的一例,说明了存储装置的处理器的使用率、缓存的使用量、盘的使用率等作为说明信息1153的一例,但不限定于此。另外,在此预测式是一次式,分学习单位预测模型表1150表示用于确定最符合数据的依赖关系的回归分析式,但不限定于此。作为其他例子,也可以设为预测式是二次以上的高次式,分学习单位预测模型表1150管理表示高次式的信息。另外,通过学习求出了目的信息1152与说明信息1153之间的关系,但也可以通过在此示出的例子以外的任意方法求出上述关系。
图10表示第二实施方式的分通用学习单位预测模型表1160的一个具体例。分通用学习单位预测模型表1160用于管理表示按每个通用规则而通用的预测模型的信息,存放预测模型中使用的度量以及与度量相关的系数等。分通用学习单位预测模型表1160包括通用学习单位id1161、目的信息1162、说明信息1163、展开规则id1164这些字段。表示预测模型的目的信息1162以及说明信息1163例如分别包括装置类别1165、设备类别1166、度量1167这些字段以及系数1168、度量1169这些字段,与图9所示的分学习单位预测模型表1150相似,但图9所示的分学习单位预测模型表1150的各字段中表示实际构成要素的装置id、设备id和实际构成要素的度量,在此被替换为装置类别、设备类别和相应类别的度量。
在通用学习单位id1161中,存放用于唯一地识别与每个相同的通用规则对应的由学习单位分割程序1940提取的通用的学习单位。针对每个相同的通用规则,通用的学习单位存放通用规则id1136作为通用学习单位id1161。在展开规则id1164中,存放1个以上的用于唯一地识别属于由通用学习单位id1161示出的通用规则的各个学习单位的识别符(即图9所示的分学习单位预测模型表1150的展开规则id1151)。分通用学习单位预测模型表1160基于学习单位分割程序1940的学习单位分割结果的分组来存放数据,其系数1168由学习程序1950更新。系数的初始值可以存放表示未充分学习的信息(例如字符串“-”)。另外,与图9的分学习单位预测模型表1150同样,图10的目的信息和说明信息也不限于在此记载的例子。另外,通过学习求出了目的信息1162与说明信息1163之间的关系,但也可以通过在此示出的例子以外的任意方法求出上述关系。
以下说明本实施方式的运营管理系统所执行的运营管理方法。图11是第二实施方式的运营管理方法的一个具体例(学习单位分割处理)的流程图。如图11所示,管理计算机1000的处理器1300通过执行内存1100上展开的规则展开程序1930,从构成信息表1110中提取符合通用规则表1130的目的部中的连接关系的模式(步骤1001)。接着,基于提取的构成,根据通用规则生成展开规则,并将展开规则存放在展开规则表1140中(步骤1002)。接着,管理计算机1000的处理器1300通过执行内存1100上展开的学习单位分割程序1940,基于生成的展开规则来分割学习单位,在分学习单位预测模型表1150中按每个学习单位存放信息(步骤1003)。在此,分学习单位预测模型表1150的系数1158可以设定任意的初始值,例如“1.0”。决定初始值可以使用任意方法。另外,模型状态1154可以设定表示未充分学习的初始值,例如字符串“-”。其中,上述步骤1001至步骤1003例如分别对应于第一实施方式中的步骤s10至步骤s30的具体例。
接着,学习单位分割程序1940按每个分割后的学习单位反复进行如下的步骤1004至步骤1009。首先,参照展开规则表1140,确定被分割中使用的展开规则作为基础的通用规则(步骤1004)。确认所确定的通用规则的条目是否存在于分通用学习单位预测模型表1160中(步骤1005)。不存在的情况下(步骤1005为否),将具有该通用规则的组的条目作为新条目,存放在分通用学习单位预测模型表1160中(步骤1006)。
在所确定的通用规则的条目存在于分通用学习单位预测模型表1160中存在的情况下(步骤1005为是),在对应的已有条目的展开规则id1164中追加该学习单位的信息(步骤1007)。然后,取得系数1168的值,判断是否存在已学习的系数1168的值,例如系数1168是否有除了表示未充分学习的信息(例如字符串“-”)以外的值(步骤1008)。在存在已学习的系数1168的情况下(步骤1008为是),将取得的系数1168的值设定于分学习单位预测模型表1150的对应项目的系数1158中,作为该学习单位的预测模型的系数的初始值(步骤1009)。在此,可以直接将已学习的系数1168设定为该学习单位的预测模型的系数的初始值,也可以针对已学习的系数1168进行规定的处理后设定为该学习单位的预测模型的系数的初始值等。
最后,学习单位分割程序1940要求学习程序1950开始基于步骤1003中分割的学习单位以及步骤1006及步骤1007中生成的具有相同通用规则的组单位进行学习(步骤1010)。
图11所示的学习单位分割处理表示计算机系统的初始设定时的分割学习单位的处理的一例。此外,在计算机系统的构成发生了变更时,通过定期地轮询构成信息表1110来取得构成发生了变更的信息,或者由构成管理程序1910或snmp等一般方法接收构成变更事件,启动学习单位分割处理,仅针对包括构成发生了变更的构成要素在内的构成,在步骤1001中确认是否符合通用规则表1130的目的部中的连接关系的模式,步骤1002以后的处理同上进行。
本实施方式的运营管理方法如上所述,按每个分割后的学习单位进行步骤1004至步骤1007的处理,从而按每个通用规则对学习单位进行分组,以便共享学习结果。即,还包括学习结果汇集步骤,汇集具有相同条件的多个学习单位各自的学习结果。由此,在具有相同条件的学习规则的系统之间共享学习数据,建立共通的预测模型,能够迅速地提供基于学习对计算机系统的高效监视。
另外,在学习结果汇集步骤中,将与新的学习单位或构成变更后的学习单位具有相同条件的其他学习单位的学习结果,用于生成与该新的学习单位对应的预测模型的初始值或与该构成变更后的学习单位对应的预测模型的初始值。由此,在具有相同条件的学习单位之间共享学习数据来架构共通的预测模型,将其用作构成发生了变更的学习单位的预测模型的初始值,能够缩短新追加构成时或构成发生了变更时架构预测模型(完成学习)所花费的时间。由此,能够迅速地提供基于学习对计算机系统的高效监视。
另外,本实施方式的运营管理方法还可以包括学习单位删除步骤,在计算机系统的实际构成发生了变更之后,删除由于该变更而不再存在的学习单位的信息。例如,学习单位分割程序1940定期地确认由分学习单位预测模型表1150的条目所示的连接关系是否存在于构成信息表1110中,如果不存在则从分学习单位预测模型表1150中删除该学习单位。或者,事先保持构成信息的履历,在随着构成发生了变更而执行学习单位分割处理时,在将构成变更后的信息保存至分学习单位预测模型表1150(步骤1003)时删除基于构成变更前的构成制作的学习单位。由此,能够根据计算机系统的构成变更自动地删除无用的学习单位的信息,节约管理负荷。
(第三实施方式)
以下说明本发明的第三实施方式。本实施方式在第二实施方式的基础上,在通用规则的基础上进一步基于更详细的条件进行分组(汇集)。在本实施方式中,关于与第一或第二实施方式的相同或等同的部分省略说明。
例如,在汇集具有相同条件的多个学习单位各自的学习结果时,相同条件包括如下条件中的至少一种:多个学习单位中的各个学习单位分别对应于根据相同的通用规则生成的多个展开规则中的各个展开规则(即第二实施方式);在所述多个学习单位所对应的多个展开规则之间构成要素的连接关系(基数、cardinality)相同;在所述多个学习单位所对应的多个展开规则之间构成要素具有相同或相似的硬件规格或类别。另外,分组条件不限于上述例子,能够根据实际需要设定。由此,能够根据多种多样的条件对学习单位进行分组,从而在各组之间共享学习数据,建立共通的预测模型,能够根据系统状况或用户需求,更灵活地提供基于学习对计算机系统的高效监视。
图12是第三实施方式的运营管理方法的一个具体例(学习单位分割处理)的流程图。图12表示基于“具有相同的通用规则,且对象之间的连接具有相同基数(连接关系相同)”的条件进行分组的情况下的学习单位分割处理的一个具体例。在图12的步骤1011之前执行与图10同样的处理,因此省略说明。
在步骤1011中,学习单位分割程序1940确认“具有相同的通用规则且对象之间的连接具有相同基数的组”的条目是否存在于分通用学习单位预测模型表1160中。不存在的情况下(步骤1011为否),将该组的条目作为新条目存放在分通用学习单位预测模型表1160中(步骤1012)。
在该条目存在于分通用学习单位预测模型表1160中的情况下(步骤1011为是),在对应的现有条目的展开规则id1164中追加该学习单位(步骤1013)。然后,取得系数1168的值,判断是否存在已学习的系数1168的值,例如系数1168是否有除了表示未充分学习的信息(例如字符串“-”)以外的值(步骤1014)。在存在已学习的系数1168的情况下(步骤1014为是),用取得的系数1168的值更新分学习单位预测模型表1150的对应项目的系数1158,作为该学习单位的预测模型的系数的初始值(步骤1015)。最后,与图11同样,学习单位分割程序1940要求学习程序1950开始学习(步骤1010)。
说明图12的处理的一个具体例。图8a、图8b及图8c所示的展开规则表1140是从相同的通用规则“rule1”生成的,按照图11的流程,被分配为同一组,在分通用学习单位预测模型表1160中被作为相同的条目存放。另一方面,在按照图12的流程,基于“具有相同的通用规则,且对象之间的连接具有相同基数”的条件进行分组的情况下,由于图8a和图8b所示的展开规则表1140都是1个主机的设备与1个处理器、1个缓存、1个盘相关联,因此被分为同一组,而图8c所示的展开规则表1140是1个主机的设备与1个处理器、1个缓存、2个盘相关联,与图8a、图8b所示的展开规则表1140相比在对象之间的连接上具有不同的基数,因此被分为不同的组,在分通用学习单位预测模型表1160中被作为不同的条目存放。
同样地,“具有相同的通用规则,且具有相同/类似的规格信息”的条件为:关于具有相同的通用规则的各学习单位所包含的构成要素,参照构成信息表1110中存放的虚拟环境的形式和类别、操作系统的类别、存储介质的类别等关于规格的信息,如果相同的规格信息的数量相对于全部规格信息的数量的比例为规定比例以上,则判断为符合上述条件。在符合上述条件的情况下,作为“具有相同的通用规则,且具有相同/类似的规格信息”的组对待,通过与图12的步骤1011同样的处理,确认“具有相同的通用规则,且具有相同/类似的规格信息”的组的条目是否存在于分通用学习单位预测模型表1160中,以后可以进行与图12同样的流程。
进而,在汇集具有相同条件的多个学习单位各自的学习结果时,还可以分级地汇集。例如,结合图11、图12的说明,可以得到基于通用规则分组的例子、基于通用规则分组进而基于连接关系的基数分组的二级分组(建模)的例子、基于通用规则分组进而基于规格信息分组的二级分组(建模)的例子,但不限定于此,例如也可以基于通用规则、连接关系的基数、规格信息进行三级分组(建模),或者基于其他条件进行多级分组(建模)。此时,在相应条件的分组中进行相当于图12的步骤1011至步骤1015的处理即可。
即,在本实施方式中,在学习结果汇集步骤中,汇集具有第一相同条件的多个学习单位各自的学习结果,并且汇集具有所述第一相同条件且具有不同于所述第一相同条件的第二相同条件的多个学习单位各自的学习结果,由此分级地汇集多个学习单位各自的学习结果。
一般而言,构成或设定类似的构成的学习构成也类似,因此通过多级分组,与仅利用通用规则等进行分组的情况相比,同组的构成更接近,预测模型的适合率更高。进而,能够将学习构成的适合率更高的系数设定为学习单位的预测模型的系数的初始值。
(第四实施方式)
以下说明本发明的第四实施方式。本实施方式在第一至第三实施方式的任一个的基础上,追加预测模型生成处理。在本实施方式中,关于与第一至第三实施方式的任一个相同或等同的部分省略说明。
图13是第四实施方式中生成预测模型的处理(预测模型生成处理)的一个具体例的流程图。生成预测模型的处理是:收集各对象的各种信息作为学习数据,通过学习,针对目标要素与其他要素之间的关联,确定最符合学习数据的模型(例如函数等)。
由管理计算机1000的处理器1300执行内存1100上展开的学习程序1950来进行预测模型生成处理,启动时机例如可以是定期执行、在用户指定的任意时机执行、根据系统负荷执行等,在此不做限定。以下说明预测模型生成处理的具体例。
为了生成每个学习单位的预测模型,学习程序1950按每个学习单位反复进行如下的步骤2001至步骤2006。首先,参照分学习单位预测模型表1150,确定由目的信息1152表示的要生成预测模型的构成要素与由说明信息1153表示的与其关联的构成要素(步骤2001)。接着,参照性能履历信息表1120,取得要生成预测模型的构成要素和与其关联的构成要素的性能履历信息的组合(步骤2002)。例如,取得如下关于性能的信息:在时刻10:01取得的“server11”中的设备“/var/www/data”的读响应时间为“1msec”、“storagea”的“disk1”的使用率(busy%)为“35%”、“storagea”的“processor1”的使用率(usage%)为“40%”、“storagea”的“cache1”的使用量(usagesize)为“4gb”等。
接着,学习程序1950生成预测模型,更新分学习单位预测模型表1150的系数1158(步骤2003)。例如,在图9的分学习单位预测模型表1150中,存放了如下预测式:
“server11”的设备“/var/www/data”的读响应时间=
33.76דstorage1”的“processor1”的使用率
+7.27דstorage1”的“cache1”的使用量
+5.1דstorage1”的“disk1”的使用率
步骤2003中生成预测式的方法不特别限定,可以采用包括回归分析等现有方法的任意方法。
接着,学习程序1950判断由分学习单位预测模型表1150表示的预测模型的系数1158是否处于稳定状态(步骤2004)。在处于稳定状态的情况下(步骤2004为是),将模型状态1154的值更新为表示稳定状态的值(例如字符串“ok”)(步骤2005)。在不处于稳定状态的情况下(步骤2004为否),将模型状态1154的值更新为表示不稳定状态的值(例如字符串“-”)(步骤2006)。预测模型是否处于稳定状态,例如可以通过分学习单位预测模型表1150的系数1158的变动率是否为规定值以下等来判断,但不限定于此。具体而言,在步骤2003中,各度量的系数1158的值被更新,因此针对各个度量求出更新前后的系数的值的变动率,如果全部度量的变动率为规定值(例如1%)以下,则判断为处于稳定状态。另外,也可以从性能履历信息中提取正常值并代入预测模型来计算值,如果计算出的值都没有示出违反值,则判断为处于稳定状态。另外,也可以采用此外的任意方法来判断预测模型的稳定状态。
另外,本实施方式在第二或第三实施方式的基础上进行预测模型生成处理的情况下,接着还可以基于分通用学习单位预测模型表1160所示的组为单位生成预测模型,学习程序1950按每个组(通用学习单位)进行如下的步骤2007和步骤2008的处理。首先,参照分通用学习单位预测模型表1160的展开规则id1164来提取属于同一组的学习单位,参照分学习单位预测模型表1150来取得所提取的学习单位之中的模型状态为稳定状态(例如字符串“ok”)的学习单位的信息(步骤2007)。
接着,基于所取得的信息,生成预测模型,并更新分通用学习单位预测模型表1160的信息(步骤2008)。具体而言,基于分学习单位预测模型表1150中的系数1158的信息,更新分通用学习单位预测模型表1160的系数1168的信息。在图9及图10所示的例子中,为了更新由通用学习单位id“1”所示的预测模型,从分学习单位预测模型表1150中,取得与通用学习单位“1”对应的展开规则id“1-1”、“1-2”、“1-3”所示的学习单位的预测模型的系数1158的值,即分别取得“33.76、7.27、5.1”、“30.56、6.3、2.3”、“30.56、6.3、2.3、3.3”、求出平均值“(33.76+30.56+30.56)/3=31.63”、“(7.27+6.3+6.3)/3=6.62”、“(5.1+2.3+2.3+3.3)/4=3.25”,利用求出的值更新分通用学习单位预测模型表1160的系数1168的值。在此,利用针对分学习单位预测模型表1150中的对应的学习单位的预测模型中的系数1158的值取平均值的方法来计算分通用学习单位预测模型表1160的系数1168的值,但不限定于此,可以采用取中间值等任意方法。
即,本实施方式的运营管理方法还可以利用学习结果中的参数来汇集具有相同条件的多个学习单位各自的学习结果。由此,利用具有相同条件的学习单位的参数共享学习数据来架构共通的预测模型,能够建立适合率更高的共通预测模型。
另外,在此将按每个学习单位已经完成学习的预测模型的系数,用于更新分通用学习单位预测模型的信息,但也可以再次参照分学习单位预测模型表1150所示的预测模型中的由目的信息1152表示的要生成预测模型的构成要素和由说明信息1153表示的与其关联的构成要素的性能履历信息,从头重新建立预测模型,并更新分通用学习单位预测模型表1160的信息。
(第五实施方式)
以下说明本发明的第五实施方式。本实施方式在第一至第四实施方式的任一个的基础上,追加性能监视分析处理。在本实施方式中,关于与第一至第四实施方式的任一个相同或等同的部分省略说明。
图14是第五实施方式的基于预测的性能监视分析处理的一个具体例的流程图。管理计算机1000的处理器1300执行内存1100上展开的性能监视分析程序1920来执行本处理。启动的时机基本上是定期执行,但也可以在用户指定的任意时机执行,或根据系统负荷执行等,在此不做限定。以下说明本处理的具体例。
首先,性能监视分析程序1920从性能履历信息表1120取得性能信息(步骤3001)。接着,按每个监视对象,判断所取得的性能信息是否违反了警报阈值(步骤3002)。在违反的情况下(步骤3002为是),在警报通知列表(在图15中示出一例)中,追加该违反信息(步骤3003)。步骤3001至步骤3003的处理是一般的计算机系统监视流程,其中按每个单一监视对象检查是否违反阈值,但也可以仅在多个监视对象同时违反阈值的情况下通知警报等。另外,说明了通过检查所取得的性能信息是否违反阈值来在警报通知列表中追加该信息的例子,但也可以由监视对象自身以处于异常状态作为触发事件,通知性能监视分析程序1920,并将该事件信息追加到警报通知列表中等。
接着,按每个学习单位反复执行如下的步骤3004至步骤3007。首先,确认分学习单位预测模型表1150的模型状态1154是否为稳定状态(预测模型已完成)(步骤3004)。在其值表示不稳定状态(例如字符串“-”)的情况下(步骤3004为否),由于预测模型未完成,因此结束该学习单位的处理,转移至下一学习单位的处理并执行步骤3004。在其值表示稳定状态(例如字符串“ok”)的情况下(步骤3004为是),由于预测模型已完成,因此基于步骤3001中取得的性能信息,计算预测模型的值(步骤3005)。
接着,判断预测模型是否表现出违反(步骤3006)。在预测模型表现出违反的情况下(步骤3006为是),在警报通知列表中追加该违反信息(步骤3007)。在预测模型未表现出违反的情况下(步骤3006为否),结束该学习单位的处理,转移至下一学习单位的处理并执行步骤3004。在此,例如可以在预测模型中代入度量的值,判断由此求出的预测模型的目的信息的值与说明信息的值之差是否为规定值以下,由此判断预测模型是否表现出违反,但不限定于此,也可以根据情况任意设定。
图15表示第五实施方式的基于预测的性能监视分析画面的一个具体例。性能监视分析画面9000用于显示在计算机系统中发生了问题的情况下供管理者追究其原因时参照的信息。具体而言,包括警报通知列表的显示区域9001、警报发生的构成要素或与警报关联的构成要素的信息的显示区域9002、表示其构成信息的性能信息的显示区域9003等。在此所示的例子中,在管理者点击了显示区域9001的条目时,在显示区域9002中显示与该警报对应的学习单位的信息,在显示区域9003中显示该学习单位的性能信息。
在警报通知列表的显示区域9001中,显示用于在计算机系统中唯一地识别警报的识别符(例如“事件id”)、警报发生的学习单位id、警报的类型(例如“事件类型”)、警报发生时间的信息。这些信息的值由性能监视分析程序1920在性能监视分析处理的步骤3007中设定。在此,也可以将步骤3003中的追加信息与装置id、设备id、度量一起追加至警报通知列表的显示区域9001,但在此由于仅显示一般的监视事件所以未图示该追加信息。
另外,显示区域9001中的各个条目的显示顺序不作限定,例如可以按照警报发生时间从新到旧的顺序排列,或者按照预测模型的违反程度从大到小的顺序排列。另外,也可以为了便于观察而削减显示区域9001中显示的条目数量,例如在学习单位id相同的条目有多个的情况下隐藏其中一部分的显示来集约显示为1个条目,或者仅显示违反程度最大的10个条目,或者在警报发生超过了规定时间后认为预测的可靠性下降而删除该条目的显示等。另外,显示区域9001中的信息不限于在此示出的例子,也可以显示关于警报的其他信息,或者采用能够显示关于警报的信息的其他显示方式。
显示区域9002中例如显示与展开规则表1140同等的信息。在此,为了使监视分析计算机系统的管理者容易理解,将展开规则表1140中的“目的部1144”表现为“分析对象”,将“说明部1145”表现为“影响构成要素”,将“装置id1141”表现为“监视对象”,将“设备id1142”表现为“监视部位”,但不限定于此。这些信息的值由性能监视分析程序1920参照展开规则表1140的信息来存放。另外,显示区域9002中的各条目的显示顺序不作限定,例如可以按照警报发生时的性能值与过去规定期间(例如一周等)的性能履历中的性能平均值之差从大到小的顺序,依次显示影响构成要素。另外,也可以采用能够显示与展开规则表1140同等的信息的其他显示方式。
显示区域9003例如与显示区域9002所示的构成要素的度量分别对应地显示其性能信息。这些信息的值由性能监视分析程序1920参照性能履历信息表1120的信息来存放。在图15中,在显示区域9002所示的构成要素的各个度量之侧,在显示区域9003中以时序曲线图的方式显示各个度量的性能信息。由此,能够一并确认同一学习单位中包括的构成要素彼此的性能信息的变动。在此,显示区域9003只要能够表示显示区域9002的构成要素在警报发生时的性能信息,也可以采用表形式等除了时序曲线图以外的其他显示方式。在显示区域9003中,通过显示事件发生的时刻(图中以虚线表示),能够使管理者掌握该时刻的各构成要素的度量的值,其显示方式不限定于虚线。
性能监视分析画面9000既可以总是显示,也可以在用户指定时显示等,显示的时机不作限定。另外,基于预测模型的警报的信息、警报发生的构成要素或与警报关联的构成要素的信息、以及该构成要素的性能信息也可以采用其他显示方式。另外,也可以将警报的详细信息或其他构成要素的性能信息等一起显示,或者从图15所示的性能监视分析画面9000打开新画面来显示。
另外,在此将性能信息与时刻信息一起显示来对辅助计算机系统的管理者进行监视和分析,但也可以显示如下信息等,该信息表示导致预测模型表现出违反值的可能性高的构成要素。例如,如果某构成要素的度量在警报发生时的性能值与过去规定期间(例如一周等)的性能履历中的性能平均值之差最大,则可以将该构成要素判断为警报发生的原因,但判断方法不限于此。
即,在本实施方式中,运营管理方法还可以包括性能监视分析步骤,基于与每个学习单位对应的预测模型,提供用于性能监视分析的事件通知及/或性能分析信息。由此,在性能监视分析画面9000中,能够按每个学习单位显示警报通知、性能分析画面等。由此,无论计算机系统的构成如何复杂,都能够以共通且简明的形式来进行监视和分析。
(第六实施方式)
以下说明本发明的第六实施方式。本实施方式在第一至第五实施方式的任一个的基础上,追加性能监视分析处理。在本实施方式中,关于与第一至第五实施方式的任一个相同或等同的部分省略说明。
图16a、图16b及图16c表示第六实施方式的问题分析规则表1170的具体例。在本实施方式中,在管理计算机1000的内存1100中,可以存放1个以上的问题分析规则表1170,通过1个问题分析规则表1170来规定1个问题分析规则。在此,问题分析规则表1170可以采用各种现有技术。
问题分析规则是表示构成计算机系统的对象中可能发生的1个以上的事象的组合与针对该1个以上的事象的组合成为故障原因的事象之间的关系的数据。即,某个故障发生时预想到会发生的事象的组合与该故障原因例如被记作“if-then(如果-那么)”的形式。问题分析规则不限于图16a、图16b、图16c所举出的例子,也可以有更多的规则。
另外,问题分析规则的条件部1171中指定的观测事象的顺序,表示该条目中的观测事象的装置类别之间具有连接关系。例如,在条件部1171以主机、ip交换机、存储装置的顺序记载的情况下,表示该规则所针对的构成具有主机、ip交换机、存储装置的连接关系。
问题分析规则表1170包括条件部1171、结论部1172及分析规则id1173这些字段。在条件部1171中,存放表示以“if-then”形式记载的分析规则中相当于条件的1个以上的观测事象的数据。在结论部1172中,存放表示以“if-then”形式记载的分析规则中相当于结论的原因事象的数据。在条件部1171及结论部1172中,分别包括装置类别1174、设备类别1175、度量1176及状态1177这些字段。在分析规则id1173中,存放作为问题分析规则的识别符的分析规则id。装置类别1174、设备类别1175、度量1176与图7a、图7b、图7c同样,所以省略说明。在状态1177中,存放表示装置内的设备在事象发生时的状态的数据。
在检测到条件部1171中记载的1个以上的观测事象的情况下,将结论部1173中记载的事象判断为发生故障的原因。如果结论部1173的状态变为正常,即与原因事象相关的性能值恢复正常值,则可以期待条件部1171的问题也被解决,即与各观测事象相关的性能值也恢复正常值。在此,条件部1171中记载的观测事象数量没有限制。
例如,图16a所例示的分析规则、即分析规则id1173为“rule1”的规则表示:作为观测事象检测到主机3000上的逻辑盘的读响应时间违反阈值、主机3000上的逻辑盘的写响应时间违反阈值、以及存储装置2000中的处理器的使用率违反阈值的情况下,对应结论为其原因是存储装置2000中的处理器的使用率违反阈值。
以下说明基于上述问题分析规则生成通用规则的通用规则生成处理的一个具体例。图17是第六实施方式的通用规则生成处理的一个具体例的流程图。通用规则生成处理用于根据问题分析规则表1170生成通用规则表1130。管理计算机1000的处理器1300执行内存1100上展开的通用规则生成程序1960,从而进行本处理。以下,说明本处理的一个具体例。
通用规则生成程序1960按每个问题分析规则1170反复执行如下的步骤4001至步骤4006。首先,取得该问题分析规则1170的条件部1171的信息(步骤4001),确认是否存在与条件部1171中的观测事象分别对应的影响构成要素列表(未图示)(步骤4002)。不存在的情况下(步骤4002为否),制作影响构成要素列表(步骤4003)。在此,如上所述,通过问题分析规则1170中由条件部1171指定的观测事象的顺序,表示相邻的观测事象的装置类别彼此的连接关系,即使是相同的观测事象,也按装置类别彼此的每个连接关系分别准备影响构成要素列表。具体而言,在图16a、图16b及图16c中,在条件部1171中按照主机、存储装置的顺序记载,作为具有主机-存储装置的连接关系的构成中的观测事象用的影响构成要素列表对待,即使是同一观测事象用的影响构成要素列表,例如与具有主机-ip交换机-存储装置的连接关系的构成中的观测事象的影响构成要素列表也分开制作。
接着,取得该问题分析规则1170的结论部1172的信息(步骤4004),确认所取得的结论部1172的信息是否被包括在步骤4001中取得的条件部1171用的影响构成要素列表中(步骤4005)。在未被包括的情况下(步骤4005为否),将所取得的结论部1172的信息追加至影响构成要素列表中(步骤4006)。但是,在步骤4006中,如果所取得的结论部1172的信息与步骤4001中取得的条件部1171的信息相同则不追加。然后,在针对全部问题分析规则1170完成了处理之后,按制作的每个影响构成要素列表,生成通用规则(步骤4007)。但是,在步骤4007中,如果影响构成要素列表的要素为空,则删除该列表,不生成通用规则。
以下说明具体例。根据图16a,制作“主机的逻辑盘的读响应性能”、“主机的逻辑盘的写响应性能”及“存储装置的处理器的使用率”用的影响构成要素列表,在“主机的逻辑盘的读响应性能”和“主机的逻辑盘的写响应性能”用的列表中追加“存储装置的处理器的使用率”。根据图16b,在“主机的逻辑盘的读响应性能”用的影响构成要素列表中追加“存储装置的缓存的使用量”,制作“存储装置的缓存的使用量”用的影响构成要素列表。另外,根据图16c,在“主机的逻辑盘的读响应性能”和“主机的逻辑盘的写响应性能”用的影响构成要素列表中追加“存储装置的盘的使用率”,制作“存储装置的盘的使用率”用的影响构成要素列表。
根据图16a、图16b、图16c,生成了如下的2个没有空要素的影响构成要素列表:“主机的逻辑盘的读响应性能”用的影响构成要素列表(构成要素为“存储装置的处理器的使用率”、“存储装置的缓存的使用量”、“存储装置的盘的使用率”)、以及“主机的逻辑盘的写响应性能”用的影响构成要素列表(构成要素为“存储装置的处理器的使用率”、“存储装置的盘的使用率”)。根据这些影响构成要素列表,生成图7a及图7b所示的通用规则。
即,本实施方式的运营管理方法还包括:通用规则生成步骤,参照表示计算机系统所包括的构成要素的度量有可能发生的事件之间的关联的规则,针对每个在相同连接关系下观测事象相同或相似的事件,提取造成该事件的原因的观测事象并制作规则,从而生成通用规则。由此,能够基于现有的计算机系统的管理中使用的信息即问题分析规则表1170,自动地生成通用规则表1130,不需要由管理者自身生成通用规则表1170,节约了成本和劳力。
根据本发明的上述各实施方式,根据通用规则事先定义不依赖于特定构成的预测模型,基于从实际系统收集的构成信息,展开为考虑了实际构成的展开规则,基于展开规则自动决定实际构成中的学习单位,从而按计算机系统中的每个管理对象,不需要从头考虑预测模型的构成单位,能够减少建立预测模型所花费的时间。
另外,在将预测模型用于分析故障原因的情况下,如果根据实际构成取得的实际测量值与由预测模型表示的关系相互背离,则各说明部中,信息变动幅度最大的说明部发生问题的可能性高,并可判断为根本原因。由此,还有助于迅速地提供在故障发生时能够立即自动确定根本原因的环境。
另外,在将预测模型用于假设分析或性能优化的情况下,通过将希望试验的值代入预测模型,有助于迅速地提供能够在代入的值的状况下对预测模型中出现的其他度量的值进行模拟的环境。
由此,能够迅速地提供如下环境:在故障发生或变得不满足管理条件之前就防患于未然,或者在故障发生时迅速地从故障中恢复。
(第七实施方式)
以下说明本发明的第七实施方式。本实施方式在第一至第六实施方式的任一个的基础上,其构成具有分布于多个站点的多个管理计算机。在本实施方式中,关于与第一至第六实施方式的任一个相同或等同的部分省略说明。
图18是第七实施方式的运营管理系统的概要的说明图。第七实施方式的运营管理系统例如由2个以上的站点构成,具备1台以上的管理计算机1000,其管理的计算机系统具备1台以上的管理对象设备8000。在此,管理对象设备8000表示第一实施方式所示的主机3000、由能够执行同样的处理的专用硬件构成的装置、或者各种传感器等。
图18的站点6000是专门为了设置/运营计算机系统而使用的设施,例如为数据中心、云服务的逻辑服务提供单位、iot(物联网)环境等中一般被称为边缘计算、雾计算的分散处理环境等中的边缘服务器所管理的单位、表示实现任意业务的计算机系统的物理或逻辑单位等。站点6000之间通过ip或专用线路等站点间网络7000相互连接。
管理计算机1000的构成基本上与第一至第六实施方式中的任一个相同,但不同点在于,使得管理计算机1000的内存1100中存放的各种程序及表对应于跨多个站点的构成。在图18所示的情况下,站点a、站点b的构成信息、性能履历信息被收集至站点c的管理计算机,通用规则及展开规则由站点c的管理计算机管理。另外,在站点c中执行学习单位分割处理,分学习单位预测模型表1150的更新(图11的步骤1003)、将组的预测模型设定为学习单位的初始值(图11的步骤1009、图12的步骤1015)、以及按每个学习单位请求开始学习(图11及图12的步骤1010)通过站点c的学习单位分割程序远程调用站点a及站点b的学习单位分割程序来执行。在此远程调用的方法不作限定,可以采用任意方法,但在调用时分发分通用学习单位预测模型表1160中的系数1168的信息。另外,预测模型生成处理之中的每个分割单位的处理(图13的步骤2001~步骤2006)由站点a及站点b的学习程序执行,以组为单位的处理(图13的步骤2007、步骤2008)由站点a及站点b的学习程序远程调用站点c的学习程序来执行。在此,远程调用的方法也不作限定。
在此,站点a、站点b的构成信息、性能履历信息被收集至站点c的管理计算机,通用规则及展开规则由站点c的管理计算机管理,但也可以是由站点a、站点b分别管理构成信息、性能履历信息、通用规则及展开规则,而在站点c的管理计算机中不收集这些信息。此时,学习单位分割处理中的基于构成将通用学习规则展开(图11的步骤1001、步骤1002)以及确定通用规则(图11的步骤1004)也通过从站点c的学习单位分割程序远程调用站点a及站点b的学习单位分割程序来执行。进而,在预测模型生成处理中,在以组为单位的处理(图13的步骤2007、步骤2008)的远程调用时,从站点a及站点b的学习程序向站点c的学习程序发送分学习单位预测模型表1150中的系数1158。由于站点c中不收集构成信息/性能履历信息,因此无法从头重新建立预测模型,在这种构成中需要上述处理。
或者,学习程序及学习单位分割程序的处理全部都由站点c执行,在站点a及站点b中仅保持分学习单位预测模型表。在该构成中,站点c的学习单位分割程序及学习程序直接参照/更新站点a及站点b的分学习单位预测模型表,由此执行学习单位分割处理及预测模型生成处理。
在此作为代表例举出了上述3个构成例,但不限定于此,只要在跨多个站点的构成中分担管理计算机1000的内存1100中存放的各种程序及表来执行即可,可以根据各站点中的管理计算机的负荷或其他处理的预定执行状况、站点间网络负荷、故障发生状况等任意条件,切换如何分担处理等,另外,也可以将站点a与站点c的处理分担和站点b与站点c的处理分担作为不同的设定来运营。在此,通过管理计算机1000实现各种处理,但也可以由管理对象设备8000进行处理,并管理各种表和程序。
即,在本实施方式的运营管理系统中,在多个管理计算机之间通过进行远程调用,分担上述的实际构成提取处理、展开规则生成处理以及学习单位决定处理。另外,也可以在多个管理计算机之间通过进行远程调用,还分担预测模型生成处理等其他处理。由此,能够灵活地切换要执行构成信息管理、性能信息管理、学习单位分割、学习等处理的站点,由此能够更迅速地实施以往花费时间的学习处理。
其中,多个管理计算机之中的1个管理计算机还也可以执行如下处理:学习结果汇集处理,汇集具有相同条件的多个学习单位各自的学习结果;以及学习结果分发处理,将汇集后的学习结果分发至其他管理计算机。其他管理计算机还执行如下处理:学习结果利用处理,将接收的学习结果,用于生成与具有相同条件的学习单位对应的预测模型的初始值。
由此,能够适用于跨多个数据中心的大规模系统形态、中央集中型的云管理方式、物联网环境中的边缘计算方式、以及管理计算机间协调动作的分散管理构成等。通过跨站点地管理/共享每个通用学习单位的预测模型,能够提高上述各实施方式中示出的各种效果。
另外,能够按每个站点切换是否提供每个通用学习单位的预测模型,在管理软件的saas(软件即服务)方式、将运营管理业务作为服务承包的方式中,能够与作为运营知识的每个通用学习单位的预测模型的利用相应地计费等。
以上参照附图说明了本发明的具体实施方式和具体例。其中,以上说明的具体实施方式和具体例仅是本发明的具体例子,用于理解本发明,而不用于限定本发明的范围。本领域技术人员能够基于本发明的技术思想对具体实施方式和具体例进行各种变形、组合和要素的合理省略,由此得到的方式也包括在本发明的范围内。例如,上述各实施方式和具体例皆可以相互组合,其组合而成的实施方式也包含在本发明的范围中。
- 还没有人留言评论。精彩留言会获得点赞!