一种面向用户角色的通用舆论信息情感识别方法与流程
本发明涉及一种面向用户角色的通用舆论信息情感识别方法。
背景技术
目前随着中国互联网的快速发展,网络媒体被公认为继报纸、电视之后反映社会舆情的主要载体,社会民众能够通过网络媒体(论坛、博客、微博)发表自己关心或利益相关的公共事件所持有的情绪、意见、态度等言论。通过对丰富情感的网络舆论信息分析,政府用户可以了解社会各个阶层民众的情绪、态度、看法以及意见和行为倾向,获取社情民意以引导社会健康发展;企业用户能够第一时间快速预警负面舆情,及时发现和处理企业的负面信息,保持企业的健康良好形象,因此舆论信息情感倾向识别分析已经成为政府、企业舆情监测工作内容的一部分。
目前舆论情感倾向识别方法主要有三种,基于情感词标注的方法、基于语义模式分析方法及基于机器学习的倾向性分析方法。基于情感词标注的方法通过分析带有语气词的特征来判断倾向性,方法简单易用,但严重依赖于标注专家且不利用训练样本;基于语义模式分析方法利用自然语言处理技术,通过识别特定主题词与语气表达式之间的关系进行倾向性分析,但受限自然语言处理技术,实用性不足;而基于机器学习的倾向性分析方法又取决于训练集的大小与质量,同时具有很强的领域或主题依赖性,因而这类有监督的情感分析方法的效果仍然难以保证。特别是情感分析不仅仅是语气倾向性,还同用户角色及语义内容密切相关,如网络舆情内容中出现暴雪天气,对于当地交通部门来说,是负面倾向,因为暴雪会影响交通出行;对于当地气象部门来说,则是中性情感,发布极端天气预警是正常工作内容。在语义内容上,如表扬气象局发布暴雪天气信息准确,这是正面信息,若责怪、调侃气象局发布信息不准,则是负面信息。
现有舆论情感倾向识别方法均是局限在某个特定领域或者关联于某个话题下进行倾向性的分析,不能很好地解决多用户复杂语义的情感分析,还缺乏一般性的通用技术。
技术实现要素:
针对现有技术的不足,本发明提供了一种面向用户角色的通用舆论信息情感识别方法,包括如下步骤:
步骤1,采集舆论信息数据训练集,对数据集中的舆论信息内容进行分词;
步骤2,对数据集中的舆论信息内容进行情感倾向初始标注,得到情感倾向初始标注数据集;
步骤3,提取语义特征,形成语义特征数据集;
步骤4,构建cnn(convolutionalneuralnetwork,卷积神经网络)分类模型,基于语义特征数据集及情感倾向初始标注数据集构建cnn分类模型,实现舆论信息情感倾向分类识别;
步骤5,情感倾向标注修正,利用基于在线情感标注的反馈手段,实现专有特定用户的情感倾向标注修正;
步骤6,定期或按需重新训练cnn分类模型,形成面向用户的专有情感识别分类器。
步骤1包括:利用开源工具ansj或hanlp工具包,基于用户行业或领域自定义词典对数据集中的舆论信息内容进行分词,可在https://github.com/nlpchina/ansj_seg等网站下载。
步骤2包括:将情感倾向分为正面、负面及中性三种类别,利用传统方法中基于通用语气倾向性词典,对数据集中的舆论信息内容进行语气极性判别和情感倾向初始标注,即对待标注舆论分别进行词典比对,计算三种极性词语总数,如果正面词多,则初始标注为正面;如负面词多,则初始标注为负面;若相等,则标注为中性。
步骤3包括:基于步骤1的分词结果,利用doc2vec(文档转向量)原理(https://arxiv.org/pdf/1405.4053.pdf),基于大数据平台并行计算引擎spark,进行词向量化转换,提取舆论信息语义表征,形成语义特征数据集。
步骤4包括:cnn分类模型的输入即为语义特征数据集及情感倾向初始标注数据集,输出为情感倾向识别类型,基于cnn分类模型方法(convolutionalneuralnetworksforsentenceclassification,https://arxiv.org/abs/1408.5882),实现初始的敏感舆论信息内容情感倾向的分类识别。
步骤5包括:利用用户在线浏览敏感舆情信息时(用户关注的关键词即为敏感词,敏感信息即用户行业领域关注的信息),提供人机交互的在线情感标注的反馈手段,即通过页面点击修正情感倾向,使得用户能够通过人机交互方式完成情感倾向标注修改,实现结合用户角色的情感倾向标注修正。
步骤6包括:利用用户日常工作时修正过的情感倾向标注数据,定期或按需重新训练cnn分类模型,不断提高情感倾向识别正确率,最终形成面向用户的专有情感识别分类器,
本发明利用通用语气倾向性词典构建初始情感倾向标注集,并训练cnn(卷积神经网络)模型实现舆论内容情感倾向分类预测,基于在线情感标注的反馈手段,完成面向用户的情感倾向修正,利用修正后的情感倾向标注集重新训练模型,提高情感倾向识别率,最终面向用户的舆论信息情感倾向精准识别。
本发明与现有技术相比,具有如下显著优点:
1、本发明是一种通用的舆论信息情感倾向识别方法,结合用户角色信息,实现舆论信息情感倾向精准识别,为后续舆论引导及事件处置提供支撑;
2、基于在线情感标注的反馈手段,在用户日常舆情监测工作时,可以基于人机交互的方式,方便地按需完成情感标注修正,为后续舆论信息情感倾向提供面向用户角色的正确标注;
3、由于舆情的不确定性和多样性,在传统情感识别过程中,容易发生“主题漂移”现象,在先验知识不多的情况下,情感识别效果一般。本发明能够在先验知识不多的情况下,先利用通用的情感词典完成倾向标注,生成初始模型,随着用户的在线情感标注反馈,面向用户角色信息的正确标注逐渐增多,识别效果会大大改善。
4、本发明在分词技术中采用了用户自定义词典,能够大大提高用户期望的分词效果,解决行业语义鸿沟,为后续面向用户角色的情感倾向识别提供相对准确的数据特征。
5、用户可以自定义情感倾向词典或规则,且用户之间相互独立,屏蔽了面向多用户不同情感倾向词典的复杂操作。
6、基于大数据平台计算引擎spark计算doc2vec方法中的文档向量,不仅提升海量数据下的计算速度,同时通过文档的向量表达方式,有效解决舆论信息结构复杂、无情感词出现但有明显情感倾向的分析问题。
7、使用本发明,不需要事先准备充足的情感词典定义,省去复杂的自然语言处理算法,在通用的情感倾向识别模型基础上,结合用户角色具备自修正能力,最终实现面向用户的情感倾向精准识别。
附图说明
下面结合附图和具体实施方式对本发明做更进一步的具体说明,本发明的上述或其他方面的优点将会变得更加清楚。
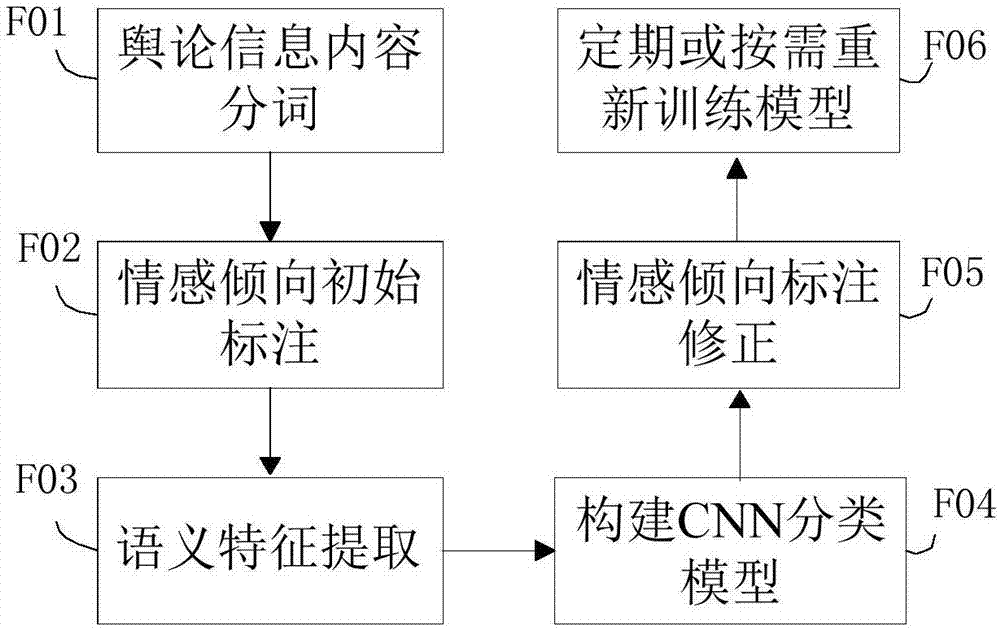
图1是本发明的方法步骤示意图。
图2是本发明的具体流程图。
具体实施方式
下面结合附图及实施例对本发明做进一步说明。
如图1所示,本发明提供方法步骤示意图,包括以下步骤:
步骤f01:舆论信息内容分词。根据用户行业或领域自定义词典对舆论信息内容分词,完成行业偏向性的分词采集。
所述行业偏向性的分词采集,利用现有开源工具ansj或hanlp等工具包,基于用户行业或领域自定义词典对已采集到的舆论信息内容进行分词,获得相对准确的领域分词数据,提升后续情感倾向识别准确率。
步骤f02:情感倾向初始标注。利用通用语气倾向性词典,实现语气极性判别和情感倾向初始标注。
所述语气极性判别和情感倾向初始标注,采用简单易用的基于情感词标注的方法,利用通用语气倾向性词典实现语气极性判别,本发明中情感倾向分为正面、负面及中性三种类别,情感判别后对该舆论内容完成初始情感倾向标注。
步骤f03:语义特征提取。根据分词结果,进行词向量化转换,实现语义特征提取;
所述语义特征提取,基于分词结果,利用doc2vec方法,基于大数据平台spark计算引擎,进行词向量化转换,提取舆论信息语义表征,形成语义特征数据集。
步骤f04:构建cnn分类模型。基于语义特征及情感倾向标注集构建cnn分类模型,实现舆论信息情感倾向分类识别。
所述基于语义特征及情感倾向标注集构建cnn分类模型,模型输入即为前述步骤中的语义特征及情感倾向标注数据,输出为情感倾向识别类型,基于cnn分类模型,实现最新舆论信息内容情感倾向的分类识别。其利用卷积神经网络自我学习能力,实现复杂语义多层特征描述,最终用于新采集的舆论信息情感倾向识别。
步骤f05:情感倾向标注修正。利用基于在线情感标注的反馈手段,实现专有特定用户的情感倾向标注修正。
所述在线情感标注的反馈,利用用户在线浏览敏感舆情信息时,提供人机交互的在线情感标注的反馈手段,使得用户能够通过页面点击等简单方式完成情感倾向标注修改,实现结合用户角色的情感倾向标注修正。
步骤f06:定期或按需重新训练模型。利用用户日常工作时修正过的情感倾向标注数据,定期或按需重新训练cnn分类模型,不断提高情感倾向识别正确率,最终形成面向用户的专有情感识别分类器,实现舆论信息情感倾向的精准识别。
本发明具体实施方式流程如图2所示:
训练s01:准备好舆论信息数据训练集01,实现舆论信息内容分词02,对分词结果进行情感倾向标注03及语义特征提取04,将完成情感倾向标注的特征集作为数据输入,完成cnn情感倾向识别模型训练05,训练结束后,保存训练模型06。
识别s02:舆论数据持续采集07,对新采集的舆论信息进行内容分词02,同时实现语义特征提取04,基于已训练的cnn情感倾向识别模型,进行舆论信息情感倾向识别08,提供基于人机交互的在线情感标注反馈手段09,并判断用户是否对识别结果进行修正10,若该条舆论信息情感倾向识别结果被修正,则返回训练s01中情感倾向标注03,并定期或按需重新训练cnn情感倾向识别模型,最终实现面向用户角色的舆情信息情感倾向精准识别。
实施例
本实施例以某领域用户日常重点关注舆论数据为例,数据集规模为4万条训练数据、2万条测试数据。具体步骤如下:
步骤f01:利用现有开源工具ansj或hanlp等工具包,基于用户行业或领域自定义词典对已采集到的舆论信息内容进行分词,可形成如“安全隐患”、“交通拥堵”等常用名词,而不会形成“安全”及“隐患”等一般分词结果。
步骤f02:利用通用语气倾向性词典,实现语气极性判别和情感倾向初始标注,最终形成2万个负面数据训练集、1万个中性数据训练集及1万个正面数据训练集。该数据集标注方式简单易用,但非常不准确,如“xx县全境普降大雪,路面出现不同程度结冰现象造成交通瘫痪,xx部门立即启动冰雪天气停运措施”,该条信息用户研判为正面倾向,然而初始标注中因为负面词“瘫痪”、“停运”比较多,因此被初始标注为负面。
步骤f03:利用doc2vec方法,基于大数据平台spark计算引擎,进行词向量化转换,提取舆论信息语义表征,形成语义特征数据集。本实施例中词向量特征数为300,最终每一条舆论信息转换为机器能够识别的分布式向量表示,如上一条“xx县全境普降大雪,路面出现不同程度结冰现象造成交通瘫痪,xx部门立即启动冰雪天气停运措施”信息即转换成[-0.0390230.1437050.070836…0.1568130.0520410.079818],维度为词向量特征数300,提供相对准确的语义层面支撑。
步骤f04:基于语义特征及情感倾向标注集构建cnn分类模型,实现舆论信息情感倾向分类识别,目前为止其分类结果还是基于初始标注数据,能够实现舆论信息情感倾向分类识别,满足用户的一般使用。
步骤f05:利用用户在线浏览敏感舆情信息时,提供人机交互的在线情感标注的反馈手段,使得用户能够通过页面点击等简单方式完成情感倾向标注修改,如上述“xx县全境普降大雪,路面出现不同程度结冰现象造成交通瘫痪,xx部门立即启动冰雪天气停运措施”用户通过页面点击等方式修改情感倾向标注,由负面转成正面。此项操作由于伴随用户日常研判时的数据操作,可以通过修正数统计展示等技术手段以游戏方式激励用户主动性,增加修正数量。值得注意的是,此处用户不是一直在修正标注,而是此前采用的是通用标注方法,没有针对用户领域造成的领域内情感倾向研判修正。此处情感倾向修正是面向领域、面向用户角色的不同而按需修正。即每一领域、每一用户均有自己的专属情感倾向标准。
步骤f06:利用用户日常工作时修正过的情感倾向标注数据,定期或按需重新训练cnn分类模型,不断提高情感倾向识别正确率,最终形成面向用户的专有情感识别分类器。由于用户修正的情况互不相同,修正数据集的规模也各不相同,因此采用定期或按需的方式将修正过的情感倾向标注数据与训练集重新训练,经过用户修正后,“xx县全境普降大雪,路面出现不同程度结冰现象造成交通瘫痪,xx部门立即启动冰雪天气停运措施”自动判断为正面。此处再次训练时,可适时将新增舆论数据与原训练集合并成新的训练集,增加数据集规模,进一步提高准确率。
本发明提供了一种面向用户角色的通用舆论信息情感识别方法,具体实现该技术方案的方法和途径很多,以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。本实施例中未明确的各组成部分均可用现有技术加以实现。
- 还没有人留言评论。精彩留言会获得点赞!