一种基于谓词的多源数据集清洗方法与流程
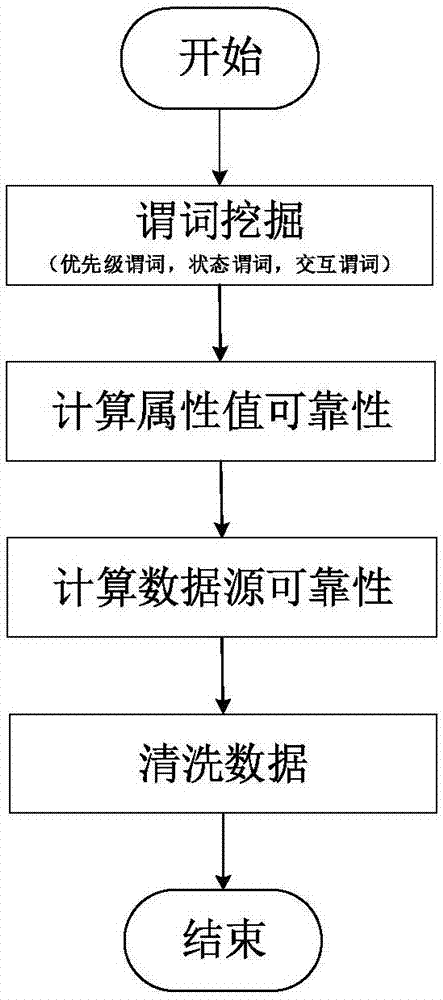
本发明涉及数据清洗、数据融合等领域,尤其是一种基于谓词的多源数据集清洗方法。
背景技术:
在信息时代,可以从大量的数据源中找到对同一个事件或者物体的描述数据,同时由于时间错误、格式错误、精确度、完整性、语义上的歧义等原因,来自不同数据源对同一实体的描述存在不一致性。在从不同数据源搜集数据后,解决属于同一实体的描述数据之间的不一致性,对后续的数据分析至关重要。简单的投票策略——选择较多数据源支持的描述——并不适用于当下web环境,而需要考虑数据源可信度、数据本身的可信度以及一些先验知识来设计更复杂的清洗策略。现有的清洗策略主要包括以下几种:中国专利201410387772号申请文件公开了“一种基于交通多源数据融合的公交路况处理系统及方法”,它融合来自不同数据源的描述公交路况的交通数据得到可供展示的路况信息。它的输入为特定交通数据,没有根据谓词进行可信度判断,也没有根据数据和数据源之间的关系计算数据源的可信度。中国专利201110369877号申请文件公开了“一种多源数据集成平台及其构建方法”,它是对不同的数据进行管理,这些数据之间不存在一致性问题。美国专利us8190546号申请文件公开了“dependencybetweensourcesintruthdiscovery”,它通过数据源之间的拷贝关系建立概率图模型来评估数据源和数据的可信度,并不涉及用谓词来评估数据的可信度。技术实现要素:发明目的:为了克服目前在多源数据融合中,描述相同实体的数据不一致的问题,也就是多源数据一致性问题中难以确定数据可信度初始值,以及如何结合数据源可信度和数据可信度的问题,本发明提供一种基于数据源可信度和数据可信度的多源数据集清洗方法,通过设定谓词计算数据可信度,再通过数据可信度计算数据源可信度,最终找出可信度最高的数据,达到数据清洗的目的。技术方案:为实现上述技术效果,本发明提出一种基于谓词的多源数据集清洗方法,包括步骤:(1)构建谓词模型:定义优先级谓词、状态谓词和交互谓词;其中,优先级谓词为prior(ai,aj),表示属性ai的优先级高于属性aj的优先级;状态谓词为:其中,ti表示语句i,表示语句i中属性ak的属性值,表示预定义的与之间满足的条件,φ(ti,tj)表示预定义的ti与tj之间满足的条件;stat(ak)表示当ti和tj满足条件p和φ时,ti的质量高于tj;交互谓词为:interδ(a1,…,al),表示当数据满足条件δ时,该条数据的属性a1,…,al的属性值质量差;(2)通过步骤(1)定义的谓词模型对待清洗的数据集进行谓词挖掘,得到数据集中的优先级谓词、状态谓词和交互谓词;(3)根据得到的谓词推导数据集中各数据的属性值可信度,包括步骤:(3-1)初始化数据集中数据的所有属性值可信度为0,并为每一条数据的各属性值设置影响因子η,η为一个常数;(3-2)运用状态谓词和交互谓词更新每条数据各属性值的可信度,更新时,先运用状态谓词更新再运用交互谓词更新,或先运用交互谓词更新再运用状态谓词更新;运用状态谓词更新数据各属性值的可信度的步骤为:两两枚举数据集中的两条数据ti和tj,如果ti和tj在属性ak上满足状态谓词:则将属性值的可信度减去η;运用交互谓词更新数据各属性值的可信度的步骤为:遍历数据集中的所有数据,如果一条数据满足某个交互谓词interδ(a1,…,al),则将该条数据属性a1,…,al的属性值的可信度减去η;(3-3)在步骤(2)完成后,运用优先级谓词更新每条数据的属性值可信度,更新时,按照优先级从高到低的顺序依次执行优先级谓词;执行优先级谓词prior(ai,aj)的步骤为:若多条数据在属性aj上的属性值的可信度相同,则将它们按照ai的属性值可信度做升序排序,按照排序后的顺序,在排在第n位的数据的aj的属性值可信度上加上n-1;(3-4)得到所有属性值的可信度后,对于多值属性,返回所有可信度大于等于预设阈值的属性值作为结果;对于只需要返回一个结果的属性,执行步骤(4)至(6);(4)将所有属性值的可信度进行归一化;根据公式计算待清洗数据集中所有数据源的可信度;其中,λi表示数据源di的可信度,t表示数据源di中的一条数据,d(t)表示数据t的可信度,数据t的可信度等于该条数据所有属性值可信度之和;(5)根据公式更新各属性值的可信度,d′表示对于属性aj提供属性值的数据源;更新后返回步骤(4);(6)重复执行步骤(4)至(5),直至所有属性值的可信度收敛;对于只需返回一个结果的属性,找出该属性下可信度最高的属性值为最终结果。进一步的,所述优先级谓词的定义方法为:对于属性ai和aj,若满足pscore(ai)<pscore(aj),则定义优先级谓词prior(ai,aj),表示属性ai的优先级pscore(ai)高于属性aj的优先级pscore(aj);其中,h(ai)表示属性ai的香农熵,pn(ai)表示属性ai的所有属性值中null值的比例。进一步的,所述状态谓词和交互谓词均通过一阶逻辑谓词挖掘方法获得。进一步的,在对数据集进行清洗前,对于所有的数据集的所有属性进行人工标记,标记每个属性需要返回一个结果还是多个结果,如果一个属性只需返回一个结果,则标记该属性为单值属性,清洗时将该属性下可信度最高的属性值为最终结果;如果一个属性可能存在多个结果,则标记该属性为多值属性,清洗时将该属性下可信度大于预设阈值的所有属性值为最终结果。有益效果:与现有技术相比,本发明具有以下优势:无需假定一个属性仅有一个正确值存在,也不依赖于众包,无需大量人工干预,利用自动挖掘出的谓词和数据集与属性值之间的关系找出可信度高的属性值。本发明通过挖掘自定义谓词来对属性值的可信度打分,对于多答案属性找出可信度高于预设阈值的属性值作为结果,对于剩下属性,结合数据源可信度和属性值可信度的关系进一步更新属性值可信度,找到可信度最高的属性值作为结果,对提高数据分析的效率和数据分析的精确度具有重要意义。采用本发明的技术方案,工程人员可以比较容易地实现相关软件。附图说明图1为本发明的流程图;图2为本发明中更新数据源中属性值可信度的计算流程示意图。具体实施方式下面结合附图对本发明作更进一步的说明。图1所示为本发明的流程图,本发明主要包括以下几个部分:a)首先定义三种谓词:1)优先级谓词:对于属性ai和aj,如果pscore(ai)<pscore(aj),则定义一个优先级谓词prior(ai,aj),表示属性ai的优先级pscore(ai)高于属性aj的优先级pscore(aj);其中,h(ai)表示属性ai的香农熵,pn(ai)表示属性ai的所有属性值中null值的比例。h(ai)的计算公式为:h(ai)=-∑x∈xp(x)log2p(x),x为属性ai属性值的值域,p(x)代表属性值x占所有属性值的比重(不包括null值)。2)状态谓词:状态谓词为一阶逻辑谓词,其形式为:表示ti和tj满足条件p和φ,则ti的质量高于tj。上述定义中的条件而fi(v1,v2)可被v1=v2或v1≠v2替换。状态谓词定义中的p可以被预先定义的6个谓词替换,分别是p1(v1,v2)、p2(v1,v2)、p3(v1,v2)、p4(v1,v2)、p5(v1,v2)、p6(v1,v2)。p1(v1,v2)、p2(v1,v2)适用于数值类型的属性值,p1(v1,v2)表示v1比v2大,p2(v1,v2)表示v1比v2小;p3(v1,v2)、p4(v1,v2)适用于字符类型的属性值,p3(v1,v2)表示v1比v2长,p4(v1,v2)表示v1比v2短;p5(v1,v2)、p6(v1,v2)适用于字符类型的属性值,字符串更详细代表其包含更多信息,其度量方式为用香农熵公式比较两个字符串包含的信息量,p5(v1,v2)表示v1比v2更详细,p6(v1,v2)表示v1比v2更简略。3)交互谓词:交互谓词为一阶逻辑谓词,其形式为interδ(a1,…,al),表示当一条数据满足条件δ,则该条数据的a1,…,al属性值质量差。上述定义中的其中pi′可以被p1~p6任意谓词替换,同时还可以被以下4个谓词替换:p7(v1,v2)、p8(v1,v2)、p9(v1,v2)、p10(v1,v2);其中,p7(v1,v2)、p8(v1,v2)适用于字符类型的属性值,p7(v1,v2)表示v1包含v2,p8(v1,v2)表示v1不包含v2;p9(v1,v2)、p10(v1,v2)适用于字符类型和数值类型的属性值,p9(v1,v2)表示v1等于v2,p10(v1,v2)表示v1不等于v2。然后根据数据集进行谓词挖掘:对于优先级谓词,可以根据公式计算数据集所有属性的优先度获得;对于状态谓词和交互谓词,根据其一阶逻辑谓词的定义,由一阶归纳学习方法自动获得。在获取状态谓词和交互谓词后,为了进一步提高谓词的可用性,可以请领域专家去掉无效谓词得到最终可用的谓词;b)首先初始化所有属性值的可信度为0,并人工设置参数η(影响因子)为一个实数。然后按以下顺序执行三类谓词推导出数据集中各实体的属性值的可信度;1)运用状态谓词:两两枚举数据集中两条数据,如果这两条数据满足某个状态谓词则将的可信度减去η。2)运用交互谓词:遍历数据集中的所有数据,如果一条数据满足某个交互谓词interδ(a1,…,al),则将该条数据a1,…,al属性值可信度减去η。3)运用优先级谓词:由于属性的优先级是由决定的,为了使当前属性值的可信度是最新的,需先执行优先级高的优先级谓词,即所含两个属性的pscore之和较小的优先级谓词。优先级谓词prior(ai,aj)的功能是,如果两条数据t1、t2满足条件此时可通过属性ai的可信度来判断和哪个好。方法为,对于所有在aj上可信度相同的多个数据,将它们按照ai的可信度作升序排序,按照排序后的顺序,在排在第n位的数据的aj的属性值可信度上加上n-1,这样就根据优先级较高的ai区分出了可信度相同的aj的值。同时注意对于需要返回多个结果的属性,如果可信度为负数,则无需运用优先级谓词。得到所有属性值的可信度后,对于需要返回多个结果的属性,返回所有可信度大于等于预设阈值的属性值作为结果,对于需要返回一个结果的属性,继续以下步骤。c)根据计算数据源的可信度,并对所有数据源的可信度进行归一化,即∑iλi=1,如图2所示。再用更新每个属性值的可信度,每个属性值的可信度等于提供该属性值的数据源的可信度之和乘上自己原有的可信度,注意null值的数据源可信度就是自身数据源的可信度,不包括其它提供null值的数据源的可信度。接着,同样对所有属性值的可信度进行归一化,使得对于任意一个属性,其所有可能取到的值的可信度和为1。重复上述步骤直到数据源的可信度和每个属性值的可信度收敛。d)最后,对于只需返回一个结果的属性,找出该属性下可信度最高的属性值为最终结果,结合b)中的结果作为最终结果。下面将结合具体样例,说明本发明的实施方式:我们令一个数据源di的可信度为λi,该数据源属性集合为{a1,…,an},而t∈di为该数据源的一条数据,其中代表t对应aj的属性值。再令d(t)表示该条数据的可信度,表示属性值的可信度。一条数据的可信度等于该条数据所有属性值可信度之和,即:而一个数据源的可信度等于其包含的所有数据的可信度的平均值,即所有数据的可信度之和除以数据的数目:同时,令d′为对于属性aj提供属性值的数据源,则属性值的可信度为所有提供该值的数据源的可信度之和乘上自己原有的可信度:实施例:清洗数据集如下表所示,一共有5条数据和5个数据源,其中ti来自数据源di,描述了一个名叫mary的科研人员数据。清洗数据集表首先,先简单观察一下数据集,做一个人工预处理,清除一些明显不合理的数据,使得后续的数据清洗效率更高,效果更好。比如上面数据集中的t5这一条数据,salary为负值,明显不合理,并且这条数据中后面的researcharea,affiliation和publication这三个属性的值也没有太大意义,因此可以将t5这条数据视作噪声直接删除,而不参与后续的清洗操作。再看t4这条数据,它的publication这个属性的值为“-”,这个也属于不合理的数据,但因为t4这条数据其他属性的值仍有参考价值,因此可以直接将publication的值改为“null”。经过上述简单的预处理之后,得到的数据集如下:第一步,对数据集进行谓词挖掘。挖掘优先级谓词对于优先级谓词,统计所有属性的熵和null值的比例。熵计算公式:h(ai)=-∑x∈xp(x)log2p(x)其中,p(x)代表属性值x占所有属性值的比重(不包括null值);以salary为例,共有3个属性值,分别是142k,120k和88k。其中,则可得属性salary的熵为:同理:pn(salary)=pn(researcharea)=0可以得到:根据上述小于关系可定义三个优先级谓词:挖掘状态谓词:由一阶逻辑谓词挖掘算法firstorderinductivelearner自动获得:挖掘交互谓词:同样由一阶逻辑谓词挖掘算法firstorderinductivelearner自动获得:第二步,推导各实体的属性值的可信度。初始化所有属性值的可信度为0,设置影响因子η=1,对于需要返回多个结果的属性,设可信度置阈值为0。然后按一定的顺序使用相应的谓词(不同的谓词执行顺序可能会产生不同的结果)。状态谓词和交互谓词都是作用于属性值,而属性值不会改变,因此状态谓词与状态谓词之间、交互谓词与交互谓词之间,以及状态谓词和交互谓词之间均相互独立,可以以任意顺序调用。然而,优先级谓词作用在属性值的可信度之上,因此优先级谓词必须在所有状态谓词和交互谓词之后使用。除此之外,优先级谓词和优先级谓词之间也必须遵守一定的顺序。为了使当前属性值的可信度是最新的,需先执行优先级高的优先级谓词,即所含两个属性的优先级之和较小的优先级谓词。对于清洗数据集表的优先级谓词,的pscore之和为3.5,的pscore之和也为3.5,的pscore之和为4.11,所以应按照的顺序执行优先级谓词。在执行状态谓词后,所有属性值的可信度如表1所示。这里有4条数据,需两两进行比较,一共进行了16次比较。以t1和t2为例,根据状态谓词因为所以将减1。表1salaryresearchareaaffiliationpublicationt1(d1)0000t2(d2)-1000t3(d3)-2000t4(d4)-2000在执行交互谓词后,所有属性值的可信度如表2所示。此处根据交互谓词和将所有affiliation和publication值为null的属性值可信度减1。表2salaryresearchareaaffiliationpublicationt1(d1)0000t2(d2)-100-1t3(d3)-2000t4(d4)-20-1-1在执行优先级谓词后,所有属性值的可信度如表3所示。以researcharea为例,初始researcharea列的值为{0,0,0,0],根据优先级谓词可以根据salary列的{0,-1,-2,-2)来更新researcharea列的值。将researcharea列中可信度相同的值根据salary列的升序重新排序,排序后分别加上0,1,2,还原顺序后得到{2,1,0,0]。同理再执行优先级谓词和表3salaryresearchareaaffiliationpublicationt1(d1)0221t2(d2)-111-1t3(d3)-2000t4(d4)-20-1-1接着对所有属性进行标记,一个科研人员同一时间只能有一个工资和一个隶属机构,所以salary和affiliation都只返回一个结果,但是一个科研人员的研究领域和著作却可以有多个,因此researcharea和publication属性应该返回多个结果值。对于多值属性,此时返回大于等于阈值0的所有属性值,即对于researcharea,返回结果为{dataintegration,datacleaningdatacleaning&googleknowledgemanagementinformationretrieve},对于publication,返回结果为{dataintegration,adiagnostictoolfordataerrors}。第三步,计算数据源可信度。接着通过把所有属性值的可信度值映射到(0,1),并且归一化,结果如表4所示。并且根据计算所有数据源的可信度。表4salaryresearchareaaffiliationpublicationλt1(d1)0.4963530.337230.3699590.4132750.404204t2(d2)0.266980.27990.3070650.1520350.251495t3(d3)0.1183330.1914350.2100140.2826550.200609t4(d4)0.1183330.1914350.1129630.1520350.143692最后通过和两个式子迭代的更新所有属性值的可信度直至所有属性值的可信度收敛,注意每次按列更新属性值的可信度后需要将该列可信度归一化。以第一次更新过程为例,对于salary列的属性值可信度:{0.496353,0.26698,0.118333,0.118333]→{0.496353×0.404204,0.26698×0.251495,0.118333×0.344301,0.118333×0.344301]→{0.200628,0.0671441,0.0407422,0.0407422)同理,对于researcharea列的属性值可信度:{0.33723,0.2799,0.191435,0.191435)→{0.500009,0.258216,0.140871,0.100903]对于affiliation列的属性值可信度:{0.369959,0.307065,0.210014,0.112963)→{0.404204,0.251495,0.200609,0.143692)对于publication列的属性值可信度:{0.413275,0.152035,0.282655,0.152035}→{0.588542,0.134713,0.199777,0.0769686]最后更新数据源的可信度:λ={0.5168,0.209168,0.164478,0.109554)重复上述过程直至收敛,最终结果如表5所示。表5salaryresearchareaaffiliationpublicationλt1(d1)11111t2(d2)00000t3(d3)00000t4(d4)00000第四步,得出结果。根据表5,可选出salary和affiliation属性中最好的属性值,即可信度最大的属性值为结果。其中salary的结果为{142k},affiliation的结果为{amazon}。以上所述仅是本发明的优选实施方式,应当指出:对于本
技术领域:
的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1