一种基于孤立森林算法和神经网络的电力运维数据清洗方法与流程
本发明提供一种电力通信运维数据的清洗方法,更具体地,涉及一种基于孤立森林算法和神经网络的电力运维数据清洗方法。
背景技术
随着电力通信网的蓬勃发展,电力运维数据体量越来越大,电力部门对数据可靠性的要求也越来越高。在电力运维数据的传输与存储过程中,受外界干扰与传输误差等影响,不可避免会产生噪声、数据缺失、数据错误等不良数据问题;电力数据含有多维属性且分别由不同设备获取,给数据的异常检测提出了挑战。传统的计算均值与回归分析等数据修正方式无法准确地学习整个数据集的特征与规律,特别是当数据维度较高的情况,导致了数据修正误差较大。目前,数据清洗主要包括一致性检验,错误值、缺失值和无效值的处理等机制,可采用人工神经网络算法提高数据质量。专利201610370415.7针对rfid数据公开了一种数据清洗方法,通过硬件epc(electronicproductcode,电子产品码)过滤器来过滤编码错误的数据,从而实现了对重复数据的清洗。但是该方法没有针对缺失值和无效值进行修正,同时由于硬件处理能力受限,不适合处理大规模属性复杂的电力运维数据;专利201510129479.3在数据仓库中基于etl机制进行数据清洗,清洗范围大,算法执行效率高。但由于电力运维数据含有多维属性,数据体量、规模巨大,属性复杂,上述方案在清洗精度和数据质量等方面仍有不足。选择高效的数据清洗方法为电力运维数据的分析和挖掘提供了重要支撑,对电力运维综合效益的提高具有重要意义。
技术实现要素:
本发明为克服上述现有技术所述的至少一种缺陷,提供一种基于孤立森林算法和神经网络的电力运维数据清洗方法,本方法改善了孤立森林算法的分支步骤,提高了孤立森林模型的效率和准确性,使学习速率随着网络的变化趋势自适应调整,改善bp神经网络的性能。此方法在异常数据定位准确性、数据修正准确率、训练时间和资源占用等方面都得到了有效的优化。
为解决上述技术问题,本发明的技术方案如下:
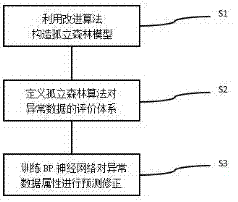
一种基于孤立森林算法和神经网络的电力运维数据清洗方法,其特征在于,包括以下步骤:
s1、利用改进的孤立森林算法,构造解决目标问题的孤立森林模型iforest;
s2、定义孤立森林算法对异常数据的评价体系;
s3、训练学习速率自适应bp神经网络对通过孤立森林检测出的异常数据属性进行预测修正。
作为优选,所述步骤s1的具体包括如下:
s11、方法的开始阶段,首先将属性分组;
s12、从训练数据集中随机选择ψ个样本数据点作为子采样集,并构造一棵初始itree,将子采样集放入树的根节点;ψ为随机选择的样本数据点个数;
s13、随机指定数据项的一个属性组,在当前节点数据中选择划分切割点;
s14、以此切割点生成一个超平面,将当前节点的数据空间划分为两个子空间,并划分数据项;
s15、递归构造新的孩子节点,直到孩子节点中只有一个数据项(无法继续切割)或该itree已经达到初始定义好的限定高度。
作为优选,所述的步骤s2具体包括:
s21、选定测试数据x,将其代入森林中的每一棵itree;x表示测试数据;
s22、计算其落在每棵树的深度h(x),并计算所有h(x)的平均值e(h(x));其中h(x)表示测试数据点落在每棵树的深度;e(h(x))表示所有h(x)的平均值;
s23、根据式(1)设置标准平均搜索长度c(ψ):
c(ψ)=2h(ψ-1)-(2(ψ-1)/ψ)式(1)
其中h(i)按式(2)计算:
h(i)=ln(i)+ec式(2)
ec为欧拉常数,其值为0.5772;c(ψ)表示itree的标准平均搜索长度;
s24、根据式(3)定义待测数据的异常评分s(x,ψ):
s(x,ψ)表示待测数据的异常评分,异常评分值越接近1,说明数据为异常数据的可能性越大。
作为优选,所述的步骤s3具体包括:
s31、随机选取数据集中小批量的数据样本,即输入向量与输出期望值的组合,代入神经网络;
s32、逐层进行前向传播过程,根据式(4)和式(5)计算神经网络各层的激活值:
其中w表示bp神经网络中的权值参数,
s33、根据式(6)计算期望值与实际输出的误差:
其中,hw,b(x)表示神经网络经过前向传播取得的输出值,y表示期望值,w和b分别表示权值矩阵与阈值矩阵,j表示误差;
s34、根据式(7)计算整体代价函数,若函数收敛到全局极小值则结束,否则转s35;
其中,l表示神经网络的整体代价函数,m表示样本数量;
s35、进行反向传播过程,反向传播的过程是通过梯度下降算法调整神经网络各层的参数,不断使代价函数减小,首先计算各神经元的误差,并根据式(8)求出误差梯度:
其中,
s36、判断梯度变化趋势,自适应调整神经网络的学习速率,如果相邻两次梯度调整为同方向,则根据式(9)增大学习速率,如果相邻两次梯度调整为相反方向,则说明梯度变化波动较大,根据式(10)减小学习速率:
其中,αk+1表示k+1时刻神经网络的学习速率,用于控制神经网络反向传播过程中梯度变化的速度,αk表示k时刻神经网络的学习速率,
s37、根据式(11)和式(12)的梯度下降算法更新权值参数和阀值参数,α表示当前学习速率,然后返回s31。
与现有技术相比,有益效果是:
(1)在异常数据检测阶段,考虑到电力元数据各属性之间存在相关性,本算法首先改进了孤立森林模型中孤立树(isolationtree)的构造方式,使之对属性的相关性更加敏感,改善了孤立森林算法的分支步骤,提高了孤立森林模型的效率和准确性。
(2)在预测修正数据阶段,本算法根据梯度变化的趋势自动调节学习速率,使学习速率不断向最合适的数值调整,在保证梯度变化稳定的同时,大幅度提高收敛速度,减少了网络开销,解决了传统bp神经网络算法训练后期收敛过于缓慢的问题,还使网络的收敛曲线更加稳定。
该方法构造孤立森林对训练数据集的特征进行提取,并检测出数据集中的异常数据,再使用改进的bp神经网络模型对异常数据处进行预测修改。使得基于改进方案的电力运维数据清洗程序在异常数据定位准确性、数据修正准确率、训练时间等方面都得到有效的优化。
附图说明
图1是本发明一种基于孤立森林算法和神经网络的电力运维数据清洗方法的流程图。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。附图中描述位置关系仅用于示例性说明,不能理解为对本专利的限制。
如图1所示,一种基于孤立森林算法和神经网络的电力运维数据清洗方法,其特征在于,包括以下步骤:
s1、利用改进的孤立森林算法,构造解决目标问题的孤立森林模型iforest;
s2、定义孤立森林算法对异常数据的评价体系;
s3、训练学习速率自适应bp神经网络对通过孤立森林检测出的异常数据属性进行预测修正。
所述步骤s1的具体包括如下:
s11、方法的开始阶段,首先将属性分组;
s12、从训练数据集中随机选择ψ个样本数据点作为子采样集,并构造一棵初始itree,将子采样集放入树的根节点;ψ为随机选择的样本数据点个数;
s13、随机指定数据项的一个属性组,在当前节点数据中选择划分切割点;
s14、以此切割点生成一个超平面,将当前节点的数据空间划分为两个子空间,并划分数据项;
s15、递归构造新的孩子节点,直到孩子节点中只有一个数据项(无法继续切割)或该itree已经达到初始定义好的限定高度。
根据本算法设计的itree分支方法代入数据进行训练,直到iforest中所有itree构造完毕。
所述的步骤s2具体包括:
s21、选定测试数据x,将其代入森林中的每一棵itree;x表示测试数据;
s22、计算其落在每棵树的深度h(x),并计算所有h(x)的平均值e(h(x));其中h(x)表示测试数据点落在每棵树的深度;e(h(x))表示所有h(x)的平均值;
s23、根据式(1)设置标准平均搜索长度c(ψ):
c(ψ)=2h(ψ-1)-(2(ψ-1)/ψ)式(1)
其中h(i)按式(2)计算:
h(i)=ln(i)+ec式(2)
ec为欧拉常数,其值为0.5772;c(ψ)表示itree的标准平均搜索长度;
s24、根据式(3)定义待测数据的异常评分s(x,ψ):
s(x,ψ)表示待测数据的异常评分,异常评分值越接近1,说明数据为异常数据的可能性越大。
所述的步骤s3步骤中,对训练集进行训练,直到神经网络的整体代价函数收敛,将属性(t,ap,rh,v)作为输入向量,电能输出ep作为输出值;具体包括:
s31、随机选取数据集中小批量的数据样本,即输入向量与输出期望值的组合,代入神经网络;
s32、逐层进行前向传播过程,根据式(4)和式(5)计算神经网络各层的激活值:
其中w表示bp神经网络中的权值参数,
s33、根据式(6)计算期望值与实际输出的误差:
其中,hw,b(x)表示神经网络经过前向传播取得的输出值,y表示期望值,w和b分别表示权值矩阵与阈值矩阵,j表示误差;
s34、根据式(7)计算整体代价函数,若函数收敛到全局极小值则结束,否则转s35;
其中,l表示神经网络的整体代价函数,m表示样本数量;
s35、进行反向传播过程,反向传播的过程是通过梯度下降算法调整神经网络各层的参数,不断使代价函数减小,首先计算各神经元的误差,并根据式(8)求出误差梯度:
其中,
s36、判断梯度变化趋势,自适应调整神经网络的学习速率,如果相邻两次梯度调整为同方向,则根据式(9)增大学习速率,如果相邻两次梯度调整为相反方向,则说明梯度变化波动较大,根据式(10)减小学习速率:
其中,αk+1表示k+1时刻神经网络的学习速率,用于控制神经网络反向传播过程中梯度变化的速度,αk表示k时刻神经网络的学习速率,
s37、根据式(11)和式(12)的梯度下降算法更新权值参数和阀值参数,α表示当前学习速率,然后返回s31。
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!