一种基于深度玻尔兹曼机的图像识别方法及系统与流程
本发明涉及模式识别和机器学习领域,具体涉及一种基于深度玻尔兹曼机的图像识别方法及系统。
背景技术
机器学习是研究如何使计算机模拟人类学习行为的一门学科。机器学习基于学习策略可分为机械学习、类比学习、演绎学习、基于解释的学习、归纳学习、基于神经网络的学习等。本文研究的重点在人工神经网络(ann),简称为神经网络。神经网络是一种并行分布式信息处理的网络结构,具有很强的非线性映射能力和较高的容错能力等特点。ann可追溯至1943年神经心理学家mcculloch和数学家pitts从数理逻辑的角度提出的神经元模型(m-p模型),ann自此开始发展。目前,常见的ann模型种类很多,我们可以依据ann的结构分为三种基本的网络模型:单层前馈网络、多层前馈网络、递归网络。多层前馈网络可以有一层或多层隐藏层。深度学习模型由于能够从输入样本直接逼近复杂的非线性映射,而被广泛用于许多领域,常用模型有卷积神经网络(cnn)和堆叠的自动编码器模型(sae)以及深度置信网(dbn)深度波尔兹曼机(dbm)等。卷积神经网络是专门为处理二维数据的,被认为是第一个采用多层次网络结构的深度学习方法,近年来在图像识别领域取得了巨大的成功。由于采用局部连接和权值共享,保持网络深层结构的同时又大大减少了网络参数,使模型具有良好的泛化能力又较容易训练。
在经典的模式识别中,一般是事先提取特征。提取诸多特征后,要对这些特征进行相关性分析,找到最能代表字符的特征,去掉对分类无关和自相关的特征。然而,这些特征的提取太过依赖人的经验和主观意识,提取到的特征的不同对分类性能影响很大,甚至提取的特征的顺序也会影响最后的分类性能。同时,图像预处理的好坏也会影响到提取的特征。而深度学习算法需要对图像进行复杂的预处理操作,可以方便地把图像作为输入,通过大量的数据来学习特征的,避免了显示的特征提取,比以往的人工选取特征更可靠。
技术实现要素:
为了更好的解决图像的识别问题,本发明提出一种基于深度玻尔兹曼机的图像识别方法及系统,避免了显式的提取特征,直接将数字化的图像像素作为输入,训练得到深度的玻尔兹曼机模型,选取神经网络最后一层的输出最为识别结果,有效的实现了图像的识别和重构过程。
本发明是通过以下方案实现的:
本发明涉及一种基于深度学习的图像识别方法,通过构建带标签的训练集作为样本集对卷积神经网络进行训练,并将训练好的卷积神经网络处理待识别的图片,最后根据神经网络的输出向量判断识别结果。
本发明具体步骤如下:
步骤1:简单的预处理训练集并将像素点作为输入:首先将图像数据集进行分batch,每一个小的batch包括100个样本,这样原来的图像数据集就分成了600个batch,然后把灰度图像归一化、并重新调节大小为28*28;
步骤2:构造深度学习模型:该网络包括:输入层、2个隐藏层和一个输出层,其中:输入层的数据是预处理完的手写数字像素点,是28*28像素点构成的矩阵,为方便处理,我们将28*28的矩阵转化为1维的向量,最后一层的输出为预测输出;
步骤3:训练深度神经网络,首先初始化网络的权值,进行预训练过程,在预训练中,我们引入了weightuncertainty方法来缓解rbm模型中的过拟合问题,然后使用半受限的玻尔兹曼机(srbm)作为第一个特征提取器,第二个特征提取器为常规的rbm,然后,逐层完成网络的预训练过程。最后,结合bp反向传播算法调整权重和偏置,具体过程如下:
步骤3.1:对网络初始化:对权值和偏置进行随机初始化;
步骤3.2:将60000个训练样本和标签集导入初始化好的网络进行预训练,首先引入weightuncertainty方法训练srbm,得到wsrbm模型,然后使用weightuncertainty方法来训练rbm,得到wrbm模型,接下来,将整个网络作为一个dbm模型再次进行预训练,其中仍然采用weightuncertainty方法,我们得到了weightuncertaintysemi-restricteddeepboltzmannmachine(wsdbm)模型。其中训练样本包括10个数字类别:数字0-9;
步骤3.3:将实际输出与标签进行对比,得到误差,将wsdbm作为神经网络,利用weightuncertaintybp算法进行微调,得到训练好的神经网络模型。
步骤4:手写数字的识别,在系统手写板中完成数字的书写后,转化为灰度图,进行归一化处理后,然后将其输入到训练好的卷积神经网络中,最终得到识别结果。
通过以上内容可知,本申请提供的是一种基于深度玻尔兹曼机的图像识别方法及系统,首先制作根据实际需要制作训练集和标签,然后设计网络的层数等参数,之后进行预训练,然后利用weightuncertaintybp算法完成对网络权重和偏置的调整,最后输入手写数字图像,预处理后输入神经网络,完成对数字图像的识别。本申请通过神经网络识别手写数字图像,避免了显示的特征提取,直接将图片作为网络的输入,识别准确率很高;且网络一经训练即可反复使用,处理效率高;训练时间短。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
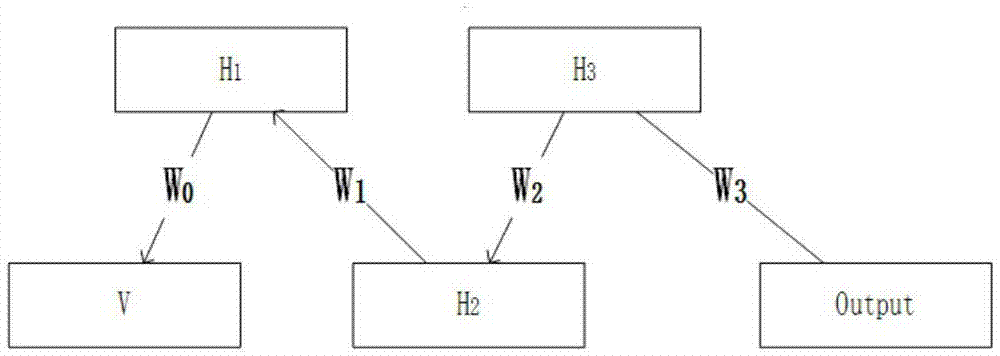
图1为本申请所使用的wsdbm模型的训练示意图。
图2为本申请所使用的深度神经网络结构示意图。
图3为本申请所使用的系统的信号传递流程示意图。
具体实施方式
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有付出创造性劳动前提下所获得的所有其它实施例,都属于本申请保护的范围。
实施例1
本实施例包括以下步骤:
步骤1:图片预处理:
步骤1.1:将手写数字图像转化为灰度图像;
步骤1.2:把步骤1.2所得到的图像归一化为28*28大小,把像素点转化为一维的向量,并保存在训练集中,然后根据训练集制作相应的标签集,10*1的矩阵代表一个数字的标签。
步骤2:构建wsdbm深度模型:
本实施例中采用的wsdbm模型是一个多层的神经网络,由输入层、中间层和输出层等多层组成,每层由多个节点单元组成。构造如图1所示的多层神经网络,包括输入层,两个隐藏层和一个输出层,每一层由于都是一种概率图模型,因此,基于能量函数,每一层单元的激活函数都是sigmoid函数的形式;
步骤3:训练卷积神经网络:
步骤3.1:用不同的小随机数(0-1之间)对可训练参数初始化,对偏置初始化为0;
步骤3.2:对网络进行预训练网络模型的激活概率公式可以表示如下:
其中,h表示隐藏层单元,v表示可见层单元,w表示权值矩阵,b表示偏置,第一个srbm的训练公式如下:
其中l表示可见层单元之间的权值矩阵。
然后引入weightuncertainty算法,这样,导数的计算改为如下形式:
根据上述公式,完成wsdbm的预训练过程。然后将整个wsdbm作为一个玻尔兹曼机再进行训练,得到神经网络模型。
步骤3.3:计算残差,结合反向传播bp算法更新可调整参数和偏置,完成对wsdbm的整个训练过程。
步骤4:手写数字识别:
步骤4.1:在系统的手写板中写完数字保存之后,进行灰度化,归一化预处理;
步骤4.2:得到预处理之后的图片,输入到已经训练好的wsdbm网络中,等待输出,取输出向量最大值得行号为识别结果,即完成对手写数字的识别。
- 还没有人留言评论。精彩留言会获得点赞!