一种短信聚类方法及装置与流程
本发明涉及数据分类领域,具体涉及一种短信聚类方法及装置。
背景技术
在信息时代的今天,智能手机的广泛普及,各种社交应用的火热。随之,我们的手机绑定了银行、电力、生活、互联网购物网站等的账户。通知类短信便成为了人们生活的一部分,一方面,人们可以更加透明的了解自己的账户信息,另一方面,通知类短信夹杂的繁多营销广告苦恼着手机用户。短信聚类,能够将通知短信进行合理聚类,方便用户管理以及挖掘有价值的信息,可以有效的解决人们的苦恼问题。
对于短信来说,短信本身和长文本不一样,它具有独特的特征,如字数少,表达简洁、缺乏丰富的上下文信息,包含的信息量有限,这使得短信的特征稀疏,很难准确的抽取有效的文档特征,加之传统的文本聚类方法直接在短信上使用的效果不佳,因此,这对短信的聚类研究带来了更多的挑战,同时也导致短信聚类技术的发展相对缓慢。目前,针对短信的文本聚类存在着诸多缺点:
对于短信而言,尤其是在问答系统中,每个样本(问题)的特征较少,如果使用向量空间模型中的思想,每个样本构建的特征向量会很长;其次,如果使用传统的长文本聚类方法,在计算两个问题之间的相似性时,往往要依赖于文档之间词形相似性。这种方法没有考虑到在一个问题样本中,往往会有一个或者几个关键词,这些关键词都具有很强的鉴别能力。如果没有考虑到关键词的权重,而只是匹配相同词的个数的话,那么聚类的时候往往会出错。
技术实现要素:
为克服现有技术中存在的缺陷,本发明提供一种短信聚类方法和装置。
本发明的技术方案如下:
一种基于文本结构的短信聚类方法,包括以下步骤:
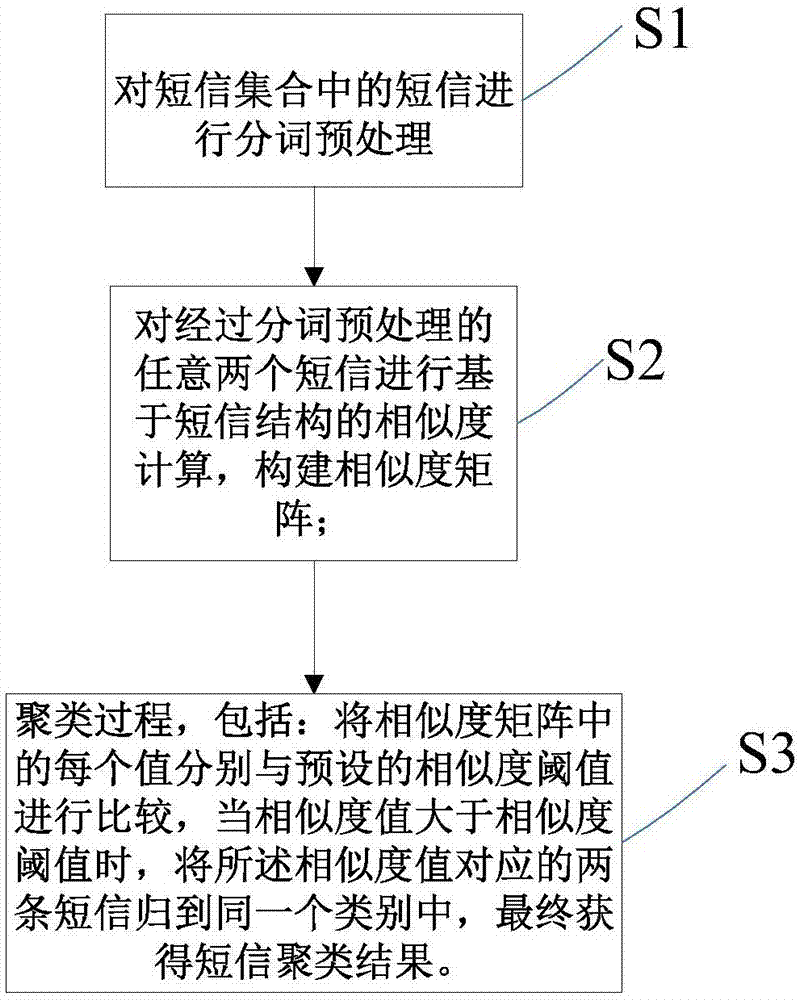
s1:对短信集合中的短信进行分词预处理;
s2:对经过分词预处理的任意两个短信进行基于短信结构的相似度计算,构建相似度矩阵;
s3:聚类过程,包括:将相似度矩阵中的每个值分别与预设的相似度阈值进行比较,当相似度值大于相似度阈值时,将所述相似度值对应的两条短信归到同一个类别中,最终获得短信聚类结果。
其中,上述步骤s3中还包括:
结构传递快速聚类,包括,当相似度矩阵中的相似度值大于相似度阈值时,将所述相似度值对应的短信分别与类别集合中包含的每个类集合进行比较,若类集合含有该相似度值对应的短信中的任一条,将所述相似度值对应的短信归入到所述类集合中;
当其中一条短信属于多个类集合,将所述多个类集合进行合并。
其中,上述步骤s2中任意两个短信的相似度计算步骤具体为:
对分词处理后的短信中的每个词根据位置信息公式计算出位置信息;
对两条短信间相同的词分别进行位置信息的距离比较,若所述距离比较结果小于预设的容忍度,将相似度单元值叠加上一固定的数值;
利用预设的相似度公式计算出两条短信的相似度。
其中,上述位置信息计算公式为:
p(s[i]0)=1/len(s[i])
其中,p(s[i]0)为第i条短信分词后第0个词的位置信息,len(s[i]为第i条短信分词后的词数。
其中,上述步骤中预设的相似度计算公式为:
p(i,j)=count/(len(s[i])+(len(s[j]))
其中,p(i,j)为第i条短信和第j条短信的相似度;count为相似度单元数值,len(s[i]为第i条短信分词后的词数,s[j]为第j条短信分词后的词数。
其中,上述步骤s1中的短信分词前,去除短信中包含的数字。
其中,上述步骤s3之前包括以下步骤:将相似度矩阵中对称的元素删除。
一种短信聚类装置,其特征在于:包括:
分词模块,用于对短信集合中的短信进行分词预处理;
矩阵构建模块,用于对经过分词预处理的任意两个短信进行基于短信结构的相似度计算,构建相似度矩阵;
聚类模块,用于将相似度矩阵中的每个值与预设的相似度阈值进行比较,当相似度值大于相似度阈值时,将相对应的两条短信归到同一个类别集合中,最终获得短信聚类结果。
其中,包括:
结构传递快速聚类子模块,用于当相似度矩阵中的相似度值大于相似度阈值时,将所述相似度值对应的短信分别与类别集合中包含的每个类集合进行比较,若类集合含有该相似度值对应的短信中的任一条,将所述相似度值对应的短信归入到所述类集合中;
当其中一条短信属于多个类集合,将所述多个类集合进行合并。
一种终端,包括:处理器;
用于存储处理器可执行指令的存储器:
其中,所述处理器被配置为:
对短信集合中的短信进行分词预处理;
对经过分词预处理的任意两个短信进行基于短信结构的相似度计算,构建相似度矩阵;
聚类过程,包括:将相似度矩阵中的每个值与预设的相似度阈值进行比较,当相似度值大于相似度阈值时,将相对应的两条短信归到同一个类别集合中,最终获得短信聚类结果。
本发明与现有技术相比,具有如下有益效果:
本发明的短信聚类方法,对短信间的距离的度量采用基于文本结构的相似度计算,能够在特征词稀疏情况下,较为精准判断结构一致性;在聚类过程中采用结构传递方法实现快速聚类,逐个扫描样本,每个样本依据其与已扫描过的样本的距离,被归为已有的类,或生成一个新类;再依据相似传递性,对各类集合间进行合并,以此提高聚类效率。
附图说明
图1为本发明一实施例的短信聚类方法流程图;
图2为图1中步骤s2的流程图;
图3为图1中步骤s1短信分词后的短信机构;
图4为相似度矩阵的结构图;
图5为实施例中相似度计算流程图;
图6为一实施例短信聚类装置的结构框图。
具体实施方式
以下结合附图对本发明作进一步的说明。
图1示出了一种基于文本结构的短信聚类方法的一种实施例,如图1所示,该方法可以包括以下步骤。
s1:对短信集合中的短信进行分词预处理;将每条短信分词获取的词组按照短信原有的语句结构排序,这样每条短信变成由多个词组成。
s2:对经过分词预处理的任意两个短信进行基于短信结构的相似度计算,构建相似度矩阵;
s3:聚类过程,包括:将相似度矩阵中的每个值分别与预设的相似度阈值进行比较,当相似度值大于相似度阈值时,将两条短信判定为结构一致,将所述相似度值对应的两条短信归到同一个类别中,最终获得短信聚类结果。
一般情况下短信规模庞大、由于短信内容有限导致个体特征稀疏,常规的文本聚类算法大多在分词过程中舍弃停用词。本方法中,使用场景为短信,基于短信文本内容有限前提下,不舍弃停用词,以保证短信的结构完整。同时在分词过程中,对出现的数字进行去干扰处理。
1)假设短信条数总计为k,短信集合表示为m,设定m[0]为第0条短信,m[1]为第1条短信。以此短信可以表示为m[0],m[1],m[2]…m[i],i<=k。
2)对每条短信分词处理后。短信集合表示为s,设定s[0]为第一条分词处理后短信,s[1]为第二条分词处理后短信。以此短信分词处理后可以表示为s[0],s[1],s[2]…s[i],i<=k。
分词处理结束后,s[i]结构如图3所示,由若干个词组成,其按照短信原有的语句结构进行排列,len(s[i])表示分词处理后包含词的个数。
在本公开的一实施例中,上述步骤s2的具体过程如下。
短信集合中第i条短信和第j条短信s[i]与s[j]相似度的计算方法原理:如果两个短信
中出现了相同的词,并且词的位置相似,其命名相似单元,两个短信中,相似单元与两
个短信词汇总和比重越高,相似度越高。参见图5,具体流程如下:
(i)设置全局变量count=0,flag=0,误差容忍度ft。其中,s[i]k1为,第i条短信第k1个词,,s[j]k2为,第j条短信第k2个词,
(ii)(ii)取s[i]0计算p(s[i]0)=1/len(s[i]),在这里p(s[i]0)设定为短信的位置信息,即s[i]0在短信中的结构信息。
(iii)若s[i]0与s[j]0同词。计算|p(s[i]0)-p(s[j]0)|,与ft比较,
若|p(s[i]0)-p(s[j]0)|<ft,count=count+2;flag=1,执行(iv);
若s[i]0与s[j]1同词。计算|p(s[i]0)-p(s[j]1)|,与ft比较;
若|p(s[i]0)-p(s[j]1)|<ft,count=count+2;flag=1,执行(iv);
若s[i]0与s[j]2同词。计算|p(s[i]0)p(s[j]2)|,与ft比较,
若|p(s[i]0)-p(s[j]2)|<ft,count=count+2;flag=1,执行(iv);
若s[i]0与s[j]n同词。计算|p(s[i]0)-p(s[j]n)|,与ft比较,
若|p(s[i]0)-p(s[j]n)|>ft,flag=0,执行(iv)
(iv)同理,依次取s[i]1,s[i]2…,执行(ii),(iii)。
通过这种方法,最终如图5所示,生成p(i,j)=count/(len(s[i])+(len(s[j]))。
生成的相似度矩阵即:p(0,0)为第0条短信和第0条短信相似度、p(0,1)为第0条短信和第1条短信相似度,以次类推。
在本公开的一实施例中,上述步骤s3的短信聚类过程如下。
聚类结果的类集合用c表示,初始值为空。c0,c1,c2,ci,表示第0类,第1类,第2类,第i类;例如,c0=[0,3,5],表示,第0条,第3条,第5条短信属于第0类。
对相似度矩阵的说明,相似度矩阵具有对称特性,如图4所示,p(i,j)=p(j,i),只需要分析对角线一侧即可。即将p(1,0)、p(2,0)、p(2,1)、p(3,0)、p(3,1)、p(3,2)直到p(k,k-2)、p(k,k-1)。相似度矩阵中的每个值依次作为聚类函数的参数,进行聚类计算;
相似度矩阵具有传递性,如果a和b相似,b和c相似,则a和c相似。
利用结构传递性进行快速聚类,包括,当相似度矩阵中的相似度值大于相似度阈值时,将所述相似度值对应的短信分别与类别集合中包含的每个类集合进行比较,若类集合中含有该相似度值对应的短信中的任一条,将所述相似度值对应的短信归入到所述类集合中;
当其中一条短信属于多个类集合,将所述多个类集合进行合并。
在本公开的一实施例中,聚类函数的分析逻辑如下:
情况1:如果len(c)=0,且c0=[];
若p(i,j)>th(相似度阈值),则c0=[i,j]。否则c不变。
情况2:如果len(c)=1,且c0=[a1,a2]。
若p(i,j)>th且c0中元素包含i或j,则i,j和c0同类,i,j加入c0;
若p(i,j)>th且c0中元素步不包含i或j,则i,j和c0不同类,i,j生成新c1,即c1=[i,j]
若p(i,j)<th,c不变。
情况3:如果q=len(c)>1,且c0=[a1,a2…],c1=[b1,b2,…],c2=[c1,c2,…],…cq-1
若p(i,j)>th且c0,c1,c2等元素中均不含i或j,则i,j生成新类cq,i,j加入cq;
若p(i,j)>th且c0,c1,c2等元素中仅有cq一个含有i或j,则i,j属于该cq,i,j加入cq;
若p(i,j)>th且c0,c1,c2等元素中有cq,cp含i或j,则i,j属于类cq,、cp,由于i,j出现在两个类中,cq、cp合并为一类;
若p(i,j)<th,c不变。
其中,len(c)为类集合的长度,th为相似度阈值,p(i,j)为第i条短信和第j条短信的相似度。
以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!