一种分布式数据存储的数据存取方法、信息数据处理终端与流程
本发明属于计算机软件技术领域,尤其涉及一种分布式数据存储的数据存取方法、信息数据处理终端。
背景技术
目前,业内常用的现有技术是这样的:随着信息技术的飞速发展,物联网以大规模的信息系统和庞大的数据产生量成为目前最吸引研究者的领域之一。日益增长的数据量对数据存储系统提出了挑战,为了解决传统的数据存储系统可扩展性差,存储效率低下、安全性低等问题;数据存储系统-云存储系统得到了前所未有的发展。云存储是在云计算(cloudcomputing)概念上延伸和发展出来的新的概念,是新兴的网络存储技术;通过集群应用、网络技术或分布式文件系统等功能,将网络中大量各种不同类型的存储设备通过应用软件集合起来协同工作,共同对外提供数据存储和业务访问功能的一个系统。云存储系统可以为用户提供巨大的数据存储空间和便捷的数据管理平台,并且有着花费低,按需使用等优点。对用户来说,数据的存取时间是衡量一个云存储系统服务质量的关键,然而,由于在云存储系统中存储节点在地理位置上分布不均匀,并且存储节点的存储能力,链路带宽等各有差异导致如何加速数据的存取时间对云服务运营商来说仍然是一个难点。随着“云”这个概念被提出之后,安全性就是人们首先关注的要点。安全已经成为处理数据的企业的头号关注问题。对用户来说,数据的机密性关乎自身利益,用户通常会关心云中的数据是否会被恶意泄露。为了解决这类问题,现有技术为用户提供了加密服务,用户可根据安全等级选择不同长度的密钥加密数据。在面对云中存储的庞大数据量时,加密数据会产生较长的加密时间并需要消耗大量的计算资源,而且需要用户自行保管自己的密钥。这些又会增加数据的存取时间,降低服务质量。随着云计算的兴起,云存储系统也得到了国内外许多学者的研究和讨论。现有技术一提出一个集中式的数据放置方法,旨在优化数据存取时间。现有技术二提出一个数据复制方法旨在考虑能量效率和带宽消耗的情况下保证数据可用性。现有技术三提出一个基于图分割的数据复制策略旨在最小化数据存取时间,有着充分的数学理论作为支撑,但图分割只从简单的拓扑层面考虑,并没有综合考虑节点性能和链路性能,所以并不能解决实际问题需求。也有基于遗传算法等智能算法来构建数据放置策略,现有技术四采用遗传算法放置数据,旨在减少数据存取时间和数据存取过程中的带宽消耗,但这种方法存在复杂度较高和局部最优问题,也不是十分适合作为较好的数据放置策略。在考虑云数据存储安全性方面,目前大多采用加密和认证的方法。现有技术五提出一个安全的且可扩展的数据接入控制机制来保证云中数据安全性。现有技术六提出一个多云存储的方法,可以极大的增强数据安全性,但多存储会产生较高的费用。以上方法均采用加密来保证数据安全性,但加密存在计算量过大,并且需要考虑密钥的安全保存等问题。
综合来看,现有技术存在的技术缺陷主要是:在选择数据存储节点时,仅仅从拓扑层面考虑了节点的地理位置,并没有综合考虑节点的其他性能信息,比如存储空间,安全性能等。从而当前的数据存储方法并不是一个优秀的方法。本方案与现有方案相比,在数据安全性方面与传统方案相当,但在数据存取时间方面大大小于现有方案,而数据存取时间是衡量一个数据存储策略最重要的指标之一。
综上所述,现有技术存在的问题是:现有技术采用加密保证数据安全性,而目前数据存储量通常过大,所以在数据存储时间方面,加密时间过长而导致数据存储和获取时间太长。
解决上述技术问题的难度和意义:上述问题为当前数据存储策略面临的普遍问题,解决上述问题可以极大的提高数据存储效率,减少数据存取时间,并保证一定的数据安全性,对用户来说,用户体验将会更好。
技术实现要素:
针对现有技术存在的问题,本发明提供了一种分布式数据存储的数据存取方法、信息数据处理终端。
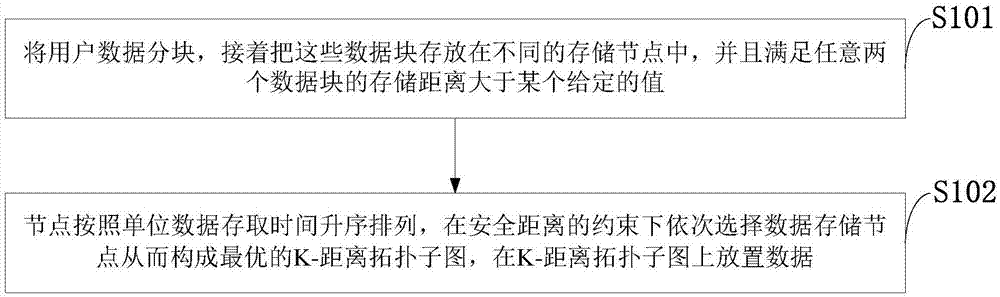
本发明是这样实现的,一种分布式数据存储的数据存取方法,所述分布式数据存储的数据存取方法将用户数据分块,接着把这些数据块存放在不同的存储节点中,并满足任意两个数据块的存储距离大于某个给定的值;节点按照单位数据存取时间升序排列,在安全距离的约束下依次选择数据存储节点从而构成最优的k-距离拓扑子图,在k-距离拓扑子图上放置数据。
进一步,所述安全距离用k表示,k=0,则表示用户对数据安全性没有要求,将所有数据存储在一个存储节点上;k=1,则表示任意两个数据块的存储距离大于1,存储距离即存储数据块的存储节点之间的最短距离;k=2,则表示任意两个数据块的存储距离大于2;
所述安全距离用fs计算,fs表示为:
fs=minfk(sdi,sdj),i≠j,i,j=1,2,...,|v|;
进一步,所述分布式数据存储的数据存取方法的安全参数的聚合值包括:入侵检测系统能力值、反病毒能力、防火墙能力、认证机制能力;
安全参数取值范围为[0,1],存储节点自身保护能力表示为:
spc=i+an+f+au;
其中,i表示入侵检测系统能力值,an表示反病毒能力值,f表示防火墙能力,au表示认证机制能力值。
进一步,所述分布式数据存储的数据存取方法的安全距离为k的数据放置策略sd,满足fs>k;据接入节点为a,则对于每个数据存储节点sdi≠0,i=1,2,...,|v|,从节点i到节点a的数据存取速度为:
其中,pi,a为节点i到节点a的最短路径;利用迪杰斯特拉等最短路径算法找出节点间的最短路径;ls,ld为链路l的两个端点;
进一步,所述分布式数据存储的数据存取方法的k-距离拓扑子图的图g(v,e)是一个无向连通简单图,存在节点集合
给定一个无向图g(v,e),选择一个节点v,寻找与此节点距离为k的节点vj,继续寻找与vj距离为k的节点,不断重复这个步骤直到遍历图g,最后找到的集合k-dis-set为所求k距离拓扑子集。
进一步,所述分布式数据存储的数据存取方法具体包括:
(1)在无向图g中,数据接入点为节点a,则对于图中所有节点v,定义节点v到数据接入点a的单位数据存取速度为:
pv,a表示从节点v到节点a的最短路径,
(2)数据存储节点选择;
输入:g(v,e),k,b,a;
输出:最优数据存储集合priset;
fori=1...|v|;
根据公式计算
endfor;
将节点按照usp从大到小排序,排序后的集合为pv;
priset←pv1;
deletepv1frompv;
fori=1...|pv|;
dis=dijkstra(a,pvi);
ifdis≥k;
priset←pvi;
0deletepvifrompv;
1endif;
2endfor;
3returnpriset;
数据存储节点选择过程:首先按照usp将所有节点从大到小排序,然后采用迪杰斯特拉算法依次选择节点,这样选择出来的节点一定是在保证安全性的前提下数据存取效率最好的节点集合。
本发明的另一目的在于提供一种应用所述分布式数据存储的数据存取方法的分布式数据存储的数据存取系统,所述分布式数据存储的数据存取系统包括:
数据块存放模块,用于将用户数据分块,数据块存放在不同的存储节点中,并且满足任意两个数据块的存储距离大于某个给定的值;
数据存取模块,用于节点按照单位数据存取时间升序排列,在安全距离的约束下依次选择数据存储节点从而构成最优的k-距离拓扑子图,在k-距离拓扑子图上放置数据。
本发明的另一目的在于提供一种实现所述分布式数据存储的数据存取方法的计算机程序。
本发明的另一目的在于提供一种实现所述分布式数据存储的数据存取方法的信息数据处理终端。
本发明的另一目的在于提供一种计算机可读存储介质,包括指令,当其在计算机上运行时,使得计算机执行所述的分布式数据存储的数据存取方法。
综上所述,本发明的优点及积极效果为:在保证一定的数据安全性的前提下减少数据存取时间;在数据安全性方面,考虑到加密算法会牺牲数据存取时间并且消耗大量资源,本发明选择合适的数据放置算法来达到安全性要求,首先将用户数据分块,接着把这些数据块存放在不同的存储节点中,并且满足任意两个数据块的存储距离大于某个给定的值。一旦某个存储节点中的数据遭到攻击,攻击者也不能从中得到有用的信息,与此同时,由于数据被分散存储在各个地理位置不同的存储节点中,攻击者也无从得知数据的放置位置,保证了用户数据安全。
本发明为了提高安全性,提出k-距离拓扑子图的概念,即在一个无向图中,如果存在一个子图,其任意两个节点在原图之间的距离都大于k,则称这个子图为原图的k-距离拓扑子图。本发明采用在原拓扑中寻找k-距离拓扑子图来放置数据从而达到安全性要求。为了最小化数据存取时间,本发明提出一个基于节点优先级的节点选择算法k-dds,k-dds算法将节点按照单位数据存取时间升序排列,然后在安全距离的约束下依次选择数据存储节点从而构成最优的k-距离拓扑子图,然后在这个k-距离拓扑子图上放置数据。最后,通过omnet++仿真平台和matlab仿真平台在不同网络规模的拓扑下对比了k-dds算法和其他算法,并且在模拟实际网络internet2拓扑中验证了算法的有效性。
附图说明
图1是本发明实施例提供的分布式数据存储的数据存取方法流程图。
图2是本发明实施例提供的同一拓扑中不同2-距离拓扑子集示意图;
图中:(a)原始拓扑;(b)4个节点的2-距离拓扑子集;(c)6个节点的2-距离拓扑子集。
图3是本发明实施例提供的随机拓扑下数据量对存取时间影响示意图。
图4是本发明实施例提供的随机拓扑下网络规模对存取时间影响示意图。
图5是本发明实施例提供的internet2拓扑下数据量对存取时间影响示意图。
图6是本发明实施例提供的internet2拓扑下安全距离对存取时间影响示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
本发明针对分布式数据存储系统数据存储方法,考虑到数据泄露问题已经是目前数据存储系统面临的最大挑战,提出考虑数据存取效率和安全性的数据存储方法。本发明提出安全距离的概念不仅保证了数据的安全性,而且考虑不同用户群体对于数据安全的侧重性;为了最小化数据存取时间,提出数据存取节点选择算法,在保证数据安全性的同时最小化数据存取时间。仿真证明在数据存取时间方面,相比目前的几种数据存储算法,在保证数据安全性的同时,提出的算法在数据存取时间方面均小于目前算法。
如图1所示,本发明实施例提供的分布式数据存储的数据存取方法包括以下步骤:
s101:将用户数据分块,接着把这些数据块存放在不同的存储节点中,并且满足任意两个数据块的存储距离大于某个给定的值;
s102:节点按照单位数据存取时间升序排列,在安全距离的约束下依次选择数据存储节点从而构成最优的k-距离拓扑子图,在k-距离拓扑子图上放置数据。
下面结合附图对本发明的应用原理作进一步的描述。
1、系统模型
1.1模型假设
令图g(v,e)表示分布式云存储系统的网络拓扑图,其中v表示存储节点集合,e表示节点之间的链路。并且令sc表示节点的存储能力向量,即sci表示节点i的存储能力大小;令b表示链路带宽矩阵,其中节点i和节点j之间的链路带宽用bij表示,并且对于任意的bij∈b有:
则任意一个分布式云存储系统可以用上述模型表示。本发明假定任何一个存储节点都可以作为存储请求提交的接入点,即用户可以在任意一个存储节点提交数据存储请求,如amazons3,其存储节点遍布全世界,用户可以在任意一个节点进行数据存储。
假定用户需要存储数据量大小为d的数据,为了保证数据安全性,本发明首先对数据分块,这样可以保证任何一块数据丢失都不会造成重要信息的泄露,即攻击者不能从某一块数据得知全部的数据信息。令sd表示存储向量,即sdi表示在节点i存放了sdi大小的数据,显然:
sdi≤sci,i=1,2,...,|v|;
1.2安全性假设
为了保证数据安全性,本发明考虑两个方面,一是数据块放置位置的差异性,即不同数据块的存储位置的距离可以表示安全性高低,若数据块之间放置距离较大,则认为安全性较高,反之亦然。显然,数据块的存储距离越大,攻击者越难获取全部的数据,相应的安全性就会越高。考虑到不同用户对于数据的安全性需求不同,如财政、金融等数据通常对安全性要求较高,而音乐,电影等对安全性要求较低。本发明引入安全距离(security-distance)的概念,用k表示安全距离,若k=0,则表示用户对数据安全性没有要求,即可以将所有数据存储在一个存储节点上;若k=1,则表示任意两个数据块的存储距离必须大于1,存储距离即存储数据块的存储节点之间的最短距离;若k=2,则表示任意两个数据块的存储距离必须大于2;以此类推,本发明用fs来计算一个数据放置策略的安全距离,fs表示为:
fs=minfk(sdi,sdj),i≠j,i,j=1,2,...,|v|;
二是存储节点自身的保护能力,存储节点自身保护能力(spc)定义为下面几个安全参数的聚合值:
入侵检测系统(ids)能力值:即依照一定的安全策略,通过软、硬件,对网络、系统的运行状况进行监视,尽可能发现各种攻击企图、攻击行为或者攻击结果,以保证网络系统资源的机密性、完整性和可用性的能力。
反病毒(anti-virus)能力:保护系统不受各种计算机病毒入侵和损坏的能力。
防火墙(firewall)能力:控制外网接入,保护内网不受黑客入侵的能力。
认证(authentication)机制能力:为了保护系统安全而验证身份的能力。
上述三个安全参数取值范围均为[0,1],则存储节点自身保护能力可以用下面的公式表示:
spc=i+an+f+au;
其中,i表示入侵检测系统能力值,an表示反病毒能力值,f表示防火墙能力,au表示认证机制能力值。由于对以上三个能力值并没有一个统一的度量标准,并且在目前数据中心建设中这些安全措施都是必须考虑的,所以本发明假设所有的数据中心节点都具有上述四个安全措施。
1.3存取时间分析
在数据放置策略满足安全性条件之后,随之本发明考虑如何最小化数据存取时间。考虑一个满足安全距离为k的数据放置策略sd,即满足fs>k。且假设数据接入节点为a,则对于每个数据存储节点sdi≠0,i=1,2,...,|v|,从节点i到节点a的数据存取速度为:
其中,pi,a为节点i到节点a的最短路径,这里的最短路径是用数据传输速率来体现的,即给链路带宽矩阵b的每个元素取倒数构成新的矩阵b',然后利用迪杰斯特拉等最短路径算法找出节点间的最短路径。ls,ld为链路l的两个端点。
1.4问题公式化
基于上述分析,分布式云存储系统数据放置问题可以表述为:给定大小为d的数据和接入点a,选择合理的数据放置方法sd,使得sd在满足安全距离大于k的前提下最小化数据存取时间。则这个问题可用公式表示为:
sdi≤sci,i=1,2,...,|v|(3)
sdi≤sdmaxi=1,2,...,|v|(4)
fs=minfk(sdi,sdj)>k,i≠j,i,j=1,2,...,|v|(5)
式(2)表示存储的所有数据块之和等于原始数据大小;式(3)表示每个存储节点存储的数据块不大于存储节点的存储能力;式(4)为每个存储节点存放的数据块的大小不大于用户指定的数据块最大值,sdmax和d的大小初步决定了数据块的分块数量;式(5)为安全距离限制,即任意两个数据块的存储距离不小于k。
2、本发明的方法
2.1k-距离拓扑子图
由于数据存储有安全距离的限制,则需要在数据块放置之前找到一列满足安全距离要求的存储节点集,为了找到这样的节点集,本发明提出k-距离拓扑子图的概念。
定义1:(k-距离拓扑子集)设图g(v,e)是一个无向连通简单图,如果存在节点集合
通过k-距离拓扑子集的定义可知,图g(v,e)的k-距离拓扑子集v′即为满足安全距离限制的节点集合。为了找到图g(v,e)的k-距离拓扑子集,本发明提出了k-距离拓扑子集生成算法。
根据算法1可以看出,给定一个无向图g(v,e),首先选择一个节点v,然后寻找与此节点距离为k的节点vj,然后继续寻找与vj距离为k的节点,不断重复这个步骤直到遍历图g,最后找到的集合k-dis-set即为所求k距离拓扑子集。
根据算法1的描述,易知图g(v,e)的k-距离拓扑子集v′不唯一,如图2,考虑一个10个顶点的简单图g(v,e),选择不同的初始节点和中间节点会得到不同的k-距离拓扑子集,图2(b)为一个2-距离拓扑子集的表示图,节点集合为{2,4,7,9};图2(c)也是图g(v,e)的一个2-距离拓扑子集,节点集合为{1,3,5,6,8,10}。
2.2数据放置算法
由上述分析可知,本发明可将满足一定安全性的数据放置问题转化为给定安全距离k,在网络拓扑中寻找满足数据存取时间最小的k-距离拓扑子集的问题。由于无向图g的k距离拓扑子集不唯一,本发明提出一个基于节点优先级的算法,将节点按照单位数据存取速度(usp)从大到小的顺序排列,如果两个节点存取速度相同,则按照节点自身保护能力spc排列,在选择存储节点时,尽量选择优先级高的节点,可以保证高的数据存取速度。考虑到寻找k距离拓扑子集的算法复杂度为o(n2),本发明提出一个节点选择算法k-dds算法,使得在满足安全距离k的基础上最小化数据存取速度,并且算法复杂度低。
(1)单位数据存取速度(usp)
假设在无向图g中,数据接入点为节点a,则对于图中所有节点v,定义节点v到数据接入点a的单位数据存取速度为:
这里pv,a表示从节点v到节点a的最短路径,这个最短路径可以利用dijkstra算法或者spfa算法得到。
(2)数据存储节点选择算法
2.3复杂度分析
k-dds算法分为两部分,第一部分将节点按照单位存取时间排列,这部分算法的复杂度为o(v),其中v为节点数量。第二部分是根据dijkstra算法或者spfa算法来选择最优的节点序列,在这部分中,算法复杂度为o(vo(dijkstra))或者o(vo(spfa))。其中dijkstra算法的复杂度为o(e+vlgv),其中e为边的数量,spfa算法的复杂度为o(ke),k为每个节点进入queue的次数,这里k一般小于等于2。但spfa算法的适用范围较小,所以在某些情况下还是需要用dijkstra算法来取得节点之间的最短距离。所以k-dds算法的复杂度分为两种:在最好的情况下(可以使用spfa算法),算法复杂度为o(kve);在最坏的情况下(使用dijkstra算法),算法复杂度为o(ve+v2lgv)。
下面结合仿真对本发明的应用效果作详细的描述。
1、仿真环境
本发明通过omnet++[andrasv.omnet++communitysite.avalaible:http://www.omnetpp.org,2007]仿真平台和matlab仿真平台来验证k-dds算法的有效性,网络拓扑图分为随机拓扑和internet2[internet2,“internet2openscience,scholarship,andservicesexchange,”www.internet2.edu/products-services/advanced-networking/layer-2-services,2016,[online:accessed20-jan-2016]]拓扑两种网络拓扑结构,前者可以衡量数据存储算法在各种情况下的性能,后者可以衡量现实场景下各个数据存储算法的性能。仿真环境具体参数设定如下表:
internet2拓扑由36个节点组成,且各个节点之间的带宽均为1gbps。
为了与k-dds算法对比,本发明选择h.p.sajjad[h.p.sajjad,f.rahimian,andv.vlassov,"smartpartitioningofgeo-distributedresourcestoimprovecloudnetworkperformance,"inieeeinternationalconferenceoncloudnetworking(cloudnet'15),niagarafalls,canada,2015,pp.112-118]算法、fnf算法和q.xu[
q.xu,z.xu,andt.wang,"adata-placementstrategybasedongeneticalgorithmincloudcomputing,"internationaljournalofintelligencescience,vol.5,2015,pp.145-157]算法在数据存取时间上与k-dds算法做对比。其他三种算法介绍如下:
h.p.sajjad算法基于图分割理论,旨在减小数据存取时延和带宽消耗。
fnf算法采取最远距离存储,其安全性能最好。
q.xu算法采用遗传算法来放置数据,从而减小数据存取时间,性能较好,但算法复杂度较大。
2、仿真结果
(1)随机拓扑
随机环境下主要衡量随着数据量的增大数据存取时间的增加情况和随着网络规模的增加(节点数量增加)数据存取时间的减少情况。图3表明,在和其他三种算法的对比中可以发现,随着数据量的增加,k-dds算法的数据存取时间最小,相比其他算法数据存取时间减少了50%左右,并且数据存取时间增长缓慢,这是因为k-dds在满足安全性的要求下充分选择了链路状况好的节点,从而最小化数据存取时间。图4表明,随着网络规模(节点数量)的增加,k-dds相比其他算法数据存取时间仍然是最小的,相比其他算法,数据存取时间降低了60%~70%左右。这表明,k-dds算法在满足安全距离限制的条件下可以选择性能最好的节点存储数据,从而最小化数据存取时间。
(2)internet2拓扑
在internet2拓扑下主要衡量随着数据量的增长和安全距离的增长数据存取时间的增长情况。图5可以看出,在internet2拓扑中随着数据量大小的增加,数据存取速度均呈增长趋势,但k-dds的数据存取时间仍然最小,并且相较其他算法的数据存取时间降低了50%左右。由于internet2拓扑节点之间带宽均为1gbps,在数据量较小的时候q.xu算法和k-dds均选择了较近的节点,所以数据存取时间相同,但随着数据量的增多,当某些较近的节点存储满了之后,k-dds算法在寻找次最优节点上优于其他算法,所以随着数据量的越来越大,k-dds算法的性能越来越好。从图6中可以看出,随着安全距离的增加,k-dds的数据存取时间相比其他算法仍然会降低50%左右。
3、结果分析
从上面的仿真结果可以看出,在两种网络拓扑下,k-dds在数据存取时间上均小于其他三种算法。由于k-dds基于节点优先级寻找数据存储节点,所以在满足安全距离的约束下,k-dds算法总能选到最优的数据存储节点序列,从而最小化数据存取时间。
本发明考虑数据存取效率和数据安全性的数据存储方法,考虑到数据安全性,提出安全距离的概念,使得用户可以根据自身需要选择合适的安全距离。为了寻找合适的存储节点,通过在网络拓扑中寻找k-距离拓扑子图的方式选择合适的存储节点集合。仿真验证了算法在保证数据安全性的同时减小了数据存取时间。算法复杂度较低,比较适合部署在大规模云存储系统中。
在上述实施例中,可以全部或部分地通过软件、硬件、固件或者其任意组合来实现。当使用全部或部分地以计算机程序产品的形式实现,所述计算机程序产品包括一个或多个计算机指令。在计算机上加载或执行所述计算机程序指令时,全部或部分地产生按照本发明实施例所述的流程或功能。所述计算机可以是通用计算机、专用计算机、计算机网络、或者其他可编程装置。所述计算机指令可以存储在计算机可读存储介质中,或者从一个计算机可读存储介质向另一个计算机可读存储介质传输,例如,所述计算机指令可以从一个网站站点、计算机、服务器或数据中心通过有线(例如同轴电缆、光纤、数字用户线(dsl)或无线(例如红外、无线、微波等)方式向另一个网站站点、计算机、服务器或数据中心进行传输)。所述计算机可读取存储介质可以是计算机能够存取的任何可用介质或者是包含一个或多个可用介质集成的服务器、数据中心等数据存储设备。所述可用介质可以是磁性介质,(例如,软盘、硬盘、磁带)、光介质(例如,dvd)、或者半导体介质(例如固态硬盘solidstatedisk(ssd))等。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!