电网设备缺陷文本的质量检测方法与流程
本发明属于电力系统领域,具体地说是电网设备缺陷文本的质量检测方法。
背景技术
随着智能电网建设地深入推进,电力系统各个环节产生了海量的多源异构数据,以文本、音频、图像为代表的非结构化数据增长最为迅速。其中描述电网设备缺陷的文本,蕴含着与设备及电网安全最为密切的信息,受到了技术和管理人员的重视,比如为掌握缺陷规律或设备质量情况,对缺陷进行各种视角的分类和统计。由于人工对缺陷文本进行分类和统计,工作量大、效率低,结果依赖于人工主观经验,如何提高缺陷文本的挖掘效率是需要解决的问题。
目前,自然语言处理技术日益成熟,利用机器学习方法或者深度学习方法对中文文本进行挖掘已可实现。然而,实际的电网设备缺陷文本常常存在一些各种原因造成的不规范问题,如描述不完整、有歧义等,若将这些存在质量问题的文本作为有效文本进行挖掘,会给挖掘结果带来一定偏差。因此需要对历史缺陷文本进行质量检测,只有通过质量检测,结果好的才能作为有效文本,结果差的则要进行质量提升后再作为有效文本。
电网设备缺陷文本由于语义复杂,进行文本挖掘难度大。一些研究针对电网设备缺陷文本,进行了不同目的的挖掘,然而共性的问题是挖掘结果受缺陷文本质量影响较大。目前尚不存在缺陷文本质量的检测方法公开发表。
技术实现要素:
本发明所要解决的技术问题是由于电网设备缺陷文本质量存在问题而给电网文本挖掘结果带来偏差,提出一种电网设备缺陷文本质量检测方法,该方法:
首先,分析电网设备缺陷文本的格式特点和内容特点,总结实际缺陷文本中可能出现的问题,如:缺陷描述遗漏对缺陷程度的记录或缺陷描述冗余、设备分层容易遗漏或写错某一层次的内容、缺陷等级与缺陷描述不匹配等。
然后,依据缺陷文本的实际问题,针对性提出完整度i1、精确度i2、冗余度i3作为文本质量检测指标,并结合缺陷文本格式特点中不同部分(如缺陷描述、设备分层等)的重要程度,定义不同指标的量化规则。按该量化规则,利用自然语言处理领域较为成熟的分词、词性标注等技术并结合正则表达式、字符串匹配等方法对实际缺陷文本进行判断,计算其在不同指标上的得分。
最后,提出层次-自适应灰色关联分析法,将层次分析法得到的指标权重向量ωmax,和灰色关联分析法的关联系数矩阵bm×n相结合,其中m为缺陷文本数,n为指标数,并对关联系数中含有的分辨系数ρ根据实际缺陷文本质量做出自适应调整,计算得到缺陷文本的质量检测结果。
本发明的有益效果:在对实际电网设备缺陷文本格式和内容分析研究的基础上,提出了缺陷文本质量检测的定义、指标及量化规则和具体的质量检测方法——“层次-自适应灰色关联分析法”,并针对性地根据不同设备类型自适应调整此方法中的分辨系数,使质量检测结果更为准确合理。本发明为提升和保证电网缺陷文本的质量、促进缺陷文本的规范化、改善缺陷文本挖掘效果奠定了基础,也为电网设备其他文本的质量检测提供了示范。
附图说明
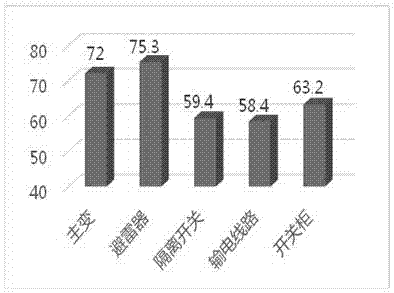
图1不同类型设备缺陷文本平均质量检测结果。
具体实施方式
本实施例以电网设备缺陷文本存在的实际质量问题为依据,提出文本质量检测指标并定义相应量化规则。采用“层次-自适应灰色关联分析法”进行缺陷文本质量检测。具体步骤如下:
步骤1.对电网企业的大量电力设备缺陷文本进行分析,结合国家电网公司输变电一次设备缺陷分类标准(下文简称标准),总结出实际缺陷文本的格式特点。并在格式特点的基础上总结出缺陷文本的常见问题,如:缺陷描述遗漏对缺陷程度的记录或缺陷描述冗余、设备分层容易遗漏或写错某一层次的内容、缺陷等级与缺陷描述不匹配等。
步骤2.依据缺陷文本的实际问题,针对性提出完整度i1、精确度i2、冗余度i3作为文本质量检测指标,并结合缺陷文本格式特点中不同部分(如缺陷描述、设备分层等)的重要程度,定义不同指标的量化规则。给出缺陷文本质量检测的含义为:根据缺陷文本在不同指标上的得分判断其规范程度的过程。具体的量化规则如下:①判断缺陷文本中是否存在缺陷描述及缺陷程度,若两者都存在则将i1记为1;只存在缺陷描述时,可通过缺陷等级对程度进行补全,将i1记为0.8;两者都不存在则记为0。②判断缺陷发生位置是否包含国家电网输变电一次设备缺陷分类标准中设备分层的五个级别,每个级别的权重依次为0.3、0.1、0.2、0.1、0.3,若记录中存在该级别词汇,则从0加上对应权重。最后将每个级别获得权重相加,可得到0~1的权重作为i2的值。若同一级别出现多个词语,此级别的权重也只累加一次。若某些词被不同等级共有,则采用累加的方式计算i2。③判断单条缺陷文本中字符重复率是否达到70%,若超过70%,将i3记为0,反之记为1。此阈值可保证所有的标准语句均不被判定为冗余语句。
步骤3.按上述量化规则,利用自然语言处理领域较为成熟的分词、词性标注等技术并结合正则表达式、字符串匹配等方法对实际缺陷文本进行处理和判断,计算其在不同指标上的得分。具体方法为:①首先利用隐马尔可夫模型(hiddenmarkovmodel,hmm)和维特比(vertibi)算法结合电力本体字典,对单条缺陷文本进行分词、去除停用词和词性标注的预处理;②根据字符重复率求出文本在冗余度上得分;③结合标准给出的设备分层词语,利用字符串匹配的方法确定缺陷文本在精确度上的得分;④利用正则表达式和词性标注结果,分析缺陷描述和缺陷程度存在与否,得到完整度得分。按上述计算缺陷文本在指标上得分的方法可得缺陷文本原始质量检测矩阵sm×n。其中,行数m代表缺陷文本个数,每一行的行向量称为缺陷文本的初始质量向量se;n为指标个数,即n=3;矩阵中的元素为每条缺陷文本在不同指标上的得分。
步骤4.提出“层次-自适应灰色关联分析法”计算缺陷文本的质量评分,具体方法为:
(1)通过对大量缺陷文本的实际特点加以分析,结合步骤2给出的不同指标的量化规则,分析得出完整度稍重要于精确度、而精确度明显重要于冗余度的结论,经过一致性检验,可得层次分析法的判断矩阵a为
(2)通过
(3)经计算得到不同缺陷文本在不同指标上的关联系数后,由βi(j)构成关联矩阵bm×n。利用由层次分析法得到的指标权重ωmax,根据s'm=bm×n*ωmax求出l类设备缺陷文本的评分列向量s'm,s'm的m维分别代表m条缺陷文本的质量检测得分。
应用例:将本发明提出的电网设备缺陷文本质量检测方法应用于实际的25000多条不同类型设备的缺陷文本。不同指标及对应量化规则如表1。示例的两条变压器缺陷文本的质量检测结果如表2;图1为不同类型电力设备缺陷文本的平均质量检测结果。
表1缺陷文本质量检测指标及量化规则
表2不同缺陷文本及其质量检测结果
- 还没有人留言评论。精彩留言会获得点赞!