基于fasterr-cnn的甲状腺肿瘤超声图像自动识别方法与流程
本发明涉及医疗图像识别的技术领域,尤其是指一种基于fasterr-cnn的甲状腺肿瘤超声图像自动识别方法。
背景技术
近年来,随着硬件的提升,人工智能兴起的浪潮带给了人们智能化的生活,而为人工智能的发展带来突破性拐点的当属深度学习了。深度学习可以极大地减少人为提取特征的过程,广泛地应用在图像处理,自然语言处理等任务上。而深度学习技术也慢慢地应用在了医疗领域,医疗图像的解读通常依赖于医生,具有较强的主观性,医生在高强度的工作下,连续大量读片可能漏诊或误诊。
传统的医疗图像识别借助于计算机辅助诊断系统(cad)以辅助医生分析和判断医学数据,渐渐地发展为通过利用图像分割技术结合机器学习的方法来进行医疗图像识别,最近也开始利用深度学习技术代替机器学习的方法,但是仍然依赖于图像分割技术然后在利用机器学习或者深度学习的方法。本发明深度学习在图像处理方面的优势,通过自动分析肿瘤图像的特征,能够实现一种端到端训练而不用图像分割的甲状腺肿瘤超声图像自动识别方法,从而辅助医生的判断,减少工作量,提高效率。
技术实现要素:
本发明的目的在于克服现有技术的缺点与不足,提出了一种基于fasterr-cnn的甲状腺肿瘤超声图像自动识别方法,不需要手工进行肿瘤超声图像分割,能够端到端训练网络,并采用数据增强提高识别率。
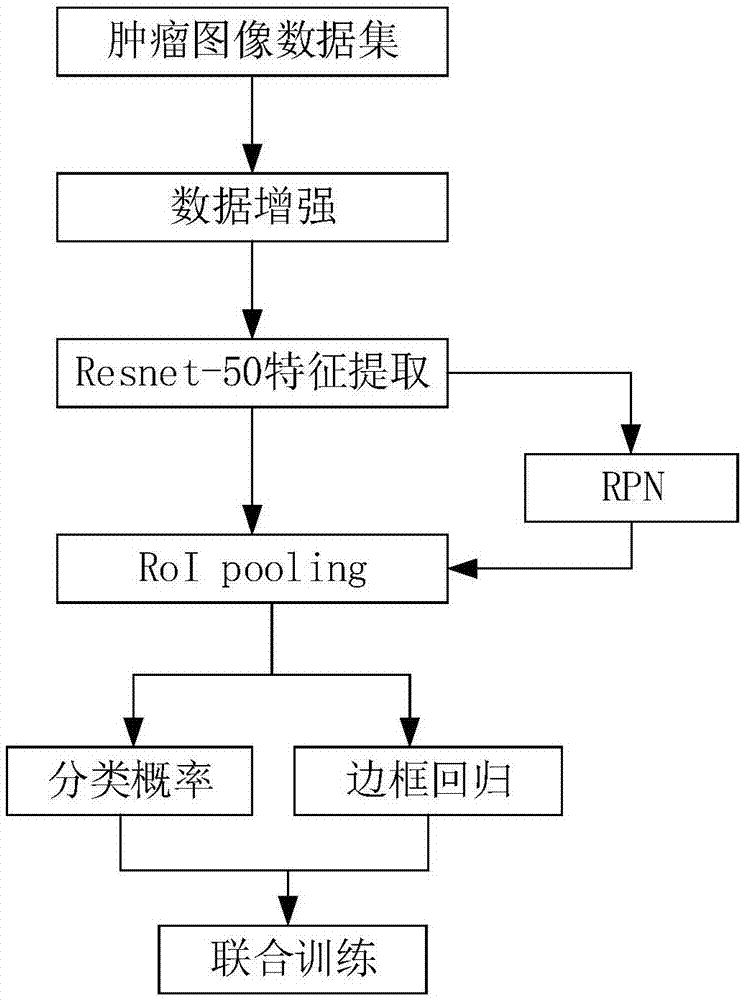
为实现上述目的,本发明所提供的技术方案为:基于fasterr-cnn的甲状腺肿瘤超声图像自动识别方法,包括以下步骤:
步骤s1:对已标注的甲状腺超声肿瘤图片进行划分,得到训练集;
步骤s2:对步骤s1中的训练集进行数据增强处理;
步骤s3:使用resnet-50网络模型对步骤s2中的数据进行特征提取;
步骤s4:通过区域建议网络rpn结合步骤s3得到的所有特征图,在步骤s2得到的原始图片上生成区域建议框;
步骤s5:将步骤s4得到的区域建议框映射到步骤s3中得到的特征图上进行roipooling,通过roipooling层使得每个roi生成固定尺寸的特征图;
步骤s6:利用softmaxloss和softmaxl1loss对分类概率和边框回归联合训练。
步骤s2中所述的数据增强处理步骤如下:
2.1)多次随机裁剪图片的某一区域,如果该区域包含完整的肿瘤区域,则标记该区域并加入到训练集中;
2.2)对图片进行不同尺度的缩放,以及进行边缘增强;
2.3)对数据进行重采样。
步骤s4中生成区域建议框的步骤如下:
4.1)使用3×3大小的卷积核在特征图上滑动,设定一种anchor机制,分别以每一个像素点为中心点,然后基于这个中心点生成3个不同面积大小和3种不同尺寸比例候选区域;
4.2)过滤掉映射到原图中超过原图边界的候选区域;
4.3)判断每个候选区域是否含有目标类,以及目标类的具体位置。
步骤s6中定义的联合损失函数如下:
分类概率采用的softmaxloss定义为:
其中,i为每个批量anchor的下标,pi为anchor是目标类的概率,
边框回归采用的softmaxl1loss定义为:
其中,ti是一个长度为4的向量,表示预测的边框值;
联合损失函数为:
其中,ncls,nreg为归一化的参数;λ为平衡损失函数的权重。
本发明与现有技术相比,具有如下优点与有益效果:
1、本发明提出了一种基于faster-rcnn可以端到端训练的甲状腺肿瘤超声图像识别方法,不像传统方法需要进行图像分割。
2、采用resnet-50作为fasterr-cnn的特征提取卷积网络,使得训练更加有效。
3、使用数据增强技术增加训练样本的个数,避免由于数据量少而产生的过拟合。
附图说明
图1为本发明方法的处理步骤流程图。
具体实施方式
下面结合具体实施例对本发明作进一步说明。
如图1所示,本实施例所提供的基于fasterr-cnn的甲状腺肿瘤超声图像自动识别方法,包括以下步骤:
步骤s1:对包含368个样本的数据集按照4:3:3的比例划分,分别得到训练集,验证集和测试集。
步骤s2:对步骤s1中的训练集按照以下方式进行数据增强处理。
2.1)多次随机裁剪图片的某一区域,如果该区域包含完整的肿瘤区域,则标记该区域并并加入到训练集中,其中裁剪区域为[50,50,1000,1000]。
2.2)对图片按照128,512,1024尺度的缩放,以及进行canny边缘增强。
2.3)对训练集进行重采样。
步骤s3:使用resnet-50网络模型对步骤s2中的数据进行特征提取。
步骤s4:通过区域建议网络rpn结合步骤s3得到的所有特征图,在步骤s2得到的原始图片上生成区域建议框,生成区域建议框步骤如下:
4.1)使用3×3大小的卷积核在特征图上滑动,设定一种anchor机制,分别以每一个像素点为中心点,然后基于这个中心点生成3个不同面积大小(128,256,512,对应到特征分别为3,6,12)和3种不同尺寸比例(1:1,1:2,2:1)候选区域。
4.2)过滤掉映射到原图中超过原图边界的候选区域。
4.3)判断每个候选区域是否含有目标类,以及目标类的具体位置。
步骤s5:将步骤s4得到的区域提议框映射到步骤s3中得到的特征图上进行roipooling,通过roipooling层使得每个roi生成固定尺寸的特征图。
步骤s6:利用softmaxloss和softmaxl1loss对分类概率和边框回归联合训练。其中,损失函数定义如下:
分类概率采用的softmaxloss定义为:
其中,i为每个批量anchor的下标,pi为anchor是目标类的概率,
边框回归采用的softmaxl1loss定义为:
其中,ti是一个长度为4的向量,表示预测的边框值;
联合损失函数为:
其中,ncls,nreg为归一化的参数;λ为平衡损失函数的权重。这里设定ncls=256,nreg=2400,λ=10。
以上所述实施例只为本发明之较佳实施例,并非以此限制本发明的实施范围,故凡依本发明之形状、原理所作的变化,均应涵盖在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!