半导体装置的制作方法
本申请主张对在2017年3月31日在韩国知识产权局提出申请的韩国专利申请第10-2017-0041748号的优先权,所述韩国专利申请的全部内容并入本申请供参考。
本发明概念涉及一种半导体装置,且更具体来说,涉及一种对图像数据执行图像处理、视觉处理及神经网络处理的半导体装置。
背景技术:
涉及图像处理、视觉处理及神经网络处理的应用(application)可例如在包含指令以及专用于矩阵计算的存储器结构的系统上实现或者作为所述系统的一部分实现。然而,尽管涉及图像处理、视觉处理及神经网络处理的应用可使用相似的计算方法,然而施行这些处理的系统在许多情形中包括多个处理器,所述多个处理器是分别孤立的且被实现为单独地施行图像处理、视觉处理及神经网络处理。这是因为,尽管涉及图像处理、视觉处理及神经网络处理的应用具有功能相似性,然而相应的应用所需的例如数据处理速率、存储器带宽、同步化(synchronization)等细节是不同的。难以实现能够集成图像处理、视觉处理及神经网络处理于一体的单个处理器。因此,对于其中需要进行图像处理、视觉处理及神经网络处理中的每一者的系统来说,需要提供可满足各个应用各自的要求的集成处理环境及方法。
技术实现要素:
本发明概念的实施例提供一种半导体装置,所述半导体装置能够提供对图像处理、视觉处理及神经网络处理进行高效控制并提高数据利用率的集成处理环境。
本发明概念的实施例提供一种半导体装置,所述半导体装置包括:第一处理器,具有第一寄存器,所述第一处理器被配置成使用所述第一寄存器执行感兴趣区域(regionofinterest,roi)计算;以及第二处理器,具有第二寄存器,所述第二处理器被配置成使用所述第二寄存器执行算术计算。所述第一寄存器是由所述第二处理器所共享,且所述第二寄存器是由所述第一处理器所共享。
本发明概念的实施例提供一种半导体装置,所述半导体装置包括:第一处理器,具有第一寄存器,所述第一处理器被配置成使用所述第一寄存器执行感兴趣区域(roi)计算;以及第二处理器,具有第二寄存器,所述第二处理器被配置成使用所述第二寄存器执行算术计算。所述第一处理器及所述第二处理器共享相同的指令集架构(instructionsetarchitecture,isa)。
本发明概念的实施例提供一种半导体装置,所述半导体装置包括:加载存储单元,被配置成向存储器装置传送图像数据以及从所述存储器装置接收图像数据;内部寄存器,被配置成存储从所述加载存储单元提供的所接收的所述图像数据;数据排列层,被配置成将来自所述内部寄存器的所存储的所述图像数据重新排列成n个数据行,其中所述数据行分别具有多个道;以及多个算术逻辑单元(arithmeticlogicunit,alu),所述多个算术逻辑单元具有n个算术逻辑单元群组。所述n个算术逻辑单元群组分别被配置成处理n个数据行的经重新排列的图像数据。
本发明概念的实施例提供一种半导体装置,所述半导体装置包括:第一处理器,具有第一寄存器,所述第一处理器被配置成使用所述第一寄存器执行感兴趣区域(roi)计算;以及第二处理器,具有第二寄存器,所述第二处理器被配置成使用所述第二寄存器执行算术计算。所述第一处理器包括:数据排列层,被配置成将来自第一寄存器的图像数据重新排列成n个数据行,其中所述n个数据行分别具有多个道;以及多个算术逻辑单元(alu),具有n个算术逻辑单元群组,所述n个算术逻辑单元群组分别被配置成处理n个数据行的经重新排列的图像数据。所述第一寄存器是由所述第二处理器所共享,且所述第二寄存器是由所述第一处理器所共享。
本发明概念的实施例提供一种半导体装置的感兴趣区域(roi)计算方法。所述半导体装置包括:内部寄存器,被配置成存储图像数据;数据排列层,被配置成将所存储的图像数据重新排列成n个数据行,所述n个数据行分别具有多个道;以及多个算术逻辑单元(alu),具有被配置成处理n个数据行的n个算术逻辑单元群组。所述方法包括:由数据排列层重新排列所存储的图像数据的第一数据以提供经重新排列的第一图像数据,所述第一数据具有n×n矩阵大小,其中n是自然数;由算术逻辑单元使用所述经重新排列的第一图像数据执行第一映射计算以产生第一输出数据;由数据排列层重新排列所存储的所述图像数据的第三数据以提供经重新排列的第二图像数据,所述第三数据及所述第一数据被包括为所存储的所述图像数据的第二数据的一些部分,所述第二数据具有(n+1)×(n+1)矩阵大小,且所述第三数据不属于所述第一数据;由算术逻辑单元使用所述经重新排列的第二图像数据执行第二映射计算以产生第二输出数据;以及由算术逻辑单元使用所述第一输出数据及所述第二输出数据执行归纳计算(reducecalculation)以产生最终图像数据。
附图说明
通过参照附图来详细阐述本发明概念的示例性实施例,本发明概念的以上及其他目的、特征、及优点对所属领域的普通技术人员来说将变得更显而易见。
图1示出用于解释根据本发明概念实施例的半导体装置的示意图。
图2示出用于解释根据本发明概念实施例的半导体装置的第一处理器的示意图。
图3示出用于解释根据本发明概念实施例的半导体装置的第二处理器的视图。
图4示出用于解释根据本发明概念实施例的半导体装置的架构的示意图。
图5a、图5b、图5c及图5d示出用于解释根据本发明概念实施例的半导体装置的寄存器的结构的示意图。
图6示出用于解释其中将数据存储在根据本发明概念实施例的半导体装置中的实现方式的示意图。
图7示出用于解释其中将数据存储在根据本发明概念另一个实施例的半导体装置中的实施方式的示意图。
图8a示出用于解释对各种大小的矩阵进行的感兴趣区域(roi)计算的数据图案(datapattern)的示意图。
图8b及图8c示出用于解释根据本发明概念实施例的感兴趣区域计算的数据图案的示意图。
图8d、图8e、图8f及图8g示出用于解释根据本发明概念另一个实施例的感兴趣区域计算的数据图案的示意图。
图8h示出用于解释根据本发明概念实施例的半导体装置的上移计算(shiftupcalculation)的示意图。
图9示出用于解释其中使用根据本发明概念各个实施例的半导体装置执行哈里斯角点检测(harriscornerdetection)的示例性操作的流程图。
图10a及图10b示出用于解释用于图8d中的5×5矩阵的卷积计算的实际汇编指令的实例的视图。
图11示出用于解释使用根据本发明概念实施例的半导体装置的示例性感兴趣区域(roi)计算的流程图。
[附图标记的说明]
1:半导体装置;
100:第一处理器;
105:存储器层次结构;
110:寄存器文件/内部寄存器;
112:图像寄存器;
114:系数寄存器;
116:输出寄存器;
120:加载存储单元;
130:数据排列层;
140:映射层;
150:归纳层;
160、alu1_1、alu1_2、alu1_3~alu1_64、alu1_128、alu2_1、alu2_2、alu2_3~alu2_64、alu2_128、alu3_1~alu3_64、alu3_128、alu8_1、alu8_2、alu8_3~alu8_64、alu8_128、alu9_1、alu9_2、alu9_3~alu9_64、alu9_128:算术逻辑单元;
160a:第一算术逻辑单元群组/算术逻辑单元群组;
160b~160c:第二算术逻辑单元群组~第八算术逻辑单元群组/算术逻辑单元群组;
160d:第九算术逻辑单元群组/算术逻辑单元群组;
170、300:控制器;
190:数据排列模块;
192:图像数据排列器;
194:系数数据排列器;
200:第二处理器;
212:标量寄存器/第二寄存器;
214:向量寄存器/第二寄存器;
220:提取单元;
230:解码器;
240a:槽位/第一槽位;
240b:槽位/第二槽位;
240c:槽位/第三槽位;
240d:槽位/第四槽位;
242a、242b、242d:标量功能单元;
242c:柔性卷积引擎单元;
244a、244b、244c:向量功能单元;
244d:控制单元;
246a、246b、246c、246d:移动单元;
400:存储器总线;
500:存储器装置;
1100:框架;
a1、b1、c1:要素/第一要素;
a2、b2、c2:要素/第二要素;
a3、a4、a64、a128、b3、b4、b64、b128、c3、c4、c64、c128、d4、d64、d128:要素;
cr[0]、cr[1]、cr[2]、cr[3]、cr[4]、cr[5]、cr[6]、cr[7]、cr[8]、cr[9]、cr[10]、cr[11]、cr[12]、cr[13]、cr[14]、cr[15]、dm、ir[0]、ir[1]、ir[2]、ir[3]、ir[4]、ir[5]、ir[6]、ir[7]、ir[8]、ir[9]、ir[10]、ir[11]、ir[12]、ir[13]、ir[14]、ir[15]、ve[0]、ve[2]、ve[4]、ve[6]、ve[8]、ve[10]、ve[12]、ve[14]、vo[1]、vo[3]、vo[5]、vo[7]、vo[9]、vo[11]、vo[13]、vo[15]、w[0]、w[1]、w[2]、w[3]、w[4]、w[5]、w[6]、w[7]:项;
csr0、csr1、isr0、isr1、osr0、osr1、ve、vo:寄存器文件;
w:w寄存器;
d1:要素/第一要素/区;
d2:要素/第二要素/区;
d3:要素/区;
data1:第一数据行/数据行;
data2:第二数据行/数据行;
data3~data9:第三数据行~第九数据行/数据行;
m1、m2、m3、m4、m5、m6、m7、m11、m12、m13、m31、m32:矩阵;
n11、n12、n13、n14、n15、n16、n17、n18、n19、n21、n22、n23、n24、n25、n26、n27:数据项/图像数据;
n28、n29、n31、n32、n33、n34、n35、n36、n37、n38、n39、n41、n42、n43、n44、n45、n46、n47、n48、n49、n51、n52、n53、n54、n55、n56、n57、n58、n59、n61、n62、n63、n64、n65、n66、n67、n68、n69、n71、n72、n73、n74、n75、n76、n77、n78、n79、n81、n82、n83、n84、n85、n86、n87、n88、n89、n91、n92、n93、n94、n95、n96、n97、n98、n99、na1、na2、na3、na4、na5、na6、na7、na8、na9、nb1、nb2、nb3、nb4、nb5、nb6、nb7、nb8、nb9、nc1、nc2、nc3、nc4、nc5、nc6、nc7、nc8、nc9、nd1、nd2、nd3、nd4、nd5、nd6、nd7、nd8、nd9、ne1、ne2、ne3、ne4:图像数据;
orh[0]、orh[1]、orh[2]、orh[3]、orh[4]、orh[5]、orh[6]、orh[7]、orh[8]、orh[9]、orh[10]、orh[11]、orh[12]、orh[13]、orh[14]、orh[15]:部分/上部部分;
orl[0]、orl[1]、orl[2]、orl[3]、orl[4]、orl[5]、orl[6]、orl[7]、orl[8]、orl[9]、orl[10]、orl[11]、orl[12]、orl[13]、orl[14]、orl[15]:部分/下部部分;
r1:第一区;
r2:第二区;
s901、s903、s905、s907、s909、s911、s913、s1201、s1203、s1205、s1207、s1209:步骤。
具体实施方式
按照本发明概念的领域中的传统,可采用施行所阐述的一种或多种功能的区块来阐述及说明各实施例。这些区块(在本文中可被称为单元、或模块等)是由例如逻辑门、集成电路、微处理器、微控制器、存储器电路、无源电子组件、有源电子组件、光学组件、硬接线电路(hardwiredcircuit)等模拟及/或数字电路以实体方式实现,且可视需要通过固件及/或软件来驱动。所述电路可例如被实现于一个或多个半导体芯片中、或例如印刷电路板等衬底支撑件(substratesupport)上。构成区块的电路可由专用硬件、或由处理器(例如,一个或多个经过编程的微处理器及相关联的电路系统)、或者由用于执行所述区块的一些功能的专用硬件与用于执行所述区块的其他功能的处理器的组合来实现。所述实施例中的每一区块可在不背离本发明概念的范围的条件下在实体上分成两个或更多个交互作用且分立的区块。同样地,所述实施例的区块可在不背离本发明概念的范围的条件下在实体上组合成更复杂的区块。
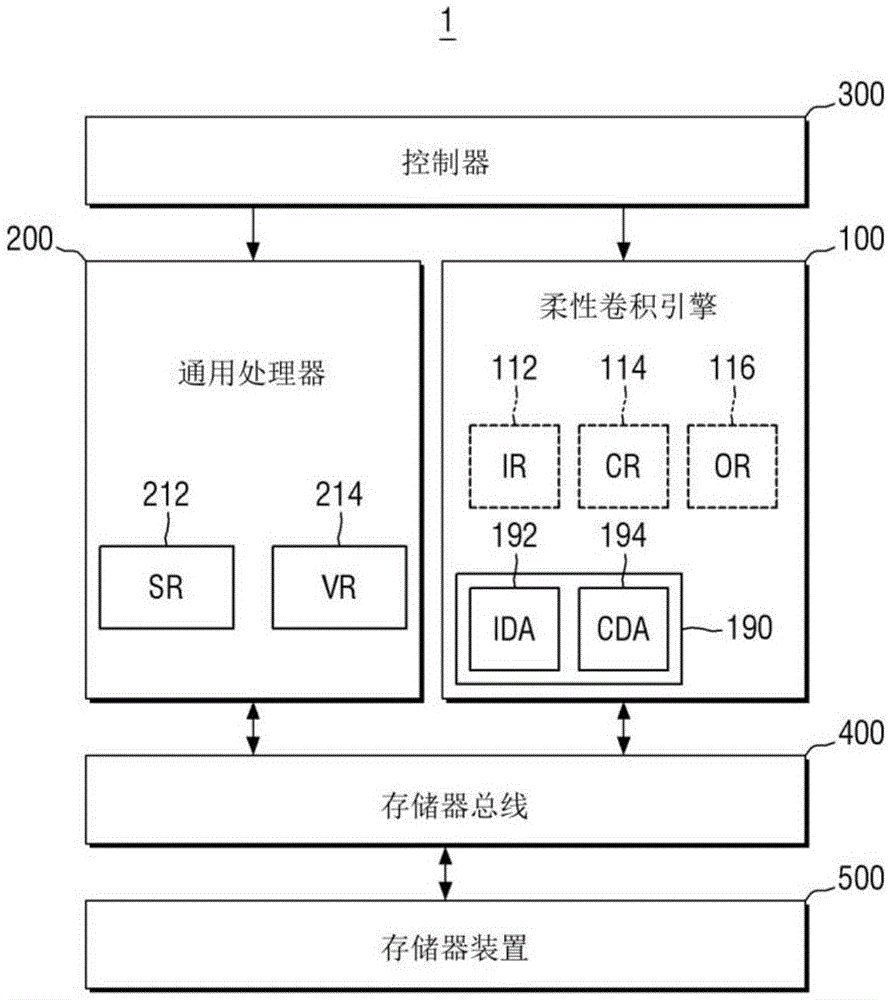
图1示出用于解释根据本发明概念实施例的半导体装置的示意图。参照图1,半导体装置1包括第一处理器100、第二处理器200、控制器300及存储器总线400。控制器300控制第一处理器100、第二处理器200及存储器总线400的总体操作。存储器总线400可连接到存储器装置500。在一些实施例中,存储器装置500可独立于包括控制器300、第一处理器100、第二处理器200及存储器总线400的半导体装置1设置。在其他实施例中,存储器装置500可被设置为半导体装置1的一部分。
第一处理器100可以是专用于在图像处理、视觉处理及神经网络处理中所主要使用的感兴趣区域(roi)计算的处理器。举例来说,第一处理器100可执行一维滤波器计算(one-dimensionalfiltercalculation)、二维滤波器计算(two-dimensionalfiltercalculation)、统计变换计算(censustransformcalculation)、最小/最大滤波器计算(min/maxfiltercalculation)、绝对误差和(sumofabsolutedifference,sad)计算、误差平方和(sumofsquareddifference,ssd)计算、非极大值抑制(nonmaximumsuppression,nms)计算、矩阵乘法计算(matrixmultiplicationcalculation)等。
第一处理器100可包括第一寄存器112、114及116,且可使用第一寄存器112、114及116执行感兴趣区域计算。在一些示例性实施例中,第一寄存器可包括图像寄存器(imageregister,ir)112、系数寄存器(coefficientregister,cr)114及输出寄存器(outputregister,or)116中的至少一者。
举例来说,图像寄存器112可存储被输入的用于在第一处理器100处进行处理的图像数据,且系数寄存器114可存储用于对图像数据进行计算的滤波器的系数。另外,输出寄存器116可存储在第一处理器100处进行处理之后对图像数据执行计算的结果。
第一处理器100还可包括数据排列模块(dataarrangemodule,da)190,数据排列模块190产生用于在第一处理器100处进行处理的数据图案。数据排列模块190可产生用于对各种大小的矩阵高效地执行感兴趣区域计算的数据图案。
具体来说,在一些示例性实施例中,举例来说,数据排列模块190可包括图像数据排列器(imagedataarranger,ida)192,图像数据排列器192通过对被输入的用于在第一处理器100处进行处理并被存储在图像寄存器112中的图像数据进行排列来产生用于在第一处理器100处进行高效感兴趣区域计算的数据图案。另外,举例来说,数据排列模块190可包括系数数据排列器(coefficientdataarranger,cda)194,系数数据排列器194通过对被存储在系数寄存器114中的用于对图像数据进行计算的滤波器的系数数据进行排列来产生用于在第一处理器114处进行高效感兴趣区域计算的数据图案。以下将参照图6至图8e阐述对于由数据排列模块190产生的数据图案的具体解释。第一处理器100可以是柔性卷积引擎(flexibleconvolutionengine,fce)单元。
第二处理器200是适用于执行算术计算的通用处理器。在一些示例性实施例中,第二处理器200可被实现为专用于包含例如向量专用指令的向量计算处理(例如预测计算(predictioncalculation)、向量重组计算(vectorpermutecalculation)、向量位运算计算(vectorbitmanipulationcalculation)、蝶形计算(butterflycalculation)、分类计算(sortingcalculation)等)的向量处理器(vectorprocessor)。在一些示例性实施例中,第二处理器200可采用以下结构:单指令多数据(singleinstructionmultipledata,simd)架构或多槽位超长指令字(multi-slotverylonginstructionword,multi-slotvliw)架构。
第二处理器200可包括第二寄存器212及214,且可使用第二寄存器212及214执行算术计算。在一些示例性实施例中,第二寄存器可包括标量寄存器(scalarregister,sr)212及向量寄存器(vectorregister,vr)214中的至少一者。
举例来说,标量寄存器212可以是在第二处理器200的标量计算中使用的寄存器,且向量寄存器214可以是在第二处理器200的向量计算中使用的寄存器。
在一些示例性实施例中,第一处理器100与第二处理器200可共享相同的指令集架构(instructionsetarchitecture,isa)。因此,专用于感兴趣区域计算的第一处理器100与专用于算术计算的第二处理器200可在指令层次上共享,因而有利于控制第一处理器100及第二处理器200。
同时,在一些示例性实施例中,第一处理器100与第二处理器200可共享寄存器。也就是说,第一处理器100的第一寄存器112、114及116可由第二处理器200所共享(即,由第二处理器200使用),且第二处理器200的第二寄存器212及214可由第一处理器100所共享(即,由第一处理器100使用)。因此,专用于感兴趣区域计算的第一处理器100与专用于算术计算的第二处理器200可共享各自的内部寄存器,此转而可提高数据利用率并减少对存储器进行存取的次数。
在一些示例性实施例中,第一处理器100及第二处理器200可被实现为使得第一处理器100与第二处理器200由单独的或相应的独立电源驱动。因此,可根据具体操作情况切断向第一处理器100及第二处理器200中的未被使用的一者供应的电力。
图2示出用于解释根据本发明概念实施例的半导体装置的第一处理器的示意图。参照图2,半导体装置1(图1所示)的第一处理器100包括内部寄存器110、加载存储单元(loadstoreunit,lsu)120、数据排列层130、映射层140及归纳层(reducelayer)150。
内部寄存器110包括以上参照图1所阐述的图像寄存器112、系数寄存器114及输出寄存器116。
加载存储单元120可向存储器装置(例如,图1所示存储器装置500)传送数据以及从所述存储器装置接收数据。举例来说,加载存储单元120可通过例如图1所示存储器总线400来读取存储在存储器装置(图中未示出)中的数据。加载存储单元120及存储器总线400可对应于以下将参照图4阐述的存储器层次结构(memoryhierarchy)105。
在一些示例性实施例中,加载存储单元120可同时读取1024位数据。同时,在一些示例性实施例中,加载存储单元120可通过支持n个端口(例如,n为2、4、8等)来同时读取1024×n位数据。由于加载存储单元120可同时读取以每1024位为单位的数据,因此以下将要阐述的数据排列层130可根据单指令多数据(simd)架构以其中一行由1024位构成的排列形式来对数据进行重新排列。
数据排列层130可对应于在图1中被示出为数据排列模块190的元件,且可对用于在第一处理器100处进行处理的数据进行重新排列。具体来说,数据排列层130可产生用于对将由第一处理器100处理的各种大小的数据(例如,矩阵)高效地执行感兴趣区域计算的数据图案。根据作为数据图案而产生的数据的类型,数据排列层130可包括分别与在图1中被示出为图像数据排列器192及系数数据排列器194的元件对应的子单元。
具体来说,数据排列层130可根据单指令多数据架构以分别包含多个数据的多个数据行的形式来对用于在第一处理器100处进行处理的数据进行重新排列。举例来说,数据排列层130可根据单指令多数据架构以分别包含多个数据的多个数据行的形式来对图像数据进行重新排列,以使得第一处理器100高效地执行感兴趣区域计算,同时还根据单指令多数据架构以分别包含多个数据的多个数据行的形式来对用于对图像数据进行计算的滤波器的系数数据进行重新排列。
尽管在图2中仅示出单个算术逻辑单元(alu)160,然而第一处理器100可包括多个算术逻辑单元(alu)160,所述多个算术逻辑单元160相对于彼此并行地排列从而与多个数据行中的每一者对应。所述多个算术逻辑单元160中的每一者可包括映射层140及归纳层150。算术逻辑单元160可执行映射计算、归纳计算等,从而使用映射层140及归纳层150来并行地处理存储在多个数据行中的每一个数据行中的数据。
通过采用对数据进行重新排列的结构,尤其可对例如在图像处理、视觉处理、及神经网络处理中经常使用的3×3矩阵、4×4矩阵、5×5矩阵、7×7矩阵、8×8矩阵、9×9矩阵、11×11矩阵执行高效处理。以下将参照图4、图6及图7阐述具体解释。
图3示出用于解释根据本发明概念实施例的半导体装置的第二处理器的视图。参照图3,半导体装置1(图1所示)的第二处理器200包括提取单元220及解码器230。
解码器230可对从提取单元220提供的指令进行解码。在一些示例性实施例中,指令可根据超长指令字架构由四个槽位240a、240b、240c及240d来进行处理,由此提取单元220会向解码器230提供超长指令字指令。举例来说,当由提取单元220提取的指令是128位时,解码器230可将所提取的指令解码成分别由32位构成的四个指令,且所述四个指令可分别由槽位240a、240b、240c及240d来进行处理。也就是说,提取单元220可被配置成向解码器230提供超长指令字指令,且解码器230可被配置成将超长指令字指令解码成多个指令。
尽管为解释方便起见,实施例示出所提取的指令被解码成四个指令且由四个槽位进行处理,然而第二处理器200并非仅限于在四个槽位处进行处理。举例来说,指令可被实现为在不少于2的任意数目的槽位处进行处理。
在一些示例性实施例中,四个槽位240a、240b、240c、240d可同时执行除了在控制单元(controlunit,ct)244d处执行的控制指令之外的所有指令。为高效进行这种并行处理,在四个槽位240a、240b、240c及240d中可设置有标量功能单元(scalarfunctionalunit,sfu)242a、242b及242d、向量功能单元(vectorfunctionalunit,vfu)244a、244b及244c、以及移动单元(moveunit,mv)246a、246b、246c及246d。
具体来说,第一槽位240a可包括标量功能单元242a、向量功能单元244a、及移动单元246a,且第二槽位240b可包括标量功能单元242b、向量功能单元244b及移动单元246b。第三槽位240c可包括柔性卷积引擎(fce)单元242c、向量功能单元244c及移动单元246c,此对应于使用第一处理器100对指令进行的处理。第四槽位240d可包括标量功能单元242d、与控制指令对应的控制单元(controlunit,ct)244d以及移动单元246d。
在此实例中,第三槽位240c的柔性卷积引擎单元242c可对应于第一处理器100。另外,除了第三槽位240c之外的槽位(即,第一槽位240a、第二槽位240b及第四槽位240d)可对应于第二处理器200。举例来说,在第三槽位240c的柔性卷积引擎单元242c中设置的指令可由第一处理器100执行,且在第四槽位240d中设置的指令可由第二处理器200执行。
另外,第一处理器100与第二处理器200可使用槽位240a、240b、240c及240d中的每一者中所包括的移动单元246a、246b、246c及246d来共享彼此的数据。因此,如果需要,则可通过槽位240c的柔性卷积引擎单元242c来使原本可能打算由第二处理器200处理的工作转而由第一处理器100来处理。另外,在这种情形中,原本可能打算由第二处理器200处理的数据也可由第一处理器100分担。
由标量功能单元242a、242b及242d进行处理的结果可存储在相对于图1所阐述的标量寄存器212中,且由向量功能单元244a、244b及244c进行处理的结果可存储在也相对于图1所阐述的向量寄存器214中。当然,存储在标量寄存器212及向量寄存器214中的结果可根据需要由第一处理器100及第二处理器200中的至少一者使用。
应理解,图3中所示出的配置仅是为解释方便而呈现的本发明概念的各种实施例中的一者,且第二处理器200不应仅限于图2所示实施例。
图4示出用于解释根据本发明概念实施例的半导体装置的架构的示意图。参照图4,根据本发明概念实施例的半导体装置的架构可包括存储器层次结构105、寄存器文件(registerfile)110、数据排列层130、多个算术逻辑单元160以及用于控制这些元件的总体操作的控制器170。
举例来说,存储器层次结构105可提供(或包括)以上参照图1及图2阐述的存储器接口、存储器装置(例如,图1所示存储器装置500)、存储器总线400、加载存储单元120等。
寄存器文件110可对应于包括以上参照图2阐述的图像寄存器112、系数寄存器114及输出寄存器116的内部寄存器110。另外,寄存器文件110可包括以下参照图5a至图5d阐述的示例性结构。
数据排列层130可对应于以上参照图2阐述的数据排列层130,且可产生用于对用于在第一处理器100处进行处理的各种大小的数据(例如,矩阵)高效地执行感兴趣区域计算的数据图案。
多个算术逻辑单元160可对应于以上参照图2阐述的多个算术逻辑单元160,可包括映射层140及归纳层150,且可执行映射计算、归纳计算等。
图4所示架构使得能够使用可由多个算术逻辑单元160共享的寄存器文件110来实现准确的流程控制及复杂的算术计算,同时还使得能够使用数据排列层130对存储在寄存器文件110中的数据进行图案化(patternizing),从而提高输入数据的重复利用率。
举例来说,数据排列层130可产生数据图案以使得用于进行处理的数据(具体来说,用于感兴趣区域计算的数据)可分别由属于第一算术逻辑单元群组160a、第二算术逻辑单元群组160b、...、第八算术逻辑单元群组160c及第九算术逻辑单元群组160d的多个算术逻辑单元进行处理。算术逻辑单元群组160a、160b、160c及160d被示出为分别包括例如64个算术逻辑单元,但是在本发明概念的其他实施例中,算术逻辑单元群组可包括任意其他适合数目的算术逻辑单元。以下将参照图6至图8e具体阐述如何产生适于由九个算术逻辑单元群组160a、160b、160c及160d处理的数据图案。
图5a、图5b、图5c及图5d示出用于解释根据本发明概念实施例的半导体装置的寄存器的结构的示意图。
参照图5a,图1所示半导体装置1的图像寄存器(ir)112被设置成存储特别地用于在第一处理器100处处理感兴趣区域计算的输入图像数据。应理解,本实施例中的图像寄存器112被表征为图像寄存器‘ir’,这是因为图像寄存器112用于存储输入图像数据,但在其他实施例中,可根据具体实现方式来对图像寄存器112进行不同的命名。
根据本发明概念的实施例,举例来说,图像寄存器112可被实施为包含16个项。另外,举例来说,项ir[i](其中,i是值为0到15的整数)中的每一者的大小可被实施为1024位。
在这些项中,项ir[0]到ir[7]可被定义为并用作寄存器文件isr0来支持各种感兴趣区域计算的图像数据大小。同样地,项ir[8]到ir[15]可被定义为并用作寄存器文件isr1来支持各种感兴趣区域计算的图像数据大小。
然而,应理解,对寄存器文件isr0及寄存器文件isr1的定义并非被限制为对于图5a所阐述,而是可根据所处理的数据的大小来以各种方式对寄存器文件isr0及寄存器文件isr1进行分组及定义。也就是说,考虑到例如图像数据大小、矩阵计算特征、滤波器计算特征等,可将寄存器文件isr0及寄存器文件isr1定义成具有与图5a所示结构不同的结构。
接下来,参照图5b,图1所示半导体装置1的系数寄存器(cr)114被设置成存储用于对存储在图像寄存器112中的图像数据进行计算的滤波器的系数。应理解,本实施例中的系数寄存器114被表征为系数寄存器‘cr’,这是因为系数寄存器114用于存储系数,但在其他实施例中,可根据具体实现方式来对系数寄存器114进行不同的命名。
根据本发明概念的实施例,举例来说,系数寄存器114可被实现为包含16个项。另外,举例来说,项cr[i](其中,i是值为0到15的整数)中的每一者的大小可被实现为1024位。
在这些项中,项cr[0]到cr[7]可被定义为并用作寄存器文件csr0来支持各种感兴趣区域计算的图像数据大小,如在图像寄存器112的情形中一样。同样地,项cr[8]到cr[15]可被定义为并用作寄存器文件csr1来支持各种感兴趣区域计算的图像数据大小。
然而,应理解,对寄存器文件csr0及寄存器文件csr1的定义并非被限制为对于图5b所阐述,而是可根据所处理的数据的大小来以各种方式对寄存器文件csr0及寄存器文件csr1进行分组及定义。也就是说,考虑到例如图像数据大小、矩阵计算特征、滤波器计算特征等,可将寄存器文件csr0及寄存器文件csr1定义成具有与图5b所示结构不同的结构。
接下来,参照图5c,图1所示半导体装置1的输出寄存器(or)116被设置成存储来自在第一处理器100处对图像数据进行的处理的计算结果。应理解,本实施例中的输出寄存器116被表征为输出寄存器‘or’,这是因为输出寄存器116用于存储计算结果,但在其他实施例中,可根据具体实现方式来对输出寄存器116进行不同的命名。
根据本发明概念的实施例,举例来说,输出寄存器116可被实现为包含16个项。输出寄存器116的各个项可包括对应的部分orh[i]及orl[i],如图5c所示。包括对应的部分orh[i]及orl[i]的项在下文中可笼统地被表征为项or[i](其中,i是值为0到15的整数)。另外,举例来说,项or[i]中的每一者的大小可被实现为2048位。在本发明概念的实施例中,输出寄存器116的大小可以是图像寄存器112的大小的整数倍。
在本发明概念的一些示例性实施例中,输出寄存器116可用作图4所示数据排列层130的输入寄存器。在这种情形中,为高效地重复使用存储在输出寄存器116中的计算结果,输出寄存器116的每一个项or[i]可被划分成上部部分orh[i]及下部部分orl[i]。举例来说,项or[0]可包括具有1024位的上部部分orh[0]以及具有1024位的下部部分orl[0]。为实现与以下将参照图5d阐述的w寄存器的兼容性,可实现将每一个项or[i]划分成上部部分orh[i]及下部部分orl[i]的这种划分。w寄存器是指存储对寄存器文件ve中所包含的对应项与在寄存器文件vo中所包含的对应项进行整合的结果的相应的单个项,如图5d所示。
通过将输出寄存器116的各个项定义成使得各个项具有与图像寄存器112的各个项及系数寄存器114的各个项中的每一个项相同的大小,可更容易且更方便地实现在图像寄存器112、系数寄存器114及输出寄存器116之间移动数据。也就是说,由于输出寄存器116的各个项可与图像寄存器112的各个项及系数寄存器114的各个项兼容,因此可高效、方便地移动数据。
在这些项中,项or[0](如图中所示包括部分orh[0]及orl[0])到or[7](如图中所示包括部分orh[7]及orl[7])可被定义为并用作寄存器文件osr0来支持各种感兴趣区域计算的图像数据大小,如在图像寄存器112及系数寄存器114的情形中一样。同样地,项or[8](如图中所示包括部分orh[8]及orl[8])到or[15](如图中所示包括部分orh[15]及orl[15])可被定义为并用作寄存器文件osr1来支持各种感兴趣区域计算的图像数据大小。
然而,应理解,对寄存器文件osr0及寄存器文件osr1的定义并非被限制为对于图5c所阐述,而是可根据所处理的数据的大小来以各种方式对寄存器文件osr0及寄存器文件osr1进行分组及定义。也就是说,考虑到例如图像数据大小、矩阵计算特征、滤波器计算特征等,可将寄存器文件osr0及寄存器文件osr1定义成具有与图5c所示结构不同的结构。
另外,图像寄存器112、系数寄存器114及输出寄存器116的项的大小、及/或构成寄存器文件的项的数目并非仅限于上述实施例,且项的大小及/或数目可根据实现方式的具体目的而有所变化。
在图5a至图5c中基于图像寄存器112、系数寄存器114及输出寄存器116的用途单独阐述了图像寄存器112、系数寄存器114及输出寄存器116。然而,在一些示例性实施例中,可实现寄存器虚拟化(virtualization)以使得从第一处理器100的角度来说,可感知到犹如存在具有相同大小的四组寄存器一样。
现参照图5d,向量寄存器(vr)214被设置成存储用于在第二处理器200处执行向量计算的数据。
根据实施例,向量寄存器214可被实现为包含16个项。举例来说,所述16个项如图5d所示可包含在下文中可笼统地被表征为项ve[i](其中,i是0与15之间的偶数整数(即,偶数编号的索引))的项ve[0]、ve[2]、ve[4]、ve[6]、ve[8]、ve[10]、ve[12]及ve[14]、以及在下文中可笼统地被表征为项vo[i](其中,i是0与15之间的奇数整数(即,奇数编号的索引))的项vo[1]、vo[3]、vo[5]、vo[7]、vo[9]、vo[11]、vo[13]及vo[15]。另外,举例来说,项ve[i]及vo[i]中的每一者的大小可被实现为1024位。
根据实施例,所述16个项中的与偶数编号的索引对应的8个项ve[i]可被定义为寄存器文件ve,且所述16个项中的与奇数编号的索引对应的8个项vo[i]可被定义为寄存器文件vo。另外,可实现w寄存器,w寄存器包含在下文中可笼统地被表征为项w[i](i是值为0到7的整数)的相应的单个项并存储对寄存器文件ve中所包含的对应项与寄存器文件vo中所包含的对应项进行整合的结果。
举例来说,可定义存储对项ve[0]与项vo[1]进行整合的结果的一个项w[0],且可定义存储对项ve[2]与项vo[3]进行整合的结果的一个项w[1],由此建立如图中所示包含总共8个项w[i]的w寄存器。
向量寄存器214的项的大小、及/或构成寄存器文件的项的数目并非仅限于上述实施例,且项的大小及/或数目可根据实现方式的具体目的而有所变化。
如以上在图5a至图5c中阐述的图像寄存器112、系数寄存器114及输出寄存器116的情形中一样,对于向量寄存器214来说,可实现寄存器虚拟化以使得从第一处理器100及第二处理器200的角度来说,可感知到犹如存在具有相同大小的五组寄存器一样。
在以上情形中,存储在虚拟寄存器中的数据可通过图3所示移动单元246a、246b、246c及246d在图像寄存器112、系数寄存器114、输出寄存器116及向量寄存器214之间移动。因此,第一处理器100与第二处理器200可使用虚拟寄存器共享数据或对所存储的数据进行重复使用,而非对存储器装置(例如,图1所示存储器装置500)进行存取或使用所述存储器装置。
图6示出用于解释其中将数据存储在根据本发明概念实施例的半导体装置中的实现方式的示意图。参照图6,由数据排列层130重新排列的数据可构成9个并行排列的数据行(data1到data9)。
数据行(data1到data9)中的每一者在垂直方向上可具有多个道。举例来说,第一数据行data1的第一要素a1、第二数据行data2的第一要素b1、第三数据行data3的第一要素c1、...及第九数据行data9的第一要素d1可形成第一道,且第一数据行data1的第二要素a2、第二数据行data2的第二要素b2、第三数据行data3的第二要素c3、...及第九数据行data9的第二要素d2可形成第二道。在图6中,由数据排列层130重新排列的数据包括64个道。
根据实施例,每一个道的宽度可以是16位。也就是说,第一数据行data1的第一要素a1可以16位数据形式存储。在这种情形中,第一数据行data1可包括分别具有16位数据形式的64个要素a1、a2、a3、...及a64。相似地,第二数据行data2可包括分别具有16位数据形式的64个要素b1、b2、b3、...及b64,第三数据行data3可包括分别具有16位数据形式的64个要素c1、c2、c3、...及c64,且第九数据行data9可包括分别具有16位数据形式的64个要素d1、d2、d3、...及d64。
第一处理器100可包括用于处理由数据排列层130重新排列的数据的多个算术逻辑单元,且所述多个算术逻辑单元可包括分别与9个数据行(data1到data9)对应的9×64个算术逻辑单元。举例来说,图4所示第一算术逻辑单元群组160a可对应于第一数据行data1,且图4所示第二算术逻辑单元群组160b可对应于第二数据行data2。另外,图4所示第八算术逻辑单元群组160c可对应于第八数据行data8(图中未示出),且图4所示第九算术逻辑单元群组160d可对应于第九数据行data9。
另外,第一算术逻辑单元群组160a的64个算术逻辑单元(即,alu1_1到alu1_64)可分别并行地处理与第一数据行data1的64个要素对应的数据,且第二算术逻辑单元群组160b的64个算术逻辑单元(即,alu2_1到alu2_64)可分别并行地处理与第二数据行data2的64个要素对应的数据。另外,第八算术逻辑单元群组160c的64个算术逻辑单元(即,alu8_1到alu8_64)可并行地处理与第八数据行data8的64个要素对应的数据,且第九算术逻辑单元群组160d的64个算术逻辑单元可分别并行地处理与第九数据行data9的64个要素对应的数据。因此,在对于图4及图6阐述的实施例中,半导体装置1包括分别具有m个道的n个数据行、以及分别处理n个数据行的n个算术逻辑单元群组,其中n个算术逻辑单元群组分别包括m个算术逻辑单元。在图4及图6的实施例中,n是9且m是64。
根据各种实施例,在由数据排列层130重新排列的数据中的数据行的数目并非仅限于9,且可根据实现方式的具体目的而有所变化。另外,分别与多个数据行对应的多个算术逻辑单元的数目可根据实现方式的目的而有所变化。
同时,如以下参照图8a所阐述,当由数据排列层130重新排列的数据的数据行的数目是9时,效率可得到提高,在各种大小的矩阵的感兴趣区域计算中尤其如此。
图7示出用于解释其中将数据存储在根据本发明概念另一个实施例的半导体装置中的实现方式的示意图。
参照图7,由数据排列层130重新排列的数据可构成9个并行排列的数据行(data1到data9)。
参照图7,仅阐述图6所示实现方式与图7所示实现方式之间的差异。在图7中,数据行(data1到data9)中的每一者在垂直方向上可具有多个道,且根据实施例,每一个道的宽度可以是8位。也就是说,第一数据行data1的第一要素a1可以8位数据形式存储。在这种情形中,第一数据行data1可包括分别具有8位数据形式的128个要素。
第一处理器100可包括用于处理由数据排列层130重新排列的数据的多个算术逻辑单元,且多个算术逻辑单元可包括分别与9个数据行(data1到data9)对应的9×128个算术逻辑单元。
根据各种实施例,在由数据排列层130重新排列的数据中的数据行的数目并非仅限于9,且可根据实现方式的具体目的而有所变化。另外,分别与多个数据行对应的多个算术逻辑单元的数目可根据实现方式的具体目的而有所变化。
如以下参照图8a所阐述,当由数据排列层130重新排列的数据的数据行的数目是9时,效率可得到提高,在各种大小的矩阵的感兴趣区域计算中尤其如此。
图8a示出为解释对各种大小的矩阵进行的感兴趣区域计算的数据图案而提供的示意图,图8b及图8c示出用于解释根据本发明概念实施例的感兴趣区域计算的数据图案的示意图,且图8d、图8e、图8f及图8g示出用于解释根据本发明概念另一个实施例的感兴趣区域计算的数据图案的示意图。参照图8a至图8g,可根据在与图像处理、视觉处理、及神经网络处理相关联的应用中最频繁使用的矩阵大小来确定使用由数据排列层130重新排列的数据的图案。
参照图8a,矩阵m1包含将通过感兴趣区域计算执行的图像大小3×3所需的图像数据,且矩阵m2包含将通过感兴趣区域计算执行的图像大小4×4所需的图像数据。矩阵m3包含将通过感兴趣区域计算执行的图像大小5×5所需的图像数据,矩阵m4包含将通过感兴趣区域计算执行的图像大小7×7所需的图像数据,且矩阵m5包含将通过感兴趣区域计算执行的图像大小8×8所需的图像数据。同样地,矩阵m6包含将通过感兴趣区域计算执行的图像大小9×9所需的图像数据,且矩阵m7包含将通过感兴趣区域计算执行的图像大小11×11所需的图像数据。举例来说,假设图8a所示图像数据存储在存储器装置(例如图1所示存储器装置500)中。如图8b所示,当对3×3大小的矩阵(例如,m11、m12及m13)执行感兴趣区域计算时,第一处理器100可读取存储在存储器装置中的图8a所示图像数据,并将所述图像数据存储在图像寄存器112中。
在这种情形中,参照图8c,与矩阵m11对应的图像数据(n11到n19)可排列在9个并行排列的数据行(data1到data9)的位于第一方向上的第一道处。接下来,与矩阵m12对应的图像数据n12、n13、n21、n15、n16、n22、n18、n19及n23可排列在第二道处。接下来,与矩阵m13对应的图像数据n13、n21、n31、n16、n22、n32、n19、n23及n33可排列在第三道处。
因此,例如图4所示的多个算术逻辑单元(alu1_1到alu9_1)可对包含与矩阵m11对应的图像数据的第一道执行感兴趣区域计算,且多个算术逻辑单元(alu1_2到alu9_2)可对包含与矩阵m12对应的图像数据的第二道执行感兴趣区域计算。另外,多个算术逻辑单元(alu1_3到alu9_3)可对包含与矩阵m13对应的图像数据的第三道执行感兴趣区域计算。
由于图像数据是如在以上实施例中所阐述的一样被处理,因此当假设将通过感兴趣区域计算执行的矩阵具有3×3大小时,第一处理器100每一个循环可对三个图像行执行矩阵计算。在此实例中,使用多个算术逻辑单元来并行处理9个数据行(data1到data9)会提供100%的效率。
如图8d所示,当对5×5大小的矩阵(例如,m31及m32)执行感兴趣区域计算时,第一处理器100可读取存储在存储器装置中的图8a所示图像数据,并将所述图像数据存储在图像寄存器112中。
在这种情形中,参照图8e、图8f、及图8g,5×5矩阵计算总共执行三个循环。在如图8e所示的第一循环期间,计算是利用与对于图8b及图8c所阐述的用于3×3矩阵的方法相同方法来执行。在如图8f所示的第二循环期间,图8a所示矩阵m2中的除了图8a所示矩阵m1的图像数据之外的图像数据(n21、n22、n23、n27、n26、n25及n24)被分配到算术逻辑单元(alu1_1到alu9_1)或者被分配到第一向量道,且图像数据n31、n32、n33、n34、n27、n26及n25的数据被分配到算术逻辑单元(alu1_2到alu9_2)或者被分配到第二向量道。在第二循环期间,数据是使用相同的方法被连续地分配到各个道。在如图8g所示的第三循环期间,矩阵m3中的除了矩阵m2的图像数据之外的图像数据(n31、n32、n33、n34、n37、n36、n35、n29及n28)被分配到算术逻辑单元(alu1_1到alu9_1)或者被分配到第一向量道,且对于后续道来说,分配及处理是以相同的方式继续进行。
由于图像数据是以根据以上实施例阐述的方式进行处理,因此当假设将通过感兴趣区域计算执行的矩阵具有5×5大小时,第一处理器100在第二循环期间跳过对仅两个数据(如在图8f中由项dm表示)的计算,且因此,获得93%的算术逻辑单元使用效率((64个道×9个列×3个循环-64个道×2个列)×100/64×9×3)。
在相同的上下文中,当假设将通过感兴趣区域计算执行的矩阵具有4×4大小时,第一处理器100通过两个循环来执行矩阵计算,同时跳过对仅两个数据的计算,在这种情形中,获得89%的算术逻辑单元使用效率。
当假设将通过感兴趣区域计算执行的矩阵具有7×7大小时,第一处理器100通过六个循环来执行矩阵计算,同时跳过对仅五个数据的计算,在这种情形中,获得91%的算术逻辑单元使用效率。
当假设将通过感兴趣区域计算执行的矩阵具有8×8大小时,第一处理器100通过八个循环来执行矩阵计算,同时跳过对仅八个数据的计算,在这种情形中,获得89%的算术逻辑单元使用效率。
当假设将通过感兴趣区域计算执行的矩阵具有9×9大小时,第一处理器100通过九个循环来对九个图像行执行9×9矩阵计算,同时使用所有的数据,在这种情形中,获得100%的算术逻辑单元使用效率。
当假设将通过感兴趣区域计算执行的矩阵具有11×11大小时,第一处理器100通过14个循环来执行矩阵计算,同时跳过对来自11个图像行的仅八个数据的计算,在这种情形中,获得96%的算术逻辑单元使用效率。
如以上参照图8a至图8g所阐述,在对包含在与图像处理、视觉处理、及神经网络处理相关联的应用中最频繁使用的矩阵大小即3×3、4×4、5×5、7×7、8×8、9×9、11×11这些大小在内的各种矩阵大小执行感兴趣区域计算时,当由数据排列层130重新排列的数据的数据行的数目是9时,可维持第一处理器100的90%的算术逻辑单元使用效率。
在一些示例性实施例中,当所计算的矩阵的大小增大时,仅对从之前的矩阵大小增大的部分执行数据排列。举例来说,为对图8a所示矩阵m2执行第二计算,在对矩阵m1执行第一计算之后,可仅对第二计算所需的图像数据(n21、n22、n23、n27、n26、n25及n24)执行额外的数据排列。
在一些示例性实施例中,多个算术逻辑单元可使用存储在图像寄存器112中的图像数据以及存储在系数寄存器114中的过滤器系数执行计算,并将结果存储在输出寄存器116中。
图8h示出用于解释根据本发明概念实施例的半导体装置的上移计算的示意图。
参照图8h,由根据本发明概念实施例的半导体装置执行的上移计算可控制用于读取存储在图像寄存器112中的数据的方法以对来自存储器装置的之前存储在图像寄存器112中的图像数据进行高效处理。
为具体解释上移计算,当需要对例如图8d所示5×5矩阵m31及m32进行感兴趣区域计算时,与图8h所示第一区r1对应的所有图像数据可能均已经过处理,且当需要处理与图8h所示第二区r2对应的图像数据时,从存储器向图像寄存器112读取额外需要的仅第六行数据(即,图像数据n38、n39、n46、n47、n48、n49、n56、n76、n96、na6及nb6)。
举例来说,当与第一区r1对应的第一行到第五行的数据分别存储在图5a所示的ir[0]到ir[4]中时,第六行的数据可预先存储在ir[5]中。这样,仅通过将图像寄存器112的读取区调整到第二区r2便可针对第二行到第六行来对5×5矩阵m31及m32连续地执行感兴趣区域计算,同时避免额外的存储器存取。
图9示出用于解释其中使用根据本发明概念各个实施例的半导体装置执行哈里斯角点检测的示例性操作的流程图。应理解,哈里斯角点检测是所属领域中的技术人员所熟知的,且因此此处将不再具体解释。
参照图9,哈里斯角点检测的实施例在s901处包括输入图像。举例来说,用于角点检测的图像通过图1所示存储器总线400(例如,从例如图1所示存储器装置500等存储器装置)被输入到第一处理器100。
在s903处,计算推导值(derivativevalue)dv。举例来说,第一处理器100可根据需要例如从由数据排列层130重新排列的图像数据来对沿x轴及y轴的像素计算推导值dv。在此实例中,可通过应用例如索贝尔滤波器(sobelfilter)等一维滤波器、通过将每一个图像乘以在x轴方向上的推导系数(ix=gx*i)以及在y轴方向上的推导系数(iy=gy*i)来容易地获得推导值(derivative)。所输入的图像被存储在图像寄存器112中,推导系数(gx及gy)被存储在系数寄存器114中,且相乘的结果(ix及iy)被存储在输出寄存器116中。
接下来,在s905处,对推导乘积(derivationproduct)dp进行计算。举例来说,根据需要,第一处理器100可从由数据排列层130重新排列的推导值dv来对每一个像素计算推导乘积dp。基于s903的结果,对x轴结果及y轴结果(即,推导值)求平方(ix2,iy2),且将x轴求平方结果与y轴求平方结果彼此相乘(ixy=ix2*iy2),由此提供dp值。在此实例中,通过重复使用存储在输出寄存器116中的s903的结果,使用输出寄存器116的图像数据排列器192/系数数据排列器194图案来将计算的x轴结果及y轴结果用作向量算术逻辑单元输入,且计算的结果被再次存储在输出寄存器116中。
接下来,在s907处,计算误差平方和(ssd)。举例来说,第一处理器100使用推导乘积dp计算误差平方和。与在s905处的运算相似,误差平方和计算(sx2=gx*ix2、sy2=gy*iy2、sxy=gxy*ix*iy)也对存储在输出寄存器116中的数据进行处理作为s905中的运算结果,且图像数据排列器192将数据分配到例如图3所示的向量功能单元(vfu)244a、244b及244c,乘以存储在系数寄存器114中的推导系数,并再次将结果存储在输出寄存器116中。
在s909处,定义关键点矩阵。另外,由于确定关键点矩阵难以仅利用专用于感兴趣区域处理的第一处理器100来执行,因此确定关键点矩阵可通过第二处理器200来执行。也就是说,第二处理器200定义关键点矩阵。
在这种情形中,在第一处理器100的输出寄存器116中存储的所得值可由第二处理器200所共享并被重复使用。举例来说,可使用图3所示移动单元246a、246b、246c及246d将存储在第一处理器100的输出寄存器116中的所得值移动到第二处理器200的向量寄存器214。作为另外一种选择,可被直接输入有输出寄存器116的值的向量功能单元(vfu)244a、244b及244c可使用第一处理器100处的结果,而无需经过移动单元246a、246b、246c及246d。
接下来,在s911处,计算响应函数(r=det(h)–k(trace(h)2))。举例来说,第二处理器200使用存储在向量寄存器214中的s909的所得值来计算响应函数。在这一阶段,由于仅使用第二处理器200,因此所有计算的中间结果及最终结果均存储在向量寄存器214中。
接下来,在s913处,通过执行非极大值抑制(nms)计算来检测关键点。s913处的操作可再次由第一处理器100来处理。
在这种情形中,在第二处理器200的向量寄存器214中存储的所得值可由第一处理器100所共享并被重复使用。举例来说,可使用图3所示移动单元246a、246b、246c及246d将存储在第二处理器200的向量寄存器214中的所得值移动到第一处理器100的输出寄存器116。作为另外一种选择,可通过图像数据排列器192/系数数据排列器194来将所得值从向量寄存器214直接分配到向量功能单元244a、244b及244c。
由于在以上述方式完成输入图像的角点检测工作之前仅使用第一处理器100的寄存器(即,图像寄存器112、系数寄存器114及输出寄存器116)以及第二处理器200的寄存器(即,标量寄存器212及向量寄存器214),因此不需要对存储器装置进行存取。因此,在对存储器装置进行存取时花费的例如开销及功耗等成本可明显降低。
表一
表一示出用于解释由根据本发明概念实施例的半导体装置所支持的在与视觉处理及神经网络处理相关联的应用中使用的用于高效地处理矩阵计算的指令的实现方式的视图。
参照表一,第一处理器100支持在与视觉处理及神经网络处理相关联的应用中使用的用于高效地处理矩阵计算的指令。所述指令可主要被划分成三种类型的指令(或阶段)。
map指令是例如用于使用多个算术逻辑单元160计算数据的指令,且支持由例如add、sub、abs、absdiff、cmp、mul、sqr等操作码(opcode)标识的计算。map指令以第一处理器100的输出寄存器116作为目标寄存器,且使用从图像数据排列器192及系数数据排列器194中的至少一者产生的数据图案作为操作数(operand)。另外,可额外地(可选地)包含字段来指示所处理数据的单位是8位还是16位。
reduce指令是例如用于树计算的指令,且支持由例如添加树(addtree)、最小化树(minimumtree)、最大化树(maximumtree)等操作码标识的计算。reduce指令以第一处理器100的输出寄存器116及第二处理器200的向量寄存器214中的至少一者作为目标寄存器,且使用从图像数据排列器192及系数数据排列器194中的至少一者产生的数据图案。另外,可额外地包含字段来指示所处理数据的单位是8位还是16位。
map_reduce指令是用于对映射计算及归纳计算进行组合的指令。map_reduce指令以第一处理器100的输出寄存器116及第二处理器200的向量寄存器214中的至少一者作为目标寄存器,且使用从图像数据排列器192及系数数据排列器194中的至少一者产生的数据图案。另外,可额外地包含字段来指示所处理数据的单位是8位还是16位。
根据上述各个实施例,第一处理器100与第二处理器200共享相同的指令集架构以使得专用于感兴趣区域计算的第一处理器100与专用于算术计算的第二处理器200在指令层次上共享,从而有利于进行控制。另外,通过共享寄存器,第一处理器100与第二处理器200可提高数据利用率并减少存储器存取次数。另外,通过使用对用于在第一处理器100处进行处理的各种大小的数据(例如,矩阵)高效地执行感兴趣区域计算的数据图案,便可有可能对在图像处理、视觉处理、及神经网络处理中频繁使用的矩阵大小即3×3矩阵、4×4矩阵、5×5矩阵、7×7矩阵、8×8矩阵、9×9矩阵、11×11矩阵专门地执行高效处理。
图10a及图10b示出用于解释用于图8d中的5×5矩阵的卷积计算的实际汇编指令的实例的视图。
参照表一及图10a,在框架1100中,在第一行处的mapmul_reduceacc16(ida_conv3(ir),cda_conv3(cr,w16))指令(即,第一汇编指令)中,mapmul_reduceacc16指示将根据表一所示阶段、目标寄存器、操作数1、操作数2、及操作码在map阶段及reduce阶段执行的指令。因此,对于16位数据,在map阶段执行mul指令且在reduce阶段执行添加树,其中由于对之前的加法结果进行累加而使用了acc指令。每一行的运算符“.”是用于对将在第一处理器100及第二处理器200的槽位240a、240b、240c及240d中的每一者中进行处理的指令进行区分的运算符。因此,计算操作是使用单指令多数据的指令集与多槽位超长指令字结构在第一处理器100及第二处理器200中执行的。举例来说,mapmul_reducedacc16被分配到第一处理器100所在的槽位,且shupreg=1指令被分配到与第二处理器200对应的槽位。指令‘shupreg’是如以上在图8f中所阐述的用于改变在计算中使用的寄存器数据区(寄存器窗口)的上移寄存器指令,且可被实现成由第一处理器100或第二处理器200执行。除了mapmul_reducedacc16之外的其他指令可在与第二处理器200对应的槽位中执行,但并非仅限于此。根据实现方式的方法而定,所述其他指令也可在第一处理器100中执行。
在此实例中,从虚拟寄存器接收到输入值,ida_conv3(ir)及cda_conv3(cr,w16)。conv3指示图8b中的3×3矩阵(即,n×n矩阵)的数据图案是从图像寄存器112及系数寄存器114输入的。当执行第一汇编指令时,图8b所示矩阵m11的数据被存储在第一道处,矩阵m12的数据被存储在第二道处,矩阵m13的数据被存储在第三道处,且其他对应的数据同样地存储在之后的道中。
第二汇编指令mapmul_reduceacc16(ida_conv4(ir),cda_conv4(cr,w16))是在仅改变输入数据图案的同时以相同的方法计算。在此实例中,如以上对于5×5矩阵计算所阐述,4×4矩阵(即,(n+1)×(n+1)矩阵)的数据中除了3×3矩阵的数据之外的其余数据(例如,图10b中d2区的不包含d1区的区的图像数据)被输入到向量功能单元的每一个道,且对应的结果根据添加树与3×3结果一同被存储在输出寄存器116中。这一结果表示对4×4大小的卷积计算的结果。
最终的mapmul_reduceacc16(ida_conv5(ir),cda_conv5(cr,w16))执行与之前的对5×5矩阵的数据中除了4×4矩阵的数据之外的其余数据的计算相同的计算。
当执行这三个指令时,对于所输入的5个行的5×5矩阵,卷积滤波器的结果被存储在输出寄存器116中。稍后当计算窗口下移一行且再次开始与第一行到第五行对应的5×5矩阵计算时,仅新输入第五行来实现这一目的,而之前使用的第一行到第四行则利用寄存器上移指令来重复使用,如以上参照图8h所阐述。
根据实施例,数据一旦被输入,则将不再从存储器装置重新读取,从而可降低对存储器装置进行存取的频率,且性能及电源效率可得到最大化。
图11示出用于解释使用根据本发明概念实施例的半导体装置的示例性感兴趣区域(roi)计算的流程图。
感兴趣区域计算可根据对于图6至图8h、图10a、图10b及表一所进一步阐述的特征,使用半导体装置(例如对于图1至图5d阐述的半导体装置1)来执行。半导体装置在此实施例中可包括:内部寄存器110,被配置成存储从存储器装置500提供的图像数据;数据排列层130,被配置成将所存储的图像数据重新排列成n个数据行,所述n个数据行分别具有多个道;以及多个算术逻辑单元(alu)160,被排列成用以处理n个数据行的n个算术逻辑单元群组160a、160b、160c、及160d。
参照图11,在s1201处,数据排列层130被配置成对内部寄存器110中的所存储的图像数据的第一数据进行重新排列以提供经重新排列的第一图像数据。第一数据可具有n×n矩阵大小,其中n是自然数。举例来说,第一数据可以是3×3矩阵,且可例如对应于图10b所示的d1区的图像数据。
在图11所示s1203处,算术逻辑单元160被配置成使用经重新排列的第一图像数据执行第一映射计算以产生第一输出数据。
在图11所示s1205处,数据排列层130被配置成对内部寄存器110中的所存储的图像数据的第三数据进行重新排列以提供经重新排列的第二图像数据。此处,第三数据及第一数据被包含为内部寄存器110中所存储的图像数据的第二数据的部分。举例来说,第二数据可具有(n+1)×(n+1)矩阵大小。举例来说,第二数据可以是图10b所示包含数据项n11、n12、n13、n21、n14、n15、n16、n22、n17、n18、n19、n23、n24、n25、n26及n27的4×4矩阵。在此实例中,第三数据可对应于图10b所示d2区的数据项n21、n22、n23、n27、n26、n25及n24。对于此实例还应注意,d2区的第三数据不属于d1区的第一数据。也就是说,d2区的第三数据不包含在由图10b所示d1区的第一数据组成的3×3矩阵中。
在图11所示s1207处,算术逻辑单元160被配置成使用经重新排列的第二图像数据执行第二映射计算以产生第二输出数据。
在图11所示s1209处,算术逻辑单元160被配置成使用第一输出数据及第二输出数据执行归纳计算以产生最终图像数据。
尽管已参照本发明概念的示例性实施例具体示出并阐述了本发明概念,然而所属领域的普通技术人员应理解,在不背离由以上权利要求书所界定的本发明概念的精神及范围的条件下,在本文中可作出形式及细节上的各种变化。因此,期望本实施例在所有方面均被视为例示性的而非限制性的,并应参照随附权利要求书而非上述说明来指示本发明概念的范围。
- 还没有人留言评论。精彩留言会获得点赞!