基于FPGA的可重构线性方程组求解加速器的制作方法
本发明属于数据处理技术领域,涉及线性方程组求解技术。
背景技术
线性方程组求解属于矩阵计算的一部分,是科学和工程计算的核心。求解线性方程组是一类计算密集型任务,广泛的存在于数据挖掘、信号处理和数值逼近等领域。
大规模线性方程组的求解一般有两类,系数矩阵是稀疏矩阵和系数矩阵是稠密矩阵两类。在求解稀疏线性方程组时,由于存在大量元素,采用迭代法求解将会节约很多计算资源,通过多次迭代,解向量最终逼近精确解。在求解稠密线性方程组时,一般采用lu分解的方法,获得线性方程组的精确解。由于两种算法的差异,大规模线性方程组的求解往往通过高性能服务器上的通用处理器实现软件求解。
fpga具有大量的计算部件,可以将大规模重复计算并行流水处理,实现算法的并行化,对于加速大规模线性方程组的求解是很好的选择。结合fpga可重构技术,针对不同的算法做出设计,可以实现求解方式的通用性。
技术实现要素:
为了解决上述问题,实现求解方式的通用性,本发明基于可重构技术,提出一种基于fpga的针对稀疏和稠密矩阵线性方程组的通用求解加速器,发明提出了针对两种不同类型线性方程组的重构方法,具体由以下技术方案实现。
基于fpga的可重构线性方程组求解加速器,包括:
数据分配模块,用于将内部存储器中的数据分配给计算阵列模块,根据输入系数矩阵的规模和类型,在主控制模块的控制下调整数据分配的方式;
主程序控制模块,用于控制数据分配模块、重构控制模块和计算阵列模块的运行以及各模块之间的通信;
重构控制模块,用于根据系数矩阵的规模和类型重新设置计算方式;
内部存储器模块,用于存储系数矩阵和向量数据;
计算阵列模块,用于计算线性方程组的解。
所述基于fpga的可重构线性方程组求解加速器的进一步设计在于,所述数据分配模块控制各个时刻内部存储器模块中的数据到计算阵列模块的缓存的数据通路,操作内部存储模块中的数据交换,对每个分配的列数据加上头标记,使数据分配到匹配的计算阵列模块的计算单元缓存中。
所述基于fpga的可重构线性方程组求解加速器的进一步设计在于,数据分配模块处理的系数矩阵类型分为稀疏系数矩阵和稠密系数矩阵。
所述基于fpga的可重构线性方程组求解加速器的进一步设计在于,主程序模块分别与数据分配模块、重构控制模块以及计算阵列模块双向通信连接,实现了对数据分配模块、重构控制模块和计算阵列模块运行以及各模块之间通信的控制,形成线性方程组求解加速器的最上层控制器。
所述基于fpga的可重构线性方程组求解加速器的进一步设计在于,重构控制模块根据系数矩阵的类型,对于矩阵的类型为稀疏系数矩阵,重新设置计算阵列模块的运行模式为迭代法;对于矩阵的类型为稠密系数矩阵,重新设置计算阵列模块的运行模式为直接法。
所述基于fpga的可重构线性方程组求解加速器的进一步设计在于,迭代法采用jacobi迭代法思想,处理系数矩阵为大型稀疏矩阵的线性方程组求解,获得所需精确度的近似解;直接法采用列选主元lu分解思想,处理系数矩阵为稠密矩阵的线性方程组求解,获得精确解。
所述基于fpga的可重构线性方程组求解加速器的进一步设计在于,内部存储模块根据系数矩阵的规模配置不同深度的ram,用于存储系数矩阵的每一列、行的数据,通过数据总线,与计算阵列模块中的缓存进行通信,完成数据的读取和写入。
所述基于fpga的可重构线性方程组求解加速器的进一步设计在于,计算阵列模块包括:
预处理单元,用于完成计算前的预处理和特定数据的分配工作;
12*12计算单元阵列,用于完成并行化大规模数据计算,执行直接法的lu分解过程和迭代法的迭代计算过程;
回代单元,用于lu分解完成后,计算线性方程组解的回代过程;
迭代判断单元,用于计算单次迭代完成后的向量x,根据精确度判断迭代是否结束。
所述基于fpga的可重构线性方程组求解加速器的进一步设计在于,在直接法计算模式下,预处理单元完成列选主元,将得到的主元所在行信息与数据分配模块通信,依次计算
所述基于fpga的可重构线性方程组求解加速器的进一步设计在于,每个计算单元阵列包括头标签匹配单元和乘加计算单元。
本发明的优点
本发明的线性方程组求解加速器,根据要求解方程的类型采用合适高效的求解方法。线性方程组求解加速器既可以完成lu分解的线性方程组求解,也可以完成jacobi迭代法的线性方程组求解。在对运算资源和运算精度不同需求的场景下可采用不同的运算模式,相比于现有的线性方程组求解加速器,本求解加速器具有更好的通用性。
本发明针对分析了两种算法的过程,提取了相似的运算过程,采用并行流水化的方法,加速了运算的过程,相比于通用处理器的软件求解方法有效的提高了运算效率。
本发明的重构控制模块,可以同时调整数据的存储和传输方式,针对大规模系数矩阵线性方程组有很好的加速效果。
附图说明
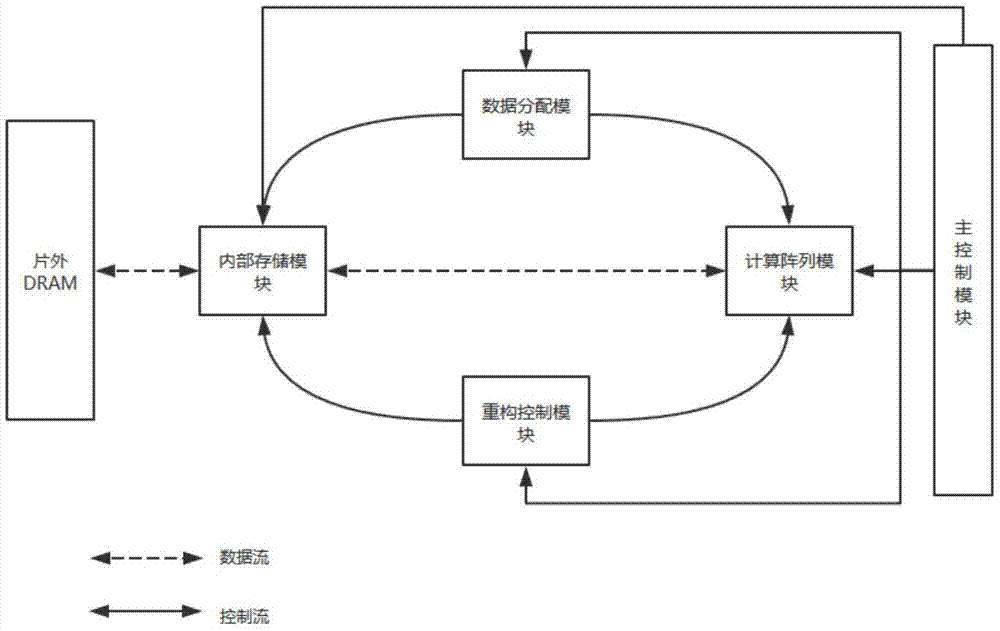
图1是线性方程组求解加速器的总体架构图。
图2是计算阵列模块结构图。
图3是计算单元结构图。
具体实施方式
下面结合附图对本发明方案进行详细说明。
如图1所示,本发明基于可重构的思想的线性方程组求解加速器。该线性方程组求解加速器由主控制模块、内部存储模块、重构控制模块、数据分配模块和计算阵列模块组成。其中:
主控制模块,作为系统的最上层控制模块,控制了求解加速器的整个运行过程。在求解加速器的运行起始,主控制模块获得片外dram存储的系数矩阵的参数(系数矩阵的规模和类型),根据获得参数与重构控制模块通信,完成本次求解的初始工作。主控制模块还会与数据分配模块、内部存储模块和计算阵列模块通信,依此完成数据的分配工作、数据的交换与预处理工作和数据的计算工作。
内部存储模块,存储计算所需要的数据和计算以后的结果。内部存储模块受重构控制模块的控制,在重构过程中完成对存储器的重构,适应系数矩阵的规模和类型。同时,数据分配模块也会与内部存储模块通信,完成其中部分数据的交换和添加头标签等数据处理工作。内部存储器分为12组,每组都通过数据总线与12个计算单元相连。
重构控制模块,在求解加速器的起始阶段,重构控制模块会根据主控制器提供的系数矩阵的规模和类型完成重构工作。重构内部存储模块,根据系数矩阵规模,调整内部存储的深度和大小;根据系数矩阵类型,调整存储方式为按行存储或按列存储。重构计算阵列模块,根据系数类型或指定的计算需求,调整计算阵列模块的运行方式,分别为直接法和迭代法。在直接法的运行方式下,调整计算阵列模块中的预处理单元为列选方式,开启回代单元;在迭代法的运行方式下,调整计算阵列模块中的预处理单元为分发模式,开启迭代判断单元。
数据分配模块,完成数据的分配,主要是对数据添加头标签,使数据送达对应头标签的计算单元中;与计算阵列模块中的预处理单元通信,得到列选主元的参数,控制内部存储模块交换主元列数据。
如图2所示,计算阵列模块由预处理单元、12*12计算单元阵列、回代单元和迭代判断单元组成。其中预处理单元由多输入比较器、缓存器和除法器构成。数据存入缓存器中,多输入比较器完成列选主元的工作,除法器完成列选主元后的求值
预处理单元有两种模式,模式选择受重构控制模块的控制,直接法为列选模式,完成列选主元、
下面以200*200的稠密系数矩阵线性方程组为例,说明线性方程组求解加速器的工作原理。初始阶段,主控制器获得矩阵的规模和类型后,与重构控制器通信,设置内部存储模块的存储方式。对于稠密系数矩阵,系数矩阵按列存储,内部存储器的每一组完整的存储一整列数据,即第一列存储在第一组,第二列存储在第二组,依次存储,在第十三列数据重新开始循环,存储在第一组中。重构控制模块还会设置计算阵列模块,调整预处理单元为列选模式,调整每个计算单元的头标签,开启回代单元关闭迭代判断单元。完成重构工作后,片外dram通过数据总线将数据传至内部存储模块。完成存储之后,数据分配模块会在每列数据之前添加头标签,每列数据的头标签即为该列所处的列序数(向量x特殊标记)。主控制器模块控制第一列数据进入计算阵列模块的预处理单元中,完成列选主元后计算
本发明基于可重构的思想设计的线性方程组求解加速器,根据要求解方程的类型采用合适高效的求解方法。线性方程组求解加速器既可以完成lu分解的线性方程组求解,也可以完成jacobi迭代法的线性方程组求解。在对运算资源和运算精度不太通需求的场景下可采用不同的运算模式,相比于现有的线性方程组求解加速器,本求解加速器具有更好的通用性。发明针对分析了两种算法的过程,提取了相似的运算过程,采用并行流水化的方法,加速了运算的过程,有效的提高了运算效率。求解加速器的重构控制模块,可以同时调整数据的存储和传输方式,针对大规模系数矩阵有很好的加速效果。
以上对本发明提供的一种可重构线性方程组求解加速器进行了详细介绍,以便于理解本发明和其核心思想。对于本领域的一般技术人员,在具体实施时,可根据本发明的核心思想进行多种修改和演绎。综上所述,本说明书不应视为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!