一种基于NetSim-TL的多源迁移学习标签流行性预测模型的构建方法与流程
本发明涉及数据挖掘、图结构分析技术,特别是涉及一种基于netsim-tl的多源迁移学习标签流行性预测模型的构建方法。
背景技术:
随着互联网技术的快速发展,越来越多的人喜欢花费时间在网络上发布和搜索自己想要的信息,积累了大量的知识问答数据。由于人工智能技术的快速发展,人们对已有的问答数据进行分析,建模以及预测,使得其能够更好的服务于用户。问答社区中的标签数据越来越受到人们的关注,例如研究标签推荐,基于标签的答案推荐,问题推荐等。我们主要研究在问答社区中新提出的标签在未来的流行性趋势预测问题。基于大规模数据的标签流行性趋势预测能够有较好的预测结果,但是在一些冷门问答社区或者是新出现的问答社区,由于具有标记的数据很难获得或者数据量比较少,无法准确的构建较好的预测或者分类模型,于是我们采用迁移学习的方法,即利用相似的较大的问答社区里的数据,来对目标领域的任务进行预测或者分类。
迁移学习依据领域和任务是否相同,大致分为四类:(1)基于实例的迁移学习;(2)基于特征的迁移学习;(3)基于参数的迁移学习;(4)基于相关性的迁移学习。目前迁移学习已经在很多领域得到应用,并取得较好的结果,例如软件缺陷预测,人类活动行为的分类和识别,图片分类,文本语义分类等等。在单源领域迁移的问题上,已提出很多方法,例如tradaboost、trbagg、a-svm等单源迁移学习方法。在多源数据迁移方面已经有很多工作,大部分工作基于数据特征分布之间差异,即用最大均方差异(maximummeandiscrepancy,mmd)作为源社区与目标社区之间的相似性,或者在此基础上,增加一些参数项,调整训练模型的损失函数,达到优化的目的。还有的则是对样本实例进行加权的方法,通过对源领域的数据样本进行数据筛选加权,多次迭代得出最后的权重,例如yao等人通过改进戴文源等提出的tradaboost的方法,将其应用到多源领域,提出了mstradaboost多源迁移模型框架。
已有的多源迁移学习模型,在衡量领域相似差异方面主要还是基于特征分布上的差异,这些方法在已有的任务或者应用上已经能够得到较好的应用,但是在网络分类或者涉及到网络特征的多源迁移任务模型中,则不能达到很好的迁移效果。
技术实现要素:
为了更好的衡量涉及网络结构的领域之间的差异性,改善多源迁移学习在涉及网络结构方面的任务上的效果,本发明提出一种基于netsim-tl的多源迁移学习标签流行性预测模型的构建方法,使用图核表征方法计算两两网络结构之间的相似性大小,作为目标领域与源领域之间的距离,并将此作为多源迁移学习模型中多个基学习器的权重,对基学习器的预测结果进行加权投票,得出最后的预测结果。本方法提高了多源迁移学习问答社区标签流行性预测的效果。
本发明解决其技术问题所采用的技术方案如下:
一种基于网络结构相似的多源迁移学习模型的构建方法,包括如下步骤:
步骤1:计算网络的结构相似性,给定n个源领域和目标领域数据集的网络集合
步骤2:构建单源迁移学习的基学习器,分别使用源领域
步骤3:构建多源迁移学习模型框架。根据步骤1,2得到的源领域社区网络和目标领域社区网络的结构相似性w1×n和分类器f={f1,f2,…,fn}。将ki作为源社区
进一步,所述步骤1中,计算网络的结构相似性的过程为:给定源领域和目标领域的网络集合
作为网络
再进一步,所述步骤2中,单源迁移学习模型的构建过程为:设定n个源领域标记数据集为
更近一步,所述步骤3中,构建多源迁移学习模型框架的过程为:对步骤1,2中得到的结构相似性w1×n和n个基分类器f={f1,f2,…,fn},选择ki作为源社区
本发明的有益效果表现在:提出了利用社区网络结构之间的相似性来作为不同领域社区之间迁移学习模型的权重,进行多源迁移学习模型的构建,在跨社区的标签流行性发展趋势预测上具有较好的效果。
附图说明
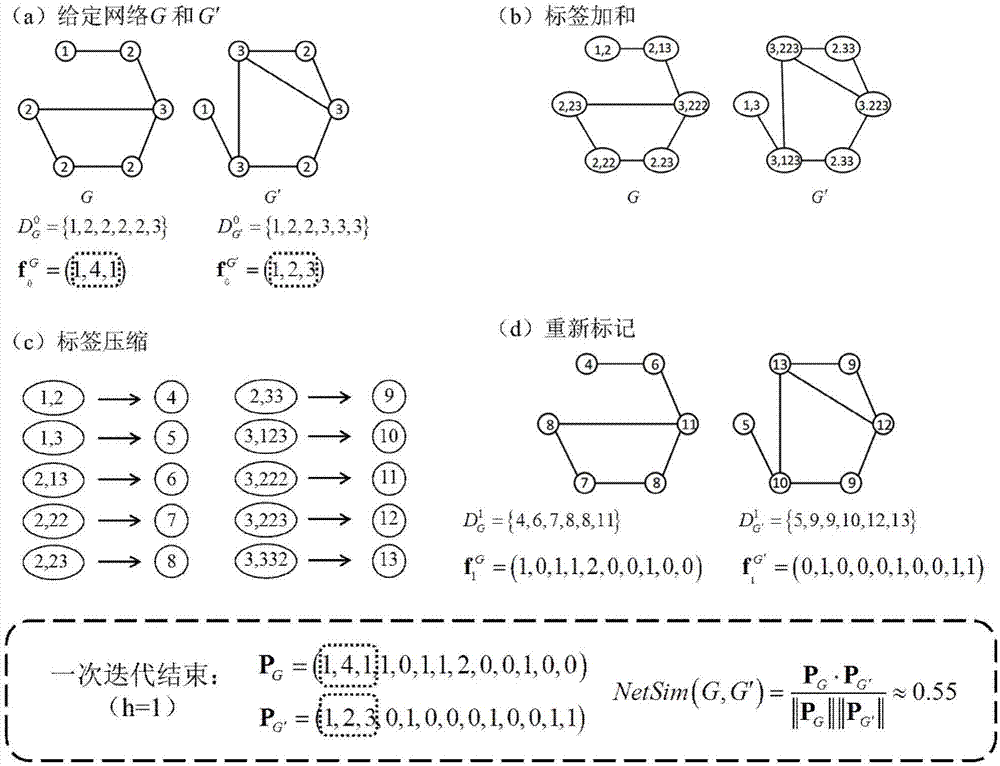
图1为wl核方法计算网络结构相似性大小的图例说明;
图2为本发明中基于网络结构相似加权的多源迁移模型框架。
具体实施方式
下面结合说明书附图对本发明的具体实施方式作进一步详细的描述。
参照图1和图2,一种基于netsim-tl的多源迁移学习标签流行性预测模型的构建方法,本发明使用了stackexchange问答网站中进行实例分析,数据采用了部分问答社区的网络结构数据,流行标签和非流行标签的标记数据及网络结构特征和非结构特征数据等。
本发明具体分为以下三个步骤:
步骤1:计算网络的结构相似性;
步骤2:构建单源迁移学习的基学习器;
步骤3:构建多源迁移学习模型框架。
所述步骤1中,计算网络的结构相似性,即计算目标领域与源领域网络结构之间的相似性程度,给定n个源领域和目标领域数据集的网络集合
所述步骤1中,计算网络结构相似性的图核方法的过程如下:依次选取集合ω中每一个源领域网络
作为网络gsi和gt之间的结构相似性,最后得出n个源领域社区网络和目标领域社区网络之间的相似性向量,即w1×n={k1,k2,…,kn}。
所述步骤2中,构建单源迁移学习的基学习器的过程为:设定n个源领域标记数据集为
所述步骤3中,构建多源迁移学习模型框架的过程为:如图2所示,对步骤2中得到n个基分类器f={f1,f2,…,fn},将其分别在测试集dtest上进行预测,得出预测结果,最后不同源领域与目标领域之间网络结构的相似性ki进行加权,得出最终的模型预测结果:
如上所述为本发明在问答网站stackexchange中进行了多源迁移学习标签流行性模型的构建,本发明选择多个较大社区里的标记数据作为源领域数据,对目标领域社区中进行多源迁移模型的构建,根据不同社区之间的网络结构相似性,对不同的单源迁移标签流行性预测模型进行加权,得出最后的多源迁移学习标签流行性预测模型,能够得出较好的预测精度。本专业技术人员理解,在发明权利要求所限定的精神和范围内可对其进行许多改变,修改,甚至等效,但都将落入本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!