一种基于遗忘机制的全局核密度估计模型的更新方法与流程
本发明涉及一种基于遗忘机制的全局核密度估计模型的更新方法。
背景技术
随着物联网技术的发展,各类智能系统中需要处理的数据量日益增长。为解决大数据处理过程中出现的问题,有学者提出了云计算技术,利用分布节点将数据收集至性能卓越的中心节点进行统一处理。云计算技术对数据的处理及其依赖中心节点的性能,间接导致系统运行存在不稳定性,因此有学者提出了分布式计算技术。利用分布节点的计算能力将数据处理任务下放至分布节点完成,而中心节点则主要承担管理工作,大大提高了系统工作效率。
核密度估计是一种不需先验知识,从数据样本本身出发求解样本概率密度的方法,被广泛应用在各类场合。利用核密度估计模型可以有效解决数据概率密度估计、异常数据检测等问题。将核密度估计模型应用在分布式场景下,每一个分布节点有自己的本地数据集,对应本地核密度估计模型。中心节点可以求解出全局核密度估计模型,但随着数据源不断产生新数据需要对全局核密度估计模型进行更新。
技术实现要素:
本发明的目的在于提供一种基于遗忘机制的全局核密度估计模型的更新方法,,以克服现有技术中存在的缺陷。
为实现上述目的,本发明的技术方案是:一种基于遗忘机制的全局核密度估计模型的更新方法,包括产生本地核密度估计模型的分布节点与产生全局核密度估计模型的中心节点;
所述分布节点独立采集数据形成本地数据集,根据本地数据集计算本地核密度估计模型,根据需要判断本地核密度估计模型是否发生显著变化,将判断结果及本地核密度估计模型上报至中心节点;
所述中心节点接收来自分布节点上传的本地核密度估计模型及本地模型变化显著性判定结果,根据需要对全局核密度估计模型进行更新。
在本发明一实施例中,所述分布节点的操作包括数据采集、本地核密度估计模型计算、本地核密度估计模型变化显著性判别三个阶段;
数据采集阶段:分布节点利用各类数据采集设备,采集系统所需数据;
本地核密度估计模型计算阶段:每隔预设周期,分布节点将采集到的数据利用核密度估计方法计算概率密度,即本地核密度估计模型;
本地核密度估计模型变化显著性判别阶段:分布节点计算最新本地核密度估计模型与前一个本地核密度估计模型的差异度,并判断当前本地核密度估计模型是否发生显著变化,将判断结果与最新本地核密度估计模型上传至中心节点。
在本发明一实施例中,所述中心节点的更新操作包括知识学习、知识回忆与知识遗忘三个阶段;
知识学习阶段:当分布节点将本地最新核密度模型上传至中心节点时,中心节点每一个模型进行参数初始化并将模型存入知识库;
知识回忆阶段:判断当前时刻是否满足全局核密度估计模型更新条件,更新条件是上报本地核密度估计模型发生显著变化的本地节点个数占本地节点总数达到预设比例或到达全局核密度估计模型强制更新时刻;当满足更新条件时,首先计算上一个全局核密度估计模型与知识库中所有模型的差异度,选取差异度最小的50%个模型作为有用的知识,最后取它们的平均结果作为全局最新核密度估计模型;
知识遗忘阶段:在对知识库中的模型进行选择与使用完毕后,对选中的模型进行参数更新,更新完毕后,若知识库中现有模型个数超过记忆容量,则将记忆强度最低的模型从记忆库中删除。
在本发明一实施例中,在所述本地核密度估计模型计算阶段,分布节点根据采集设备采集到的数据,通过如下方式获取本地核密度估计模型:
其中,n为样本容量,h为窗宽,k(·)为核函数。
在本发明一实施例中,所述核函数采用高斯核函数:
在本发明一实施例中,所述本地核密度估计模型变化显著性判别阶段,每隔预设周期,所述分布节点求得最新本地核密度估计模型后,对最新模型与上一时刻模型进行差异度计算,评估本地核密度估计模型的变化;若差异度超过预设阈值,则判定为当前分布节点本地核密度估计模型发生显著变化,反之则未发生显著变化;判定结束后所述分布节点将差异度及最新本地核密度估计模型上传至所述中心节点,通过所述中心节点进行全局核密度估计模型更新操作。所述预设周期为5min,所述预设阈值为0.5。
在本发明一实施例中,在所述本地核密度估计模型变化显著性判别阶段,通过如下方式进行求解前后两个本地核密度估计模型差异度:
其中,ψjs为评估标准;p和q为前后两个本地核密度估计模型,ω为数据样本x的值集。
在本发明一实施例中,在所述知识学习阶段,所述参数初始化操作包括对知识库中每一个核密度估计模型进行如下两个参数的初始化:其一是记忆强度w,初始值为1;其二是遗忘因子v,初始值为该模型与上一个对应本地核密度估计模型的差异度。
在本发明一实施例中,在所述知识回忆阶段,通过如下方式进行求解上一个全局核密度估计模型与知识库内各核密度估计模型差异度:
其中,ψjs为评估标准;p为上一个全局核密度估计模型,q为知识库内保存的核密度估计模型,ω为数据样本x的值集。
在本发明一实施例中,在所述知识回忆阶段,所述模型的选择方式为选择与上一个全局核密度估计模型差异度最小的前50%个知识库内保存的核密度估计模型参与最新全局核密度估计模型的计算。
在本发明一实施例中,在所述知识遗忘阶段,所述参数更新操作包括对知识库中每一个被选中的核密度估计模型进行如下三个参数的更新:其一是模型选中次数λ,更新时直接加1即可;其二是记忆强度w,更新公式如下:
w=e-v(t'-τ)
其中,τ表示该模型最近一次被选中的时间,t’表示当前时间;其三是遗忘因子v,更新公式如下:
其中,β表示遗忘因子初始值。
相较于现有技术,本发明具有以下有益效果:
(1)能够充分利用分布节点广泛分布的特性及日益增强计算能力,减少中心节点计算量,提高系统稳定性;
(2)相较于传统的更新方法,利用遗忘机制通过已有的核密度估计结果计算出最新全局核密度估计模型,即使系统数据量急剧增长也不会使计算量出现大幅增加。此外,将数据的时间性列入考量范围,可以使更新结果趋于稳定,获得良好的更新效果;
(3)方法对分布节点、中心节点的硬件不做限制,具有通用性。
附图说明
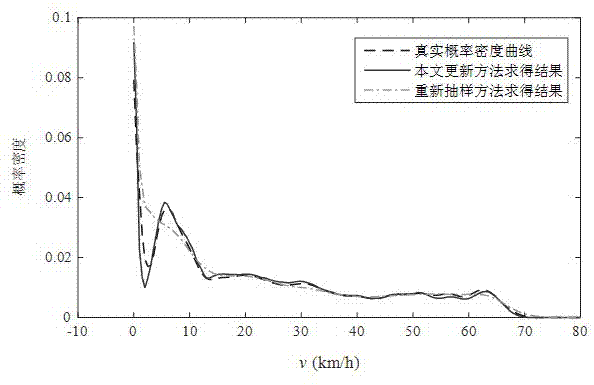
图1为本发明一实施例中效果验证结果示意图。
具体实施方式
下面结合附图,对本发明的技术方案进行具体说明。
本发明提供了一种基于遗忘机制的全局核密度估计模型更新方法,方法基于分布式场景,包括:分布节点以及中心节点。
分布节点独立采集数据形成本地数据集,根据式(1)利用本地数据集计算本地核密度估计模型:根据需要判断本地核密度估计模型是否发生显著变化,将判断结果及本地核密度估计模型上报至中心节点。
中心节点不采集数据,接收来自分布节点上传的本地核密度估计模型及本地模型变化显著性判定结果,根据需要对全局核密度估计模型进行更新。
进一步的,方法具体包含“知识”学习、回忆与遗忘三个阶段;
“知识”学习阶段:当分布节点将本地最新核密度模型上传至中心节点时,中心节点每一个模型进行参数初始化并将模型存入知识库;
“知识”回忆阶段:判断当前时刻是否满足全局核密度估计模型更新条件,当满足更新条件时,首先计算上一个全局核密度估计模型与知识库中所有模型的差异度,选取差异度最小的若干模型作为有用的知识,最后取它们的平均结果作为全局最新核密度估计模型;
“知识”遗忘阶段:在对知识库中的模型进行选择与使用完毕后,对选中的模型进行参数更新,更新完毕后,若知识库中现有模型个数超过记忆容量,则将记忆强度最低的模型从记忆库中删除。
进一步的,在分布节点本地核密度估计模型计算阶段,根据采集设备采集到的数据,通过式(1)获取本地核密度估计模型:
其中,n为样本容量,h为窗宽,k(·)为核函数,常用如式(2)的高斯核函数:
进一步的,每隔预设周期,所述分布节点求得最新本地核密度估计模型后,对最新模型与上一时刻模型进行差异度计算,评估本地核密度估计模型的变化;若差异度超过预设阈值,则判定为当前分布节点本地核密度估计模型发生显著变化,反之则未发生显著变化;判定结束后所述分布节点将差异度及最新本地核密度估计模型上传至所述中心节点,通过所述中心节点进行全局核密度估计模型更新操作。
进一步的,在所述本地核密度估计模型变化显著性判别阶段,通过式(3)进行求解前后两个本地核密度估计模型差异度:
其中,ψjs为评估标准;p和q为前后两个本地核密度估计模型,ω为数据样本x的值集。在本实施例中,预设周期为5min,将ψjs>0.5作为变化程度显著的阈值。
进一步的,中心节点在“知识”学习阶段,参数初始化操作包括对知识库中每一个核密度估计模型进行如下两个参数的初始化:其一是记忆强度w,初始值为1;其二是遗忘因子v,初始值为该模型与上一个对应本地核密度估计模型的差异度。
进一步的,中心节点在“知识”回忆阶段,全局核密度估计模型的更新条件是上报本地核密度估计模型发生显著变化的本地节点个数占本地节点总数达到预设比例或到达全局核密度估计模型强制更新时刻。
在本发明一实施例中,在“知识”回忆阶段,所述预设比例为50%。
在本发明一实施例中,在“知识”回忆阶段,通过式(4)进行求解上一个全局核密度估计模型与知识库内各核密度估计模型差异度:
其中,ψjs为评估标准;p为上一个全局核密度估计模型,q为知识库内保存的核密度估计模型,ω为数据样本x的值集。
在本发明一实施例中,在“知识”回忆阶段,所述模型的选择方式为选择与上一个全局核密度估计模型差异度最小的前50%个知识库内保存的核密度估计模型参与最新全局核密度估计模型的计算。
进一步的,中心节点在“知识”遗忘阶段,参数更新操作包括对知识库中每一个被选中的核密度估计模型进行如下三个参数的更新:其一是模型选中次数λ,更新时直接加1即可;其二是记忆强度w,更新公式如式(5):
w=e-v(t'-τ)(5)
其中,τ表示该模型最近一次被选中的时间,t’表示当前时间;其三是遗忘因子v,更新公式如式(6):
其中,β表示遗忘因子初始值。
进一步的,对上述实施例进行效果验证,基于实际生活中收集到的车速数据得到如图1所示结果。从图1中可以看出,本发明提出的基于遗忘机制的全局核密度估计模型更新算法在实际中能取得比较好的更新效果,相比于不考虑时间性的重新随机抽样方法更贴近实际概率密度曲线。
以上是本发明的较佳实施例,凡依本发明技术方案所作的改变,所产生的功能作用未超出本发明技术方案的范围时,均属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!