基于非负矩阵分解及视觉感知的多聚焦图像融合方法与流程
本发明属于图像处理技术领域,尤其涉及一种基于非负矩阵分解及视觉感知的多聚焦图像融合方法。
背景技术
(1)非负矩阵分解
非负矩阵分解(non-negativematrixfactorization,nmf)是一种新的矩阵分解方法,由lee和seung于1999年在《nature》上的一篇论文中提出,该方法在矩阵分解的过程中始终约束所有元素作为非负数存在,即要求所有分量始终为纯加性的描述,同时使分解后的所有分量也均为非负值,并且降低了矩阵的维度。这种纯加性的描述刚好符合许多物理信号中非负性的要求,使得数据的解释更加具有合理性,而矩阵的稀疏的描述能使对数据的解释更加清晰,并且处理更加方便,同时在特征识别过程中抑制由外界变化带来的负面影响(如:噪音、光线和目标形态变化等)。随后,lee和seung又于2001年又对提出的算法迭代规则的收敛性进行了证明,从理论上保证了算法的收敛性。此后,nmf成为目标识别、医学工程、机器人和图像处理等领域的热门研究课题,并得到广泛应用。
非负矩阵分解问题可以做如下描述:已知m维的非负矩阵v=[v·1,v·2,…,v·n],其中v·j=νj,j=1,2,…,n,可以找到适当的非负的m×l的基矩阵w=[w·1,w·2,…,w·n]和l×n的系数矩阵h=[h·1,h·2,…,h·n],使得:
v≈wh(1)
公式(1)也可以表示为向量标量积的形式:
即对于给定的m维数据向量vm×n的集合(其中n为集合中数据样本的个数),可以分解为两个矩阵wm×l和矩阵hl×n,这两个矩阵的积就近似于vm×n。通常,选择l小于m或n,使w和n小于原始矩阵v,这样分解矩阵就降低了原始数据矩阵v的维度。
在传感器成像的过程中,由于传感器自身的因素或外界的各种影响常常会引入各种噪声,因此待融合的原始观测图像实际是就是客观真实世界在成像过程中引入了这些噪声形成的。因此,有效的降低或消除这些噪音,将提高图像的清晰度。在非负矩阵分解算法中,可以假设v=wh+ε(ε表示噪声),此时噪声ε会在迭代算法中趋于收敛,这个过程恰好符合图像融合的过程。因此,联系图像融合过程,如果假设观测图像为v,真实图像为w,噪声为ε,那么v可以理解为w和ε之和,这样nmf可以有效地应用于图像融合。
nmf算法通过迭代运算方法能够针对原始数据矩阵v得到一个基于部分的近似表示形式wh。其中,w的列数即特征基的数量r是一个待定量,它将直接决定特征子空间的维数。对于特定的数据集,隐藏在数据集内部的特征空间的维数是确定的,也就是说当选取的r与实际数据集的特征空间的维数一致时,所得到的特征空间以及特征空间的基最有意义。当r=1时,通过迭代算法将得到唯一的一个含有源数据全部特征的特征基。
由上述内容可知,nmf与图像融合能很好的结合在一起应用。假设有k幅来自于多传感器的大小为m×n的观测图像f1,f2,…,fk,将每副观测图像的元素逐行存储到一个列向量中,这样将可以得到一个mn×k的矩阵v,v中包含k个列向量v1,v2,…,vk,每个列向量代表k幅观测图像中的一幅图像的信息,如公式(3)所示。对这个观测矩阵v进行非负矩阵分解,分解时取r=1,则可得到一个唯一的特征基w。显然,此时的w包含了参与融合的k幅图像的完整特征,将特征基w还原到源图像的像素级上即可得到比源图像效果都好的图像。
(2)视觉感知理论
视觉是人眼对客观事物的感知结果,人类视觉系统(hvs)是研究人眼成像机理、视觉现象及视觉特性的理论。虽然科研人员对此做了大量研究,但到目前为止人类还未能真正的理解和掌握视觉处理的复杂性,不过科研人员也已经研究出了一些有价值的视觉现象,如视觉阈值、视觉掩蔽效应等现象。
根据weber定律,假设存在均匀背景i的情况下,物体的可见性检测门限(对比度敏感门限)δi为δi=0.02·i,即背景亮度和可见性检测门限成正比关系。当一副图像的背景亮度确定的时候,图像中叠加的变化信号必须达到可见性检测门限值之上才能被人眼视觉系统所感知。可见性检测门限是和背景亮度相关联的,背景亮度越强,人眼能感知的叠加信号也就必须越强,这种现象称为对比度掩蔽。
已有的研究已经发现对比度敏感门限和背景亮度之间的关系是按指数规律变化,同时,研究人员也得到了一些对比度敏感函数(contrastsensitivityfunction),其中,对比度敏感门限可被表示为如下公式所示。
δi=i0·max{1,(i/i0)α}
式中i0表示i=0时的对比度敏感门限,α表示幂函数的指数,是常数,根据视觉生理实验,其值为0.6~0.7。
因此,根据上述视觉感知特性,感知相同的绝对梯度,在整体亮度较大处,人眼的感知值较小。
苗启广2005年发表的学术论文“图像融合的非负矩阵分解算法”,论文中利用非负矩阵分解方法实现多源图像的融合。
综上所述,现有技术存在的问题是:
光学镜头在进行光学成像的过程中,由于光学成像系统的聚焦范围有限,会使处于聚焦区域外的物体成像模糊;而现有技术没有采用多聚焦图像融合对聚焦区域不同的多个图像进行融合处理,合成清晰图像,改善视觉效果;并且现有技术存在摄装置的单一聚焦性不足,针对不同目标没有分别进行聚焦得到多个图像;单纯的使用非负矩阵分解方法进行融合,虽然也能实现一定程度的多聚焦点融合,但由于没有结合考虑人类视觉感知特征,总的来说效果并不好。没有结合非负矩阵分解和视觉感知理论将多幅同一场景下聚焦目标各不相同的图像融合成一幅新的所有目标都清晰的图像。
技术实现要素:
针对现有技术存在的问题,本发明提供了一种基于非负矩阵分解及视觉感知的多聚焦图像融合方法。
本发明是这样实现的,一种基于非负矩阵分解及视觉感知的多聚焦图像融合方法,包括:
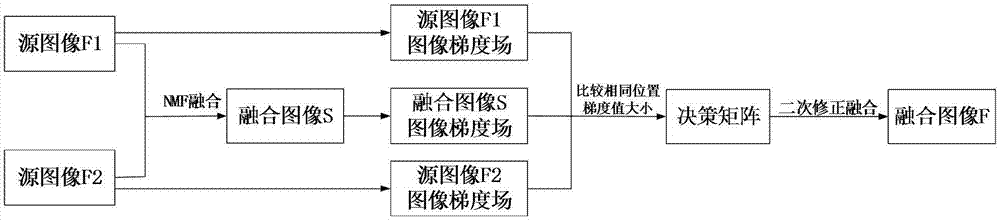
利用nmf融合方法得到一幅临时融合图像s后,对源图像f1、f2以及临时融合图像s进行相对梯度场求解,得到图像相对梯度场图;再比较三个图像梯度场相同位置处的梯度值大小,得到决策矩阵图;根据决策矩阵图,如果源图像f1或f2的梯度值大于临时融合图像s相同位置处的梯度值,则选择f1或f2对应位置的图像像素取代融合图像s处对应位置的图像像素,即为二次修正融合,得到最终的融合图像f。
进一步,所述基于非负矩阵分解及视觉感知的多聚焦图像融合方法,具体包括:
对待融合的源图像f1、f2进行非负矩阵融合,生成临时融合图像s;
构建待融合的多聚焦图像f1和f2的观测矩阵v;
用非负矩阵分解算法对观测矩阵v进行分解,得到基矩阵w;
将基矩阵w转换成大小为的矩阵,该矩阵对应的图像即为临时融合图像s;
对源图像f1、f2以及临时融合图像s进行多方向梯度场求解,得到图像梯度场图;
比较三个图像梯度场相同位置处的梯度值大小,得到决策矩阵图;
根据决策矩阵图,如果源图像f1或f2的梯度值大于临时融合图像s相同位置处的梯度值,则选择f1或f2对应位置的图像像素取代融合图像s处对应位置的图像像素,即为二次修正融合,得到最终的融合图像f。
进一步,多方向梯度值新方法,按以下公式进行;
其中,h(x,y)表示绝对梯度,表示相对梯度,f(x,y)为图像亮度值。
本发明的另一目的在于提供一种基于非负矩阵分解及视觉感知的多聚焦图像融合控制系统。
本发明的另一目的在于提供一种实现所述基于非负矩阵分解及视觉感知的多聚焦图像融合方法的计算机程序。
本发明的另一目的在于提供一种搭载有所述计算机程序的计算机。
本发明的另一目的在于提供一种计算机可读存储介质,包括指令,当其在计算机上运行时,使得计算机执行所述的方法。
本发明的优点及积极效果为:
本发明提出一种新的多聚焦图像融合方法,克服拍摄装置的单一聚焦性不足,针对不同目标分别进行聚焦得到多个图像,并在此基础上通过图像融合技术得到一个目标都聚焦清晰的融合图像。本发明通过结合非负矩阵分解和视觉感知理论将多幅同一场景下聚焦目标各不相同的图像融合成一幅新的所有目标都清晰的图像。
现有技术在单纯的基于非负矩阵分解的图像融合方法中,经过算法迭代后,得到唯一的特征基,由此该特征基包含了参与融合的多幅图像的完整特征,将特征基还原到源图像的像素级上,就得到了比源图像效果都要好的融合图像。这种方法虽然得到了较好效果的融合图像,但对于多聚焦图像而已,融合方法的基础中没有针对清晰度特征进行融合,因而虽然有一定的总体清晰度效果,但在细节上却并不十分理想。因此本发明在此基础上,专门针对清晰度特征,在视觉感知理论的基础上采用相对梯度方法即为二次修正融合,进一步提取出聚焦清晰区域进行融合,得到融合效果更好的图像。
首先,由于本发明在单次nmf融合的基础上采用了二次修正融合,因此融合效果肯定优于单次nmf融合的效果。其次,本发明在二次修正融合时,判断聚焦清晰区域采用了基于视觉感知理论的相对梯度,显然更有利于找出聚焦清晰的细节区域,使最终的融合效果更好。
实验结果图如下所示:图中a为右聚焦图像,b为左聚焦图像,c为基于小波方法的融合结果,d为基于nmf方法的融合结果,e为基于curvlet方法的融合结果,f为本发明的融合结果。从图中可以看出本发明方面取得了最好的融合结果。
附图说明
图1是本发明实施例提供的基于非负矩阵分解及视觉感知的多聚焦图像融合方法流程图。
图2是本发明实施例提供的实验结果图。
图中:a、右聚焦图像;b、左聚焦图像;c、基于小波方法的融合结果;d、基于nmf方法的融合结果;e、基于curvlet方法的融合结果;f为本发明的融合结果。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
本发明实施例提供的首先利用nmf融合多幅多聚焦图像,得到一幅临时融合图像,在此基础上再即为二次修正融合。
根据所介绍的视觉感知特性可知,感知相同的绝对梯度,在整体亮度较大处,人眼的感知值较小。本发明基于此提出了相对梯度的概念,
按以下公式进行;
其中,h(x,y)表示绝对梯度,表示相对梯度,f(x,y)为图像亮度值。
在得到临时融合图像s后,对源图像f1、f2以及临时融合图像s进行相对梯度场求解,得到图像相对梯度场图。再比较三个图像梯度场相同位置处的梯度值大小,得到决策矩阵图。根据决策矩阵图,如果源图像f1或f2的梯度值大于临时融合图像s相同位置处的梯度值,则选择f1或f2对应位置的图像像素取代融合图像s处对应位置的图像像素,即为二次修正融合,得到最终的融合图像f。
具体步骤:如图1,
对待融合的源图像f1、f2进行非负矩阵融合,生成临时融合图像s;
构建待融合的多聚焦图像f1和f2的观测矩阵v;
用非负矩阵分解算法对观测矩阵v进行分解,得到基矩阵w;
将基矩阵w转换成大小为的矩阵,该矩阵对应的图像即为临时融合图像s;
对源图像f1、f2以及临时融合图像s进行多方向梯度场求解,得到图像梯度场图;
比较三个图像梯度场相同位置处的梯度值大小,得到决策矩阵图;
根据决策矩阵图,如果源图像f1或f2的梯度值大于临时融合图像s相同位置处的梯度值,则选择f1或f2对应位置的图像像素取代融合图像s处对应位置的图像像素,即为二次修正融合,得到最终的融合图像f。
本发明提出了二次修正融合的概念,利用nmf融合方法快速得到一幅融合效果较好的临时融合图像,然后在视觉感知理论的基础上,利用多方向梯度值新方法将源图像中聚焦清晰的细节再次融合入临时融合图像,进一步提升融合质量。
本发明在二次修改融合时,在视觉感知理论的基础上提出了相对梯度的概念,更符合人类视觉特点,能更好的选择出图像中聚焦清晰的区域。
图2是本发明实施例提供的实验结果图。
图中:a、右聚焦图像;b、左聚焦图像;c、基于小波方法的融合结果;d、基于nmf方法的融合结果;e、基于curvlet方法的融合结果;f为本发明的融合结果。
在上述实施例中,可以全部或部分地通过软件、硬件、固件或者其任意组合来实现。当使用全部或部分地以计算机程序产品的形式实现,所述计算机程序产品包括一个或多个计算机指令。在计算机上加载或执行所述计算机程序指令时,全部或部分地产生按照本发明实施例所述的流程或功能。所述计算机可以是通用计算机、专用计算机、计算机网络、或者其他可编程装置。所述计算机指令可以存储在计算机可读存储介质中,或者从一个计算机可读存储介质向另一个计算机可读存储介质传输,例如,所述计算机指令可以从一个网站站点、计算机、服务器或数据中心通过有线(例如同轴电缆、光纤、数字用户线(dsl)或无线(例如红外、无线、微波等)方式向另一个网站站点、计算机、服务器或数据中心进行传输)。所述计算机可读取存储介质可以是计算机能够存取的任何可用介质或者是包含一个或多个可用介质集成的服务器、数据中心等数据存储设备。所述可用介质可以是磁性介质,(例如,软盘、硬盘、磁带)、光介质(例如,dvd)、或者半导体介质(例如固态硬盘solidstatedisk(ssd))等。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!