一种基于时序关联规则的交通拥堵预测方法与流程
本发明涉及智能交通系统
技术领域:
,特别涉及一种基于时序关联规则的交通拥堵预测方法。
背景技术:
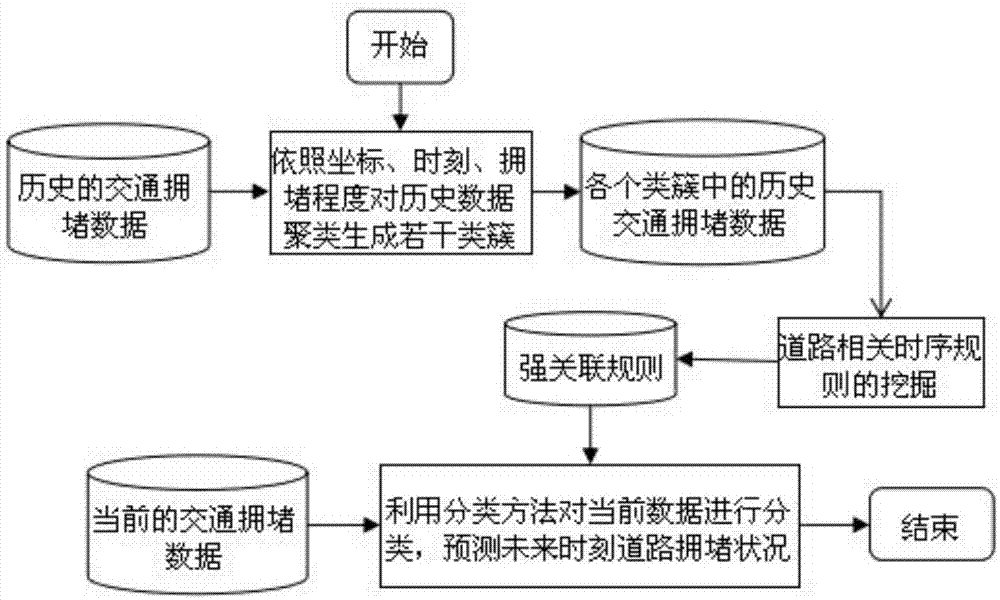
随着我国经济的快速发展,城市规模迅速扩大,城市人口大幅增长,社会活动逐渐增多,交通需求量迅速上升,交通拥堵带来的环境污染,引发的交通事故急剧增加,城市交通拥堵问题亟待解决,因此,设计合理的拥堵预测模型成为交通管理部门研究的热点内容。现有的交通预测方法众多,各有优缺点。大多数算法是建立在数学模型的基础上,只能够简单的预测单个时刻或者固定路段的拥堵,而在实际智能交通系统的拥堵预测问题中,路段之间的拥堵有一定的相关性,而且预测拥堵有考虑时序性的必要。因此道路的相关时序规则显得尤为重要。技术实现要素:针对现有技术存在的问题,本发明充分利用历史交通数据信息,实现复用重要信息,并根据历史交通数据,挖掘道路之间的时序关联规则,可以灵活控制道路相关性规则的时间间隔,使挖掘的时序关联规则结果更具有实际意义,从而使得交通拥堵预测更有实际的价值,提高了交通拥堵预测的精度。为了实现上述目的,本发明提供了一种基于时序关联规则的交通拥堵预测方法,包括以下步骤:步骤1、将原始的历史交通数据信息离散化;交通信息中心根据地理信息库中的路网信息和采集到的各道路不同时刻行驶的车辆数量,将每条道路的拥堵状态离散化处理转化为拥堵程度并存入mysql数据库中;步骤2、交通信息中心根据数据库内的交通信息以及路网信息提取出道路发生交通拥堵的时间、空间信息作为历史交通拥堵数据集,通过使用dbscan聚类方法将历史交通拥堵数据集进行划分,产生若干个类簇;根据道路的时空相关性,利用dbscan聚类方法进行时空聚类,将历史交通拥堵数据集划分为若干个簇,每个类簇中包含的信息即是路段关联性大、时间间隔近的交通拥堵数据;对交通路网中的历史交通拥堵事件,计算各条道路之间的时空相关性,公式如下所示:其中,x=(xp,yp)为拥堵事件p对应的坐标值,y=(xq,yq)为拥堵事件q对应的坐标值,tp和tq分别为拥堵事件p和拥堵事件q发生拥堵对应的时间值,cp和cq分别为拥堵事件p和拥堵事件q发生拥堵的程度,a、b、c均为大于0小于1的实数,代表权重值,cmax代表拥堵程度的最大差异值,dmax为拥堵数据集对应的空间距离最大值;步骤3、设计时序关联规则方法对每个类簇分别进行相关时序规则的挖掘,具体设计过程包括以下步骤:步骤3.1、采用遗传算法,设置进化代数计数器g以及最大进化次数,并通过染色体编码方式产生初始种群;步骤3.2、根据交叉概率来判断种群中染色体是否发生交叉,若发生交叉,则两个父代的染色体会交叉生成一个子代染色体;步骤3.3、根据变异概率来判断种群中染色体是否发生变异,若发生变异,则一个父代的染色体会变异生成一个子代染色体;步骤3.4、将个体对应的染色体解码得到的每个规则与数据库中对应的实际交通拥堵信息进行匹配,计算其支持度和置信度,所述规则的支持度support和置信度confidence计算公式如下所示:式中,a为规则前提,b为规则结论。n为数据集合t内所包含的记录数,μa(a)为数据集合t中规则前提a出现的次数,μab(ab)为数据集合t中规则前提a和结论b同时出现的次数;且种群中对应的染色体适应度评价值计算公式如下所示:其中,chromosome为种群中的染色体,r为挖掘获得的某条规则,r为染色体解析得到的所有规则的集合,x2(r)表示规则r的卡方值,recovered表示规则r的新颖程度,如果规则r在原先得到的规则中不存在,其recovered值设置为某一定值,并将规则r作为一条新规则,如果规则r在原先得到的规则中存在,则recovered值取0;在进化的过程中,保留满足设定阈值的时序规则,同时计算每个个体的适应度值;步骤3.5、利用轮盘赌方法从当代种群的父代个体和子代个体中选择个体遗传到下一代种群中;步骤3.6、根据g值判断是否达到最大进化次数,若达到最大进化次数,则结束运算,没有达到最大进化次数,则重新执行步骤3.2至步骤3.5,直到达到最大进化次数;步骤3.7、结束运算后,将规则的支持度support和置信度confidence满足以下条件的关联规则作为强时序关联规则:support>supminconfidence>confmin式中,supmin和confmin分别表示定义的最小支持度阈值和置信度阈值;步骤4、交通信息中心根据获得的强时序关联规则,利用classificationbasedonassociation分类方法,简称cba分类方法,来预测道路交通拥堵,具体实现过程包括以下步骤:步骤4.1、对于步骤3中不同类簇中挖掘产生的强时序关联规则,每条规则均包括支持度和置信度两个属性,利用规则优先级次序对规则进行降序排列;步骤4.2、在交通信息中心的历史拥堵数据集中,利用降序排列的每条规则对历史拥堵数据集进行检测,如果规则能够至少正确分类一个样本数据,则该规则就作为一个潜在分类器规则,否则该规则不会加入到分类器中;步骤4.3、从历史拥堵数据集中移除满足步骤4.2条件的数据;步骤4.4、重复步骤4.2至步骤4.3,直到所有降序排列规则或者历史拥堵数据集被全部检测完毕,完成对分类器的构建;步骤4.5、利用构建的分类器来预测未来时刻的交通拥堵状态。所述步骤2中所述的提取的道路发生交通拥堵的时间、空间信息包括道路编号ai、道路发生拥堵空间坐标(x,y)、道路发生拥堵时间time和道路拥堵程度congestionlevel。所述步骤3.2中所述的交叉实现过程如下:上层属性交叉:子代染色体的每一位上层属性随机从父代染色体的对应位置中选择一位遗传;下层属性的交叉:定义下层属性等于2的个数为x个,等于1的个数为y个,记录父代染色体下层属性为2的位置,子代染色体下层属性从这些位置中随机选择x位置为2,记录父代染色体下层属性为1的位置,若子代染色体对应下层属性已经为2,则在其剩余位置中随机选择y位置为1。所述步骤3.3中所述的变异实现过程如下:上层属性的变异,子代染色体的每一位上层属性突变为不等于父代染色体的其他属性;下层属性的变异,定义下层属性等于2的个数为x个,等于1的个数为y个,记录父代染色体下层属性为2和1的位置,子代染色体的下层属性排除这些位置,从剩余位置中随机选择x位突变为2,y位突变为1。所述步骤4.1中所述的规则优先级次序定义如下:给定两个规则r1和r2;设r1.confidence>r2.confidence,则此时规则r1的优先级高于规则r2;设r1.confidence=r2.confidence且r1.support>r2.support,则此时规则r1的优先级高于规则r2;设r1.confidence=r2.confidence且r1.support=r2.support,但是规则r1早于规则r2出现,此时规则r1的优先级高于规则r2。本发明的有益效果:本发明利用历史交通拥堵数据集进行相关性聚类,综合考虑时间信息和空间信息,产生路段关联性大和时间间隔近的类簇,提高了预测的准确度,同时本发明根据历史交通数据集,挖掘道路之间的时序关联规则,可以灵活控制道路相关性规则的时间间隔,使挖掘的时序关联规则结果更具有实际意义,从而使得交通拥堵预测更有实际的价值。附图说明图1为本发明的基于时序关联规则的交通拥堵预测方法中进行交通拥堵预测的总体流程图。具体实施方式本发明是一种基于时序关联规则的交通拥堵预测方法,包括以下步骤,如图1所示:步骤1、将原始的历史交通数据信息离散化;交通信息中心根据地理信息库中的路网信息和采集到的各道路不同时刻行驶的车辆数量,将每条道路的拥堵状态离散化处理转化为拥堵程度并存入mysql数据库中,代表不同道路在不同时刻对应的拥堵状态,所述mysql数据库信息样例如表1所示。表1mysql数据库信息样例timea1a2a3a4a5a6a7a8a91272013111113312840331111333129602333111131308012112123313200131121121133201212311321344023113313213560132133321136802321331111380032231211113920133111231所述路网信息包括道路长度和路网拓扑结构,而车辆密度是评价道路拥堵程度的重要依据,所述车辆密度计算公式如下:其中,n为道路车辆数量,1为车辆平均长度,s为车辆之间的空间距离,l表示道路的长度;道路的交通拥堵状态用1到3之间的数字量化表示,1表示道路畅通,2表示道路中度拥堵,3表示道路严重拥堵,定义道路拥堵级别判断标准如表2所示。表2拥堵等级划分标准拥堵状况拥堵密度拥堵等级不拥堵<0.21中度拥堵[0.2,0.6]2严重拥堵>0.63步骤2、交通信息中心根据数据库内的交通信息以及路网信息提取出道路发生交通拥堵的时间、空间信息作为历史交通拥堵数据集,通过使用density-basedspatialclusteringofapplicationswithnoise聚类方法,简称dbscan聚类,将历史交通拥堵数据集进行划分,产生若干个类簇,所述提取的道路发生交通拥堵的时间、空间信息包括为道路编号ai、道路发生拥堵空间坐标(x,y)、道路发生拥堵时间time和道路拥堵程度congestionlevel;根据道路的时空相关性,利用dbscan聚类方法进行时空聚类,将历史交通拥堵数据集划分为若干个簇,每个类簇中包含的信息即是路段关联性大、时间间隔近的交通拥堵数据;对交通路网中的历史交通拥堵事件,计算各条道路之间的时空相关性,公式如下所示:其中,x=(xp,yp)为拥堵事件p对应的坐标值,y=(xq,yq)为拥堵事件q对应的坐标值,tp和tq分别为拥堵事件p和拥堵事件q发生拥堵对应的时间值,cp和cq分别为拥堵事件p和拥堵事件q发生拥堵的程度,a、b、c均为大于0小于1的实数,代表权重值,cmax代表拥堵程度的最大差异值,dmax为拥堵数据集对应的空间距离最大值,因时空距离的公式综合了多方面因素,而各因素的数据单位不一致,因此采用归一化处理的方式,解决具有不同意义的输入变量不能平等使用的问题;步骤3、设计时序关联规则方法对每个类簇分别进行相关时序规则的挖掘,具体设计过程包括以下步骤:步骤3.1、采用遗传算法,设置进化代数计数器g以及最大进化次数,并通过染色体编码方式产生初始种群;所述染色体的结构包括上下两层:上层代表道路拥堵程度,下层代表上层属性的类型,定义的取值有0,1,2三种情况。其中,0代表上层属性所代表的道路拥堵状况不属于规则,1代表上层属性所代表的拥堵状况属于规则前提,2代表上层属性所代表的拥堵状况属于规则结论,这样定义有利于实现后续时序关联规则的挖掘;步骤3.2、根据交叉概率来判断种群中染色体是否发生交叉,若发生交叉,则两个父代的染色体会交叉生成一个子代染色体,其中种群中每个个体定义[0,1]的随机数,而小于交叉概率pc=0.9的两个个体进行交叉产生一个个体,交叉实现过程如下:步骤3.2.1、上层属性交叉:子代染色体的每一位上层属性随机从父代染色体的对应位置中选择一位遗传;步骤3.2.2、下层属性的交叉:定义下层属性等于2的个数为x个,等于1的个数为y个,记录父代染色体下层属性为2的位置,子代染色体下层属性从这些位置中随机选择x位置为2,记录父代染色体下层属性为1的位置,若子代染色体对应下层属性已经为2,则在其剩余位置中随机选择y位置为1;步骤3.3、根据变异概率来判断种群中染色体是否发生变异,若发生变异,则一个父代的染色体会变异生成一个子代染色体,其中种群中每个个体定义[0,1]的随机数,而小于变异概率pm=0.8的个体通过变异操作产生一个子代个体,变异实现过程如下:步骤3.3.1、上层属性的变异,子代染色体的每一位上层属性突变为不等于父代染色体的其他属性;步骤3.3.2、下层属性的变异,定义下层属性等于2的个数为x个,等于1的个数为y个,记录父代染色体下层属性为2和1的位置,子代染色体的下层属性排除这些位置,从剩余位置中随机选择x位突变为2,y位突变为1;步骤3.4、将个体对应的染色体解码得到的每个规则与数据库中对应的实际交通拥堵信息进行匹配,计算其支持度和置信度,所述规则的支持度support和置信度confidence计算公式如下所示:式中,a为规则前提,b为规则结论。n为数据集合t内所包含的记录数,μa(a)为数据集合t中规则前提a出现的次数,μab(ab)为数据集合t中规则前提a和结论b同时出现的次数;且种群中对应的染色体适应度评价值计算公式如下所示:其中,chromosome为种群中的染色体,r为挖掘获得的某条规则,r为染色体解析得到的所有规则的集合,x2(r)表示规则r的卡方值,recovered表示规则r的新颖程度,如果规则r在原先得到的规则中不存在,其recovered值设置为某一定值,并将规则r作为一条新规则,如果规则r在原先得到的规则中存在,则recovered值取0;在进化的过程中,保留满足设定阈值的时序规则,同时计算每个个体的适应度值;步骤3.5、利用轮盘赌方法从当代种群的父代个体和子代个体中选择个体遗传到下一代种群中;步骤3.6、根据g值判断是否达到最大进化次数,若达到最大进化次数,则结束运算,没有达到最大进化次数,则重新执行步骤3.2至步骤3.5,直到达到最大进化次数;步骤3.7、结束运算后,将规则的支持度support和置信度confidence满足以下条件的关联规则作为强时序关联规则:support>supminconfidence>confmin式中,supmin和confmin分别表示定义的最小支持度阈值和置信度阈值;步骤4、交通信息中心根据获得的强时序关联规则,利用cba分类方法预测道路交通拥堵,具体实现过程包括以下步骤:步骤4.1、对于步骤3中不同类簇中挖掘产生的强时序关联规则,每条规则均包括支持度和置信度两个属性,利用规则优先级次序对规则进行降序排列;所述步骤4.1中所述的规则优先级次序定义如下:给定两个规则r1和r2;设r1.confidence>r2.confidence,则此时规则r1的优先级高于规则r2;设r1.confidence=r2.confidence且r1.support>r2.support,则此时规则r1的优先级高于规则r2;设r1.confidence=r2.confidence且r1.support=r2.support,但是规则r1早于规则r2出现,此时规则r1的优先级高于规则r2;步骤4.2、在交通信息中心的历史拥堵数据集中,利用降序排列的每条规则对历史拥堵数据集进行检测,如果规则能够至少正确分类一个样本数据,则该规则就作为一个潜在分类器规则,否则该规则不会加入到分类器中;步骤4.3、从历史拥堵数据集中移除满足步骤4.2条件的数据;步骤4.4、重复步骤4.2至步骤4.3,直到所有降序排列规则或者历史拥堵数据集被全部检测完毕,完成对分类器的构建;步骤4.5、利用构建的分类器来预测未来时刻的交通拥堵状态。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1