一种基于词网络和词向量的短文本主题模型生成方法与流程
本发明涉及文本主题模型构建领域,尤其是一种基于词网络和词向量的短文本主题模型生成方法。
背景技术:
随着互联网快速发展以及互联网中短文本内容的迅速增加,短文本数据的挖掘和分析越来越紧迫,面对这些短文本,如何从这些短文本背后准确地发掘主题是一项公认的具有挑战性也极有前景的任务。
由于短文本具有的稀疏性、实时性和不规则性等特点,直接在短文本上实施传统的主题模型算法例如:plsa、lda等,往往效果很差。随着短文本研究的进展,btm和wntm等针对短文本的主题模型陆续被提出,但它们都只考虑了语料库中词语的共现关系,尽管可以在一定程度上解决短文本的稀疏问题,因为不管是建立词对关系还是词网络,可以用来建模的共现关系都要比短文本中本身的词语要丰富得多,但是它们都忽略了词语间的语义关系,这就致使它们对于文本挖掘任务的性能面临着瓶颈。
技术实现要素:
发明目的:为解决常规的短文本主题模型只考虑了词语共现关系,但缺乏对语义信息的考虑,使得常见模型的主题发现、文本分类、文本聚类等任务的性能不高的技术问题,本发明提出一种基于词网络和词向量的短文本主题模型生成方法。
技术方案:本发明提出的技术方案为:
一种基于词网络和词向量的短文本主题模型生成方法,包括步骤:
(1)学习文本的语义信息,包括:对文档进行预处理,对预处理后文档语料进行词向量训练,得到每个词语的词向量;根据词向量计算词语间的相似度;
(2)为文档中的每个词语构建伪文档,包括对每一个词语i依次执行步骤(2-1)至(2-4):
(2-1)设置大小为w的滑动窗口,通过滑动窗口提取包括词语i在内的n个词语,构成词语i的词网络;
(2-2)构建词语列表lcooccur(i),将提取到的除词语i以外的词语以频率fri,j加入词语列表lcooccur(i);
(2-3)构建词语列表llatent(i);设置相似度阈值δ,对词网络中每个词语j,计算j与
(2-3)判断是否满足lcooccur(i)+llatent(i)<l,l表示设定的伪文档的最小长度;若满足,则选取词网络中与词语i相似度最高的m个词语加入词语列表lsimilar(i)中,m<l;
(2-4)合并词语列表lcooccur(i)、llatent(i)、lsimilar(i),得到词语i的伪文档;
(3)对每个伪文档进行lda主题建模,得到原始文档的主题、词语频率分布。
进一步的,所述对文档进行预处理包括对文档进行中文分词以及去除停止词处理。
进一步的,所述sim(i,j)的表达式为:
进一步的,所述词向量训练采用word2vec模型方法。
有益效果:与现有技术相比,本发明基于词网络,并通过训练词向量、计算词语相似度,为短文本数据中的词语构建伪文档,随后进行lda主题建模,既能克服短文本的稀疏性、不平衡性等难点,又通过引入语义信息提升了模型的性能。
附图说明
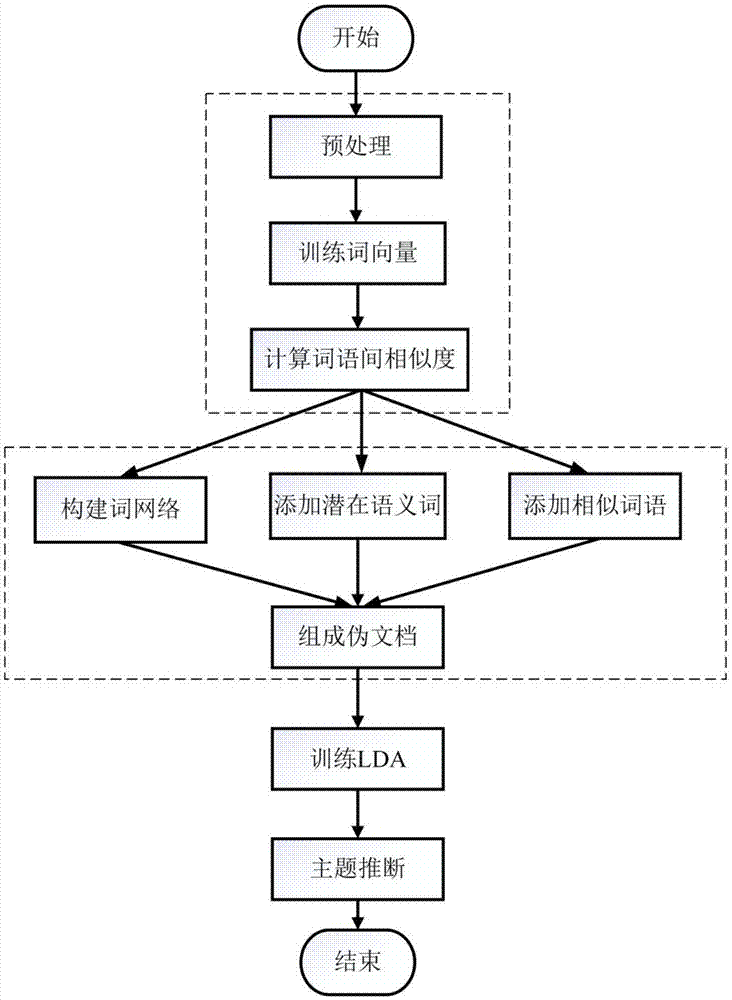
图1为本发明所述基于词网络和词向量的短文本主题模型生成方法的流程图;
图2为构建词网络的流程示意图;
图3为构建词语列表llatent(i)的流程图;
图4为构建词语列表lsimilar(i)的流程图。
具体实施方式
下面结合附图对本发明作更进一步的说明。
图1为本发明的流程图,整个流程包括三个阶段:
一、学习语义信息阶段:
步骤1、对文本数据进行预处理,主要实施的动作为分词(若是英文短文本数据可以省略分词步骤,中文则需要进行分词,一般使用jieba分词工具)、去除停止词;
步骤2、使用mikolov提出的word2vec模型方法对预处理后的文档进行词向量训练;
步骤3、利用步骤2训练得到的词向量计算词语之间的相似度,此处采用余弦相似度,余弦相似度计算公式为:
式中,sim(i,j)表示词语i和词语j之间的余弦相似度,
二、构建伪文档阶段:本发明对每个词语i构建一个伪文档,再在其伪文档的基础上进行主题建模,每个词语i的伪文档由三个部分组成,以下分别进行介绍:
步骤4、构建词网络:设置窗口大小为w,通过滑动窗口提取包括词语i在内的n个词语,构成词语i的词网络;图2是利用滑动窗口构建词网络的示意图,可以看出,与词语i距离越近的词语,在词网络中出现的频率越高。
步骤5、构建共现词语列表,在此用llatent(i)表示;将提取到的除词语i以外的词语以频率fri,j加入词语列表lcooccur(i);fri,j的计算公式为:
其中,avri为构建词网络之后i的伪文档的平均长度,sim(i,j)为词语i和词语j之间的相似度,σ()为sigmoid函数;count(i,j)为词语i的当前词网络中j出现的次数。
步骤6、用词向量的算术关系寻找语义相近但不存在共现关系的词语加入词语列表llatent(i),具体流程如图3所示:
对词语i的词网络中的词语j,用词向量计算向量wi+wj与词语j的余弦相似度,其计算公式如下:
式中,wlatent表示将要加入到llatent(i)中的词语,δ为设置的相似度阈值,
将计算得到的余弦相似度与相似度阈值δ的大小进行比较,若大于δ,则将词语j添加到词语列表llatent(i);否则,不添加词语j。
步骤7、判断词语i目前的伪文档长度,若长度小于预设的最大长度l,则将与i最相似的m个词语加入词语列表lsimilar(i),具体流程如图4所示:
判断是否满足lcooccur(i)+llatent(i)<l,l表示伪文档的最大长度;若满足,则选取词网络中与词语i相似度最高的m个词语加入词语列表lsimilar(i)中。
步骤8、将步骤5、6、7得到的三个词语列表lcooccur(i)、llatent(i)和lsimilar(i)组合得到词语i最终的伪文档;
步骤9、利用步骤8得到的伪文档,进行lda主题建模;
步骤10、用步骤9得到的伪文档主题、词语概率分布推断得到原文档的主题词语分布。
综上所述,本发明是一种基于词网络和词向量的短文本主题模型方法,解决了短文本主题模型中的稀疏性、不平衡性以及噪声多的诸多难点。本发明基于词网络,并通过训练词向量、计算词语相似度,为短文本数据中的词语构建伪文档,随后进行lda主题建模,最终的发明效果:既能克服短文本的稀疏性、不平衡性等难点,又通过引入语义信息提升了模型的性能。
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!