一种基于局部敏感哈希的近相似快速查找方法与流程
本发明涉及计算机算法,具体为一种基于局部敏感哈希的近相似快速查找方法。
背景技术:
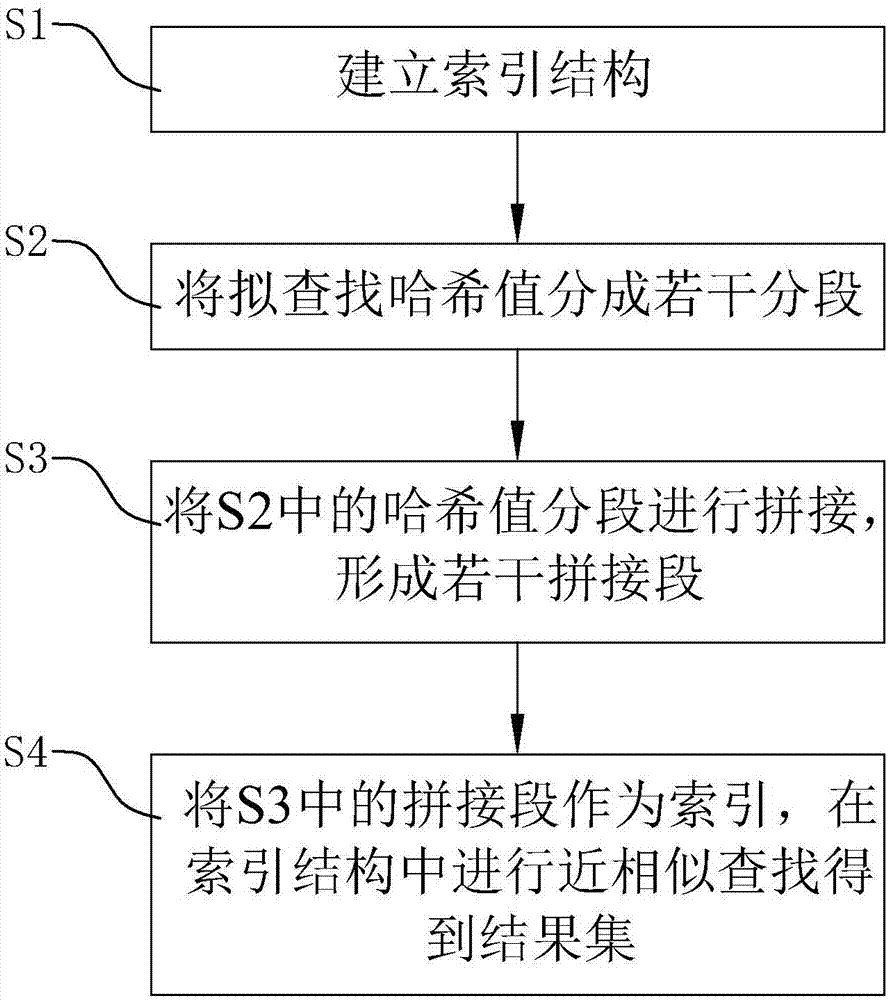
“局部敏感哈希”是一种针对海量高维数据的快速近相似查找算法。在信息检索,数据挖掘以及推荐系统等应用中,会面临着海量的高维数据查找近相似的需求。如果使用线性查找,对于高维、海量数据,就会变得非常耗时。为了解决这样的问题,人们设计了一种特殊的hash函数,使得两个相似度很高的数据以较高的概率映射成相同或相近的哈希值,而令两个相似度很低的数据以极低的概率映射成相同或相近的哈希值。这样的函数,叫做局部敏感哈希(lsh)。lsh最根本的作用,就是能高效处理海量高维数据的近相似问题。业界通常应用局部敏感哈希值分段建立索引的方法加快对海量高维数据进行近相似查找。分段算法中存在加速倍率、最大海明距离和最小相似度这几个主要衡量指标,其中,加速倍率=段内空间/索引段数,最大海明距离=分段数-1,最小相似度=(1-(最大海明距离/哈希比特位数))*100%。其中,海明距离用于评判两个哈希值之间的相似度。海明距离的计算方法是对两个比特数组按位进行异或计算,结果比特数组中1的个数即是两个输入比特数组间的海明距离。两个哈希值之间的海明距离越小,就越相似;反之,越不相似。最小相似度是分段算法的业务目标指标,即该算法可以在大多的“旷量”下进行近相似查找,最小相似度越低,说明可满足的业务场景越宽。以新闻标题的近相似查找为例。排除停用词后,新闻标题通常不会超过10个词。只要其中某个词发生变化,则由标题提取的局部敏感性哈希值从概率上讲就会发生约10%的变化,所以在上述应用场景中,最小相似度小于90%的算法才能符合业务要求。结合应用场景,可见上述分段算法有如下缺点:常见的分段算法不能同时兼顾最小相似度和时间开销。在分段数少的情况,最大海明距离小,使得最小相似度增大,最终导致得到的结果集范围偏小甚至结果集为空;但是如果增加分段数,虽然最大海明距离和最小相似度能够满足业务要求,但是相应的时间开销也会增大。技术实现要素:本发明的目的是为了提供一种基于局部敏感哈希的近相似快速查找方法,能够极大的增加索引值的段内空间,在满足业务需求的最小相似度的基础上能够获得足够的加倍速率,以及在可接受的空间开销增长条件下换取时间开销的极大减少。为了实现上述发明目的,本发明采用了以下技术方案:一种基于局部敏感哈希的近相似快速查找方法,包含如下步骤:s1:建立索引结构;s2:将拟查找哈希值分成若干分段;s3:将s2中的哈希值分段进行拼接,形成若干拼接段;s4:将s3中的拼接段作为索引,在索引结构中进行近相似查找得到结果集。优选的,为了适应上述s3和s4中的查找步骤中的分段方法,使得查找过程更加方便,所述步骤s1:建立索引结构包括:s101:将拟构建索引结构的多个哈希值均分成若干分段;s102:将s101中每个哈希值对应的分段进行拼接,形成若干拼接段;s103:将s102中相同的拼接段所对应的哈希值添加到同一映射列表中;s104:s103中不同的映射列表组成完整的索引结构。优选的,所述步骤s4中在索引结构中进行近相似查找得到结果集,包括:s401:在索引结构的若干映射列表中找到与s102所述的拼接段形成映射的映射列表;s402:遍历s401中该映射列表中的哈希值,判断该映射列表中是否有与待查找哈希值之间的相似度符合相似度标准的哈希值,若有,则将该符合相似度标准的哈希值加入结果集中。优选的,所述s101中的构建索引结构的哈希值的分段方式与s2中拟查找的哈希值的分段方式相同。优选的,每个哈希值均匀分段,每个分段的长度相同,使得在分段拼接过后的查找过程中,优选的,在对分段进行拼接时,从同一哈希值的不同分段中任取两段进行拼接,形成若干拼接段。优选的,采用海明距离判断哈希值之间的相似度。与现有技术相比,采用了上述技术方案的基于局部敏感哈希的近相似快速查找方法,具有如下有益效果:一、采用本发明的基于局部敏感哈希的近相似快速查找方法,将两个哈希分段进行拼接后,极大地增加了索引值的空间,同时相比较于原始分段算法,获得了足够的加速倍率。二、相较于传统的传统方法和分段算法,本发明的分段拼接算法能够兼顾最小相似度和加速倍率,能够满足不同的业务要求。附图说明图1为本发明基于局部敏感哈希的近相似快速查找方法实施例的流程图;图2为本实施例中步骤s1的流程图;图3为本实施例中步骤s4的流程图;图4为本实施例中索引机构建立的流程图;图5为本实施例中查找特定哈希值的流程图。具体实施方式下面结合附图对本发明做进一步描述。如图1至3所示的基于局部敏感哈希的近相似快速查找方法,包括如下步骤:s1、建立索引结构:将需要建立索引结构的多个哈希值全部进行分段,每个哈希值分成多段。从一个哈希值的多个分段中取出部分分段进行拼接,形成若干的拼接段。对拼接段进行映射,具有相同映射的拼接段所对应的哈希值添加到同一映射列表中,索引结构由不同的映射列表组成。s2、将拟查找的哈希值以与上述s1中哈希值的分段方法相同的分段方法进行分段,分成若干分段。s3、将步骤s2中的分段进行拼接形成拟查找哈希值所对应的若干拼接段。s4、在索引结构中的多个映射列表中找到与步骤s3中的拼接段映射的某个映射列表,并将拟查找的哈希值与该映射列表中包含的构建成索引结构的哈希值进行相近似查找,当两个哈希值的相似度符合业务要求的相似度时,将映射列表中的这个哈希值加入到结果集中。图4为本实施例中利用分段拼接算法建立索引结构的流程图,图5为本实施例中在索引结构中使用分段拼接算法进行近相似查找的流程图。下面以64比特位哈希值建立索引结构和64比特位的拟查找哈希值为例,结合图4和图5对本发明的快速查找方法进一步说明:假定构建索引结构的哈希值为n个,当两个哈希值之间的海明距离小于等于7时两个哈希值近相似,则要在索引结构中查找到与拟查找的哈希值符合近似程度的所有哈希值,构成一个结果集。使用不分段的线性查找时,将该拟查找哈希值与索引结构中的所有哈希值依次进行海明距离计算后得到结果集,此方法所用的空间开销为n,时间开销也为n。当使用传统的线性查找时,定义将64比特位的哈希值均分为8分段,那么使用8分段的分段算法所对应的空间开销为8n。此时,线性查找只发生在段内映射列表中,映射列表集合的平均大小为n/s8,其中s8为该索引值的可能空间大小,s8=28=256,所以此分段算法中的时间开销为8n/s8,分段算法的查找速度是线性查找的s8/8倍,即32倍,此时该分段算法的最小相似度=(1-(最大海明距离/哈希比特位数))*100%=89.06%。显然,面对最小相似度符合业务要求的情况下,分段算法相对线性查找的加速倍率严重不足。其中,上述加速倍率为线性查找的时间开销与相应方法的时间开销之比。如图4所示,逐个将n个待构建的64比特位的哈希值构建为索引结构。将n中的一个哈希值均分为8分段,每个分段为8个比特位。将8个分段两两拼接形成16比特位的拼接段。如果枚举,那每个哈希值分别会有28个拼接段按照拼接段,寻找对应的映射列表,如果找到了对应的映射列表,则将该拼接段对应的哈希值加入到该映射列表中;如果没有找到对应的映射列表,则建立一个新的空映射列表,并将该拼接段对应的哈希值放入该空映射列表中。一个哈希值对应的拼接段都进行过查找映射列表后,对下一个哈希值进行分段到加入映射列表的处理,直到所有的哈希值全部处理完毕后,结束索引结构的建立。最终,索引结构中包含有多个映射列表。如图5所示,将待查找的64位哈希值进行分段,分段方式与构建索引结构的分段方式相同,分成8分段,每个分段为8比特位。将8个分段两两拼接形成若干16比特位的拼接段,以新形成的拼接段为索引,找到索引结构中对应的映射列表,并遍历该映射列表中所有哈希值,比较拟查找哈希值和映射列表中哈希值的相似度,将海明距离小于等于6的哈希值加入到查找到的结果集中。当该拼接段对应的映射列表中的哈希值都比较完成后,对下一拼接段进行相同的对应的映射列表的查找,直到所有拼接段都处理后,结束查找,得到最终近相似查找的结果集。在利用本实施例中的上述方法进行查找时,原始的分段值空间大小和上述传统分段算法的分段值空间大小相同为28=256,将分段进行两两拼接后,空间大小为s16=216=(28)2=(s8)2,显然,任意等长的两个原始分段进行拼接后,空间大小变成原来的平方倍。使用本方法进行查找时,空间开销为28n,时间开销为28n/s16。相比传统分段算法,本方法的加速倍率为线性查找的216/28=2340倍。当然,由于在拼接分段中,利用了两段进行了索引查找,使得本方法相对于原分段算法,最大海明距离会小1。相比于线性查找和传统分段查找,针对上述64比特位分8段哈希值查找中,本方法能够以适度的空间开销增加和极小的海明距离损失为代价极大地提高查找速度。对上述实施例的前提下线性查找、传统分段算法查找和本发明方法的空间开销和时间开销如表1所示,在64比特位哈希值均匀分成8段并两两进行拼接时,本方法在可接受的空间开销内,极大的增加查找速度。表1:空间开销和时间开销对比表线性查找分段算法本发明方法空间开销n8n28n时间开销nn/32n/2340利用同样的分段和拼接方法对不同比特位的哈希值进行分段拼接后,得到的结果如表2中所示,表2中的加速倍率为线性查找的时间开销与相应方法的时间开销之比。从表2中可以得出,此方法能够很好的应用在分段算法中以提高查找速度。其中,分段算法中没有进行拼接,可以查找到的最大海明距离=原分段数-1,但是对于本近相似快速查找方法的分段之间进行两两拼接的实施例来说,在索引构建和拟查找哈希值分段和拼接方式完全一样的前提下,必须保证有两个分段之间是完全相同,这样才能保证在进行拼接后至少有一个拼接段是相同的。所以,在采用本发明方法进行查找时,所能达到的最大海明距离=原始分段数-拼接段内包含的原始分段数。表2中以两两拼接形成拼接段为例,则最大海明距离=原始分段数-2。表2:不同位数和分段数的查找算法的加速倍率对比表(两两分段拼接)在运用本发明的方法进行近相似快速查找时,不局限于上述例子中的哈希位数和分段方法以及拼接方式。且在实际运用中,也不一定应用于分段算法中,也可能会应用于层次分段算法或其他能够运用此方法实现提高加速倍率的算法中。以上所述是本发明的优选实施方式,对于本领域的普通技术人员来说不脱离本发明原理的前提下,还可以做出若干变型和改进,这些也应视为本发明的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1